0 Anomaly Detection
해당 부분은 https://hoya012.github.io/blog/anomaly-detection-overview-1/ 를 참고하여 작성하였습니다
Out-of-Distribution(OOD) 문제
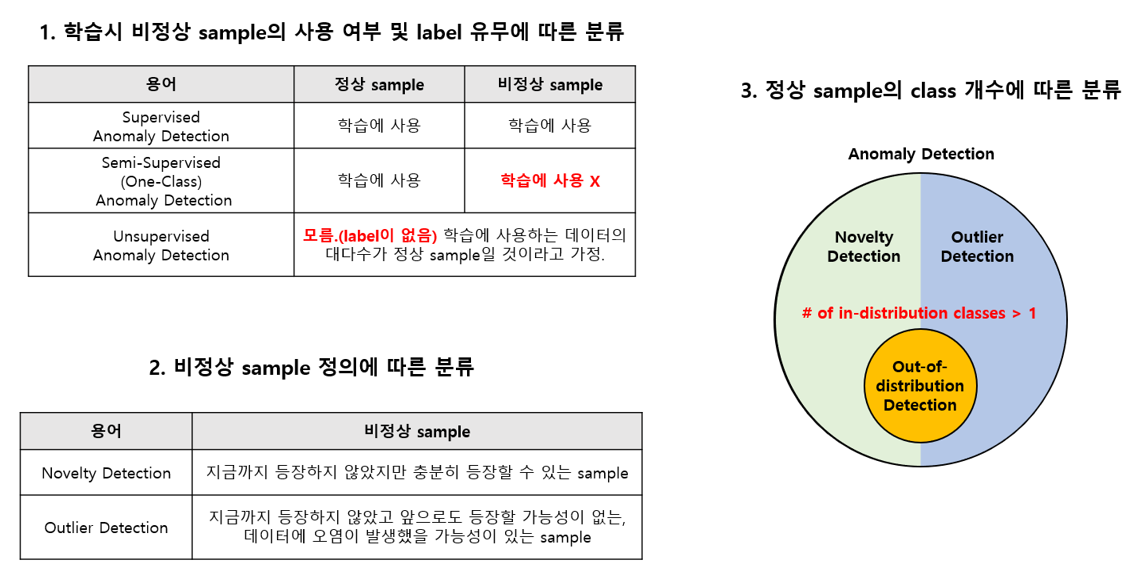
- 정의
- 현재 보유하고 있는 In-distribution 데이터셋을 이용해 multi-class classification network를 학습 시킨 후,
- test 단계에서 In-distribution test set은 정확하게 예측하고 Out-of-distribution 데이터 셋은 걸러내는 것
- test 단계에서의 목표
- OOD를 test 단계에 넣어주는 경우, 그에 대한 이상적인 결과는 어떠한 class로도 예측되지 않도록 각 class를 (1/class 개수) 확률로 uniform 하게 예측하는 것
- high-confidence prediction이 관찰되지 않도록 하자 !
예시
- 0~9까지 숫자를 예측하는 MNIST web demo 페이지에서 ‘미소 짓는 얼굴’
- 이상치임을 인식해야 함
- 어떻게? : 분류기 학습할 때, 0~9에 속하지 않는 샘플들을 모아서 unknown이라는 11번째 class로 가정후, 11-way classification으로 문제를 바꾸기 ⇒ 한계점 많음
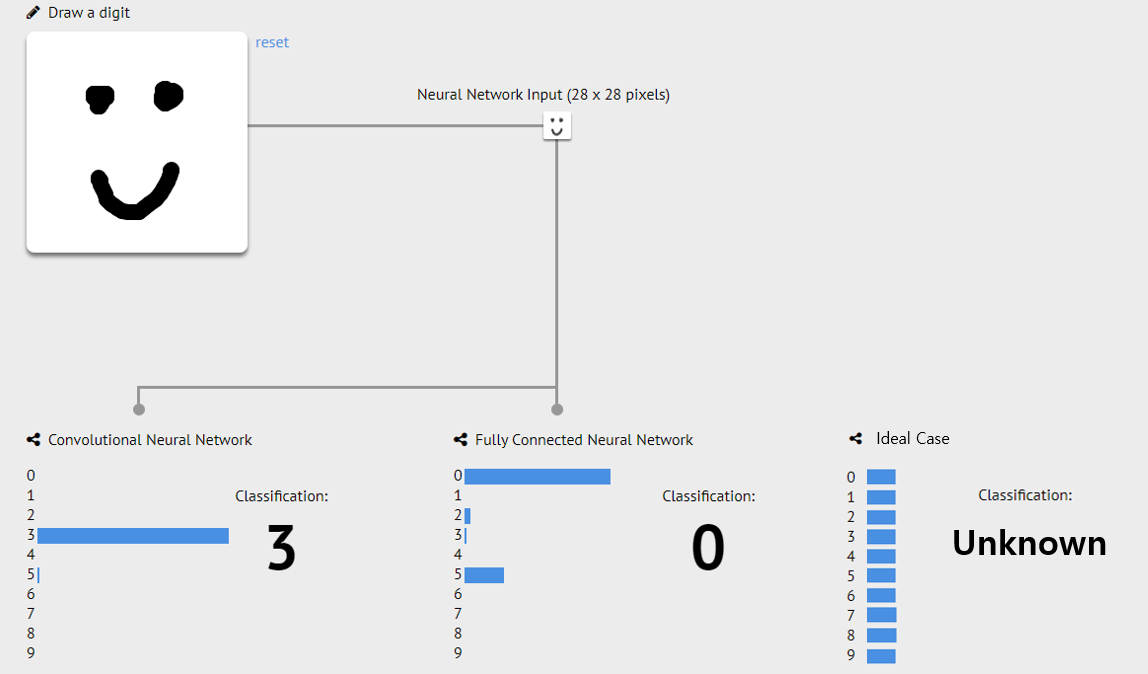
- high-confidence prediction을 보여주는 예시(3, 0)
1 Introduction
Background
- NLP 모델은 training과 test의 distribution이 같을 때 당연히 잘 작동
- 하지만, 모델이 실제 환경에 배포될 때 훈련 데이터와 다른 분포의 OOD(out-of-distribution) 예제를 만나는 것이 일반적임
- distribution이 다르면, 모델들은 신뢰할 수 없거나 치명적인 예측을 할 가능성이 높음
- -> 사용자 신뢰에 영향을 끼침
- distribution이 다르면, 모델들은 신뢰할 수 없거나 치명적인 예측을 할 가능성이 높음
- 그렇기에, OOD inputs를 잘 알아차려서 모델의 inference-time behavior를 잘 수정하고 보류, 인간의 피드백을 요청하거나 추가 정보를 수집하는 과정이 중요
Background_NLP
- 현대 NLP 작업들은 1) 특정 task(예. 대화의 의도 분류)나 2) 임의의 in-distribution(ID) 및 OOD 데이터셋 쌍에 초점을 둠
- 예) 감성 분류 데이터셋을 ID로 하고 자연어 추론 데이터셋을 OOD로 취하는 것
- 하지만, 실제 세팅에서는 사용자가 일반적으로 의도된 작업을 알기 때문에 다른 작업을 위한 입력을 받는 것은 드뭄.
