[개발지식] Web Application의 상호보완적 Eventually Consistency #17 - Spring Batch Remote Executing(with REST API)
개발지식
1. 개요
Spring job은 #16에서 살펴보았듯이, 보통은 batch 모듈의 jar 생성 후, 해당 jarfmf CLI(커맨드라인)으로 실행하는 방법으로 운용한다.
물론 이 커맨드라인의 입력은, 금융권 기준, 보통 batch 도구가 따로 존재하여 jar를 등록하거나 모듈 FQCN을 입력해주면, 해당 파일 혹은 java로직을 실행하는 방식으로 이루어진다.
하지만, Spring batch의 실행은 때와 장소를 가리지 않는다.
다시 말해, CLI를 통한 실행 이외에도 원격 Web을 통한 제어, 특히 REST API를 호출하여 JobLauncher, JobOperations를 활용한 Remote한 Job Executing이 가능하며, 더 나아가 필요 시 Job실행을 중지하고 재시작까지 할 수 있는 세밀한 제어방식을 제공하여준다.
이에 대한 과정을, JobLauncher를 통한 remote job executing(REST API를 통한 원격실행), JobOperator를 통한 Job의 중지 및 재시작 관리, Job 중지 및 재시작 시 이전 상태의 복원 과정(Spring batch의 상태 저장 및 복원)의 일련의 흐름으로 각각 분석을 해보고자 한다.
먼저, spring batch의 entryPoint를 cli가 아닌 web HTTP요청에 의한 진입으로 설정하기 위해, web mvc를 활용하기 위한 의존성을 먼저 설정해주도록 한다.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
}참고로 나의 경우 프로젝트를 서브모듈(MSA) 형태로 구성해주었기 때문에, root project에 공통으로 필요한 의존성을, sub project에 해당 프로젝트에서만 필요한 의존성을 구성해주었으며, 이 sub project에 대한 의존성이 위와 같다.
더불어, application 실행시 batch 자동 실행을 방지하기 위해
batch:
job:
enabled: falsebatch:job:enabled 설정을 false로 해주도록 한다.
@ConditionalOnProperty(prefix = "spring.batch.job", name = "enabled", havingValue = "true", matchIfMissing = true)
public JobLauncherApplicationRunner jobLauncherApplicationRunner참고로, JobLauncherApplicationRunner를 실행하는 Condition은 위와 같이, application.yml의 spring.batch.job.eanbled 설정을 기반으로 판단이 된다.
이 값이 true라면 자동으로 실행, false라면 application 실행 시 자동으로 실행하지 않는다.
이 의미는, spring batch에 대한 application sever를 띄우고, rest api를 통한 선별적 실행만을 spring batch 실행의 전제로 설정하겠다는 의미이다.
2. JobLauncher - Spring batch 원격 제어 및 실행
이제 본격적으로 REST API 기반의 spring batch 원격 실행 및 제어를 할 수 있도록 그 과정을 살펴보도록 하겠다.
먼저, application 도메인에서 api를 호출하여 spring batch job을 실행할 수 있도록 web mvc를 하나 생성한다.
이때 중요한 것은, 원격으로 job을 실행할 경우, application 내부가 아닌 jobRegistry에서 실행할 job을 탐색해야 한다는 점이다.
job = jobRegistry.getJob(jobName); //from jobRegistry여기서 찾은 job 정보를
JobParameters jobParameters = new JobParametersBuilder(jobExplorer)
.getNextJobParameters(job)
.toJobParameters();이와 같이 jobExplorer, JobParametersBuilder를 활용한 빌더 패턴의 NextJobParameters의 매개변수로 전달한다.
일전에 살펴보았듯이, getNextJobParameters를 활용하여 이전에 실행한 job 정보를 가져오거나, 새롭게 생성하여 최종적으로 jobParameters 객체로 변환한다.
이 jobParameters를 job을 실행하기 위한 매개변수로 전달하여,
JobExecution execution = jobLauncher.run(job, jobParameters);위와 같이 최종적으로 jobLauncher가 job을 실행할 수 있도록 JobExecution 정보를 구성해주었고,
return ResponseEntity.ok("Job launched with ID: " + execution.getId());이후 실행한 jobExecution의 execution id 정보를 추출하여 ResponseEntity로 구성, 반환하게 된다.
참고로 JobLauncherApplicationRunner가 spring batch를 실행하여, 내부적으로 jobLauncher.run을 실행하는 전체적인 과정이 상당히 비슷한 흐름으로 이루어짐을 확인할 수 있다.
CLI를 통한 localJob, web api를 통한 JobRegistryJob 모두 동일한 컴포넌트, 동일한 엔진으로 사용되기에 가능한 일이다.
다시 한번 정리하자면,
- JobLauncher : job 객체와 jobParameters 정보를 매개변수로 받아, 실제 job의 "실행"을 담당하는 Job Squad의 출발점이다(launcher.run).
- JobExplorer : spring batch 메타데이터에 대한 탐색기로, 메타데이터 전반에 걸친 정보를 깊이 있고 폭넓게 조회, 추출할 수 있는 컴포넌트이다. jobParametersBuilder와 함께 사용하여, 이전에 실행한 이력을 바탕으로 JobParameters를 생성하거나, 신규 구성한다.
- JobRegistry : 로컬 이외, web 실행으로 진행할 job을 관리하는 중앙 저장소이며, 해당 저장소에 등록된 job들을 조회가능하다.
결국 RunSquad를 내부적으로 어느정도 구성하여, 이를 외부에서 실행할 수 있는 진입점을 마련해놓은 것이다.
이때 중요한 구성이 또 하나 있는데, TaskExecutorJobLauncher 구현체는 Spring batch에서 사용하는 기본적인 구현체로,
@Bean
public JobLauncher jobLauncher(JobRepository jobRepository) throws BatchConfigurationException {
TaskExecutorJobLauncher taskExecutorJobLauncher = new TaskExecutorJobLauncher();위와 같이 DefaultBatchConfiguration에서 jobLauncher 빈객체 등록 시, 해당 타겟 클래스를 TaskExecutorJobLauncher로 기본 반환해주는 기본 구현체이다.
이 구현체는
taskExecutorJobLauncher.setTaskExecutor(getTaskExecutor());위와 같이 taskExecutor를 getTaskExecutor로 부터 가져오는데, 이를
protected TaskExecutor getTaskExecutor() {
return new SyncTaskExecutor();
}SyncTaskExecutor라는 동기방식의 executor를 사용하게 된다. 즉, 이 SyncTaskExecutor를 사용하게된다면 말그대로 web 요청을 한 스레드는 동기방식에 의해, spring batch의 결과를 반환받을때까지 대기하게 된다.
