[개발지식] Web Application의 상호보완적 Eventually Consistency #19 - Spring Batch의 사용효율 극대화 - 적합한 설계와 더불어 ThroughPut에 대한 고찰(with MultiThread)
개발지식
1. 개요
Spring Batch의 기본적인 컴포넌트들, 설계 및 구조, 사상에 대해 기초적인 적용역량을 함양하였다면, 이제부터는 spring batch의 사용효율을 어떻게 극대화할 수 있을까에 대한 내용을 고민해보는 단계로 진입한다.
Spring Batch의 사상에 부합하는 적합한 아키텍칭, 설계는 시스템의 온전한 운용, 지속가능성, 멈춤없는 처리에 집중한 부분이었다면, 이제는 처리량 그 자체에 대해 주목해보고자 한다.
Spring Batch 자체가 대규모 데이터를 타겟으로 가공하고, write하는 목적으로 이루어진 하나의 거대한 체계이기에, 구성도 중요하지만, 이러한 대규모 데이터를 효율적으로, 빠르게 처리하는 것도 못지 않게 중요한 key point가 되겠다.
아래의 내용들을 중심으로,
- multi Thread Step : 하나의 Step(Machine)을 다중 스레드로 처리량을 극대화
- Partitioning : 데이터 자체를 분산화, 파티셔닝하여 처리량 극대화
- Parallel Step : 다양한 Step을 한번에 동시에 처리하여 처리량 극대화
- Remote Chunking - Kafka(메시지 기반)의 외부 데이터 관리 체계를 활용하여, 처리환경의 규모를 최대화, 이를 통한 처리량 극대화
처리량을 높이고 Spring Batch의 효율성을 극대화할 수 있는지, 각각의 핵심 본질을 중심으로 단계적으로 분석하고 이해해보도록 하자.
2. 처리량 극대화 전략
spring batch의 구성도 중요하지만, 결국 대규모 데이터 처리속도를 조금이라도 보완하기 위해선 다중 스레드 및 다중 프로세스를 통한 처리량 보완이 필수적이다.
즉, 단일 스레드, 단일 프로세스로는 한계가 무조건적으로 발생할 수 밖에 없으며 이러한 처리량 극대화 전략을 위해 취할 수 있는 4가지 방안에 대해 분석해보고자 한다.
1) 멀티스레드 스텝 전략의 경우, 한 상태머신(Step)의 chunk에 대해 멀티스레드를 적용하여 처리량을 증가한다.
2) 파티셔닝의 경우, 배치잡 적용 대상 데이터의 구역을 논리적 분산(파티셔닝)하여 각 파티셔닝 별로 별도의 스레드 및 프로세스를 적용한다.
3) 병렬스텝의 경우, 스텝별로 스레드 병렬로 실행하여, 독립적인 스텝들이 동시적으로 처리될 수 있도록 진행한다.
4) 원격 청킹의 경우, 메시지 기반 도구 등을 활용하여 청크 단위로 개별적인 처리 도구 및 스레드 등에 처리를 잠시 맡긴다. 이러한 도구 및 스레드를 증가하여, 혹은 청크를 처리할 수 있는 서버 및 인스턴스를 증가하여 처리량을 증가한다.
위 4가지 전략을 어떠한 방안으로 구성이 가능하며, 해당 전략을 사용하여 어떠한 결과를 기대할 수 있을지 분석해보도록 한다.
3. Multi Thread Step
하나의 step, 그 중에서도 chunk에 대해 스레드 병렬 처리(multiThread)를 하고자 할 경우, 스텝 빌더에서 taskExecutor의 설정 구현체를 전달하면 된다.
이 taskExecutor 구현체 내부적으로, 멀티스레드를 운용할 thread pool의 환경을 조정해주면 되고, 이를 기반으로 item 처리 시 싱글스레드가 아닌 멀티스레드 기반의 처리가 시작된다.
@Bean
public TaskExecutor taskExecutor{
ThreadPoolExecutor executor = new ThreadPoolExecutor();
executor.setMaxPoolSize(10);
...
}이 구현체를 스텝빌더에 적용하면, 청크지향처리(SimpleStepBuilder) 및 tasklet지향처리(TaskletStepBuilder)의 공통 부모 클래스인 AbstractTaskletStepBuilder의 build() 과정을 통해 해당 taskExecutor가 지정이된다.
참고로, 청크지향처리이든 tasklet지향처리이든 모든 stepBuilder의 build는 반드시 부모클래스의 build인 super.build()를 호출하게 되어있으므로, 반드시 거치게 되는 관문이다.
super.build(), AbstractTaskletStepBuilder에서 반복엔진인 RepeatTemplate을 구성한 후에 taskExecutor를 등록하는 부분을 확인할 수 있다.
if (taskExecutor != null) {
TaskExecutorRepeatTemplate repeatTemplate = new TaskExecutorRepeatTemplate();
repeatTemplate.setTaskExecutor(taskExecutor);
repeatTemplate.setThrottleLimit(throttleLimit);
stepOperations = repeatTemplate;
}위 과정을 수행한다면, 단일스레드를 위한
stepOperations = new RepeatTemplate();RepeateTemplate이 아닌, 멀티스레드를 위한 TaskExecutorRepeatTemplate을 반복엔진으로 변경 반영하게 된다.
stepOperations를 TaskExecutorRepeatTemplate 구현체로 설정하였다면, TaskletStep 구현체의 doExecute를 호출하여
stepOperations.iterate해당 iterate를 진행, repeatCallback의 doInTransaction 및 task.execute()를 멀티스레드 기반의 반복호출을 통해 작업을 처리한다.
참고로, 그 이전 step을 실행하기전에 jobInstance 및 이에 따른 stepExecution의 생성 등은 싱글스레드 기반으로 main에서 일괄 진행하며, 실질적으로 청크단위로 작업을 처리할때 해당 청크를 멀티스레드 기반의 병렬연산이 적용된다.
이때,
- Tasklet 지향처리의 경우 Tasklet.execute를 멀티스레드 기반으로 처리하며, 멀티스레드들의 연산 결과를 종합한다.
- chunk 지향처리의 경우 각 chunk들을 멀티스레드들이 분할책임 하 병렬처리를 진행하며, 멀티스레드들의 각 청크별 연산 결과를 종합한다.
따라서, 동일한 작업량이라도 혼자서 처리하던 일전의 방법에서, 멀티스레드 기반의 다수의 스레드로 병렬적으로 처리하게 되므로 처리량 및 처리속도가 향상하게 된다.
Chunk1
Chunk2
Chunk3
- Main thread read -> process -> write
----
vs
----
Chunk1
- thread1 read -> process -> write
Chunk2
- thread2 read -> process -> write
Chunk3
- thread1 read -> process -> write특히, 청크지향처리의 경우 하나의 스레드가 아닌 멀티스레드가 chunk 단위의 처리를 itemReader부터 itemProcessor, itemWriter까지 전 영역에 대해 일련의 과정을 모두 위임하여 처리하고, 이 처리결과를 비동기적으로 이어받아 다음의 chunk를 처리할 수 있으므로 싱글스레드 기반의 처리방식에 비교를 할 수 없을 정도로 성능향상을 기대할 수 있다.
StepOperation의 구현체인 TaskExecutorRepeatTemplate 클래스를 살펴보도록 하자.
public class TaskExecutorRepeatTemplate extends RepeatTemplate {taskExecutorRepeatTemplate은 부모클래스를 RepeatTemplate로 가지고 있는 상속체이며, 이에 따라 stepOperations의 iterate 호출 시 1차적으로는 RepeatTemplate의 iterate 메소드를 호출하게 된다.
그리고,
result = getNextResult(context, callback, state);
..
return callback.doInIteration(context);getNextResult를 호출하는 시점에는, 실행로직이 부모에 있더라도 주체(this)가 TaskExecutorRepeatTemplate이므로, RepeatTemplate이 아닌 해당 자식구현체의 getNextResult를 호출하게 된다.
동적 디스패치 (Runtime Polymorphism), 현재 로직의 실질적인 인스턴스는 부모가 아닌 자식이기에, 동일한 오버라이드 메서드를 호출하였고 부모와 자식에게 모두 해당되어있는 로직이라면, 실질적인 구현체의 메서드를 따른다.
템플릿 메서드 패턴이자, JVM의 동적 디스패치 작동이며 이에 대한 내용은 일전에 많이 살펴보았기에 이쯤에서 하고 넘어가도록 하겠다.
이후의 전체적인 과정은 부모클래스와 동일하다. 이 부분도 많이 살펴본 내용인데,
result = getNextResult(context, callback, state);이후, callback의 doInIteration을 호출하며, 이때 callback 구현체는 StepContextRepeatCallback이다.
@Override
public RepeatStatus doInIteration(RepeatContext context) throws Exception {
StepContext stepContext = StepSynchronizationManager.register(stepExecution);내부적으로 StepSynchronizationManager에 stepExecution 정보를 바인딩해주는 작업이 Step에 대한 정보를 활성화하여, stepScope의 해석이 가능해지는 시점이 진행된다.
이것이 가능한 이유는 TaskExecutorRepeatTemplate 구현체를 사용하였다고 하더라도, 내부적으로 callback의 doInIteration을 공통적으로 호출하기 때문이다.
이때, 각 멀티스레드의 threadLocal에 공통적인 Step 객체에 대한 정보를 바인딩하여 사용하므로, 멀티스레드가 threadLocal을 각자 사용한다고 하더라도, 동일한 step 정보를 바인딩하여 사용하기에 정상적인 scope 활성화 및 Step 인스턴스 활용 등이 충분히 가능하다.
이후 callback 내부적으로 doInChunkContext를 호출하며, 일전의 과정과 동일하게 진행이 된다.
이때는, 알고있듯이, 싱글스레드, 멀티스레드 상관없이 TaskletStep에서 callback 구현체를 전달하면서 오버라이드한 doChunkContext, 및 내부적으로 tasklet.execute() 반복호출하면서 다음 chunk를 진행하게 된다.
그다음 중요한 단계는 멀티스레드의 처리과정에 대한 공유, 즉 스레드 환경 내의 chunk 진행상태 공유이며, 데이터 일관성 및 정합성을 위해 스레드 안전성, 즉 동시성 문제에 대한 이해가 반드시 필요하다.
Thread-safe, 스레드 안전성은 다수의 스레드가 동시에 하나의 자원에 접근할때 데이터 처리에 대한 일관성을 유지하고자 하는 동시성 문제에 대한 방안으로 이해하면 된다.
Spring batch에서 스레드 안전성은,
- 데이터를 읽고 처리하는 비즈니스 로직에 대한 안전성
- 메타데이터 테이블에 상태내역을 기록하기 위한 batch 메타데이터 로직에 대한 안전성
이 두가지를 고려해야 한다.
3-1. 비즈니스 로직에 대한 Thread-safe
먼저, 비즈니스 로직에 대한 동시성 문제를 살펴보자.
멀티스레드가 동일한 자원에 동시에 접근하여, 연산 누락 및 중복 처리 등과 같은 문제를 야기할 수 있는데, ItemWriter의 경우 대부분 thread-safe하지만 문제는 ItemReader이다.
FlatFileItemReader, JdbcCursorItemReader를 살펴보면


위와 같이 모두 thread-unsafe하다.
Paging 기반 방식의 ItemReader의 경우,
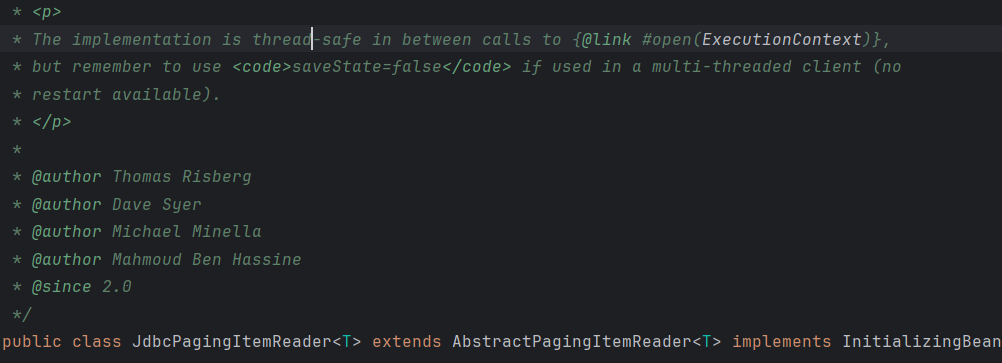
thread-safe하게 구성이 되어있다.
FlatFileItemWriter, JdbcBatchItemWriter, JpaItemWriter를 살펴보면

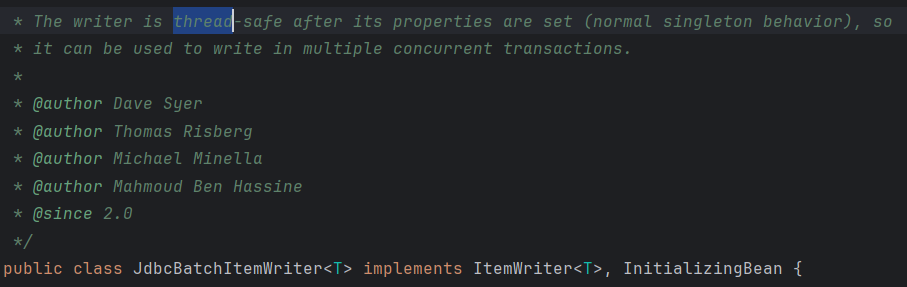
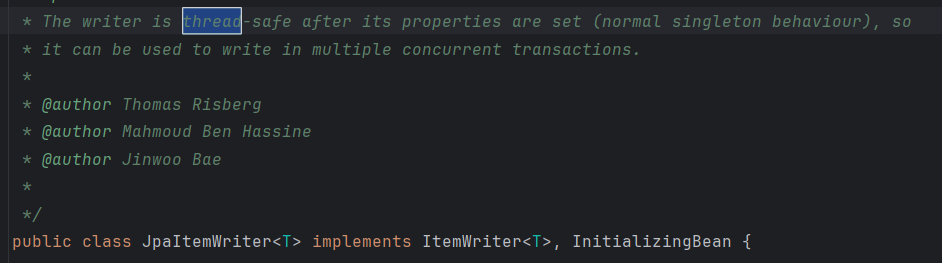
flatFileItemReader를 제외한 대부분의 writer의 경우 thread-safe하다는 것을 알 수 있게 된다.
여기서 개발자로서 가져야할 생각은, 만약 멀티스레드 기반으로 spring batch를 구성하고자 한다면, 기본적으로 해당 reader, writer가 thread-safe한지 thread-unsafe한지 판단해야 한다는 의미이다.
thread-unsafe한 FlatFileItemReader를 대표적으로 한번 살펴보자.
사실 cursor도 마찬가지인데, readLine()을 통해 데이터소스로 부터 데이터를 읽어오는 과정에서
line = this.reader.readLine();
if (line == null) {
return null;
}
lineCount++;데이터를 읽어오고, lineCount를 증가시킨다.
이때 lineCount는 동일한 FlatFileItemReader 인스턴스를 공유하고 있는 멀티스레드로, private int로 선언되어있는 lineCount이지만 내부적으로는 이를 공통변수로써 공유한다.
Step (1개)
└── FlatFileItemReader (1개 인스턴스)
├── Thread-1 → doRead()
├── Thread-2 → doRead()
├── Thread-3 → doRead()
즉, 하나의 객체인 상태에서 변수를 공유하고 있으므로 각 멀티스레드들이 doRead()를 호출하면서 증감하는 lineCount는 모든 멀티스레드, 공유 객체의 lineCount에 전역적으로 관리되면서 증감이 반영이 된다.
따라서, lineCount는 thread-unsafe 하게되어, 데이터 일관성 및 정합성을 보장해주지 못한다.
