[개발지식] (작성중) Web Application의 상호보완적 Eventually Consistency #4 - Batch만이 보유하고 있는 강력한 유지관리성 - JobRepository의 추상화된 메타데이터 저장소 분석(객체에 상태정보를 저장하고 이를 RDBMS로 최종 전달하기 위한 과정을 중심으로)
개발지식
1. 개요
Spring Batch의 중요한 점 중 하나는, 배치처리를 진행하기 위한 조건을 동적으로 구성해 줄 수 있고 또한 이러한 조건과 Job/Step의 상태정보 및 이력 등을 저장하여 관리하고 추적할 수 있다는 점이다.
특히 application.yml과 같은 프로퍼티를 통해서는 정적인 변수 할당, 이로 인해 변수 변경이 발생할 경우 일일이 변경해주어야 하는 번거로움이 발생하기에 job parameters에 대한 이해는 그만큼 중요하다.
Spring Batch를 본질적으로 이해하고 완성시킬 수 있는 마지막 퍼즐인 JobParameter와 이를 전달하고 상태정보를 저장하는 과정에 대해 자세하게 알아보았다.
2. 상태관리에 대한 기본 동작원리
일단 우선적으로 알아야하는 3가지 명제가 있다.
1) Spring batch에서 job/step의 상태정보 및 실행이력을 JobRepository를 통해 메타데이터 저장소에 기록한다.
2) JobRepository에 전달된 상태정보 및 실행이력들의 영속성을 부여하고 상태관리를 위해 RDBMS에 저장한다.
3) JobParameter를 통해 전달된 값들 역시 JobRepository를 통해 메타데이터 저장소에 기록한다.
즉, Spring Batch는 상태관리를 하기 위해 JobRepository를 통해 메타데이터 저장소에 먼저 기록하고, 이 기록한 것을 최종적으로 RDBMS에 영구적으로 저장 및 영속화한다.
이때 JobParameter를 통해 전달된 매개변수들도 이 관리이력에 포함되는 것이고, 이 매개변수들이 각각의 상태정보, Job/Step 등을 구별할 수 있는 중요한 기준이 되는 것이다.
다시 정리하자면,
- 내부적으로 JobInstance, JobExecution, StepExecution 등의 엔티티(메타데이터)를 객체화하여 저장한다(RDBMS에 저장하기 전에 추상적으로 데이터를 저장하는 객체이자 DTO).
- 이후 이러한 상태정보를 JobRepository에 전달, JobRepository의 구현체(SimpleJobRepository)는 JDBC를 사용해서 RDBMS의 테이블(BATCH_JOB_INSTANCE, BATCH_JOB_EXECUTION, BATCH_STEP_EXECUTION 등)에 이 정보를 저장한다.
기본적으로 Spring Batch의 상태관리는 RDBMS를 기반으로 진행하며, JobRepository가 그 전에 데이터를 저장하는 곳은 추상화된 인터페이스라 보면 되겠다(즉, RDBMS가 그 메타데이터 저장소의 "구현체").
이러한 이해를 바탕으로 JobParameter를 통한 Spring Batch 상태관리 과정을 분석해보도록 한다.
2-1. Spring.beans.factory.annotation의 @Value 어노테이션 활용
향후 cli를 통해 jobaparameter를 전달하고, 이를 @Value를 통해 주입받는 방식을 사용할 것이다.
이를 위해선 @Value 어노테이션에 대한 이해가 먼저 필요하다.
@Value 어노테이션은 많이 보았을텐데, 이는 클래스에서 사용하는 lombok패키지의 어노테이션으로 해당 클래스를 불변(Immutable)으로 만들고 모든 필드를 final화 및 생성자, getter, equals, toString 등의 메소드를 자동으로 "컴파일 단계에서" 생성해주는 컴파일 레벨의 어노테이션이다.
이처럼 DTO/VO를 만들 목적으로 @Value 어노테이션을 사용할 수 있기도 하지만, 지금과 같이 job paramter, 넓게는 프로퍼티(#{}) 혹은 SpEL(Spring Expression Language) 기반으로(${}) 해당 Bean(여기서는 @StepScope 등에 의해 관리하는 Proxy Bean)에게 값을 전달하여 최종적으로 실제 객체에게 속성을 주입해주는 Spring.beans.factory.annotation 패키지의 @Value 어노테이션이 존재한다.
이러한 이해를 바탕으로 StepScope 어노테이션에 대해 단계적으로 알아보도록 한다.
