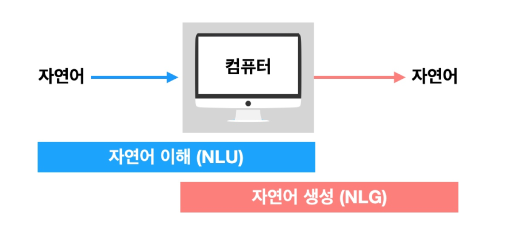
- 자연어 이해(Natural Language Understanding): 말, 텍스트로 입력된 자연어를 컴퓨터가 이해하는 과정
- 자연어 생성(Natural Language Generation): 컴퓨터가 이해하고 처리한 데이터를 다시 자연어로 생성하는 과정
자연어 생성
: 단어들의 시퀀스를 아웃풋으로 예측해내는 태스크
- 일반적으로 생성 모델은 각각의 디코딩 타임 스텝에서 전체 단어 사전에 대한 확률 분포를 예측한다, 따라서 실제로 단어를 생성하기 위해 모델의 예측 확률 분포를 이용해 각 타임 스탭의 단어로 변환하는 과정이 필요하다
용어정리
- decoding methods = 다양한 문장 생성 방법
- 언어모델: 주어진 단어들을 바탕으로 다음에 등장할 단어를 예측하는 모델
- continuation = context가 주어진 상태에서 다음에 등장할 단어를 예측해서 문장을 완성하는 것
- teacher forcing : 언어 모델이 학습을 수행할 때 매 시점마다 정답이 주어지는데, 특정 시점에서 틀린 답을 예측했더라도 다음 시점의 input은 원래의 정답이 들어가는 것
Abstract
-
자연어 모델의 text generation에서 어떤 것이 최고의 decoding strategy인가에 대한 의문점이 남아있다
- 예) story 생성하기
-
반직관적인 경험적 관찰은 likelihood를 training objective로 사용하는 것이 광범위한 language understanding 작업에 대한 high quality 모델로 이어지더라도 maximization-based decoding methods(beam search)은 degeneration으로 이어져 output text가 bland, incoherent하고 repetitive loop에 갇힌다는 것이다.
(likelihood를 사용하는 방법이 beam search 같은 모델의 경우에는 해결책이 될 수 없다는,, 뜻) -
해당 문제를 해결하고자, Nucleus Sampling 제시
- 기존의 decoding 전략들보다 neural language models에서 높은 질의 text를 이끄는 간단하지만 효율적인 방법
- text degeneration(악화)을 피한다
- 어떻게? 확률 질량의 대다수인 토큰의 dynamic nucleus에서 샘플링하여 probability distribution의 unreliable tail를 잘라내서(truncating)
-
실험
- current maximization-based와 stochastic decoding methods를 적절히 비교하고자, 각 방법으로부터의 generations를 'the distribution of human text along several axes(예. likelihood, diversity, repetition)'와 비교
-
실험 결과
1) maximization은 open-ended text generation(이게 뭘까)에서 부적합한 decoding objective이다
2) 현재 최고 언어 모델의 확률 분포는 unreliable tail을 가지고 있어 generation 동안에 잘라내져야 한다
3) Nucleus Sampling은 long-form text 생성에 현재 가장 좋은 디코딩 전략이다
(1) high-quality — human evaluation에 의해 측정
(2) human-written text만큼 다양.
1 Introduction
- top-quality generations는 likelihood를 최대화하는 text를 decode하는 것에 목표 두기 보다는 decoding method에서 randomness와 특히 top-k sampling에 의존했다(randomness랑 top-k sampling을 쓰는 generations 방법들이 높은 질의 결과를 가져온다,,,)
- top-k sampling: 다음 단어를 가장 가능성 있는 top k 선택에서 sampling하는 방법
maximization-based decoding: greedy search, beam search 등, 확률이 가장 높은 단어를 확정적으로 선택하는 deterministic한 문장 생성 방식
maximization-based decoding의 한계
-
사실 high probability인 output을 최대화하는 decoding 전략(예. beam search)은 GPT-2 Large 같은 state of the art models를 사용했을 때도 degenerate한 text로 이어진다(Figure1)

-
Figure 1 해석
- beam search의 경우 반복(좌측), pure sampling은 일관성 없는 문장 나열
- beam search의 경우 지나치게 일반적이고, 반복적이고 긴 문장이 생성된다.
-
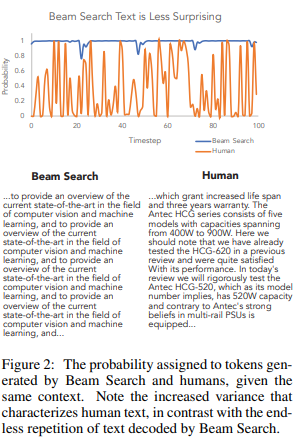
Figure 2(실제 문장의 확률 분포와 beam search가 생성한 문장의 비교) 해석
- beam search에 할당된 확률 분포에 자연적으로 생성되는 문장(human)이 어떻게 다른지 확인 가능
- 실제 사람이 생성하는 문장은 등장 확률이 낮은 단어도 자주 등장(오히려 beam search가 놀랍게도!! 덜 변화가 있다)
-
Figure 1의 우측 "pure sampling"
- pure sampling: 모델에 의해서 예측된 확률로부터 직접적으로 sampling 하는 것
- 결과인 text는 일관적이지 않고 문맥에 거의 연관이 없다
- pure sampling에서 생성된 문장은 왜 degenerate할까?
