[개발지식] Web Application의 상호보완적 Eventually Consistency #12 - NoSQL 데이터를 Spring Job을 통해 읽고 쓰는 과정 분석(*With MongoDB/Redis)
개발지식
1. 개요
일전에 관계형 데이터베이스 기반의 Spring Batch job 실행과정에 대해 살펴보았다면, 이제는 NoSQL 기반의 데이터를 읽고 쓰는 과정에 대해 분석해보고자 한다.
먼저, document-oriented based db인 mongoDB를 사용하고자 한다.
mongoDB에 대해 간략하게 알아보고 넘어가보면, 데이터를 JSON와 유사한 BSON(Binary JSON) 문서(document)를 저장하여 스키마 제약이 없는 NoSQL 데이터베이스를 의미한다.
{
"_id": "6721a",
"name": "홍길동",
"age": 20,
"address": {
"city": "Seoul",
"zip": "12345"
},
"hobbies": ["soccer", "coding"]
}관계형데이터베이스라면, 구조화된 데이터(필드/값을 가진 객체)를 저장하는 것이 기본이지만, RDB의 “행(row)”으로 표현되는 Record 혹은 이에 준하는 객체 대신 “도큐먼트” 단위로 저장하는 것이 바로 mongoDB이다.
my_service_db
┣ users 컬렉션
┣ posts 컬렉션
┣ orders 컬렉션도큐먼트를 여러 개 모아 “컬렉션(collection)”이라는 단위로 관리하며(=Table, 단 스키마가 없기에 각각 데이터 구조는 모두 다를 수 있음), 이러한 컬렉션들을 논리적으로 그룹화한 최상위 컨테이너인 Database로 최종 관리한다(MySQL의 DB(=Schema)와 유사한 개념).
조회는 문서 기반(Querying)이 되며, Index, Document Relationship 등 RDB에 가까운 기능을 지원하며 동시에 스키마 정의없는 상태에서 유연한 구조 운용 및 변경(도큐먼트), 애플리케이션 요구사항 변화에 빠르게 대응할 수 있는 여러 구조적 장점이 있으며, 동시에 NoSQL답지 않게 대량 데이터의 빠른 처리까지 지원하는 강력한 성능적 장점까지 존재한다.
참고로, 흔히 알고 있는 Redis와 자료구조적인 측면에서 많은 차이점이 있는 NoSQL 데이터베이스이다.
Redis는 Key-Value 저장소이며, 값(value)은 string, list, set, zset, hash 등 Redis만의 자료구조로 존재한다.
메모리 기반이라 빠르고 TTL 기반 캐싱에 사용되는 것이 일반적이며, Redis 역시 스키마가 필요 없다.
단일 Key에 단일 Value(또는 Redis 자료구조)를 매핑하는 방식이다.
MongoDB와 Redis는 둘 다 NoSQL이지만, 목적이 다소 다르다.
| 구분 | MongoDB | Redis |
|---|---|---|
| 저장 방식 | JSON 문서(Document) | Key-Value |
| 데이터 구조 | 계층적, 스키마 유연 | 단일 Key에 단일 자료구조 |
| 목적 | 영속적 저장(DBMS) | 캐시, 세션, 메시지 큐 등 |
| 조회 | 조건 기반 쿼리 (find) | Key 기반 조회 (get, hget 등) |
| 성능 | 디스크 기반 (일부 메모리 활용 캐시) | 메모리 기반 초고속 |
| 복잡한 쿼리 | 가능 | 불가능 (Key-Value만 검색) |
| 데이터 관계 | Document 안에 중첩 구조 | 없음(모든 Key는 평면 구조) |
본 분석은 Spring Batch라는 영속적인 데이터 관리를 위해 MongoDB라는 NoSQL 데이터베이스를 선택한 상황을 가정해보고 진행할 것이다.
2. MongoItemReader
Spring Batch 5.1 버전에서는 MongoDB에 대한 Cursor 기반의 item Reader를 제공하게 되었는데, 이에 따라 RDB처럼 편하게 데이터 읽기/쓰기가 가능해졌다.
더불어 일전의 Jdbc/Jpa Cursor Item Reader처럼 한 메모리에 모든 데이터를 옮겨서 이를 읽는 것이 아닌, batchSize만큼 버퍼에 담아 이를 보관하여 처리하며 read()를 호출할때마다 내부 버퍼에 저장된 데이터를 스트리밍 방식으로 읽는다.
다만, 최초의 document fetch는 101개로 구성되어 있으며 이후 batchSize만큼 버퍼에 저장해온다. 이 버퍼가 비었을때 서버로부터 새로운 데이터를 추출해오는 것이며, 유의해야 할 점은 mongoDB에서 제공하는 BSON document의 크기가 최대 16MB이기에 batchSize가 이 크기를 넘지 않는 선에서 데이터를 읽어온다.
추가적으로 mongoDBCursorItemReader의 mongoCursor라는 커서가 존재하며, next()를 호출할때마다 mongoDB에서 다음 document를 바라보고 이를 네트워크로 가져온다. 이러한 네트워킹은 batchSize(fetchSize) 만큼 이루어지고 추출한 데이터는 버퍼에 저장한다. 내부적인 데이터 읽기는 chunk size만큼 read를 반복 호출하여 진행한다.
2-1. CursorItemReader 동작 원리
일단 전체적인 동작과정을 정리하면 다음과 같다.
Step 시작
→ MongoClient 연결
→ MongoCollection + Query 생성
→ Mongo Cursor 열기
→ Cursor.next()로 1건씩 읽기
→ Chunk 단위로 ItemProcessor → ItemWriter
→ Step 종료 시 Cursor closemongoDB Cursor Item Reader는 최초 reader를 open()을 하여, client를 연결하고 query를 생성하며, 데이터를 읽기 위해 가장 핵심 요소인 cursor를 생성한다.
이때, client는 mongoDB와 소통하기 위한 소통객체로 추상화된 mongoTemplate 내부에서 사용되는 요소이다. 이 client가 있기에 개발자 입장에서는 별도의 mongoDB Driver를 설정해주는 작업이 필요가 없다.
이후 Query를 생성하는데, 자체적인 query dsl을 통해 조회 조건을 정의한다.
Query query = new Query()
.addCriteria(Criteria.where("status").is("READY"))
.with(Sort.by("createdAt"));이 과정을 종합하면 아래와 같이 이루어진다.
MongoTemplate
→ MongoCollection
→ find(query)
→ FindIterable<T>즉, mongoTemplate에서 client를 통신 객체로 하여, 자체적인 query dsl(query)를 생성하여 데이터를 MongoCollection 형태로 읽어오는 것이다. 이때 query 생성 및 데이터 추출은 최초 1번만 이루어진다.
이때 읽어오는 방법이 바로 mongoCursor, 말 그대로 mongoDB 서버와 연결된 포인터이며 hasNext가 없을때까지 커서는 DB를 바라보면서 fetch를 대기, 데이터를 추출한다. 커서가 가지고 온 데이터를 Reader 버퍼에 저장하는데, 이를 reader가 읽을 데이터가 없을때까지 read()한다.
if (cursor.hasNext()) {
return cursor.next();
}
return null;이에 대한 구체적인 동작은 위와 같고,
public T read()spring batch는 cursor가 읽어온 데이터를 chunk size만큼 read를 반복 호출하게 되는 것이다.
더이상의 읽을 데이터 혹은 버퍼에 남아있는 데이터가 없으면 reader는 최종 reader.close();를 하여 cursor 및 이와 관련한 컴포넌트들을 닫는다.
위 과정을 간략하게 두가지 방법으로 도식화해보았다.
┌────────────────────────────┐
│ Step 시작 │
└──────────────┬─────────────┘
v
┌────────────────────────────┐
│ reader.open(context) │
└──────────────┬─────────────┘
v
┌────────────────────────────┐
│ MongoTemplate 준비 │
└──────────────┬─────────────┘
v
┌────────────────────────────┐
│ Query 생성 │
│ (criteria, sort, fields) │
└──────────────┬─────────────┘
v
┌────────────────────────────┐
│ MongoCollection.find(query)│
└──────────────┬─────────────┘
v
┌────────────────────────────┐
│ MongoCursor OPEN │
│ (서버와 연결 유지) │
└────────────────────────────┘전체적인 과정은 위와 같고,
Spring Batch (Chunk Loop)
|
v
┌──────────────────────┐
│ reader.read() │
└─────────┬────────────┘
v
┌──────────────────────┐
│ cursor.hasNext()? │
└───────┬───────┬──────┘
│ YES │ NO
v v
┌──────────────┐ ┌──────────────┐
│ cursor.next()│ │ return null │
│ (문서 1건) │ │ Step 종료 신호│
└──────┬───────┘ └──────────────┘
v
┌──────────────────────┐
│ ItemProcessor │
└─────────┬────────────┘
v
┌──────────────────────┐
│ ItemWriter │
└──────────────────────┘가장 중요한 Reader의 동작 방식은 위와 같다.