2-2. 상태전달을 위해 알아야하는 추가적인 원리 - Bean 정의/등록과정 및 StepScope에 의한 lazy Injection
향후 JobParameter를 전달하기 위해선 @StepScope, @JobScope와 같은 객체생성을 lazy하게(객체생성지연) 진행하여 job parameter를 온전하게 주입할 수 있는 장치가 반드시 필요햐다.
위에서 파악한 @Value 어노테이션과 같이 이해하자면, StepScope에 의해 실객체생성을 지연하고 이를 Proxy객체로 대리호출을 하되, 실제 호출 시점에서 Proxy객체가 해당 프로퍼티 및 매개변수를 전달하고 실객체는 이를 전달받아 비로소 생성자 주입/필드주입/setter 주입 등의 데이터 주입이 일어난다.
이처럼 실객체에 대한 주입과 생성, 빈객체 생성이 런타임 시점이 아닌, 해당 클래스를 호출하는 시점에 이루어지도록 하여 null이 아닌 온전한 프로퍼티 전달이 이루어지도록 시간차를 두는 전략을 StepScope를 통해 진행할 수 있다.
참고로, Chunk의 경우 보통 객체 인스턴스를 생성한 후에 주입하는 형태로 일반 application과 동일한 원리로 프로퍼티를 주입하기에 StepScope/JobScope 어노테이션은 보통 tasklet에 많이 활용한다.
StepScope/jobScope가 적용되어있지 않은 클래스라면 당연히 런타임시점에 해당 클래스로더를 통한 로딩 및 실객체 생성, 빈주입이 정상적으로 동작한다.
| 구분 | 어노테이션 | 역할 | Bean 스코프와 관계 |
|---|---|---|---|
@lombok.Value | Lombok 제공 | 불변(immutable) 객체 자동 생성 | 컴파일 시 코드 생성, DI와 무관 |
@Value | Spring 제공 | 외부 프로퍼티 or JobParameter 주입 | 런타임 DI, SpEL 가능 |
@StepScope | Spring Batch 제공 | Step 실행 시점에 Bean 생성 (Lazy Init) | JobParameters 주입 가능하게 함 |
Chunk 방식 | 보통 new 로 객체 생성 | Spring Bean 아님 | @StepScope 불필요 |
Tasklet 방식 | Spring Bean 등록 | JobParameter 주입 필요 시 @StepScope 필수 |
이에 대한 내용을 위와 같이 정리해볼 수 있다.
2-3. 세부적인 동작원리에 대한 이해 - Bean Definition/refresh와 연결하며
StepScope에 대한 이해는 Bean 객체생성과정, 나아가 어노테이션 동작원리까지 넓게 이해할 수 있는 좋은 키워드이다.
여기서 들 수 있는 의문점, 클래스는 스캔대상인데, 어떻게 객체 생성 및 bean 객체 생성이 지연된다는 것인가?
이에 대해 이해한다면 클래스로더 ~ Bean Definition ~ 객체 생성 등의 일련의 과정을 전체적으로 한번에 파악 가능하다.
기본적으로 클래스로더에 의한 메타데이터 구축, Bean Definition단계까지는 정상적으로 이루어진다. 다만 이때 definition단계에서 해당 어노테이션의 명세가 들어가, Spring Container가 이를 읽어 ApplicationContext를 refresh할때 어노테이션 리플렉션에 영향을 미친다.
즉, 다른 싱글톤 빈을 이 시점에서 초기화하지만 StepScope/JobScope가 붙은 어노테이션은 실객체 생성을 지연하고 Bean객체가 만들어지지 않는다. 다만 이를 대체하는 Proxy 빈객체는 만들어진다.
해당 클래스를 호출하는 지점에 와서야 비로소 ProxyBean객체를 통해 실객체를 생성하며, 이 실객체를 생성하는 시점에 값들을 Value를 통해 전달하면서 온전한 주입과 실객체/Bean객체 생성 및 등록이 일어난다.
이를 아래 도식화하면 이해가 쉽다.
클래스 로드 시점
│
├─> 리플렉션으로 어노테이션 정보 읽음 (@Component, @StepScope, @Value)
│
ApplicationContext refresh()
│
├─> BeanDefinition 등록 (설계서)
│ - scope: singleton / step
│ - lazy 여부, 의존성, 생성 방법 등
│
└─> Bean 생성
├─ Singleton: refresh() 시점
└─ StepScope: Step 실행 시점 → JobParameter 주입
StepScope 대상 클래스는 Value 어노테이션을 사용하여 지연 주입이 가능한데, 향후에 매개변수를 통한 주입/필드주입/Setter 주입/생성자 주입이 모두 가능하다.