- 본 연구에서 우리는, "unreliable tail"이 비난해야 할 것임을 입증한다(이게 문제다!!!)
- unreliable tail: 전체에서 과도하게 표현되는 상대적으로 낮은 확률을 가진 수만 개의 후보 토큰으로 구성.
-
해당 문제를 극복하고자, 우리는 "Nucleus Sampling"을 소개
- 주요 직관은, 각 단계에서 대다수 확률 질량이 nucleus에 집중된다는 것
- nucleus: 1~1000 사이의 후보로 이루어지는 작은 vocabulary 집합
- 분포의 모양을 통제하기 위해서 unreliable tail을 충분히 suppressing하는 것 없이 (1) 고정된 top-k에 의존하거나, (2) temperature parameter를 쓰기보다 , 우리는 확률 질량에서 top-p portion을 샘플링하는 것을 제안한다
-> 역동적으로 candidate pool을 확장하거나 줄일 수 있다 !!
-
여기부터는 뒤에서 자세히~~(Figure3만 간단히)
-
현재 방법을 Nucleus Sampling과 비교하고자, 우리는 생성 문장의 다양한 분포를 'repetition으로 변환될 가능성', '생성된 텍스트의 복잡도' 같은 'reference distribution'에 비교한다(뒤의 여러 실험 결과들)
- 후자는 최대화 또는 top-k 샘플링에 의해 생성된 텍스트가 too probable하다는 것을 보여주며, 이는 human distribution으로부터 다양성의 부족과 어휘 사용의 차이를 나타낸다.
- 반면에 pure sampling은 lower generation quality에 상응하는 significantly less likely than the gold인 텍스트를 생성한다
-
Vocabulary usage와 Self-BLEU statistics는 top-k 샘플링을 human statisitcs와 맞추기 위해, 높은 값의 k가 필요함을 입증했다
-
하지만 높은 값의 k에 의존하는 generations는 자주 likelihood에서 높은 분산을 가진다 -> 이는 질적으로 관측 가능한 불일치 문제를 암시한다
-
Nucleus Sampling은 p의 값을 튜닝하는 과정에서 reference perplexity를 쉽게 매칭할 수 있다(distributional statisitcs를 매칭하고자 k를 충분히 높게 놓아서 발생한 incoherence를 피하면서)
-
Human Unified with Statistical Evaluation (HUSE)
- decoding 전략의 전반적인 quality와 다양성에 공동으로 평가하도록
- 이는 human이나 automatic evaluation 하나만 써서는 포착 불가능
- HUSE evaluation은 Nucleus Sampling이 decoding 전략 중 최고임을 입증
- decoding 전략의 전반적인 quality와 다양성에 공동으로 평가하도록
-
질적 연구를 위한 생성 예제
- 초기 문장을 이어가는 문장 예시
- Maximization과 top-k truncation 방법은 반복(파란색)
- temperature 있거나 없거나 한 sampling은 incoherence(빨간색)
- Nucleus sampling은 둘 다를 피함
- Figure3

2. Background
(+) Decoding Strategy
- 가장 기본적인 디코딩 전략
- 매 타임스텝마다 가장 높은 확률을 가지는 토큰을 다음 토큰으로 선택하는 전략

- 가장 기본적 + 직관적
- 시간 복잡도면에서 좋지만, 최종 정확도 관점에서 아쉬움
- 특정 시점 t의 확률 분포 상에서 1, 2등의 확률 차이가 매우 작더라도 1등만을 선택하기 때문
- 디코딩이 (특정 t 시점에서 끝나는 것이 아니라) 시퀀스 길이 N만큼의 시점 t가 있기 때문에 -> 단 한 번이라도 정답 토큰이 아닌 다른 토큰으로 예측하면 뒤의 디코딩에도 영향을 끼쳐 정확도면에서의 한계
2. Beam Search
- 등장 배경: Greedy Search의 시간 복잡도를 포기하고, 정확도를 높여보자!

- "가장 좋은 디코딩 방법": 가능한 모든 경우의 수를 고려해 누적 확률이 가장 높은 경우를 선택하는 것 -> 시간복잡도면에서 불가능
- 해당 시점에서 유망하다고 판단되는 beam k개를 골라 진행
- = 탐색의 영역을 k개의 가장 가능도가 높은 토큰들로 유지하며 다음 단계 탐색
- Greedy search가 놓칠 수 있는 시퀀스를 찾을 수 있다는 장점,
- 시간 복잡도 면에서 느리다는 단점
- -> beam k를 몇으로 설정하느냐가 중요(결과와 수행시간에 영향)
Beam search 관련 파이썬 코드 및 시각화 예시
- k = 5인 beam search 과정의 시각화

2.1 Text Generation Decoding Strategies
- 많은 연구들은 output을 high grammaticality이지만 low diversity로 생성하는 maximization으로 generation의 단점을 해결하고자 했다
- Generative Adversarial Networks (GANs)는 유망한 research direction이었지만 최신 연구들은, 'quality'와 'diversity'가 함께 고려되었을 때 -> GAN-generated text가 language models에서 generations을 수행하는 것을 실패함을 입증했다
- neural dialog systems 관련 연구는, task-specific diversity scoring function을 사용하거나 beam hypotheses를 충분히 다르게 제한하면서 diverse beam search에 대한 방법을 제시했다
- 해당 utility functions가 generations에서 desirable properties를 encourage하지만, 그들은 적합한 decoding strategy를 선택할 필요성을 없애지 않으며, 우리는 이런 관점에서 Nucleus sampling이 완전한 이점을 가질 것이라 본다.
