1. 개요
지금까지 MSA 환경을 구축하고, 이 환경을 구축함으로 인해 대규모 트래픽을 처리할때 어떠한 점에서 유리한지 체득하는 관점에서 많은 시행착오를 겪어왔다.
하지만, 이러한 구현도 중요하지만 그에 못지 않게 이 구조가 왜 필요하고, 이 선택의 비용은 어떻게 되는지에 대해 한번 고민해보는 것도 필요하기에, 분산환경이라는 기본적 내용에 대해 분석해보는 시간을 가져보고자 한다.
기술의 사용에 앞서, 그 기술을 왜 사용해야 하는지, 이를 선택함으로써 어떠한 것을 획득하고 그 대신에 어떤 부분을 잃어야 하는지 폭넓게 이해하며,
나아가 분산 환경을 채택하고 이를 실무적으로 활용할 수 있는 설계적 관점, 안목에 대해 넓히고자 하는 것이 주 목적이다.
MSA, 물론 대규모 트래픽 상황에서 경계를 명확히 분리하여, 각 경계별 시스템으로 나누어 그 책임과 트래픽을 분산시키고 경량화할 수 있기에, 더불어 이에 따른 Cloud 환경을 적용하기에 적절한 구조이기에 규모가 큰 기업에서 많이 선택하는 구조는 확실하다.
하지만, 그렇지 않은 상황에서 무작정 MSA를 사용하는 것이 좋을까?
수많은 CICD 환경 구축, 차세대 환경을 구축하면서 느낀 점은 Over Architecturing은 운용 관리적 측면에서 상당한 번거로움, 비용을 야기하고, 불필요한 소모가 발생한다는 점이었다.
분산 환경 구축의 시작점은 트래픽이 많아졌을때, Monolithic 시스템 분리의 고민, 경계의 고민에서 출발한다.
서비스를 개발하고, 여러 패턴과 설계를 공부하면서 100%, 모든 Trouble을 Coverage할 수 있는 완벽한 시스템이라는 것은 없다는 것을 알게 되었다.
정답을 찾기보다는, 현재 상황에서 best practice, 즉 지금 상황에서 요구하는 우선적 사항을 정확히 파악하고 이를 중점적으로 맞추되, 그런 과정에서 다른 후우선순위 사항들을 조금씩 희생하는 과정이 설계이다.
MSA를 선택하고, 분산환경을 설계하기 위해 어떠한 점을 고려하고 접근해야 하는가, 어떠한 관점이 필요한지 한번 단계적으로 살펴보도록 하자.
2. Monolithic, and MSA
Monolithic 구조가 지니는 가장 큰 특징은 배포 단위가 단일 프로젝트 그 자체인 점이다.
즉, Monolithic은 모든 기능과 layer가 하나의 프로젝트, 배포 단위로 묶여있기에 관리 단위도 하나의 application 그 자체가 된다.
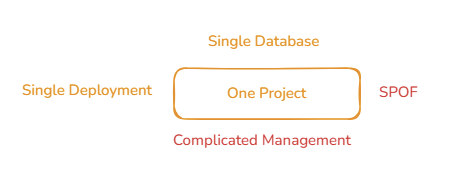
이로 인해, 전개 방식이 도메인 단위가 아닌 layer, functional 기반으로 이루어지며, 각기 다른 도메인간의 layer 및 function이 복잡하게 얽혀있을경우 상당한 결합도가 발생하며, 나아가 다른 layer에서 발생한 문제가 전체 프로젝트에 영향을 미치는 SPOF(Single Point Of Failure)의 특징을 지니게 된다.
layer 및 functional 기반의 전개는 단순하지만, 새로운 도메인 혹은 layer의 추가 시 해당 도메인을 기존 layer를 완전히 복사해야하는 번거로움이 발생한다.
물론, 무조건 이러한 단점만 있는 것은 아니다.
단일 데이터베이스에 기반한 layer, functional 기반의 운용은 강한 일관성, 특히 ACID를 보장할 수 있는 트랜잭션을 구성할 수 있다.
또한, 트래픽 규모가 작은 상태에서 Single Database per Single Domain, 굳이 서비스와 도메인을 분리하여 여러개의 마이크로서비스로 운용하는 것은 상당한 OverHead이다. 가장 표준적이고, 통용적이며 단순한 관리 방안을 마련할 수 있는 Monolithic은 프로젝트를 시작하기에 가장 효율적인 구조임에는 틀림없다.
하지만, 트래픽 규모가 커졌을때 각 도메인 별 책임을 명확히 분리하여, 서비스 별 언어 및 데이터베이스 독립적 운용(Polyglot Persistence)을 가능하게 하여 운용과 배포의 유연성을 강화한 것이 바로 MSA구조이다.
MSA구조는 각 분리된 마이크로서비스가 다른 데이터베이스를 바라보고 있기에, 인스턴스가 다른 각 도메인이 적용하는 OSI 7 Layer의 응용계층(HTTP, Raw Socket TCP, RESP, Kafka 등) 및 통신방안(gRPC, Message Queue)이 다르다.
이로 인해, 분산 시스템의 ACID 및 일관성을 보장하기 위해 SAGA 패턴을 적용하는 등, CAP 정리에 기반한 고려사항을 충족할 수 있도록 구조를 구성해주어야 한다.
- C : Consistency
- A : Availability
- P : Partition Tolerance
더불어, 동기방식이든 비동기방식이든 트랜잭션 원자성을 저해하는 상황을 맞닥뜨렸을때 트랜잭션을 보상하거나, 어떠한 방식으로 일관성, 정합성을 보장할 수 있을지 항상 고민하고 설계에 적용할 필요가 있겠다.
2-1. Monolithic to MSA
그렇다면 Monolithic을 MSA구조로 변환하는 방안이 있을까?
있다.
Monlithic 구조를 MSA 구조로 변환하는 과정에 있어 가장 핵심은 점진적 변화와 적용이다.
Monolithic과 MSA는 설계 사상자체가 다르고, 데이터베이스 및 스키마 등 모든 근간을 뜯어 고쳐야하는 대규모의 작업이다.
이러한 대규모 작업은 그만큼의 충분한 시간, 검토, 검수 작업이 동반되어야 하기에 waterfall 방식처럼(블루그린배포) 진행하는 것은 안정성 측면에서 불가능하다.
첫번째 단계 : Modular Monolith Hardening
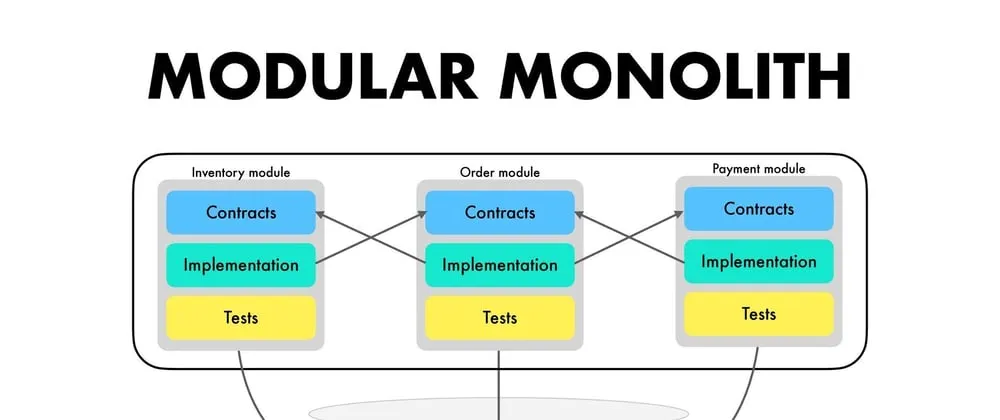
Monolithic 내부를 layer, 계층구조 기반이 아닌 기능적 도메인 기반으로 분리하는 것이다.
사실 Monolithic 구조를 최초 개발시점부터 Infra Layer 기반이 아닌 Modular 기반으로 구축한다면, 일관성을 중점적으로 고려하여 프로젝트 관리에 번거로움을 더하는 것에 비해 훨씬 효율적으로 유연성있게 Scaled Out를 할 수 있다.
/MyModularMonolith
├── /Modules
│ ├── /Inventory
│ │ ├── InventoryService.cs
│ │ └── InventoryController.cs
│ ├── /Orders
│ │ ├── OrderService.cs
│ │ └── OrderController.cs말 그대로, controller/repository와 같은 layer 중심이 아닌 위와 같이 기능/책임별로 프로젝트를 재정비하고, 각 모듈간 통신이 필요하다면 인터페이스를 정의하여 각 도메인 경계를 명확히 분리하고, 도메인 간 접근 및 호출을 정의해주는 것이다.
이에 따라 Facade Pattern을 통해 도메인간 결합도, 의존성을 낮추어 구조전환 작업을 좀 더 빠르게 진행할 수 있게 된다.
참고로 굳이 MSA 전환을 위한 의도가 아니더라도, 도메인 및 책임을 명확하게 분리할 수 있기에 Clean Architecture 관점에서 이를 잘 구현한, 가독성이 좋고 관리가 용이한 구조라 할 수 있다.
Monolithic 구조에서 MSA의 장점을 취하기 위해 이러한 Modular Monolithic 구조를 개발 설계 시점부터 적용할 수 있겠으나, Public API 노출 및 경계 명확화, 결합도를 최소화하기 위한 방안 등 그만큼 팀 운용에서 확실하게 정하고 규칙을 적용하는 방법이 필요하다.
Strangler Fig Migration
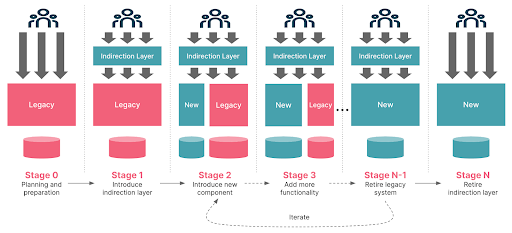
Strangler는 다른 나무를 감고 올라가 결국 숙주를 죽이는 식물을 의미하는데, 이때 숙주는 기존 시스템인 Monolithic을, 새로운 나무는 이를 교체하는 MSA 서비스를 의미한다.
Strangler Fig Migration의 핵심 단어는 "점진적 기능 추출"이다.
주로 API Gateway, 혹은 이에 준하는 인터페이스를 통해 신규 개발된 요청은 MSA 서비스에 라우팅하고, 기존 기능들은 기존 시스템에 라우팅하여 서비스 호출을 분리하는 과정을 의미하며, Strangler Fig Migration은 나아가 MSA로 점진적인 Scaled Out을 진행하는 동안 두 시스템을 병행 운용하는 것 자체를 의미한다는 점에서 유의할만하다.
단순 서비스 호출을 분리하는 것 부터 시작하여, 그 후로 로직을 점진적으로 수정하고 데이터베이스를 수정한다는 것이 큰 기조이다.
Strangler Fig Migration을 진행하면서 생기는 데이터 불일치 및 일관성 문제를 빠르게 파악하여, 이를 조정하는 과정이 반드시 필요하겠다.
Branch By Abstraction
위에서 기술하였던대로, 점진적 변화를 취하되 그 시작을 기존의 로직에서 변화한(MSA) 로직으로 전환하되, 바로 전환하지 말고 일단 인터페이스를 도입하자는 아이디어이다.
interface PaymentService {
void pay();
}이와 같이 인터페이스를 도입하고,
class LegacyPaymentService implements PaymentService {
public void pay() {
// 기존 로직
}
}class NewPaymentService implements PaymentService {
public void pay() {
// 새로운 로직
}
}기존의 로직과 신규 로직(MSA에 적용될 로직)을 인터페이스를 통해 적용할 수 있도록 장치를 마련하는 것이다. 이때,
if (featureFlag) {
newPaymentService.pay();
} else {
legacyPaymentService.pay();
}feature flag(Toggle)을 적용하여, 전환된 로직에 문제가 발생하였다면 즉시 기존 로직으로 fallback을 하거나 분기를 전환하는 방법으로 로직을 구성하는 방법이다.