Cursor: [doc1][doc2][doc3]...[docN]
↓ ↓ ↓
read() read() read()
Chunk Size = 3 이라면
read(doc1) ┐
read(doc2) ├─▶ processor → writer → COMMIT
read(doc3) ┘
Cursor는 계속 열린 상태
(Commit과 무관)중요한 점은, read()를 호출하여 버퍼에 있는 document를 읽는다는 점과 내부적으로 이 버퍼에 데이터를 추출하기 위해 cursor가 fetch를 해온다는 점이다. cursor가 hasNext할때 DB 측에서 더이상 읽을 데이터가 없고, 버퍼에 read()할 데이터가 없다면 reader는 Step을 종료한다.
참고로, jdbc와 닮은 점이 매우 많은데 fetchSize를 통해 driver buffer에 저장하는가 혹은 batchSize를 통해 driver buffer에 저장하는가에 대한 차이이다.
| 항목 | JDBC Cursor | MongoDB Cursor |
|---|---|---|
| Cursor 위치 | DB 서버 | DB 서버 |
| 버퍼 위치 | JDBC Driver | MongoDB Driver |
| 버퍼 단위 | fetchSize | batchSize |
| read() 호출 | 버퍼에서 1건 | 버퍼에서 1건 |
| 버퍼 소진 시 | DB fetch | getMore 호출 |
마지막으로 nosql의 데이터를 읽고 추출하는 것과는 별개로, batch 상태를 기록 및 저장하기 위한 RDB는 반드시 필요하다는 점을 유의하자.
2-2. MongoCursorItemReader
public HackerPatternDetectionJob(
JobRepository jobRepository,
PlatformTransactionManager transactionManager,
MongoTemplate mongoTemplate
) {
this.jobRepository = jobRepository;
this.transactionManager = transactionManager;
this.mongoTemplate = mongoTemplate;
}job을 구성할때는 기본적으로 Job/Step 상태를 기록하기 위한 jobRepository 및 transactionManager를 등록해주어야 한다. 여기에 추가적으로 cursor 기반의 스트리밍을 위해 mongoTemplate을 추가해주도록 한다.
이때 유의해야할 점은 mongoDB 기반의 item reading이 이루어진다 하더라도, RDB에 이 상태를 저장하는 것은 별도로 진행되어야 한다는 점이며, 이를 위해 H2 및 이에 준하는 RDB를 연동해야 한다는 것이다.
MongoDB reader를 실행하기 전에 알아야 할 것은 mongo DB의 데이터 구조와 쿼리의 형식이다.
mongoDB는 조회의 대상이 collection을 기준으로 이루어지며, collection을 탐색하여 내부의 bson document를 조회해온다는 점이다.
실제로 DDL(insert) 및 DML(select) 쿼리를 살펴보면 이해가 쉬워진다.
db.security_logs.insertMany([
{
attackerId: "shadow_walker",
command: "ssh admin@192.168.1.200",
timestamp: new Date(today + "03:15:00Z"),
label: "PENDING_ANALYSIS"
},
..
])Mongosh의 insert 문은 위와 같다. 현재 db를 기준으로 collection과 document를 모두 명기해주는데, 여기서 중요한 것은 security_logs라는 collection에 document 데이터를 넣는 구조로 되어있다는 점이다.
db.security_logs.find().pretty()조회를 할 경우 위와 같이 collection을 명기하고, 이를 기준으로 모든 document를 추출하는 형태이다.
db.security_logs.findOne().pretty()다른 조회형태도 마찬가지이다.
db.security_logs.find({
label: "PENDING_ANALYSIS",
timestamp: {
$gte: ISODate("2025-12-18T00:00:00Z"),
$lt: ISODate("2025-12-19T00:00:00Z")
}
})만약 collection에서 document 조회조건을 구성해준다면, 위와 같이 json 형태로 각 프로퍼티별 조회조건을 설정해준다.
MongoCursorItemReader는 이와 마찬가지로, collection을 기준으로 내부의 document를 조회하는 형태로 되어있다.
return new MongoCursorItemReaderBuilder<SecurityLog>()
.name("securityLogReader")
.template(mongoTemplate)
.collection("security_logs")그것이 이러한 api로 제공되는 것이며, jsonQuery api를 통해 document를 추출할 조건식을 json형태로 명시해주면 된다. 이에 대한 자세한 내역은 아래에 후술한다.
.jsonQuery("""
{
"label": "PENDING_ANALYSIS",
"timestamp": {
"$gte": ?0,
"$lt": ?1
}
}
""")참고로 Java 15버전 이상부터는 더블쿼터를 위와 같이 3번 기재하여, 더블쿼터 escape 및 줄바꿈 같은 번거롭고 가독성이 떨어지는 작업을 한번에 해결해주는 text block을 제공한다.
따라서, json 식을 이용할때 java 15+ 버전에서는 더블쿼터 3개(""")를 활용하여 pretty한 형태를 기재해줄 수 있다.
이외는 지금까지 알고있는 itemReader와 유사하다.
추가적으로 동적 파라미터의 경우 mongoDB의 데이터가 UTC 기준이기 때문에 atInstance로 UTC기준 시간으로 변경해준 것이다.
.parameterValues(List.of(startOfDay, endOfDay))매개변수는 위와 같이 순서대로 List형태로 전달해주면 된다.
./gradlew batch:mongo:bootRun --args='--spring.batch.job.name=detectHackerPatternJob searchDate=2025-12-18,java.time.LocalDate'위와 같이 구성한 job 실행 시
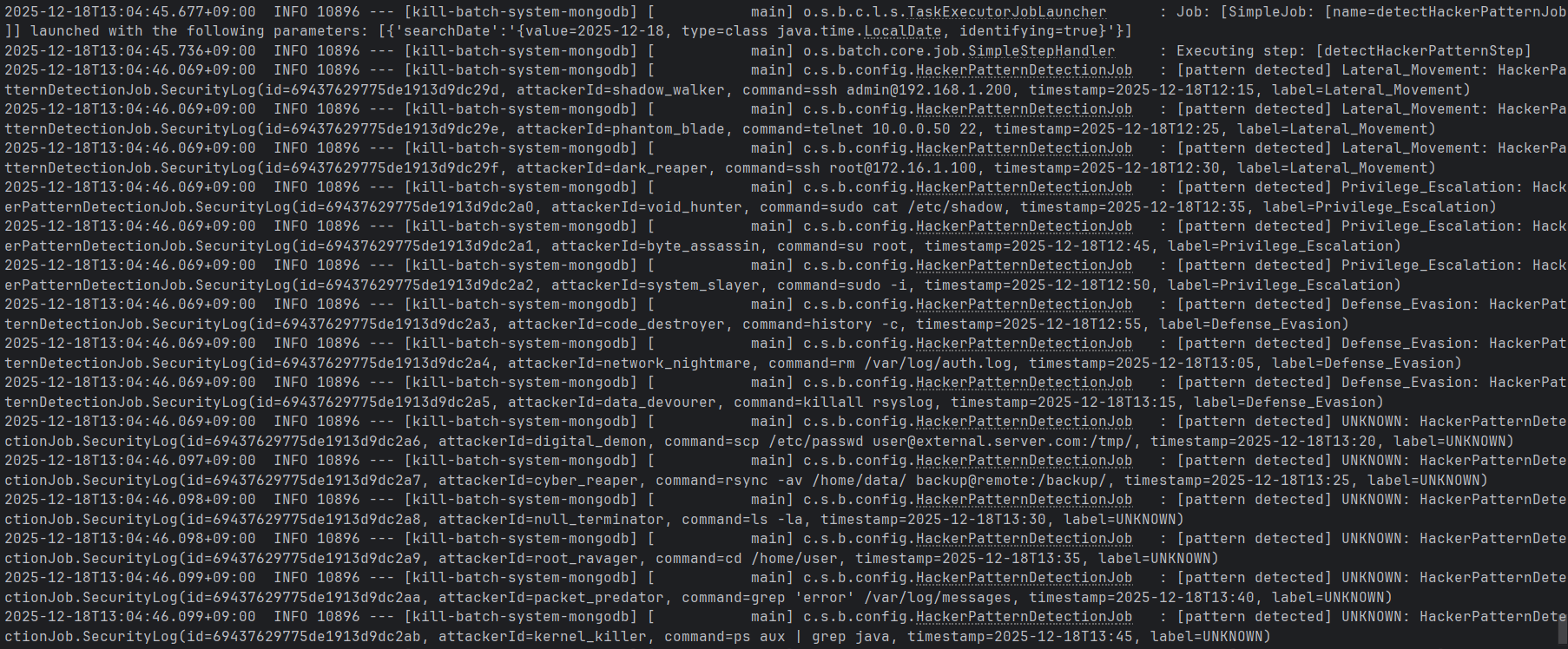
최종적으로 reader-processor-writer로 진행하는 MongoCursorItemReader 동작을 확인할 수 있다.