하지만 대규모데이터를 처리하는 spring batch 특성상, 1개의 job을 끝마치기 위해서는 엄청난 시간이 소모될 수 있기에, 반드시 클라이언트가 요청 후 이를 기다리지 않고 다음 요청을 실행하는 비동기 방식의 executor를 사용해야만 한다.
이를 위해,
@Configuration
public class BatchCustomizedConfiguration {
@Bean
@BatchTaskExecutor
public TaskExecutor taskExecutor() {
SimpleAsyncTaskExecutor simpleAsyncTaskExecutor = new SimpleAsyncTaskExecutor();
return simpleAsyncTaskExecutor;
}
}위와 같이 동기식 executor가 아닌, 비동기식 executor를 반환하도록 빈객체를 customized하면 된다.
이에 따라, BatchTaskExecutor의 어노테이션에 의해 taskExecutor 빈객체를 등록할 수 있고, Spring Boot가 이를 감지하여 taskExecutorJobLauncher의 구현체를 동기식 executor가 아닌 위에서 등록한 비동기식 customized executor로 대신 등록한다.
./gradlew batch:remote:bootRun --args='--spring.batch.job.name=brutalizedSystemRESTAPIJob'이후 spring application을 실행하고, 테스트해보자.
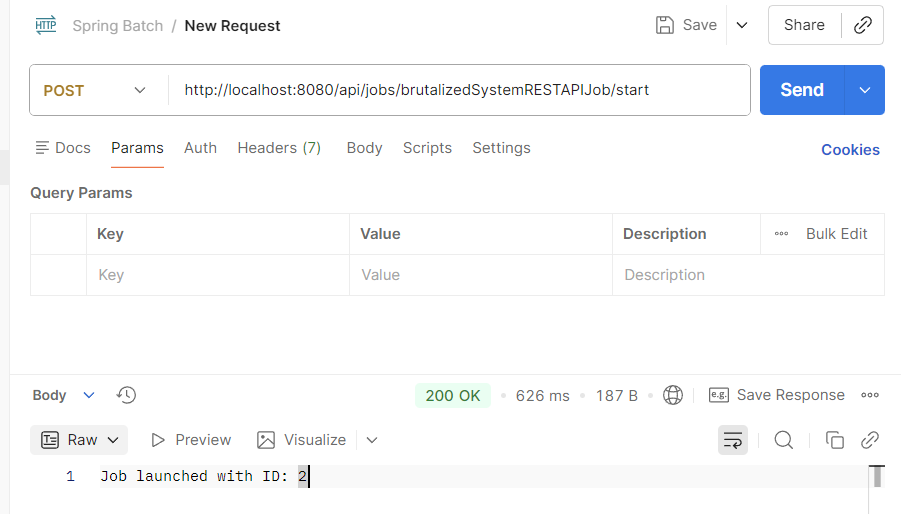
Response가 정상적으로 반환되는 것을 확인할 수 있다.
참고로, job을 한번 실행한 이력이 있고, drop schema 설정을 주석처리해준 상태에다가 JobBuilder에 .incrementer(new RunIdIncrementer()) 설정을 해주었기에(중복 실행 가능) Job Id가 1이 아닌 2로 표기된 상태이다.
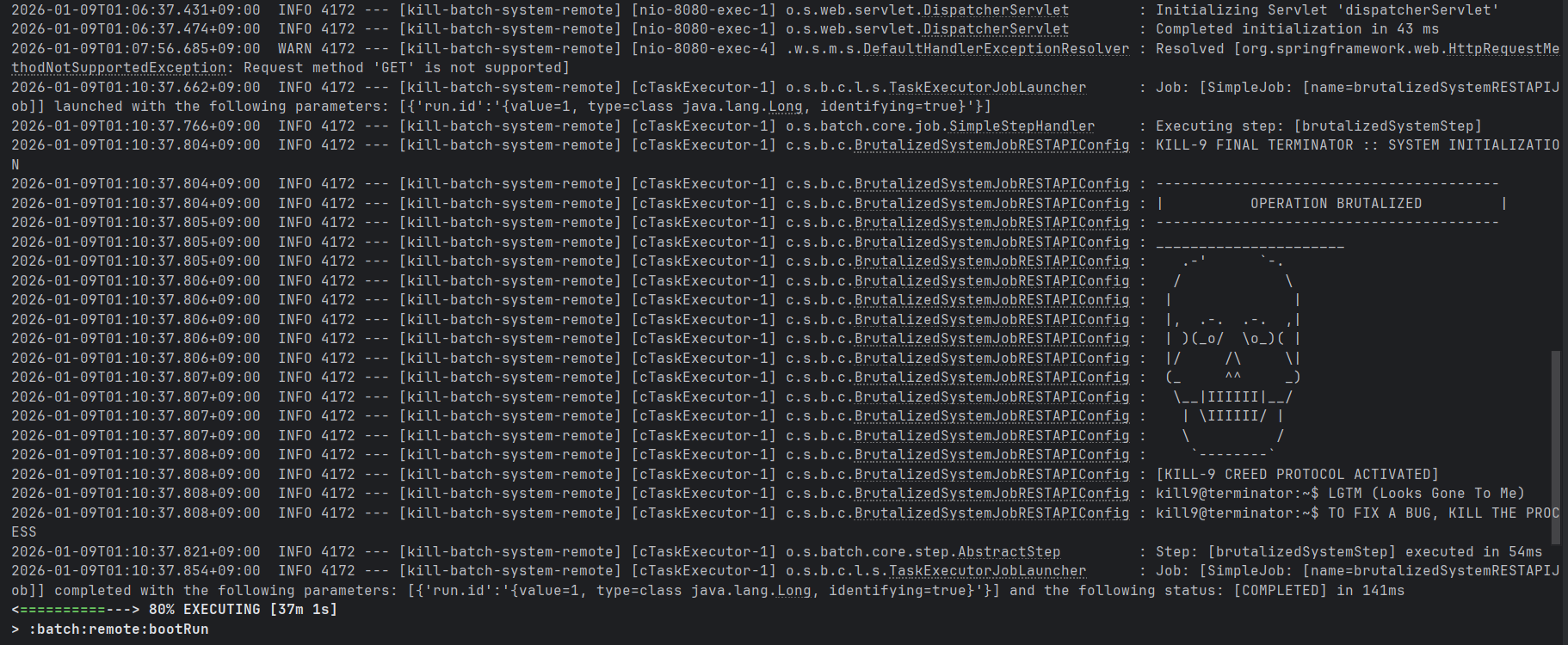
application에서는 job을 실행해주었음을 확인할 수 있고, 이 job 실행 후에도 application의 동작은 유지된다.
jobLauncher를 활용하여 기본적인 batch 원격 실행은 완료하였으나, 실행 중인 job을 중지하거나 실패한 job을 재시작하고 실행상태를 모니터링하는 등의 훨씬 더 복잡하고 폭넓은 제어가 반드시 요구된다.
