백엔드
1.[백엔드] 개발이 이루어지는 공간/요소

개발이 이루어지기 위해선 개발공간과 해당 공간의 내장요소들이 필요하다.공간/요소는 여러 종류와 형태가 있으며, 목적 및 기능에 따라 잘 선택하여 사용할 수 있어야 한다.프레임워크 (Spring(Java) / Django(Python) /Angualrjs(JS))보통 웹
2.[백엔드] 가상화(Virtual Machine / Docker)
물리적인 컴퓨터 자원을 논리적인 객체로 표현하는 기술하나의 하드웨어를 여러 하드웨어가 있는 것처럼 동작하거나, 여러 하드웨어를 하나의 하드웨어처럼 묶어 동작하는 방법이 있다.CPU, memory, server, storage, DB 등 HW자원 및 OS 등의 효율적인
3.[백엔드] binding / bundle 개념
객체와 묶는 과정말 그대로 묶는 과정을 말한다.보통 class나 객체 내부에서 this를 통해 인스턴스를 묶는 과정을 말하고, binding된 this(프론트엔드에서는 props가 될 것)를 통해 해당 객체로 접근할 수 있다.여러 모듈이나 파일을 하나로 묶는 과정bun
4.[백엔드] 오버헤드(overhead)
process A를 제약사항없이 처리하였을 때 소요되는 시간이 있다.이때 비동기처리를 위한 logic 추가나 middleWare 등과 같은 부가적인 요소들로 인해 process A를 처리하는 시간이 늘어날 때 오버헤드가 발생하였다고 한다.즉 쉽게말하면 처리시간의 지연을
5.[백엔드] reverse proxy
뒤에 있는 proxy serverclient가 host server에 직접 접속하는 것이 아닌, proxy server를 통해 network에 접속할 수 있도록 통로를 제공하는 cache의 일종.가상의 server, 실제 server 역할을 대신 해주는 곳이라 생각하면
6.[백엔드] fetch
1-1. 레지스터 관점의 개념 > 명령을 한 레지스터에 옮겨 담는 과정, 혹은 옮기는 것 시스템 구조론, 레지스터 관점에서의 fetch는 명령(operand)을 레지스터에 옮기는 과정을 일컫는다. 1-2. javascript 관점의 개념 > 외부의 REST AP
7.[백엔드] fetch / axios 비교
코드예시를 통해 fetch와 axios의 차이점을 살펴본다.react-native에 적합한 함수.fetch는 url를 인자로 전달받는다.주어진 url의 res를 전달하며, json data형식으로 반환한다.반환(return)하는 res는 body 속성을 지닌다.url
8.[GraphQL/Apollo] Apollo & GraphQL을 활용하여 백엔드 기본 개념 살펴보기