- 더 나아가 실제로 예제들은 다양한 이유들로 OOD로 고려됨
- 희귀한, 도메인 외, 적대적 등
- 이런 광범위한 분포 변화로 인해 테스트 분포에 대한 가정 없이 임의의 OOD 예제를 잘 탐지하는 알고리즘 개발은 사실상 거의 불가능
- 더 나아가 실제로 예제들은 다양한 이유들로 OOD로 고려됨
In this paper
- NLP 문제에서 일반적인 분포 변화의 유형에 따라 OOD 예제를 분류
- 구체적으로, 입력(예: 영화 리뷰)은
- 1) 서로 다른 레이블에서 불변인 background features(예: 장르)과
- 2) 예측 작업에서 구별력이 있는 semantic features(예: 감성 단어)으로 표현될 수 있다고 가정
- 구체적으로, 입력(예: 영화 리뷰)은
- 따라서 test time 때 주요한 변화로 특징화되는 두 가지 유형의 OOD 예제를 고려
- background와 semantic features
- 두 유형의 변화가 종종 동시에 발생하지만, 이럴 때는 하나가 우세하게 됨
- 예1) background feature가 우세한 경우: 도메인이나 텍스트의 스타일이 변경되는 경우
- 예2) semantic feature가 우세한 경우: test 때 unseen classes 가 등장한 경우
[GPT]
- "background features"
- refer to features that are present in both the training and testing data but have different distributions. -> train/test 모두에 나타나지만 다른 distribution을 가지는 feature
- For example, if a model is trained on text data from news articles, but during testing, it encounters text data from social media posts, then the difference in the style of writing and vocabulary used between these two types of text would be considered as background features.
- "semantic features"
- refer to features that are not present in the training data and thus are out-of-distribution. -> training에서 안나타나서 OOD로 고려
- For example, if a model is trained on text data related to sports, but during testing, it encounters text data related to politics, then the differences in the vocabulary and topics discussed between these two types of text would be considered as semantic features.
Method
- 두 분류(background and semantic features)를 사용해
- OOD 탐지의 두 가지 주요 접근 방식-> 평가
- 모델의 예측 신뢰도를 사용하는 보정(calibration) 방법
- 학습 입력의 분포를 적합시키는 밀도 추정(density estimation) 방법
- OOD 탐지의 두 가지 주요 접근 방식-> 평가
- 본 연구에서는
- 두 방식을 distribution shift의 유형에 따라 암묵적 가정을 하고,
- 각 유형의 변화에 따라 behavioral difference가 발생함을 입증
- 실제로, 시뮬레이션과 실제 데이터셋에서 구성된 ID/OOD 쌍을 연구하여,
- density estimation method가 background features의 shift에 대해 더 잘 대응하며, background features의 shift pairs에서 항상 calibration method를 능가함을 입증
- semantic shift pair에서는 반대의 결과로, calibration method가 항상 더 높은 성능을 발휘
challenge datasets에서의 성능
- background and semantic shift의 관점에서 challenge datasets에서 감지 성능을 분석
- 해당 challenge datasets은 두 방법 모두에 대한 재미있는 실패 사례를 제공
- 모델이 spurious(거짓된) semantic features 때문에 over-confident할 때, Calibration methods 완전 실패.
- density estimation method가 약간 더 견고하지만, 언어 모델은 텍스트의 확률을 크게 높이는 반복적인 단어들에 의해 쉽게 속아넘어감
- 연구 결과는 모델 개발과 OOD 감지 방법의 공정한 비교를 위해 OOD의 더 나은 정의와 이에 상응하는 평가 데이터셋이 필요함을 시사.
6 Related Work
Distribution shift in the wild.
- OOD detection 관련 이전 연구들은 test time 때 발견되는 distribution shift의 유형에 대해서 구분하지 않았고, 다양한 데이터셋을 사용해서 합성 ID/ODD pair를 만듦
- 최근에 real-world distribution shifts를 연구하는 경우가 늘어나고 있음
- 다양한 distribution shift 환경이 있는 해당 벤치마크에서 단일 감지 방법으로 좋은 성과를 거두는 것은 불가능
- 본 연구에서는 distribution shift의 특성화와 관련된 프레임워크를 탐지
- semantic shift와 background(=non-semantic) shift를 따라서
- 결과적으로, 현재 모델의 성능 향상에 빛을 발휘
OOD detection in NLP.
