📌 Small Language Models Need Strong Verifiers to Self-Correct Reasoning
📝 저자 : Mengzhou Xia, Shiyue Zhang, Saurabh Garg, Xuezhi Wang, Yi Tay, Jason Wei, Jiawei Han, Xinyun Chen, Diyi Yang
📅 발행 연도 : 2024
🔗 논문 링크: https://arxiv.org/abs/2404.17140
현재 학교 딥러닝 프로젝트에서 SLM/LLM의 환각(hallucination)을 정보 부호화 이론(Information Coding Theory)을 활용해 줄이는 연구를 진행하고 있다. 이번 논문은 이러한 연구 주제와 밀접하게 관련되어 있어, 관련 기술적 접근과 self-correction 메커니즘을 이해하기 위해 리뷰하게 되었다.
또한 self-correcting 개념이 익숙하지 않은 분들이라면,
이전에 리뷰했던 아래 글을 함께 참고하길 바란다.
👉 https://velog.io/@gyoon2data/Large-Language-Models-Cannot-Self-Correcting-Reasoning-Yet
🔹Abstract
Self-correction은 대형 언어 모델(LLMs)의 추론 성능을 향상시키기 위한 유망한 해결책으로 부상했으며, 이는 모델이 스스로 생성한 오류 지점을 지정하는 critique를 이용해 자신의 답안을 정제하는 방식이다.
본 연구는 13B 이하의 소형 언어 모델(Small LMs)이 더 강한 모델로부터 최소한의 입력만 받고도 추론 작업에서 self-correction 능력을 가질 수 있는지를 탐구한다.
우리는 작은 LMs가 self-correction 데이터를 스스로 수집하도록 유도하여, self-refinement 능력의 학습을 지원하는 새로운 파이프라인을 제안한다.
- 올바른 정답을 활용하여 모델이 자신의 오답을 비판(critique)하도록 안내한다.
- 이렇게 생성된 critique는 필터링 과정을 거친 후, solution refinement를 통해 self-correcting reasoner를 지도학습 하는 데 사용한다
실험 결과, 저자는 두 개의 작은 모델이 수학 및 상식 추론 분야의 다섯 개 데이터셋에서 self-correction 능력이 향상됨을 확인하였다. 특히 GPT-4 기반의 강력한 verifier와 결합할 때 두드러진 성능 향상이 나타났다. 그러나 언제 답안을 수정해야 하는지 판단하는 역할을 약한 self-verifier가 수행할 경우에는 한계가 있음도 밝혀졌다.
🔹Introduction
최근 연구들은 대형 언어 모델(LLMs) (OpenAI, 2023)이 유해한 내용을 줄이거나 특정 키워드를 포함하게 하거나, 코드 디버깅을 하는 등 다양한 사용자 요구를 충족하기 위해 자기 교정(self-correction)을 수행할 수 있음을 보여주었다(Madaan et al., 2023; Chen et al., 2023b).
Self-correction은 일반적으로 먼저 초기 응답의 문제점을 찾아내는 critique(비판)를 생성한 뒤, 그 critique에 따라 답변을 수정하는 방식으로 이루어진다. 이 과정은 반복적으로 수행될 수도 있다.
Self-correction은 LLM 출력의 오류를 바로잡기 위한 흥미로운 패러다임으로 부상하고 있다(Pan et al., 2023). 그러나 이러한 self-correction을 효과적으로 수행하는 모델들은 대부분 매우 대규모이며, 많은 경우 상업적 API로만 접근이 가능하다.
본 연구는 작고(open-source) 공개된 언어 모델들(small LMs)의 self-correction 능력에 초점을 맞춘다.
이전 연구들은 작은 모델이 강한 모델로부터의 distillation을 통해 추론 기반 self-correction 능력을 학습할 수 있음을 보여주었다. 그러나 이러한 방식은 고위험(high-stakes) 영역에서 보안 리스크를 초래할 수 있으며, 모델 스스로 오류를 수정하는 능력을 어떻게 강화할 수 있는지에 대한 과학적 이해를 방해한다.
따라서 저자는 다음과 같은 질문을 제기한다.
작은 LMs는 추론 기반 self-correction을 학습하기 위해 어느 정도까지 강한 모델의 도움을 필요로 하는가?
저자는 강한 LM에 의존하는 대신, 작은 모델 스스로가 supervised training 데이터를 생성하여 self-correction 능력을 향상시키도록 만드는 접근을 연구한다.