이를 위해, 기존 jobLauncher 기반 로직에, JobRepository 및 JobExplorer 컴포넌트 등을 덧붙힌 복잡한 로직을 구성해주어야 하며, 이에 대한 전략적 인터페이스로 JobOperator를 제공한다.
참고. Web / BatchOnly
오해할 수 있는 부분에 대해 바로잡고 넘어가자.
bootRun은 batch 실행에 대한 명령이 아닌, spring application 실행에 대한 명령어이다.
정말 간단하게 말하면, start-web 의존성이 없다면, JVM 백그라운드에서 실행할 WAS 및 이에 따른 Spring containter 관련 설정을(Servlet 등) 작동할 수 없고, Application 측에서는 이를 web 프로젝트라고 인식하지 못할 뿐더러, JVM에서 동작하는 non-daemon-thread 등이 존재하지 않아 application 실행 후, spring batch 실행 및 종료에 맞춰 application 같이 종료된다.
spring.batch.job.enabled 구성은 JVM 종료와는 별개의 사안이다. Application 실행 시 batch를 실행하느냐, 하지 않느냐에 대한 트리거 차이일 뿐이다.
web 의존성을 추가했느냐, 추가하지 않았느냐가 먼저 출발점이 되어야 한다.
이 경우, tomcat이 가동되고 spring boot의 web 자동설정이 활성화되는데, 이때 유의해야할 점은 spring-boot-start-web은 "웹서버 띄우세요" 명령이 아닌, classpath에 web 관련 라이브러리에 대한 내용을 그대로 등록, 의존성을 추가하는 것이다.
이때,
spring-web
spring-webmvc
spring-boot-starter-tomcat이 의존성들이 등록, classpath를 탐색하였을때 Servlet 클래스들을 감지, 이에 따라 spring boot web application 관련 자동설정이 시작되고 이 과정에서 내장 tomcat으로 web server를 띄우게 된다.
이 tomcat은 JVM을 잡고 있는 non-daemon-thread이자 main thread로, tomcat이 살아있다면, 즉 application이 종료되지 않는다면 JVM은 죽지않는다.
이를 이해하고나서 spring.batch.job.enabled 설정을 살펴보면 되겠다.
만약, web 설정을 활성화 한 이후
- enabled true -> app 실행, 이에 따라 batch도 실행
- batch 종료 시 thread 남아있음, 실행 유지 - enabled false -> app만 실행.
반대로, web 설정을 비활성화하였다면,
- enabled true -> app 실행, 이에 따라 batch도 실행
- web 설정이 없기에 실행 daemon(tomcat 등) 없음, batch 종료 시 app도 같이 종료 - enabled false -> app 실행, batch 실행하지 않음, 실행 시도 후 곧바로 종료

참고로, bootRun을 하게되면 우리가 평소 Run버튼을 누른 것과는 다소 다른 로그를 보이는데, 실제 동작은 버튼을 누른 상태와 동일하다.
즉, 서버를 띄운 상태로, 기존에 봐왔던 Run 진행상태는 UI형태이고 이는 command line에 나타난 상태의 차이일 뿐 상태는 동일하다. 다소 생소할 뿐이다.
3. JobOperator/JobExplorer - Spring batch 원격 중지 및 재시작
위에서 살펴본 원격실행만으로는 부족하고, 실행중지, 실행이력 파악, 모니터링 등 복잡한 상태제어를 위해 Spring batch 측에서는 jobOperator 인터페이스라는 하나의 전략적 인터페이스를 제공한다.
단순 실행을 넘어, Job의 시작/재시작/중지와 더불어, Job/Step의 운영 관련 모니터링 데이터 등, Operator라는 말마따나 job에 대한 전반적인 정보 및 실행정보를 제공해주는 기능, 이러한 운영을 손쉽게 할 수 있는 제어방안을 제공해준다.
이 JobOperator를 활용하여 Spring batch 제어를 어떻게 진행할 수 있있을까?
먼저, jobLauncher가 아닌 jobOperator를 통한 job 실행이 가능하다.
Long executionId = jobOperator.start(jobName, jobParameters);이 역시 launcher와 마찬가지로, job이름과 jobParameter에 대한 매개변수 객체를 구성해주어 전달해주도록 한다.
Properties jobParameters = new Properties();
jobParameters.setProperty("run.timestamp", String.valueOf(System.currentTimeMillis()));또한, jobExecutionId에 해당하는 job의 실행을 중지할 수 있으며, 실제 중지에는 시간이 많이 소요되기에 api 전달여부에 대해서만 반환받을 수 있다.
boolean stopped = jobOperator.stop(executionId);마지막으로 jobExecutiodId에 해당하는 job을 재시작할 수 있다.
Long newExecutionId = jobOperator.restart(executionId);일전 재시작 로직을 살펴본 바와 같이, 이전 실행의 executionContext를 기반으로 중단지점을 찾아 해당 chunk 단위 지점부터 다시 job을 진행한다.
이때, 반환값은 새롭게 생성된 job execution id이다.
추가적으로 jobExplorer을 통해서 job 내역 확인이 가능하다.
