1. Redux 배경
Redux를 알기위해선 먼저 React의 UI Rendering logic을 알아야 한다.
React에서는 App.js라는 최상위 컴포넌트가 모든 Data를 확보 및 전송, UI rendering까지 모든 과정을 진행한다.
즉 하나의 컴포넌트에서 다양한 컴포넌트 및 Data의 흐름을 관장하고 지휘하며,
각 컴포넌트끼리의 접근은 보통은 불허한다.
이러한 흐름에서 Data 저장소의 개념은 사실 존재하지 않고,
코드 상에서 선언한 변수에 담아놓는 개념이다.
더 자세히 보면
- App.js에서 input을 통해 받은 변수 및 문자열을 value에 저장한다.
- onChange 함수를 통해 상태변화를 일으키면, 이를 setValue라는 상태변수에 넣어 상태관리한다.
- 이러한 value들을 todoList와 같은 별도의 배열이나 객체에 저장하고, 추가적인 Data가 추가되면 이러한 todoList 변수나 해당 컴포넌트에 전달되어 Data가 관리된다.
이러한 Data흐름이 한 컴포넌트에 의해 관리되고, 그 방향성(Data흐름)이 정해지지 않은 프로젝트의 경우
- App.js 자체의 코드 용량증가
- 이러한 Data 흐름을 관리할 Component의 과부하
- graph처럼 얽힌 node, Data 구조에서 App.js와 Data간의 거리증가
유지보수가 매우 어려워지게 되는 React의 단점을 보완하고자 나온 pattern으로,
Data의 단방향 흐름을 구현하여 코드의 가독성 및 Data흐름, 제어를 가능하도록 해주는 기술이 Redux이다.
간략히 말하면 Redux는 facebook에서 고안한 design pattern으로
Data의 단방향 흐름을 실현하고, 이를 효율적을 구현하기위한 방법론이다.
2-1. flow Architecture (기초)
Redux의 Data 단방향 흐름은 Action - Store(Reducers) - React
이 흐름은 Redux의 기초적인 흐름을 이해하기위한 최소한의 logic이다.