- 마침내 Welleck et al. (2020)가 repeated tokens에서 training loss를 감소하고, 그와 동시에 암시적으로 frequent tokens에서 gradients를 줄이는 'unlikelihood loss'를 통해 neural text degeneration 문제를 다루기 시작했다
- 우리의 초점은, neural text degeneration을 노출하고, arbitrary models에서 사용될 수 있는 decoding solution을 제시하는 것이다(하지만 미래 연구는 training-time과 inference-time solutions를 결합하는 것이 될 것이다)
neural text generation
- Directed Generation: [입력 문장, 출력 문장] pair가 존재하는 경우
- Open-ended Generation: 입력 문장이 존재하지 않거나 context가 주어짐
2.2 OPEN-ENDED VS DIRECTED GENERATION
Directed generation
- 많은 텍스트 생성 task는 (input, output) pairs로 정의된다
- 이 때, output은 input의 constrained transformation이다
- 사용 예시로는, machine translation, data-to-text generation, summarization이 있다
- 주로 attention mechanism과 함께 encoder-decoder 아키텍처가 사용되거나, Transformer 같은 attention-based 아키텍처가 쓰인다
- generation은 일반적으로 beam search 사용해서 수행된다
- output이 input에 의해 tightly하게 범위가 지정돼, 반복과 일반성은 문제가 되지 않는다
- 하지만 포괄적인 search가 확률 최대화에 도움이 되기 때문에 1) 큰 beam size를 사용할 때와 2) 최근에는 정확한 추론을 사용하여 반직관적인 관찰을 사용할 때 유사한 문제가 보고되고 있다.
Open-ended generation
- 종류
(1) conditional story generation
(2) contextual text continuation(Figure 1)
문맥이 주어졌을 때 연결할 수 있는 일관성있는 부분을 만드는 것.
- 이 기법은 최근에, neural language models의 상당한 발전으로 유망한 research direction이 되었다
- 특징: input context는 허용 가능한 output generation의 공간을 제한하지만, directed generation settings와 달리 다음에 올 것에 대해서는 상당한 자유도가 있다.
- 우리 연구는 자유도가 높아진 neural text generation가 직면한 문제는 해결하지만, goal-oriented dialog 같은 일부 작업은 open-ended generation과 directed generation 사이의 어딘가에 있을 수도 있다.
3. LANGUAGE MODEL DECODING
open-ended generation task
- input text passage가 context로 주어졌을 때 task는 '주어진 문맥에서 일관성있는 연속인 text를 생성'하는 것이다
- 즉! tokens가 이 context로 주어졌을 때, task는 다음 continuation tokens를 생성하는 것 --> 그를 통해 completed sequence 을 얻기
- 모델이 를 흔히 알려진 text probability의 left-to-right decomposition을 사용해서 계산할 것임을 가정한다
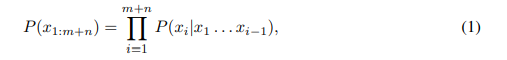
- 해당 (1) 식은, 특정한 'decoding strategty'를 사용해서 'generation token-by-token'을 생성하는데 쓰인다
- 모델이 를 흔히 알려진 text probability의 left-to-right decomposition을 사용해서 계산할 것임을 가정한다
Maximization-based decoding
- 특히 directed generation에서 가장 흔히 쓰이는 decoding objective
- 모델이 높은 질 텍스트에 높은 확률을 부여함을 가정하면서
- 해당 decoding 전략은 highest likelihood를 가진 continuation을 찾는다
continuation: context가 주어진 상태에서 다음에 등장할 단어를 예측해 문장을 완성하는 것
- 해당 decoding 전략은 highest likelihood를 가진 continuation을 찾는다
- recurrent neural language models이나 Transformers에서 최적의 argmax sequence를 찾는 일이 다루기 쉽기에, 흔한 일은 beam search를 사용하는 것이다
- 하지만 open-ended generation에 대한 몇 최신 연구들은 'maximization-based decoding이 high quality text로 이어지지 않음을 보고했다'
3.3 SAMPLING WITH TEMPERATURE
Sampling
- 조건부 확률 분포에 따라 다음에 올 단어를 랜덤으로 선택하는 방법
- 장점: 다양한 단어를 사용한 문장 생성 확률이 높아짐
- 단점: 어색한 표현 생성 확률도 높아짐
- 이를 위해, 확률이 높은 단어는 더 높이고, 낮은 단어는 더 낮추어서 확률분포를 조정하자 ! "temperature"
- temperature: 샘플링 시, 무작위성을 얼마나 조정할 것인지 결정(값이 0에 가까울수록 덜 랜덤해짐)
temperature를 낮추어 분포 를 더 선명하게 만듦.- 높은 확률의 단어의 가능성은 증가시키고 낮은 확률의 단어 가능성은 감소시키는 효과가 있음.


- sampling-based generation의 또 다른 흔한 방법은 temperature를 통해 probability distribution을 shape하는 것이다
- Temperature sampling은 text generation에 널리 적용되어왔다
- logits 와 temperature 가 주어지면, softmax는 다음과 같이 재추정된다
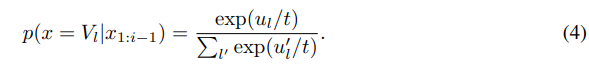
- 로 두면, 분포를 high probability events로 왜곡한다 -> 암묵적으로 꼬리 분포에서 질량을 내렸음을 뜻한다
일반적으로 문장 생성 시 을 사용해서 분포를 높은 확률 쪽으로 왜곡시켜 낮은 확률을 갖는 단어를 덜 샘플링하도록 함
- Low temperature sampling은 top-k sampling의 이슈를 부분적으로 줄인다고 알려져왔다.