아래와 같이 job 실행이력을 조회하고,
List<JobExecution> executions = jobExplorer.getJobExecutions(jobInstance);JobExecution 객체 리스트를 통해 jobExecution 정보를 추출하여 job 실행상태 및 이력에 대한 정보를 확인할 수 있다.
for (JobExecution execution : executions) {
executionInfo.add(String.format("Execution ID: %d, Status: %s",
execution.getId(), execution.getStatus()));
}이 상태에서 bootRun 실행 후(혹은 application Run), api 호출 시
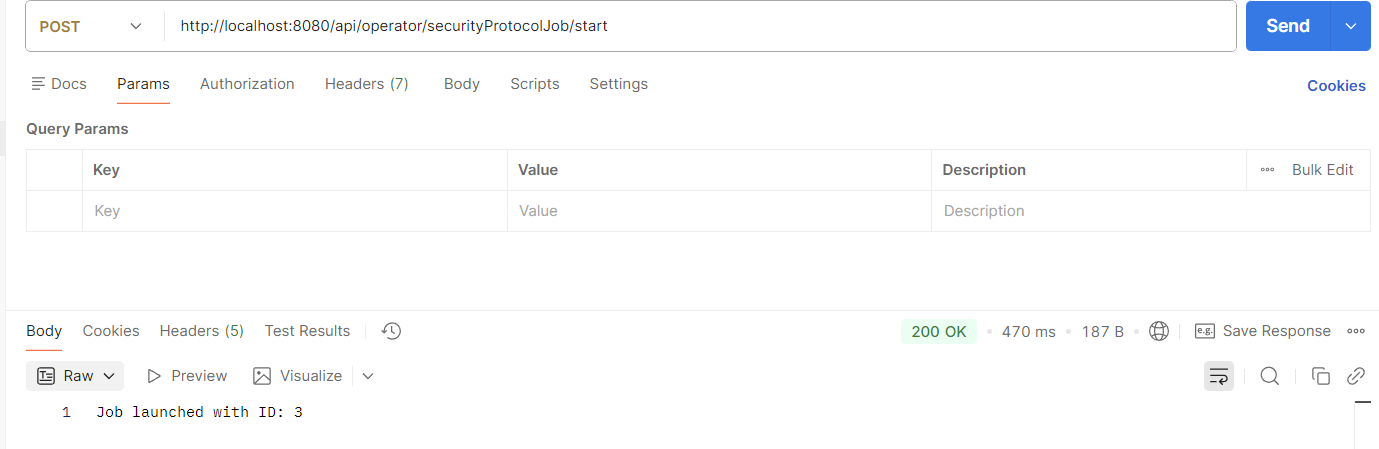
위와 같이 일전과 동일하게 정상적인 200 status를 반환하였으며,

여기서는 기술하지는 않았으나, AbstractItemCountingItemStreamItemReader를 상속한 ItemReader의 open을 오버라이드한 메서드에 작성한 로직을 실행한 후, doRead()를 실행하였다.
참고로 Reader의 doRead()의 경우 Step측에서 호출하는 Reader.read() 내부에서, 실제 dataSource로부터 data를 읽어오고 이를 Processor 혹은 Writer에게 전달하는 로직으로, 사용자가 직접 구현할 수 있는 부분이다.
사족은 여기서 충분하고, 다음 단계는 jobOperator.stop을 진행하는 중지 api를 호출해보도록 하자.
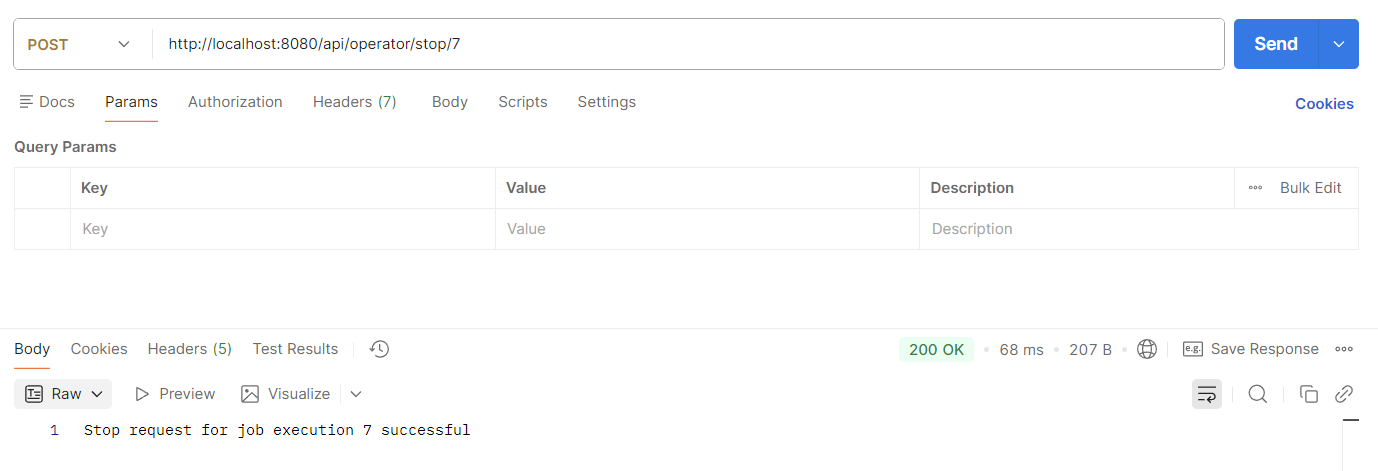
실행한 job에 대해 성공적으로 중지요청을 보냈다는 상태를 확인하였다.
로그와 메타데이터를 확인해보자.
중지를 호출하였을때 나타나는 양상은 두가지가 존재한다.
- 첫째, Reader가 reader를 어느정도 진행이 된 상태에서의 중지

stop api 호출 후 시스템을 최종 중지하기까지 어느정도 시간이 소요될 것으로 보였지만, 실제로 예상을 상회하는 시간이 더 소모되었음을 확인할 수 있었다.

위와 같이 첫번째 chunk 처리에 대해서는 이미 진행을 한 상태였고, 그 이후 job에서 중지 interruption이 발생하였음을 감지하고 job 실행을 중지한다.
- 둘째, Reader 초반에서의 중지
Reader를 실행한 시점 중 매우 극초반(거의 시작하자마자)에 stop을 하여도, 일단 첫번째 chunk에 대한 read는 위의 경우처럼 일단 그대로 진행하고, 두번째 chunk의 경우 read를 시작하기 전에 중지한다.
아무래도 step.read를 호출한 로직 자체는 일단 진행하지만, 그 이후의 처리에 대해서는 stop 명령을 수용하는 것으로 생각이 들게 된다.