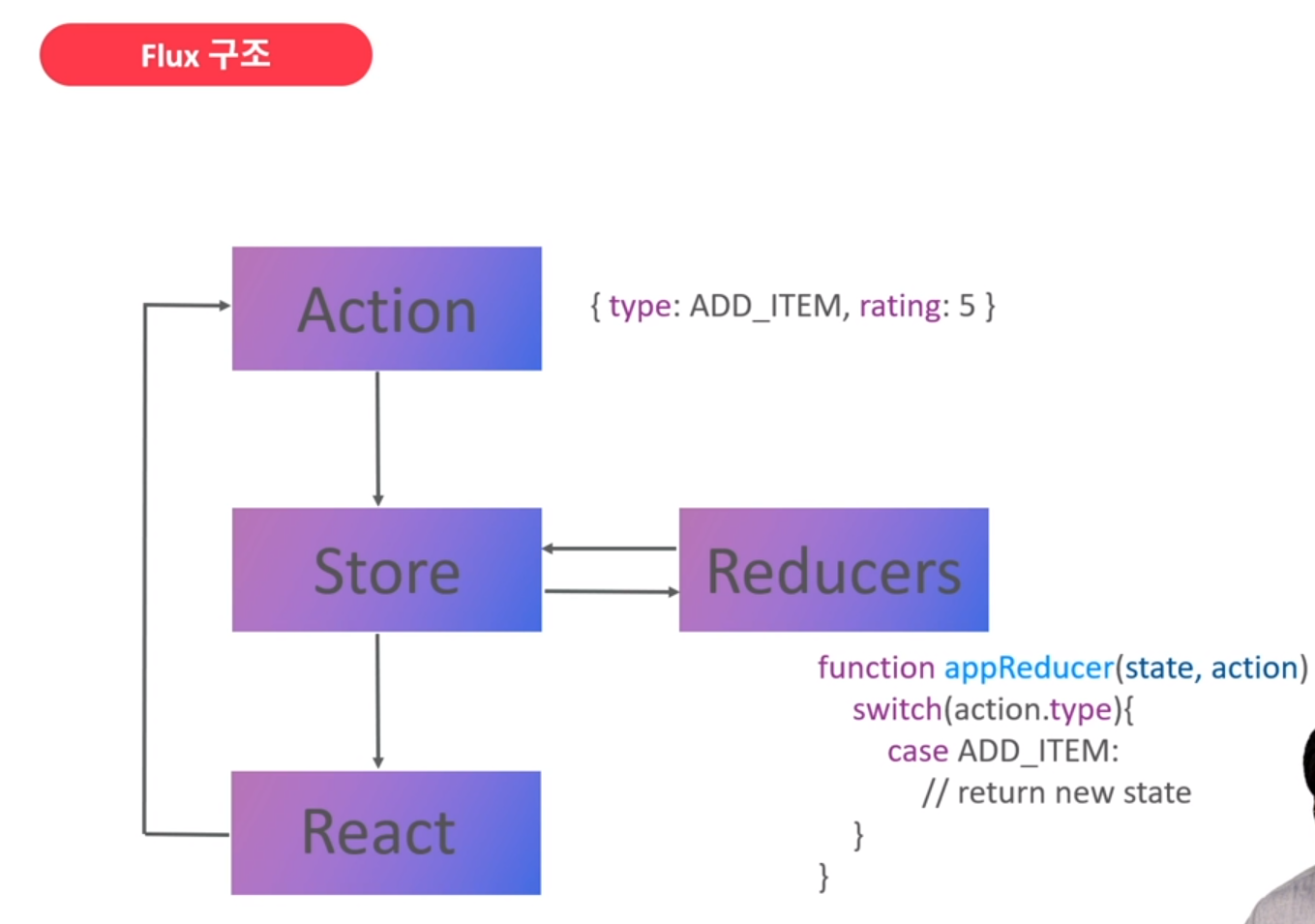
우리는 특정 API나 Command를 통해 Data에 접근하고 수정하는 작업이 필요하다.
기존 NVC Pattern 및 React component 구조에서 Data를 CRUD하기위한 다양한 함수 및 컴포넌트들이 여러 곳에서 정의되고, 이로 인해 Data흐름이 양방향적이고 분산적이었다.
하지만 Redux의 flow Architecture에서는 그러한 CRUD Command가 Action으로 저의되어, Store라는 곳에 Data가 저장된다.
이 Store는 단순히 Data가 저장되는 곳이 아닌, 상태관리가 이루어지는 곳으로
기존 App.js라는 최상위 컴포넌트에서 관리한 Data의 흐름을 한 곳에서 관리해주는 역할을 맡는다.
보통 React에서 Redux를 호출하여 사용하며, Redux controller를 포함한다. 서로 종속적인 관계는 아니다.
위 과정만 보면 아무리 Redux 구조가 잘 구현되었더라도, React자체로 구현된 microservice에서 곳곳에 산발한 controller 등으로 data의 단방향 흐름이 과연 가능할지
의문이 든다.
이러한 microservice의 data흐름과 분산을 단방향화하도록 가능하게 해주는 도구가 Reducer이고, Reducer는 Data를 건드리지 않고 읽기만 한다.
Data가 변화가 필요하다면 상태변화한 Data를 새로운 객체, 새로운 배열로 만들어 반환해준다.
2-2. flow Architecture (심화)
Redux의 flow Architecture에서 중요한 흐름은 Data Store가 외부에 있다는 것이다.
위 기초에서 전체적인 흐름을 이해한 상태로, 세부적인 logic을 살펴보자.
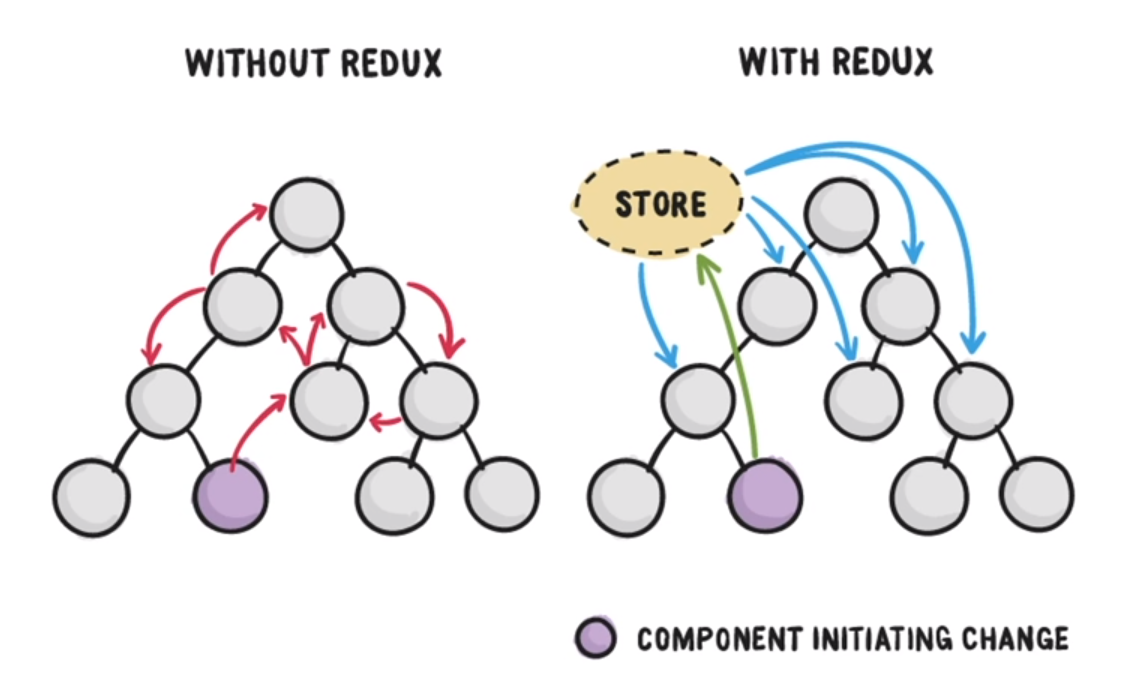
- App.js 최상위 컴포넌트는 Data를 받아 UI Rendering 한다.