Apollo/GraphQL을 사용하기 전에 왜 GraphQL을 사용해야하고, GraphQL를 실무에서 활용하기 위해 Apollo가 왜 필요한지 그 이유를 알아본다.REST API는 접속할 url에 대해 POST/GET 등의 방식으로 data를 요청한다.REST API는
9.[백엔드] loading 구성이 필요한 이유와 관련 실무 logic
Route, useQuery 등 외부에서 받아오는 data들은 기본적으로 요청, 응답까지 소요되는 시간이 매우 길다.useQuery를 통해 받아오는 data는 GraphQL server로부터 전달받는다.이러한 데이터 처리에 오랜 시간이 소요되는 경우, 별도 장치없이 바
10.[백엔드] 백엔드에서 처리해야하는 logic
실무에서 다음과 같은 경우가 발생한다.특정 시점에서 DB table의 존재 유무를 확인한다.DB table이 존재하지 않는다면, 새로 생성된다. 생성한 table이 존재한다면 특정 column의 value를 update한다.이때 특정 시점에서 DB table의 존재 유
11.[백엔드] API를 만들면서 유의해야하는 점
backend API를 만들면서 기능이 동작한다는 점, frontend에서 보안적인 이유로 진행할 수 없던 logic을 backend에서 보완했다는 점 외에 사실 매우 많은 유의사항이 존재한다.추가적으로 알게되었던 유의사항들 중 하나는, 기능개발을 진행하면서 추후 DB
12.[백엔드] 동기화/동시성 문제(한 작업에 대한 병렬처리) 해결을 위한 개념1 - 프로세스와 스레드

동시성 문제를 해결하기 위해 필요한 개념인 프로세스와 스레드에 대해 공부하고 정리한 내용을 기록한다.프로세스와 스레드는 운영체제에서 작업 효율성을 극대화하기 위한 병렬처리 과정에서 사용하는 개념으로, 이 개념은 웹개발 및 백엔드에서도 활용한다.프로세스 : 운영체제로부터
13.[백엔드] 동기화/동시성 문제(한 작업에 대한 병렬처리) 해결을 위한 개념2 - 싱글 스레드와 멀티 스레드
동시성 문제를 해결하기 위한 개념을 학습하기 위해 싱글 스레드와 멀티 스레드 공부 내용을 기록한다.프로세스를 하나의 스레드로만 작업하는 과정을 의미하며, Java의 경우 메인메서드를 실행하였을때 메인스레드를 생성한다.별도의 스레드 요청 작업이 없다면 메인스레드라는 싱글
14.[백엔드] 동기화/동시성 문제(한 작업에 대한 병렬처리) 해결을 위한 개념3 - 접근 및 구현방안
스레드를 구현할 수 있는 대표적인 3가지 방안에 대해 공부한 내용을 기록한다.Thread 추상클래스를 상속받아 사용한다.Runnable 인터페이스를 구현하여 사용한다.(\* 이때 Runnable 객체를 Thread의 인자로 전달하여 스레드를 구현할 수 있다.)람다식을
15.[백엔드] 동기화/동시성 문제(한 작업에 대한 병렬처리) 해결을 위한 개념4 - 스레드를 관리하기 위한 기본 개념(데몬스레드, 스레드그룹 등)