3. Command Line을 통한 Job Parameters 전달
먼저 가장 기본적인 배치 실행방법인, cli를 통해 인자를 하나하나 전달해보도록 하겠다.
기본적인 배치 컴포넌트를 구성하기 위해, 스캔 대상으로 Config 클래스를 지정해주었다.
@Slf4j
@Configuration
public class SystemTerminatorConfig {
@Bean
public Job processTerminatorJob(JobRepository jobRepository, Step terminationStep) {
return new JobBuilder("processTerminatorJob", jobRepository)
.start(terminationStep)
.build();
}
@Bean
public Step terminationStep(JobRepository jobRepository, PlatformTransactionManager transactionManager, Tasklet terminatorTasklet) {
return new StepBuilder("terminationStep", jobRepository)
.tasklet(terminatorTasklet, transactionManager)
.build();
}그리고 tasklet을 지정해주었고, 일단 tasklet은 별도 책임분리를 진행하지는 않았다.
@Bean
@StepScope
public Tasklet terminatorTasklet(
//lombok value - 불변 클래스 생성
//beas.factory - SpEL(Spring Expression Language(CLI)를 통해 프로퍼티/jobparameter 값 주입 시
@Value("#{jobParameters['terminatorId']}") String terminatorId,
@Value("#{jobParameters['targetCount']}") Integer targetCount
) {
return (contribution, chunkContext) -> {
log.info("Processing terminator tasklet");
log.info("Terminator tasklet id : {}", terminatorId);
log.info("Terminator tasklet targetCount : {}", targetCount);
for(int i = 0 ; i <= targetCount ; i++){
log.info("target terminating System is Running : {}/{}", i, targetCount);
}
log.info("Terminator tasklet finished");
return RepeatStatus.FINISHED;
};
}다음 단계는 실행이다.
나의 경우 멀티모듈(MSA) 구성이기에, gradlew 파일이 있는 루트 프로젝트에서 cli를 실행하되, 어떠한 멀티모듈을 실행할 것인지에 대한 정확한 경로를 명시해주었다.
./gradlew :batch:jobParameters:bootRun --args='--spring.batch.job.name=processTerminatorJob terminatorId=KILL-9,java.lang.String targetCount=5,java.lang.Integer'이 CLI를 실행하였을때 정상적으로 batch 실행 동작을 확인할 수 있었다.

또한 추가적인 로그로 어떠한 매개변수들이 전달되었는지 확인할 수 있었는데,

이와 같이 cli에서 전달한 jobparamters이 기록되고, 나아가 관리대상으로 인식하고 있음을 알 수 있다.
3-1. enum을 통한 job parameters 전달
실무에서는 단순 문자열을 매개변수로 주입해주기 보다는, enum과 같이 자료구조화하여 안정적이고 가독성 높으며 유지보수성 측면에서 훨씬 유리한 상태로 관리하거나 이 관련한 변수를 전달한다.
util packge에 enum을 구성해주었고 간단한 enum 자료구조를 구성해주었다.
public enum QuestDifficulty {
EASY,
NORMAL,
HARD,
EXTREME
}이 enum 매개변수를 tasklet이 전달받도록 구성해주었다. 구성은 모두 동일하다, 다만 매개변수를 enum 형태로 받는 것 뿐이다.
@Bean
@StepScope
public Tasklet terminatorTasklet(
//lombok value - 불변 클래스 생성
//beas.factory - SpEL(Spring Expression Language(CLI)를 통해 프로퍼티/jobparameter 값 주입 시
@Value("#{jobParameters['questDifficulty']}")QuestDifficulty questDifficulty
) {
return (contribution, chunkContext) -> {
log.info("Processing terminator tasklet");
log.info("Terminator tasklet quest difficulty : {}", questDifficulty);
log.info("reward is based on quest difficulty.");
int reward = switch (questDifficulty){
case EASY -> 1;
case NORMAL -> 2;
case HARD -> 3;
case EXTREME -> 4;
};
log.info("finially reward is : {}", reward);
log.info("Terminator tasklet finished");
return RepeatStatus.FINISHED;
};
}이에 대한 실행을 CLI을 통해 진행해주면 되는데 일전 문자열 jobparameters를 전달해주었을 때와 동일하다. 단지 그 type을 위에서 정해준 디렉토리 그대로 명확히 명기해주면 된다.