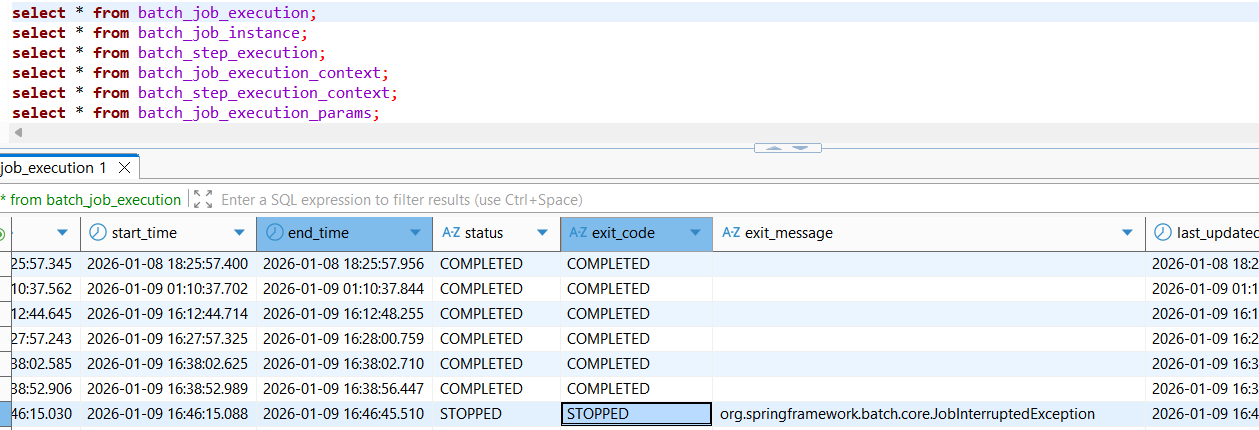
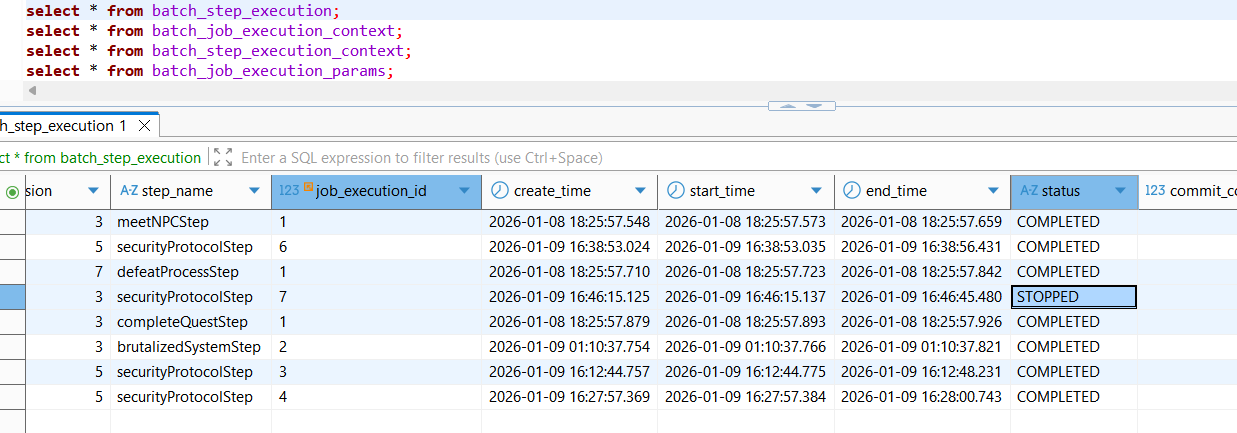
위 두가지 경우에 상관없이, 최초 execution의 exit status 상태는 STOPPING, exit code의 상태는 UNKNOWN이었다. 즉, 중지중인 상태였다.

최종적으로 중단요청을 받은 후, job을 완전하게 종료된 상태에서는 status, exit code 모두 "STOPPED" 상태로 변경되었다.
restart를 진행해보자.
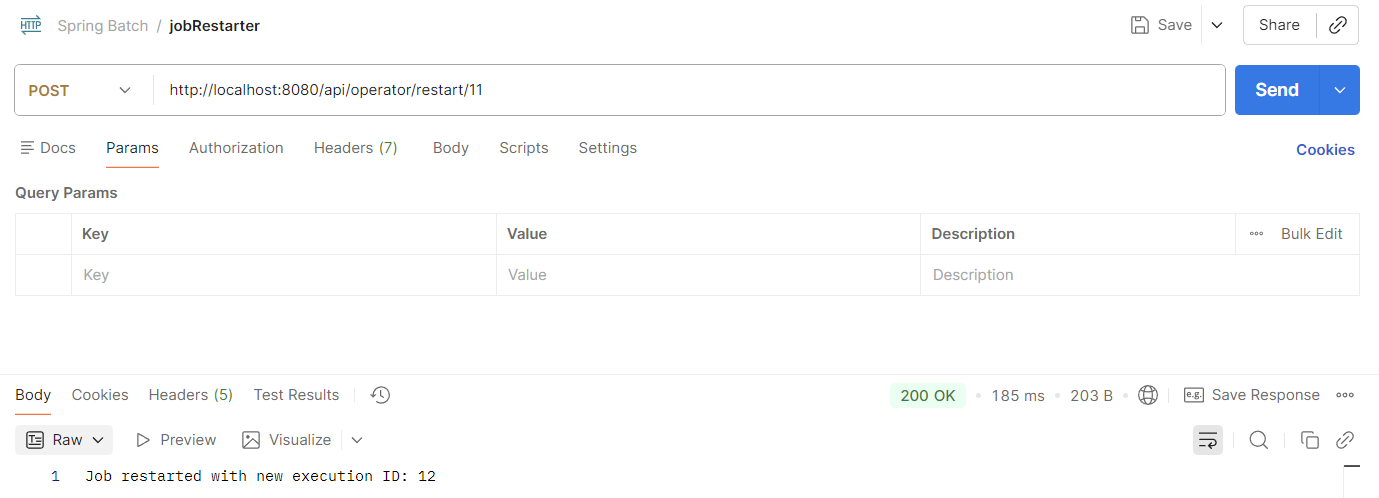
위와 같이 일전에 중단한 execution id인 11번에 대해 restart를 진행하면, 새로운 execution id인 12번이 반환되는 것을 확인할 수 있으며,
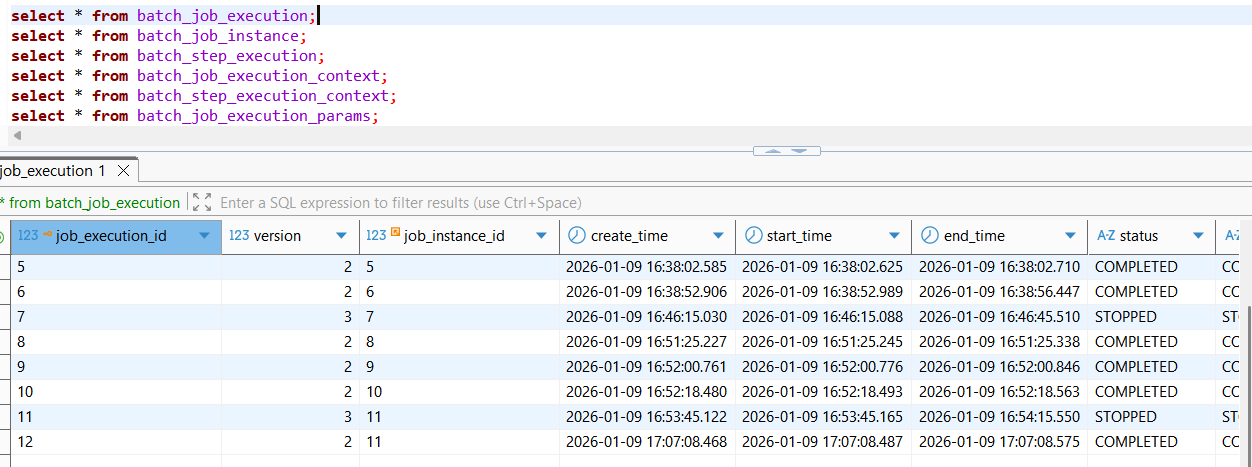
job instance id - 11, job execution id - 11의 이전 실행상태내역에서 job instance id - 11의 동일한 job에 대하여 job execution id - 12라는 새로운 execution을 생성하여 COMPLETED의 온전한 종료까지 "동일하면서도 새로운 job을" 재시작하였음을 확인할 수 있다.