→ rejection sampling fine-tuning(RFT)에서 영감을 얻음
RFT에서는 다양한 chain-of-thought 샘플을 통해 모델의 추론 능력을 구축하고, 올바른 추론 과정만을 사용해 supervised fine-tuning을 수행한다.
저자는 SCORE 즉, 작은 모델의 Self-COrrection in REasoning 능력을 bootstrap하기 위한 접근을 제안한다.
구체적으로, 작은 LMs로부터 고품질 critique–correction 데이터를 수집하도록 하는 파이프라인을 설계하고, 이를 이용해 self-correcting reasoner를 supervised fine-tuning한다.
-
정답(correct solutions)을 힌트로 활용해 base LM이 자기 자신의 오답에 대해 critique를 생성하도록 유도
정답을 기반으로 역추론(reverse engineering)함으로써, 모델은 더 효과적인 critique를 생성 -
생성된 critique는 정확성, 구조적 적절성(well-formedness), 명확성을 기준으로 규칙 기반 및 prompting 기반 방법을 통해 필터링
-
정제된 데이터를 사용해 동일한 LM을 self-refining model로 fine-tuning
강한 LM의 감독(supervision)을 사용하지 않기 때문에, 작은 LM이 스스로 self-correction 능력을 bootstrap하도록 생성
저자는 SCORE로 fine-tuning된 refiner 모델을 extrinsic self-correction 설정과 intrinsic self-correction 설정에서 평가한다.
- extrinsic: 모델이 외부 신호(예: verifier)가 있을 때만 self-correct 수행
- intrinsic: 모델 자체가 "언제 수정할지" 판단해야 함
언제 self-correct할지 판단하는 과정은 해결안의 정답 여부를 검증하는 문제와 직접 관련되며, 이는 현재의 최첨단 LLM조차 적절한 외부 피드백 없이 해결하기 어렵다.
⚒️ 실험 방법
- self-verification baseline은 Cobbe et al.(2021)을 따르며, 동일한 LM을 정답 여부(정답/오답)만을 라벨로 하여
binary verifier로 fine-tuning하였다. (입력: 질문 + 후보 답안)- extrinsic self-correction setting에서는 GPT-4 기반 verifier와 oracle label을 strong verifier로 사용하여,
SLM이 self-correcting reasoner로서 얼마나 효과적인지를 평가하였다.- 제안한 SCORE 파이프라인은 LLaMA-2-13B-chat과 Gemma-7B-it 모델에 적용하였으며,
수학(GSM8K 등) 및 상식 추론을 포함한 5개 데이터셋에서 실험을 수행했다.- 실험 결과, SCORE로 fine-tuning된 모델은 GPT-4 기반 strong verifier를 사용할 때 평균 14.6%의 성능 향상을 보였다.
반면, self-generated data로 학습된 weak self verifier를 사용할 경우 self-correction 성능 향상은 제한적이었다.
⭐ 주요 기여 요약
- SCORE라는 새로운 파이프라인을 제안하여, SLM이 self-correction 데이터를 스스로 생성하고, 이를 활용해 모델을 self-correcting reasoner로 fine-tuning 할 수 있다.
- 본 방법은 강한 verifier가 있을 때, 작은 LM의 self-correction 능력을 수학, 상식 추론에서 효과적으로 향상시킨다.
- 강한 LM으로부터 distillation과 사람의 라벨링 없이 SLM이 자기 교정형 추론(self-corrective reasoning) 능력을 boostrap 할 수 있음을 보인 최초의 연구이다.
🔹Problem Formulation of Self-Correction
🔻Self-Correct := (SELF-)VERIFY + SELF-REFINE
저자는 self-correction 작업을 (SELF-)VERIFY와 SELF-REFINE의 두 단계로 분해한다.
- 언어 모델(LM)은 먼저 주어진 추론 문제에 대한 초기 해답을 생성한다.
- 그 다음 verifier(검증기)는 LM 자체(내재적, intrinsic)일 수도 있고 외부 신호(외재적, extrinsic)일 수도 있다.
이 초기 해답의 정답 여부를 판단한다.
(if 정답이라면, 초기 해답을 최종 답안으로 그대로 사용, if 오답이라면, refiner(교정기)가 해당 해답을 수정)
이러한 self-correction 과정은 반복적으로 수행될 수 있지만, 본 논문에서는 효율성을 위해 반복 횟수를 1로 고정하며, 다중 반복은 향후 연구 과제로 남긴다.