- 이 Data들은 Store라는 외부 저장소에 저장되어 관리된다.
- 컴포넌트들은 Data에 접근하기위해 subscribe 한다.
- 한 컴포넌트에서 Data가 변화하여 이를 상태변화할 필요가 있을 경우, 이 상태변화는 Action을 통해 이루어지고 해당 컴포넌트의 dispatch를 통해 Action이 전달된다.
- Store는 그러한 Action을 받고, Reducer를 통해 상태변화를 한 후 Subscribe한 컴포넌트에게 이러한 상태변화를 알린다.
- 해당 컴포넌트는 Rerendering하게 되고, App.js는 Virtual DOM의 변화를 감지하고 변화한 부분에 대해 update한다.
3-1. Redux logic의 특징
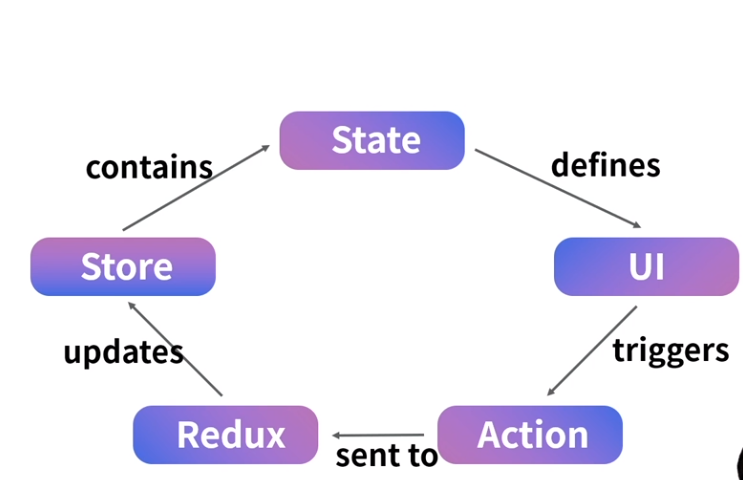
- Only, Immutable store
오직 한가지, 유일하게 존재하며 Data의 무결성을 보장 - Action triggers changes
Action, 이를 dispatch한 과정만이 상태변화를 유도할 수 있다. - Reducers update new state
Reducer는 data를 변화시키는 개념이 아닌, 상태변화한 Data를 새로운 객체 혹은 상태로 Store에 반환하는 것이다.
3-2. Reducer의 특징
- Store에 있는 Data는 Read Only로, 기본적으로 변하지 않는다.
- Redux ACTION declared(type(변화대상)/rating or value(변화값))
ACTION = {type : RATE_COURSE, rating : rating} - Reducer가 ACTION을 호출할 수 있도록 ACTION EXPORT
export const RATE_COURSE = 'RATE_COURSE' - Reducer가 ACTION을 실제 실행하고, 상태변화 발생 후 새로운 객체를 반환
rateCourse(rating){ return { type : RATE_COURSE, rating : rating } } - Reducer는 new state를 return 하고 이를 update,
Store에 있는 Data를 수정하는 개념이 아님을 기억.
4. 참조링크
redux 구조
fastcampus 강의자료 발췌
Redux 개념(※Redux 이해를 위해선 필수)
https://velopert.com/3528
https://velopert.com/3533
flow Architecture
https://facebook.github.io/flux/docs/in-depth-overview/
