NLP Study
1.[논문 리뷰]Recurrent Convolutional Neural Networks for Text Classification

RCNN
2.[논문 리뷰] Attention is all you need
sequence transduction models주요한 sequence transduction 모델들은 인코더와 디코더를 포함하는 복잡한 recurrent나 convolutional neural networks를 기반으로 한다.더 나아가 가장 뛰어난 성능의 모델들은
3.[논문 리뷰] Towards Ordinal Suicide Ideation Detection on Social Media
(소셜미디어에 대한 시각)소셜미디어의 보편성 → 전통적인 임상 환경 대신 개인이 suicide ideation을 표출할 수 있는 platform이 제시됨.기존 자살 위험 평가 neural methods가 있지만, 자살 위험의 고유 순서 무시한다는 한계.(ignor
4.[논문 리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
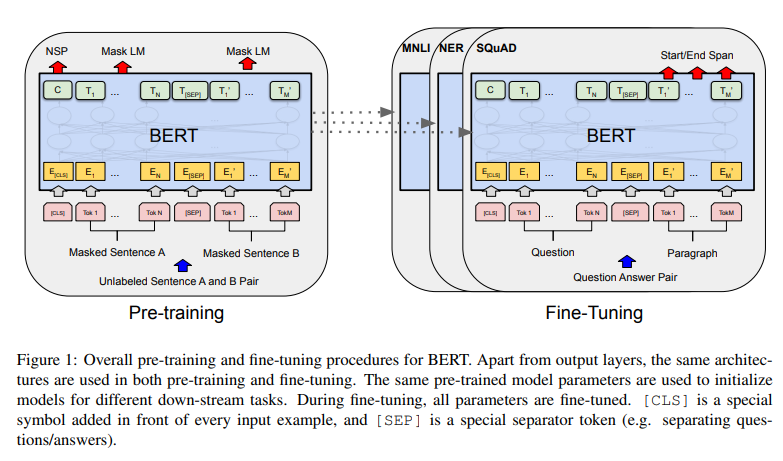
ABSTRACT
5.LSTM (LONG SHORT-TERM MEMORY)
0. Abstract recurrent backpropagation을 이용해서 extended time intervals의 정보를 축적하는 것을 학습하는 것은 오랜 시간이 걸린다. 이를 해결하고자 novel, efficient, gradient-based 방법인 "Lo
6.[논문 리뷰] Enriching Word Vectors with Subword Information
참고자료 책: 한국어 임베딩 > Enriching Word vectors with Subword Information Word vectors: 자연어 -> vector로 표현하는 word representation 방법 Fast: baseline(CBOW & Ski
7.[논문 리뷰] SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing

Abstract SentencePiece language-independent subword tokenizer and detokenizer Neural Machine Translation 같은 Neural-based text processing에서 쓰임 ca
8.Dependency Parsing