- sampling 전에 distribution을 shaping해서
- 하지만 최근 연구에 따르면 temparature를 낮추면 generation quality가 향상되지만 diversity가 감소하는 비용이 발생한다.
3.2 Top-k Sampling
Top-K sampling
- sampling 방식 중 하나로, k개의 후보 단어를 먼저 필터링 한 후, 그 단어들 사이에서 확률 분포를 계산
- k=6으로 설정한 경우
- 장점
- 높은 확률 순 k개로 단어의 pool을 제한해, 확률이 낮은 단어를 제거 가능
(우측 "not", "the", "small", "told")- 단점
- 후보에 오를만한 단어임에도 Top-k개 안에 들지 못해 걸러질 수 있음
(좌측 "people", "big", "house", "cat")- 확률이 낮은 단어도 걸러지지 않을 수 있음
(우측 "down", "a")

- sampling procedure의 유망한 대안이 되었다
- Nucleus Sampling과 top-k는 둘다, 절단된 Neural LM distributions에서 sample한다('where to truncate'에서만 다르다 !)
- 'where to truncate'를 고르는 일은 generative model의 trustworthy prediction zone을 결정하는 것으로 해석될 수 있다
- 단어 분포에서 확률값 기준 상위 k개의 단어만을 선택
- 선택한 K개를 renormalize해서 새로운 분포를 생성하고 sampling
- 각 시간 단계에서 가능한 개의 다음 토큰이 상대 확률에 따라 샘플링된다
- 분포 가 주어지면,
- 우리는 vocabulary ⊂V를 를 최대화하는 size 의 set으로 정의한다
- 다음 을 가정했을 때
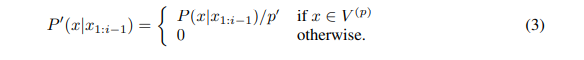
- distribution은 equation (3)에 있는대로 re-scaled되고, sampling은 그 분포에 기반해서 수행된다
- ( scaling factor 은 Nucleus Sampling과 달리 각 시점마다 다를 수 있다)
Difficulty in choosing a suitable value of k
- full distribution에서는 beam search나 sampling보다 sampling이 상당한 higher quality text로 이어지지만, constant 를 사용하는 것은 varying contexts에서 sub-optimal이다.
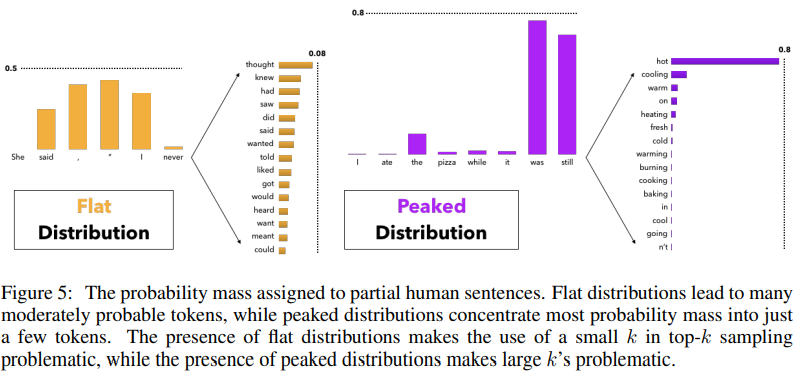
- Figure 5의 좌측
- 일부 상황에서는 다음 단어 분포의 head가 수십 또는 수백 개의 합리적인 옵션(예: 일반 상황에서 명사 또는 동사)에 걸쳐 평평할 수 있지만
- 다른 상황에서는 대부분의 확률 질량이 우측과 같이 하나 또는 적은 수의 토큰에 집중된다.
- 그러므로 가 작으면 일부 상황에서 단순하거나 일반적인 텍스트를 생성할 위험이 생기고, 가 크면 vocabulary에 재정규화에 의해 샘플링될 확률이 증가하는 부적절한 후보가 포함될 위험이 생긴다
- Nucleus Sampling에서 고려되는 candidate의 수는 중 하나의 선택에 대해 sampling이 포착하지 못하는 vocabulary에 대한 모델의 신뢰 영역의 변화에 따라 동적으로 증가/감소한다(Nucleus는 와 달리 해결책이 있다!).