VERIFY 단계와 REFINE 단계를 분리하는 이유
SELF-VERIFY와 SELF-REFINE를 분리하면 기존의 “단일 모델이 모든 역할을 하도록 하는 구조” 대비 두 가지 중요한 이점이 있다.
- 각 모듈을 별도로 설계할 수 있다.
예를 들어, verifier는 fine-tuned 모델을 사용하고 refiner는 few-shot prompting 모델을 사용할 수 있다.
이를 통해 강한 verifier vs 약한 verifier가 refiner의 성능에 어떤 영향을 미치는지 세밀하게 분석할 수 있다.
(반면, 기존의 small LM 기반 self-correction 연구는 VERIFY와 REFINE 기능을 하나로 뭉뚱그려 처리했기 때문에, 각 능력이 어떻게 다른지 완전히 이해하는 데 장애가 있었다.)- 각 모듈이 단일 능력만 학습하면 되므로 학습 난도가 낮아진다.
즉, 모델은 VERIFY(정답 여부 판단) 또는 REFINE(해설 기반 교정) 둘 중 하나의 기능만 전문적으로 학습하면 되므로 안정적이다.
🔻SELF-REFINE = Critique + Correction
SELF-REFINE의 도전 과제는 다음과 같다.
언어 모델은 아무런 안내 없이 초기 해답을 바로 수정(correct)하는 데 어려움을 겪는다.
따라서 저자는 critique 즉, 추론 과정 내 오류가 발생한 지점을 정확히 짚어주고 오류 원인을 설명하며 이를 어떻게 고쳐야 하는지를 안내하는 설명을 활용한다. 이러한 critique는 수정 과정에서 언어 모델의 성능을 크게 향상시킨다는 것이 여러 연구에서 확인되었다.
refinement의 두 단계 절차
- 오답으로 판단된 초기 해답에 대해 critique를 생성한다.
- 이어서 수정된(corrected) 답안을 단일 패스(single pass)로 생성한다.
그러나 높은 품질의 critique를 얻는 것은 쉽지 않다. 저자는 이 문제를 해결하기 위해 정답(correct solutions)을 힌트로 활용해 critique 생성이 더 쉽게 이루어지도록 한다. 자세한 내용은 Section 3.1에서 다룬다.
🔹The SCORE Method
저자의 접근법은 rejection sampling fine-tuning(RFT)에서 영감을 받았다.
RFT는 질문마다 다양한 해답을 샘플링한 뒤, 최종적으로 정답에 도달하는 self-generated reasoning을 이용해 LLM을 미세조정하는 방식이다.
저자는 SLM이 추론 단계에 대한 critique를 생성하는 고유 능력을 스스로 구축하도록 만들고자 한다.
- 강한 LM의 distillation에 전혀 의존하지 않는다.
- 작은 LM이 대규모로 self-correction 데이터를 생성할 수 있도록 하는 end-to-end 파이프라인을 설계하였다.
- self-generated critiques는 필터링을 거친 후 작은 LM의 self-correction 능력을 bootstrapping하기 위한 fine-tuning에 사용된다.
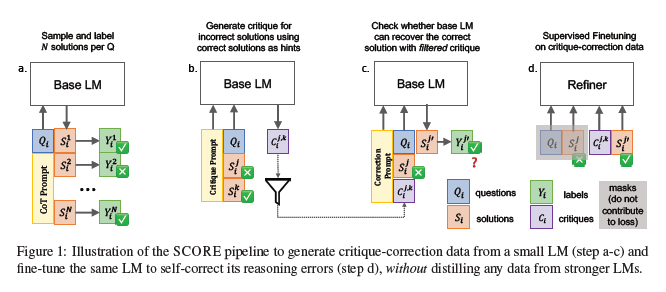
구체적으로, SCORE 파이프라인은 그림 1에 나타난 바와 같이 두 단계로 구성된다.
⚒️ 파이프라인
- Stage 1: Critique 생성 및 필터링
단계 a - 훈련 데이터셋의 각 질문에 대해 base LM을 few-shot CoT prompting하여 N개의 해답을 샘플링
단계 b - base LM이 자신의 오답을 되돌아볼 수 있도록, 동일한 질문의 정답(correct solution)을 힌트로 제공
단계 c - 이후 생성된 critique는 정확성과 명확성을 기준으로 필터링한다.