./gradlew :batch:jobParameters:bootRun --args='--spring.batch.job.name=processTerminatorJob questDifficulty=HARD,com.system.batch.util.QuestDifficulty'을 cli로 실행하면 되는데, 과정은 모두 동일한데 tasklet에서 전달하는 매개변수에 맞게 cli에서도 그 type을 명확히 지정해주면 된다는 것(enum)을 유의해주면 되겠다.

정상 동작하였음을 확인하였다.
3-2. POJO(객체)를 통한 job parameters 전달
마찬가지로 실무에서는 훨씬 더 복잡한 잡파라미터를 필요로 하고, 이를 구조화 및 체계화하여 관리하기 위해 enum 관리 뿐만 아니라 매개변수들을 클래스화하여 관리하는 방안도 존재한다.
@Data
@StepScope
@Component
public class SystemInfiltrationParameters {
@Value(
"#{jobParameters[missionName]}"
)
private String missionName;
private int securityLevel;
private final String operationCommander;
public SystemInfiltrationParameters(
@Value("#{jobParameters[operationCommander]}") String operationCommander
){
this.operationCommander = operationCommander;
}
@Value("#{jobParameters[securityLevel]}")
public void setSecurityLevel(int securityLevel){
this.securityLevel = securityLevel;
}
}POJO의 경우, cli 실행시점에 enum type을 아예 명시적으로 적어주어 값만 주입받은 반면, 이번에도 값을 전달해주는 것은 맞지만 데이터의 전달과 주입이 발생하며, 이를 통한 최종적인 값주입이 Proxy Bean과 객체의 값 주입이라는 일련의 순차적 과정을 통해 일어난다.
즉, 쉽게 말하면 개발자가 구조화/체계화한 과정을 그대로 지나가면서, 그 내용의 부합 여부 등을 파악할 수 있다.
결론적으로는 job parameters를 체계화/구조화하여 유지관리성과 안정성을 확보할 수 있다.
이에 대한 선행조건으로, "2-1"의 빈 Definition 및 등록/생성 과정을 온전히 이해해야 지금의 과정을 이해할 수 있으므로 반드시 선행과정을 숙지해야 한다는 점에 유의한다(refresh 시점이 아닌 클래스 호출 시점에 값 주입/생성자 주입 발생!).
./gradlew batch:jobParameters:bootRun --args='--spring.batch.job.name=processTerminatorJob missionName=안산_데이터센터_침투,java.lang.String op mmander=KILL-9 securityLevel=3,java.lang.Integer,false'마찬가지로 위 스크립트를 실행하면
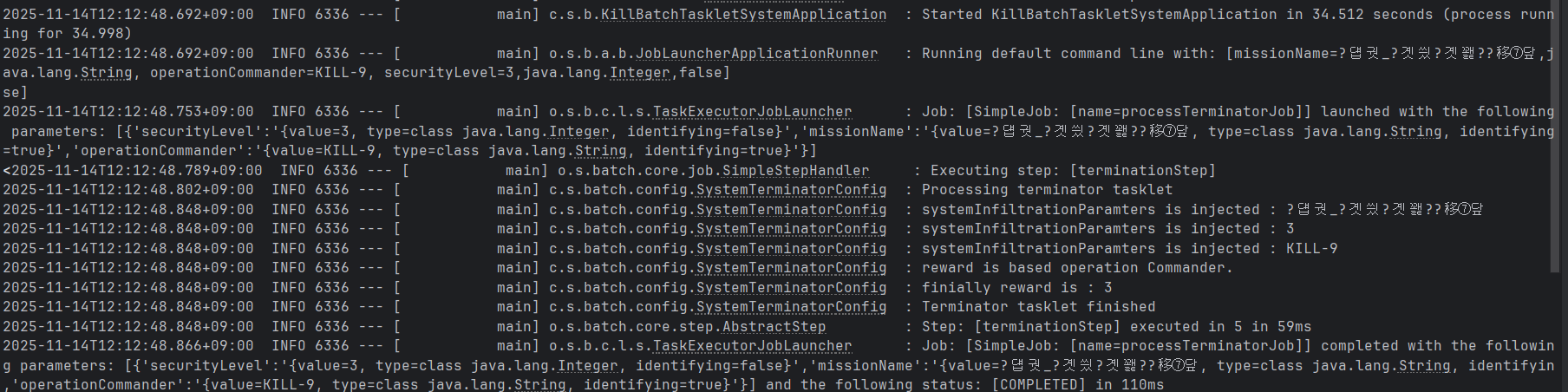
이와 같은 정상적인 동작 실행을 확인할 수 있다(한글로 변수를 저장하면 위와 같이 깨지므로 웬만하면 영문으로 전달하는 것을 권장한다).