- 1) dialogue systems 같은 production과 2) healthcare 같은 high-stake application에서는 중요하지만, 지금까지 NLP에서는 상대적으로 관심이 적었음
- 최근 연구들은 pre-trained transformer model의 calibration(교정)을 evaluated/improved해옴
- 그 결과 pre-trained transformer model가 잘 calibration(교정)이 되어, 이전 모델보다 OOD 탐지에 우수함을 입증
- 본 연구는 교정에 기반을 둔(calibration-based) 탐지가 background shift를 만났을 때 생기는 한계를 밝힘
- 이와 달리 다른 연구들은 특정 task(예.prototypical(원형) network for low-resource text classification, data augmentation for intent classification)에 초점
Inductive bias in OOD detection.
- 본 연구는 방법의 효율성이, 가정 'distribution shift가 test data에 맞는지 아닌지'에 크게 의존함을 입증
calibration, density method 방법 둘이, semantic/background 둘 중 하나에 더 잘 맞는다는 것을 확인했다는 뜻같은데 => test data에 없는게 semantic, 있는게 background니까, 그리고 두 방법이 두 shift중에 더 잘맞구 덜 맞는게 잇으니까
- distribution shift의 유형에 대한 사전 지식을 포함하는 직관적인 방법 중 하나는 훈련할 때 유사한 OOD 데이터를 보강하는 것
- = outlier exposure method
- question answering에서 효율성이 입증
- = outlier exposure method
- 적절한 유형의 OOD 데이터를 얻는 것이 어려울 수 있기에,
- 다른 연구들은 semantic features와 background features를 모두 포착하는 균형을 달성하기 위해 calibration과 density estimation 방법을 혼용해서 사용.
- 이런 모델은 discriminative loss와 self-supervised loss를 사용하여 훈련
- 다른 연구들은 semantic features와 background features를 모두 포착하는 균형을 달성하기 위해 calibration과 density estimation 방법을 혼용해서 사용.
Domain adaptation versus OOD detection.
- OOD data의 효율성을 다루는 두 방법
- 1) 도메인(background shifts)에 대해서 잘 수행하는 모델 생성
- i.e., domain adaptation
- 2) 모델이 데이터 분포의 변화를 감지하고 예측을 하지 않는 것.
- 1) 도메인(background shifts)에 대해서 잘 수행하는 모델 생성
- 본 연구에서 2), 모든 종류의 OOD 데이터로부터 방어하고 싶음
- 이는 일반적으로 OOD data에 대한 접근에 의존하는 domain adaptation과는 다른 방향
- 이런 설정은 1)보다 더 중요할 수 있음
- safety-critical applications에 대해서(health care같은)
- 왜냐하면, 잘못된 예측의 잠재적 비용이 더 커서,
- 예측을 하지 않는 것과 같이 OOD 데이터를 더 보수적으로 처리하는 접근 방식이 필요할 수 있기 때문
- 또한 selective prediction에서도 성능을 향상시키는 데 도움이 될 수 있음
우리 Bd는 1) 방향..? DEP이랑 같이 있을 때, BD를 찾아야 되니까
2 Categorization of OOD Examples
2.1 Problem Statement
- 각 예제가 1) input x ∈ 와 2) 라벨 y ∈ 로 구성된 -> 분류 task
- OOD detection task에서
- training dataset of pairs가 주어짐
- training data distribution 에서 샘플됨
- training dataset of pairs가 주어짐
- Inference time 때 input x' ∈ 가 주어지면
- OOD detection의 목표는 x'이 에서 샘플링 된 것인지 알아차리는 것
2.2 Types of Distribution Shifts
-
가정1. 인풋 , 의 어떠한 representation도 two independent와 disjoint components로 분해 가능
- background features: ∈
- semantic features: ∈
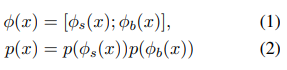
-
가정2. 는 label에 independent이고, 는 아님, ∀y ∈
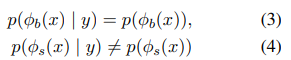
- : ground truth distribution
분해 방법 정리
-
background features: population-level statistics로 구성(label에 의존X)
-
semantic features: label과 강한 상관관계
-
유사한 decomposition이 이전 연구(style transfer)에서 사용
- sentence는 embedding space에서 content(semantic)과 style (background)으로 분해
-
해당 분해 방법에 의존해서
- OOD data의 유형을 semantic 또는 background shift로 분류
- distribution shift가 각각 나 에 의한 것인지 봄
- sentiment classification corpus(예. IMDB : GoodReads)로
- background shift의 예는
- positive review (e.g. “best”, “beautifully”) -> 거의 같음
- background phrases는 바뀜(e.g. “movie” vs “book”)
- semantic shift는
- test time 때 unseen classes를 봤을 때 발생
- 예) 음식 예약 요청을 받았을 때 비행기를 예약하는 dialogue system, 대답할 수 없는 질문을 다루는 question-answering system
- background shift의 예는
- 이 때 다음을 명시함
- 두 유형의 shift가 실제 상황에서는 동시에 일어날 수 있음,
- categorization은 shift의 가장 유망한 유형에 기반함
- OOD data의 유형을 semantic 또는 background shift로 분류
3 OOD Detection Methods
- input x ∈ 를 ID나 OOD로 분류하기 위해서
- score 를 만들고 그것을 < 일 때, OOD로 분류
- 이때 은 사전에 정의된 임계값
- 대다수의 방법은 를 어떻게 정의하냐에 따라 다름
- OOD detection에서 흔히 쓰이는 두 유형의 방법을 이제부터 설명
1 Calibration methods.
- 모델의 prediction confidence를 score로 사용
- well-calibrated인 모델의 confidence score는 predicted label이 맞다는 likelihood를 반영
- OOD data에서의 성능이 ID data에서보다 일반적으로 낮기에, lower confidence는 input이 더 OOD 같음을 시사함
- confidence score를 얻는 가장 간단한 방법은
- probabilistic classifier 로 만들어진 conditional probability를 직접적으로 쓰는 것
- 는 maximum softmax probability (MSP)라 불림

- 추가적인 calibration steps를 취하는 더 구체적인 방법이 있지만
- MSP는 강한 베이스라인임을 입증
- 특히 이 pre-trained transformers에서 fine-tuned되었을 때
[GPT]
Calibration methods in out-of-distribution (OOD) settings aim to improve the reliability of machine learning models by ensuring that the model's predictions are appropriately confident and calibrated.