3.1 NUCLEUS SAMPLING
Top-p Sampling
- 누적 확률 p 를 기준점으로 두고 단어를 선택
- p=0.92로 설정시 -> 누적 확률이 92% 를 넘지 않는 선에서만 단어들을 선택

- 연구에서 새로운 stochastic decoding method로서 제안
- 주요 아이디어는 확률분포의 모양을 사용해서 set of tokens가 sampled form이 되도록 결정하는 것이다
- 분포 가 주어졌을 때, 우리는 vocabulary ⊂ V를 다음과 같이 smallest set으로 정의한다
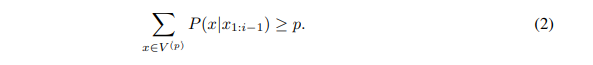
- 다음을 가정하면,
- original distribution은 다음 단어가 sampled되는 새로운 분포로 re-scale된다
- 실제로 '누적 확률 질량이 사전에 선택된 임계값 를 초과하는 가장 높은 확률 토큰을 선택하는 것'을 뜻한다
- sampling set의 크기는 각 시간 단계에서 확률분포의 모양에 따라 동적으로 조정된다
- 가 높은 값인 경우, 확률 질량의 대부분을 차지하는 어휘의 작은 부분집합이다 --> nucleus
- 단어 분포에서 누적확률분포 기준 상위 p까지의 단어를 선택
- 선택한 단어들을 top-k때와 같이 renormalize해서 새로운 분포를 만든 후, sampling
- 확률분포의 모양에 따라 sampling set의 크기가 가변적으로 변함
- p를 높게 설정할 경우, 선택된 일부 단어에 대부분의 확률값이 집중되게 되므로 이를 nuclues라고 명명
4 LIKELIHOOD EVALUATION
4.1 EXPERIMENTAL SETUP
- Generatively Pre-trained Transformer, version 2 (GPT2; Radford et al., 2019) 사용
- WebText(a 40GB collection of text scraped from the web)에서 훈련됨
- Large model (762M parameters)로 실험 수행
- comtext가 주어진 채로, 5,000개 text passages 생성에 기반을 두어 비교
- 이는 end-of-document token이나 maximum length of 200 tokens에 도달했을 때 끝난다
- text는 별도의 언급이 없다면 WebText의 held-out portion에 있는 문서의 첫 번째 단락(1-40 토큰으로 제한)에 따라 조건부로 생성.
4.2 PERPLEXITY
모델이 단어를 생성할 때 얼마나 헷갈리는지를 나타내는 척도
- 낮다면, 모델이 선택한 단어들이 확률값이 대체로 높음(우측)
- 높다면, 선택되는 단어들의 확률값이 대체로 낮고 고르게 분포(좌측)
generated text의 perplexity 계산
-
우리의 첫번째 실험
-
gold text의 perplexities와 비교(figure 6)
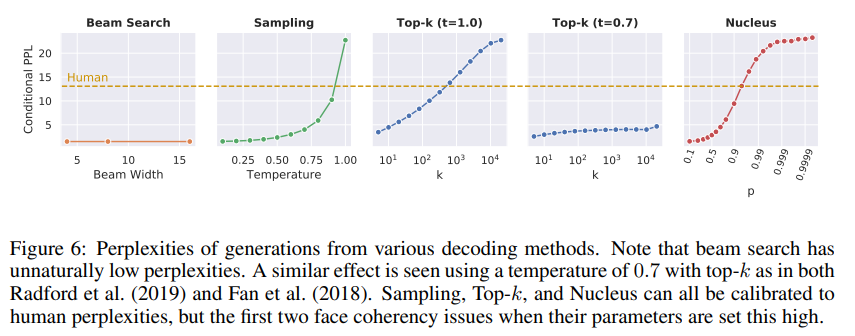
- 결과 해석
- beam search: 파라미터인 beam width를 아무리 조절해도 human perplexity에 도달 불가
- Temperature, Top-k: 파라미터를 잘 설정하면 human perplexity와 유사해짐(동등한 성능을 낼 수 있다)
Human perplexity는 모델이 원본 문장을 선택할 때의 확률로 계산
- 결과 해석
-
우리는 "최적의 generation strategy는 perplexity가 gold text와 close한 text를 생성해야 함"을 논했다(여기까지 보면, sampling이 좋은데 굳이 왜 새로운 모델을 제안하지? 싶은데 sampling이 문제인 이유!!!-> 지금부터)
-
비록 모델이 lower perplexity(higher probability)인 text를 생성할 능력을 가지지만, 그러한 text는 low diversity를 가지는 경향과 반복 루프에 갇히는 경향이 있다(Figure4)
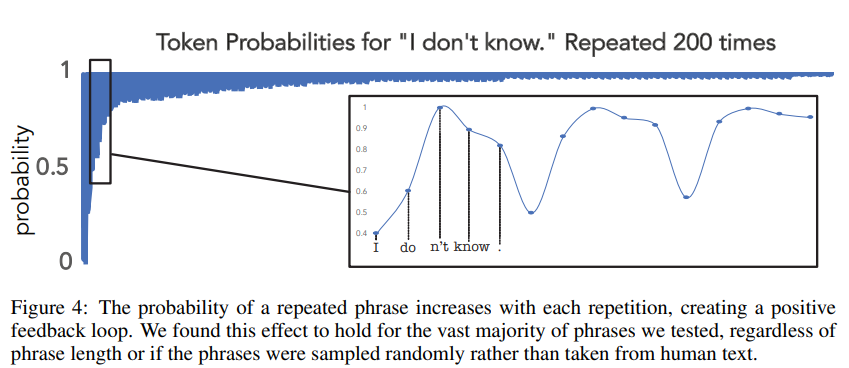
- Figure 4 해석
- 특정 단어나 구가 한 번 등장하면 그 뒤로부터 등장 확률이 높아진다
- 이는 일종의 positive feedback loop
- 다양한 구로 실험한 결과, 구의 길이, 종류에 상관없이 대부분 이러한 경향성을 보임
- Figure 4 해석
-
우리는 pure sampling에서 얻은 text의 perplexity가 gold보다 worse함을 확인가능하다
- 이는, 모델이 스스로를 혼동을 주고 있음을 나타낸다
- Figure1에 묘사된대로, 너무 많은 unlikely한 토큰을 sampling + text의 human distribution을 recover하기에 어렵게 만드는 문맥 생성
-
temperature를 낮게 설정하는 것은 diversity and repetition 이슈를 만든다(section5)
-
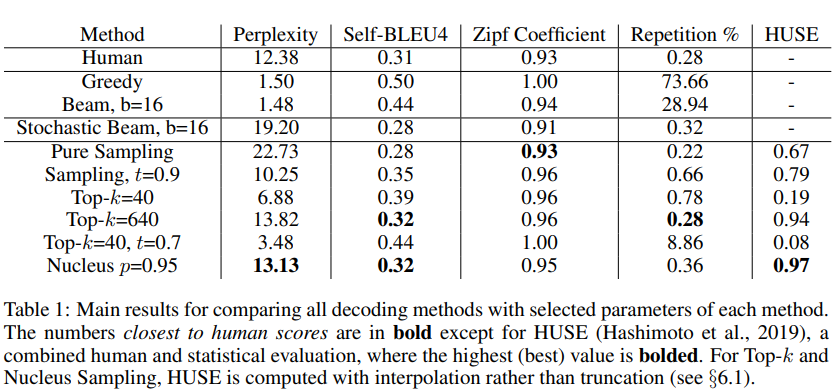
결론: 우리의 relatively fine-grained parameter 쓸기로 Nucleus Sampling은 human text에 가장 가까운 perplexity를 얻는다(Table1)
4.3 NATURAL LANGUAGE DOES NOT MAXIMIZE PROBABILITY
maximization에서 beam search가 최적의 조합을 못찾은 것 아닐까?