다른 Reader도 거의 유사한 원리로,
- JpaCursorItemReader
protected T doRead() {
return this.iterator.hasNext() ? this.iterator.next() : null;
}- JdbcCursorItemReader
protected T readCursor(ResultSet rs, int currentRow) throws SQLException {
return rowMapper.mapRow(rs, currentRow);
}iterator를 활용하면서 데이터를 읽어나갈때, Read Commit로 인한 DB고유의 동시성 관리 단위에 의한 데이터 정합성 저해 및 특히 데이터 추가로 인해 멱등성을 보장할 수 없을때, 멀티스레드 기반의 itemReader를 사용하기가 곤란할 수 있겠다.
참고로, Jpa(jdbc)PagingItemReader의 경우 thread-safe하다.
부모클래스인 AbstractPagingItemReader내부의 doRead를 살펴보면,
@Nullable
@Override
protected T doRead() throws Exception {
this.lock.lock();이처럼 멀티스레드가 객체를 공유하고 있는 상태이더라도(this),
private final Lock lock = new ReentrantLock();해당 구현체의 ReentrantLock를 통해 공유객체에 대한 비관락을 걸어버린다.
finally {
this.lock.unlock();
}이후 해당 lock을 unlock하여 비관락을 해제하고, 해당 공유 객체의 스레드 접근을 허용한다.
이처럼, paging 방식의 경우 page 및 current index 증감을 비관락을 걸어놓은 상태에서 증가하기에, paging의 기본적인 증감은 비관락에 의해 thread-safe하게 운용이 된다.
그렇다면 다른 Reader에 대해서는 thread-safe하게 lock을 별도로 구성하는 전략을 취해야 할까? 그럴 필요까지 없다.
다행히도 Spring batch 측에서 이러한 Cursor/flatFile 기반의 reader에 대한 동시성 문제 발생을 방지하고자, thread-safe한 reader 구현체를 제공한다.
SynchronizedItemStreamReader의 구현체를 사용하되, 일전에 composite 구성한 것처럼
SynchronizedItemStreamReader<T> reader =
new SynchronizedItemStreamReader<>();
reader.setDelegate(flatFileItemReader);읽는 연산 자체를 특정 구현체에 위임하기만 하면 된다.
@Override
@Nullable
public T read() throws Exception {
this.lock.lock();내부적으로 read() 메소드를 살펴보면, ReentrantLock을 활용하여 공유 객체에 대한 멀티스레드 접근을 비관락을 걸어 방지한다.
이 경우, 일전에 ItemCursorReader를 사용하여 발생하였던 동시성 문제를 방지할 수 있게 된다.
그 후 위에서 살펴보았듯이, thread-safe하게 구성한 환경 하에 데이터 읽기를 itemReader에 위임하여 처리하기에 동시성 문제를 방지한 환경에서 안전한 데이터 읽기가 가능해진다.
실제 로직으로 구성하고자 할 경우,
SynchronizedItemStreamReader<HumanThreatData> synchronizedReaderSynchronizedItemStreamReader 구현체를 먼저 설정한 후,
synchronizedReader.setDelegate(reader);해당 구현체에 FlatFileItemReader와 같은 구현체 reader를 등록해주기만 하면 된다.
3-2. SynchronizedItemStreamReader
위에서 기술한 내용을 살펴보면,
- SynchronizedItemStreamReader의 reader 구현체로 읽기를 위임한다.
- reader 구현체는 flatFileItemReader와 같은 특정 구현체이다.
- SynchronizedItemStreamReader를 반환형태로 할 경우, ItemStreamReader가 최종적인 반환형태이다.
이 중 주목해야 할 점은 최종적인 반환형태는 인터페이스인 ItemStreamReader라는 점이다.
SynchronizedItemStreamReader는 ItemStreamReader 인터페이스를 구현한 구현체인데, Spring batch Step 측에서 stream, listener를 등록할때 사용한 범용적 itemStream를 이 상황에도 적용하고자 하는 목적으로 ItemStreamReader를 구현하였다.
즉, 해당 Reader 역시, itemStream으로 인식할 수 있도록 하고, 내부적으로 open, close, update 등 자원관리를 가능하게 할 수 있도록 오버라이드한 것을 확인할 수 있는데 이것을 그대로 stream 등록에 반영하고자 하기 위함이다.
@Override
public void close() {
this.delegate.close();
}
@Override
public void open(ExecutionContext executionContext) {
this.delegate.open(executionContext);
}
@Override
public void update(ExecutionContext executionContext) {
this.delegate.update(executionContext);
}상태관리를 위한 리소스, 컴포넌트 초기화를 delegate한 reader의 itemStream 자원상태관리 내역 그대로 진행(this.delegate.open/close 등), 그 이후의 데이터 읽기 역시 delegate한 reader를 통해 이루어지는 양상이다.
만약, 자원관리 상태를 customized하게 구성하며, thread safe한 골자만 유지하고 싶다면 SynchronizedItemReader를 사용하면 된다.
public class SynchronizedItemReader<T> implements ItemReader<T> {
private final ItemReader<T> delegate;
private final Lock lock = new ReentrantLock();SynchronizedItemReader는 itemStreamReader를 구현하지 않은 형태이므로, 리소스 상태관리를 직접 구현해주어야 한다. 다만, thread-safe한 특성은 유지한다.
Writer 역시, SynchronizedItemWriter 및 SynchronizedItemWriter를 사용하면 되겠다.
3-3. 상태 반영에 대한 Thread-safe
상태 반영, 즉 메타데이터 반영을 위한 스레드 안전성에 대해 살펴보자.
FlatFileItemWriter를 하나의 예로 들어보겠다.
사실, flatFileItemWriter는 비즈니스 로직에 대한 스레드 안전성은 보장할 수 있다.
Reader 측에서 이미 스레드 안전하게 처리할 chunk size의 item 묶음을 읽어온 상태이다.
@Override
public String doWrite(Chunk<? extends T> items) {
StringBuilder lines = new StringBuilder();
for (T item : items) {
lines.append(this.lineAggregator.aggregate(item)).append(this.lineSeparator);
}
return lines.toString();
}이에 따라, 공유 객체 내부적으로 활용하는 lineCount와 같은 공유변수가 존재하지 않고, item 묶음 Chunk에 대해 각 멀티스레드들이 고유의 객체 및 변수를 활용하여 데이터를 읽는다.
따라서, 비즈니스 로직에 대한 thread-safe 특성은 유지할 수 있지만, 문제는 메타데이터 반영 관점에서의 thread-safe 특성이다.

FlatFileItemWriter의 주석에 기재된 thread-unsafe하다는 특성은 바로 이러한 메타데이터 반영 관점에서 unsafe하다는 의미이다.
itemStream 인터페이스가 상태관리를 저장하고 반영하는 기본적인 원리는 ExecutionContext를 임시적인 저장소로 활용하여, 해당 저장소에 1차적인 반영이 이루어지는 과정부터 시작된다.
write하기 전에 먼저 write 대상의 파일을 open하는 작업을 진행하는데, 이때
OutputState outputState = getOutputState();이때 getOutputState는,
try {
file = resource.getFile();
}위와 같이 공유 객체에 저장된 resource 변수에 접근하여, write 대상 파일을 연결한다.
이 부분부터, 공유 객체 내 변수가 멀티스레드 간 동시 호출이 되면서 동시성 문제가 발생할 것 같지만 다행히 이부분은 동시성 관리 대상이 아니다. 어차피 멀티스레드 입장에서는 본인들이 처리한 chunk에 대해서만 처리하고 이에 대한 읽은 데이터를 writer로 넘긴다. 위에서 기술하였듯이, 이 과정은 모두 동일한 스레드에 대해 진행이 되므로, 사실 동시성 문제는 걱정할 필요가 없는 부분이다. 더불어 자원 open, close와 같은 부분의 경우 main thread라는 싱글스레드 작업 영역이기에, 다중 스레드로 인한 동시성 문제는 고려 대상이 아니다(즉, 멀티스레드로 처리한 chunk 작업 내역을 싱글스레드가 일괄적으로 종합하여 처리하는 방식).
문제는 update 부분이다.
@Override
public void update(ExecutionContext executionContext) {
super.update(executionContext);
...
if (saveState) {
try {
executionContext.putLong(getExecutionContextKey(RESTART_DATA_NAME), state.position());
}
catch (IOException e) {
throw new ItemStreamException("ItemStream does not return current position properly", e);
}
executionContext.putLong(getExecutionContextKey(WRITTEN_STATISTICS_NAME), state.linesWritten);
}executionContext에 현재의 상태를 state.position(), state.linesWritten를 기반으로 기록하여, 현재의 처리 상태 및 처리 수를 context에 반영하게 된다.
이 과정에서 멀티스레드 접근으로 인해 두서없는 상태반영이 일어난다면, 순서상관없이 가장 최근에 데이터를 write한 writer에 대한 상태내역이 저장되므로, 재시작 시 정확한 지점을 찾을 수 없게 된다.
즉, 비즈니스 로직 자체는 thread-safe하지만 상태 내역 관리에서 thread-unsafe한 로직이 이어지기에, 로직의 일관성을 보장할 수 없는 상태가 이어진다.
멀티 스레드에 의한 상태관리 환경에서 순차성, 순서보장이 의미가 있을까?
결론적으로는 없다.
따라서, 스텝빌더에서
if (saveState) {해당 saveState 부분을 false로 처리하여 의미없는 상태내역 저장을 하지 않도록 구성한다.
상태관리에 대한 부분을 처리하지 않도록 구성하는 것이 필요하다. 즉, 이전 상태내역을 가져오는 과정을 포기하고, 실패시 재시작이 아닌 처음부터 다시 시작하는 job으로 구성해야한다는 것이다.
이는 모든 writer에 해당이 된다.
만약 멀티스레드 환경에서 itemReader를 사용한다면, 정확하게 해당 목적을 얻을 수 있지만, itemWriter에서도 이를 사용하겠다면 반드시 saveState를 false로 지정하여, 재시작을 포기해야 한다.
3-4. 실무적용방안
기본적으로 멀티스레드 환경을 적용하기 위해서는 taskExecutor 구현체를 구성해야 한다.
@Bean
public TaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(5);
executor.setWaitForTasksToCompleteOnShutdown(true);
executor.setAwaitTerminationSeconds(10);
executor.setThreadNamePrefix("T-800-");
executor.setAllowCoreThreadTimeOut(true);
executor.setKeepAliveSeconds(30);
return executor;
}corePoolSize의 경우 멀티스레드 환경에서 기본적으로 생성할 갯수, maxPoolSize의 경우 가용한 멀티스레드의 최대 허용 갯수이다. 멀티스레드를 구성하는 목적 자체가 최대량을 극대화하는 것이기에, 이 두개의 값은 일치해주는 것이 좋다.
waitForTasksToCompleteOnShutDown은 api 명에서도 알 수 있듯이, 중단요청이 왔을때 모든 멀티스레드의 처리 종료를 wait(대기)할 것인지에 대한 여부이다.
이를 true로 설정하였다면, 강제처리종료 이전까지 얼마나 기다릴 것인지 대기시간을 awaitTerminationSeconds를 설정해주어야 한다.
coreThreadTimeOut의 경우, 모든 step chunk를 처리하고 유휴상태에 있는 스레드들을 강제로 종료할 것인지 그 여부에 대해 설정해주는 api이다.
해당 api를 true로 설정하였다면 유휴상태에 있는 스레드들을 강제적으로 종료하는 것을 허용하겠다는 의미이며, 이 종료대기시간을 keepAliveSeconds로 설정해줄 수 있다(위의 경우 30초).
보통 spring batch 프로젝트의 경우 application 혼용보다는, batch job 전용의 프로젝트를 구성하는 경우가 많은데, 이에 따라 보통은 batch 종료를 해당 프로젝트 main thread의 종료로 간주하여, 프로젝트를 바로 종료시키는 것이 대부분이다.
따라서, 이러한 기본적인 요구사항에 맞추어 유휴상태의 스레드를 종료하도록 설정하여, batch 종료 시 application 종료로 이어질 수 있도록 환경구성을 해주는 것이 필요하다.
참고로 5버전 이상부터
//.throttleLimit(5)stepBuilder에서 멀티스레드 환경 구성시, step의 병렬처리, 즉 멀티스레드의 step을 병렬로 처리하기 위한 스레드 생성 개수를 스로틀 리밋으로 추가 제한할 수도 있었지만, 5버전 이상부터는 중복설정으로 간주하여 deprecated 되었다.
taskExecutor를 통한 스레드 환경 제어가 이루어지도록 구성하자.
그리고, 스텝빌더에 해당 taskExecutor를 등록하여 멀티스레드 환경임을 기재해주고
.taskExecutor(taskExecutor())reader, writer에서 saveState를 false로 설정해주도록 한다.
.saveState(false)Step, tasklet 구성 후 적절한 jobParameter를 전달하여 실행해보면,
./gradlew batch:multiThread:bootRun --args='--spring.batch.job.name=humanThreatAnalysisJob fromDate=2025-02-01,java.time.LocalDate outputPath=C:/Users/gyrbs/OneDrive/Desktop'위와 같이 실행하면,
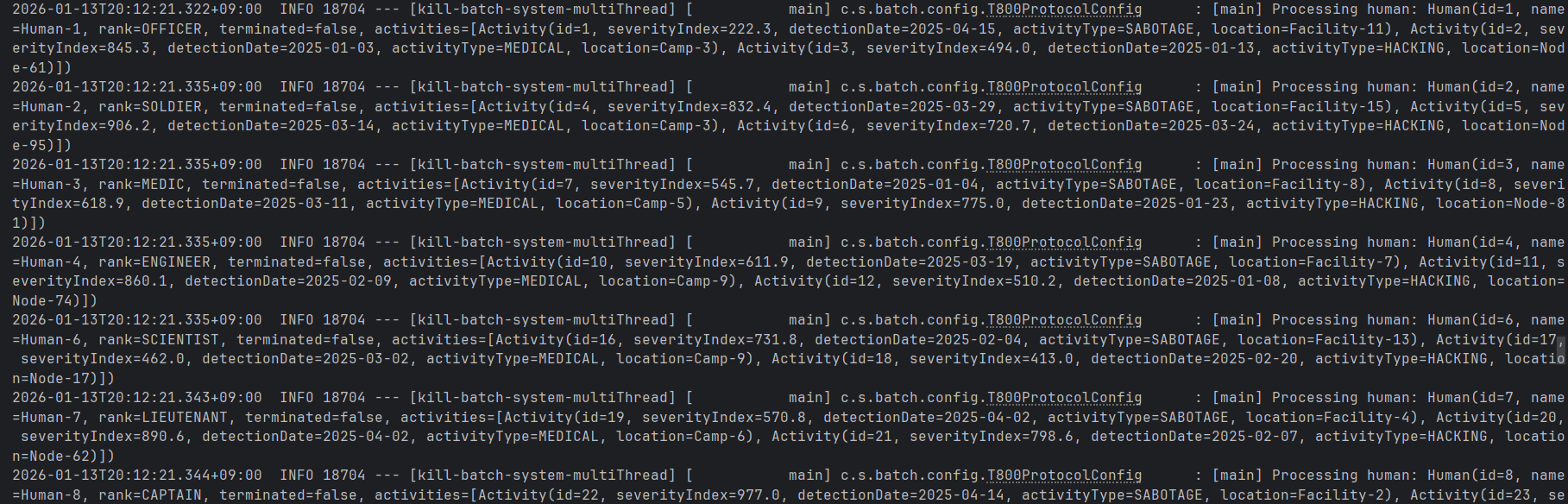
기존의 main 단일 스레드로만 처리하던 step을
위와 같이 5개의 스레드로 병렬처리 하는 것을 확인할 수 있으며, 사실 멀티스레드로 처리한다고 하더라도 원자성을 반드시 보장해야하기때문에, 동기화 처리로 인해 main thread의 일괄처리와 결과적으로는 큰 차이가 없음을 확인할 수 있다.