In an OOD setting, the model is expected to make predictions on input data that may differ from the training data distribution, and therefore, the model may be overconfident or underconfident in its predictions. Calibration methods aim to address this issue by adjusting the probabilities outputted by the model to better reflect its uncertainty and confidence in its predictions.
One common method for calibration in OOD settings is called temperature scaling. Temperature scaling involves modifying the softmax function used to compute the probabilities for each output class by introducing a temperature parameter. The temperature parameter scales the logits (outputs of the final layer of the model) before they are passed through the softmax function. The scaled logits are then used to compute the class probabilities. By adjusting the temperature parameter, the probabilities can be calibrated to better reflect the model's confidence in its predictions.
Another approach to calibration in OOD settings is through the use of auxiliary datasets that are used to help adjust the probabilities. One such method is called the "class-balanced loss" method, which involves training the model on a dataset with a more balanced class distribution than the original training data. This can help to reduce overconfidence in the model's predictions by ensuring that the model is not biased towards predicting the most common classes.
Overall, calibration methods in OOD settings are important for improving the reliability of machine learning models by ensuring that their predictions are appropriately calibrated and reflect the model's confidence in its predictions.
2 Density estimation methods.
- input의 likelihood 사용해서, density estimtor를 score로 줌
- text, sequence data에 대해서 언어모델 은 주로 를 추정하기 위해서 사용
- sequence의 길이에 의한 bias를 피하기 위해 token perplexity(PPL)을 score로서 사용
- sequence
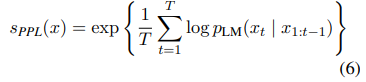
- CV에서 flow-based models를 사용하는 density estimation methods에 대한 많은 연구들이 있지만 text에서 OOD detection을 위한 estimation methods 연구는 별로 없음
Implicit assumptions on OOD.
- OOD detection 때 생기는 질문은 distribution이 test time 때 어떻게 shift되느냐
- 즉, ID와 OOD 예시들 사이의 차이를 특정화하는 것
- 훈련 때 OOD data에 대한 접근 없이, 지식은 inductive bias를 통해서 detector에 통합되어야 함
- 이 때 1 calibration method는 classifier에 의해 추정된 에 의존
- 그러므로 라벨과 상관관계가 있는 semantic features에 더 영향력 있음
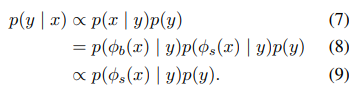
- 2 그에 반해 density estimation methods는 input의 모든 구성요소(background, semantic features 포함)에 민감
- 이 때 1 calibration method는 classifier에 의해 추정된 에 의존
- 다음 section에서 implicit assumptions가 다양한 ID/OOD pairs에서 성능에 어떤 영향 끼쳤는지 알아봄
4 Simulation of Distribution Shifts
- illustrative example로서 toy OOD detection 문제를 만듦
- fig1에 묘사된 binary classification setting과 유사하게
- estimation errors를 제거하고 optimal calibration과 density estimation detectors들을 통제된 semantic, background shifts 하에 연구하는 것을 가능하게 함
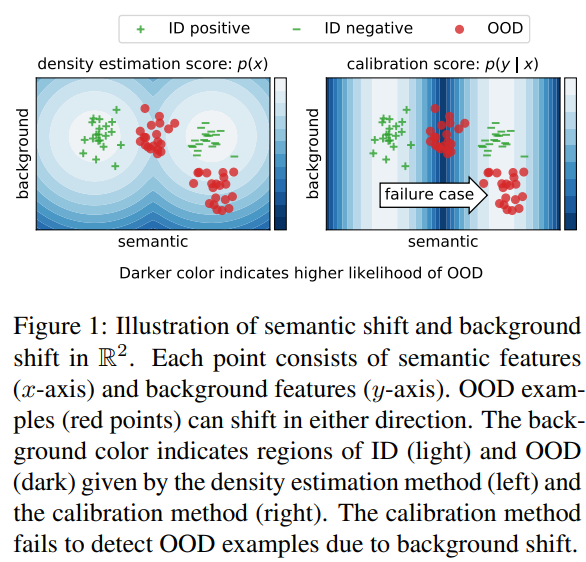
- (FIg1 해석) calibration은 background shift 때문에 OOD 예측을 실패
4.1 Data Generation
Gaussian Mixture Model(GMM)에서 ID examples들을 만듦
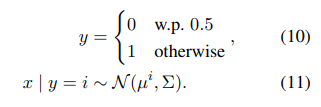
- centroid는 semantic, background features의 set
- = [, ] and = [−, ] ( ∈ , ∈ )
- Fig1의 2D case에서 이는 두 가우시안 클러스터에 상응함
- 첫번째가 semantic feature
- 두번째가 background feature
- 이 경우에 우리는 어떠한 input이 주어져도 true calibrated score 와 true density 를 안다
- 특히 최적의 classifier는 LDA predictor에 의해서 주어짐
- 를 identity matrix로 설정하면, 그것은 weights [2, ]인 linear classifier에 상응
- ∈ 은 모든 0의 벡터다
- 간단하게 하고자, = 과 = 로 설정
- 이때, ∈ , ∈ 은 모든 0의 벡터임
4.2 Semantic Shift
- OOD examples set를 semantic shift를 사용해서 생성
- ID와 OOD의 semantic features의 overlap을 다양화하면서
- 공식적으로 overlap rate 을 다음과 같이 다양화함
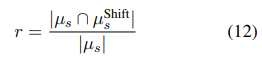
- 이때 , ∈ 는 각각 ID와 OOD의 semantic feature의 set임
- ∩ 는 둘 사이의 common features를 나타내고
- |·|는 elements의 수를 나타냄
- total dimensions를 n+m=200으로 고정하고,
- n=40(semantic features), m=160(background features)
- 더 나아가 을 10% 간격으로 변화시킴
- 큰 은 더 큰 semantic shift를 나타냄
- 각 에 대해서 ID와 OOD semantic features를 랜덤 샘플링하고 20 trial이 넘는 평균을 95% confidence얻음.

