오늘 알고리즘 스터디에서 진행한 두 번째 문제이다.
Problem
https://school.programmers.co.kr/learn/courses/30/lessons/86971?language=java
n개의 송전탑이 전선을 통해 하나의 트리 형태로 연결되어 있습니다. 당신은 이 전선들 중 하나를 끊어서 현재의 전력망 네트워크를 2개로 분할하려고 합니다. 이때, 두 전력망이 갖게 되는 송전탑의 개수를 최대한 비슷하게 맞추고자 합니다.
송전탑의 개수 n, 그리고 전선 정보 wires가 매개변수로 주어집니다. 전선들 중 하나를 끊어서 송전탑 개수가 가능한 비슷하도록 두 전력망으로 나누었을 때, 두 전력망이 가지고 있는 송전탑 개수의 차이(절대값)를 return 하도록 solution 함수를 완성해주세요.
Solution
- 완전탐색과 bfs를 이용해 풀이했다.
- 먼저 입력받은 wires 배열의 연결 정보를 이중
LinkedList인graph에 저장했다.LinkedList를 이용한 이유는 모든 노드가 서로 연결되어있지 않기 때문에 각 노드마다 연결정보를 가변크기의 리스트 형태로 저장하고 싶었기 때문이다. - 다시 연결 정보를 탐색하면서 해당 연결을 끊어 주기 위해 list에서 연결 정보를 삭제하고
bfs로 각 네트워크를 탐색한 뒤 크기를 구했다. answer에 네트워크 차의 최솟값을 담아주기 위해Math.min함수로answer와 두 네트워크 차의 절대값을 비교해 담아준다.- 모든 연결 정보를 끊은 경우를 탐색하고 나면
answer에 네트워크 차의 최솟값이 담기게 된다.
JAVA Code
class Solution {
public int solution(int n, int[][] wires) {
int answer = Integer.MAX_VALUE;
LinkedList<LinkedList<Integer>> graph = new LinkedList<>();
for (int i = 0; i <= n; i++) {
graph.add(new LinkedList<Integer>());
}
for (int[] wire : wires) {
graph.get(wire[0]).add(wire[1]);
graph.get(wire[1]).add(wire[0]);
}
for (int[] wire : wires) {
boolean[] visited = new boolean[n + 1];
graph.get(wire[0]).remove(Integer.valueOf(wire[1]));
graph.get(wire[1]).remove(Integer.valueOf(wire[0]));
int net1 = bfs(graph, wire[0], visited);
int net2 = bfs(graph, wire[1], visited);
answer = Math.min(answer, Math.abs(net1 - net2));
graph.get(wire[0]).add(wire[1]);
graph.get(wire[1]).add(wire[0]);
}
return answer;
}
private int bfs(LinkedList<LinkedList<Integer>> graph, int start, boolean[] visited) {
LinkedList<Integer> q = new LinkedList<>();
q.add(start);
visited[start] = true;
int cnt = 0;
while (q.peek() != null) {
int curr = q.poll();
cnt++;
for (int next : graph.get(curr)) {
if (!visited[next]) {
q.add(next);
visited[next] = true;
}
}
}
return cnt;
}
}연결 정보 그래프를 LinkedList로 구현했을 때와 int[][]로 구현했을 때의 차이
LinkedList로 풀이하고 나서 int[][]로 연결정보를 구현하면 성능이 어떻게 달라질지 궁금했다.
LinkedList를 선택한 이유는 가변 리스트를 통해 메모리를 절약할 수 있다고 생각했기 때문이다. 하지만 remove 함수를 사용할 때 LinkedList도 순차탐색이 필요하므로 O(n)의 시간복잡도가 필요하다는 생각이 들었다. int[][]는 배열의 인덱스로 바로 접근이 가능하므로 성능면에서 더 나을 수도 있겠다는 생각이 들었고 int[][]로도 구현해보았다.
public int solution(int n, int[][] wires) {
int answer = Integer.MAX_VALUE;
int[][] graph = new int[n + 1][n + 1];
for (int[] wire : wires) {
graph[wire[0]][wire[1]] = 1;
graph[wire[1]][wire[0]] = 1;
}
for (int[] wire : wires) {
boolean[] visited = new boolean[n + 1];
graph[wire[0]][wire[1]] = 0;
graph[wire[1]][wire[0]] = 0;
int net1 = bfs(graph, wire[0], visited);
int net2 = bfs(graph, wire[1], visited);
answer = Math.min(answer, Math.abs(net1 - net2));
graph[wire[0]][wire[1]] = 1;
graph[wire[1]][wire[0]] = 1;
}
return answer;
}
private int bfs(int[][] graph, int start, boolean[] visited) {
LinkedList<Integer> q = new LinkedList<>();
q.add(start);
visited[start] = true;
int cnt = 0;
while (q.peek() != null) {
int curr = q.poll();
cnt++;
for (int i = 0; i < graph.length; i++) {
if (graph[curr][i] == 1 && !visited[i]) {
q.add(i);
visited[i] = true;
}
}
}
return cnt;
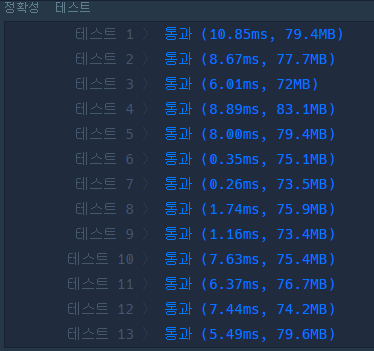
} LinkedList로 풀이했을 때의 결과
int[][]로 풀이했을 때의 결과
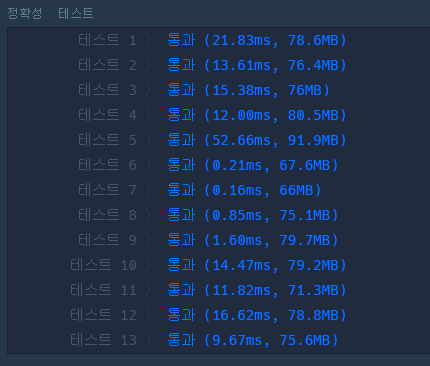
생각과 달리 성능은 LinkedList로 구현했을 때 더 좋았고 메모리 성능은 int[][]로 구현했을 때 좋았다.
어떤 부분에서 차이가 나는지 예측해보자. 먼저 연결을 끊기 위한 삭제 연산에서는 인접 행렬은 O(1)의 시간 복잡도를 갖고 인접 리스트는 O(degree(v))의 시간 복잡도를 가진다. degree(V)는 정점의 차수를 의미한다. bfs 함수 내부에서 간선과 연결된 모든 노드를 탐색하는 부분에서는 인접 행렬은 O(n * v)의 시간 복잡도를 가진다. v는 해당 네트워크 내부의 간선의 개수이다. 인접 리스트는 O(e)로 해당 네트워크의 전체 간선의 개수를 시간 복잡도로 가진다. 문제에 주어지는 graph는 완전 그래프가 아니기 때문에 간선의 개수가 적을 수록 탐색부분에서 성능차이가 많이 날 것이라는 생각이 든다.