오히려 스레드 숫자를 늘리는 것이 처리량, 처리효율을 늘리는 절대적인 방법은 아니다. 임계점(Threshold) 이후의 스레드 증가는 오히려 스레드 남용으로 인한 성능저하를 유발할 수 있다.
다수의 스레드가 공유객체에 접근하는 방식은 말 그대로 힙에 있는 참조객체를 활용한다는 점, 해당 공유 객체를 점유한 상태로 동기화 Reader 사용 시 점유시간동안 다른 스레드들이 lock 처리되어 대기상태에 들어가는 점, 공유객체를 점유하기 위한 경쟁상태 등 성능 저하의 이유는 결국 공유객체를 차지하기 위한 경쟁 및 병목이다.
따라서, 멀티스레드의 숫자를 오용하지말고, 적절한 처리스레드를 설정하여 환경에 맞는 처리가 이루어질 수 있도록 하자.
참고. Process는 동시성 관리 대상에서 상대적으로 "자유롭다"
Processor의 경우, ItemProcessor는 입력받은 "단일" 아이템을 가공하여 "반환"하는 역할만 수행하는 경우가 대부분이다.
즉, 이전 아이템의 처리 결과가 다음 아이템에 영향을 주지 않는 순수 함수(Pure Function) 형태로 작성된다면, 여러 스레드가 동시에 process() 메서드를 호출해도 데이터 정합성 문제가 발생할 여지가 없으며, 이러한 동작이 대부분 다른 스레드의 간섭이 이루어지지 않는 안전한 환경이므로 Reader, Writer에 비해 상대적으로 동시성 관리 대상에서 자유롭다.
특히, Chunk 지향 처리에서 Spring Batch의 멀티 스레드 스텝(Multi-threaded Step)에서 동시성은 청크(Chunk) 단위로 동작한다. 다시 말해, Chunk마다 thread가 붙는 형태이고, thread는 ItemReader, ItemProcessor, ItemWriter를 각각 공유객체로 생성하면서 작업을 처리한다.
프레임워크는 Reader를 통해 데이터를 읽어올 때 동기화(Synchronization)를 통해 스레드 안전성을 보장할 수 있으며, 데이터가 일단 읽혀서 개별 스레드에 할당되면, 해당 청크 내의 아이템들은 write할때까지 thread 각자에 대해 할당, 전속된다고 보면 된다.
따라서 Processor로 전달하는 과정은 해당 스레드 내부에서 독립적으로 일어나는 것이 대부분이고, 한 스레드가 관리하는 Processor 작업은 다른 스레드의 간섭을 받지 않다고 보아도 무방하다.
4. Partitioning
멀티스레드 환경으로 인한 공유객체 점유 경쟁이 증가하고, 이로 인한 병목이 증가한다면 임계점 이후의 상태에서는 오히려 성능 저하를 유발할 수 있다.
데이터 파티셔닝의 목적은 하나의 데이터로부터 만들어지는 ItemReader, ItemWriter 객체를 공유해서 사용하지 않고, 각 데이터를 구분하여 스레드들 고유의 객체를 생성하도록 유도하는 것이다.
따라서, 멀티스레드들은 공유객체를 참조하여 사용하는 것이 아닌, 데이터마다 구분된 객체와 고유의 stepExecution으로 작동하게 되어, 하나의 Reader/Writer를 점유하기 위한 경쟁을 제거할 수 있다.
데이터의 영역, 범위, 조건 등을 구분하여 Step 실행 객체의 생성을 이에 따라 구분하는 것, 즉 서로 다른 파티션 영역을 처리하기 위해 Step 실행을 구분하는 것이 파티셔닝의 최종 목표이다.
말이 조금 어려운데, 쉽게 말하면 다음과 같다.
Step
├─ ItemReader (공유)
├─ ItemProcessor (공유)
├─ ItemWriter (공유)
└─ 여러 Worker Thread기존의 방식에서는 Step 1개에서 발생하는 객체들을 멀티스레드들이 공유하였다.
[ StepExecution 1 ]
├─ Thread-1 → read/process/write
├─ Thread-2 → read/process/write
├─ Thread-3 → read/process/write
└─ Thread-4 → read/process/write
↑
공유 객체 + 공유 메타데이터이로 인해 StepExecution이 하나만 존재하여, 멀티스레드들이 하나의 stepExecution에 대해 두서없는 상태관리 혹은 상태관리를 포기한 상태에서 단일 step을 진행하는 방식으로 이루어졌다.
이와 반대로, 파티셔닝의 접근 방향은 스레드를 공유하지 말고, Step을 나누어 실행하자는 것이다.
[ Master StepExecution ]
│
├─ Partition 1 → StepExecution #1
├─ Partition 2 → StepExecution #2
├─ Partition 3 → StepExecution #3
└─ Partition 4 → StepExecution #4
각 StepExecution은 완전히 독립즉, 다수의 Step을 만들어 병렬로 처리하며, 병렬로 만든 각 Step은 독립적인 StepExecution을 만들어 관리하자것이 핵심 방향이다.
Partitioner
├─ partition-0 : id 1 ~ 25,000
├─ partition-1 : id 25,001 ~ 50,000
├─ partition-2 : id 50,001 ~ 75,000
└─ partition-3 : id 75,001 ~ 100,000이를 위해 데이터도 파티셔닝하여 나누고 이를 분할하자는 것이 그 출발점이며,
MasterStep
├─ WorkerStep (partition-0)
├─ WorkerStep (partition-1)
├─ WorkerStep (partition-2)
└─ WorkerStep (partition-3)데이터를 파티셔닝하여, 각 파티셔닝에 대한 독립적인 워커스텝, 실행인스턴스를 만들어 병렬로 처리한다.
WorkerStep (partition-0)
├─ ItemReader (id 1~25,000 전용)
├─ ItemProcessor
├─ ItemWriter
└─ StepExecution #1
WorkerStep (partition-1)
├─ ItemReader (id 25,001~50,000 전용)
├─ ItemProcessor
├─ ItemWriter
└─ StepExecution #2각 Step은 완전히 독립적이며 다른 Step의 실행에 영향을 주지도 않고 받지도 않는다. 다만 본인이 위임받은 Step, StepExecution에만 관심이 있고, 이러한 기조로 인해 파티셔닝된 데이터를 처리하는 객체는 워커스텝 별로 모두 다른 인스턴스를 생성, 참조한다.
ThreadPool
├─ Thread-A → WorkerStep #1
├─ Thread-B → WorkerStep #2
├─ Thread-C → WorkerStep #3
└─ Thread-D → WorkerStep #4결론은 멀티스레드가 하나의 공유객체를 점유하는 것이 아니라, 아예 별도의 스텝인스턴스(WorkerStep)을 만들어 병렬로 처리하도록 하는 것이 바로 데이터 파티셔닝의 목적이다.
이때 각각의 워크스텝 실행은 매니저스텝의 TaskExecutorPartitionHandler 및 StepExecutionSplitter가 동작하여 관리하며, 컴포넌트명에서 유추할 수 있듯이 StepExecutionSplitter를 통해 워커스텝을 분할 생성하며 PartitionHandler를 통해 독립적인 워커스텝 실행관리를 진행한다.
참고로, Splitter의 step 분할은 데이터 파티셔닝 규칙을 보통은 동일하게 사용하여, 파티셔닝된 데이터의 처리책임을 동일하게 분할, 이에 따라 처리 스텝 인스턴스(StepExecution)를 별도로 생성한다.
이후 Handler를 통해 stepExecution을 매개변수로 워커스텝을 실행하게 되며, 워커스텝은 멀티스레드 별로 독립 할당 및 step을 병렬로 처리하게 된다.
WorkerStep #1 COMPLETED
WorkerStep #2 COMPLETED
WorkerStep #3 COMPLETED
WorkerStep #4 COMPLETED
↓
MasterStep COMPLETED
↓
Job COMPLETED이후 모든 워커스텝의 실행이 완료된다면, MasterStep도 같이 완료된다. MasterStep은 관리의 역할일뿐, 모든 처리의 책임을 워커스텝에게 위임하며, 결과만 관리한다.
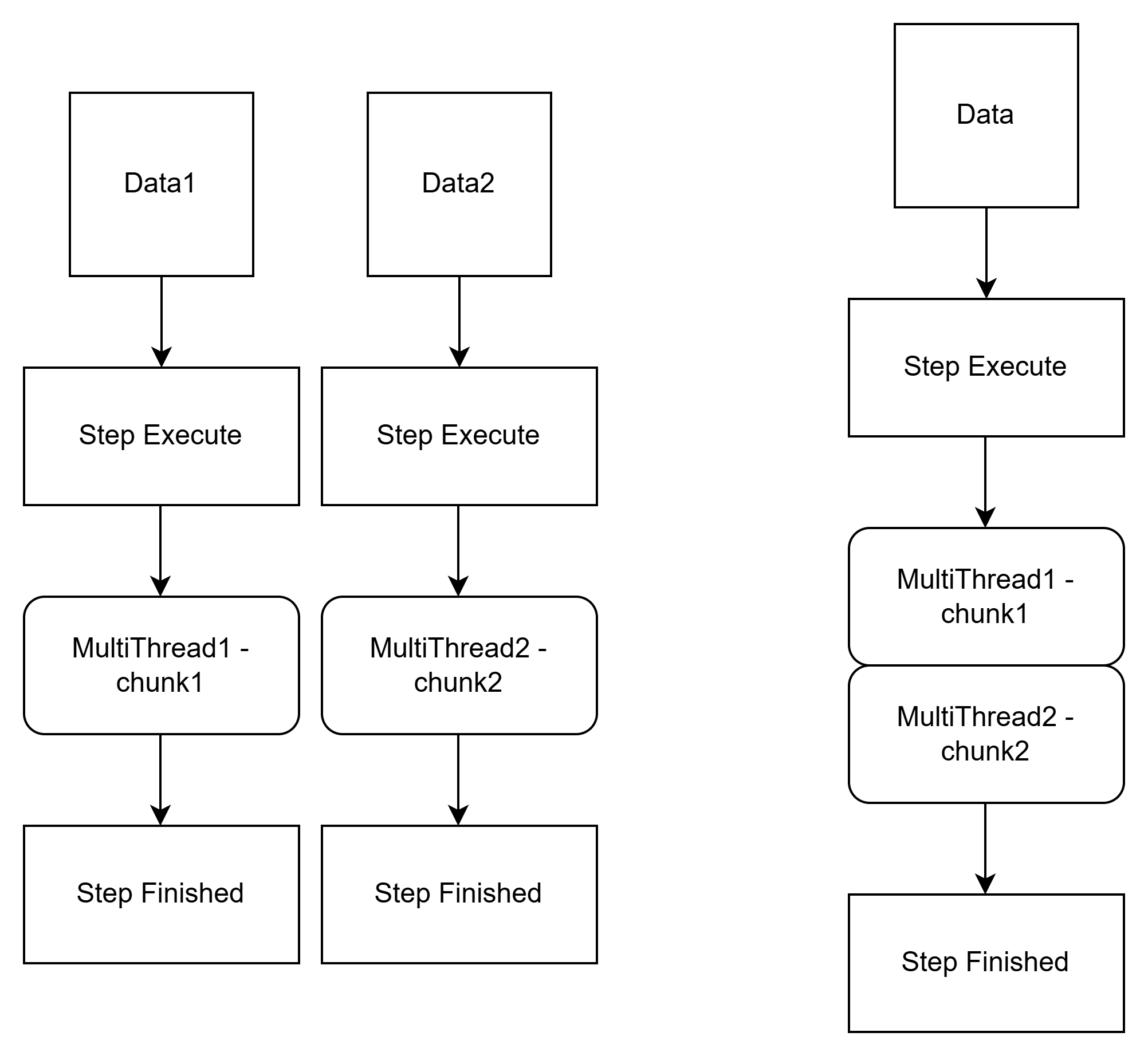
위 도식을 보면 한눈에 이해가 될 것이다. 멀티스레드 병렬처리라 하더라도, 멀티스레드들의 공유객체는 단 하나이며 이로 인한 동기화 처리가 단일 스레드 처리와 비슷한 결과를 유발하는 모순적인 상황이 발생한다.
하지만, 멀티스레드의 진정한 효과를 내기위해 멀티스레드들에게 독립적인 stepExecution 및 워커스텝 인스턴스를 할당하여, 각 스레드들의 자원 점유를 신경쓰지 않고 말 그대로 진정한 병렬처리를 진행하게 된다. 이를 위해 데이터를 구분하여 나누고, 이 기준에 따라 워커스텝도 같이 파티셔닝한다.
이로 인해, ItemReader 및 ItemWriter 인스턴스는 각 워커 스텝별로 다를 수 밖에 없고, 본인이 처리해야 하는 영역(partitioned data range)만을 담당하여 처리한다.
4-1. Partitioner
데이터 파티셔닝에 따른 워커스텝을 분할 생성하는 주체는 Partitioner 인터페이스를 구현하는 구현체이다.
@FunctionalInterface
public interface Partitioner {
/**
* Create a set of distinct {@link ExecutionContext} instances together with a unique
* identifier for each one. The identifiers should be short, mnemonic values, and only
* have to be unique within the return value (e.g. use an incrementer).
* @param gridSize the size of the map to return
* @return a map from identifier to input parameters
*/
Map<String, ExecutionContext> partition(int gridSize);
}위와 같이, 처리할 기준에 따라 데이터를 파티셔닝하기 위해 Partitioner에게 그 기준을 정립한다.
이후 파티셔닝된 영역에 따라 managerStep에게 넘겨주고, 내부적으로 StepExecutionSplitter를 통해 partition 메소드를 실행, 그 후 StepExecution을 새롭게 생성하면서 파티션 기준까지 넘겨받는다.
이에 따른 워커스텝을 통해 멀티스레드에게 일거리를 나누어주는 것이고, 최종적으로 PartitionHandler가 stepExecution을 매개변수로 전달받고 워커스텝을 실행, 병렬처리가 진행되는 것으로 요악할 수 있다.
그렇다면 partition의 데이터 파티셔닝 기준을 어떻게 정립하면 되는지 알아보자.
일단, spring batch를 실행하기 위해 전달하는 매개변수인 job parameter부터 거슬러 올라간다.
job parameter는 데이터 원천에서, 기본적으로 어떠한 데이터를 대상으로 batch job을 진행해야 하는지 기초 경계를 나누는 매개변수의 역할이다. 이 기본적인 "경계"가 있는 상태에서, 세부적으로 데이터를 어떻게 나눌 것인지 폐구간을 정하는 것이 바로 파티셔닝의 본질이다.
이 세부적인 폐구간을 정하는 것이 바로 splitter 내부적으로 Partitioner의 partition을 호출하는 과정이다.
public class Test implements Partitioner {
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
return Map.of();
}
}Partitioner의 partition의 반환값은 위와 같이, String을 key값으로 하고 ExecutionContext를 value값으로 하는 Map Object이다.
이때 Map은 파티셔닝된 데이터를 저장하는 저장소의 역할이 아니라, 파티션이 처리해야 하는 "범위"에 대한 정보성 메타데이터가 들어있다.
어떠한 특정 구역의 파티셔닝된 데이터에 대한 조건, 어떠한 조건으로 데이터를 읽어야 하는지 그 범위, 조건에 대한 메타데이터를 partition을 통해 제공한다.