Dependency parsing 관련 논문: https://nlp.stanford.edu/pubs/emnlp2014-depparser.pdf 0. Sentence Structure 참고 문장의 구조를 파악하는 두 가지 방법 -> 문장의 의미를 정확하게 파악하기 위해, 정확한 문장 구조 파악은 중요하다 1. Phrase-structure grammar(...
9.[NLP 논문 리뷰] NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
* 논문 소개 * 참고 Attention mechanism이 처음으로 소개된 논문 attention보다는 soft-alignment로 논문이 소개 > 용어 정리 Soft-alignment(attention): source word -> target에 대한 정보를 스
10.[논문 리뷰] THE CURIOUS CASE OF NEURAL TEXT DeGENERATION
자연어 처리 과정 자연어 이해(Natural Language Understanding): 말, 텍스트로 입력된 자연어를 컴퓨터가 이해하는 과정 자연어 생성(Natural Language Generation): 컴퓨터가 이해하고 처리한 데이터를 다시 자연어로 생성하는
11.[논문 리뷰] Barack’s Wife Hillary: Using Knowledge Graphs for Fact-Aware Language Modeling
0. Abstract * 과거 연구의 한계 * 사람의 언어를 모델링하는 것은 유창한 텍스트와 사실 지식 모두가 필요하다 하지만 전통적인 언어 모델들은 훈련 때 본 사실들만 기억하는 것이 가능하고, 그것들을 회고하는데 어려움이 있다 * 본 연구에서는 * 이를 다루고자,
12.Big Bird: Transformers for Longer Sequences
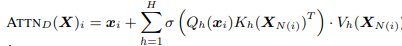
Bert 같은 트랜스포머 기반의 모델은 NLP의 딥러닝에서 성공적인 효과를 가져왔다.핵심적인 한계는 full 어텐션 메커니즘으로인한 특히 메모리의 양에서 sequence 길이에 대한 quadratic dependency였다. 이를 해결하고자, 우리는 BIGBIRD를 제
13.[논문 리뷰] Locally Typical Sampling

typical_p (float, optional, defaults to 1.0) — The amount of probability mass from the original distribution to be considered in typical decoding. If