- Fig 2 해석
- toy binary classification 문제를 사용한 OOD 방법
- calibration이 density estimation을 앞도함(larger semantic shift에 대해서)
- larger background shift에서는 그 반대임
4.3 Background Shift
방법
- OOD examples의 set을 background shift를 사용해서 생성
- displacement vector = [, ] 을 두 평균에 적용해서
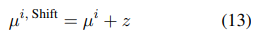
- 이 때 ∈ 은 모든 0의 벡터
연구 적용
- = [, ]로 설정(이 때, ∈ 는 1의 벡터)
- 이 shift는 의 direction을 따라서 ID distribution의 translation에 상응함
- total dimensions를 n+m = 200으로 설정하고 semantic(n)과 background(m) 사이의 split을 다양화 함(20씩 값을 올리면서)
4.4 Simulation Results
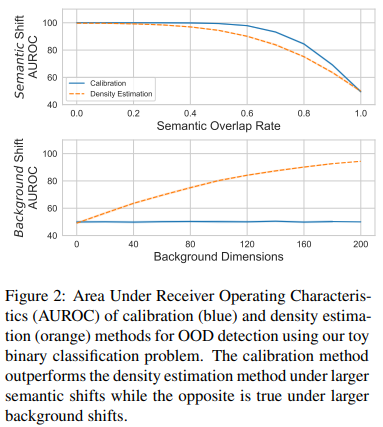
- 결과
- simulated 환경에서 OOD detection 성능
- AUROC를 성능 지표로 사용
- 해석
- calibration 방법이 일반적으로 density를 outperform
- 성능 차이는 두 방법이 near-perfect performance 일 때 감소함
- calibration method는 background shift에서 성능 향상이 불가능함
- 왜냐하면 background features가 에 기여하지 않기 때문
- LDA weights가 이 구성요소에 대해서는 0이어서
- 우리는 이 결과가 예상한 바라고 생각했고, 직관을 끌어내고자 실제 text data에서 OOD detection 방법을 두 유형에서 평가할 때 사용하기로 함
- 왜냐하면 background features가 에 기여하지 않기 때문
5 Experiments and Analysis
- 14개 ID/OOD 쌍에서 calibration과 density estimation 방법을 비교 수행함
- 해당 쌍들은 background shift나 semantic shift로 카테고리화되는데
- 8개는 challenge datasets로부터임
5.1 Setup
OOD detectors.
- 1 calibration method
- ID data에서 훈련된 classifier에 의존
- RoBERTa 모델을 ID data에 fine-tune하고 그것의 prediction probability를 계산함
- 2 density estimation method
- GPT-2를 ID data에서 fine-tune하고 perplexity를 OOD score로서 사용
- GPT-2를 ID data에서 fine-tune하고 perplexity를 OOD score로서 사용
- 모델 사이즈와 두 방법을 통제하고자 RoBERTaBase를 GPT- 선정
- 각각 110M, 117M parameter
- 두 개의 더 큰 모델, RoBERTaLarge, GPT-로도 실험
- OOD detectors를 AUROC, FAR95(False Alarm Rate at 95% Recall)로 evaluate
- 이는 ID examples들을 95% OOD recall로 misclassificatin rate를 측정
- 두 metric 모두 유사한 결과
- FAR95의 결과는 appendix에 있음

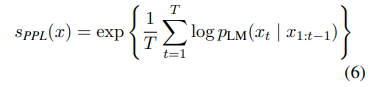
FAR95의 결과
Training details.
- RoBERTa: fine-tune the model for 3 epochs on the training split of ID data with a learning rate of 1e-5 and a batch size of 16.
- GPT-2: fine-tune the model for 1 epoch on the training split of ID data for the language modeling task, using a learning rate of 5e-5 and a batch size of 8
Oracle detectors
- OOD detection 성능의 높은 bound를 추정하고자
- OOD data에 접근할 수 있고 OOD 분류기를 직접 학습할 수 있는 환경을 고려함
- 구체적으로 logistic regression model을 test data의 bag-of-words feature 80 %로 훈련하고 나머지 20%의 결과를 report함
5.2 Semantic Shift
- discriminative feature(예. sports vs. politics)의 distribution은 semantic shift setting에서 바뀜
- = 즉, 일 때
방법
- semantic shift pairs를 훈련 때 안 보인 classes에서의 test examples를 포함해서 만듦
- 그러므로 훈련 데이터를 분류하는데 유용한 semantic feautes는 test set을 대표하지 않음
dataset
- News Category, DBPedia Ontology Classification 같은 multiclass classification dataset을 사용해 -> two ID/OOD pairs를 만듦
- News Category dataset: HuffPost news data로 구성
- 가장 흔한 5가지 클래스의 예시들을 사용해서 ID(News Top-5)로, 나머지 36개 class를 OOD(News Rest)로
- DBPedia Ontology Classification dataset은 Wikipedia 데이터로 구성
- DBPedia 2014의 14 non-overlapping classes
- class number 1-4를 ID(DBPedia Top-4)로 나머지를 OOD(DBPedia Rest)로 사용
- News Category dataset: HuffPost news data로 구성
Results.