이때 Map은,
key : 파티션 이름 (partition0, partition1 ...)
value : ExecutionContext (해당 파티션의 설정값)각 파티션 영역을 key값으로 하고, 이에 대한 executionContext를 제공하며 내부적으로,
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> result = new HashMap<>();
for (int hour = 0; hour < 24; hour++) {
ExecutionContext context = new ExecutionContext();
context.putInt("startHour", hour);
context.putInt("endHour", hour + 1);
result.put("partition-" + hour, context);
}
return result;
}위와 같이 context에 범위 분할 기준을 나누고, Map에 해당 매개변수를 그대로 전달하면 된다.
partition-0 → { startHour=0, endHour=1 }
partition-1 → { startHour=1, endHour=2 }
...
partition-23 → { startHour=23, endHour=24 }즉, 각 context에는 폐구간의 시작지점과 끝지점을 나타내며, 각 파티션은 고유식별자로 관리(Map.key), 전체 권역의 크기는 gridSize로 나타낸다.
이 분할 결과로, 하나의 분할 구간(Map)에서 어떠한 세부 폐구간으로 파티셔닝 범위를 설정할 것인지(context, startHour ~ endHour) 구성이 된다.
이때 gridSize가 의미하는 것은 작게 보면 전체 데이터의 몇개의 권역으로 나눌 것인지 그에 대한 크기이다. 넓게 보면, 파티셔닝의 "정도"로, gridSize를 통해 지정된 파티셔닝의 개수에 대한 힌트 정도로 간주하면 된다.
(예를 들어, gridSize = 4, maxPoolSize가 8이라면, 4개 권역으로 나누어진 데이터 구역을 8개의 멀티스레드가 병렬처리하게 되며 수치적으로 정확히 부합하는 것이 아닌, 이러한 기조로 진행한다는 "힌트"의 의미를 가진다.)
중요한 것은, 각각의 executionContext가 새로 생성되는 것, 워커스텝이 실행할때 stepScope를 활성화하여 threadLocal에 step 정보를 바인딩하고, executionContext 정보를 등록할텐데 이 정보가 Map 객체에서 파티셔닝된 key값에 매핑되는 executionContext 객체이다.
4-2. StepScope
그리고 중요한 것은 워커스텝을 만들기 위해선 해당 대상 step을 stepScope로 지정해주어야 한다는 것이다.
타겟 객체를 만들때 partition에서 지정한 stepExecutionContext와 이에 대한 파티셔닝 기준 값을 stepExecution['startHour'], stepExecution['endHour']를 통해 jobParameter로 전달받는 것이다.
@Value("#{stepExecutionContext['startDateTime']}") LocalDateTime startDateTime)@Value("#{stepExecutionContext['startDateTime']}") Date startDate,
@Value("#{stepExecutionContext['endDateTime']}") Date endDate)이와 같이 매개변수를 받아오고, 본인의 threadLocal에 바인딩한 step 인스턴스에, 파티셔닝한 executionContext 범위 기준 및 새롭게 생성된 context 객체까지, 완전히 다른 "무대"에서 각 워커스텝은 본인이 처리해야 할 데이터만 처리한다.
4-3. itemReader
이제 더 나아가, Reader 관점에서 데이터 파티셔닝이 어떻게 이루어지는지 세부적으로 살펴보자.
ItemReader는 stepScope에 의해 동적인 jobParameter 주입 후, 프록시 객체에서 타겟 객체로 참조를 하게 되는데, 이때 Partitioner의 partition 호출 후, 각 워커스텝이 executionContext를 주입받고 해당 context에 기재되어있는 partitioning 기준(=동적 파라미터)에 따라 데이터 권역을 분할하여 나눠 받는다.
예를 들어, MongoCursorItemReader가
@Value("#{stepExecutionContext['startDateTime']}") Date startDate,
@Value("#{stepExecutionContext['endDateTime']}") Date endDate)의 동적 매개변수를 문자열을 통해 주입받아, ParameterValues를 구성하였다고 가정하자.
이 stepExecutionContext는 partition을 통해 주입받은 executionContext이고, 여기에는 executionContext마다 분할 기준이 들어있다. 이 분할기준을 통해 데이터 파티셔닝, 즉 데이터 세부 분할을 진행하는 것이다.
MasterStep
└─ Partitioner.partition(gridSize)
↓
Map<partitionKey, ExecutionContext>
↓
partition-0 → {00:00 ~ 06:00}
partition-1 → {06:00 ~ 12:00}
partition-2 → {12:00 ~ 18:00}
partition-3 → {18:00 ~ 24:00}
TaskExecutor (병렬)
├─ Thread-A → WorkerStep(partition-0)
├─ Thread-B → WorkerStep(partition-1)
├─ Thread-C → WorkerStep(partition-2)
└─ Thread-D → WorkerStep(partition-3)
각 WorkerStep
└─ MongoCursorItemReader
WHERE timestamp >= startDateTime
AND timestamp < endDateTime참고로, 문자열로 전달된 매개변수는 jobParameters라는 spEL에 의해 paramterValues로 변환, 이 리스트의 0인덱스, 1인덱스가 각각 ?0, ?1과 같은 변수로 할당된다.
4-4. job Config
이 기본 구성을 마친 후에 job config를 구성하면 되겠다.
return new JobBuilder("Job", jobRepository)
.start(managerStep)먼저, managerStep을 구성한다. managerStep을 통해 실질적인 처리 담당인 워커스텝을
@Bean
public Step managerStep(Step workerStep) {
return new StepBuilder("managerStep", jobRepository)
.partitioner("workerStep", dailyTimeRangePartitioner)이 managerStep이 워커스텝을 생성하고, 데이터를 파티셔닝하기 위한 Partitioner를 partitioner에 등록한다.
.step(workerStep)
.gridSize(4)이후 실제 처리를 담당하는 workerStep을 등록한다. 이 step의 로직을 통해 step chunk 단위의 병렬처리가 진행된다.
이때, 병렬처리를 진행할 권역을 몇개로 구성할것인지 지정해준다.
멀티스레드에 의한 병렬처리 환경이기에, 병렬처리를 위한 TaskExecutor 객체를 구성한다.
이때 gridSize에 맞추어 멀티스레드 환경을 지정할것인지, 멀티스레드 환경에 맞추어 gridSize를 지정할 것인지 상황에 맞게 적절하게 선택하여 진행한다.
@Bean
public TaskExecutor partitionTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setMaxPoolSize(4);
...
중요한 것은, maxPoolSize = gridSize = corePoolsize, 즉 이 값을 일치시키는 방향으로 구성을 하는 것이 좋다는 것이다.
기본적인 처리효율, 처리량을 극대화하고 유휴 스레드 없이 리소스 낭비를 최소화할 수 있는 방안으로 멀티스레드 환경을 구성하는 것이 기본 전략이겠다.
5. Parallel Step(다중 계층 병렬화)
더 나아가, 파티셔닝된 데이터를 1개의 thread가 아닌, multi Thread로 처리하도록 처리량, 처리효율을 극대화할 수도 있다.
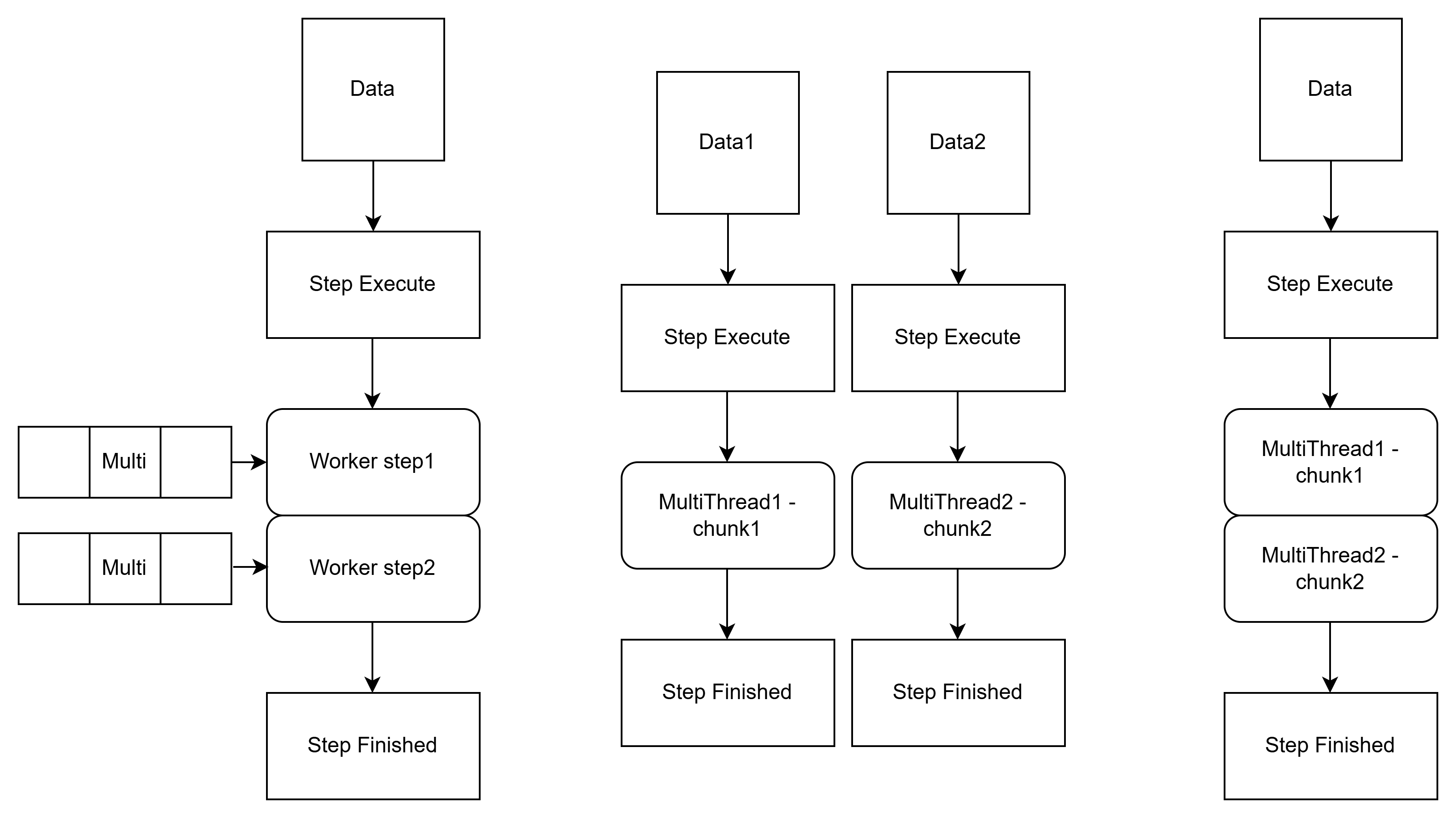
즉, 위의 도식처럼 StepExecution 레벨에서의 MultiThread 병렬화(stpExecution에서의 taskExecutor 적용) 및 내부적으로 WorkerStep이 처리하는 청크 레벨에서 또다시 MultiThread를 통해 병렬화(chunk에서의 taskExecutor 적용)하는 것이다.
다중 계층 병렬화, Multi-level Parallelization
말 그대로 모든 영역에서 멀티스레드를 다중으로 적용하여 처리량, 처리효율을 극대화하는 것이다.
하지만 문제는 그 이후의 관리이다.
절대적인 멀티스레드 운용 환경의 스케일 아웃을 위해, Thread pool도 그에 맞게 관리해야 하며, 이전 단계에서 살펴보았듯이 애초에 같은 ItemReader, ItemWriter 객체를 공유하는 multi Thread들은 락경쟁 및 자원점유 등을 고려해야 하여 성능적 한계가 있을 수 밖에 없다(각 워커스텝을 반드시 원자성 보장을 위한 동기화처리를 해주어야 한다).
이로 인해, 당연히 ManagerStep에 대한 멀티스레드 풀 관리와, 하위의 WorkerStep에 대한 멀티스레드 풀 관리는 별도의 taskExecutor로 진행이 되어야 할 것이다.
이 부분은 실전감각을 더 쌓아올린 후에 적용하는 것이 맞겠고, 데이터를 파티셔닝한것만으로 성능 개선을 기대할 수 있고, 복잡도 측면에서도 위와 같은 다중 계층 병렬화에 비해 훨씬 간단해진다.
참고. flat file based partitioning
Redis, mongoDB, Postgresql과 같은 DB 기반의 파티셔닝은 위와 같이 executionContext를 주입받고, 주입받은 context로부터 parameters 배열을 활용하여 데이터 파티셔닝 기준에 따라 데이터를 추출해온다.
이는 Database에 대한 내용이며, flat file일 경우 완전히 다른 접근법을 고려해야 한다.
하나의 파일에 대해 데이터를 파티셔닝하는 것이 아닌, 파일이 여러개일 경우에, 여러개의 파일에 대해 여러개의 파티셔너 및 워커스레드를 위임하여 다수의 파일들을 처리하는 것이 중요하다.
이를 위해 MultiResourcePartitioner라는 구현체를 아예 따로 제공한다.
public class MultiResourcePartitioner implements Partitioner {
private static final String DEFAULT_KEY_NAME = "fileName";
private static final String PARTITION_KEY = "partition";
private Resource[] resources = new Resource[0];
private String keyName = DEFAULT_KEY_NAME;
/**
* The resources to assign to each partition. In Spring configuration you can use a
* pattern to select multiple resources.
* @param resources the resources to use
*/
public void setResources(Resource[] resources) {
this.resources = resources;
}
/**
* The name of the key for the file name in each {@link ExecutionContext}. Defaults to
* "fileName".
* @param keyName the value of the key
*/
public void setKeyName(String keyName) {
this.keyName = keyName;
}
/**
* Assign the filename of each of the injected resources to an
* {@link ExecutionContext}.
*
* @see Partitioner#partition(int)
*/
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> map = new HashMap<>(gridSize);
int i = 0;
for (Resource resource : resources) {
ExecutionContext context = new ExecutionContext();
Assert.state(resource.exists(), "Resource does not exist: " + resource);
try {
context.putString(keyName, resource.getURL().toExternalForm());
}
catch (IOException e) {
throw new IllegalArgumentException("File could not be located for: " + resource, e);
}
map.put(PARTITION_KEY + i, context);
i++;
}
return map;
}
}여기서 MultiResourcePartitioner의 Resource 배열을 기반으로 ExecutionContext를 생성하고, context에 파티셔닝 변수를 넣는 부분에 주목해보자.
일전에는
context.put("startDateTime", partitionStartDateTime);위와 같이, context에 key-value 형태로 파티셔닝 기준을 등록해주었다.
for (Resource resource : resources) {
ExecutionContext context = new ExecutionContext();
try {
context.putString(keyName, resource.getURL().toExternalForm());
}파일기반의 경우에도 동일하다. 다만, 이 파티셔닝이 기준이 동일한 데이터에 대해 이루어지는 것이 아니라, 각기 다른 파일들(각각의 독립적인 파일들)에 대해 이루어진다는 것이 핵심이다.
map.put(PARTITION_KEY + i, context);
i++;이외, 최종적으로 해당 context를 Map에 key-value 형태로 등록하는 것은 동일하다.
파일의 개수가 N개가 있다면, 파티셔닝의 개수는 100개로 처리되며 gridSize는 무시된다.
참고로, 이 MultiResourcePartitioner 구현체는 paritioner 빈객체 내부에서 사용하는 도구이며,
@Bean
@StepScope
public Partitioner flatFilePartitioner(@Value("#{jobParameters['path']}") String path) {
MultiResourcePartitioner partitioner = new MultiResourcePartitioner();위와 같이 Partitioner 내부에서 파티셔닝을 위해 사용한다.
그리고, 이 partitioner 빈객체를
@Bean
public Step managerStep(Step workerStep) {
return new StepBuilder("managerStep", jobRepository)
.partitioner("workerStep", flatFilePartitioner)managerStep의 partitioner에 등록하면 된다. 그러면, workerStep은 알아서 각 파일별로 파티셔닝을 구성하여 멀티스레드에 의한 병렬처리를 진행하게 된다(기존의 경우 모든 파일에 대해 순차적으로 동기적인 처리를 하였다면, 파일의 처리 종료를 기다리지 않고 파일별 병렬처리가 가능해짐).