참고. mongoTemplate은 mongoDB와 연동하기 위한 "엔진"이다.
MongoTemplate
└─ MongoDatabaseFactory
└─ MongoClientmongoTemplate은 위와 같이 각 layer을 통해, 어떤 mongoDB 서버를 연결할 것이며 어떠한 database와 client객체를 사용할 것인지 구성해주는 역할을 한다.
참고. mongosh에서만 표현하는 독특한 조건식
mongosh은 >=, <, =와 같은 조건을 표현하는 특수 표현식들이 존재한다.
위에서 명기한 조건 중 $gte (grater than or equal)은 이상조건, $lt (less than)은 이하조건이다.
| MongoDB 표현 | 의미 | SQL 대응 |
|---|---|---|
{ f: v } | f == v | = |
{ f: { $eq: v } } | f == v | = |
{ f: { $ne: v } } | f != v | != |
{ f: { $gt: v } } | f > v | > |
{ f: { $gte: v } } | f ≥ v | >= |
{ f: { $lt: v } } | f < v | < |
{ f: { $lte: v } } | f ≤ v | <= |
{ f: { $in: [...] } } | 포함 | IN |
{ f: { $nin: [...] } } | 미포함 | NOT IN |
조건을 JSON형태로 구성해준다는 것이 특징인데,
{
"PROPERTY" :
{
$eq : ?0
}
}동등조건의 경우, 표현식을 사용하면 위와 같이 불필요하게 조건이 복잡해지므로
{
"label" : "PENDING_ANALYSIS"
}위와 같이 동등조건의 특정값 그대로 명기해준다.
참고로 OR조건은 표현식을 먼저 구성하고, OR조건의 대상을 적어주는 것이 일반적이다.
{
"$or": [
{ "label": "READY" },
{ "label": "FAILED" }
]
}위와 같이 json 형태로 OR조건 : 대상을 표현해주고, 대상이 여러개라면 배열([])로 감싸주면 되겠다.
조건이 없다면 AND조건이 생략되어있는 형태로 이해하면 된다.
참고. 임시적인 DTO 등의 목적으로 static inner class를 사용하고자 할 때
MongoDB 혹은 RDB 등의 데이터를 Read-process-write를 구성할때, JPA가 아닌 이상 사실상 DTO의 목적으로 inner class를 임시적으로 생성할 필요가 있을 것이다(굳이 도메인 분리를 통해 DTO를 만들지 않고).
이 경우, 내부적으로 static class를 만들어 DTO 클래스로 활용하면 좋은 방안이 될 수 있다.
더불어 MongoCursorItemReader의 경우 JPA의 엔티티처럼 target class를 document 형태의 객체로 저장하는 것이 좋은데, 이를 위해 @Document 어노테이션을 사용하도록 한다.

참고로 이 id필드를 @Id 프로퍼티를 통해 매핑해줄 수 있는 등 Collection을 객체화할 수 있고, Job/Step 등의 상태를 Repository를 통해 연동이 가능해진다.
따라서 단순 매핑이 아니라면 웬만하면 엔진에 맞는 ItemReader를 사용해야 Batch 상태 관리 등이 가능해지므로, 강력하게 어노테이션 활용을 권장한다.
참고. static inner class는 멤버 중 하나이지만 종속되지 않는다.
참고차 또 하나 정리할 부분이 있다면, static inner class는 outer class의 멤버 중 하나이면서 "종속이 되지 않는" 클래스라는 점이다.
즉, static 클래스(정확하게 말하면 static 멤버로 설정된 inner class)의 경우 말 그대로 인스턴스 없이 클래스 프로퍼티에 접근할 수 있는 클래스를 정의하는데(*heap이 아닌 stack의 메서드 및 데이터 영역에서 생성됨), Outer class의 this에 종속되지 않기에 outer class 객체에서 해당 프로퍼티로 바로 접근이 가능하다는 장점이 생긴다.
다만, 자체적인 inner class의 this, 즉 객체는 존재한다. static이든 non-static이든 객체 자체는 반드시 존재하는 것이고, 이에 따라 getter/setter 메서드를 통한 프로퍼티 접근도 가능하다는 것에 유의하자.
더불어 Outer class의 멤버 중 하나이지만, 해당 클래스에 종속된 클래스가 아니기에 heap이 아닌 metaspace에 outer class와 별도의 클래스로 로드가 된다.
즉, 클래스 정보나 내부적인 메서드들의 구조가 metaspace에 1차 저장이 된다.
Metaspace:
Outer
Outer$Inner위와 같이 Outer 클래스에 종속된 this가 아닌, Outer 클래스 내부의 컴포넌트로 저장이된다(Outer$outer$inner의 종속형태가 아니라, Outer의 한 멤버로의 정보로 기재됨).
class Outer {
class Inner {
void f() {}
}
}따라서 위와 같은 형태일 경우 컴파일러가
class Inner {
final Outer this$0;
Inner(Outer outer) {
this.this$0 = outer;
}
void f() {}
}this라는 inner 클래스를 $this라는 Outer class에 종속이 되도록 구성하는데, static 선언 시 위 메타스페이스 구성처럼 멤버변수의 역할만 구성해주고 종속이 되도록 구성해주지는 않는다는 것이다.
이로 인해,
Outer o = new Outer();
Outer.Inner i = o.new Inner(); // 반드시 Outer 필요일반적인 상황에서는 outer를 통한 inner 객체생성이 선행되어야 하지만
Outer o = new Outer();
Outer.Inner i = new Outer.Inner();메타스페이스에서 독립구성 및 outer 종속이 안되어있기 때문에, outer.inner 클래스를 생성하지 않고도 바로 해당 클래스 생성이 가능하다는 점이다.
이게 처음에는 상당히 헷갈리는 부분인데, 이 과정을 이해한다면 더 유연하고 정확한 inner class(DTO) 활용이 가능해질 것이다.
또한 "객체"로 생성되기에 heap에 저장이 되며
Heap:
[Outer 객체]
[Outer$Inner 객체]stack에 이를 참조하는 변수가 저장이 되는 과정은 동일하다.
Stack:
o → Outer 객체
i → Inner 객체heap/stack을 통한 객체생성 및 변수참조는 그대로 이루어지기에 @Data와 같은 어노테이션이 정상적으로 적용이 가능한 것이다.
2-3. query dsl의 활용
만약 위와 같이 일반 text block을 통한 쿼리 작성이 아니라, type safe한 query dsl을 활용한다면 좀 더 명확한 쿼리 작성이 가능해진다.
Query query = new Query()
.addCriteria(Criteria.where("label").is("PENDING_ANALYSIS"))
.addCriteria(Criteria.where("timestamp")
.gte(startOfDay)
.lt(endOfDay)
)
.with(Sort.by(Sort.Direction.ASC, "timestamp"))
.cursorBatchSize(10)
;이 쿼리를 기존 jsonQuery가 아닌 query api에 적용해주면 된다.
.query(query)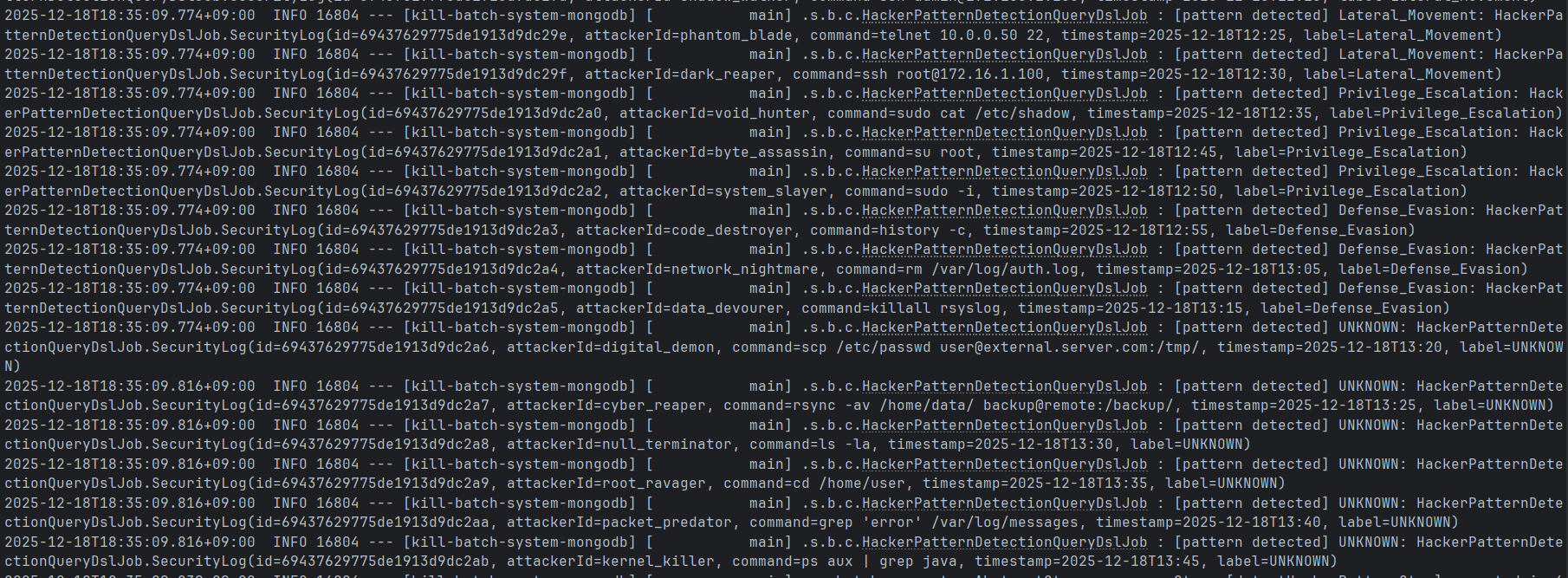
이를 실행하면 동일한 결과를 얻을 수 있다.