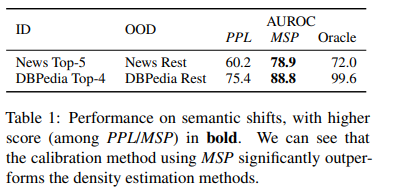
- calibration method(MSP)가 일관적으로 density estimation method를 앞섬
- calibration methods가 large semantic shifts한 시나리오에 더 적합함을 보임
- simulation 결과와 이어짐
- calibration methods가 large semantic shifts한 시나리오에 더 적합함을 보임
[chat GPT]
- hypothetical entity that provides the best possible predictions for a given problem.
- "perfect" model that can accurately predict outcomes based on any input data.
- In practice, an oracle is not achievable because it would require complete knowledge of the true underlying data generating process. However, by comparing the performance of machine learning algorithms to the performance of an oracle, researchers can get an idea of how close they are to achieving optimal predictions for a given problem.
5.3 Background Shift
- background features (e.g. formality)는 label에 의존하지 않음.
- 그러므로 sentiment classification과 NLI dataset에서의 domain shift를 고려함
dataset
-
- SST-2, IMDB, Yelp Polarity -> binary sentiment classification 데이터셋
- SST-2, IMDB: 다양한 길이의 영화 리뷰
- Yelp polarity : 다양한 사업에 대한 리뷰이어서 SST-2와 IMDB로부터의 domain shift를 나타냄
- 각 데이터셋은 ID/OOD로 사용
- validation split은 SST-2로
- test split은 IMDB와 Yelp Polarity로
-
- SNLI, MNLI, RTE 데이터셋 사용
- SNLI, MNLI: 다양한 장르에서의 NLI 예시들
- RTE(GLUE): 다양한 도메인에서의 예시들
-
task가 two labels (entailment, non-entailment)인데
- 그와 달리 SNLI와 MNLI는 3개(entailment, neutral, contradiction)
- -> domain/background shift가 더 유망함(NLI에 대한 semantic feature가 더 비슷해서)
- 각 데이터는 ID, OOD로 쓰이고
- OOD data에 대한 validation set을 evaluation에 사용
Results
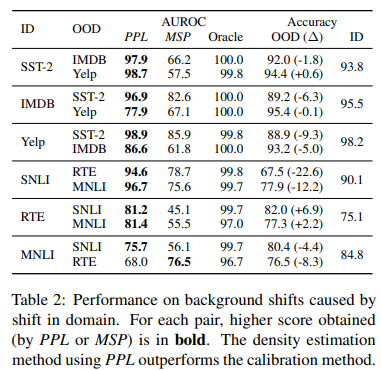
-
해석
- density estimation method(PPL)가 calibartion method를 앞섬(맨 마지막행 MNLI vs RTE 제외)
- PPL이 background features의 변화에 더 민감함을 암시
- discriminative model이 잘 일반화하는 상황에서(증거로 ID와 OOD accuracy number의 작은 변화에서)
- calibration method 성능이 random(50)에 가까움을 발견
- well-calibrated model이 그것의 정확한 OOD prediction에 높은 신뢰도를 가지고 있기 때문
- calibration method 성능이 random(50)에 가까움을 발견
- density estimation method(PPL)가 calibartion method를 앞섬(맨 마지막행 MNLI vs RTE 제외)
-
discriminative model이 여기서 잘 일반화함
- 그렇기에 OOD detection보다 domain adaptation에 초점을 두는 것이 더 나음
- shift가 background shift를 우세할 때(Sec 6)
- 그렇기에 OOD detection보다 domain adaptation에 초점을 두는 것이 더 나음
1) MDD->BD만 넣고, 2) X->BD도 추가.
- 2) 일 떄 OOD가 더 일반화되는 것이니까, accuracy가 각각 어떻게 변했는지? 쓰면 될듯
--> 우리도, ANX인 데이터를 OOD로 두었을 때, BD인 데이터를 OOD로 두었을 때, 우리 모델은 BD에 최적화되어있어서(manic구분잘함) 후자에서 더 성능이 좋음을 입증하는 방향으로??
5.4 Analysis
Controlled distribution shifts.
- 실제 text data에서 두 controlled distribution shift 사용
- semantic과 background shifts의 framework를 더 잘 연구하기 위해서
- 1 background shift의 경우
- Wiki-text에서 다양한 양의 텍스트를 추가하고, Civil Comments는 SST-2 examples로
- 각각 synthetic ID와 OOD examples들을 만들려고
- unrelated texts를 lengths ∈ (25, 50, 100, 150, 200) words로 추가
- 2 semantic shift에 대해서
- News Category dataset을 쓰고 classes를 ID에서 OOD로 옮김
- top 40 ID classes에서 frequency로 시작해서 classes를 10 씩 상승시킴
- semantic information을 커버하는 ID는 더 많은 클래스가 OOD subset으로 이동하면서 줄어듦 -> larger semantic shift로 감
1번은 길이 추가해서 문맥 다양하게 해주는 예제들을 만든거고, 2번은 클래스 추가해보면서 각각 shift를 controll한거!