만약 이를 활용하여 파티셔닝을 Writer까지 적용한다면, 각 파티셔닝된 파일 읽기에 대해 매핑되어, 파일 쓰기는 하나의 파일이 아닌 각기 다른 파일에 Write가 이루어져야 한다.
@Bean
@StepScope
public FlatFileItemWriter<BattlefieldLog> battlefieldLogFileWriter(
@Value("#{stepExecutionContext['fileName']}") String fileName)flatFileItemWriter는 반드시 파일을 write할 경로를 구분할 수 있도록 구분자를 반드시 적절하게 지정해주어야 한다. 위의 경우와 같이, 동적 매개변수로 전달받은 fileName을 outputPath로 사용하도록 구성해주었다(partition을 통한 path 입력 > 그 후 stepExecutionContext에 탐색한 fileName을 활용).
참고. PartitionStepBuilder의 Splitter / partition / handler까지의 일련의 진행과정
만약 StepBuilder에 partitioner를 구성해주었다면, 이 시점부터 SimpleStepBuilder가 아닌 ParititonStepBuilder라는 특별한 구현체를 사용하게 되며, 이때 사용하는 Step 구현체는 SimpleStep이 아닌 PartitonStep이다.
이 PartitionStepBuilder의 build()를 살펴보면,
if (partitionHandler != null) {
step.setPartitionHandler(partitionHandler);
}이와 같이, customized partitionHandler를 지정해주고,
else {
TaskExecutorPartitionHandler partitionHandler = new TaskExecutorPartitionHandler();만약 partitioner 구현체가 없다면, 기본 구현체로 TaskExecutorPartitionHandler를 주입하는 것을 알 수 있는데, 이것이 대부분의 상황에서 사용되는 기본 구현체라 볼 수 있겠다.
이 핸들러는
partitionHandler.setGridSize(gridSize);
partitionHandler.setTaskExecutor(taskExecutor);이와 같이 gridSize, taskExecutor를 등록해주고,
partitionHandler.setStep(this.step);파티셔닝 권역을 처리하기 위한 workerStep을 등록하는 것을 확인할 수 있다. 따라서, 이 독립적으로 생성된 workerStep의 execute를 실행하여 파티셔닝마다 개별적인 병렬처리를 진행한다.
이후, splitter 등록을 진행한다.
SimpleStepExecutionSplitter splitter = new SimpleStepExecutionSplitter();이를 위해 기본 구현체로 SimpleStepExecutionSplitter를 사용하며,
splitter.setPartitioner(partitioner);
splitter.setJobRepository(getJobRepository());
splitter.setAllowStartIfComplete(allowStartIfComplete);
splitter.setStepName(name);
this.splitter = splitter;
step.setStepExecutionSplitter(splitter);구성해주었던 Partitioner가 바로 splitter를 통해 등록이 되며, 각 분할된 워커스텝에 대한 관리를 위해 파티션별로 ExecutionContext를 생성하고, jobRepository와 같은 메타데이터 관리 컴포넌트, 파티션 별 StepExecution을 생성하는 것으로 Splitter의 역할은 종료된다.
이 시점에서, 모든 워커스텝(PartitionStep) 구성이 완료되어, 실행할 수 있는 모든 준비는 끝난다.
@Override
protected void doExecute(StepExecution stepExecution) throws Exception {
stepExecution.getExecutionContext().put(STEP_TYPE_KEY, this.getClass().getName());
// Wait for task completion and then aggregate the results
Collection<StepExecution> executions = partitionHandler.handle(stepExecutionSplitter, stepExecution);
stepExecution.upgradeStatus(BatchStatus.COMPLETED);
stepExecutionAggregator.aggregate(stepExecution, executions);
// If anything failed or had a problem we need to crap out
if (stepExecution.getStatus().isUnsuccessful()) {
throw new JobExecutionException("Partition handler returned an unsuccessful step");
}
}실행 시, PartitionStep의 doExecute를 실행하게 되는데 위 로직 중
Collection<StepExecution> executions = partitionHandler.handle(stepExecutionSplitter, stepExecution);해당 부분에서, partitionHandler.handle을 호출하여, splitter 와 stepExecution에 기반한 분할 및 처리를 진행하게 된다.
이때 stepSplitter의 split()을 호출하고, 내부적으로 partitioner의 partition 메서드를 호출하여 멀티스레드들 본인이 처리할 권역 데이터의 파티셔닝한 영역, stepExecution을 추출해온다. 이때, stepExecution은 워커스레드 별로 생성된 execution 객체들이며, 이 컬렉션이 executions 형태로 담겨져 워커스레드들이 병렬로 처리할 준비과정이 진행되는 것이다.
이후,
doHandle(managerStepExecution, stepExecutions);을 호출하여 워커스레드별 task.execute()가 진행된다.
참고로, StepSplitter의 구현체인 SimpleStepExecutionSplitter를 살펴보면,
@Override
public Set<StepExecution> split(StepExecution stepExecution, int gridSize) throws JobExecutionException {
JobExecution jobExecution = stepExecution.getJobExecution();
Map<String, ExecutionContext> contexts = getContexts(stepExecution, gridSize);
Set<StepExecution> set = new HashSet<>(contexts.size());
for (Entry<String, ExecutionContext> context : contexts.entrySet()) {
// Make the step execution name unique and repeatable
String stepName = this.stepName + STEP_NAME_SEPARATOR + context.getKey();
StepExecution currentStepExecution = jobExecution.createStepExecution(stepName);
boolean startable = isStartable(currentStepExecution, context.getValue());
if (startable) {
set.add(currentStepExecution);
}
}
jobRepository.addAll(set);
Set<StepExecution> executions = new HashSet<>(set.size());
executions.addAll(set);
return executions;
}위와 같이, getContext는 통해 워커스레드의 execution 정보가 담긴 Map객체를 추출해온다.
어디서 많이 본 형태인데, 이 map 객체는
result = partitioner.partition(splitSize);partitioner의 partition 로직에 의해 구분된 데이터 영역 혹은 파일 영역이다.
그 후,
for (Entry<String, ExecutionContext> context : contexts.entrySet()) {
// Make the step execution name unique and repeatable
String stepName = this.stepName + STEP_NAME_SEPARATOR + context.getKey();
StepExecution currentStepExecution = jobExecution.createStepExecution(stepName);
boolean startable = isStartable(currentStepExecution, context.getValue());
if (startable) {
set.add(currentStepExecution);
}
}해당 stepExecution을 순회하면서 jobExecution에 반영하며, 이때 중요한 것은
StepExecution currentStepExecution = jobExecution.createStepExecution(stepName);각 워커스레드 별로 StepExecution 객체를 새롭게 생성한다는 것이다. 이러면 확실히 멀티스레드가 서로를 간섭하여 원자성을 해칠 일은 없다는 것을 유추할 수 있다.
이 정보를 최종적으로
Set<StepExecution> set = new HashSet<>(contexts.size());set에 담고, doHandle을 호출하여, 워커스텝을 실행하는 것이다.
for (final StepExecution stepExecution : partitionStepExecutions) {
final FutureTask<StepExecution> task = createTask(step, stepExecution);
try {
taskExecutor.execute(task);
tasks.add(task);
}TaskExecutorPartitionHandler의 doExecute를 호출하면, 위와 같이 taskExecutor.execute를 호출하게되며, 중요한 것은 이 형태가 비동기로 처리하기 위해 futureTask 기반의 호출형태라는 점이다.
final FutureTask<StepExecution> task = createTask(step, stepExecution);이는,
protected FutureTask<StepExecution> createTask(final Step step, final StepExecution stepExecution) {
return new FutureTask<>(() -> {
step.execute(stepExecution);
return stepExecution;
});
}이와 같이 비동기적으로 step.execute를 처리하게 되며,
해당 task를
taskExecutor.execute(task);taskExecutor에게 전달하여, 스레드 풀 환경에서 운용/관리되도록 한다. 즉, task.execute는 병렬로 실행된다.
for (Future<StepExecution> task : tasks) {
result.add(task.get());
}최종적으로 모든 task가 종료될때까지 모니터링하고, 최종 결과(result)를 반환한다.
이 결과는
Collection<StepExecution> executions = partitionHandler.handle(stepExecutionSplitter, stepExecution);PartitionStep의 doExecute에 다시 전달되어, 워커스텝들의 결과가 저장된 stepExecution 리스트가 반환이 된다.
stepExecution.upgradeStatus(BatchStatus.COMPLETED);
stepExecutionAggregator.aggregate(stepExecution, executions);이 결과들이 최종적으로 매니저스텝(PartitionStep) 측에서 stepExecution 상태를 최신화하고, DefaultStepExecutionAggregator에게 해당 정보를 전달하여 처리정보를 집계한다.
참고로, 워커스텝 중 하나라도 실패한다면 TaskExecutorPartitionHandler 측에서 catch 로직을 통해 실패라고 처리하여, 최종 매니저스텝의 stepExecution 상태는 FAILED 상태로 바뀐다.
public class DefaultStepExecutionAggregator implements StepExecutionAggregator {
/**
* Aggregates the input executions into the result {@link StepExecution}. The
* aggregated fields are
* <ul>
* <li>status - choosing the highest value using
* {@link BatchStatus#max(BatchStatus, BatchStatus)}</li>
* <li>exitStatus - using {@link ExitStatus#and(ExitStatus)}</li>
* <li>commitCount, rollbackCount, etc. - by arithmetic sum</li>
* </ul>
* @see StepExecutionAggregator #aggregate(StepExecution, Collection)
*/
@Override
public void aggregate(StepExecution result, Collection<StepExecution> executions) {참고로, DefaultStepExecutionAggregator의 결과집계가 부족하다면 Customized하여 최종 집계 로직을 맞춤형으로 구현할 수 있다.
6. Remote Chunking
하지만 이러한 멀티스레드, 다중 계층 병렬화는 결국 1개의 서버, 1개의 메인스레드 내부에서 내부적인 멀티스레드, 병렬처리를 진행하는 로컬적인 수준이다.
사실 웬만한 상황에서는 위의 stepExecution 파티셔닝 및 멀티 스레드 병렬처리로 충분하겠지만, 규모가 더 커진다면 아무래도 JVM 1대에서 혹은 서버 1대에서 내부적으로 서브 스레드들을 활용한 병렬화를 한다하더라도 그 처리 효율 및 처리량은 한계가 있을 수 밖에 없을 것이다.
이에 대한 한계를 scale-up 하기위한 방안이 바로 서버를 여러대 두어, 절대적인 물리적 크기 자체를 늘리는 다중 처리 방식에 대한 고민이 바로 Remote Chunking의 핵심이다.
이 Remote Chunking의 방법은 두가지가 존재한다.
- 데이터 파티셔닝을 원격의 다수 워커스텝으로 진행하여 분할한다.
- 청크 처리를 멀티스레드 기반으로 진행하되 이 멀티스레드를 원격으로 다수의 멀티스레드로 분할한다.
일전에 살펴보았던 다중 계층의 병렬화를 한 발 더 나아가, 원격 서버를 통해 그 처리 수를 늘린다는 방향으로 이해하면 되겠다.
6-1. Remote Partitioning
일전의 워커스텝 기반의 멀티스레드 병렬 처리의 경우, 각 워커 스텝이 파티셔닝된 데이터 영역을 구분하여 처리하므로 스레드 별로 간섭을 받지 않고 독립적으로 작업을 비동기적으로 수행하여 처리 속도, 효율이 개선되었다는 장점이 있었다.
하지만, 이는 단일 JVM의 main thread 내부에서 멀티스레드를 파생하는 방향에서 각 워커스텝별로 stepExecution 객체도 완전히 새로 생성하고, 처리 대상 데이터를 해당 객체에 반영하기 위해 요구되는 참조객체, 메모리 요구량은 그만큼 많아질 수 밖에 없다.
공유객체의 한계는 없어졌지만, 역설적으로 전체적인 메모리 사용량으로 인한 OOM 한계에 근접하게 된다는 것이다.
이처럼 단일 JVM 환경 하, CPU core/native memory와 함께 별도의 I/O에 소모되는 비용까지, 기본적으로 물리적인 한계가 존재할 뿐만 아니라 이를 실행하는 OS의 성능적 영향을 많이 받을 수 밖에 없다.
만약 로컬JVM에서의 멀티스레드, 청크처리에 대한 멀티스레드 등을 다수의 서버를 통해 진행하는 방식으로 물리적 한계를 극복하는 것이 핵심 방향이며, 그 중 하나가 바로 파티셔닝, 워커스텝에 대한 원격처리(Remote Partitioning)이다.
로컬JVM에서, 워커스텝을 다수 서버 배치 및 원격 기동이 이루어진다면 자연스럽게 JVM의 수평적 확장이 이루어진다(Horizontal Scalbitity). 또한 이에 따라 대규모 데이터를 처리할 수 있는 절대적인 용량 자체가 늘어난다.
Remote Partitioning의 핵심은 Message Queue를 중재자로 배치하는 것이다.
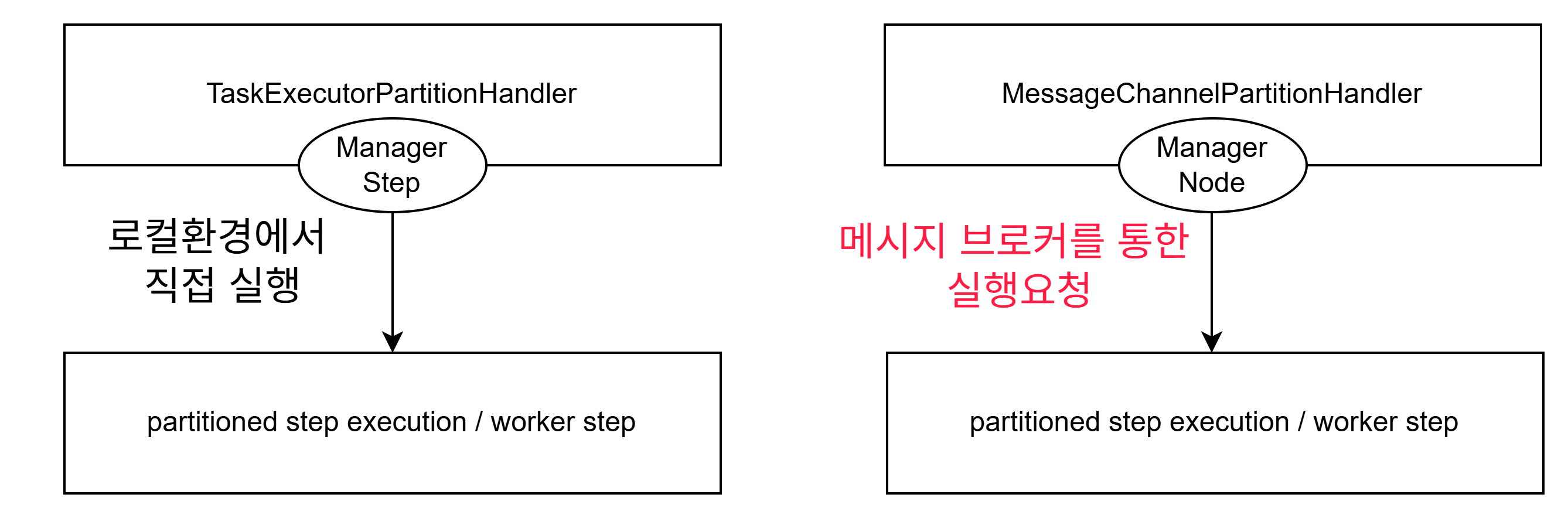
-
로컬에서의 managerStep이 아닌 중앙관리소 격인 managerNode가 TaskExecutorPartitionHandler가 아닌, MessageChannelPartitionHandler를 통해 파티션을 생성 및 실행요청을 한다. 이때 Message Broker를 통해 다수의 원격 워커스텝에게 실행요청을 전달한다. ManagerStep이 워커스텝을 직접 실행하는 과정에서, managerNode가 메시지브로커를 통해 실행요청을 전달한다.