- Stage 2: Refiner의 Supervised Fine-tuning
단계 d - 1단계에서 필터링된 critique들은 작은 LM 자체를 fine-tuning하는 데 사용된다. refiner는 질문 + 초기 해답을 입력으로 받아 critique와 수정된(corrected) 해답을 생성하도록 학습된다. 이때, fine-tuning 과정에서는 힌트를 제공하지 않는다.
🔻Generating and Filtering Critiques
외부 감독 신호 없이 오답에 대한 critique를 직접 생성하는 것은 어렵다.
-
초기 실험에서는, 정답을 힌트로 제공했을 때 LM이 critique 생성에 훨씬 능숙해짐을 확인했다.
이 경우 모델은 두 해답(오답 vs 정답)의 각 단계를 비교한 뒤 올바른 방향을 설명하기만 하면 되기 때문이다.
정답을 힌트로 활용하기 위해, 우리는 각 질문에서 오답과 정답을 쌍(pair)으로 구성하기 위해 라벨링하고, 오답–정답 모든 가능한 조합(Cartesian product)을 수집한다. -
step-level critique는 solution-level critique보다 더 유용하다. 그 이유는 step 단위 피드백이 더 미세하고 정확한 감독 신호를 제공하며, LM이 틀린 추론을 통해 우연히 맞는 정답을 만드는 비정상적 행동을 완화하기 때문이다.
따라서 모델은 초기 해답의 각 단계마다 피드백을 제공하도록 요청한다.
- 맞는 단계는 endorsement (“this step is correct”)
- 틀린 단계는 오류 지적 및 이유 설명 (“there are errors in this step because ...”)
- critique가 특정 단계에 기반하도록 하기 위해, 피드백을 주기 전에 해당 단계를 그대로 복사하도록 모델에게 요구한다.
이러한 요구사항을 반영해 우리는 critique prompt의 형식을 설계했다.
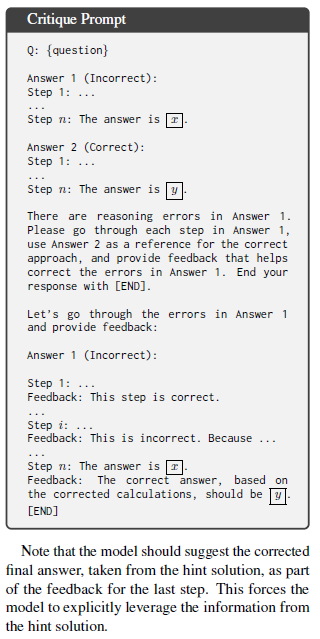
또한 모델은 마지막 step의 피드백에서 정답(힌트의 정답)을 제안하도록 되어 있다. 이를 통해 모델이 힌트 정보를 반드시 활용하도록 강제한다.
Critique 필터링
raw critique를 얻은 뒤에는, 품질이 낮은 critique를 제거하고 나머지만 fine-tuning에 사용한다.
구조가 매우 잘 정의되어 있기 때문에, rule-based filtering을 손쉽게 적용할 수 있다.
[필터링 기준]
1. Step 개수와 Feedback 개수가 동일해야 한다. (“Step {i}:”, “Feedback:” 등장 횟수 비교)
2. 각 step은 초기 해답에서 정확히 복사되어야 한다.
3. 마지막 step의 feedback에는 정답이 포함되어야 한다.
- 첫 번째·두 번째 기준은 형식적 완전성(well-formedness) 검증이며, 세 번째 기준은 critique의 정확성을 보장한다.
- 세 기준 중 하나라도 어기면 critique는 제거된다.
- 그러나 마지막 step이 올바른 정답을 포함하더라도 critique 전체가 여전히 오류를 포함할 수 있으므로, 저자는 rule-based filtering 뒤에 prompting 기반 필터링 단계를 추가한다.
- 구체적으로, rule-based 필터를 통과한 critique를 base LM에 제공하고 “이 critique를 사용해 오답을 수정하라”고 요청한다.
- base LM이 지시를 잘 따를 수 있다는 가정하에서, critique가 명확하고 정확하다면 수정된 해답은 정답이어야 한다. 따라서 수정된 해답이 정답이 아닌 critique는 제거한다.
rule-based + prompting-based 두 단계를 거친 뒤, 저자는 fine-tuning에 사용할 고품질 critique를 확보한다.