처음 적용할때는 다소 복잡할 수 있지만, 말 그대로 type-safe하기도 하고 윈도우/ubuntu와 같은 환경적 의존성을 상관하지 않고 java 로직을 통해서만 구현이 가능하다는 강력한 장점이 있다.
다만, mongoDB 내부적으로 구성한 query에서 한번 더 정렬조건을 지정해주어야 하기에(query의 정렬조건 상관없이 내부적으로 정렬조건을 반드시 탐색하며, query에서의 정렬조건은 무시된다) 빌더패턴을 어느 정도는 숙지할 필요는 있겠다.
2-4. MongoPagingItemReader
paging기반 reader는 일전에 봐왔던 바와 같이 limit, offset을 활용하여 각 페이지 별로 새로운 쿼리를 날리면서 데이터를 reading 해오는 방식이다.
기존에도 paging방식은 가뜩이나 성능적으로 비효율적이고 좋지 않은데, mongoDB는 성능적으로 더욱 불리하다.
일단 mongoDB는 자체적인 물리적 샤드를 지원하는데, 흩어져 있는 데이터를 페이지별로 분류하기 위해 1차적으로 모아서 전체 데이터를 로드하는 과정이 발생한다.
여기에 mongos가 전체 데이터에 대해 정렬 및 별도로 offset만큼 건너뛰는 작업을 진행하게 되어, 샤드 별 정렬 + 전체 데이터 정렬과 같은 반복 작업이 누적되어 데이터 크기가 커지면 커질수록 과부하가 발생할 수 밖에 없다(오버헤드 발생).
return new MongoPagingItemReaderBuilder<SecurityLog>()
.name("securityLogReader")
.template(mongoTemplate)
.collection("security_logs")
.query(query)
.parameterValues(List.of(startOfDay, endOfDay))
.sorts(Map.of("timestamp", Sort.Direction.ASC))
.targetType(SecurityLog.class)
.pageSize(10)
.build();mongoPagingItemReader로 변경하고, fetchSize(batchSize)가 아닌 pageSize를 설정해주기만 하면 된다. 이 외의 설정은 동일하다.
./gradlew batch:mongo:bootRun --args='--spring.batch.job.name=detectHackerPatternPagingJob searchDate=2025-12-18,java.time.LocalDate'이를 실행하게 되면
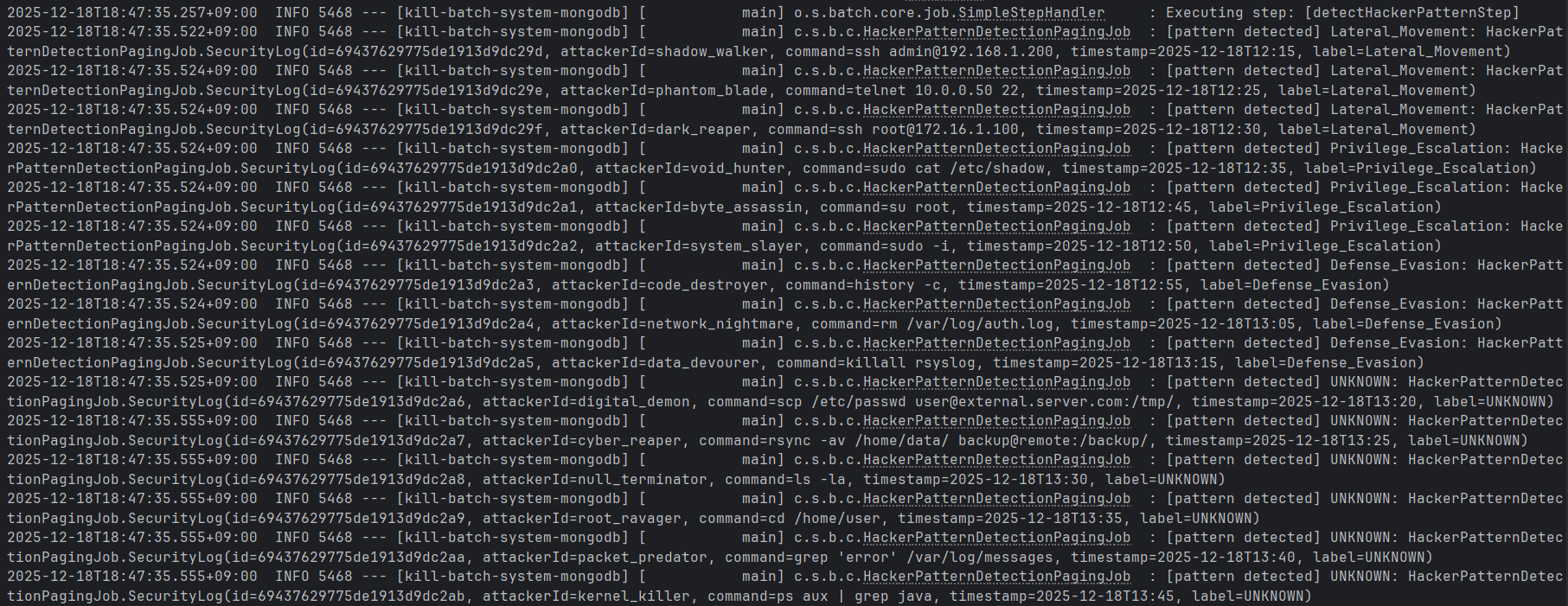
위와 같이 일전의 CursorItemReader와 동일한 Reading 결과를 확인할 수 있다.
3. MongoItemWriter
말그대로 MongoTemplate을 활용하여, mongoDB에 청크 아이템을 insert/replace/delete할 수 있는 기능을 제공한다.
다만 기존 writer의 batchUpdate와 차이점이 있다면, multi value insert/update/delete 등을 한 번의 요청으로 모두 진행한다는 점이며 단일 쓰기 작업이 아닌, 여러 형태의 쓰기 작업을 하나의 요청에 모두 담아 진행한다.
이를 bulkWrite라 하며, 청크마다 모든 형태의 처리를 진행하고 그만큼 개별적인 요청을 단일화하여 네트워크 소모 비용을 최소화한다.
@Bean
public MongoItemWriter<SecurityLog> securityLogWriter() {
return new MongoItemWriterBuilder<SecurityLog>()
.template(mongoTemplate)
.collection("security_logs")
.mode(MongoItemWriter.Mode.UPSERT) // 기존 문서 수정
.build();
}mongoItemWriter의 경우 Output할 객체(여기서는 SecurityLog)를 통해 mongoDB에 어떠한 형태의 write를 할 것인지 선택하는 mode가 중요하다.
아래 3가지의 형태를 spring batch에서는 제공한다.
- INSERT : insertOne, 신규 데이터를 삽입한다.
- UPSERT : replaceOne, 데이터가 없으면 삽입하고 있으면 수정한다.
- REMOVE : deleteMany, 데이터를 삭제한다.
public class MongoItemWriter<T> implements ItemWriter<T>, InitializingBean {
private static final String ID_KEY = "_id";
private MongoOperations template;
private final Object bufferKey;
private String collection;
private Mode mode;
public MongoItemWriter() {
this.mode = MongoItemWriter.Mode.UPSERT;
this.bufferKey = new Object();
}MongoItemWriter 인터페이스를 살펴보면 위와 같은데, 생성자를 보면 알 수 있듯이 기본적인 모드는 UPSERT이다.
이때 JPA 엔티티처럼, document 역시 마찬가지로, id값을 기반으로 write를 진행한다. 즉, 해당 객체에서의 @Id 프로퍼티 및 해당 값과 일치하는 도큐먼트를 찾아서 있으면 update, 없으면 insert를 진행한다.
