NLP
1.[논문 리뷰] Efficient Estimation of Word Representations in Vector Space

💡Word2vector란? 원 핫 인코딩을 사용하면서도 단어 간 유사도를 반영할 수 있도록 단어의 의미를 벡터화하는 방법 자세히 말하면, 모든 단어를 vector로 표현하여 단어 사이의 유사성과 차이점을 계산하여 결과를 바탕으로 그 주변 단어와의 관계를 통해 예측하
2.[논문 리뷰] GloVe: Gloval Vectors for Word Representation
💡GloVe란? 글로브(Gloval Vectors for Word Representation, GloVe)는 카운트 기반과 예측 기반을 모두 사용하는 방법론 기존의 카운트 기반의 LSA(Latent Semantic Analysis)와 예측 기반의 Word2Vec
3.[논문 리뷰] Sequence to Sequence Learning with Neural Networks
💡LSTM이란? LSTM이란 RNN의 장기 의존성 문제(long-term dependencies)를 해결하기 위해 고안된 모델이다. > LSTM은 이전 정보를 오랫동안 기억할 수 있는 메모리 셀을 가지고 있으며, 이를 통해 긴 시퀀스 데이터를 처리할 수 있다.
4.[논문 리뷰] NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
💡Encoder-Decoder 구조 >Neural Maschine Translation은 대부분 encoder-decoder 형식으로 이루어져 있다. Encoder: 입력 문장을 고정 길이 벡터로 변환 Decoder: 해당 벡터를 이용해서 번역 결과 생성 **
5.[논문 리뷰] Attention Is All You Need
💡Seq2seq 모델의 한계점 Transformer 모델에 대해 공부하기 전에 Seq2seq 모델의 한계점에 대해 알아보자! Seq2seq 모델에 대한 자세한 설명은 Sequence to sequence Learning with Neural Networks 논문
6.[논문 리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
💡NLP에서의 사전 훈련(Pre-training) > "사전 훈련된 단어 임베딩이 모든 NLP 실무자의 도구 상자에서 사전 훈련된 언어 모델로 대체 되는 것은 시간 문제이다." - 세바스찬 루더 BERT(Bidirectional Encoder Representat
7.[논문 리뷰] SpanBERT: Improving Pre-training by Representing and Predicting Spans
💡 BERT란? >* BERT는 Word2Vec, GloVe 등의 정적인 워드 임베딩과 LSTM 기반 언어 모델의 한계를 극복하기 위해 개발된 모델이다. BERT는 트랜스포머 구조를 활용하여 양방향 문맥 정보를 학습하며, Masked Language Model(ML
8.[논문 리뷰]REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS

💡AI Agent란? 2025년 인공지능 업계에서 가장 주목해야 할 트렌드 중 하나로 AI Agent는 많은 주목을 받고 있다. 많은 기업에서 AI Agent에 대한 기대감을 가지고 있고 투자 규모 역시 확대되고 있다. 그렇다면 AI Agent란 무엇일까? >A
9.[논문 리뷰] DETERMINE-THEN-ENSEMBLE: NECESSITY OF TOP-K UNION FOR LARGE LANGUAGE MODEL ENSEMBLING
👉 논문 링크 : DETERMINE-THEN-ENSEMBLE: NECESSITY OF TOP-K UNION FOR LARGE LANGUAGE MODEL ENSEMBLING 🔹Abstract 대규모 언어 모델(LLMs)은 다양한 과제에서 서로 다른 강점과 약점을
10.[논문 리뷰]Large Language Models Cannot Self-Correcting Reasoning Yet
💡 CoVe란? CoVe(Chain-of-Verification)은 대형 언어 모델(LLM)에서 발생하는 환각을 줄이기 위한 검증 체인 방법이다. CoVe는 모델이 응답을 생성한 후, 스스로 그 응답의 정확성을 검증하는 일련의 질문을 계획하고, 그 질문에 독립적으
11.[논문 리뷰] Small Language Models Need Strong Verifiers to Self-Correct Reasoning
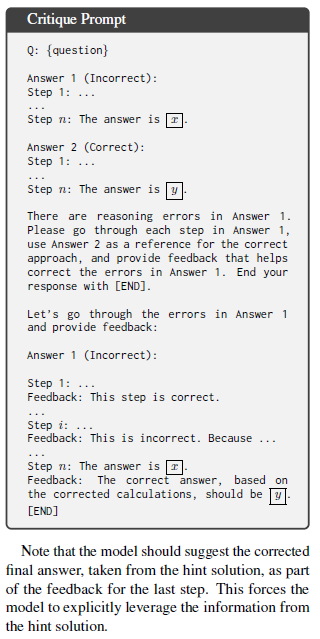
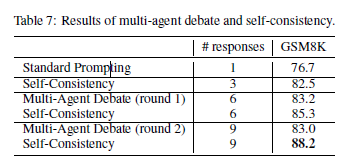
🔹Abstract Self-correction은 대형 언어 모델(LLMs)의 추론 성능을 향상시키기 위한 유망한 해결책으로 부상했으며, 이는 모델이 스스로 생성한 오류 지점을 지정하는 critique를 이용해 자신의 답안을 정제하는 방식이다. 본 연구는 13B
12.FACTSCORE: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
🔹 Abstract 대형 언어모델(Large Language Models, LMs)이 생성하는 장문의 텍스트에 대해 사실성을 평가하는 것은 쉽지 않은 문제이다. 그 이유는 (1) 생성물이 사실에 부합하는 정보와 부합하지 않은 정보가 섞여 있어 이분법적(binary