🔻Supervised Fine-tuning of the Refiner
refiner는 질문과 초기 해답을 조건으로 critique + 수정된 해답을 단일 패스(single pass)로 생성하도록 훈련된다.
데이터 수집 단계에서 critique를 생성하기 위해 정답을 힌트로 제공했지만, fine-tuning과 inference에서는 힌트를 제공하지 않는다.
저자는 모든 단계에 대한 critique를 수집했지만, fine-tuning에서는 첫 번째 오류 단계의 피드백만 남기고 나머지는 truncate한다.
→ LM에게 힌트 없이 모든 오류를 한 번에 수정하도록 요구하는 것은 매우 어렵기 때문이다.
- refiner는 이전 단계에서 수집한 truncate된 critique + corrected answer를 사용해 cross-entropy loss로 학습된다.
- fine-tuning 시 few-shot 예시는 포함하지 않는다.
- input token에는 mask를 적용해 loss 계산에 기여하지 않도록 한다.
비록 본 연구에서는 refinement를 1회만(iteration=1) 수행했지만, 강한 verifier와 결합할 경우 작은 LM도 단 한 번의 self-correction으로 큰 성능 향상을 달성할 수 있음을 이후 실험에서 보인다.
🔹Experimental Setup
🔻Self-Correction Data Collection.
base model로부터 CoT 프롬프트를 사용해 각 질문당 N = 10개의 해답(solution)을 샘플링한다.
이후 각 해답의 정오 여부를 라벨링하고, 비정답–정답 solution pair를 구성하여 critique 생성에 사용한다. 각 base LM과 task별로 데이터를 별도로 수집한다.
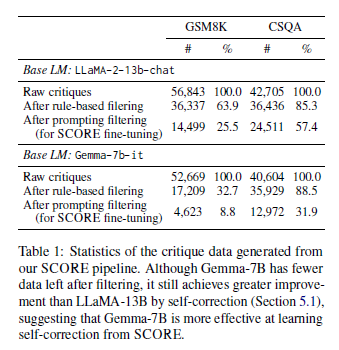
이 과정을 통해 Table 1에 제시된 수의 raw critique를 얻는다.
얻은 critique들은 규칙 기반 필터링(rule-based filtering) 과 프롬프트 기반 필터링(prompting-based filtering)을 순차적으로 거쳐 최종적으로 고품질 critique들을 확보한다.
🔻Verifiers.
저자는 LM의 self-correction 성능에 대한 영향을 확인하기 위해 서로 다른 강도 수준을 가진 verifier들을 실험했다.
- Self-Verifier(Weak Verifier)-Cobbe et al.(2021) 방식의 단순 baseline
- 가장 먼저, Cobbe et al.(2021)을 따라 self-verifier baseline 을 구축한다.
- self-verifier는 base LM과 동일한 아키텍처를 사용
- 입력: "질문 + 후보 해답(solution)", 출력: 해당 solution이 정답인지/오답인지의 확률
- 구체적 구성 방식
- base LM에서 샘플링한 solution들을 최종 답의 정오만으로 0(오답), 1(정답)으로 라벨링
- 이진 분류 헤드를 LM 마지막 토큰의 표현 위에 얹어 fine-tuning
- 데이터는 정답과 오답의 비율이 불균형하므로, 클래스 비율에 따라 loss 가중치를 조정
- 추론 시 동작 방식
- verifier가 “이 해답은 틀렸을 확률”을 출력
- 이 확신(confidence)이 dev set에서 accuracy를 최대화하는 기준값(threshold)을 넘으면 refinement 수행, 넘지 않으면 그대로 유지
- 학습 시 선택된 threshold는 테스트에서도 고정됨
- Strong Verifier — GPT-4 사용
- GPT-4에 few-shot verifying prompt(부록 A)를 주어, 작은 LM이 생성한 초기 해답의 정오를 판단하게 한다.
- SCORE refiner의 잠재력을 최대한 발휘할 때 가능한 성능을 보여준다.
- Oracle Verifier — 문제의 gold 정답 사용
gold 정답을 직접 활용하는 oracle verifier 설정을 실험
“어느 시점에 self-refine을 해야 하는지” 완벽한 신호를 제공하며,
refiner가 달성할 수 있는 성능의 상한(upper bound) 을 보여준다.