- maximization 관련한 이슈가 search error인지 궁금할 수도 있다
- 즉, 모델이 디코딩된 문장보다 더 높은 확률을 할당하는 고품질 문장이 있으며, beam search는 그것들을 찾는 데 실패했다.
- 하지만 Figure 2&6를 통해 natural text의 per-token probability가 평균으로 beam search로 생성된 text보다 훨씬 작음을 알 수 있다(maximization의 대표 사례인 beam search가 probability가 높은 확률을 가져야 되는데 작게 찾는 search error가 발생한 것이 문제 아닐까? 라고 의문을 제기할 수 있지만 사람이 만드는 probability보다 beam search의 probability가 더 크다는 것을 Figure2&6에서 확인 가능하므로 그건 아니다!! 는 뜻)
결론: 실제 문장들은 확률이 낮은 값을 선택하는 경우가 많다
- 실제 문장은 여러 연속 시간 단계에서 높은 확률 영역에 머무르는 경우가 거의 없으며, 대신 lower-probability지만 더 정보가 있는(informative) 단어를 선택한다.
- 더 나아가, 모델이 높은 확률을 할당한다해도, 자연어는 반복 루프에 빠지지도 않는다(Figure 4)(무슨 뜻일까)
왜 human-written text가 가장 probable한 text가 아닐까?
- 우리는 이것이 인간 언어의 본질적인 속성이라 추측한다
- text에 대한 global model 없이 한 단어에 대해 각 시간에 확률을 부여하는 언어모델은 이 효과를 포착하는데 어려움이 있을 것이다.
- Grice’s Maxims of Communication(대화의 격률)에 따르면 사람들은 뻔한 것을 말하거나 많은 정보가 담긴 단어를 연속해서 전달하며 이야기를 하지 않는다.
- 그러므로 모든 단어를 예측가능하게 만드는 것은 선호되지 않을 것이다
- 이는 단순히 더 큰 모델을 훈련시키거나 표준 단어당 학습 목표를 사용하여 신경 구조를 개선하는 것만으로 문제를 해결할 수 없게 만든다.
- 이러한 모델은 informative language보다는 가장 낮은 공통 denominator(분모)를 선호할 수밖에 없다.
5 DISTRIBUTIONAL STATISTICAL EVALUATION
5.1 ZIPF DISTRIBUTION ANALYSIS
- generations를 reference text와 비교하고자, vocabulary사용을 분석하는 것에서 시작하기로했다
사람이 생성한 문서는 일반적으로 지프의 법칙을 따른다고 알려져있다
- 지프의 법칙: 텍스트 중 어구별 빈출 순위와 빈도의 관계에서 k번째로 많은 어구의 빈도가 1번째로 많은 어구의 빈도의 1/k의 값이 되는 법칙
Zipf's law(지프의 법칙)
- 단어의 rank와 text의 빈도수 사이에 exponential 관계
- Zipfian coefficient s: 주어진 text에서 distribution 비교에 사용 가능(이론적으로 완벽한 지수 커브는 s=1)
- 다양한 decoding methods에서 선정된 파라미터에 대한 추정된 Zipf coefficients에 따른 vocabulary 분포(Figure7)
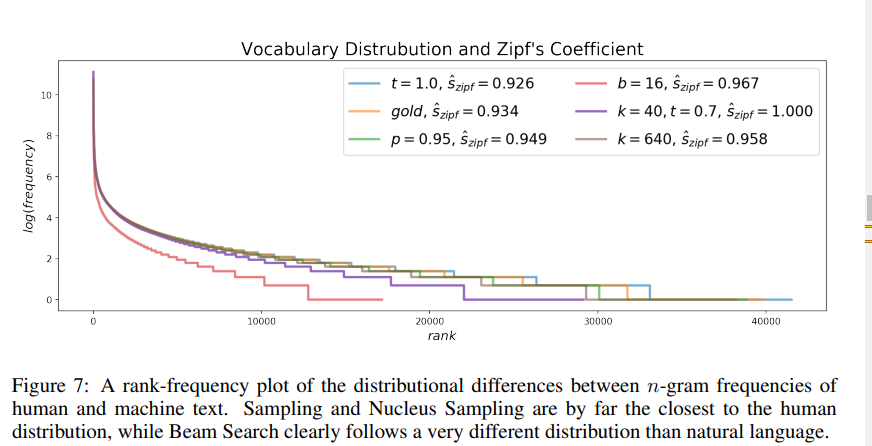
- 결과
- 문서 생성 후 zipf 분포에 피팅 결과, pure sampling(하늘)이 human distribution(gold text, 노랑)에 가장 가까움(그 다음이, Nucleus Sampling(연두))
- 하지만, pure sampling의 경우, 분포 뒷 부분을 보면 rare words의 빈도를 과대추정함을 보여줌
- 같은 이유로, pure sampling이 human text보다 higher perplexity를 가짐.
