AutoML
Automated Machine Learning의 줄임말로, 머신러닝 모델 개발, 배포등을 자동으로 처리할 수 있게 도와주는 프로세스입니다.
AutoML은 구글(GCP)의 Vertex AI, AWS의 SageMaker Autopilo등의 클라우드 서비스도 있고, 파이썬에서 라이브러리만 설치하면 매우 쉽게 알고리즘을 선택하고, 튜닝, 그리고 배포까지 간단하게 할 수 있습니다.
간단하게 PyCaret의 기본적인 사용방법을 알아보겠습니다.
PyCaret
https://pycaret.gitbook.io/docs/
PyCaret은 python의 AutoML 라이브러리입니다.
개인적인 생각으로 PyCaret의 가장 큰 장점은
1) 로컬 개발 환경에서 사용 가능
2) 읽기 편한 공식 docs
이라고 생각합니다. 한글로 되어 있는 공식 문서가 있다는 것은 진입장벽을 상당히 낮춰주는 것 같습니다.
시작하기
1. 설치
1) pycaret 설치
pip install pycaret각종 머신러닝 라이브러리를 포함하고 있기 때문에 설치에 시간이 걸립니다. 잠시 기다려주세요
2) juypter notebook 실행
jupyter notebook2. 데이터 불러오기
1) pycaret 내장 데이터 활용
from pycaret.datasets import get_data
data = get_data('boston')
data.info()여러 머신러닝 라이브러리와 마찬가리로 타이타닉, 보스톤과 같은 기본적인 데이터셋을 api를 활용해 다운 받을 수 있습니다
여기서는 또스톤 데이터를 사용해보겠습니다.
2) 데이터 자동 전처리 및 파이프라인 생성
from pycaret.regression import *
reg_test_1 = setup(data=data,
target='medv',
train_size= 0.8,
fold=5)또스톤 데이터는 분류가 아닌 회귀(point estimate)이기 때문에 pycaret.regression을 사용합니다.
setup은 automl을 할 데이터, 종속변수(target), 학습/데스트 데이터 분리, kfold 검증, 스케일링(default=z-score), 아웃라이어 제거, one-hot encoding 등등등등 매우 많은 기등들을 분석할 데이터에 적용할 수 있습니다.
setup의 옵션은 반드시 한번쯤은 공식 문서를 읽어보시는 걸 추천합니다. https://pycaret.readthedocs.io/en/latest/api/regression.html
setup은 파이프라인으로, 전처리한 데이터 및 변수 정보를 포함한 다양한 정보를 포함하고 있습니다.
위코드를 실행하면 아래와 같이 변수들의 정보들과 함께 대화상자가 나타나는데 'enter'를 눌러 처리하면됩니다.
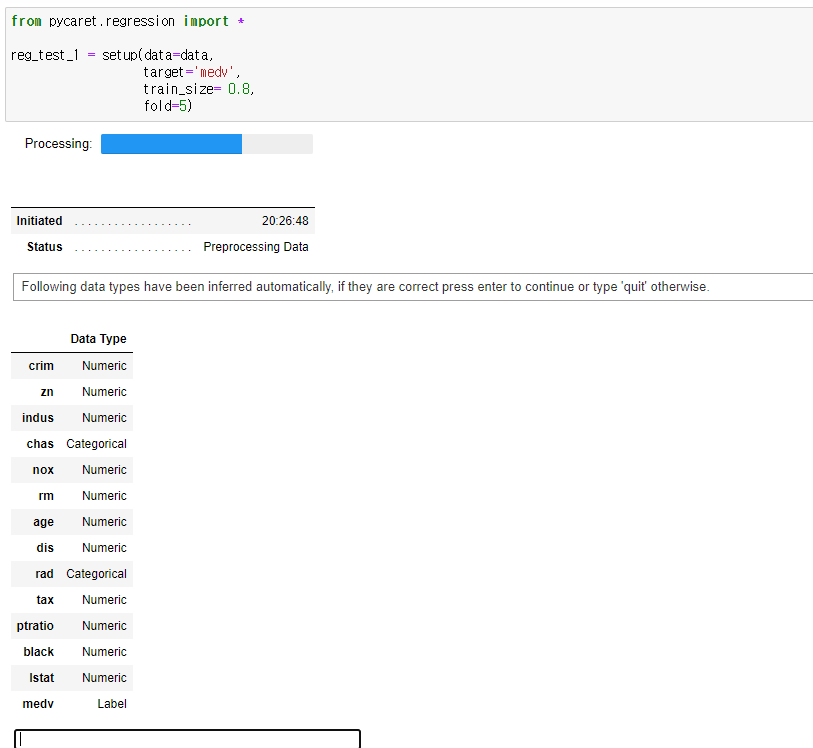
그러면 데이터의 변수들에 대한 분석이 이루어지고, 전처리한 내용이 나타납니다.