최근에는 @id 단일 PK값을 통해서만 write가 이루어졌는데, 최근 5.2.3버전부터는 복합PK(primayKeys())를 활용한 write기능을 지원하고있다.
@Bean
public MongoItemWriter<SecurityLog> securityLogWriter() {
return new MongoItemWriterBuilder<SecurityLog>()
.template(mongoTemplate)
.collection("security_logs")
.primaryKeys(List.of("attackerId", "timestamp"))
.mode(MongoItemWriter.Mode.UPSERT) // 기존 문서 수정
.build();
}위와 같이 primayKeys에 list형태로 복합PK를 등록하면 해당 인자를 기준으로 데이터를 write한다.
참고로 본인의 경우 spring boot버전이 3.2.7버전이기에 batch의 최신버전이 적용이 안되었다. 이에 대한 환경설정을 위해 root project의 플러그인 적용 후, batch에 대한 버전을 덮어씌우기 위해 별도의 dependencyManagement를 적용해주었다.
apply plugin: 'java'
apply plugin: 'org.springframework.boot'
apply plugin: 'io.spring.dependency-management'
dependencyManagement {
imports {
mavenBom "org.springframework.batch:spring-batch-bom:5.2.3"
}
}위와 같이 dependency management를 적용해주면, 현재 boot버전이 최신이 아니더라도 특정 버전의 batch 모듈 라이브러리를 가져올 수 있게 된다.
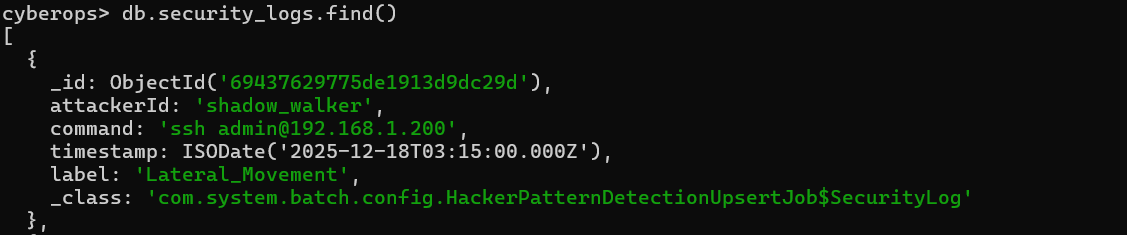
이를 실행하면 위와 같이 데이터가 update 되었음을 확인할 수 있다.
참고. _class
mongoDB의 document를 살펴보면 _class가 추가된 것을 확인할 수 있는데, 이는 mongoDB에서 제공하는 Type hint이다.
즉, mongoDB는 java 타입이 저장될 수 있는, 매핑될 수 있는 구조를 지원하고자 mongoDB에 데이터를 역직렬화하여 쓰는 target class의 FQCN을 그대로 저장한다.
MappingMongoConverter위 인터페이스가 직렬화/역직렬화의 핵심 컴포넌트이며, 해당 _class의 프로퍼티를 참고하여 java 수준의 객체 역직렬화를 진행한다.
4. MongoTransactionManager
mongoDBItemReader/Writer를 사용할 경우 유의해야 하는 점은 바로 롤백에 대한 처리, 즉 오류상황에 대한 후처리 로직 구성이다.
| 항목 | MongoDBCursorItemReader |
|---|---|
| Cursor | 트랜잭션과 무관 |
| Chunk Commit | Writer 기준 |
| Rollback | Cursor 위치 되돌리지 않음 |
mongoDB의 처리는 위에서 볼 수 있듯이 철저하게 PK(id) 혹은 유니크 인자를 기준으로 진행이 되는데, 기본적인 mongoDB의 write 데이터 후처리 역시 이를 기반으로(pk/@id) 이루어져야 한다.
cursor 자체는 forward-only이기 때문에, 중간에 오류 발생 시 cursor의 위치를 원복하거나 재조정할 수 없기 때문에, 이를 고려한 batch 구성 재설계/재구성이 반드시 필요하다.
이 재설계/재구성을 가능하도록 해주는 핵심 컴포넌트가 바로 MongoTransactionManager이다.
다만, 사용을 위해서는 몇가지 제약이 존재한다.
- MongoDB 4.0+ 버전에서만 사용 가능하며, 단일 MongoDB 환경이 아닌 레플리카 및 샤드 클러스터 환경에서만 사용 가능하다.
- 자동 구성 대상이 아니기에 반드시 mongoTemplate.getMongoDatabaseFactory()를 통해 직접 구현 및 mongoTransactionManager를 주입받아 사용해야 한다.
mongoItemWriter의 경우 flatFileItemWriter와 같이, update 데이터를 내부적인 버퍼에 일단 옮겨놓고 beforeCommit() 시점에 파일을 쓴다. 내부적인 버퍼의 데이터를 모두 write한 후에, 최종 commit하기에 잘못된 데이터가 쓰여지는 것을 지연할 수 있지만, 모든 데이터를 롤백하지는 못하고(원자단위의 롤백) commit한 데이터의 성공 내역은 저장이 된다는 것을 기억하자.
(사실 모든 writer는 chunk size만큼 데이터를 write > commit은 동일하지만, RDB처럼 모든 데이터를 롤백하고 이를 관리하는 체계는 아직 부족하다는 점을 유의하도록 한다)
5. Redis
최근 Spring Batch (5.1ver)에는 MongoDB와 함께 Redis또한 ItemReader/Writer 기능을 제공하여 준다.
Redis는 너무 많이 다루는 내용지만 그만큼 중요하고, 아무리 반복학습하여도 지나침이 없기에 다시 한번 정리하고 넘어간다.
Redis는 다른 NoSQL와는 달리 In memory based 데이터베이스이기에 속도가 빠르고, 동시에 key-value의 구조를 넘어 value의 형태를 List/Set/String/Hash/Sorted Set 등 다양한 자료구조로 지원하여 유연성높은 데이터 영속화를 지원한다.
- String
Redis 관점에서 가장 보편적이고 안정적인 byte 배열로, 숫자/문자열/JSON 등 모든 객체를 String 형태로 역직렬화할 수 있다.
주로 단일한 상태값 및 JSON 객체 자체를 통째로 저장하고자 할 때 사용한다.
저장 형태는
"user:1:name" → "Lee"이와 같고, 이에 대한 setter/getter 명령도 지원한다.
SET user:1:name "Lee"
GET user:1:name- List
인덱스 기반의 일련의 요소를 저장하는 자료구조로, 말 그대로 중복을 허용하고 순서를 보장한다.
메시지큐나 대기열, timeline 등 순차적인 작업 내역 등을 저장하기 위해 사용한다.
저장 형태는
"chat:room:1" → ["hi", "hello", "bye"]이와 같고, java의 api처럼 put 명령도 지원한다(Redis는 push)
LPUSH chat:room:1 "hi"
LPUSH chat:room:1 "hello"
RPUSH chat:room:1 "bye"
LRANGE chat:room:1 0 -1- Set
인덱스 및 순서보장 없이, 중복을 허용하지 않는 데이터의 집합이다.
내부적으로 hashSet 형태로 저장하는 것이 대부분이다.
저장 형태는
"user:1:roles" → {"ADMIN", "USER"}이와 같고, java의 api처럼 put 명령을 지원한다(Redis는 SADD).
SADD user:1:roles "ADMIN"
SADD user:1:roles "USER"
SMEMBERS user:1:roles- Hash
객체형태의 자료구조이며, JSON과 같이 한 필드에 여러 속성이 있는 row(record) 및 이에 기반하는 통신(RESTful)에 많이 활용하는 자료구조이다.
저장 형태는
"user:1" → {
"name": "Lee",
"age": "30"
}이와 같고, 이 역시 java의 api처럼 setter/getter 명령을 지원한다.
HSET user:1 name "Lee" age 30
HGET user:1 name
HGETALL user:1- Sorted Set(ZSet)
Redis에서 자랑하는 대표적인 자료구조이자, 인기글 및 우선순위 선정을 위해 사용하는 Set 자료구조 기반의 scored(가중치) 자료구조이다.
set 자료구조 기반이기에 value의 중복이 없고, 가장 특징적인 부분인 우선순위(Score)가 존재하므로 이를 활용한 다양한 실무적 상황에 활용이 가능하다.
"game:ranking" → {
("Lee", 1500),
("Kim", 1700)
}위와 같은 저장형태를 지니며, score와 함께 value를 저장하는 것이 특징이다.