-
Manager Node, 원격 워커스텝 간의 비동기 통신을 중재하며, stepExecution 생성요청 및 작업종료 메시지 등에 대해 Queue 기반의 순차적, 안정적인 메시지 통신을 중간에서 관리한다. 기본적인 고가용성을 보장해야 하기에, Kafka 및 RabbitMq와 같은 안정적인 중개 시스템을 놓아야 가능하다.
-
워커노드 : 실질적인 작업 처리를 진행하는 노드로, 다수로 포진된 원격 JVM 환경하에 만들어진 partitioned stepExecution 객체들이다. 워커노드들은 메시지 브로커의 본인이 해당되어있는 토픽을 구독하면서 처리 요청을 모니터링하며, stepExecution 생성 요청이 왔을때 이를 consuming하고 연산을 처리한다.
워커노드에 stepExecution 생성 요청을 하고, 워커노드는 이를 수신받아 itemReader로 부터 이어지는 worker step을 실행한다. 기존의 manager Step의 직접 실행이 아닌, manager Node가 메시지 브로커 시스템을 통해 전송한 메시지에 의해 비동기적인 호출(실행 trigger)가 이루어지고, 이에 따른 원격의 워커스텝의 step 실행이 진행된다.
이때 최종적인 jobRepository를 통한 상태관리는 managerNode 측의 jobRepository를 통해 aggregate, 통합 관리된다.
6-2. Configuration - integration의 필요성
가장 먼저 필요한 라이브러리 의존성 결합은 Spring Integration에 대한 것이다.
외부 시스템 A → 처리 → 외부 시스템 B위와 같이 외부 시스템으로부터 데이터를 받고, 조건에 따라 필터링 및 가공을 하여 또다른 외부 시스템으로 전송하며, 실패하면 재시도하는 체계가 있다고 하자.
이를 만약 일반적인 web mvc 및 java 로직으로 구성해야 한다면, 아래와 같다.
public void process() {
List<Data> list = clientA.fetch();
for (Data data : list) {
// 1. 필터
if (!isValid(data)) {
continue;
}
// 2. 변환
Transformed t = convert(data);
// 3. 전송 + 재시도
int retry = 0;
while (true) {
try {
clientB.send(t);
break;
} catch (Exception e) {
retry++;
if (retry >= 3) {
log.error("fail", e);
break;
}
}
}
}
}즉, 데이터 리스트를 fetch해오고 이 리스트를 순회하면서, 데이터를 필터링(if)하고, 외부 시스템으로 전송하고 실패에 대한 후처리를 위해 try-catch 로직을 구성해주었다.
이러한 연동 및 흐름에 대한 전체적인 로직을 직접 구성해주어야 하는데, spring integration 활용 시
IntegrationFlows.from(clientA())
.filter(this::isValid)
.transform(this::convert)
.handle(clientB())
.get();위와 같이 fetch(메시지 통로) 및 filter(필터링), 데이터 변환(transform) 등의 흐름을 integration에서 제공하는 빌더패턴을 구성해도록 api를 한번에 제공하는 효과를 기대할 수 있다.
또한 예를 들어, 성공 시 상태정보를 저장하고 실패 시 file log를 작성하는 후처리 로직이 있다고 하자.
try {
step1();
step2();
step3();
} catch (AException e) {
handleA();
} catch (BException e) {
handleB();
}위와 같이 Exception이 많아지고 다양해진다면, CheckedExecption을 추가적으로 구성해주고 로직이 비대해져 최초 의도하였던 구조에서 많은 보완이 필요해질 것이다.
IntegrationFlows.from(input())
.handle(dbHandler(), e ->
e.advice(retryAdvice())
.errorChannel("failChannel")
)
.get();
IntegrationFlows.from("failChannel")
.handle(fileWriter())
.get();이에 대한 Exception 처리도 위와 같이 빌더패턴에서 제공하는 api로 간결하게 해줄 수 있다.
뿐만 아니라,
IntegrationFlows.from(input())
.channel(asyncChannel())
.handle(this::process)
.get();위와 같은 스레드 풀을 연계하여 비동기 처리를 진행한다던가,
IntegrationFlows.from(input())
.publishSubscribeChannel(c -> {
c.subscribe(f -> f.handle(db()));
c.subscribe(f -> f.handle(file()));
c.subscribe(f -> f.handle(kafka()));
})
.get();Event Driven 구성을 통해 구독 설정을 손쉽게 해줄 수도 있다.
좀 더 쉽게 설명하겠다.
정리해보자면, Application과 Kafka/RabbitMq와 같은 외부통신체계를 연결하는 다리의 역할을 하여, 두 체계사이의 메시지 채널 및 흐름, 구독관계를 dsl api로 정립하여 제공해주는 역할을 하는 것이 바로 Integration flow이다.
(Batch) <--> (원격 체계: Kafka 등)이러한 통신이 필요하다고 하자.
//fro manangerNode
kafkaTemplate.send(...);
@KafkaListener
public void consume(...) {
jobLauncher.run(...);
}기본적으로는 위와 같이, kafkaTemplate을 통해 메시지를 전송(send)하고, 이에 대해 구독관계에 있는 객체 및 메소드를 지정(KafkaListener)하여 메시지 송수신 관계 및 처리에 대해 정의한다.
이 경우 Kafka 라이브러리에 대한 의존성이 상당히 높아지는데,
Spring integration을 활용하면 해당 api를 활용하여, 메시지의 상태나 형태 등은 상관없이 application의 메시지 송수신, 연결관계에 대해서만 집중할 수 있게 된다.
또한 다양한 기능을 제공하여 integration 활용만으로 가독성 및 응집도를 많은 부분 향상시킬 수 있다.
- 채널 (Direct / Queue / PublishSubscribe)
- 구독 관계
- 라우팅
- 변환
- 필터링
- 재시도 / 에러 채널
application > Kafka
``java
[Batch Step]
|
v
[MessageChannel]
|
v
[Kafka Outbound Adapter] ---> Kafka
> Kafka > application
```java
Kafka ---> [Kafka Inbound Adapter]
|
v
[MessageChannel]
|
v
[Batch Job / Step]
참고로, 이러한 Integration 프레임워크를 활용하여 구성한 하나의 흐름, 메시지가 어디서 시작해서, 어떤 채널을 거쳐, 무엇을 거쳐, 어디로 끝나는지에 대해 정의한 구체적인 파이프라인이 바로 Flow이다.
6-3. Configuration - Kafka/ManagerNode
위 "외부 통신 체계"로 사용할 Kafka를 사용할 예정이며, Kafka를 통해 manager node가 stepExecution 생성 "요청"을 각 네트워크의 워커 스텝에게 전달한다(subscribe).
이에 대한 구성을 위해 Kafka 관련 의존성을 추가한다.
implementation 'org.springframework.kafka:spring.kafka'
implementation 'org.springframework.integration:spring-integration-kafka'그리고 manager node에 대한 설정을 진행한다.
[ Manager Node ] [ Worker Node들 ]
- Job 시작 - Step 실행
- Partitioner 실행 - ItemReader/Processor/Writer
- StepExecution 생성
- StepExecutionRequest 전송위와 같이, remote partitioning 구조에서는 manager node가 워커 노드에게 stepExecutionRequest를 전송하는 구조로, Manager Node(Producer)와 Worker Node(Consumer)에 대한 역할 분담 및 책임 분리가 필요하다.
이를 위해, spring batch 실행 시 manager 노드 및 worker 노드 실행 시, 해당 실행 시점에서만 본인에게 맞는 빈 객체를 실행하도록 유도할 수 있다.
이것이 @Profile 어노테이션의 명세이다.
또한, kafka를 integration 기반의 stepExecutionRequest 생성 및 전송, 이를 메시지화하여 outputChannel로 전송하는, spring batch integration 프레임워크를 활성화할 수 있게 된다.
이것이 @EnableBatchIntegration 어노테이션의 명세이다.
이러한 필수적인 어노테이션을 활용하고,
@Profile("manager")
@EnableBatchIntegration
@Configuration
@AllArgsConstructor
@Slf4j
public class ManagerConfiguration {
private final JobRepository jobRepository;
private final RemotePartitioningManagerStepBuilderFactory remotePartitioningManagerStepBuilderFactory;
private final DailyTimeRangePartitioner dailyTimeRangePartitioner;이러한 명세를 통해, manager 프로파일로 실행될 경우에만
Spring Batch Job을 Remote Partitioning Manager 역할로 실행하고(객체분리실행),
@EnableBatchIntegration을 통해 StepExecution을 Spring Integration 메시지로 변환하여 Kafka로 전송할 수 있도록 한다.
그리고, managerNode의 심장이라할 수 있는 managerStep을 구성한다.
@Bean
public Step managerStep() {
return remotePartitioningManagerStepBuilderFactory
.get("managerStep")
.partitioner("workerStep", dailyTimeRangePartitioner)
.outputChannel(outboundRequestsToWorkers())
.gridSize(4)
.build();
}이를 잘 살펴보면, RemotePartitioningManagerStepBuilderFactory 형태의 remotePartitioningManagerStepBuilderFactory를 주입받아 빌더패턴에 그대로 활용하는 것을 확인할 수 있다.
애초에, remote partitioning이라는 batch 전략을 사용할 경우, 이에 맞는 빌더패턴 구현체를 제공하는 것이며, 실제로도 원격 워커노드에 stepExecutionRequest를 전송하기 위해서는 일반적인 SimpleStepBuilder가 아닌 remotePartitioningManagerStepBuilderFactory 구현체를 사용해야 한다.
이 구현체는 내부적으로 AbstractPartitionHandler 부모클래스를 상속한 remote partitioning 맞춤형 구현체, MessageChannelPartitionHandler를 partitionHandler 구현체로 사용한다(일반 파티셔닝의 구현체는 TaskExecutorPartitionHandler이다).
또한, 위 managerNode의 managerStep을 보면 step을 구성하지 않는다, 즉 managerStep 측에서 직접 실행할 workerStep을 지정해주지 않고 대신 원격의 워커스텝을 실행하기 위한 outputChannel를 구성해주어야 한다.
┌─────────────┐
│ Manager │
│ (Job 실행) │
└──────┬──────┘
│
▼
┌──────────────────────────┐
│ managerStep (Partition) │
└──────┬───────────────────┘
│ ① Partitioner 실행
▼
┌──────────────────────────┐
│ ExecutionContext 분할 │ ← DailyTimeRangePartitioner
│ (partition0 ~ partition3)│
└──────┬───────────────────┘
│ ② StepExecution 생성 (4개)
▼
┌──────────────────────────┐
│ StepExecutionRequest │
│ (stepExecutionId 포함) │
└──────┬───────────────────┘
│ ③ Message 로 변환
▼
┌──────────────────────────┐
│ outputChannel() │ ← DirectChannel
└──────┬───────────────────┘
│ ④ IntegrationFlow
▼
┌──────────────────────────┐
│ Kafka Topic │
│ remote-partitioning │
└──────┬───────────────────┘
│
▼
┌──────────────────────────┐
│ Worker Consumer │
│ StepExecutionRequest 수신 │
└──────┬───────────────────┘
│
▼
┌──────────────────────────┐
│ workerStep 실행 │
│ (Reader/Processor/Writer)│
└──────────────────────────┘먼저 위 도식을 살펴보자. ManagerNode 측에서 Job을 실행, 이후 단계적으로 managerStep을 통한 stepExecution partitiong 및 stepExecutionRequest를 거친다.
최종적으로 이를 메시지로 변환(직렬화) 하여 outputChannel를 통해 kafka 메시지 큐에 integration flow 기반의 동작으로 전달한다.
outputChannel은 어디로 보낼지 "구성"의 역할이고, 실질적으로 메시지를 전송하는 주체는 integration측에서 send()를 호출하여 진행한다.
그 이후는 원격 서버에 지정되어있는 workerStep(Reader ~)에 처리 책임이 위임된다.
@Bean
public IntegrationFlow outboundFlow(KafkaTemplate<Long, StepExecutionRequest> kafkaTemplate,
StepExecutionPartitionRouter stepExecutionPartitionRouter) {
KafkaProducerMessageHandler<Long, StepExecutionRequest> messageHandler =
new KafkaProducerMessageHandler<>(kafkaTemplate);
messageHandler.setTopicExpression(new LiteralExpression("remote-partitioning"));
messageHandler.setPartitionIdExpression(new FunctionExpression<>(
stepExecutionPartitionRouter::routeToKafkaPartition));
return IntegrationFlow
.from(outboundRequestsToWorkers())
.log()
.handle(messageHandler)
.get();
}outputChannel()을 통해 메시지가 integration flow 상에 들어왔다면, 워커스텝으로 stepExecutionRequest를 전송하기 위한 outboundFlow 객체를 활성화한다(해석한다가 더 정확한 표현).
자세히 보면, IntegrationFlow에서 하나의 "통로"가 이어지는 것을 확인할 수 있다.
- from outputChannel, manager step
.outputChannel(outboundRequestsToWorkers())- to integration flow, flow 입장에서는 통로(from)
.from(outboundRequestsToWorkers()) 그리고, 실질적인 메시지 전송이 바로 flow.handle을 통해 이루어지며, 이 핸들러를
KafkaProducerMessageHandler<Long, StepExecutionRequest> messageHandler =
new KafkaProducerMessageHandler<>(kafkaTemplate);위와 같이 KafkaProducerMessageHandler 구현체로 구성한다. 참고로 이 Handler 구현체 내부에서 kafkaTemplate.send()를 호출하여, 토픽의 구독자가 이를 감지하여 동작하도록 후속동작을 취한다.
messageHandler.setTopicExpression(new LiteralExpression("remote-partitioning"));이를 위해, kafka의 메시지를 "어디에" 일단 저장하여 파티셔닝할 것인가, kafka topic을 지정하는 단계를 누락하지 않도록 한다.
Kafka Topic: remote-partitioning
┌───────────────┬───────────────┬───────────────┬───────────────┐
│ Partition 0 │ Partition 1 │ Partition 2 │ Partition 3 │
│ StepExec A │ StepExec B │ StepExec C │ StepExec D │
└───────────────┴───────────────┴───────────────┴───────────────┘topic은 하나이다. 단지, 내부적으로 partitioner를 구성한 그대로 kafka 역시 파티션 구역을 나누는 것이며, 해당 파티션 구역에 stepExecutionRequest를 전송,
Worker A ← Partition 0
Worker B ← Partition 1
Worker C ← Partition 2
Worker D ← Partition 3분리된 워커스텝은 하나의 파티션을 맡게되어 메시지를 구독하고, 요청을 감지하여 실질적인 step 동작을 처리한다.
이 책임할당방식은 round robin보다는,
messageHandler.setPartitionIdExpressionhandler에 지정한 partitionIdExpression 방식에 의해 정립이 되며, 이때
StepExecutionPartitionRouter stepExecutionPartitionRouterpartitionRouter를 통해, 생성된 메시지를 kafka의 어떠한 Id로 전송할지 선택하게 된다.
Worker A ← Partition 0,2
Worker B ← Partition 1,3참고로, 만약 파티션 권역 개수보다 워커의 개수가 낮다면, 효과적인 병렬처리를 보장할 수 없을 것이다.