사실 Wrapping이라는 것 자체가 구조적으로 그리 좋은 방법은 아니지만, MSA 환경으로 전환하기위해 점진적인 변화 장치를 두기 위해 임시로 조치하는 것으로 이러한 추상화 과정을 도입하는 것이다.
Event Interception & Data Facade Pattern
로직을 전환하였다면, 이제는 본격적으로 데이터베이스의 전환 및 일관성을 확보하는 작업이다.
이 과정에서도 중요한 것은 점진적 변화인데, 데이터베이스 스키마를 구성하여 일괄 전환하는 것이 아니라, MSA의 Database per Service 원칙을 지키면서 전환하는 기간 동안 기존 데이터베이스와 같이 운용하되, 데이터를 동기화하면서 일관성을 확보하고, 제한적 범위 내에서 캐싱 등 부하 분산까지 점진적 전환을 취하는 것이다.
Event Interception의 경우 말 그대로 Event 기반의 비동기적 방식으로 데이터 변경에 대한 사항을 동기화처리하는 방식을 의미한다.
또한 (Debezium/Kafka Connect), Data Facade의 경우 MSA 전환이 이루어지는 과정에서 혼용되고 있는 데이터베이스에 대해 제한된 도메인의 읽기 API에 대해 Redis 캐싱을 적용하는 등 호출 과정을 복합적으로 운용하는 방식을 의미한다.
이러한 데이터베이스의 점진적 변화를 통해, 전환 과정에서 데이터 정합성을 보장하면서 Migration 범위를 Sprint과 같이 조절해가면서 단계적으로 진행할 수 있게 된다.
이 과정을 통해 Monolithic에서 MSA 구조로 점진적으로, 안전하게 전환할 수 있다.
3. MSA에서 서비스 경계 설정 및 분리 과정
MSA구조로 전환하기 위해서는 단순한 구조, 패키지의 분리뿐만 아니라 분산 환경에서 트랜잭션을 어떻게 구성할 것인지, 서비스의 경계를 어떻게 설정할 것인지 심도있는 분리 과정을 진행해야만 한다.
서비스 경계는 곧 데이터의 일관성 수준, 나아가 도메인의 통합 및 분리에 영향을 주는 중요한 요소이다.
MSA라고해서 무조건적으로 SAGA Pattern에 기반한 Choreography, Orchestration 등을 적용해야 하는 것은 아니다.
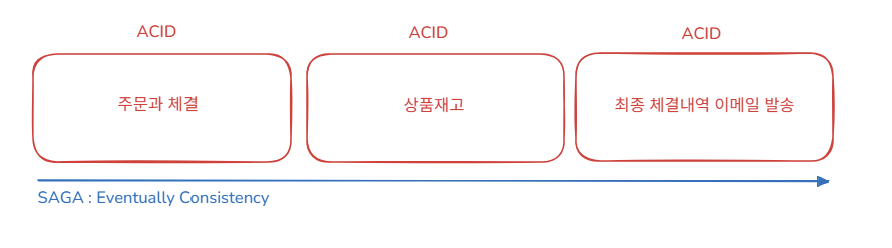
위와 같이 특정 상품에 대한 계약(주문 및 체결)에 대해 분산 환경에서 분산 트랜잭션을 구성하기 위한 방안을 고민해본다고 가정하자.
강한 데이터 일관성과 원자성을 보장해야 한다면 도메인을 분리하지 않고 하나의 도메인으로 통합 운용해야 할 것이고, 강한 일관성 및 실시간 처리보다는 데이터의 최종적 일관성(Eventually Consistency)에 초점을 둔다면 그때 독립적인 마이크로 서비스로 분리하여 운용할 수 있을 것이다.
물론, 도메인의 통합과 분리는 위와 같이 데이터 일관성 관점에서 고려할 수도 있겠으나, 보통 강한 일관성을 보장하고자 할때 수반되는 Thread Blocking 및 동기성 처리, 성능 저하 등을 고려하여 외부 체계와의 네트워킹, I/O 비용이 크다면 이때도 서비스 경계를 분리하는 것으로 고려할 수 있을 것이다.
3-1. Service Seperation
서비스 경계를 분리하는 과정에 대해 좀 더 자세하게 살펴보자.
서비스 경계를 나눈다는 것은 도메인 분리, 책임을 명확히 분리하여 그 책임 내에서 유스케이스 구현을 달성하는 목적에서 이루어진다.
다만, 그 경계를 비즈니스 기능의 집합으로 바라볼 것인가, 해당 유
스케이스 구현을 위한 데이터 모델의 집합으로 바라볼 것인가에 따라 분리 방법은 달라질 수 있다.
비즈니스 기능 기반의 분리
말 그대로 인프라, 기술, 라이브러리의 집합이 아닌 하나의 비즈니스 로직 관점에서 동일한 기능, 비즈니스적으로 진행하는 단계적 가치, 의미를 하나로 집약하여 바라보고 분류하자는 의도이다.

쉽게 말해, 주문과 주문내역은 비즈니스적으로 동일한 기능이자 책임영역으로 간주하여 하나의 도메인으로 처리하겠다는 의미이다.
전체적으로 도메인 책임이 명확하여 생명주기를 관리하는데 있어 매우 편리하고 유용하지만, 서비스 경계를 나누는 과정, 협의 과정이 어려울 수 있고 Event Storming과 같은 특수한 기법을 도입하기도 한다.
데이터/모델링 기반의 분리

이번에는 비즈니스 도메인, 기능적 분리보다는 데이터/스키마에 기반한 분리가 또 하나의 방법이 될 수 있겠다.
말 그대로 데이터의 소유권, 트랜잭션 패턴을 최적화하기 위한 방안에 기반한 DB per Service 원칙에 기반한 분리로, 데이터 모델링적으로 일관성과 원자성을 강하게 지켜야하는 경우, 이에 따라 스키마의 의존도가 높은 모델링의 경우 하나의 도메인으로 보겠다는 의미이다.
어렵게 생각할 필요 없이, 주문과 주문내역(History)를 별도의 도메인으로 분리하겠다는 사상이다.
당연히 이로 인해 불필요한 서비스 분리, 이벤트 과다 호출, 특히 CQRS의 경우 의도된 비정규화로 인해 데이터 일관성 문제 등 관리 측면에서 상당히 번거롭고 힘든 요소가 많이 존재하는 방안이 될 수 있다.
인터페이스 기반 분리(BFF)
Backend For FrontEnd, 클라이언트 별, 클라이언트라 하면 Mobile 혹은 Web 에서의 요청 등 각 필요한 영역과 책임에 맞게 프로젝트 및 API 구성을 맞춤화하여 제공하겠다는 방법이다.
일반적인 범용 API가 아닌, Core Service를 조합하여 클라이언트 및 요청 패턴에 따라 자율적으로, 적절하게 조합하여 엔드포인트를 제공하고, 이에 따라 데이터 간소화 및 패턴 최적화 등을 이루어내겠다는 의도이다.
3-2. SAGA Pattern
서비스 경계를 분리하였다면 각 분산 환경에서 데이터 일관성을 보장할 수 있는 처리 패턴을 적용하면 될 것이다.
보통 이에 대한 표준으로 사용하는 것이 SAGA Pattern, 본래 현대 데이터베이스에서 Long Lived Transaction에 대해 대응하도록 도입된 개념이지만 분산 환경에서 트랜잭션의 서사를 구성하여 처리하는 형태로 알맞게 다듬어진 패턴이다.
분산트랜잭션을 구체화하기위한 SAGA Pattern의 형태의 가장 큰 특징점은 서비스 간의 낮은 결합도와, 확장성, 가용성 등 CAP 원칙을 최대한 준수하여 도입된 하나의 방안이라는 것이다.
서비스간의 결합도를 최소화하여 각 도메인의 스키마 변경 등에 영향을 받지 않고, 로컬 트랜잭션이 이벤트 기반의 자율적 진행, 특히 로컬 트랜잭션이 해당 도메인에서 원자성과 일관성을 확실하게 보장하는 적절한 범위에서 진행되기에 필요한 작업 범위에 대해 명확히 처리할 수 있는 장점을 지니게 된다.
Coordinator 기반의 동기적 2PC, 3PC 처리보다는, 각 서비스가 발행하는 이벤트를 통해 상호작용하며, 이 상호작용은 최소한의 인터페이스로 이루어지기에 도메인간의 변경점 전파도 그만큼 최소화할 수 있다.
3-3. Exception/Fault Tolerance
무엇보다 SAGA Pattern의 중요한 점은 트랜잭션이 실패하였을때 보상(Compensating) 트랜잭션을 진행하는 등 일관성 보완 작업에 대해 충분히 설계하고 적용해야 한다는 점이다.
Eventually Consistency의 이면
SAGA Pattern의 사상은 데이터 일관성을 실시간 유지하는 것이 아니라, 모든 트랜잭션이 완료되었을때 시간차를 두어 일관성을 완성하는 것에 있다.
따라서, SAGA Pattern에서 로컬 트랜잭션의 depth가 깊어진다면 일정 수준 이상의 depth는 피하거나, 각 depth에서 발생하는 여러 예외 및 오류 상황에 대해 충분히 인지하고 보완책을 설계하는 안목이 반드시 필요하다.
특히, 단순히 각 로컬 트랜잭션 처리가 실패하였을때 재시도를 하거나, 최악의 경우 이전의 saga를 논리적으로 원복하는 보상 트랜잭션을 넘어, 이벤트 메시지가 도달하지 못하였을때, 이벤트 메시지가 도달하였더라도 해당 phase를 진행하지 못하였을때 등 외부 메시징 체계를 도입하면서 발생할 수 있는 일관성 저해 상황에 대해 충분히 고려하고 보완책을 도입할 필요가 있겠다.
뿐만 아니라, saga 트랜잭션 요청이 동시에 들어왔을때, 다른 saga가 진행하는 동안의 변수를 다른 스레드가 읽는 구조적 Dirty Read가 발생할 수 있으므로, 상태값(Pending/Reserved)에 기반한 트랜잭션 처리 및 보상 등 트랜잭션 처리를 통해 일관성을 최대한 보장할 수 있도록 모델링을 하는 작업도 필요할 수 있다.
그리고, 메시지를 처리하였어도 메시지 처리 과정에서 오류가 발생하여 재시도를 하는 과정에서 멱등성을 보장할 수 있는 부분까지 고려가 필요할 수 있다(단순히 메시지를 재처리하는 것 뿐만 아니라, 메시지를 중복으로 발행할 수도 있음에 유의).
3-4. CQRS
도메인 서비스 경계를 나누는 과정과 더불어, 도메인 내에서도 트래픽 패턴이 명확하게 다르기에 이를 기능적으로 분리하여, 내부 호출 및 I/O 패턴을 완전히 다르게 구성하는 것까지 고려해볼 수 있겠다.
CQRS, Command Query Responsibility Segreation
말 그대로 명령 처리에 대한 패턴, 책임에 따라 분류하는 패턴으로 트랜잭션을 서사대로 구성하는 SAGA Pattern에서 나아가, 명령에 대한 세분화를 구현하기 위한 하나의 방법이다.