3-3. JSON 방식의 job parameters 전달
cli를 통한 job parameters 전달을 이번엔 단순 인자전달이 아닌, JSON 방식으로 인자를 전달해보도록 하겠다(Spring Batch 5ver. 이상).
일단 json 방식으로 job parameters를 전달하기 위해선 별도의 의존성 추가가 필요하다.
implementation 'org.springframework.boot:spring-boot-starter-json'참고로, 지금은 SpEL를 통해 문자열을 바로 받아오는 형태이지만, Job Launcher 수준에서는 Json job parameter 파싱을 위해 JsonJobParametersConverter 빈 객체를 별도로 생성해주어야 한다(일단 미리 참고사항으로 기록해둔다).
@Bean
public JobParametersConverter jobParametersConverter() {
return new JsonJobParametersConverter();
}테스트 결과, 환경차이 및 이스케이프 인식 불가 등으로 인해 CLI를 통한 batch 실행은 단순 문자열 및 원시형(String/int 등)만 가능하고 JSON 배열을 전달하는 것은 지양하는 것으로 결론지었다.
| 타입 | 전달 가능 여부 |
|---|---|
| String | ✅ 가능 |
| int / long / double / boolean 등 원시 타입/Wrapper | ✅ 가능 |
| Date | ✅ 가능 (ISO 8601 형식 문자열로 전달 후 자동 변환) |
| Object / JSON / Map / List | ❌ 불가능 (bootRun + CLI 환경에서는 파싱 지원 안 됨) |
JSON 파싱문제가 지속 발생, 단순 문자열로 바꾸어 진행하였다.
./gradlew batch:jobParameters:bootRun --args='--spring.batch.job.name=processTerminatorJob infiltrationTargets=pangyo'(Intellij 내부의 window powershell에서 입력한 명령어는 환경차이가 너무 많이 발생하고, 이스케이프 처리 불가하여 단순 문자열로 대체하였다)

단순 문자열 대체 후 배치실행 성공.
4. job parameters의 파싱 - DefaultJobParametersConverter / DefaultConversionService
job parameters를 통한 매개변수 주입이 어떤 과정으로 일어나는지 알아보도록 하겠다(CLI에서 value 주입까지).
너무 깊게 들어가지는 않고 대략적인 흐름만 알아보도록 한다.
1) 최초 spring batch 실행 시 JobLaunchApplicationRunner를 실행하여, Spring batch를 총괄/진행한다(*job parameter 해석 및 job 실행)
2) job 목록 "준비"
- Application context에 등록된 job bean객체가 JobLauncherApplicationRunner에 주입된다.
3) 유효성 검증
- job객체를 주입받을때 job을 특정하지 못하는 경우 Exception을 발생한다.
4) CLI해석
- 이 단계에서 본격적인 파싱이 이루어지는데, key=value의 인자를 JobParameter로 변환하는데, 이때 DefaultJobParametersConverter를 사용하여 CLI의 key=value,type,identificationFlag 를 알맞게 주입해준다.
이때 내부적으로 Spring의 DefaultConversionService를 사용하여, 웬만한 타입지원 및 변환이 가능하며, 참고로JSON의 경우, DefaultJobParametersConverter 클래스를 계승(5ver 이상)한 JsonJobParametersConverter 클래스에서 내부적으로 ObejctMapper를 사용하여 job parameter를 파싱한다.
5) Job 실행
- 위에서 얻은 Job 정보 및 job parameter 정보를 바탕으로 최종적으로 job을 실행한다(this.jobLauncher.run(job, jobParameters);.
5. spring batch 로직 구현을 통한 job parameter 전달
이제 본격적으로 spring batch를 활용하여 job parameter를 전달해보고자 한다.
위와 같은 CLI 실행은 기본적으로 "수동" 실행이기도 하고, 전달해줄 수 있는 매개변수 형태/타입/길이/오기 등의 제한적인 요소가 너무 많기에 실제 실무에서 적용하기엔 적합하지 않다.
보통은 REST API를 통한 이벤트 발생 및 배치 트리거, 메시지 큐, 특정 비즈니스 작업 완료 후 배치 실행, @Scheduled를 통한 특정 시간에서의 실행 등 여러 요소가 복합적으로 맞물려 있는 상황 혹은 방식으로 batch를 실행할 필요가 있다.
이를 위해 Spring batch 내장 모듈을 통한 job parameter를 직접 구현하여 전달해볼 수 있겠다.