@Bean // <--- (5) Spring Batch 파티션과 카프카 토픽 파티션 매핑
public StepExecutionPartitionRouter stepExecutionPartitionRouter() {
return new StepExecutionPartitionRouter(4);
}
// (5)
public static class StepExecutionPartitionRouter {
private final int partitionSize;
public StepExecutionPartitionRouter(int partitionSize) {
this.partitionSize = partitionSize;
}
public Long routeToKafkaPartition(Message<StepExecutionRequest> message) {
StepExecutionRequest executionRequest = message.getPayload();
long stepExecutionId = executionRequest.getStepExecutionId();
long kafkaPartitionId = stepExecutionId % partitionSize;
log.info("Step Execution Id: {} Kafka Partition Id: {}",
stepExecutionId, kafkaPartitionId);
return kafkaPartitionId;
}
}마지막으로, 위에서 기술하였듯이 managerStep에서 생성한 stepExecution을 kafka의 어떠한 구역(id)로 보낼지, StepExecutionPartitionRouter를 통해 정한다.
즉 spring batch 파티션과 kafka 파티션을 연결하는 연결다리와 같은 역할을 하며,
long stepExecutionId = executionRequest.getStepExecutionId();
long kafkaPartitionId = stepExecutionId % partitionSize;위와 같이 executionRequest의 id값을 4개의 권역으로 나누어 관리하고자, 4로 나눈 나머지값을 kafka 파티션 id로 매핑한다.
위의 경우,
StepExecution 1 5 9 -> kafka partition 1
StepExecution 2 6 10 -> kafka partition 2
StepExecution 3 7 11 -> kafka partition 3
StepExecution 4 8 12 -> kafka partition 4위와 같은 형태로 stepExecution이 kafka 파티션에 전달되어, 해당 파티션에 따라 워커스텝을 할당하여 처리하게 되며, Router의 경우 파티션을 매핑하기 위한 로직을 직접 구성해주어야 한다.
Kafka 내부적으로는, 한 파티션에는 1개의 구독자(Consumer)만 존재하기에, 워커스텝 입장에서는 반드시 하나의 파티션만 구독해야 하는데, Kafka Consumer 측의 관심사는 사실 "topic"이다. 한 topic 내부에서 관리중인 다수의 파티션에 할당되는 워커스텝(구독자) 규칙은 Kafka의 “컨슈머 그룹 리밸런싱”이 결정한다.
6-4. Kafka/WorkerNode
이제는 요청을 받아 처리하는 consumer, 즉 워커노드의 "워커스텝" 구성 방안에 대해 분석해보자.
기본적으로 workerNode 설정을 위해 Profile 및 SpringIntegration까지 구성해주도록 한다.
@Profile("worker")
@EnableBatchIntegration // <--- (1)
@Configuration
@AllArgsConstructor
@Slf4j
public class WorkerConfiguration {워커노드는 단일 JVM에서 생성된 managerStep에 의한 직접적인 실행이 아닌, 원격 중앙통제소의 managerNode로부터 stepExecutionRequest 요청을 메시지를 생성 및 전달, 이것을 Kafka 파티션에 전달하여 최종적으로 이 메시지를 워커노드가 전달받는 형태이다.
이를 근거로, 워커노드는 오로지 전달받은 stepExecution 요청에 구독(응답) 및 처리만을 담당하여, job 구성은 없고 오로지 Step에 대한 로직만 존재한다.
그 후, 메시지를 수신받고 송신할 inputChannel, outputChannel을 반드시 설정해주어야 하며, 이때 inputChannel은 managerNode에서 구성한 outputChannel과 이어지는 통로이다.
return remotePartitioningWorkerStepBuilderFactory.get("workerStep")
.inputChannel(inboundRequestsFromManager)
.outputChannel(outboundRequestsToManager)워커노드 마찬가지로 remotePartitioningWorkerStepBuilderFactory 구현체를 사용하여 빌더패턴을 구성해주고, 위와 같이 입력, 출력 채널을 지정해주면 되겠다(RemotePartitioningWorkerStepBuilder가 사용됨).
또한, 워커노드는 실질적인 처리를 담당하기에,
.reader(redisLogReader)
.processor(logProcessor)
.writer(mongoLogWriter)위와 같이 처리를 위한 reader, processor, writer를 구성해주면 되겠다.
더불어, 메시지 수신 채널을 spring integration flow에 사용하여, 해당 메시지 수신 채널을 kafka, 그 중에서도 관심있는 토픽에 대한 메시지 통로를 만들기 위해 integration flow를 설정해두록 한다.
@Bean
public QueueChannel inboundRequestsFromManager() {
return new QueueChannel();
}
@Bean
public IntegrationFlow inboundFlow(ConsumerFactory<String, String> cf) {
return IntegrationFlow
.from(Kafka.messageDrivenChannelAdapter(cf, "remote-partitioning"))
.channel(inboundRequestsFromManager())
.get();
}inboundFlow의 경우 inbound통로에 대한 adapter를 구성해주었고, 그 다음 단계로 해당 메시지를 비동기, 순차적 대기큐를 활용하기 위해 inboudRequestsManager(QueueChannel)를 구성해주었다.
참고로,
return new DirectChannel();DirectChannel의 경우 큐, 대기작업 및 버퍼링없이 메시지를 send한 스레드가 바로 메시지를 보내는 handler.handle 처리를 즉시 진행한다.
즉, 해당 스레드가 작업을 대기 큐에 쌓지 않고 바로 메시지를 보내는 동기처리이다(sender Thread send() 와 handler.handle()이 서로 동기적 관계).
return new QueueChannel();QueueChannel의 경우 비동기 방식, sender Thread가 보낸 요청 메시지를 일단 QueueChannel에 보관하여 consumer가 폴링 혹은 message driven 방식으로 처리하는 방식이다(sender thread()의 요청에 즉시 반응하는 것이 아닌 대기큐 저장을 거쳐 처리를 진행).
이에 대한 integration 파이프라인을 flow를 통해 구현하였다면, 해당 파이프라인을 통해 메시지가 송수신 될 수 있는 기초 뼈대가 만들어진것이다.
6-5. Batch의 영역 vs Integration flow의 영역
Manager Node와 Worker Node 간의 메시지 교환이 어떻게, 어떤 규칙으로 이루어지는지 한번 살펴보자.
이를 좀 더 "효율적"으로 이해하기 위해서는, Batch의 영역과 Integration의 영역을 구분하여 이해하는 것이 좋겠다.
- Batch
Batch의 영역에서는 데이터를 어떻게 나누고(partitioner), 이 나눈 데이터들을 어떤 파티션에 구획할지(partitionId), 그리고 무슨 정보를 전달해주어야 할지(stepExecution/executionContext), 최종적으로 이 정보를 전달받아 처리하는(stepExecuting) 등에 대한 책임을 맡고 있다.
즉, 정보의 내용과 구획에 대한 규칙, 정보처리 등에 대한 영역이 바로 Batch 측 역할이다.
- Integration
반면 integration(Flow를 통한 파이프라인 구성)은 말 그대로 파이프라인 구성, "메시지 전달 체계"에 대한 정립에 주 목적이 있다.
. 메시지로 감싸기
. 채널에 태우기
. Kafka / JMS / AMQP로 보내기
. Worker 쪽으로 흘려보내기
와 같이, 전송 수단 및 메시지 흐름에 대한 구조적 관점에서 Integration이 맡는 역할이라 보면 되겠다.
또한 핵심 요소는 바로 이러한 정보들을 "메시지"로 Wrapping하여 전달하는 것인데,
Message<StepExecutionRequest>위와 같이 request(요청)을 보내면 이를 메시지화하여 Kafka로 전달해주는 것이 바로 Integration의 중요 역할이다. 이후 integration Inbound Adapter를 통해 구독하고 있는 토픽, 할당받은 파티션의 메시지를 수신받아 Request를 꺼내어, 해당 stepExecutionContext를 바탕으로 step을 실행하는 것이 전체적인 흐름이다.
Manager side
Partitioner
↓
StepExecutionRequest
↓
MessageChannel
↓
Kafka Outbound AdapterWorker side
Kafka Inbound Adapter
↓
MessageChannel
↓
StepExecutionRequestHandler
↓
Step 실행flow는 말 그대로 "흐름"을, batch는 "정보생성과 실행"에 그 역할이 있다.
6-6. RemotePartitioningManagerStepBuilder/RemotePartitioningWorkerStepBuilder
이러한 이해를 바탕으로 좀 더 구체적으로 살펴보도록 하자.
Manager Node side
RemotePartitioningManagerStepBuilder 구현체의 build() 메서드 호출 시,
this.messagingTemplate = new MessagingTemplate();
this.messagingTemplate.setDefaultChannel(this.outputChannel);위와 같이 messagingTemplate 객체를 생성하고, 빌더패턴에서 구성한 outputChannel을 등록해주는 것을 확인할 수 있다. messagingTemplate을 통해 메시지 전송이 일어난다.
그 후,
final MessageChannelPartitionHandler partitionHandler = new MessageChannelPartitionHandler();
partitionHandler.setStepName(getStepName());
partitionHandler.setGridSize(getGridSize());
partitionHandler.setMessagingOperations(this.messagingTemplate);
...
super.partitionHandler(partitionHandler);위와 같이 partitionHandler의 구현체인 MessageChannelPartitionHandler 객체를 생성하여, stepBuilder로 구성해주었던 partitioner(데이터 구획을 나눈 후, 이에 대한 stepExecution 생성)를 등록한다.
여기서 정해진 partitionHandler는
@Override
protected void doExecute(StepExecution stepExecution) throws Exception {
stepExecution.getExecutionContext().put(STEP_TYPE_KEY, this.getClass().getName());
// Wait for task completion and then aggregate the results
Collection<StepExecution> executions = partitionHandler.handle(stepExecutionSplitter, stepExecution);추후 PartitionStep에서 해당 partitionHandler를 통해 데이터 분할 및, 분할된 데이터의 파티션 지정 및 그 파티션으로 stepExecution을 생성하여 전송 할 수 있도록 한다(ManagerStep Side).
이제 integration flow의 진정한 힘이 나오는데, 위에서 생성한 "정보"를 MessageChannelPartitionHandler의 doHandle을 통해 생성한 stepExecution 정보들을 stepExecutionRequest로 담아 message로 wrapping한다.
Message<StepExecutionRequest> request = createMessage(count++, partitionStepExecutions.size(),
new StepExecutionRequest(stepName, stepExecution.getJobExecutionId(), stepExecution.getId()),
replyChannel);위와 같이, flow 측에서 메시지를 생성하고 이를 전송(전달)한다.
Worker Node side
Worker Node는 RemotePartitioningWorkerStepBuilder를 워커스텝의 구현체로 사용한다.
이때,
ate void configureWorkerIntegrationFlow() {
...
StepExecutionRequestHandler stepExecutionRequestHandler = new StepExecutionRequestHandler();
stepExecutionRequestHandler.setJobExplorer(this.jobExplorer);
stepExecutionRequestHandler.setStepLocator(this.stepLocator);workerNode 측에서는 Manager Node가 Kafka에 전달하여 수신한 메시지(stepExecutionRequest) 요청에 대해 handling할 StepExecutionRequestHandler 객체를 생성하는 것 부터 시작한다.
StandardIntegrationFlow standardIntegrationFlow = IntegrationFlow.from(this.inputChannel)
.handle(stepExecutionRequestHandler, SERVICE_ACTIVATOR_METHOD_NAME)
.channel(this.outputChannel)
.get();이후 메시지를 처리할 핸들러 객체와 처리 이후 메시지를 수신받고 수신할 inputChannel 및 outputChannel, 처리 주체인 handler를 구성하고,
integrationFlowContext.registration(standardIntegrationFlow).autoStartup(false).register();이를 integration flow에 등록해준다. 이 시점에 kafka와 workerNode 간의 연결관계가 성립된 것이다.
6-7. StepExecutionRequestHandler
StepExecutionRequestHandler 구현체에선 정보를 어떻게 처리하고 step을 실행하게 될까?
일단 구현체 이름부터 유추할 수 있듯이, stepExecutionRequest 정보로부터 필요 정보를 추출하고, 실제 스텝 실행을 담당한다.
@ServiceActivator
public StepExecution handle(StepExecutionRequest request) {
Long jobExecutionId = request.getJobExecutionId();
Long stepExecutionId = request.getStepExecutionId();
StepExecution stepExecution = jobExplorer.getStepExecution(jobExecutionId, stepExecutionId);
if (stepExecution == null) {
throw new NoSuchStepException("No StepExecution could be located for this request: " + request);
}
String stepName = request.getStepName();
Step step = stepLocator.getStep(stepName);
if (step == null) {
throw new NoSuchStepException(String.format("No Step with name [%s] could be located.", stepName));
}
try {
step.execute(stepExecution);
}
...
return stepExecution;
}최초 jobExecutionId 및 stepExecutionId를 매개변수객체인 StepExecutionRequest로부터 그대로 전달받고 생성하여, jobExecutionId, stepExecutionId 및 stepExecution 객체를 생성하는 과정을 확인할 수 있다. 또한 중간에 step.execute()하여 Worker step을 실행하는 것까지 살펴볼 수 있다.
이에 대한 상태관리(jobRepository) 동작은 일전에 살펴보았던 일반적인 메타데이터 관리 동작과 일치한다.
6-8. MangerNode의 WorkerNode의 일관성 유지/보장 전략 Remote Partitioning Aggregation(MessagePartitionHandler/RemotePartitioningManagerStepBuilder)
위 구성만으로는 동작 자체는 가능하지만, 모든 원격 worker node들의 일관된, 온전한 step 실행완료를 보장할 수 없고, 이에 대한 상태파악도 불가능하다.
partitioner를 적용했을때, 메인 스레드의 managerStep이 파티셔닝된 데이터 및 이에 따른 워커스텝을 "실행"시키고, 각 실행한 워커스텝들의 결과를 누적하면서 하나라도 처리실패 시 최종 FAILE처리 했던 것을 기억하는가?
remote partitioning 역시 마찬가지로, 하나의 원격 스텝이 실패하더라도 job을 실패처리하는 일관성을 유지 및 보장할 수 있는 세부 전략 구현이 반드시 필요하다.
이 역할을 해주는 구현체가 Manager Node side의 MessageChannelPartitionHandler이다.
이 핸들러 구현체는 stepExecutionReqeust 메시지를 전송해주는 역할을 하였지만, 나아가 워커노드들의 결과를 취합하고 집계하는 역할까지 수행한다.
해당 구현체의 send() 메소드 이후의 로직을 살펴보면,
if (!pollRepositoryForResults) {
return receiveReplies(replyChannel);
}
else {
return pollReplies(managerStepExecution, partitionStepExecutions);
}위와 같이 구성환경에 따라, worker node로부터 응답 메시지를 직접 수신받는 receiveReplies, manager node의(어차피 이를 실행하는 주체가 manager node) jobRepository를 polling을 통해 주기적으로 조회하여, 모든 worker stepExecution의 상태내역을 조회하고 최종 완료(COMPLETED or FAILED) 상태를 조회할 때까지 대기한다.
기본적인 구성방식이 정해져있지 않다면, pollReplies 방식을 활용하며, pollInterval(폴링주기)에 기반하여 jobRepository를 조회, 여기서 모든 worker stepExecution의 상태를 살핀다. 이 상태를 모두 살피기전까지 polling을 지속하고, 모든 stepExecution 상태 확인 시 결과를 취합(aggregate)한다.
참고로 timeout을 설정하여, 워커노드 측의 응답이 없을 경우, managerNode가 무한히 대기하지 않도록 설정한다.
메시지 방식을 설정해주었다면, worker node의 outputChannel에 대응되는 manager node의 inputChannel을 반드시 설정해주어야하고, 해당 설정을 통해 자동적으로, MessagePartitionHandler는 "메시지 기반 응답"이라는 것을 인지하게 된다.
