정규식
정규식을 만드는 두 가지 방법
- 정규식 리터럴을 사용하는 방법
var re = /ab+c/;정규식 리터럴은 스크립트가 불러와질 때 컴파일된다.
정규식이 상수라면, 이렇게 사용하는 것이 성능을 향상시킬 수 있다. - RegExp 객체의 생성자 함수를 호출하는 방법
var re = new RegExp("ab+c");생성자 함수를 사용하면 정규식이 실행 시점에 컴파일된다.
정규식의 패턴이 변경될 수 있는 경우, 혹은 사용자 입력과 같이 다른 출처러부터 패턴을 가져와야 하는 경우에 사용한다.
단순 패턴 사용하기
/abc/위의 정규식은 문자열에 정확히 'abc'라는 문자들이 모두 함께 순서대로 나타나야 대응된다.
- abcdefg => true
- Grab crab => false
특수 문자 사용하기
- \(백슬래쉬) : 백슬래쉬는 두가지 규칙이 있다.
1. 특수 문자가 아닌 문자 앞에서 사용될 경우 : 해당 문자는 특별하고, 문자 그대로 해석되면 안된다
ex) \b : 단어 경계 대응, \d : 숫자 문자에 대응
- 특수 문자 앞에서 사용될 경우 : '다음에 나오는 문자는 특별하지않고, 문자 그대로 해석되어야 한다.
ex) /a\*/는 a*와 대응된다.
- ^ : ^는 두가지 규칙이 있다.
1. 문자셋 패턴의 첫 글자로 쓰이는 경우 : 부정 문자셋, 괄호 내부에 등장하지 않는 어떤 문자와도 대응된다.
ex) [^abc]는 [^a-c]와 동일하고 두 패턴은 a,b,c 가 아닌 모든 문자와 대응된다.
- 문자셋 패턴의 첫 글자로 쓰이지 않는 경우 : 입력의 시작 부분에 대응된다.
ex) /^A/는 "an A"의 'A'와는 대응되지 않는다.
/An E/의 'A'와는 대응된다.
- $ : 입력의 끝 부분과 대응된다.
ex) /t$/ 는 "eater"의 't'에는 대응되지 않는다. 그러나 "eat"와는 대응된다.
- * : 앞의 표현식이 0회 이상 연속으로 반복되는 부분과 대응된다. {0,}과 같은 의미이다.
ex) /bo*/는 "A ghost booooed"의 'boooo'와 대응되고, "A bird warbled"의 'b'에 대응된다.
- + : 앞의 표현식이 1회 이상 연속으로 반복되는 부분과 대응된다. {1,}과 같은 의미이다.
ex) /a+/는 "candy"의 'a'에 대응되고 "caaaaandy"의 모든 'a'들에 대응된다.
- ? : 앞의 표현식이 0 또는 1회 등장하는 부분과 대응된다. {0,1}와 같은 의미이다.
ex) /e?le?/는 "angel"의 'el'에 대응되고, "angle"의 'le'에 대응된다.
- . : 개행 문자를 제외한 모든 단일 문자와 대응된다.
- x(?=y) : 오직 'y'가 뒤따라오는 'x'에만 대응된다.
ex) /Jack(?=Sprat)/는 'Sprat'가 뒤따라오는 'Jack'에만 대응된다.
- x(?!y) : x 뒤에 y가 없는 경우에만 x에 일치한다.
ex) /\d+(?!.)/는 소수점이 뒤따라오지 않는 숫자에 일치한다. 3.14에서 3에 일치
/\d+(?!.)/.exec("3.141")는 141에 일치
- x|y : 'x'또는 'y'에 대응
- {n} : 앞 표현식이 n번 나타나는 부분에 대응된다.
- {n,m} : 앞 표현식이 n번 이상 m번 이하 나타날 때 대응된다.
- [xyz] : 문자셋이다. 이 패턴 타입은 괄호 안의 어떤 문자와도 대응된다. 점이나 별표같은 특수 문자는 문자셋 내부에서는 특수 문자가 아니다. 따라서 이스케이프 시킬 필요가 없다.
ex) [a-z.]는 "test.i.ng"전체 문자열이 일치한다.
- [\b] : 백스페이스와 대응된다. \b와는 다르다.
- \b : 단어 경계에 대응된다.
- \d : 숫자 문자에 대응된다. [0-9]와 동일하다.
- \D : 숫자가 아닌 문자에 대응된다. [^0-9]와 동일하다.
- \s : 하나의 공백 문자에 대응된다.