예를 들어, 계약상품에 대한 계약을 진행하기 위해 주문/체결 - 재고 감소로 SAGA Pattern을 구성하여, 이 시스템을 기반으로 상품 주문 통계내역 추출에 대한 성능을 최적화하는 방안을 고민해본다고 가정하자.
일단, 상품 도메인은 일반적으로 상품 통계 및 재고 추출 등 조회에 대한 요청이 중점적으로 이루어지고, 쓰기 요청은 상대적으로 요청률이 적다고 할 수 있겠다.
이 상황에서, 쓰기와 조회 트래픽에 대해 트랜잭션 접근 및 호출 경로를 동일하게 설정하지 않고, 각 패턴에 맞게 별도로 최적화하여 구성하는 것이 바로 CQRS이다.
- Product 주문 및 재고 현황에 대한 변경(Write Pattern)
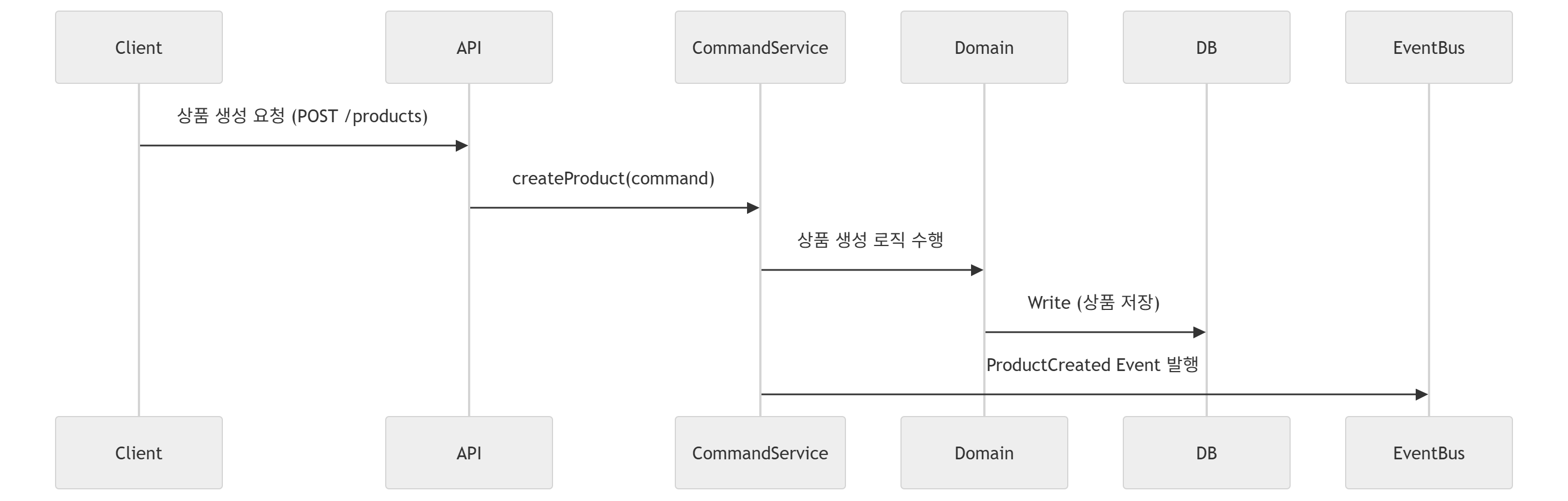
위와 같이 Write 트래픽에 대한 과정은 Master DB에 대해 진행하며,
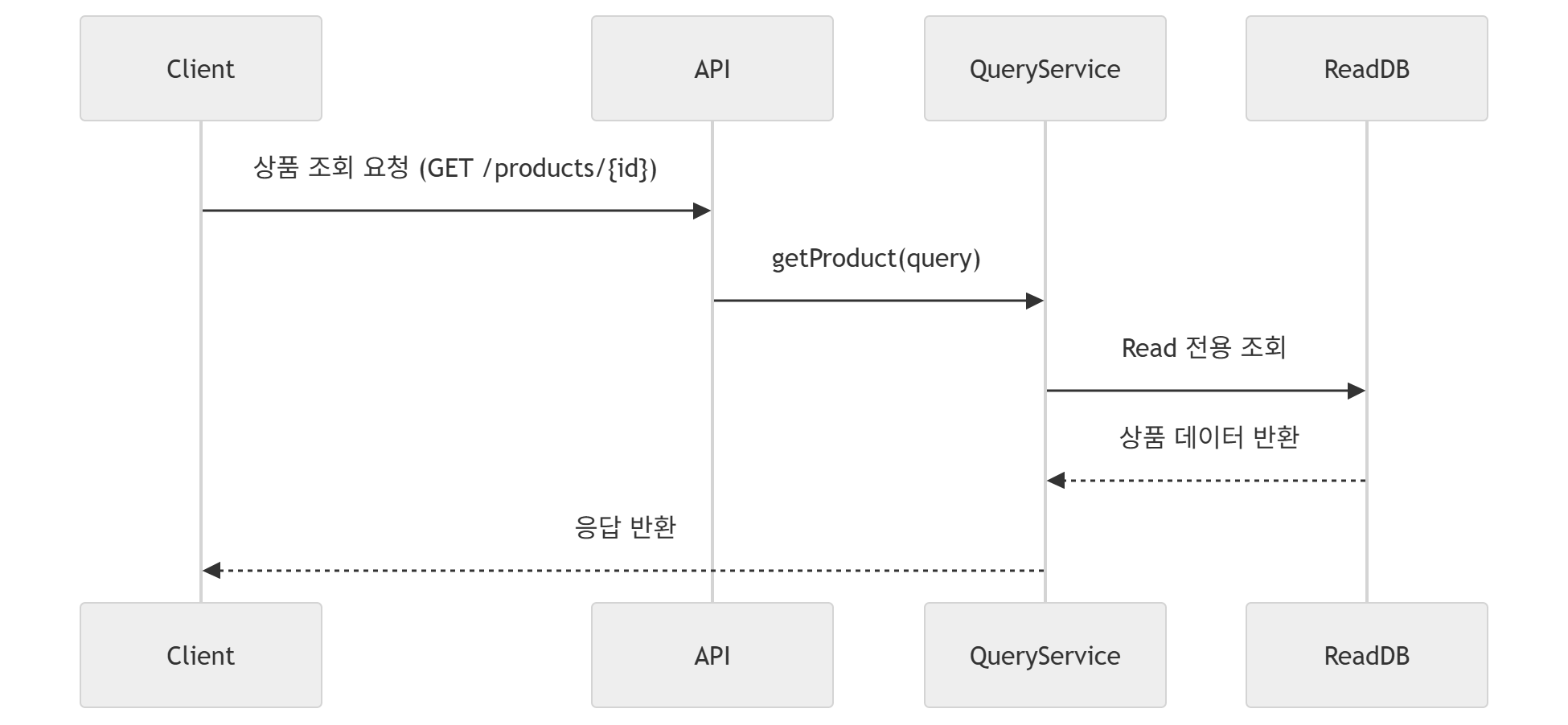
Write 트래픽에 비해 훨씬 많이, 중점적으로 발생하는 Read 요청에 대해서는 쓰기 성능을 최적화하기 위해 별도의 Replica DB 혹은 인메모리 데이터베이스 기반의 접근 경로를 설정하여 조회 성능을 향상할 수 있도록 별도의 패턴을 구성한다.
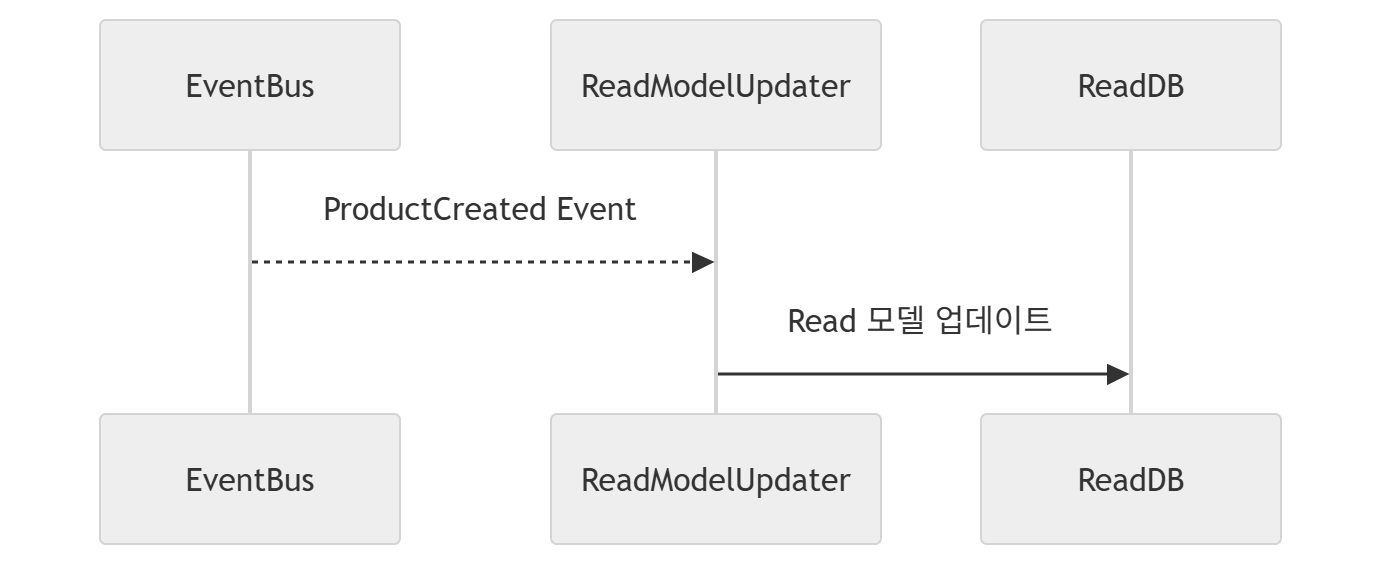
이때 통계 데이터는 Eventually Consistency의 일관성 보장에 맞추어, 각 트랜잭션이 바라보거나 접근하는 데이터베이스에 대해 비동기적 동기화 작업을 진행해주어야 한다.
이처럼, CQRS는 모델 분리라는 본질적인 사상에 기초하여, 쓰기 성능과 읽기 성능을 최대한 향상하여, 특히 읽기 처리 시 QueryModel이라는 별도의 DTO/엔티티를 운용하여 데이터 관점에서의 Seperation으로 시스템을 세분화, 구체화하는 과정을 진행하는 것이 목표이다.
3-5. DDD
Domain Drived Development, DDD는 서비스 간의 경계를 구분하고 명확한 책임에 따른 유즈케이스 구현을 위해 사용하는 하나의 개발 방법론이다.
하지만, 나아가 DDD는 MSA 환경, 뿐만 아니라 Monolithic에서도 Modular Monolithic, Clean Architecture를 위한 책임 분리를 위해 사용하는 이론적 배경으로 활용할 수 있는 중요한 개념이다.
DDD에 기반한 MSA 환경 구축은 가장 이상적인 환경에 가깝겠지만, 그 차선책으로 DDD 개념을 활용하여 서비스 경계를 구분하고 유즈케이스 구현을 하는 방향으로 설계를 진행하여도 좋을 것이다.
그렇다면, 그 DDD 개념과 요소, 설계 과정에는 어떤 내용이 있을까?
Bounded Context
DDD는 실생활, 비즈니스 과정에서 수반하는 모든 필요 요소들을 객체화하여 나타낸다.