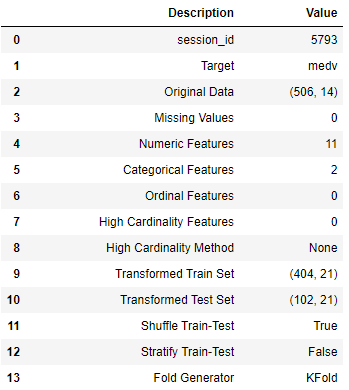
데이터의 크기, 숫자형 변수와 카테고리컬 변수의 수등 다양한 정보를 포함하고 있습니다.
3) 알고리즘 자동 비교
best = compare_models(sort='mse')compare_models는 머신러닝의 여러 알고리즘을 자동으로 생성하여 비교해줍니다. sort는 알고리즘들의 정렬 순서를 의미하며, n_select옵션을 설정하지 않으면 mse성능이 가장 좋은 알고리즘의 파라미터들이 best에 저장됩니다.
setup에서 kfold 옵션을 설정했기 때문에 Kfold 교차검증의 결과값이 표시됩니다.
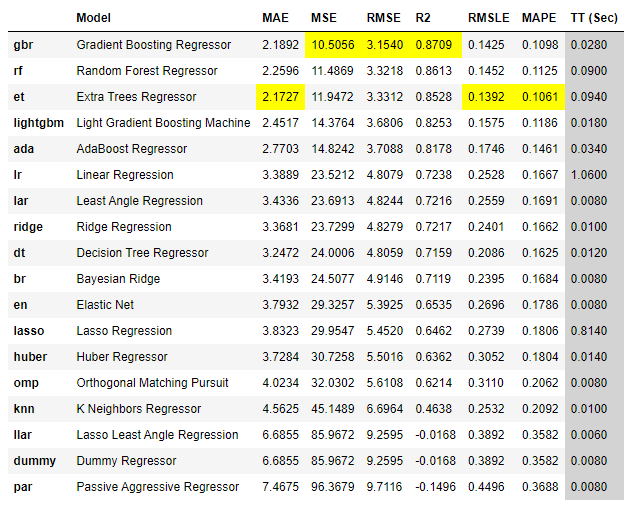
각 모델들의 평가 지표 중 좋은 점수를 기록한 셀에 노란색으로 하이라이트가 있습니다. mse 기준으로는 gbr이 가장 좋습니다.
best에는 아래와 같이 파라미터들이 저장되어 있습니다.
best
GradientBoostingRegressor(alpha=0.9, ccp_alpha=0.0, criterion='friedman_mse',
init=None, learning_rate=0.1, loss='ls', max_depth=3,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_iter_no_change=None, presort='deprecated',
random_state=5793, subsample=1.0, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False)3) 모델 튜닝
best_tune = tune_model(best)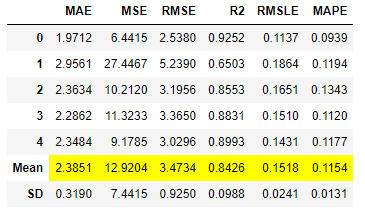
명령어 한 줄로 놀라울 만큼 간단하게 하이퍼 파라미터를 튜닝할 수 있습니다.
best_tune
GradientBoostingRegressor(alpha=0.9, ccp_alpha=0.0, criterion='friedman_mse',
init=None, learning_rate=0.2, loss='ls', max_depth=6,
max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0001, min_impurity_split=None,
min_samples_leaf=4, min_samples_split=7,
min_weight_fraction_leaf=0.0, n_estimators=250,
n_iter_no_change=None, presort='deprecated',
random_state=5793, subsample=0.85, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False)일부 파라미터들이 변경된 것을 볼 수 있습니다.
4) 모델 학습 정보 시각화
evaluate_model(best_tune)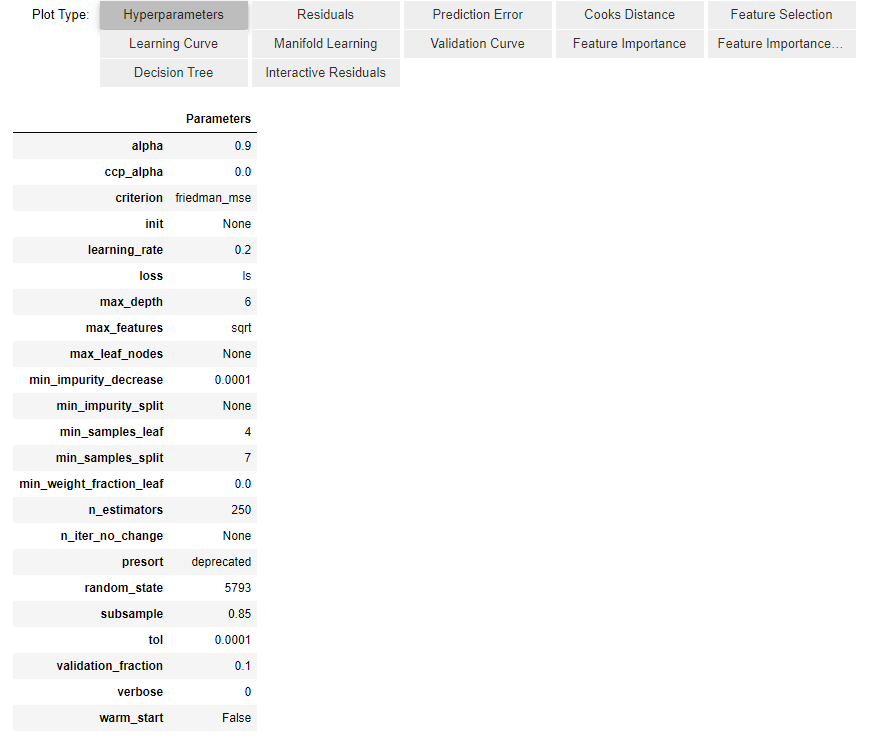
각각의 탭을 눌러보면 모델의 학습 및 평가 정보를 볼 수 있습니다.