🔻Benchmarks and Base Models.
SCORE의 효과를 입증하기 위해 우리는 두 가지 주요 reasoning 분야에서 실험을 진행했다.
-
학습용 Dataset
- GSM8K — 수학적 추론
- CommonsenseQA — 상식 추론
-
일반화/전이 실험 Dataset
- MATH — 수학 추론
- QASC, RiddleSense — 상식 추론
-
상식 분야 실험 설정
- CommonsenseQA train으로만 학습
- 평가: CommonsenseQA dev, QASC, RiddleSense
-
사용된 Small LMs
- LLaMA-2-13B-chat
- Gemma-7B-it
🔻Fine-tuning and Evaluation.
모든 fine-tuning은 LLaMA-Factory(Zheng et al., 2024) 기반 LoRA로 수행했다.
- LoRA rank: 32
- learning rate: 2e-5
- epochs: 3
- batch size: 32
추론 설정
- temperature: 0 (greedy decoding)
- max length: 2048 tokens
모든 실험은 A40 GPU × 4 (각 48GB) 환경에서 수행 가능하다.
🔹Results
이 절에서는 먼저 다양한 모델과 데이터셋에서 SCORE 방법을 적용한 실험 결과를 제시한다.
이후 self-correction 이후의 성능 변화를 더 잘 이해하기 위해, verifier와 refiner의 동작 특성을 분석하고, 파이프라인의 여러 핵심 설계 선택들을 ablation 실험을 통해 검증한다. 마지막으로, SCORE fine-tuning 데이터 규모가 self-correction 성능에 미치는 영향을 살펴본다.
🔻Main Findings
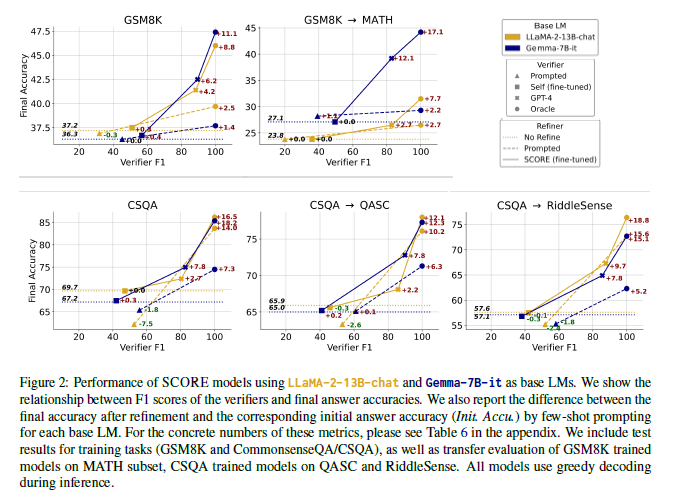
Figure 2는 해당 모델을 fine-tuning 했을 때의 평가 결과를 baseline 모델과 비교하여 보여준다.
결과는 두 가지 지표를 포함한다.
-
Verifier F1: verifier 예측의 정밀도(precision)와 재현율(recall)을 평가
-
Final accuracy: self-correction 이후 최종 답안의 정답률
저자는 여기서 네 가지 주요 발견을 보고한다.
- SCORE 파이프라인으로 수집한 critique–correction 데이터는 base LM의 self-correction 능력을 향상시킨다.
- SCORE로 fine-tuning한 모델은 few-shot 초기 답안 대비 큰 폭의 정답률 상승을 보였다.
- 반면 기존의 prompting 기반 self-correction은 오히려 성능을 떨어뜨렸다.
- CommonsenseQA처럼 객관식 문제에서도, oracle verifier 기준 SCORE refiner는 무작위 선택(random baseline)보다 훨씬 향상되었다.
→ 모델이 단순히 “다른 보기 고르기”를 하는 게 아니라, 실제 self-correction을 수행하고 있음을 의미한다.
- 다양한 모델과 다양한 추론(task)에서 일관된 성능 향상
- 수학(GSM8K)과 상식(CommonsenseQA) 모두에서 성능이 개선됨.
- 초기 성능이 더 낮았던 Gemma-7B는 self-correction 후 LLaMA-13B를 역전하는 경우도 존재한다.
- Gemma-7B는 더 적은 학습 데이터로 더 큰 향상 → self-correction 학습 효율이 높다.