ZADD game:ranking 1500 "Lee"
ZADD game:ranking 1700 "Kim"
ZRANGE game:ranking 0 -1 WITHSCORESZADD/ZRANGE 등 Z의 prefix를 붙인 명령어를 사용하며, java에서 잘 지원하고 널리 알려진 자료구조이기도 하다.
| 자료구조 | Key → Value 형태 | 특징 | 대표 사용처 |
|---|---|---|---|
| String | "key" → "value" | 단일 값 | 토큰, 상태값 |
| List | "key" → ["a","b"] | 순서 O, 중복 O | 큐, 로그 |
| Set | "key" → {"a","b"} | 순서 X, 중복 X | 권한, 태그 |
| Hash | "key" → {f:v} | 필드 구조 | 객체 저장 |
| ZSet | "key" → (value,score) | 정렬 O | 랭킹 |
5-1. RedisItemReader
말 그대로 Redis의 데이터를 읽어오는 Reader이며, SCAN 명령어를 사용하여 key값들을 읽어온다.
따라서 RedisItemReader를 사용하여 데이터를 읽어올때는 key값 -> 이후 GET명령을 통해 해당 자료구조의 value를 얻는 두번의 과정이 필요하다.
참고로, SCAN 명령은 String 타입에 대한 명령어이고, 다른 데이터 타입들은 HSCAN/SSCAN/ZSAN 등을 기반으로 ItemReader를 직접 구현해야만 한다.
핵심은 scan 커서이다. scan을 해서 key값들을 받아올때, scan 커서가 따로 존재하여 key 목록을 일부 가져오고, 해당 목록을 JVM에 적재하여 key iterator가 read()를 반복하여 1개의 key를 추출해오는 구조이다.
즉, key cursor -> read by 1 key 형태로 key를 받아오는 것이 핵심이며, RDB의 row(record) 자체를 반환하는 것과는 완전히 반대의 과정이다.
좀 더 자세히 살펴보자.
최초 open()을 통해 RedisConnection을 생성한다.
open()
└ RedisConnection 획득
└ SCAN 초기 커서 = 0
└ 내부 상태 초기화이때 생성한 SCAN 커서는 이후 힌트값을 참고로 하여 COUNT만큼의 key값을 추출해오는데, SCAN cursor는 key batch를 통해 일정 COUNT만큼의 key값을 JVM 버퍼로 옮긴다.
[Redis SCAN Cursor]
↓ (key batch)
[JVM 내부 key iterator]
↓ (1개씩)
read() → item이후 batch 측에서 read()를 호출하여, key iterator를 통해 한개씩 key값을 가져 오는 방식이다.
이때 내부 버퍼에 key값이 남아있지 않을때까지 iterator를 지속 동작한다.
iterator.next() → key
GET / HGETALL / etc → value
return item이를 key값이 남아있지 않을때까지 반복하는데, key값이 null일때(iteraotr의 hasNext가 false일때) SCAN cursor로부터 새로운 key batch를 추출해온다.
SCAN(cursor)
└ 새로운 key batch 획득
└ iterator 재생성
└ cursor 갱신이 cursor가 0이면 더이상 읽을 데이터가 없는 것으로 판단하여, iterator의 next 요소가 없을때 Reader Step을 종료한다. 내부적으로 데이터를 읽을때는 read()를 호출하게 되는데, 추출할 key값이 더이상 존재하지 않을때까지 read()를 계속 호출한다.
그리고 RedisItemReader의 가장 중요한, 나악 cursor 기반의 itemReader의 가장 핵심적인 부분은 cursor의 이중화이다.
Redis Cursor는 RDB의 "위치" 및 "포인터" 역할과는 달리, key batch에 의해 추출해오는 key 배열(keyBatch)을 분할 순회하기 위한 토큰값의 일종이라 보면 되겠다.
Redis는 내부적으로 hash 구조를 지니기에, 내부 hash Table의 버킷 위치에 대한 정보를 cursor가 가지고 있도록 하고 다음 SCAN 요청 시 이를 활용하여 데이터를 읽어온다.
이때 Redis의 scan cursor는 scan 동작마다 업데이트가 이루어지고, 내부 iterator를 순회하면서(read()/GET) 받아온 key space를 소모하는 과정이다.
SCAN → 100 keys
cursor = 18372
read() × 100
└ cursor 그대로
└ iterator만 소비
iterator 소진 →
SCAN(cursor=18372)이러한 과정이 반복되면서, 더이상 읽을 데이터가 없을때까지 Step을 지속하는 것이다.
최종적으로 value는 read()호출 시 GET을 통해, redis로부터 추출해온다.
따라서 key batch를 통해 확보한 key값들을 바탕으로, value를 추출해오기 위해 각각의 key값마다 read()를 호출하고, redis connection을 통해(=GET/ZGET) value를 추출해오는 과정이며, 이로 인한 네트워크 부하가 Redis에서는 상대적으로 많이 발생할 수 밖에 없게 된다.
참고. RedisCursorItemReader의 멱등성
Cursor기반의 Redis item Reader는 동일한 데이터가 있어도, SCAN 중간에 데이터 쓰기가 가능하여 멱등성이 보장되지 않는 치명적인 단점이 존재한다.
더불어 Redis 자체가 key값의 중복을 허용하지는 않지만, ItemReader가 읽는 도중에 key값이 추가되어 내부적인 hash table의 rehashing이 이루어지게 된다.
즉, 읽는 도중 key값이 추가 및 삭제 되었을때 rehashing하는 도중에(rehash 전), update된 hash table bucket에서 기존의 key값을 다시 한번 훑게되는 중복 scan이 발생할 수 있다.
즉 쉽게 말하면, key가 저장되는 공간은 hash table이라는 버킷배열에서 각각의 배열 하나하나이다.
dict
├─ ht[0] ← old table
└─ ht[1] ← new table (rehash 중일 때만 존재)이때 기존의 ht공간은 0인덱스만 존재하였는데, 1인덱스까지 추가된 상태라고 하자.
ht[0]
bucket 0 → keyA
bucket 1 → keyB
bucket 2 → keyC이때 기존의 hash table(버킷배열)은 위와 같이 key값을 보유하고 있는데, 중간에 key값이 추가되어 hash table을 추가할 경우, key값의 전면 재배치가 발생한다.
ht[0] (old) ht[1] (new)
bucket 0 → (empty) bucket 0 → keyA
bucket 1 → keyB bucket 1 → (empty)
bucket 2 → keyC bucket 2 → (empty)문제는 전면적인 재배치를 일괄적으로 한번에 진행하지 않기에, keyA의 값이 새로 추가된 버킷배열에 배치된 상태로 scan cursor가 데이터를 읽어오는 상황이 있을 수 있다.
SCAN입장에서는 key값을 순서대로 순회하는 것이 아니라, 버킷배열의 인덱스를 기억하고 있기 때문에 새로운 버킷배열을 읽음으로 인해 기존의 keyA값을 또 읽는 중복 SCAN이 발생하게 된다.
이러한 구조적 특성으로 인해, 읽는 도중 Write가 발생하게되면 key값을 중복으로 읽는 등 멱등성을 보장하지 않는 결과를 초래한다.
참고로 멱등성에 대한 부분은, 이러한 Read 중간에 쓰기가 발생한 문제뿐만 아니라 데이터 순서를 보장하지 않기에 동일한 데이터 내역이라도 batch job 전/후의 실행의 결과를 온전하게 보장할 수 없다는 점도 포함한다.
이러한 멱등성 문제로 인해, Redis의 경우 재시작 기능을 제공하지 않는다.
참고. Redis/RDB에서의 cursor 기반 ItemReader의 중요한 원리 - cursor의 이중화(분리운용)
cursor 기반의 item Reader는 기본적으로 DB를 향하는 cursor와, driver 측에서 관리하는 cursor, 최종적으로 cursor의 위치정보 및 포인터(RDB) 혹은 메타 데이터 객체(NoSQL)를 저장하는 JVM 측의 정보로 나눌 수 있다.
이때 DB를 바라보는 실제 cursor, driver에서 관리하는 cursor가 별도로 운용이 되기에, cursor의 이중화 개념은 반드시 이해하고 넘어가야할 요소 중 하나이다.
DB에 따라 다르지만, 보통은 RDB - Driver(batch buffer) - JVM Cursor(iterator)로 나뉘어져있고, Redis의 경우 Scan Cursor와 JVM(iterator) cursor로 이분화 되어있다.
| 시스템 | DB 서버 cursor | Driver 상태 | JVM cursor |
|---|---|---|---|
| RDB (JDBC) | O | O | O |
| MongoDB | O | O | O |
| Redis | X | X | O |
| Cassandra | X | O | O |
resultSet을 사용하는 RDB의 경우, DB에서 바라보는 cursor와 fetch한 데이터를 임시로 보관하는 Drvier Buffer, 이를 역직렬화하여 읽을 수 있는 객체로 변환하여 저장하고 cursor의 위치정보(포인터)를 기억하고 있는 JVM Cursor로 나뉘어진다.