Reader에서, contextKey의 분기조건을 "STARTED" 감지 조건으로 추가해준 부분이 있는데,
if (executionContext.containsKey(getExecutionContextKey("started"))) {
log.info("====================== Execution Context contains 'Started' ======================");
log.info("Protocol Action Retry is Detected.");
log.info("System would be Retried! \n");이 조건을 따라 진행하게되어, 두번째 청크부터 재시작함에 따라 아래와 같은 로직을 확인할 수 있다.
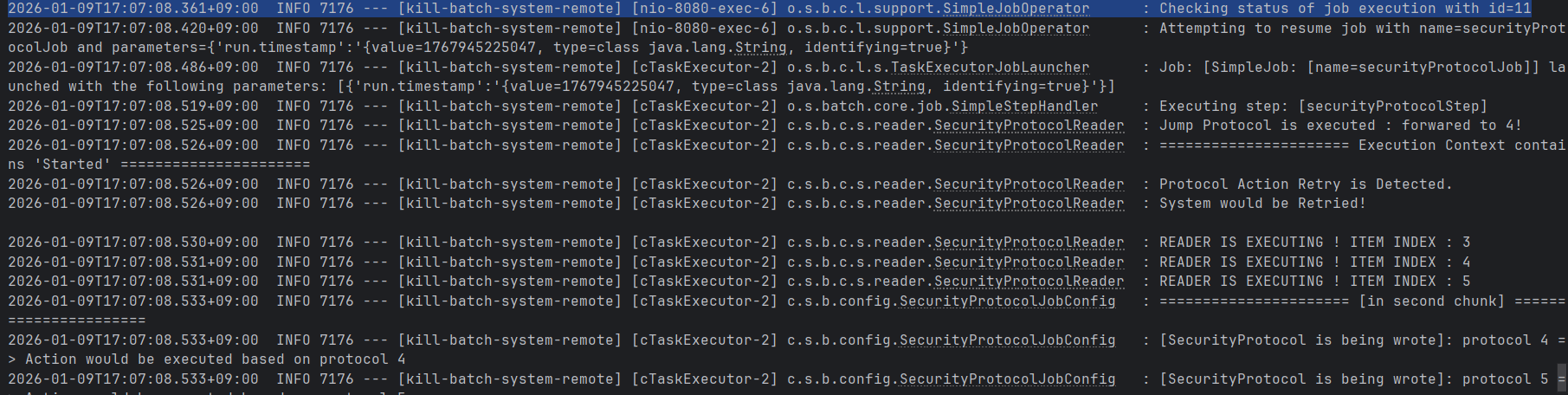
즉, 먼저 job execution id가 11인 내역에 대해 먼저 상태를 살펴보고, 이전에 첫번째 청크까지 진행되었으므로 현재 잔존하는 item index는 2일 것이다.
이에 따라 jumpToItem을 호출하면서, 이전 상태내역인 index = 2를 추출, 다음 청크의 시작점인 index = 3을 읽기 시작한다.
그후, job을 재시작하되 execution id = 12인 상태로 시작하게 되고, Reader를 진입하는 시점에 open을 호출하면서 위에서 작성한 재시작 감지 로직을 그대로 진행하게 된다.
이후 두번째 청크인 item index = 3부터 read시작, 최종적으로 두번째 청크에 대한 write까지 마친 후에 job을 완전히 종료한다.
즉, jobOperator > open > jumpToItem > read > write 순으로 진행이 이루어진 것을 확인할 수 있다.
4. Spring batch 상태저장 및 이전상태의 복원 과정
이처럼 이전상태내역을 저장하고 이를 기반으로 다음 chunk부터 batch job을 진행할 수 있었던 이유는, 기본적으로 매 청크처리마다, AbstractItemCountingItemStreamItemReader의 update를 진행하면서 이전 상태내역을 저장해두었기 때문이다.
@Override
public void update(ExecutionContext executionContext) {
executionContext.put(getExecutionContextKey("started"), true);
super.update(executionContext);
}위에서 청크처리시 contextKey를 started로 지정해두었기때문에, restart할때 해당 context의 key를 포함하는지 여부 확인 및 해당 지점(논리적으로는 청크 단위)부터 job을 진행할 수 있게 된다.
재시작시, jobOperator가 open을 먼저 시도했는데,
@Override
public void open(ExecutionContext executionContext) throws ItemStreamException {
super.open(executionContext);
if (executionContext.containsKey(getExecutionContextKey("started"))) {
log.info("====================== Execution Context contains 'Started' ======================");
log.info("Protocol Action Retry is Detected.");
log.info("System would be Retried! \n");
} else {
log.info("====================== Execution Context does not contain 'Started' ======================");
log.info("Protocol Action is Executed in normal status. \n");
}
}실제로도 executionContext로부터 이전에 저장된 위치를 탐색, 읽어오고 이를 기반으로 jumpToItem을 통해 "이전에 마지막으로 읽었던 위치"를 읽어온다.