- self-correction의 핵심 병목은 refiner가 아니라 “verifier”
- 동일 refiner라도 어떤 verifier를 쓰느냐에 따라 최종 성능이 크게 달라짐.
- weak self-verifier → 미미한 개선 또는 오히려 잘못된 수정
- GPT-4 verifier → 평균 +8~9% 큰 폭 개선
→ Self-correction 연구의 병목은 “추론 검증(verification)”이며, 이 부분이 해결될 때 refiner의 잠재력이 드러난다.
- Self-correction 능력은 다른 데이터셋에서도 전이됨
- GSM8K로 학습한 refiner가 MATH에서 최대 +12.1%까지 성능을 개선.
- SCORE는 특정 데이터셋에만 overfit되지 않고 일반적인 self-correction 능력을 학습한다는 의미한다.
- verifier는 refiner만큼 전이되지 않음
→ verification이 더 어려운 문제임을 재차 확인할 수 있다.
🔻Analysis of Self-Correction Behaviors
Self-correction 행동을 두 가지 지표로 분석한다.
-
Freq. (Frequency)
→ verifier가 “수정해야 한다”고 판단한 비율 -
Contrib. (Contribution)
→ 수정 시도가 실제 정답 향상에 기여한 정도
[주요 결과]
-
SCORE refiner는 prompting refiner보다 기여도(Contrib.)가 훨씬 높음
-
SCORE verifier와 GPT-4 verifier 모두 과도한 수정 없이 적절한 빈도로 self-correction을 수행한다.
→ 수정 시도와 정확도 사이의 균형이 훌륭함
🔻Ablation Study
Table 3의 실험을 통해 설계 선택을 검증했다.

-
“첫 번째 오류 step만 수정하기”가 가장 효과적
-
critique 모듈과 correction 모듈을 분리할 필요 없음
모든 step을 critique하게 하면 오히려 성능 하락하고,
LMs는 “모든 오류 단계”보다 “첫 오류 단계”를 식별하는 것이 쉽기 때문이다. 또한 두 모듈로 나누면 시스템 복잡성이 증가하고, 추론 시간이 증가하며 최종 정확도가 하락한다.
즉, 하나의 unified refiner가 최적 구조이다.
🔻Fine-tuning 데이터 규모에 따른 성능 변화
LLaMA-13B 기준, SCORE 데이터 14,499개 중 25~75% 비율의 부분 데이터로 refiner를 학습해 비교했다.
그 결과
- GPT-4 또는 oracle verifier 세팅
→ 데이터가 많을수록 self-correction 성능도 증가 - weak self-verifier 세팅
→ 데이터 증가 효과가 거의 없음
→ 다시 한 번 “verification이 self-correction의 핵심 병목”임을 보여줌
🔹Conclusion
이 연구에서는 강한 LMs의 최소한의 신호만을 이용하여 작은 LMs(SLMs)에게 추론 self-correction 능력을 학습시키는 방법을 탐구했다. 이를 위해 저자는 SCORE라는 새로운 방법을 제안하며, 이 방법은 small LM 스스로 생성한 데이터만을 사용해 self-correction fine-tuning 데이터를 구축할 수 있게 한다.
실험 결과는 다음과 같다.
-
SCORE로 fine-tuning된 작은 LM은 강한 LM의 지식 증류(distillation)에 의존하지 않더라도 더 우수한 refiner(수정기) 로 발전한다.
-
하지만 추론 오류를 실제로 교정하는 과정에서는
여전히 강한 verifier가 필요함을 확인했다.
즉, SCORE는 Small LM에게 self-refinement 능력을 부여하지만, self-verification의 한계가 intrinsic self-correction의 가장 큰 장애물임을 밝혀냈다.
향후 연구는 이 verification 문제를 해결하는 방향으로 나아가야 한다.
👀 My thoughts
- 요새 LLM의 Hallucination에 대해서 프로젝트로 연구를 진행하고 있는데, 소형 언어 모델의 자기 교정 능력에 대해 공부를 해야 해서 읽어본 논문이었다. SLM의 경우 Verifier에 굉장히 크게 의존한다는 해당 연구의 결론을 잘 활용하여 연구의 내용에 뒷받침 할 수 있겠다는 생각이 들었다.
- 그리고 SLM도 올바른 데이터 구조만 주어지면 self-correction 능력을 학습할 수 있다는 것을 새롭게 알게되어 좋았다.