저는 feature의 기여도를 볼 수 있는 feature importance를 쉽게 제공한다는 것이 정말 편한 것 같습니다.
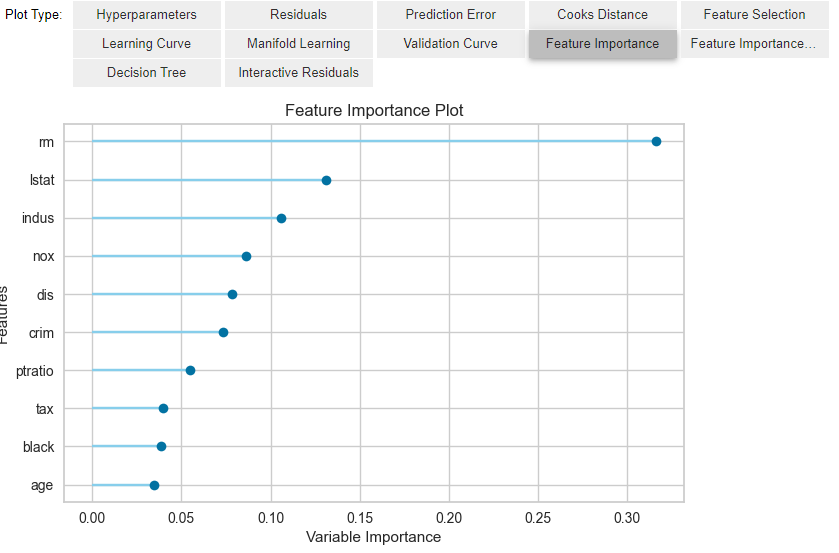
5) 예측 값 보기
predict_model(best_tune)predict_model로 setup에서 설정한 test데이터에 dataframe형태와 모델 예측 값(Lable)을 알 수 있습니다.
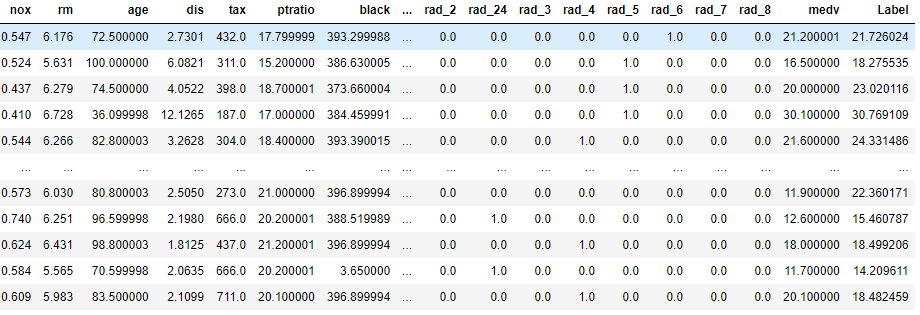
새로운 데이터로 예측한 결과를 보고 싶은면 data옵션에서 새로운데이터를 입력하면 됩니다.
predict_model(best_tune, data= new_data)6) 모델 저장
모델을 저장하고 배포하는 방법은 사용자별 용도와 인프라 환경이 다르기 때문에 공식 문서를 활용하는 것이 좋다고 생각합니다.
https://pycaret.gitbook.io/docs/get-started/functions/deploy
정리
1) pycaret은 간단한 명령어로 모델을 생성할 수 있는 큰 장점이 있지만, pycaret에서 생성된 모델을 바로 실전에서 사용하기는 어렵다고 생각합니다.
2) pycaret은 본격적인 모델링 작업에 앞서 간단하게 모델을 생성 및 비교, feature 중요도 탐색 등의 유용한 기능을 활용하기에 적합한 라이브러리라고 생각합니다.
3) pycaret이 생성한 모델의 파라미터를 기본으로 직접 세부적인 부분을 튜닝한다면, 보다 좋은 모델을 생성할 수도 있습니다.

(털개)
안녕하세요. 글 잘봤습니다 너무 도움이 되었습니다!! 감사합니다
질문이 하나있는데요 , new_data를 넣으면 이것은 정답레이블이 없는데
Label이 예측값인건가요 아니면 target값이 예측한 결과인건가요 ,,?