- \S : 공백문자가 아닌 하나의 문자와 대응된다.
- \w : 밑줄 문자를 포함한 영숫자 문자에 대응된다. [A-Za-z0-9_]와 동일하다.
- \W : 단어 문자가 아닌 문자에 대응된다.
이메일 유효성 검사
const isEmail = (email) => {
const emailRegex =
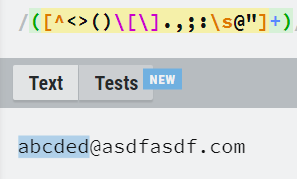
/^(([^<>()\[\].,;:\s@"]+(\.[^<>()\[\].,;:\s@"]+)*)|(".+"))@(([^<>()[\].,;:\s@"]+\.)+[^<>()[\].,;:\s@"]{2,})$/i;
return emailRegex.test(email);
};위의 코드의 @앞의 정규식을 보자
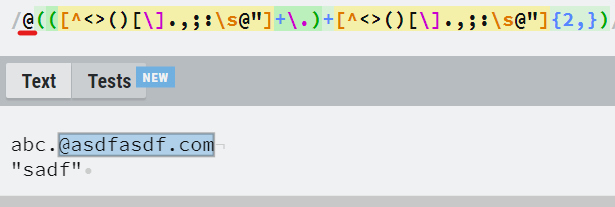
- 특수문자를 제외한 한 개 이상의 문자(+)가 선택되었다.
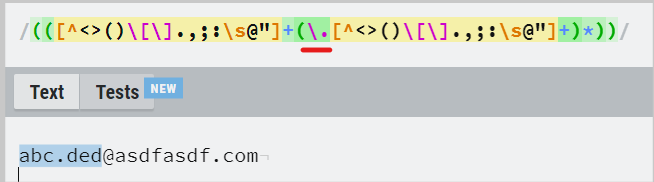
- 중간의 \. 가 있어서 .을 포함해도 된다.
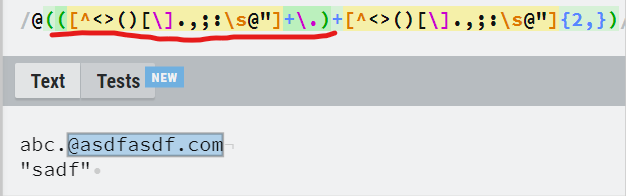
- 그러나 두 번째 중괄호의 뒤에 +가 있어서 . 뒤에 특수문자를 제외한 한글자 이상이 와야한다.
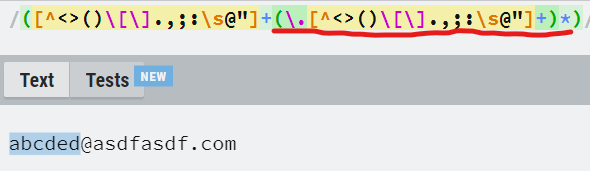
- 밑줄 친 괄호뒤에 *가 있어서 괄호의 내용이 있어도 되고 없어도 된다.(0개 이상이면 된다.)
ex) abc@abc.com 또는 abc.abc@ab.com 모두 가능하다
- "이메일"의 형태도 유효하게 판단했다.
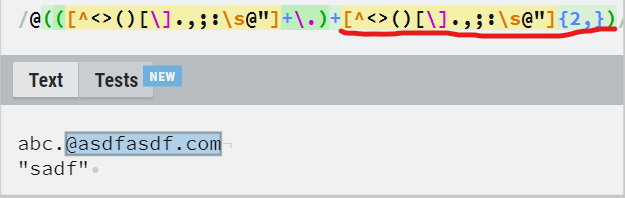
- @가 한개 이상 있을 때 유효하게 판단
- 특수문자가 없고 ' . ' 이 한개 포함되어 있어야함
- 특수문자가 아닌 문자가 2개이상 있어야함
ex) com, net 등
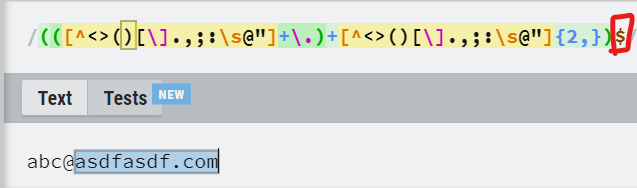
- $는 ()안의 문자들로 끝이나야 유효하게 판단.
ex) abcde.com
- 마지막의 \i는 대소문자를 구별하지 않는다는 뜻


참고 사이트
정규식 연습 사이트
https://regexr.com/

Hi