- Order
- Cart
- User
- Payment
- Money
- Address
- Delivery
...이때 객체화한 모든 요소들은 같은 단어이지만, 개념적으로 각 도메인 별로 다르게 받아들여질 수 있다.
예를 들어 "Order"라는 객체 혹은 비즈니스 단어는, 그 단어를 사용하는 맥락 및 문맥, 도메인 등에 따라 다른 의미로 해석이 될 수 있는 것이다.
| Context | “Order” 의미 |
|---|---|
| 주문(Order) Context | 고객이 만든 주문 |
| 배송(Delivery) Context | 배송 대상 |
| 정산(Billing) Context | 결제 대상 |
이때 동일한 객체, 단어라도 그 의미가 통용되는 범위와 유효성이 도메인 별로 달라질 수 있고, 그러한 "의미", "문맥"이 유효한 범위를 Context라 한다.
이걸 반대로 말하면, 특정 도메인 모델이 유효한, 의미나 가치적으로 통용될 수 있는 범위를 Context라 하는 것이다.
결국 하나의 모델로 모든 비즈니스를 처리하지 않고, 각 비즈니스 의미를 도메인별로 분리하고 책임을 나누어 낮은 결합도, 높은 응집도의 적절한 MSA 환경을 구축하는데 책임분리, 이는 곧 DDD에서 Bounded Context를 설정하는 과정과 동일하다.
Ubiquitous Language
Bounded Context에서 개발자, 고객, 유관 부서가 동일한 개념으로 활용할 수 있도록 소통하는 언어이자 체계로, 결국 위에서 기술한 도메인 모델의 유효성, Bounded Context에서 유효한 의미를 나타내는 개념이다.
이는 도메인 모델을 나타내는 언어이자, 소통 방식이기도 하기에 불필요한 의사소통 및 이해를 위한 소모 비용을 줄여주는 체계이다.
개발자 입장에서는 Ubiquitos Language를 활용하여, 해당 도메인에 대한 비즈니스를 이해할 수 있는 상태 관리 및 API 구성을 진행해야 한다.
Aggregate
이제 어느정도 도메인 경계, 객체 및 요소의 구성 정보를 파악하였다.
트랜잭션의 일관성, 데이터의 일관성을 확보하기 위한 트랜잭션 컨텍스트, 세부적으로는 트랜잭션에 필요한 요소(factor)들을 어떻게 활용할 것인가에 대한 대답이 바로 Aggregate에서 비롯된다.
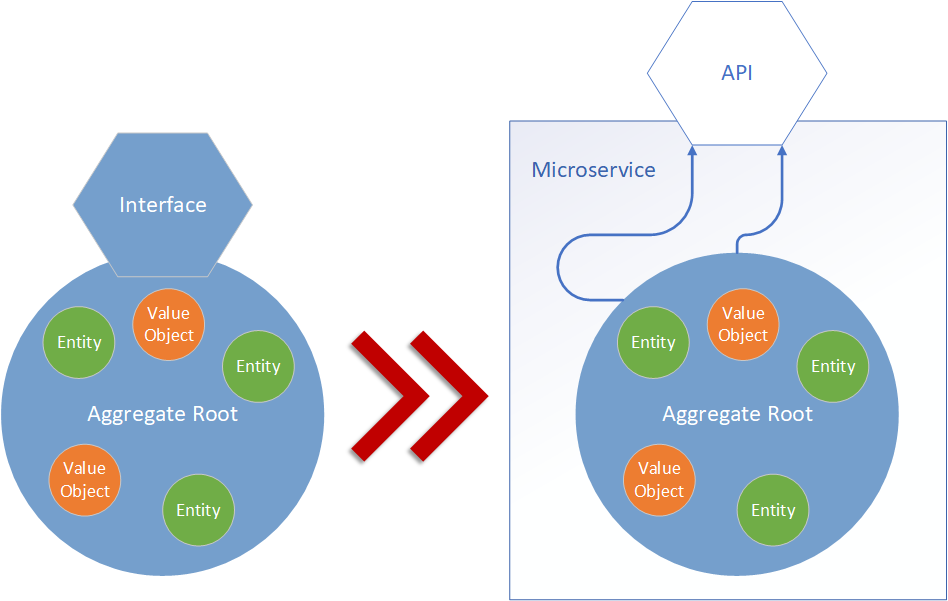
Aggregate는 각 도메인 경계에서 책임 경계 내에서 데이터 일관성을 보장하기 위한 트랜잭션 구성 요소를 "도메인 개념"으로 경계화하는 과정을 의미한다.
쉽게 말하면 데이터 일관성을 보장하기 위해 비즈니스 로직을 구성해야 하는데, 이때 필요한 요소들을 지정하기 위해 Bounded Context의 요소들을 명확히 경계화(Consistency Boundary), 응집화하는 것이다.
동일한 도메인이라도, 여러 트랜잭션이 존재할 수 있고 심지어 같은 비즈니스 로직/문맥이더라도 패턴을 다르게 가져갈 수 있기에(CQRS) Bounded Context 내부에서 활용하는 요소들은 트랜잭션마다 aggregate, 응집화 범위 및 경계가 다를 수 밖에 없다.
이 수많은 aggregate들중에 다른 Context, Client 측에서 접근할 수 있는 경계는 Aggregate Root가 유일하고, 이 Root에서 인터페이스를 별도로 추출하여 Open API/Open Host API를 제공하여 외부에서 내부로 접근할 수 있는 접근 경로를 제공하게 된다.
Aggregate 자체가 해당 도메인, 도메인 트랜잭션의 규칙을 포함하고 있기에 Aggregate Root를 통한 접근 및 호출은 반드시 해당 도메인의 규칙을 준수한다는 의미도 내포하고 있다.
예를 들어,
Order (Aggregate Root)
├── OrderItem
├── ShippingAddress (Value Object)
└── PaymentInfo (Value Object)위와 같은 다양한 Aggregate가 존재하더라도, Order라는 Bounded Context를 접근할 수 있는 유일한 접근 경로는 Order라는 Aggregate Root라는 점이다.
order.addItem(...); -- OK
orderItem.changeQuantity(); -- 직접 접근 금지이처럼 Aggregate Root 이외의 "경계"에서는 외부에서 접근이 불가능하고, 나아가 데이터 일관성을 보장해주지 못한다.
데이터의 일관성을 유지할 수 있는 Aggregate Root를 통한 접근과 호출만이 해당 도메인 모델의 유효성을 보장할 수 있는 유일한 경로임을 반드시 기억하자.
참고로, Aggregate는 단순 조합이 아닌 데이터 일관성을 보장할 수 있는 경계, 일관성의 의미이기에 DTO나 Entity와 같은 객체의 의미보다는, 그러한 객체들을 조합하고 비즈니스 단계로의 가치를 가지고 있는 또 하나의 도메인, 세부적인 영역으로 바라보는 것이 좋겠다.
| 구분 | 역할 |
|---|---|
| Entity | 식별자 + 상태 |
| Aggregate | 일관성 경계 |
| DTO | 데이터 전달용 (네트워크용) |
참조. DDD 기반의 컨텍스트 분리와 통신
참고로, 이러한 DDD기반의 컨텍스트 분리가 이루어졌다면 DDD기반의 도메인간 통신이 이루어진다면 좋을 것이다.
이에 대한 방법이 바로 Context Mapping이다.
말 그대로, Bounded Context 간의 주도권, 연결, 네트워크, 관계, 방향성 등 두 도메인 간의 상호작용과 통신을 위한 체계가 바로 Context Mapping이라 볼 수 있다.
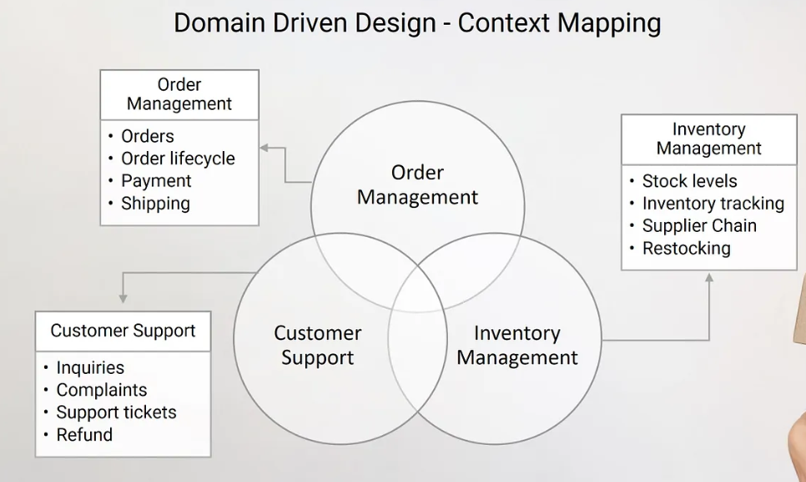
이러한 각 Context 간의 통신을 위해 누가 주도권을 보유해야 하는가, 주도권을 보유한 측에서 어떠한 Spec을 필요로 하는지 API "계약내역"까지 지정해주는 과정을 의미한다.
가령, 주문을 할때 상품이 먼저 존재해야 하기에, 주문 Context 입장에서는 상품 Context에 의존적이다.
Order → Inventory따라서, Order 입장에서 Inventory는 Supplier이고, Inventory 입장에서 Order는 Customer이다.
- Customer = Order
- Supplier = Inventory
이 상태에서, Upstream Context인 Inventory가 DownStream 측에서 일관성있는 API를 사용할 수 있도록 인터페이스, 즉 계약 내역(Published Language)을 제공하는 과정이 필요하겠다.
참고로, 모든 Context에서 사용하는 범용적인 객체 및 요소(Money, Address, Email 등)에 대해 각 도메인 별로 재량껏 통합하거나 구현하여 사용할 경우, 범용 객체를 미리 Common Type으로 지정하여 사용할 수 있다.
이때 지정한 Common Type을 DDD에서는 Shared Kernel이라 하며, 이러한 범용적으로 활용하기 위한 도메인을 별도로 지정하여 결합도를 낮추는 방식으로 활용할 수도 있겠다.
4. 분산 트랜잭션의 구축
분산 환경을 구성하였다면, 분산 트랜잭션을 구축하여 이제 본격적으로 비즈니스 로직을 적용하는 과정을 진행하면 되겠다.
분산 트랜잭션의 표준은 각 로컬 트랜잭션이 다른 도메인의 결과를 기다리지 않고, 일단 진행하는 낙관적 방식의 SAGA Pattern과, 트랜잭션 진행 도중 오류가 발생하였을때 Eventually Consistency 기반으로 이를 보장하기 위한 트랜잭션 보상을 생각할 수 있겠다.
물론 Kafka, RabbitMQ 모두 Retry나 Buffering(Client 측에서 메시지 처리를 실패하였을때 메시지를 제거하지 않고 큐에 보관하는 패턴)이 시스템적으로 잘 이루어져 있기에, 추가적인 보상 파이프라인이나 메시지 전달 과정에서의 유실 등 어느 정도 예상된 오류에 대한 대응책을 설계할 수 있을 것이다.
하지만, 데이터 일관성을 어느 정도 수준으로 보장하느냐에 따라 위와 같은 비동기말고 동기 방식(2PC), 혹은 비동기 방식이지만 동기 방식에 가까운 일관성 보장 및 로컬 트랜잭션의 단계적 운용 방식(TCC)를 채택할 수도 있겠다.