또한 managerNode의 inputChannel 구성여부에 따라, RemotePartitoningManagerStepBuilder의 동작이 달라진다.
if (isPolling()) {
partitionHandler.setJobExplorer(this.jobExplorer);
partitionHandler.setPollInterval(this.pollInterval);
partitionHandler.setTimeout(this.timeout);
}이처럼 polling 방식 기반일 경우(inputChannel 없음), partitionHandler에 폴링 환경구성을 하고,
else {
PollableChannel replies = new QueueChannel();
partitionHandler.setReplyChannel(replies);
StandardIntegrationFlow standardIntegrationFlow = IntegrationFlow.from(this.inputChannel)
.aggregate(aggregatorSpec -> aggregatorSpec.processor(partitionHandler))
.channel(replies)
.get();
IntegrationFlowContext integrationFlowContext = this.beanFactory.getBean(IntegrationFlowContext.class);
integrationFlowContext.registration(standardIntegrationFlow).autoStartup(false).register();
}메시지 방식 기반일 경우(inputChannel 있음), 위와 같이 해당 채널을 integrationFlow에 반영하여, 메시지를 주고받을 수 있는 다리가 세워진다.
이 "다리"를 기반으로, manager 측에서 consumer 측에 전달할 메시지 생성 시 같이 정립한 고유번호인 correlationId(consumer 측에서 메시지를 보낼때 해당 id값을 그대로 활용)를 사용하여 그룹을 만들고, 해당 그룹에서 응답받아야 할 메시지 개수(sequenceSize)를 지속적으로 확인하면서 개수가 부합할때까지 메시지 수신을 대기한다.
물론, 타임아웃 시간을 설정하여 적정시간동안의 응답이 없다면 FAILED 처리를 할 수도 있다.
이후, @Aggregate 어노테이션 명세에 의해 aggregate() 메서드를 호출하여, 수집된 메시지 페이로드를 분석하고, 해당 분석내역을 List<StepExecution>으로 Wrapping하여 내부적으로 replies 채널인 QueueChannel로 전송된다.
private Set<StepExecution> receiveReplies(PollableChannel currentReplyChannel) {
Message<Set<StepExecution>> message = (Message<Set<StepExecution>>) messagingGateway
.receive(currentReplyChannel);
if (message == null) {
throw new MessageTimeoutException("Timeout occurred before all partitions returned");
}
else if (logger.isDebugEnabled()) {
logger.debug("Received replies: " + message);
}
return new HashSet<>(message.getPayload());
}이는, 구체적으로 MessageChannelPartitionHandler.receiveReplies() 메서드를 통해 수신되어, 다수의 worker에 대한 응답을 취합하여 일관된 job 상태를 보장할 수 있도록 한다.
참고. 원격 파티셔닝 적용은 완벽하지 않으면 권장하지 않는 전략이다.
일단, 기본적으로 원격 파티셔닝은 Spring batch를 넘어, spring integration에 대한 이해를 요구하는 상당히 고급 수준의 전략이다.
일단 두 프레임워크 이해만으로는 어렵고, 정확한 목적과 아키텍칭 등 완벽한 설계가 뒷받침되어야 원격 파티셔닝 적용이 가능하다.
Spring integration 프레임워크 도입으로 인한 비용 상승
- Message, worker 간의 채널 통신 구축 및 전송(라우팅), Aggregation 등의 복잡한 파이프라인 구축과 관리 등 수준 높은 운용지식을 요구한다.
- Kafka, RabbitMQ와 같은 메시지 미들웨어를 반드시 혼용을 해야하며, 이로 인한 설치, 클러스터링, 관리 비용 추가는 감수해야 하는 부분이다.
이 감수를 해야할 정도로 성능이 부족한가? - 워커스텝을 다중 JVM 환경, 즉 분산 서버에서 관리하는 분산 시스템의 side effect 고려가 필수적이다. 가령, 네트워크 오류 및 메시지 유실, 노드 관리, 분산 트랜잭션 등 메시지 생성 부터 모니터링(추적)까지 고려해야할 부분이 한두가지가 아니다.
메타데이터 저장소 변경으로 인한 운용비용 증가
ManagerNode - WorkerNode로 이어지는 stepExecution(step실행정보 및 파티션 정보 등)에 대해 worker 조회, 그리고 이후 이어지는 aggregate 등을 위한 상태내역 관리 체계 등이 결국 하나의 메타데이터 저장소로부터 진행이 되어야 한다(공유가능한 체계에서).
일단 이 하나로 공유되는(모든 manager, worker가 공유하는) 메타데이터 저장소 운용을 위해, 인메모리(H2) 상태내역 관리는 기본적으로 포기해야한다. 반드시 공유가 가능한 상태여야 하며, 이로 인한 DB 운용 비용이 추가 된다.
따라서 이에 대한 보완책으로, 동일한 batch job을 여러 파티션 권역으로 나눈 job parameter를 기반으로 여러번 나누어 실행하는 (혹은 동시에 병렬로 실행하는 = 독립적인 JVM 인스턴스 필요) 방안을 마련할 수 있다.
원격파티셔닝은 정말 필요한 경우에만 도입하도록 하고, 웬만한 경우에는 여러개의 잡 파라미터로 하나의 job을 다수의 JVM 환경에서 병렬적 혹은 순차적으로 처리하도록, 다만 원자적으로 처리될 수 있도록 구성하는 것을 권장한다.
실무에서는 나만이 알고있는 목적, 복잡성은 의미가 없다. 반드시 모두가 수용가능하고 이해가능한 단순함, 비용을 더 중요시해야하며, 또한 그것이 먼저이다.
6-9. Remote Chunking
Remote Partitioning이 데이터 처리와 권역을 WorkerNode에게 모두 위임하는 방식이었다면, Remote Chunking은 말 그대로 청크단위의 데이터 분리를 ManagerNode가 진행하고, 이 분리한 청크를 원격의 worker node에게 전달해주는 방식이다.
remote partitioning으로 부족한 고가용성을, manager의 데이터 분리(청킹)까지 진행하여 그 수준을 한단계 더 끌어올리는 전략이다.
Remote Partitioning은 manager 측에서 StepExecution context을 생성하여 worker에게 보내고 worker 측에서 데이터 권역을 직접 추출한다. Remote Chunking은 Manager 측에서 데이터 권역을 직접 나누고 청크 단위로 분리하기까지 하며, 이후 worker 측에 전달한다.
이처럼 Manager 측의 데이터 분할이 이루어지고 책임이 분할되어 처리가 가능해지므로, worker 측에서 processing, writing 속도가 너무 느려 원격파티셔닝의 수준을 한단계 높이고자 할 때, Manager 측의 단일 스트림 제공구조로 매니저가 순차적으로 데이터를 읽어야 하는 상황에서 처리효율을 높이고자 할 때 도입 가능한 전략이다.
Manager는 ItemReader의 역할을, worker는 ItemProcessor 및 ItemWriter의 역할을 수행하게 되는데, 그만큼 네트워크 비용이 소모될 수 있으며, Message Broker를 사이에 두고 각 Manager 및 worker는 결과에 대한 보고, 집계를 위해 ChunkRequest/ChunkResponse를 통신하는 방안을 고민해보아야겠다.
6-10. Manager - RemoteChunkingManagerStepBuilderFactory ~ IntegrationFlow
Manager 측에서 remote chuking을 구성할때는 RemoteChunkingManagerStepBuilderFactory 구현체를 사용하여 빌더패턴을 구성하게 된다.
remoteChunkingManagerStepBuilderFactory
.get("globalRetaliationStep:manager")
.reader(globalResistanceDataReader())
.outputChannel(outboundChunksToWorkers())
.inputChannel(inboundRepliesFromWorkers())RemoteChunkingManagerStepBuilderFactory 구현체를 사용하여, 데이터를 읽고(reader), 읽은 데이터 청크를 worker에게 보낼 전송채널(outputChannel) 및 처리 결과를 전달받을 채널(inputChannel)을 구성한다.
채널에 대한 구성 및 흐름은 이전과 같이, Integration flow를 사용하며 ChunkMeesageChannelItemWriter 구현체를 사용하여 reader가 읽은 데이터 청크를 chunkRequest 메시지로 wrapping, 위에서 구성한 outputChannel을 통해 전달한다.
public class ChunkRequest<T> implements Serializable {
private static final long serialVersionUID = 1L;
private final long jobId;
private final Chunk<? extends T> items;
private final StepContribution stepContribution;
private final int sequence;이때 전송하는 ChunkRequest의 프로퍼티, 멤버변수는 위와 같이 구성되어있다.
Manager Step 측에서는 원격청킹으로 전송할 Chunk 리스트(items)를 저장하며, worker 측에서 chunk를 처리한 결과를 aggregate하여 담는 stepContribution 및 처리일련번호인 sequence를 보유하고 있다.
이를 전송받는 inputChannel, outputChannel은 remote partitioning과 동일하게, 수신은 directChannel로, 송신은 queueChannel로 구성하도록 한다.
return IntegrationFlow
.from(outboundChunksToWorkers())
.log()
.handle(messageHandler)
.get();이후 위에서 구성한 outboundChunksToWorkers 채널을 통해 메시지를 전송할 flow을 구성해준다(messageHandler -> KafkaTemplate을 통한 메시지 전송).
return IntegrationFlow
.from(Kafka.messageDrivenChannelAdapter(cf, "chunk-response"))
.log()
.channel(inboundRepliesFromWorkers())
.get();또한 각 worker node들로부터 처리결과를 전달받기 위한 inboundFlow를 구성하여 주며, 이때 Adapter를 통해 topic을 구성해주도록 한다(위의 경우 chunk-response).
참고로 outboundChunksToWorkers(워커와의 메시지 전달 통로), inboundReplyFlow(처리완료 후 이에 대한 처리응답 통로) 각각 토픽을 달리해주어 구분 운용하도록 한다.
public Long routeToKafkaPartition(Message<ChunkRequest> message) {
..
long partitionId = chunkSequence % partitionSize;
..
}그리고 중요한 파티션id 분배 도구인 Partitioner(PartitionRouter)를 등록해준다. 위와 같이, chunkRequest로부터 payload를 전달받아, 이를 partitionId로 변환(분배)해주는 역할을 한다.
6-11. Worker - IntegrationFlow ~ RemoteChukingWorkerBuilder
Worker는 특이하게도 step 구성이 주가 아닌, integrationFlow를 중심으로 청킹빌더를 활용하여 step을 구성하는 방향으로 이루어진다.
IntegrationFlow를 통해, 메시지를 전송받아 처리하는 흐름으로 진행이 되기 때문이다.
@Bean
public IntegrationFlow workerIntegrationFlow() {
return this.remoteChunkingWorkerBuilder
.inputChannel(inboundChunkRequestsFromManager())
.outputChannel(outboundRepliesToManager())
.itemProcessor(nuclearStrikeProcessor())
.itemWriter(damageReportWriter())
.build();
}위와 같이, 메시지를 전달받아(inputChannel) 처리결과를 보고하고(outputChannel), 수신된 청크의 아이템들을 처리하고 write할 itemProcessor, itemWriter에 대해 구성하는 것이 올바른 방향이다.
이떄 RemoteChunkingWorkerBuilder의 build() 시,
public IntegrationFlow build() {
...
return IntegrationFlow.from(this.inputChannel)
.handle(chunkProcessorChunkHandler, SERVICE_ACTIVATOR_METHOD_NAME)
.channel(this.outputChannel)
.get();
...
}위와 같이, IntegrationFlow 객체에서 직접 chunkProcessorChunkHandler 객체를 만들어 이를 핸들러로 등록하는데,
이 구현체가 바로 SimpleChunkProcessor이며, 내부적으로 chunkProcessorChunkHandler의 handle을 호출하여 청크 아이템을 process, write한다.
여기서 유의할 점은

위와 같이 Java17 버전이상에서만 디컴파일이 가능한, 즉 프레임워크 활용이 가능한 상향된 로직이라는 점이다.
그리고 최종적으로 Manager Node에게 ChunkResponse를 전달하는데,
public class ChunkResponse implements Serializable {
private static final long serialVersionUID = 1L;
private final StepContribution stepContribution;
private final Long jobId;
private final boolean status;
private final String message;
private final boolean redelivered;
private final int sequence;
public ChunkResponse(int sequence, Long jobId, StepContribution stepContribution) {
this(true, sequence, jobId, stepContribution, null);
}ChunkResponse에서 구성한 여러 프로퍼티 중, worker의 작업 내역은 stepContribution에 담겨져 전송이 이루어진다. 이 stepContribution이 manager Node에서 전 워커에 대한 순회가 진행되면서, main stepContribution에 aggregate한다. 모든 청크 처리가 완료된 시점에, 최종 COMPLETED or FAILED 처리하며, 하나라도 FAILED라면 실패처리한다.
6-12. Serialization/DeSerialization - chunkRequest, chunkResponse
원격 청킹에서 또다른 중요한 점은 chunkRequset, chunkResponse에 대한 직렬화/역직렬화 설정을 진행해야 한다는 점이다.
ChunkRequest, ChunkResponse 별로 각각 직렬화, 역직렬화하기 위한 유틸성 직렬화/역직렬화 로직을 구성한다.
public class ChunkRequestSerDes{
public static class ChunkRequestSerializer implements Serializer<ChunkRequest<ResistanceActivity>> {
private final DefaultSerializer serializeer = new DefaultSerializer();
@Override
public byte[] serialize(String topic, ChunkRequest<ResistanceActivity> chunkRequest) {
...
public static class ChunkRequestDeserializer implements Deserializer<ChunkRequest<ResistanceActivity>> {
private final DefaultDeserializer byteDeserializer = new DefaultDeserializer();
@Override
@SuppressWarnings("unchecked")
public ChunkRequest<ResistanceActivity> deserialize(String topic, byte[] data) {
}Request는 위와 같이, ChunkRequest 인스턴스 형태에서 바이트 배열로의 직렬화, 그 반대의 역직렬화를 적절하게 구성하도록 한다. 이때 유의할 점은 Serializer,DeSerializer를 implements하여 통신 시 직렬화를 하기 위한 구성을 맞춰주어야 한다는 점이다.
public class ChunkResponseSerDes {
public static class ChunkResponseSerializer implements Serializer<ChunkResponse> {
private final DefaultSerializer serializeer = new DefaultSerializer();
@Override
public byte[] serialize(String topic, ChunkResponse chunkResponse) {
...
public static class ChunkResponseDeserializer implements Deserializer<ChunkResponse> {
private final DefaultDeserializer byteDeserializer = new DefaultDeserializer();
@Override
public ChunkResponse deserialize(String topic, byte[] data) {ChunkResponse에 대해서도 동일하게 직렬화, 역직렬화 메서드를 구성해주도록 한다.
7. 결론
단일 JVM에서 실행하는 단일 batch job의 처리 한계를 극복하기 위해, 멀티스레드 step부터 시작하여 remote partitioning, remote chunking 등 다양한 비동기적, 병렬적 처리 방식에 대해 분석해보았다.
물론 처리량 및 처리효율을 극한으로 끌어올릴 수 있다는 장점이 있었지만, 그 내면에는 동시성 문제 해결을 위해 동기화 처리 방안으로 인한 side effect 발생, 이 부작용에 대한 방안으로 이어지는 과정에 대해 알 수 있었고, 나아가 이러한 방안들(RemotePartitioning/RemoteChunking)을 적용할때 발생하는 유지관리의 비효율적인 문제, Spring Integration에 대한 충분한 이해 등 상당한 러닝커브가 소요되는 것을 확인할 수 있었다.
사실 Spring batch를 하면서 가장 어려운 단계였지만, 포기하지 않고 꾸준히 파고들고 그에 대한 배경지식, 적용 방안에 대해 고민하였으며 이러한 과정에서 수도 없이 많은 나뭇가지들이 퍼지면서 Integration과 같은 주요 컴포넌트/프레임워크들에 대해서도 겸사 겸사 알 수 있게 되었다.
지금 파악하였던, 부족한 점을 향후 성장의 밑거름으로 삼아서, 최대한 보완하고 실무 적용이 가능한 수준으로 끌어올리는 것이 중요하겠다.