14.[논문 리뷰] DIVERSE BEAM SEARCH: DECODING DIVERSE SOLUTIONS FROM NEURAL SEQUENCE MODELS
Abstract Neural sequence models는 time-series data를 모델하고자 널리 사용된다 마찬가지로 보편적인 것은 이러한 모델에서 출력 시퀀스를 디코딩하기 위한 대략적인 추론 알고리즘으로 빔 검색(BS)을 사용하는 것이다. BS explo
15.[NLP23-1_2] BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension(2020, ACL)
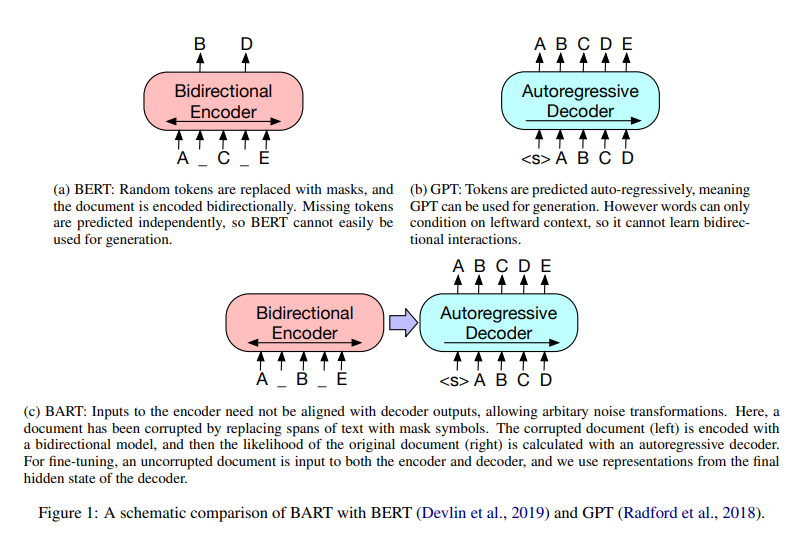
BART denoising autoencoder, for pretraining sequence-to-sequence modelstrain1) corrupting text with an arbitrary noising function, 2) learning a mode
16.[NLP 23-1_1] SimCSE: Simple Contrastive Learning of Sentence Embeddings(2021, EMNLP)
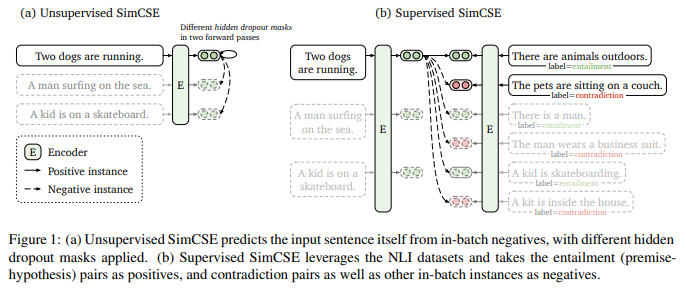
SimCSE: simple contrastive learning framework로서 sentence embedding의 SOTA를 앞섬방법1 => '비지도학습'으로 진행input 문장을 받고그 자신을 contrastive objective에서 예측함(noise로 쓰이
17.[NLP 23-1_3] Mutual Information Alleviates Hallucinations in Abstractive Summarization
abstractive summarization model에서 생성된 언어의 질이 향상되었지만, 해당 모델들은 여전히 환각 하는 경향성을 가지고 있다즉, 결과인 내용은 source document에 의해서 이루어지지 않는다수 많은 연구들이 이를 고치려고 했지만 한계가 있
18.[NLP 23_1]
자세한 논문 내용 확인 링크:Pretrained multilingual models (PMMs)을 새로운 언어에 평가해보기Challenging한 이유(1) the small corpus size(2) the narrow domain논문에서 발견한 사실continued
19.[NLP 23-1] Types of Out-of-Distribution Texts and How to Detect Them(EMNLP, 2021)
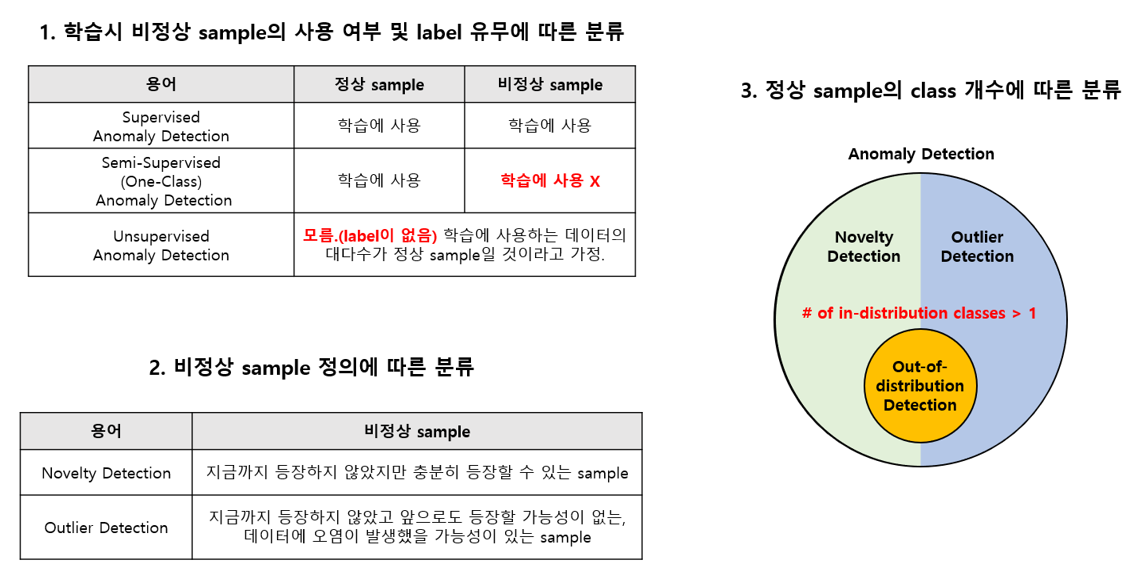