동기식 방식의 경우 설계적 보상보다는 Application의 Rollback 요청에 의한 데이터 원복이 주된 복구 요소이기에, DB와 Application 간의 상호작용과 DB의 WAL 등과 같은 복구 메커니즘을 잘 이해하고 있는 것이 중요할 것이다.
이 분산 트랜잭션에 대한 세부적인 내용은 별도로 자세하게 기술하도록 한다.
5. 분산환경에 적용할 수 있는 트랜잭션 패턴
이외에도, 분산환경에서 구성할 수 있는 다양한 방안들이 존재한다.
분산환경에서 환경 자체를 구축하는 것도 중요하지만, 분산환경에 적절하게, 성능을 저해하지 않는 선에서 분산 트랜잭션을 적절하게 구성하는 것도 중요한 요소이다.
무조건 SAGA Pattern을 적용하는 것이 아닌, TCC, 3PC와 더불어 Aggregator, BFF, Service Discovery Pattern 등 매우 다양한 패턴들이 존재한다.
중요한 것은 이러한 패턴들이 있다는 것을 외우는 것이 아니라, 분산 시스템에서 분산 트랜잭션을 설계하기 위한 안목으로 활용하자는 것이다.
선배님들의 분산 트랜잭션 패턴은 어떠한 것들이 존재하는지 살펴보고, 이러한 분산 트랜잭션 패턴들을 보면서 어떠한 설계적 안목을 넓힐 수 있을지 고찰해보도록 하자.
5-1. Aggregator
DDD의 Aggregate와는 비슷하게 생겨서 헷갈릴 수 있는데, 본질적으로 다른 개념이다.
DDD의 Aggregate는 도메인 모델이 유효한 범위 내의 흩어진 여러 객체, 요소들을 데이터 정합성 관점에서 묶고 응집화하는, 도메인 모델의 단위이자 정합성을 유지할 수 있는 최소한의 단위이다.
Aggregator는 조합의 의미가 강하다.
사실 Aggregatgor는 분산 트랜잭션이라기 보다는, 분산 환경에서 각 다른 도메인 서비스의 읽기 성능을 조합할때 성능을 향상시킬 수 있는 방안이다.
분산 환경에서 다른 서비스들을 조합(Composition)하여 하나의 응답을 생성하고자 할 경우, 이를 병렬적으로 요청하여 결과를 조합해서 하나의 응답으로 처리한다는 관점이다.
Aggregator의 가장 큰 특징은 네트워크 호출을 1번으로 줄이는 것이다.
Redis의 layer 패턴에서 client측에서는 호출 인터페이스에 대해서만 관심이 있고 내부적으로 서비스 호출을 별도로 진행하는 것처럼, Aggregator 패턴 역시 외부 상호작용은 하나의 api 요청을 통해 이루어지고 내부 서비스들을 병렬요청으로 응답을 조합하는 방식이다.
조합은 나아가, 부분응답의 개념이 강한데,
주문 상세 화면
- 주문 정보 (Order Service)
- 사용자 정보 (User Service)
- 상품 정보 (Product Service)
- 배송 상태 (Delivery Service)위와 같이, 주문 상세 화면에서 각 분산된 도메인의 서비스를 호출하여 응답값을 가져와야 한다고 가정해보자.
- Naive
순수하게 Monolithic 구조처럼 Client 측에서 각 분산 도메인에 1개씩 서비스를 호출하고, 그 응답을 기다리는 동기식 방식으로 분산 트랜잭션을 구성할 수도 있겠다.
Client → Order
Client → User
Client → Product
Client → Delivery하지만 각 서비스에 호출하는 네트워크 I/O가 4번 발생하고, 그만큼 각 응답을 기다려야 하기에 latency가 증가할 수 밖에 없다.
- Aggregator
하지만 Aggregator 패턴에서는 기본적으로 네트워크 진입 경로를 분산 환경 개수만큼 open하는것이 아니라, 단 하나의 호출 경로만 존재하도록 구성한다.
Client → Aggregator → (병렬 호출)
↳ Order
↳ User
↳ Product
↳ Delivery외부와 맞닿는 인터페이스는 단 하나이고, 내부적으로 서비스들을 병렬호출하고 조합하는 형태로 응답을 받아오는 형태인것이다.
Aggregatgor의 내부 동작 구조는 크게 3가지이다.
- 각 분산된 도메인 서비스들을 병렬 호출한다.
- 느린 서비스를 기다리지 않고, 전체 응답이 아닌 개별적 응답을 취한다.
- 각 개별적 응답이 실패하였을때 Circuit Breaker, Fallback 등의 우회경로를 지정하고 이에 따른 결과를 받을 수 있다.
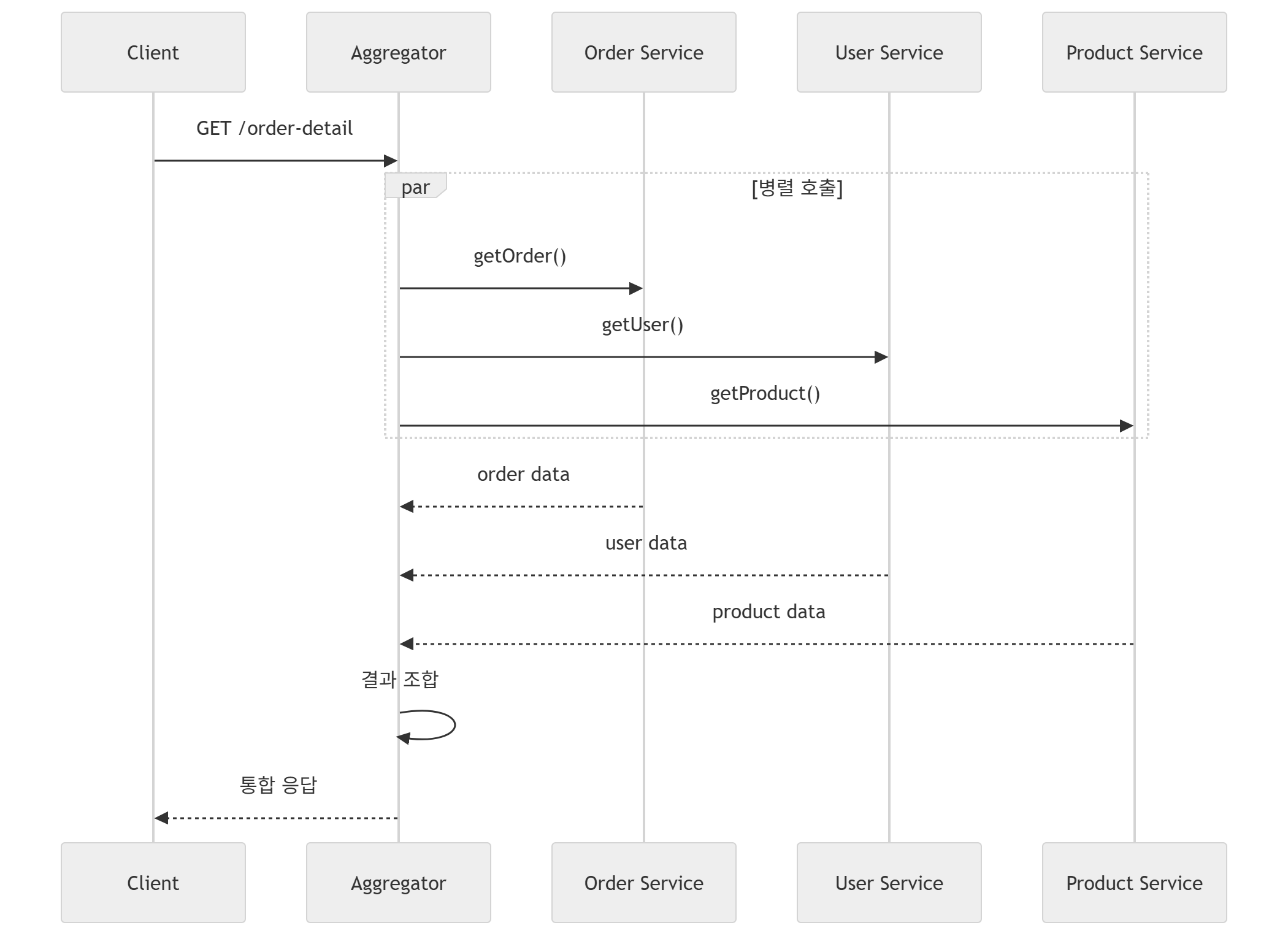
위와 같이, Aggregator가 Client와 상호작용하는 인터페이스가 되며, 내부적으로 각 분산 환경 서비스를 호출하고 결과를 조합하여 인터페이스를 통한 통합 응답을 제공한다.
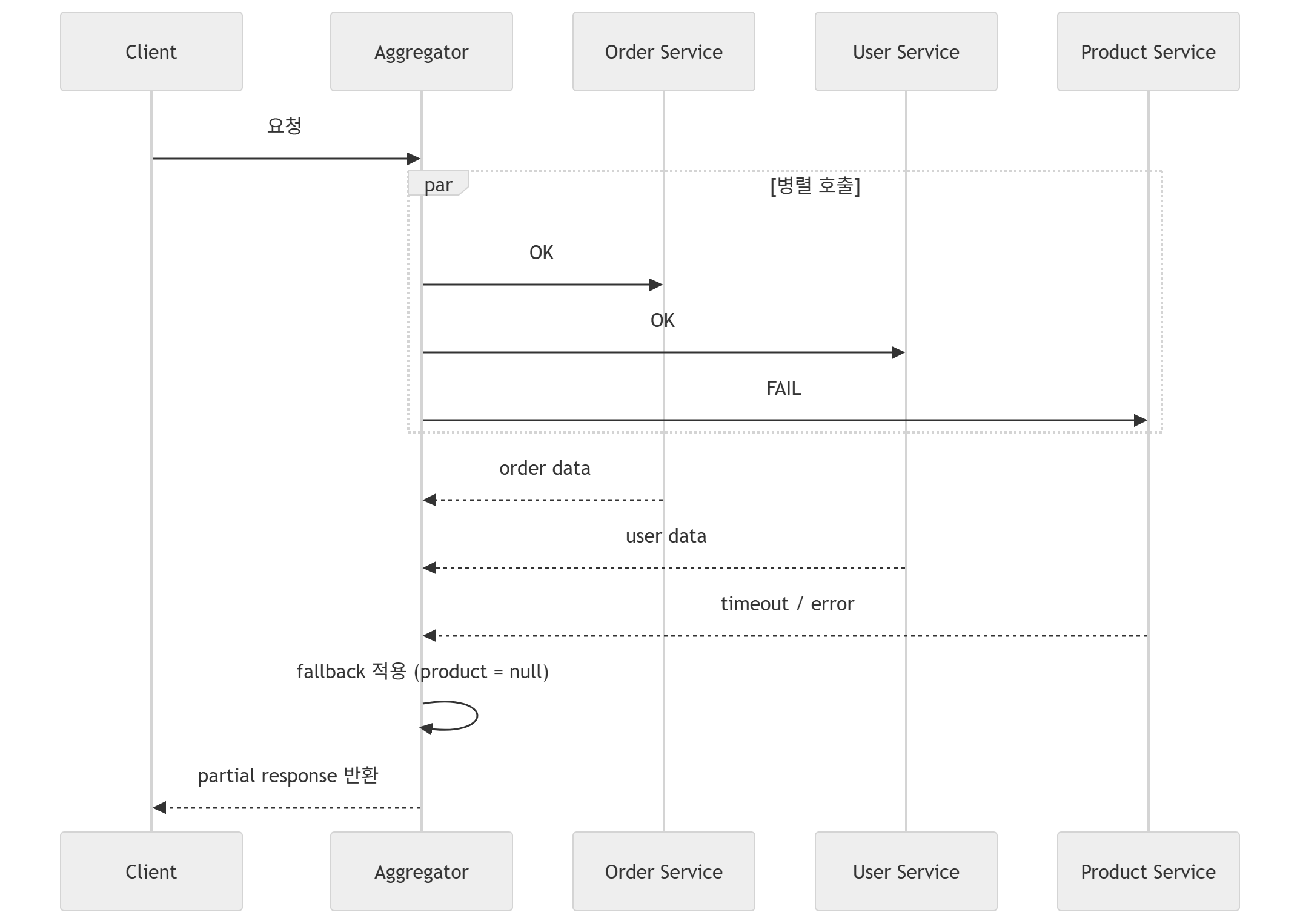
만약 일부 환경에서 오류가 발생한다면, 전체 응답이 False가 되는 것이 아닌 부분적인 오류를 유지한 채로 Partial Response를 응답한다.