Results
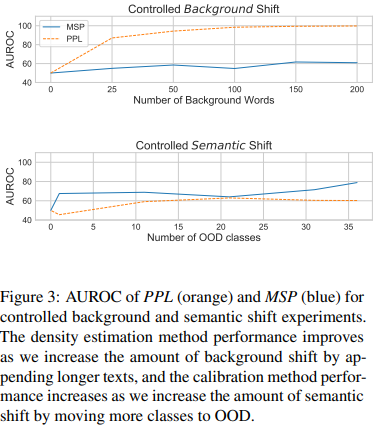
- 해석
- density estimation method(PPL)가 synthetic background text의 양에 더 민감한 반응
- calibration method(MSP)가 ID/OOD classes의 수에 더 민감
- simulated data에서와 상응하는 결과
Larger models
- Yelp, IMDB -> background shift
- News Top-5, News Rest -> semantic shift
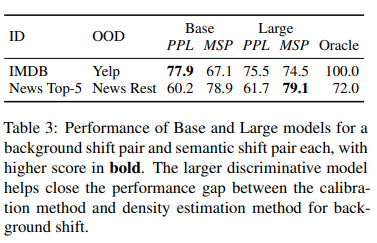
- OOD detection을 더 큰 모델에 했을 때의 결과
- 해석
- larger discriminative model이 background shift pair에서 더 높은 점수
- 점수 간격이 더 작아짐
- larger model이 representation에서 background features를 몇 개 더 학습하는 것이 가능한 것 같음(추측)
- semantic shift pair에 대한 성능은 larger model를 썼을 때 크게 안바뀜
- larger discriminative model이 background shift pair에서 더 높은 점수
5.5 Challenge Data
- Challenge datasets은 superficial heuristics나 model deficiencies를 타겟하기 위해서 고안됨
- 그러므로 OOD examples들을 삼가는 것이 바람직함
Human-generated challenge data.
- Kaushik et al.(2020)이 counterfactually(조건법적서술, 예. 만약 내가 알고 있었더라면) augmented IMDB examples (c-IMDB)의 set을 crowdsourced함
- annotator들에게 예시들을 조금씩 편집하라고 해서
- semantic features의 distribution을 label에 high correlation하게 바꿈 -> semantic shift를 만듦
- IMDB를 ID, c-IMDB를 OOD로 고려해서 -> c-IMDB evaluation을 위해 training, validation, test split을 결합함
Rule-based challenge data.
- HANS: template-based 예시들로 구성
- high premise-hypothesis overlap를 가짐
- 그러나 non-entailment
- 그래서 특정한 templates/syntax 때문에 background shift의 결과로 이어짐
- Stress Test dataset
- 자동으로 생성된 예제들
- NLI 모델의 common error를 evalutate하고자 고안됨
- test categories에서부터 distribution shift의 유형을 카테고리화함
- MNLI (ID)에 대해서, -> depending on whether they append “background” phrases to the ID examples or replace discriminative phrases
- Antonym(반의어), Numerical Reasoning는 semantic shifts를 구성
- semantic features의 set가 이제 entailment reasoning의 특정한 유형에 초점을 두기 때문에
- e.g. antonymy and numerical representation
- Negation, Spelling Errors, Word Overlap, Length Mismatch는 background shift를 구성
- population level changes를 소개하기 때문
- e.g. appending “and true is true” to each hypothesis
- 각 예시의 entailment conditions와는 관련이 없음
- 해당 challenge examples에 있어서 MNLI를 ID로 고려
- 평가를 위해 HANS와 MNLI의 validation split 사용
Failure case 1: spurious(위조) semantic features.
[GPT]
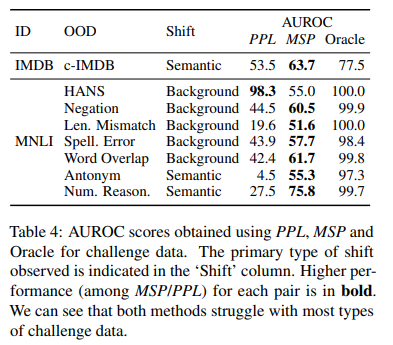
도전 데이터는 종종 훈련 세트에서 유용하지만 일반적으로 레이블과 상관 관계가 없는 가짜 기능 (예 : NLI의 전제-가설 중복)을 대상으로 구성됩니다. 따라서, 분별 모델은 훈련 중 구별력이 있었던 가짜 의미 기능이 여전히 두드러져 있지만, 이제는 더 이상 레이블을 예측하지 못하므로 OOD 예제에서 지나치게 자신감을 가질 것입니다. 결과적으로, 표 4에서 MSP는 대부분의 도전 데이터에서 고민하며 AUROC 점수가 무작위로(50)에 가깝게 달성됩니다. 반면, 밀도 추정 방법은 HANS에서 거의 완벽한 성능을 달성합니다.
- Challenge data는 training set에서는 유용하지만 일반적으로 label과 상관관계가 없는 spurious features(e.g. premise-hypothesis overlap for NLI)을 대상으로 구성되는 경우가 다수
- 그러므로 discriminative model이 OOD examples에서 over-confident할 수 있음
- 훈련 때 discriminative했던 spurious semantic feaures가 더 이상 label의 예측이 아니기 때문
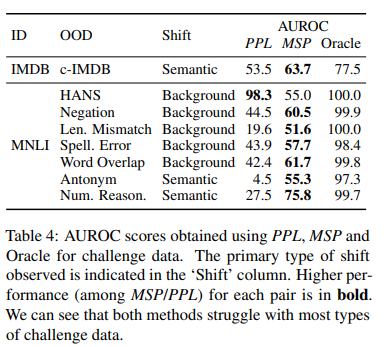
- 결론적으로 Tab4에서 MSP는 가장 challenge한 data(HANS)에서 결과 안좋음(55.0)
- random(50)에 가까운 AUROC score를 기록
- 반면에 density estimation은 HANS에서 거의 완벽한 성능
- 그러므로 discriminative model이 OOD examples에서 over-confident할 수 있음
Heuristic Analysis for NLI Systems(HANS): NLI의 강건함을 알아보기 위한 데이터셋
Failure case 2: small shifts.
- density estimation(PPL)이 background shift에서 더 잘해야 하기에
- 시뮬레이션 결과는 ID랑 OOD 분포가 크게 overlap되었을 때 small shift를 탐지하는 것을 어려워함을 암시함
- Tab4는 Negation과 Word Overlap Stress Test categories에 대해서 유사한 결과를 입증
- 두 OOD는 짧은 phrases (e.g. “and true is true”)를 각 ID hypothesis에 추가함
작은 변화(=짧은 phrase)를 잘 눈치채지 못한다
Failure case 3: repetition.