현대 NLP 모델은 training과 test의 distribution이 같을 때 당연히 잘 작동예를 들어서 같은 benchmark 데이터셋일때하지만, out-of-distribution(OOD)한 예제들을 자주 직면하게 됨distribution이 다르면, 최근 모델들
20.[NLP 23_1] What is Twitter, a social network or a news media?
Introduction트위터의 등장 배경, 구성요소(follow, followed)에 대한 설명: 그 관계가 상호작용일 필요는 없음, follower가 된다는 것은 tweets라 불리는 메시지를 받겠다는 의미, RT(=retweet)으로 답변을 하며 이를 통해 정보를
21.[NLP 23-1] Sequential Modelling of the Evolution of Word Representations for Semantic Change Detection(EMNLP, 2020)
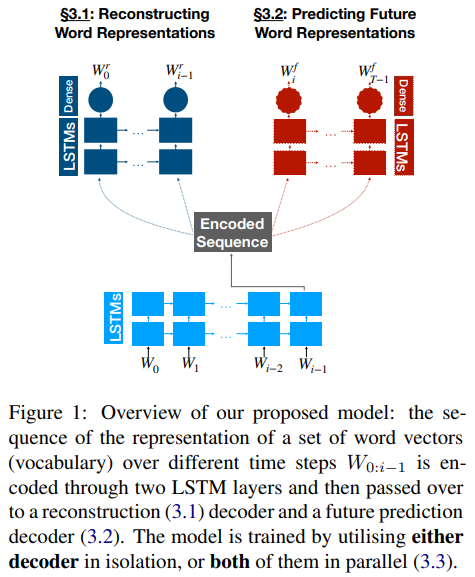
1 Introduction 2 Related Work 3 Methods 3.1 Reconstructing Word Representations 3.2 Predicting Future Word Representations 3.3 Joint Mode 3.4 Model Eq
22.[NLP Paper Review] Is ChatGPT a General-Purpose Natural Language Processing Task Solver? (EMNLP, 2023)
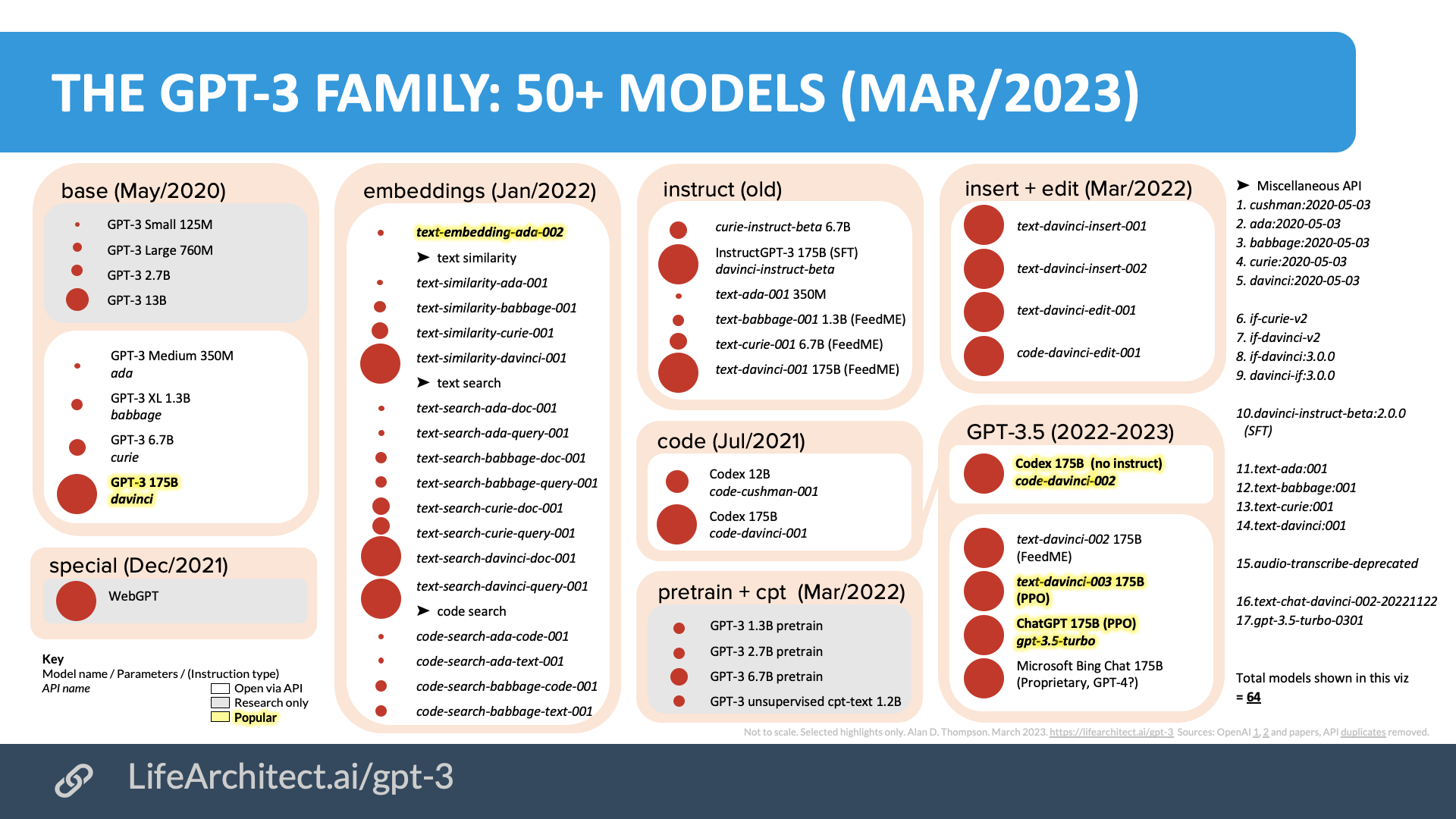
zero-shot learning ability of ChatGPT를 분석하기20개의 데이터 + 7개의 Task결과favoring reasoning capabilities (e.g., arithmetic reasoning)에 챗지피티가 유능함sequence taggin
23.[NLP. 24-1] Tree of Thoughts:Deliberate Problem Solving with Large Language Models (Neurips, 2024)
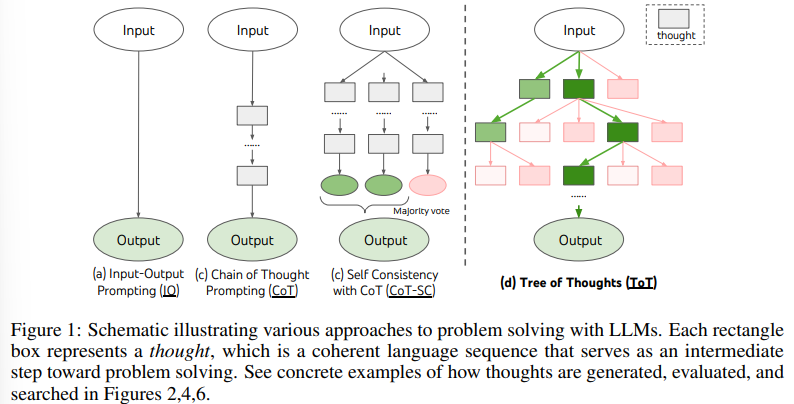
본 논문은 Neurips 2024 에 게재되었다.LLM이 많은 사고를 필요로 하는 넓은 범위의 task에서 엄청난 가능성을 보여주고 있다.이런 방법들은 여전히 text를 생성할 때 autoregressive mechanism가 모든 과정들에 기반해있다. (아직 auto