Pseudo 코드를 보면 좀 더 이해가 용이해지는데,
CompletableFuture<Order> order = supplyAsync(() -> orderService.get());
CompletableFuture<User> user = supplyAsync(() -> userService.get());
CompletableFuture<Product> product =
supplyAsync(() -> productService.get())
.exceptionally(e -> null); // fallback
CompletableFuture.allOf(order, user, product).join();
return new Response(
order.join(),
user.join(),
product.join()
);이처럼 각 서비스 호출들의 결과를 순차적으로 기다리는 방식이 아닌, 각 서비스들을 병렬로 호출하여 서로의 결과를 간섭하지 않고 병렬로 서비스의 응답을 조합하는 방식이다.
전체적인 체계는 동기적 방식이지만, 네트워킹을 한번으로 줄이고 내부적으로 병렬로 호출할 수 있기에 성능적으로 보완할 수 있으나 사실상의 Facade 패턴이기에 서비스간 결합이 그만큼 증가하고, 일정 depth 수준 이상 깊어지지 않도록 서비스의 결합도를 조정해야 하는 방안이 필요하다(결합도가 지나치게되면 God Service가 되어 구조적으로 비대해지고 관리가 어려워진다).
5-2. BFF
Backend For Frontend, 말 그대로 범용적으로 Service 및 서비스 아키텍처를 구성하는 것이 아닌, FrontEnd에서의 요구사항에 맞춰 맞춤형적인 인터페이스 및 서비스 아키텍처를 구성하여 제공하는 방안이다.
BFF의 출발점은 동일한 서비스 레이어, 도메인이 있다고 하더라도 이에 대한 개념과 활용정도가 다르기에 각 Bounded Context에 맞게 백엔드 서비스를 조합하거나 적절하게 사용하여 제공해야 한다는 생각에 있다.
심지어, Mobile 및 PC Desktop 등 같은 도메인이더라도 플랫폼에서의 데이터 사용량이나 반응형 UI 등 여러 부분에서 많고 적은 차이가 발생할 수 있기에, 각 요구사항에 맞는 적절한 데이터 네트워크 유량 등을 맞추기 위한 특별한 전략이라 볼 수 있다.
기본적으로 모바일에서는 경량화된 데이터 용량, 데이터의 절대적인 "개수"가 PC에 비해 적으므로 불필요한 데이터 네트워킹을 방지하기위해 도입할 수 있는 패턴이다.
보일러 플레이트나 가용한 서버의 개수, 운영복잡도가 늘어난다는 단점이 있지만 각 프론트엔드에 대한 인터페이스 계약을 필요 수준만큼 정확하게 구현하고 제공할 수 있기에 극한적인 성능 향상을 위해 고려할 수 있는 아키텍칭 패턴이라 할 수 있겠다.
5-3. Service Discovery
다양한 마이크로서비스가 흩어져있는 분산 환경에서 서비스를 호출하기 위한 패턴으로, 서비스의 진입점을 각 도메인 그 자체로 볼 것인지, gateway 및 Load Balancer와 같은 단일 진입점으로 볼 것인지, 즉 서비스 호출 지점에 따라 나누는 패턴이다.
이때 Discovery는 쉽게 말하면 endpoint의 진입지점이라 보면 되겠다. 호출 혹은 접근하고자 하는 서비스를 어디서 탐색(lookup)하는지에 따라 세부적인 Discovery 패턴이 나뉘어진다.
- Server Side Discovery
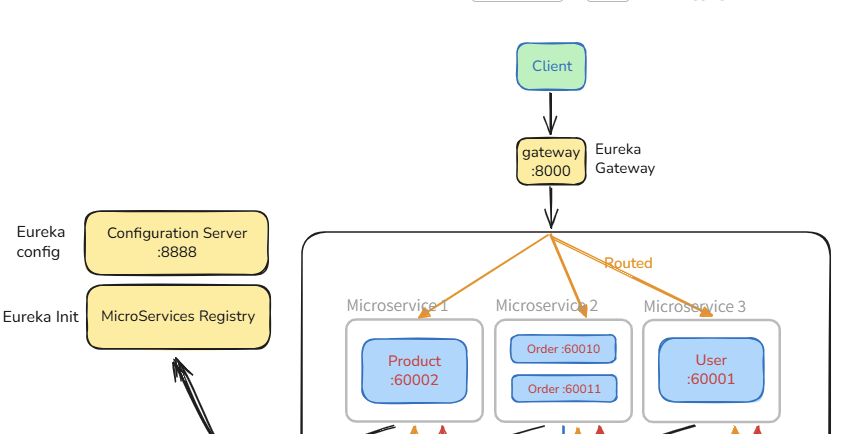
Client가 아닌, Server에서 Load Balancer 및 Gateway를 통해 서비스 호출 진입점, 즉 적절한 인스턴스로 Routing을 해주는 패턴이다.
Client 측에서는 서비스 인스턴스의 물리적 주소 및 포트번호를 직접 알 필요없이, gateway라는 단일 진입점만 알고 있어도 충분하며 해당 서비스 엔드포인트를 중앙의 라우팅 서버에서 탐색(look up)하기에 Server Side Discovery라 한다.
Server Side Discovery의 장점은 단순한 단일 진입점 뿐만 아니라, 평시 연결되어있는 마이크로 서비스에 대한 health check를 통한 서비스 가용여부 확인이 가능하며, 각 MSA의 수동적인 환경 구성이 아닌 중앙의 config server를 통해 변경사항을 비교적 쉽게 적용 가능하다는 효율성까지 확보할 수 있다.
Netflix Eureka 기반의 MSA 환경을 직접 구축하였다면 알 수 있겠지만, 각 서비스의 물리적인 IP주소가 아닌 각 서비스 ID를 매핑한 라우팅을 통해, 물리적인 주소가 변경되더라도 Client 입장에서는 변경점없이 gateway를 통한 호출을 지속할 수 있기에 유연한 운용에는 적합한 선택지일 수 있다(K8S, Nginx).
물론 그만큼 환경 구성이 복잡해지고, 모든 MSA를 중앙의 Service Discovery에 등록해야 한다는 과정이 필요하며, Discovery 및 Config 서버에 오류가 발생할 경우 단일 진입점 장애(SPOF)를 유발할 수 있기에 운용 난이도가 늘어나는 단점이 존재한다.
- Client Side Discovery
중앙의 Gateway 및 Load Balancer가 아닌, 직접 서비스 인스턴스로 물리적 주소를 조회, 요청하여 Registry로 부터 그 주소를 전달 받고 직접 해당 경로로 요청을 전달하는 패턴이다.
가용한 인스턴스 목록을 전달받는 방안이 Round Robin 등 여러 전략이 있을 수 있겠고, Eureka와 마찬가지로 결국 중앙의 Discovery(Registry)에 본인의 인스턴스를 등록해야 하는 번거로움이 존재한다.
다만, 호출을 Discovery를 통한 조회, 응답, 직접 호출의 과정으로 하여 중간의 인터셉터 및 경유과정없이 좀 더 단순하고, 그만큼 성능적으로 더 빠른 경로로 접근할 수 있다는 장점이 생긴다.
Eureka, Consul, Zookeeper가 Client Side Discovery에 속하며, 중앙의 Discovery가 말 그대로 서비스 등록 역할 이외의 어떠한 역할도 수행하지 않기에(Server Side의 주기적인 health check 등) 운용 측면에서 단순할 수 있지만 유연한 대응이 불가능할 수 있다.
6. 분산 환경을 바라보는 다양한 구조적 접근 방향, 패턴
마지막으로, 분산 환경을 구축하기 위해 어떠한 설계적 안목이나 패턴이 있는지 추가적으로 분석해보고자 한다.
분산 환경은 단순히 MSA라는 다양한 서비스가 흩어져 있는 구조에서 끝나는 것이 아니라, 각 도메인을 기능적으로 나눌지, 데이터베이스 기준으로 나눌지, 도메인 내부에서도 데이터베이스를 세부적으로 분류하기 위한 다양한 설계적 방안들이 존재하기에, 아직 분산 환경을 접하지 않았더라도 다양한 서비스를 관리할 수 있는 안목으로 그 수준을 넓혀볼 수 있겠다.
이러한 목적에 기반하여 분산 환경을 어떻게 바라보고 구성할 수 있을지 살펴보도록 하자.
6-1. 분산 환경을 구성하기 위한 기본적인 고려사항
Monolithic 구조에서는 모든 service layer가 하나의 프로젝트 및 데이터베이스를 기반으로 전역으로 공유하는 패턴이다.
결국 단일 데이터베이스를 바라보고 있기에, 한 도메인의 스키마 변경은 다른 service layer에 고스란히 영향을 줄 수 있다. 그만큼 결합도가 강하다는건데, 하지만 그만큼 Database가 제공하는 트랜잭션 Aggregation도 강하여 데이터 일관성, 트랜잭션의 원자성(ACID)를 매우 강하게 확보하고 보장할 수 있다는 장점이 있다.
결국 분산 환경은 각 로컬 트랜잭션의 원자성이나 일관성은 강하게 보장할 수 있지만, 이러한 로컬 트랜잭션을 서사로 연결하는 분산 환경에서 바라본다면 일관성 및 멱등성, 보상 로직 등의 문제가 발생하게 된다.
비동기 기반의 분산 트랜잭션 구성으로 성능은 어느 정도 보장할 수는 있겠지만, 일관성을 보장할 수 없는 trade-off가 발생하게 되는 것이다.
이러한 서비스간의 네트워크, 일관성, 성능 등을 종합적으로 고려하여 바라보아야 하는 것이 분산 환경에 대한 관점이고, 여느 설계와 마찬가지로 어느 한쪽의 우선순위와 어느 한쪽의 희생이 반드시 수반되는 적절한 방책을 고려하는 안목이 필요하겠다.
6-1. Database Per Service
각 분산환경을 기능적으로 접근할 수도 있겠지만, 일단 기본적으로 각 서비스가 자신만의 데이터베이스를 소유하는 Database per Service 구조가 그 기반이 될 수 있을 것이다.
말 그대로,
- User 도메인은 사용자에 연관된 데이터만 다루고
- Product 도메인은 상품에 연관된 데이터만 다루는 것이다.
각 도메인은 서로 간섭하지 않으며, 데이터 소유권과 이에 관여하는 기능적 범위, 영향도가 명확하게 지정된다는 장점이 존재한다(경계가 명확하지 않더라도 데이터베이스를 기준으로 한 일관성, 체계 정립이 가능하다).