4-1. 중지 과정 - SimpleJobOperator, TaskletStep
JobOperator.stop을 호출하면, 내부적으로 어떠한 과정이 일어나는지 세부적으로 살펴보도록 해보자.
boolean stopped = jobOperator.stop(executionId);일전에, Spring batch 환경구성 시 BatchAutoConfiguration이 동작하고, DefaultBatchConfiguration를 상속한 SpringBootBatchConfiguration의 빈객체 등록이 일어나면서 batch 환경구성이 자동적으로 일어난다고 하였다.
이 DefaultBatchConfiguration 내부에서
@Bean
public JobOperator jobOperator(JobRepository jobRepository, JobExplorer jobExplorer, JobRegistry jobRegistry,
JobLauncher jobLauncher) throws BatchConfigurationException {
JobOperatorFactoryBean jobOperatorFactoryBean = new JobOperatorFactoryBean();
jobOperatorFactoryBean.setTransactionManager(getTransactionManager());
jobOperatorFactoryBean.setJobRepository(jobRepository);
jobOperatorFactoryBean.setJobExplorer(jobExplorer);
jobOperatorFactoryBean.setJobRegistry(jobRegistry);
jobOperatorFactoryBean.setJobLauncher(jobLauncher);
jobOperatorFactoryBean.setJobParametersConverter(getJobParametersConverter());
try {
jobOperatorFactoryBean.afterPropertiesSet();
return jobOperatorFactoryBean.getObject();
}
catch (Exception e) {
throw new BatchConfigurationException("Unable to configure the default job operator", e);
}
}위와 같이 jobRepository, jobExplorer를 비롯한 필요 컴포넌트들을 factoryBean을 통해 주입하여 jobOperator를 구성한다.
jobOperator를 필요로한다면,
private SimpleJobOperator getTarget() throws Exception {
SimpleJobOperator simpleJobOperator = new SimpleJobOperator();
simpleJobOperator.setJobRegistry(this.jobRegistry);
simpleJobOperator.setJobExplorer(this.jobExplorer);
simpleJobOperator.setJobRepository(this.jobRepository);
simpleJobOperator.setJobLauncher(this.jobLauncher);
simpleJobOperator.setJobParametersConverter(this.jobParametersConverter);
simpleJobOperator.afterPropertiesSet();
return simpleJobOperator;
}위와 같이 JobOperatorFactoryBean에서 getTarget 메서드를 호출하여, SimpleJobOperator라는 구현체를 전달하는 방식으로 이루어진다.
따라서 jobOperator.stop을 호출하기 위해서는 SimpleJobOperator 구현체의 stop 메서드를 호출해야한다.
이후,
JobExecution jobExecution = findExecutionById(executionId);입력받은 executionId를 매개변수로 하여, jobExecution 상태를 추출한다.
jobExecution.setStatus(BatchStatus.STOPPING);
jobRepository.update(jobExecution);해당 jobExecution 상태를 STOPPING(중지중)으로 변경하여, 이를 jobRepository를 통해 즉시 메타데이터로 반영한다.
위에서 살펴보았듯이, 중지요청을 보냈다면 즉시 중지하지는 않고 일단 job execution 기록에 "STOPPING"이 남겨두는 것이다.
이후의 실질적인 실행중지는 TaskletStep에서 맡아 처리하게 된다.
Step step = ((StepLocator) job).getStep(stepExecution.getStepName());
if (step instanceof TaskletStep) {
Tasklet tasklet = ((TaskletStep) step).getTasklet();
if (tasklet instanceof StoppableTasklet) {
StepSynchronizationManager.register(stepExecution);
((StoppableTasklet) tasklet).stop();
StepSynchronizationManager.release();
}
}이처럼, TaskletStep에서 tasklet 정보를 가져오고, 해당 tasklet이 Stoppable한지 판단, 이에 대한 이상이 없다면 해당 step에 대해 바인딩, 중지, 해제의 과정을 거친다.
result = new TransactionTemplate(transactionManager, transactionAttribute)
.execute(new ChunkTransactionCallback(chunkContext, semaphore));그 이후 transactionTemplate.execute를 실행하여, ChunkTransactionCallback의 doInTransaction을 진행하게 되고, 내부적으로 jobRepository의 정보를 추출하여 stepExecution 정보를 최종 update하는 것을 확인할 수 있다.
SimpleJobRepository의 update 메서드 중, stepExecution 정보를 매개변수로 받는 부분을 살펴보면 아래와 같다.
private void checkForInterruption(StepExecution stepExecution) {
JobExecution jobExecution = stepExecution.getJobExecution();
jobExecutionDao.synchronizeStatus(jobExecution);
if (jobExecution.isStopping()) {
logger.info("Parent JobExecution is stopped, so passing message on to StepExecution");
stepExecution.setTerminateOnly();
}
}
step execute를 진행하고, jobRepository update를 진행하는데, stepExecution 정보에서 상태정보가 isStopping인 것을 감지해버렸다.
이 실시간 상태감지는 jobExecutionDao.synchronizeStatus를 통해 정보 모니터링이 이루어지기에 가능하다.
이후, jobExecution 정보를 확인하여 STOP요청이 왔다는 사실을 알아챈다. 이 과정이 checkForInterruption을 통해 진행이 되는 것이다.
그후, stepExecution 프로퍼티 중,
public void setTerminateOnly() {
this.terminateOnly = true;
}위와 같이 terminationOnly 필드를 true로 설정한다.
이후, taskletStep의 doInChunkContext에서, 해당 청크를 일단 실행한 후에
interruptionPolicy.checkInterrupted(stepExecution);stop요청과 같은 interrupted 상태가 발생하였는지 확인한다.
private boolean isInterrupted(StepExecution stepExecution) {
boolean interrupted = Thread.currentThread().isInterrupted();
if (interrupted) {
logger.info("Step interrupted through Thread API");
}
else {
interrupted = stepExecution.isTerminateOnly();
if (interrupted) {
logger.info("Step interrupted through StepExecution");
}
}
return interrupted;
}ThreadStepInterruptionPolicy구현체의 해당 메서드를 살펴보면, 위와 같이 위에서 설정한 stepExecution의 isTerminateOnly 필드를 검사하게 되고, 해당 값이 true일 경우 Step이 interrupted 되었다는 로그를 출력하게 된다.

이로 인해 로그에 해당 내용을 출력하는 것을 확인할 수 있다.
로그를 살펴보면, AbstractStep의 execute를 진행하는 것을 알 수 있는데, step의 doexecute 실행 중 stop interruption이 발생하여, catch 로직을 진행하게 된다.