- 더 나아가, lower temperature sampling은 tail에서 rare words를 샘플링하는 것을 피함
5.2 SELF-BLEU
BLEU score
- 모델이 생성한 문장과 실제 정답 문장(reference)간 유사성을 비교하는 척도
- 서로 겹치는 단어 혹은 n-gram을 이용해 측정
-
diversity의 metric으로 사용
-
모델이 unconditional하게 5000개의 문장을 생성한 후, 1개의 문장을 측정 대상으로 나머지 4999개를 reference로 삼아 계산
-
(논문에서는) 계산이 오래 걸려, 5000개 중 1000개를 샘플링 해 계산하고 평균을 냄
-
Self-BLEU score가 높다면, 모델이 생성한 문장들이 서로 유사한 것
-
Self-BLEU score가 낮다면, 유사성이 적어 diversity가 높은 것(higher diversity)
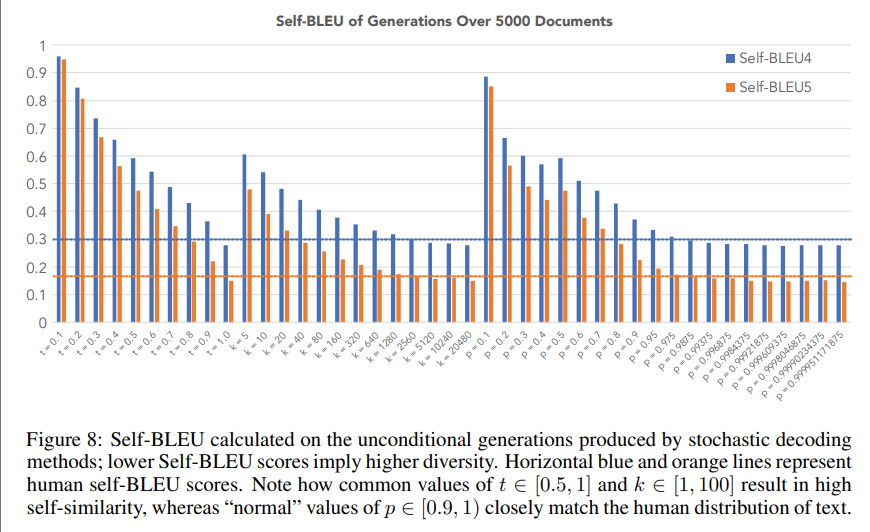
- 중간의 파랑, 주황 수평선은 사람이 생성한 문장들의 self-BLEU score를 의미
- 일반적으로 자주 사용되는 temperature 와 top-k의 은 self-BLEU가 높음 -> 즉, 생성한 문장들 간 self-similarity가 높음
- 반면에 top-p sampling은 일반적인(normal values) 파라미터 은 사람이 생성한 문장과 유사한 성능을 냄
결과 해석
- Self-BLEU는 Zipfian distribution을 따름(diversity measure로서)
- k, t의 높은 값이 refernece distribution에 가깝게 가기 위해 필요하다
5.3 REPETITION
-
text quality의 한 기여는 우리가 repetition을 양적화할 수 있다는 것
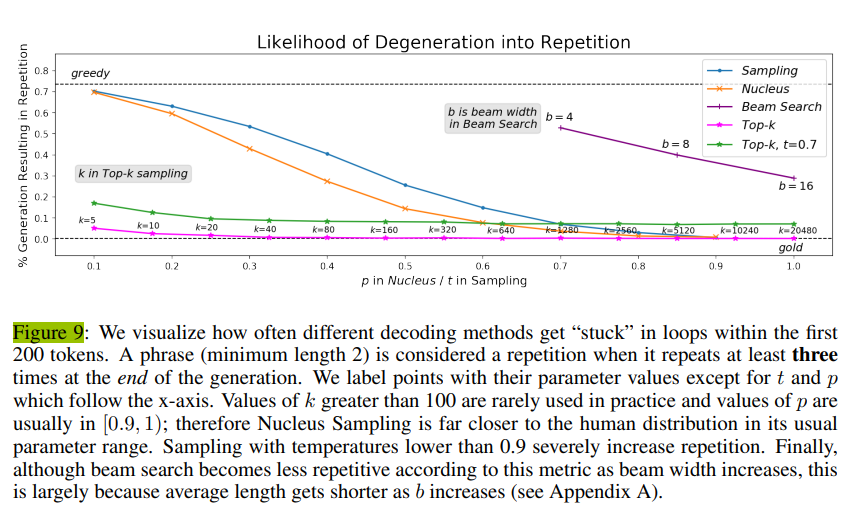
-
모델이 문서를 생성하며 첫 200 token 동안 반복적인 구(적어도 세 번)를 생성하는 비율 측정
-
Top-k는 (기존 논문에서 보통 설정하는 값인) 100 이하를 쓰면, repetition 등장 구간이 있음
-
sampling temperature도 0.9 아래로 설정시, repetition이 등장
-
top-p의 경우 [0.9,1)로 설정시, repetition 등장X
-
Beam search의 경우, beam size를 위 그래프보다 늘리면 repetition이 줄어들기는 하지만, 생성되는 문장들의 평균 길이가 짧아진다는 문제점이 있음
-
결과 해석
- Nucleus와 top-k sampling이 reasonable parameter ranges에 대해 가장 적은 repetition
- temperature sampling의 generations는 더 많은 repetition -> very high temperature가 쓰이더라도
- 모든 stochastic methods는 repetition issue를 직면
- tuning parameter가 너무 작을 때, overtruncate되어서 greedy search를 모방하는 경향
- 그러므로, 우리는 desirable generations를 위해 모든 distributional criteria로 Nucleus Sampling이 충족됨이라 결론 내린다.