각 데이터베이스 소유권이 명확하게 지정된 분산환경에서 중요한 점은 각 도메인간의 인터페이스 계약과 이를 기반으로 한 네트워킹(상호작용)이다.
결국 각 도메인이 스키마를 변경하거나 데이터베이스 구성, 비즈니스 로직을 바꾼다 하더라도 외부 도메인은 여기에 신경쓰지 않아도 된다.
각 도메인이 상호작용하는 인터페이스(계약)내용만 잘 맞추면 되는 문제이며, 다만 이로 인한 데이터 일관성, 분산 트랜잭션 구성이 복잡하게 흘러갈 수 있는 단점이 존재한다.
분산환경에서의 핵심 포인트는 결국 흩어진 로컬 트랜잭션을 어떻게 연결하고 데이터 일관성을 보장하느냐인데, 위에서 기술하였듯이 이로 인한 성능과 일관성 사이의 trade off를 선택해야 하므로 실무적 상황에 맞게 잘 구성하는 것이 좋겠다.
6-2. Polyglot, CAP theorem
Polyglot은 다개국어 언어를 유창하게 잘 사용하는 사람을 일컫는데, 분산 환경에서는 각 로컬에서 이루어지는 다양한 언어 및 운용환경을 전체적인 하나의 통합 시스템 관점에서 이르는 개념이다.
즉, 데이터베이스 혹은 기능 기반으로 흩어진 각 로컬 도메인은 그에 따라 기술, 언어, 프레임워크 등을 최적으로 선택해야 하기에 그 종류나 기준이 다를 수 있다.
이렇게 채택된 다양한 언어나 데이터베이스, 운용 환경이 각 서비스에 맞게 구성이 되어 연결이 되고, 분산 트랜잭션 구성 시 이러한 운용 요소들이 영향을 준다는 것이 Polyglot의 핵심이다.
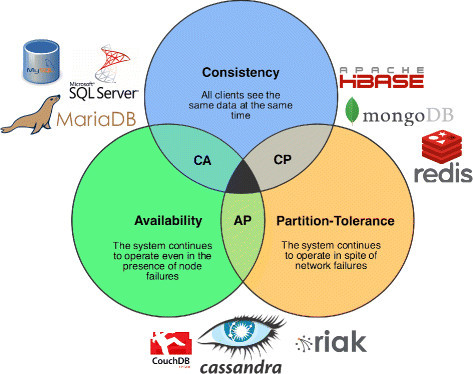
Polyglot에서 알 수 있는 점은, 각 로컬 환경에서는 서비스에 맞게 최적의 운용환경을 구성해야 한다는 점이다.
분산 환경은 단순히 하나의 서비스 장애가 다른 서비스의 장애로 이어지지 않는 분산 내결함성(Partition Tolerance)뿐만 아니라, 각 최적화된 로컬 운용환경에서 선택한 기능적/구조적 trade-off까지 고려해야 하는데 이를 CAP 이론이라 한다.
CAP이론은 분산환경의 기본적인 분산 내결함성에, 데이터 일관성을 우선하였는지(Consistency), 가용성 및 성능을 우선하였는지(Availability) 어느 요소에 더 집중하였는가에 대한 판단 기준을 제공한다.
금융권에서는 당연히 강한 일관성을 더 보장할 수 있을 것이고, Hot Item이나 MIS에서는 강한 일관성 및 동기화는 어느 정도 지연하고 좀 더 조회 성능의 향상을 목표로 시스템을 구축할 수 있겠다.
각 최적의 기술 스택이나 데이터베이스 등을 선택하는 기준도 해당 도메인의 특성, CAP이론 등을 종합적으로 고려한 결과로 생각하여 접근할 수 있겠다.
6-3. Sharding
샤딩은 데이터베이스를 수평적 확장, Scaled-Out하여 한 도메인에서 여러 데이터베이스로 데이터를 나누어 저장하는 전략을 의미한다.
분산환경 자체가 많은 트래픽 규모 환경에 선택된 전략이기에, 데이터를 한곳에 보관하여 생기는 분실 위험을 줄이고 부하도 여러 데이터베이스에 분산하여 부담을 완화하는 중요한 전략이다.
따라서, 데이터를 물리적으로 분산하는 것도 중요하지만 그러한 데이터를 어떻게 논리적으로 분산하여 저장할지 Shard Key 구성, 즉 Shard Route 전략도 매우 중요하다고 볼 수 있다.
데이터를 논리적으로 분리하는 방법은,
- 단순하게 hashing 함수를 기준으로 샤딩하거나
- 데이터 범위를 기준으로 샤딩하거나
- 데이터의 지역을 기준으로 샤딩하거나
등 여러가지 방법을 채택할 수 있겠다.
물론, 각 샤딩 방법은 명확한 trade-off가 존재하기에 각 상황에 맞게 적절한 방안을 선택하거나 직접 만들어내는 것이 중요하겠다.
참고로, hasing 함수 기준의 샤딩은 일련의 샤딩키(1,2,3,4)라도 모두 다른 데이터베이스로 샤딩되기에 그만큼 Random I/O로 인한 데이터 탐색 비용이 증가하고 조회 성능이 떨어질 수 있다.
더불어 범위 기준의 샤딩은 데이터가 한 곳에 모여 성능이나 조인 관점에서 유리할 수는 있지만, 편향된 데이터 샤딩이 이루어질 수 있고 지역(Geography) 기반의 샤딩은 지역 별 데이터가 나뉘어 질 수 있지만 특정 지역(한국/서울 등)에 데이터가 편중될 가능성이 있다.
로컬 환경 내부에서도 부하를 조절하기 위한 샤딩 전략을 적절하게 선택하여, 각 도메인에 맞는 최우선적 요구사항을 설계할 수 있는 방안으로 구성하는 것이 필요할 것이다.
6-4. 회복성과 관측성
분산환경에서 중요한 요소는 모든 로컬 환경에서 적용되는 분산 내성은 단순히 하나의 서비스가 중단되더라도, 다른 서비스의 동작에는 영향을 미치지 않는다는 의미가 아니다.
서비스의 동작이 다른 서비스에게 영향을 주지 않는 것에서 나아가, 분산 환경에서 어떠한 도메인에서 오류가 발생하였는지 파악하고 대응하기 위한 회복성, 관측성을 내포하고 있기도 하다.
즉 분산 환경의 지속성과 유지보수의 관점에서 흩어져 있는 각 서비스의 문제점을 단시간에 파악하고 회복을 이끌어내는 회복성, 관측성(가시성) Resilience/Observability의 개념도 매우 중요하다고 볼 수 있다.
현대적인 애플리케이션은 이미 이러한 회복성과 관측성을 위한 도구들을 제공하고 있고, 이를 프로젝트에 추가하여 매우 편리하게 활용할 수 있다.
- 회복성
기본적으로 서비스 응답이 실패하였을때 Retry하거나, timeout을 통해 일정 수준 이상의 응답시간이 소요될 경우 실패처리로 하는 단순한 방법이 존재한다.
하지만, 회복성의 꽃은 단연 Circuit breaker.
실패 기준을 걸어두고 실패를 하는 서비스가 일정 수준 이상으로 발생할 경우 서비스 호출을 차단하며, 자체적으로 평시 Circuit Breaker(Closed) 상태를 유지하면서 일정 수준 이상으로 서비스 호출 실패가 누적될 경우 Open, 이후 응답이 정상적으로 돌아왔을때 Half Open하여 성공률을 파악하고, 일정수준 이상으로 성공이 된다면 다시 Circuit Breaker를 닫는( Closed) 생명주기를 적용할 수 있다.
참고로 Circuit Breaker는 서비스 호출 실패율에 도달하였을때 호출 차단을 할 수도 있지만, fallback을 유발하여 사용자 경험을 개선할 수 있는 방안도 존재한다.
Bulkhead의 경우 서비스의 오류를 다른 서비스의 오류 전파로 이어지지 않도록 "격리하는 개념"이 적용된 체계이다.
정상 → 실패 증가 → 임계치 초과 → OPEN (호출 차단)
↓
일정 시간 후 HALF-OPEN → 일부만 호출 → 성공하면 CLOSECircuit Breaker는 일단 서비스 호출을 하면서, 실패율을 누적하고, 누적된 실패율에 기반한 서비스 호출 차단 체계(Reactive)이다.
Thread Pool / Semaphore로
각 서비스 호출 자원을 격리
→ A 서비스가 죽어도 B 서비스는 영향 없음반면, Semphore Bulkhead는 다른 서비스 호출 시 일단 진행함으로써 스레드 자원을 소모하는 단계까지 넘어가지 않고, 그 이전부터(실패가 발생하기 전에) 그 최대치를 제한하자는 것이다.
즉, 스레드 pool 자체를 다른 환경과 격리하여, 실패가 발생하기 전부터 실패전염을 방지하고(Preventive) Thread 점유를 처음부터 철저히 경계짓는, 리소스 제한, 환경 격리의 의미를 가진다.
- 가시성
분산 환경에서의 가시성은 각 분산 환경의 서비스 호출 과정을 TraceId, SpanId 등으로 단계적으로 모니터링하여 문제 발생 지점을 명확하게 찾을 수 있는 동작 원리를 일컫는다.
Logging 시스템, 내부적으로 해당 로깅 요소를 추출하기 위한 Metrics, Tracing 등 이 역시 다양한 OpenTelemetry 및 모니터링 라이브러리를 등록하고 사용할 수 있다.
참고로 구글 SRE에서 정한 모니터링 기준, 유지보수를 적절한 타이밍에 운용할 수 있는 Golden Signals가 존재한다.
모니터링의 지표 경험치가 부족하다면, 이러한 참고 자료를 활용하도록 하자.
이러한 회복성과 탄력성을 기본적으로 갖추고 있는 상태에서, 그 다음에 성능 보장 및 일관성 보장 등 로컬 환경에 맞는 운용 전략을 구성하는 것이 필요하다.
7. TDD
분산 환경에서 테스트는 어떻게 이루어지는 것이 좋을까?
기존 Monolithic 구조보다는 서비스 간의 계약, 인터페이스, 상호작용 검증 등 로컬 트랜잭션의 동작과 더불어 분산 트랜잭션의 관점에서도 테스트해야 할 다양한 요소들이 존재한다.
- 고려요소
일단 "What", 무엇을 테스트하기 이전에 "How", 어떠한 요소 및 환경에 대해 고려해야 하는지 살펴볼 필요가 있다.
기본적으로 트랜잭션이 로컬에서 단일로 이루어지는 것이 아닌, 데이터베이스 및 체계가 분리된 환경에서 진행되기에 테스트 상호작용, 즉 계약에 대해 먼저 정확히 파악하는 것이 중요하다.
이후, 테스트 속도와 테스트 환경 격리, 특히 환경 격리의 경우 테스트 상호작용이 서비스 운용에 지장이 없도록 구성하는 환경 구성이 필요하겠다.
- 테스트 요소
이러한 테스트 환경 구축 요소를 고려하였다면, 본격적으로 어떠한 항목에 대해 테스트를 진행하는 것이 좋을지 살펴보자.
Test Pyramid(테스트 계층화)
분산 환경에서는 기본적으로 테스트를 단일 level에서 테스트 내역을 분리하는 것이 아닌, 다양한 도메인과의 상호작용을 위해 각 서비스 별로 테스트를 계층화하여 진행하는 것이 보통이다.