서버 커서가 있는 Reader는 말 그대로 Driver 측에서 cursor를 보유하고 있다는 의미이고, 나아가 이를 resultSet과 같은 client 측(JVM) cursor 메타데이터를 관리하도록 설계하였다. 이 인터페이스는 보통 resultSet과 같은 객체이고, 이를 통해 cursor 관리와 역직렬화를 동시에 진행한다.
[DB Server]
Cursor position: 0 → 10 → 20 → ...
FETCH
[JDBC Driver]
Fetch Buffer: rows[0..9]
rs.next()
[JVM]
ResultSet cursor: 0 → 1 → 2 → ...
Domain Object 생성RDB나 MongoDB의 경우에는 위와 같고, Redis의 경우에는 이러한 ResultSet을 관리할 인터페이스 및 계층이 존재하지 않기 때문에 이중화된 cursor 체계로 되어있다(아마 Redis 자체가 인메모리 방식이기에, 어느정도는 접근 속도가 보장되어있다보니 driver buffer를 따로 두지 않고 DB/JVM의 I/O로 직접 관리하는 것으로 추정).
이를 제외한 대부분의 경우에는,
- 네트워크 비용 최소화
- DB cursor 이동 최소화
- JVM에서 빠른 순차 접근 제공
등의 목적으로, 성능적인 한계점(특히 네트워크 비용)을 보완하기 위해 DB/Driver/JVM의 3가지 형태로 cursor 체계를 관리한다.
5-2. 실무적용방안
전체적인 컴포넌트는 MongoDB와 유사하다.
RedisTemplate 및 Cursor/Options(hint) 등을 구성하여 Cursor 기반의 RedisItemReader를 구성해주면 된다.
몇가지 복잡하게 느껴지는 설계적 사안들에 대해 잠깐 훑고 바로 실행단계로 넘어가보겠다.
- chunk Step - tasklet Step 복합 구성
Redis에 저장되어있는 데이터를 합계 및 산출하는 Step을 각각 별도로 나누어 진행하며, 이때 chunk성 작업과 단순 tasklet 작업으로 복합구성해주도록 한다.
@Bean
public Job aggregateHackerAttackJob(
Step aggregateAttackStep,
Step reportAttacktStep,
AttackCounter attackCounter
) {
return new JobBuilder("aggregateHackerAttackJob", jobRepository)
.start(aggregateAttackStep)
.next(reportAttacktStep)
.listener(attackCounter)
.build();
}
- 리스너의 실행시점(job리스너로 붙여진 만큼 job의 생명주기에 반응)
job에는 job 생명주기에 포함하는 jobListener를 등록해주었으며, job 실행 이후에 static한 value를 초기화하는 작업을 진행한다.
JobLauncher.run(job, jobParameters)
↓
Job.execute()
↓
[1] JobExecutionListener.beforeJob() ← 여기서 호출
↓
Step 1 실행
Step 2 실행
...
↓
Job 상태 결정 (COMPLETED / FAILED / STOPPED)
↓
[2] JobExecutionListener.afterJob() ← 여기서 호출참고로 jobListener는 말 그대로 job의 생명주기에 포함하는 리스너로, job 실행 전/후 시점(beforJob/afterJob)에 관심사를 실행한다.
- Step/Reader/Processor/Writer 간 반환 type의 일치
Step의 Input(Reader 반환형태)는 RedisItemReader의 반환값, Oupput은 Processor의 반환형태이자 Writer의 전달형태로 서로의 반환형태/전달형태는 일관되어야 한다(일치).
또한 산출 Step에서 반환한 Output(Writer)값을 그대로 그 다음의 Step Input으로 활용할 수 있도록 적절하게 batch step을 구성해주도록 한다.
- 편의상 리스너 메소드를 writer에서 사용가능
@Component
@RequiredArgsConstructor
public static class AttackCounterItemWriter implements ItemWriter<AttackLog> {
private final AttackCounter attackCounter;
@Override
public void write(Chunk<? extends AttackLog> chunk) {
for (AttackLog attackLog : chunk) {
attackCounter.record(attackLog);
}
}
}writer에서는 위와 같이 listener 내부의 로직을 실행하는데, 도메인 분리 등의 세부적인 고려사항을 생략하고 편의상 구현한 것이다.
Listener 자체의 목적과 별도로, 내부의 메소드를 선언하여 사용하는 것 자체는 문제없다.
참고로,
@Bean
public Step aggregateAttackStep(
RedisItemReader<String, AttackLog> attackLogReader,
AttackCounterItemWriter attackCounterItemWriter
) {
return new StepBuilder("aggregateAttackStep", jobRepository)
.<AttackLog, AttackLog>chunk(10, transactionManager)
.reader(attackLogReader)
.processor(item -> {
log.info("{}", item);
return item;
})
.writer(attackCounterItemWriter)
.build();
}위 Step에서 지금까지 봐왔던 이름형태가 아닌, AttackCounterItemWriter라는 반환 형태 그대로 주입받아 사용하는 것을 알 수 있다.
기본적으로 Bean주입은 첫째로 반환형태 그 자체이고, 반환 형태가 같을때 이름을 찾아 주입받는다.
따라서 이러한 주입방식도 있다는 것을 염두에 두도록 한다.
- (참고) RedisItemReader는 Redis로부터 String 형태만 기본제공, HASH/SET/ZSET 등의 자료구조에 대해서는 별도의 ItemReader 구현이 필요하다.
@Bean
public RedisItemReader<String, AttackLog> attackLogReader() {RedisItemReader는 아직까지 기본제공 Input 타입이 String밖에 없다.
즉, Redis의 다양한 자료구조 중 String 형태의 데이터만 파싱이 가능하며 이외 Set/ZSet 등의 자료구조는 별도 파싱 구현체를 만들어 사용해야 한다.
이 정도의 구조를 이해한 상태에서 실행에 넘어간다.
./gradlew batch:nosql:bootRun --args='--spring.batch.job.name=aggregateHackerAttackJob'위 gradle을 실행해주면
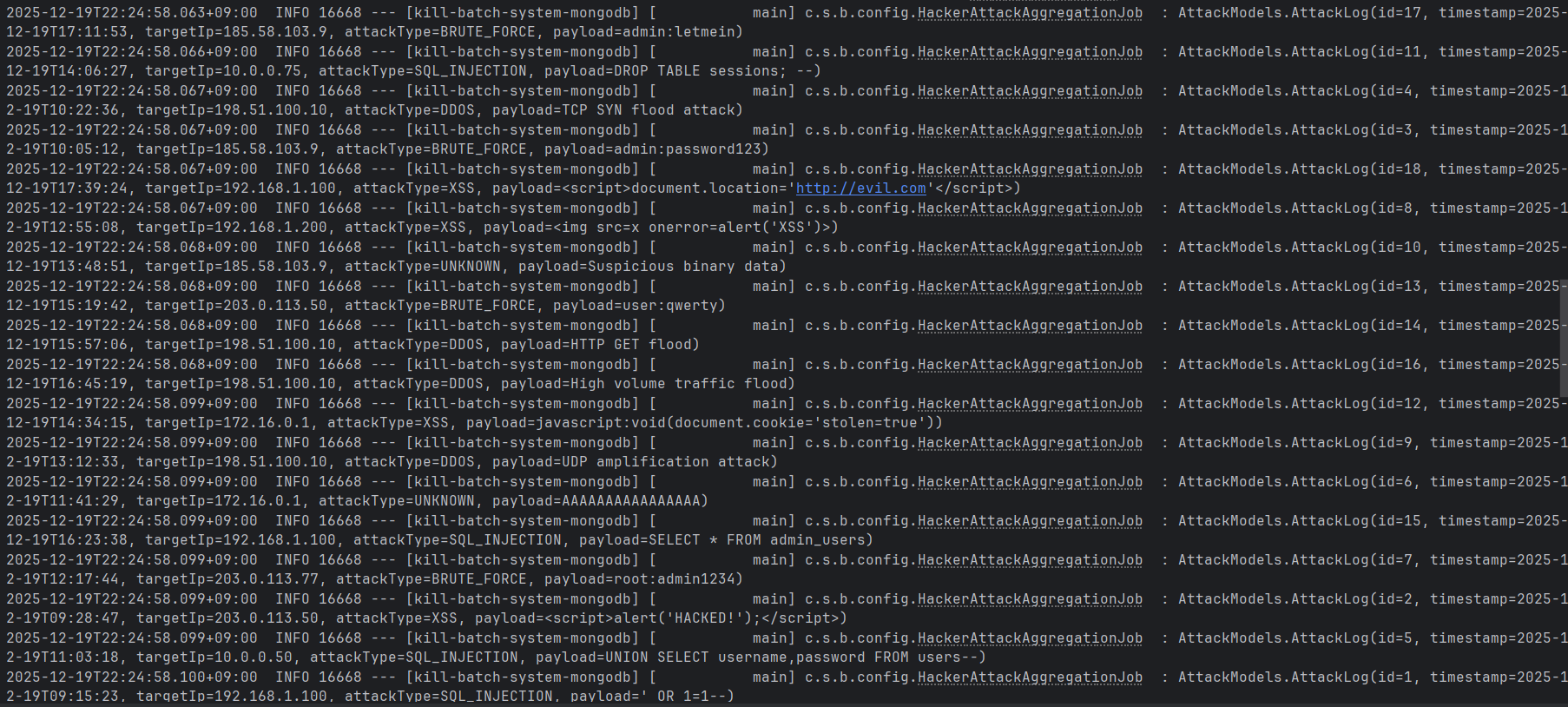
위와 같은 redis Reader를 통한 데이터 읽기 과정을 살펴볼 수 있다.