6 HUMAN EVALUATION
6.1 HUMAN UNIFIED WITH STATISTICAL EVALUATION (HUSE)
등장 배경
- statistical evaluations(앞의 방식들)는 generated text의 일관성을 평가할 수 없다(따라서 생성된 문장들의 quality를 비교하기 위해 human evaluation은 필수적이다)
- 하지만 pure한 human evaluation은 생성된 문장들의 다양성을 고려하지 않는다
- 그러므로 HUSE 사용
HUSE 특징
- 모델이 생성한 문장과 사람이 생성한 문장을 구분하는 분류기(knn)를 학습하고 성능을 평가
- 분류기가 구분을 못할 수록(error가 높을 수록) 모델이 생성한 문장이 사람과 유사한 것
-
human, statistical evaluation을 결합
-
human과 model distributions 사이에서 text가 나왔을 때 discriminator를 훈련하면서 계산
- 그 때, 다음 두 feature를 기반으로: 언어 모델에 의해서 할당된 probability, generations의 typicality에 의한 human judgements
- quality와 diversity면에서 human distribution에 가까운 text는 likelihood evaluation과 human judgements 둘 다에서 잘 성능을 내야 한다
- 그 때, 다음 두 feature를 기반으로: 언어 모델에 의해서 할당된 probability, generations의 typicality에 의한 human judgements
-
이전 섹션에서 논의된 바와 같이, 가장 좋은 성능을 내는 디코딩 전략은 probability distribution에 truncation(potential tokens의 대다수에 0의 확률을 낸다)이다
-
처음에 HUSE를 적용하는 방법은 직접적으로 top-k와 Nucleus Sampling으로 이어졌고 truncation 때문에 거의 0의 점수를 받았다
-
대략적으로 HUSE를 계산하기 위한 text를 생성할 때 우리는 truncated distribution을 smoothing하면서 top-k와 Nucleus Sampling에서 original probability distribution을 mass 0.1로 채운다
-
각 decoding 알고리즘에 대해 200개의 generations를 annotate해, 20명의 annotator가 20개의 annotations를 생성하게 해서(Decoding 방법마다 200개의 문장이 존재하고, 한 문장 당 20명이 평가)
- 최종적으로 decoding scheme 당, 4000개의 annotations
-
KNN classifier로 HUSE 계산
- k=13 -> higher accuracy(실험 결과 Table 1, Nucleus가 가장 좋고 Top-k가 그 다음)
- k=13 -> higher accuracy(실험 결과 Table 1, Nucleus가 가장 좋고 Top-k가 그 다음)
6.2 QUALITATIVE ANALYSIS
- Figure 3은 대표 생성 예제다.
- beam search는 벗어날 수 없는 반복 루프에 갇힌다
- stochastic decoding schemes 중, 완전한 샘플링의 출력은 분명히 가장 이해하기 어려우며, 새의 일종인 "umidauda"라는 새로운 단어를 발명하기도 한다.
- Nucleus Sampling에 의한 generation은 완벽하지 않다
- 모델은 whales를 birds와 혼동하기도 한다
- 하지만 top-k 샘플링은 즉시 관련 없는 이벤트로 전환된다.
- 일반적으로 수행되는 것처럼 top-k 샘플링을 0.7의 temperature와 결합하면 출력이 반복으로 발전하여 고전적인 문제인 low-temperature decoding를 보여준다.
- Generations 관련 예시는 Appendix B에 더 있다
7 CONCLUSION
- open-ended language generation에 대한 가장 흔한 decoding 전략의 속성에 깊은 분석을 제공
- 우리는 likelihood maximizing decoding이 반복과 지나치게 일반적인 언어 사용(overly generic language usage)을 유발하는 반면, truncation(절단) 없는 샘플링 방법은 모델의 예측 분포의 low-confidence 꼬리로부터 샘플링될 위험이 있음을 보였다.
- 더 나아가 우리는 해결책으로 Nucleus Sampling을 제시
- 언어모델의 신뢰도 구간을 잘 포착 !
- 후속 연구에서 우리는 신뢰도의 구간이 역동적으로 characterize되기를, decoding 절차를 가이드하기 위한 더 semantic utility function이 포함되기를 고대한다