이때,
catch (Throwable e) {
stepExecution.upgradeStatus(determineBatchStatus(e));가장 먼저 stepExecution의 상태를 최종적으로 어떻게 변경할 것인지에 대한 내용이 들어가있다.
determineBatchStatus는, 함수 명에서도 추측할 수 있듯이,
private static BatchStatus determineBatchStatus(Throwable e) {
if (e instanceof JobInterruptedException || e.getCause() instanceof JobInterruptedException) {
return BatchStatus.STOPPED;
}
else {
return BatchStatus.FAILED;
}
}발생한 예외가 interruption의 형태라면 BatchStatus.STOPPED라는 상태를 반환해주는 것을 알 수 있다. 이에 따라, stepExecution의 상태는 STOPPED 상태로 최종 바뀐다. 다만 아직 반영은 하지 않는다.
그리고 그 이후에
exitStatus = exitStatus.and(getDefaultExitStatusForFailure(e));
stepExecution.addFailureException(e);stepExecution에 대해 최종 exit status를 STOPPED, exit message까지 해당 예외 클래스명으로 저장한다.
이후 SimpleStepHandler로 넘어가서, handleStep을 진행하게 되며
if (currentStepExecution.getStatus() == BatchStatus.STOPPING
|| currentStepExecution.getStatus() == BatchStatus.STOPPED) {
// Ensure that the job gets the message that it is stopping
execution.setStatus(BatchStatus.STOPPING);
throw new JobInterruptedException("Job interrupted by step execution");
}최종적으로 stepExecution이 STOPPING 혹은 STOPPED이라면, JobExecution상태를 STOPPING으로 설정하고, jobInterruption을 발생시킨다.
다시, abstractJob의 execute가 콜백되어,
catch (JobInterruptedException e) {
if (logger.isInfoEnabled()) {
logger.info("Encountered interruption executing job: " + e.getMessage());
}
if (logger.isDebugEnabled()) {
logger.debug("Full exception", e);
}
execution.setExitStatus(getDefaultExitStatusForFailure(e, execution));
execution.setStatus(BatchStatus.max(BatchStatus.STOPPED, e.getStatus()));
execution.addFailureException(e);
}jobExecution의 상태가 STOPPED로 설정되고,
jobRepository.update(execution);이 상태로 jobRepository를 통해 반영하여 최종 모든 jobExecution 정보를 메타데이터로 저장한다.
이 과정까지 진행한 후에, 모든 메타데이터에는 "STOPPED"라는 상태값만이 나타난다.
4-2. 즉시 중단의 함정 - 일관성 저해 및 낭비
위 로그를 살펴보면 알겠지만, spring batch는 stop 요청이 들어왔을때 그 상태를 바로 중단하지 않고, 일단 첫번째 청크를 완료한 이후에 중지한다.
spring batch의 설계적 사상이 담겨져있는데, 중지요청이 왔어도 해당 spring batch의 제어도메인이 비즈니스 측에 있을 수 있으므로 일단 해당 청크는 완료한 후, 청크처리가 완료되어 다음 청크로 넘어가는 시점에, spring batch 도메인으로 처리단계가 위임되는 순간 그때 비로소 작업을 중지시키는 것이다.
composite reader 등에서 살펴본 설계사상과 유사한데, 기본적으로 spring batch는 데이터 일관성을 철저하게 유지하고자 한다(모든 청크에 대해 write가 완료될때까지 commit을 하지않고 대기).
이 역시 마찬가지로, 일단 한번 시작한 처리에 대해서는 일단은 유지한다. 일관성 측면에서도, 더불어 굳이 롤백 혹은 버림으로써 발생하는 자원낭비까지 고려하여, 진행중인 청크에 대해서는 즉시 중단을 하지 않고 넘기게 된다.
참고로 KafkaItemWriter와 같이 중간 롤백이 불가능한 구현체도 있기에, writer 도중에 아예 롤백하는 것은 이러한 예외적인 컴포넌트로 인해 spring batch 측에서 제공하는 방법은 아니다.
4-3. 재시작
재시작 시, SimpleJobOperator의 restart를 호출한다.
JobExecution jobExecution = findExecutionById(executionId);
String jobName = jobExecution.getJobInstance().getJobName();
Job job = jobRegistry.getJob(jobName);
JobParameters parameters = jobExecution.getJobParameters();전달받은 job execution id를 통해, 이전에 실행한 jobExecution 내역 및 jobName, 이를 통한 RegistryJob 객체 등 launcher가 jobRun을 하는데 필요한 job, parameters 정보를 추출 및 생성한다.
return jobLauncher.run(job, parameters).getId();그리고 jobLauncher가 실행한 jobExecution id (long) 값을 반환한다.
5. 정리
JobOperator를 통한 원격 중지 및 재시작에 대해 정리하면 아래와 같다.
1) 중지 요청
- SimpleJobOperator.stop 호출
- jobExecution 상태가 STOPPING으로 변경
- 첫번째 청크 작업은 실행, 그 이후의 청크 작업에 대해 중지
2) 중지상태 감지 및 stepExecution 상태전파
- SimpleJobRepository에서 jobRepository.update(stepExecution)을 통해 STOPPING 상태를 반영
- 이 반영하는 과정 중 실시간 jobExecution 상태를 추출하여, execution 상태가 STOPPING일 경우 stepExecution의 terminationOnly = true로 설정
3) 중지
- stepExecution에서 terminationOnly 필드를 탐색하고 JobInterruptionException 발생
- SimpleStepHandler의 handlerStep에서 stepExecution을 확인하여 JobInterruptionException을 발생
- abstractJob의 excute 콜백 후, 내부적으로 jobRepository를 통해 해당 상태를 메타데이터로 저장(STOPPED)
6. 결론
Spring batch application 내부에서 실행하는 로컬 Job, web application을 실행하여 job 내역을 RegistryJob에 저장하여 이에 대한 web entry를 구성하고, rest api를 호출하여 job을 실행/중지할 수 있는 방법에 대해 폭넓게 분석해보았다.
이름만 들어도 흥미로운 주제였기에, 여느때처럼 힘들고 고된 여정이었지만 동시에 spring batch job을 더욱 세밀하게 제어할 수 있는 다양한 요소들에 대해 알 수 있었던 계기가 되어 귀중한 시간 될 수 있었던 것 같다.
하지만 더욱 세밀하게 job을 제어할 수 있다면 어떨까?
좀 더 유연하고, 정확하게 job을 제어할 수 있는 방법에 대해 더 고민하고 알아보자.