5-3. RedisItemWriter
RedisItemWriter를 아래와 같이 구성해주어 빈객체로 등록하면 되겠다.
@Bean
public RedisItemWriter<String, AttackLog> deleteAttackLogWriter(
RedisTemplate<String, AttackLog> attackLogRedisTemplate
){
return new RedisItemWriterBuilder<String, AttackLog>()
.redisTemplate(attackLogRedisTemplate)
.itemKeyMapper(attackLog -> "attack:" + attackLog.getId())
.delete(true)
.build();
}특히, mongoTemplate의 경우 바로 빈객체를 주입받으면 되는 간단한 구성방식에 비해 Redis의 경우 redisTemplate을 구성하고 여기에 redis연결 정보 및 Value값을 객체로 역직렬화하기 위한 Mapper 정보 등을 등록해주어야 한다.
@Bean
public RedisTemplate<String, AttackLog> attackLogRedisTemplate() {
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.registerModule(new JavaTimeModule());
RedisTemplate<String, AttackLog> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(
new Jackson2JsonRedisSerializer<>(objectMapper, AttackLog.class)
);
return template;
}RedisItemReader/Writer의 경우 chunk 지향처리의 논리객체 파이프라인을 이해하는 것이 사실상 핵심 요소이다.
Chunk → ItemWriter.write(List<AttackLog>)
↓
for (AttackLog item)
↓
itemKeyMapper(item) // AttackLog → String
↓
redis key = "attack:{id}"
↓
Redis DEL keyProcessor로부터 Writer는 AttackLog라는 객체를 전달받고, itemKeyMapper를 통해 key값을 구성, 이에 대한 Value값을 Processor로부터 받은 객체로 구성한다.
참고로,
public RedisItemWriterBuilder<K, V> redisTemplate(RedisTemplate<K, V> redisTemplate) {
this.redisTemplate = redisTemplate;
return this;
}
/**
* Set the {@link Converter} to use to derive the key from the item.
* @param itemKeyMapper the Converter to use.
* @return The current instance of the builder.
* @see RedisItemWriter#setItemKeyMapper(Converter)
*/
public RedisItemWriterBuilder<K, V> itemKeyMapper(Converter<V, K> itemKeyMapper) {
this.itemKeyMapper = itemKeyMapper;
return this;
}RedisItemWriterBuilder에서 제공하는 itemKeyMapper는 위와 같이, Converter를 통해 Key값(본 로직에서는 String 형태)을 구성하고 Processor로부터 받은 Value를 write(혹은 delete)할때(redis set) 활용하게 된다.
chunk 지향처리에서 위와 같은 논리적 파이프라인 및 세부 진행과정은 아래에 별도 기술하며, 구성에 대한 것은 이걸로 마치겠다.
./gradlew batch:nosql:bootRun --args='--spring.batch.job.name=aggregateHackerAttackWriterJob' 이 RedisItemWriter Job을 실행해보면

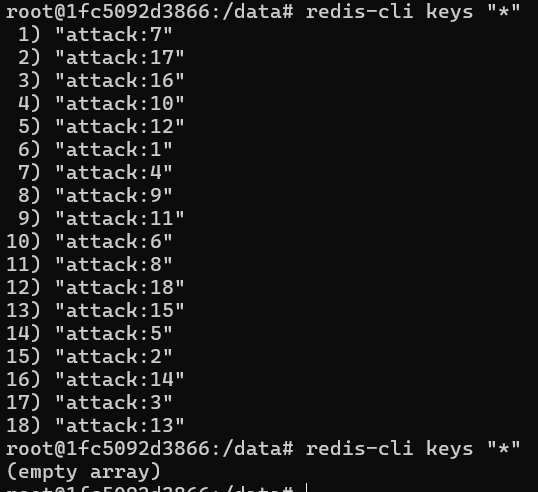
위와 같이 정상적인 batch job 실행과 데이터 삭제(delete) 결과를 확인할 수 있다.
참고. Chunk 지향처리의 유형 2가지
Batch job은 위에서 살펴보았던 것처럼 Reader-Processor-Writer로 이어지는 논리적 파이프라인이 매우 중요하다.
즉, reader에서 반환하는 객체와 processor에서 전달받는 객체 등의 파이프라인이 일치해야한다는 점이다.
다만, RedisReader/Writer의 경우 Processor로부터 받은 객체를 그대로 활용한다기보다는, 객체를 통해 key값을 별도 생성하는 논리적으로(상대적으로) 느슨한 결합의 처리 특성을 지닌다.
- 논리적 파이프라인 동일성 모델
mongo외 일반 RDB의 경우 chunk 타입 안정성이 강제되며 파이프라인이 철저하게 준수, 특히 전달하는 객체를 그대로 활용하여 영속화한다.
- Side-effect / Command 모델
반면 redis의 경우 논리적으로 느슨한데, 전달받은 객체를 그대로 활용하지는 않고 그 정보를 바탕으로 key값을 추출하는 등의 매개적인 작업이 존재한다.
위와 같이 두가지 모델을 바탕으로 chunk 지향처리를 이해하는 것이 좋을 것이다.
참고. RedisItemWriter의 세부과정
RedisItemWriter는 Redis Key 타입(현재는 String 기본제공) 및 Processor로부터 받은 Value 타입을 기준으로, 아래와 같은 제너릭을 제공한다.
RedisItemWriter<K, V>| 제네릭 | 의미 | 지금 코드에서 |
|---|---|---|
K | Redis Key 타입 | String |
V | Chunk로부터 전달받는 Item 타입 | AttackLog |
따라서, keyMapper에서 Object(target class)를 전달받은후에, 반드시 Key type인 String 형태로 변환해주는 과정이 반드시 필요하다.
template.setConnectionFactory(redisConnectionFactory);
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(
new Jackson2JsonRedisSerializer<>(objectMapper, AttackLog.class)
);이로 인해 redisTemplate의 keySerializer와 valueSerializer 구성이 필요한 것이고, job에 따라 target class가 달라지기 때문에 이에 맞는 redis value serializer 구성이 중요하다.
그 후 최종적으로 write할때는 delete 옵션에 따라 삭제 및 덮어쓰기 과정이 이루어진다.
public class RedisItemWriter<K, V> implements ItemWriter<V> {
private RedisTemplate<K, V> redisTemplate;
private Converter<V, K> itemKeyMapper;
private boolean delete = false;
@Override
public void write(List<? extends V> items) {
if (delete) {
delete(items);
} else {
write(items);
}
}
}만약 delete 호출할 경우,
redisTemplate.delete("attack:1");이와 같이 key값을 바탕으로 내부적으로 redis 명령을 전송하는 과정을 수행하며,
public Boolean delete(K key) {
byte[] rawKey = keySerializer.serialize(key);
return doWithKeys(connection -> connection.del(rawKey));
}최종적으로 DEL 명령을 redis에 전송하여 데이터 삭제를 한다.
DEL attack:1반대로 delete = false일 경우, 내용 갱신을 시도하는데 이때 내부적으로 redisTemplate의 opsForValue을 사용하고, 매개변수인 key와 value를 각각 keyMapper/Value값으로 전달받아 최종적으로 set 명령어를 redis에 전송한다.
protected void write(List<? extends V> items) {
for (V item : items) {
K key = itemKeyMapper.convert(item);
redisTemplate.opsForValue().set(key, item);
}
}SET attack:1 {json serialized AttackLog}그렇기에 redisTemplate 설정은 중요한 포인트가 된다는 것을 기억하자.
6. 결론
RedisItemReader/Writer는 이처럼 다른 batch job 구성과는 달리, Redis의 자료구조, key Serializer, value Serializer와 같은 세부적인 환경설정 사항까지 모두 전반적으로 이해를 한 상태에서 구현해주는 것이 좋다는 생각이 들게되는 컴포넌트로 판단된다.
단순히 "제공해주는" 컴포넌트 사용이 아닌, 논리적 흐름 및 파이프라인을 이해하고 구성하는 것이 중요한 것을 보여준 이번 내용이 아닌가 싶다.
정확한 이해와 논리적 흐름을 살펴보면서 Spring Batch에 대해 넓고 깊게 이해하는 태도가 항시 필요하다고 보여진다.