이때,
- 로컬 환경에서의 Unit(평소의 Mock검증/로컬 환경에서의 비즈니스 로직 검증)
- 각 로컬 트랜잭션의 인터페이스 상태 및 동작을 Mock화하여 Integration(통합) 테스트
- 분산 트랜잭션의 일련의 과정을 E2E(End to End, 사실상의 QA) 테스트
로 이를 하나의 레벨이 아닌, 점진적 계층화하여 진행하는 것이다.
이후,
Contracting Tesing(계약 변경 시 즉시 감지)를 통해 각 도메인간의 상호작용이 원활히 일어나는지, 변경점이 발생하였는지 확인한다.
참고로 이를 CDD 기반의 테스트라 하며, Provider가 계약을 정립하지만 그 주도 및 테스트는 Customer Drived Contracts 환경으로 운용되는 환경에서 계약사항이 정상적으로 정립이 되고 있는지 확인한다.
더불어 각 분산 환경의 임계점을 확인하기 위해 부하 테스트를 진행한다.
Monolithic에서 많이 들어봤던 Performance Testing(성능 테스트)를 진행하는 것이며,
- Load test : 정상 부하(K6, JMeter)
- Stress Test : 정상 부하에서 트래픽을 늘려가면서 병목지점을 찾고 보완하는 방식
- Spike Test : 단 시간에 부하를 급격하게 증가하여 시스템의 장애 발생 지점 및 복구 능력을 파악하는 방식
의 테스트를 진행해가면서 병목지점을 정확히 파악하고, 이에 대한 내구성과 복구능력을 파악한다.
Devops에서는 이러한 테스트를 CI 환경에 적용하여 자동화하기도 한다.
Test Automation(CI)라 하며, 파이프라인 구축 성공 시 delivery/Deploy 진행하고, 테스트를 통과하지 못하였다면 Integration 단계에서 차단할 수 있게 된다.
8. Deployment Patterns
마지막으로 분산환경에서의 배포 전략에 대해서도 안목을 넓혀보자.
분산환경은 다양한 도메인이 독립적인 운용체계를 보유하고 있는 환경을 의미하며, 이에 따라 각 도메인은 개별적인 인스턴스 기반으로 구축되어 별도의 배포 전략을 가지게 된다.
변경점이 많고 적고를 떠나, 하나의 변경점 배포라도 유관부서의 협의를 거쳐 통합적인 배포가 이루어지는 Monolithic에 비해 비교적 운용, 배포 단위가 작고 자유롭기에 배포횟수가 그만큼 많아질 수 밖에 없다.
또한 정상적인 배포 및 로드 밸런싱이 이루어졌다 하더라도, 해당 환경에서 문제가 발생하였을때 발빠르게 롤백하거나 재복원하는 등의 전략도 필요하다.
따라서, 배포횟수가 많은 분산 환경에서 사용자 경험의 저해를 최대한 완화하고, 유연하게 배포를 진행하는 전략을 취하는 안목이 어느 정도는 있어야 하겠다.
이러한 분산 환경에서 유연한 Devops를 진행하기 위해 어떠한 전략을 펼칠 수 있는지 알아보자.
Sidecar Pattern(*AOP)
사이드카는 근대시대에 이륜/삼륜 오토바이와, 그 옆에 장착하는 수송기구를 장착한 탈 것에서 유래하여, Main application 혹은 컨테이너 환경에 부가적으로 장착하여 실행하는 보조 컨테이너 혹은 체계를 같이 운용하는 형태이다.
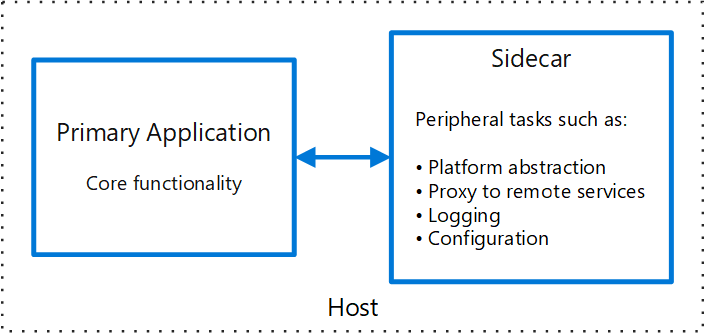
main application은 말 그대로 비즈니스 로직을 담당하게 되고, 여기에 붙이는 sidecar application(container)는 로그 수집, 환경설정, 프록시 등 부가적인 공통 관심사 로직을 전문적으로 담당하고 처리하게 된다.
Fluented, Envoy와 같이 전문적인 로깅 컨테이너 및 프록시 서버를 활용하여 구축할 수 있으며, 이 패턴에서 중요한 것은 트래픽 제어 및 보안, 모니터링 등의 인프라, 이에 준하는 공통 관심사를 별도로 구성하여 주 컨테이너에는 비즈니스 로직 처리에 집중할 수 있다는 것이다.
어떻게 보면 AOP와도 같다.
공통 관심사의 응집도가 충분히 높고 격리성이 있다면, 해당 부가 로직을 다른 필요한 애플리케이션에 붙이는 등 재사용이 가능하고, 그와 동시에 독립적인 관리가 가능하기에 유연한 대응에도 활용할 수 있다.
Canary Deployment
탄광에서 유독가스를 감지하는 카나리아라는 꽃에 유래하여, 점진적으로 배포 범위, 인스턴스를 늘려가면서 사용자 버그를 미연에 감지하고 대응하는 목적으로 진행하는 배포 방식이다.
카나리아처럼 최전방에서 미리 변경점이 배포된 인스턴스를 일부 사용자에게 공개하여, 에러율 및 latency 등을 모니터링하고 정상적인 상황에서 배포율을 점진적으로 늘려가는 것이다.
이처럼 배포율을 늘려가면서 배포하기에, 사용자 입장에서는 무중단 기반의 서비스 이용이 가능하지만 이전 버전과 새 버전을 모두 관리해야 하는 복잡성을 감안해서 전략을 선택해야 한다.
Blue-Green Deployment
기존의 운영 환경(Blue), 신규 환경(Green)을 운용하면서 기존의 트래픽을 일괄적으로 신규 환경으로 로드 밸런서를 조정하는 방식이다.
사용자 입장에서는 서비스 중단을 느낄 수 없으나, 서비스 오류가 많아질 경우 복구를 통한 점진적 확대가 아닌, 이전 버전의 운용 등 이분법적 운용이 필요하고 리소스가 어느 정도 소모가 되는 단점이 있다.
더불어, 일괄적인 운용환경 변경이 이루어지기에, 신규 환경과 기존 환경의 동기화 및 스키마 일치 등을 어느 정도는 맞춰주어야 한다는 점에 유의하도록 한다.
Rolling Update
로드 밸런서 기반으로, 신규 환경을 배포 운용할때 로드 밸런서에서 삭제한 후 health check 통과 및 추가, 이후 또 다른 신규 환경 배포 등의 과정을 반복하여 인스턴스의 점진적 업데이트(Rolling Update)를 진행하는 과정이다.
배포 시 일부에 문제가 생길 경우, 로드밸런서에 해당 인스턴스를 제거하고 문제점을 수정한 후에 다시 로드밸런서에 추가할 수 있다.
참고. Serverless
분산환경의 Devops를 아예 클라우드 측에서 제공하는 FaaS, BaaS 등 Serverless 프로덕트를 적용하는 것도 하나의 방법이 될 수 있다.
Serverless는 서버가 없다는 것이 아니라, 프로젝트 서버 관리를 위해 트래픽 규모에 따른 Scaled-out, Configs, 보안 등의 설정을 클라우드 측에서 자동적으로 제공하는 Cloud Server, 즉 Server 자체를 하나의 서비스, 인프라로 제공해주는 체계를 의미한다.
기존의 EC2, K8S의 경우 트래픽 규모에 따른 Auto Scaling까지는 가능하였으나, 말 그대로 단순히 기존 인스턴스 환경의 개수를 늘리는 과정이고 Serverless는 인스턴스의 개수가 아닌 운영적 관점에서 트래픽 제어, 리소스, 과금을 클라우드 측에서 조절하는 체계이다.
따라서, 개발자가 프로비저닝 등 서버 환경 구성에는 신경 쓸 부분이 존재하지 않는다.
개발자 입장에서는 서버의 구성이 아닌, 비즈니스 로직을 실행할 코드 조각에만 신경쓰고 이를 FaaS 혹은 BaaS에 붙여주기만 하면 된다(대표적으로 AWS Lambda, Azure Functikons, Google Cloud Functions).
다만, AWS Lambda처럼 최초 함수, 로직 등이 호출될때 애플리케이션을 웜업하고 컨테이너를 띄우는 동작으로 인해 최초 요청의 latency가 수 초가 소요될 수 있다는 Cold start의 단점이 존재하며, 상태 저장의 관점에서는 불리한 점이 많은 선택지일 수 있다(기본적으로 상태저장을 하지 않는다).
따라서 Java보다는 함수 조각을 실행하기 위해 좀 더 가볍고 호출시간이 적은 Go, nodeJs 등을 사용하는 것이 더 바람직하겠다.
더불어, Serverless(FaaS)를 활용하여 Event Driven Serverless, Serverless Orchestration, Serverless Choreography 등 과금을 좀 더 들여서라도 무거운 외부체계와의 연동 및 복잡한 SAGA Pattern보다 좀 더 중앙집중적인 관리와, 유지보수의 효율성을 취할 수 있는 패턴도 하나의 방안이 될 수 있을 것이다.
9. 결론
분산 환경은 단순히 분산 트랜잭션을 의미하는 것이 아니라, 각각의 Polyglot(각기 다른 언어, 프레임워크, 체계 등) 환경으로 이루어진 통합 환경에서 여러가지 요소를 고려하면서, 마치 톱니바퀴가 굴러가듯이 서로가 약속된 상황에서 적절하게 동작하는 환경을 의미한다.
그만큼 복잡하고, 설계가 어렵지만 다르게 보면 다양한 설계패턴과 방안을 접목해가면서 다양한 해를 도출해가는 과정을 느낄 수 있는 환경이 바로 분산환경이다.
설계에는 정답이 없고, 오로지 우선순위와 희생항목이 존재하는 trade-off, 선택과 집중의 연속이다.
각 로컬 트랜잭션은 본인이 바라보는 데이터베이스 및 모델링에 기반하여 적절한 trade off를 선택하고, 분산 환경은 이러한 로컬 트랜잭션과 로컬 환경이 모여 각 약속을 기반으로 이루어진 거대한 시스템이다.
이러한 "Path", 로컬 환경, 각기 다른 로컬 환경이 서로 만나서 이루어진 하나의 분산 환경을 생각하면서, 지금의 과정을 통해 얻은 안목과 설계 접근 방향 등을 충분히 활용하면서 안전하고 가용성이 좋은 환경을 구축하도록 하자.
10. 참고자료
Modular Monolith Hardening - https://dotnetfullstackdev.medium.com/modular-monolith-the-sweet-spot-between-monoliths-and-microservices-c515246f585d
Strangler Fig Migration - https://www.thoughtworks.com/en-us/insights/articles/embracing-strangler-fig-pattern-legacy-modernization-part-one
Bounded Context/Aggregate in DDD - https://www.c-sharpcorner.com/article/an-overview-on-domain-driven-design-ddd/?utm_source=chatgpt.com
CAP - https://www.linkedin.com/pulse/understanding-cap-theorem-sanjeev-singh/
Google SRE 4 Golden Signals - https://sre.google/sre-book/monitoring-distributed-systems/
Sidecar Pattern - https://learn.microsoft.com/en-us/azure/architecture/patterns/sidecar