- Antonym(4.5), Numerical Reasoning(27.5), Length Mismatch(19.6)의 경우 PPL 성능이 random보다도 나쁨
- 언어모델이 OOD보다 ID examples에 더 높은 likelihood를 부여함을 암시
- 언어모델이 OOD보다 ID examples에 더 높은 likelihood를 부여함을 암시
- 이 challenge example은 높은 반복 구문을 포함
- e.g. Length Mismatch에는 “and true is true”를 5번 추가,
- e.g. Numerical Reasoning와 Antonym에는 high overlap between premise and hypothesis
- 이런 상황은, recursive 언어모델에서 high likelihood를 가져온다고 알려져있음
- 그러므로 repetition은 OOD detector에 기반을 둔 언어모델에게 해가 될 수 있음
- 전체적으로 두 방법에 대한 성능은 challenge dataset에서 훅 떨어짐
- 이들 중, human-generated counterfactual data가 가장 탐지가 어려움
- rule-based challenge data는 예상하지 못한 행동을 이끄는 unnatural한 pattern을 포함할 수도 있음
5.6 Discussion
- shift에 기반해서 카테고리화된 OOD 예제들에 대한 두 방법의 성능은 OOD 탐지의 성능을 높이는데 도움이 되는 시야를 제공
- 해당 프레임 워크는 OOD 탐지에서 다양한 challenge에 초점을 둔 benchmark를 더 잘 평가하는데 사용될 수 있음
- 두 방법 간의 선택은 또한 test time 때 예상한 분포로 만들어질 수 있음
- calibration을 semantic shift 탐지가 더 중요할 때 쓰기
- density estimation을 background shift를 탐지할 때 쓰기
- 하지만 challenge examples에서의 실패 사례도 있음
- density estimation이 OOD examples를 repetiton과 small shifts로 탐지에 실패
- calibration이 대다수의 예제 탐지를 실패
- 이는 이런 challenge examples가 두 접근 방식의 약점에 타겟한 OOD의 유형으로 구성됨을 나타냄
- 이는 OOD에 대한 더 명백한 정의가 OOD 탐지 방법에 진보를 가하고, realistic distribution shifts를 반영하는 benchmark를 창조할 것임을 강조함
7 Conclusion
-
outlier 및 OOD 감지에 대한 광범위한 문헌에도 불구하고,
- NLP 분야의 이전 연구들은 OOD 예제를 엄격하게 정의하는 것에 대한 합의가 부족하며, 대신 서로 다른 작업에서 추출된 임의의 데이터셋 쌍을 의존함.
-
본 연구에서는
- natural text와 simulated 데이터에서 OOD 예제를 background 변화 또는 semantic 변화로 분류하고,
- calibration과 density estimation이라는 두 가지 일반적인 OOD 감지 방법의 성능을 연구.
- 두 유형의 데이터 모두에서, density estimation이 background 변화에서 calibration보다 우수한 성능을 보이지만, semantic 변화에서는 그 반대임.
- 더 나아가 모델의 결함을 대상으로 하는 challenge examples에서 여러 실패 사례를 발견
-
와 가 각각 x를 상호 배타적인 부분 집합으로 매핑한다고 가정(단순화를 위해)
- 이 가정은 프레임워크를 단순화하고 두 종류의 변화와 관련하여 두 가지 탐지 방법을 비교하는 데 도움이 됨.
- 이 단순화된 프레임워크는 두 방법 간의 차이를 설명하는 데 많은 도움이 되지만, challenge examples의 실패 사례들은 더 나은 프레임워크와 더 명확한 OOD 정의가 OOD 감지 방법의 발전에 영향 끼칠 것임을 암시함.
- 이 정의는 실제 분포 변화를 반영하는 OOD 감지 벤치마크의 생성에 도움이 될 수 있음
- predictors가 target으로 하는 OOD 예제 유형을 정의하는 것은
- calibration과 density estimation을 사용하여 모델링 결정을 내리는 데에 도움
- 감지 성능을 개선하는 데도 도움.
- 유망한 후속 연구는
- test-time fine-tuning과 data augmentation
- 개선된 감지 성능을 위해 특정 유형의 분포 변화를 대상으로 지도될 수 있음
- test-time fine-tuning과 data augmentation
- 본 연구에서 쓴 방법은 한 종류의 변화에 대해 잘 작동,
- 그렇기에 동시에 두 가지 유형의 변화가 발생할 때는 두 방식을 모두 사용하는 하이브리드 모델의 사용을 권장
Discussion
- 공식 깃허브: https://github.com/uditarora/ood-text-emnlp
- 좋은 점
- 체계적인 내용
- 왜 이 실험을 했고, 단계적으로 들어가서 설명을 탁탁해준 느낌
- Related work도 나누어진 부분 좋고
- toy detection과 simulation을 위한 challenge data가 결국 같은 결과를 시사했다!는 점
- 한 것도 정말 많고 결과가 잘 일관되게 나왔구나 ! 라는 느낌
- BD 연구에서 많은 도움을 받을 수 있을 것 같다 !!!!
- 아쉬운 점
- 사용한 데이터가 많아서 -> 실험에 대해서 이해를 하려면 해당 데이터에 대한 사전지식이 있다면 더 좋지 않았을까
- 깃허브에 코드가 공개되어있는 것 같아보이지만, 아쉽게도 바로 쓸 수가 없다 ㅎㅎ

3개의 댓글


OOD를 잘 해결하기 위한 2가지 방법을 제시하고 그 중 어느 방법이 더 효과적인지를 검증하는 논문이었네요 ! 본 저자들이 접근한 방식이 매우 흥미롭습니다 !
OOD에 대해 자세히 몰랐었는데 여러가지 예를 보며 이해가 쏙! 되는 발표였습니다 !! data distribution과 관련한 2개의 기법에 대해 아주 흥미롭게 잘 보았습니다~~