기본적으로 스레드를 활용하고 관리하기 위해 필요한 개념들을 공부하여 정리한 글이다.데몬스레드는 우선순위가 낮아 보이지 않는 곳에서 실행되는 스레드를 의미하는데, 1차적으로 메인스레드 실행 완료 후 필요 시 데몬스레드가 실행된다.JVM 및 애플리케이션 종료는 메인스레드의
16.[백엔드] 동기화/동시성 문제(한 작업에 대한 병렬처리) 해결을 위한 개념5 - 스레드를 관리하기 위한 기본 개념(스레드 상태관리, 동기화)
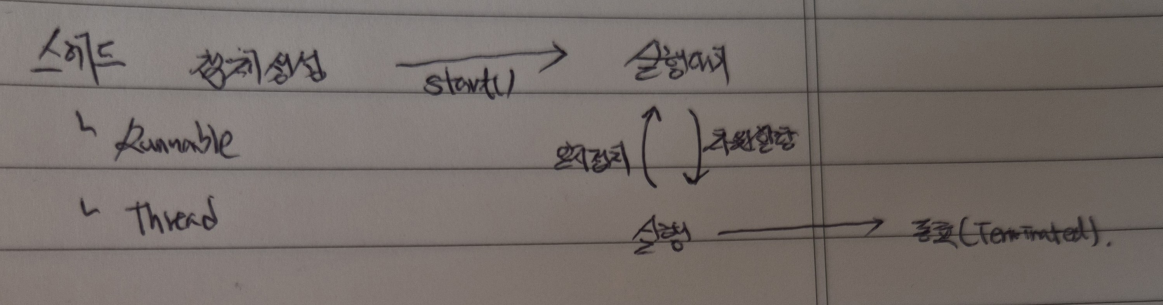
스레드 상태를 직접적으로 관리할 수 있는 메소드를 공부한 내용을 기록한다.스레드는 실행대기 - 실행 - 종료의 생명주기를 가진다.스레드의 실행대기는 start() 메서드를 통해 이루어진다.그 후 자원을 할당받아 정의한 작업 내용대로 처리하며, 이는 run() 메서드를
17.[백엔드] myBatis 설정 유의사항
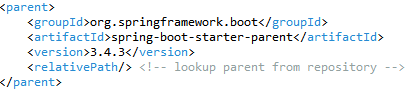
myBatis mapper 사용 시 bean 오류가 매번 발생하여 고생을 좀 하였는데, 이번에 오류해결을 하면서 했던 설정 방법을 남기고자 작성한다.spring boot 버전에 맞는 myBatis spring boot starter maven dependency를 설치
18.[백엔드] 찬찬히 살펴보는 Docker - Local/Docker hub의 상호작용
지금까지 Docker 개념이 자리잡지 못한 채로 개발을 진행하다보니 헷갈리는 부분도 많고, 어떠한 필요에 의해 Docker를 사용하는지 정확히 인지한지 못한 채 흐르는 파도에 몸을 맡긴 상황인 것처럼 개발자답지 못한 개발을 진행하였다.개인 프로젝트 겸 학습을 진행하면서
19.[백엔드] 찬찬히 살펴보는 Docker - Docker Run ~ Docker Stop
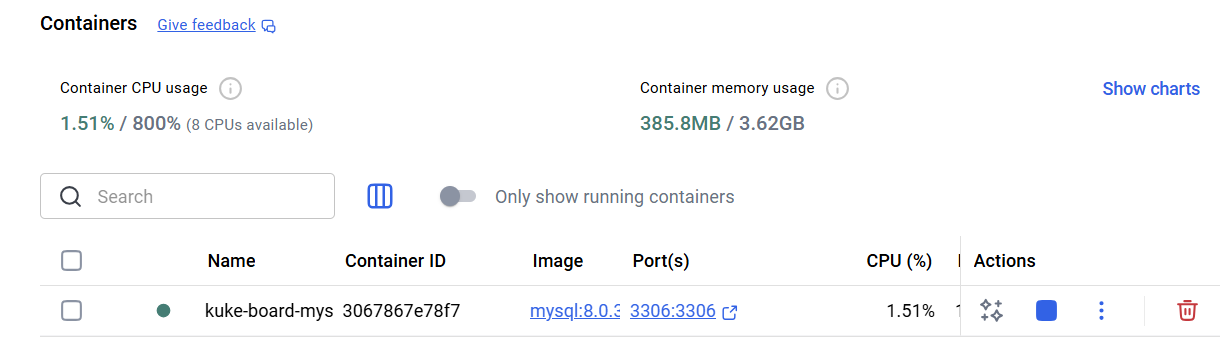
일전에 작성한 Docker 작동원리 및 과정을 토대로 Docker를 실행하는 과정에 대해 이해한 내용을 정리해본다.Docker Run, 도커를 실행하는 과정은 정확하게 말하면 "특정 환경을 구성할 이미지파일을 컨테이너로 실행한다"라는 의미와 동일하다.Docker Des
20.[백엔드] 인덱스가 조회성능향상에 무조건 도움이 되는가 - 조회성능향상을 위해 고려해야할 점들(단순 인덱스 활용부터 Covering Index 등의 전략까지)
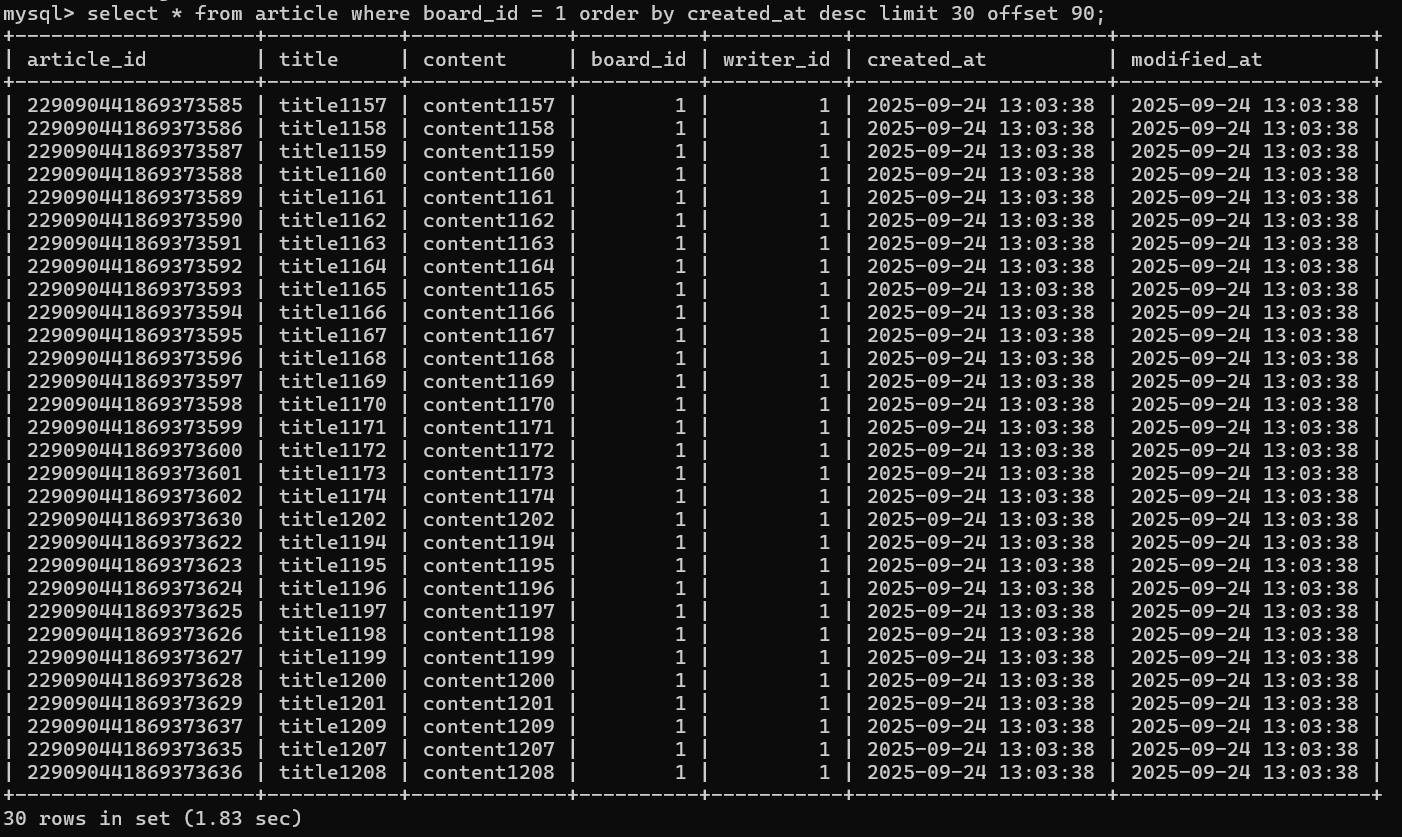
개인 프로젝트를 진행하면서 인덱스를 좀 더 깊게 살펴보는 기회가 생겨 공부해보았다.단순히 정렬된 데이터를 저장하는 공간인가? 필요한 데이터를 추출하기 위한 데이터 저장공간에 이미 데이터가 정렬이 되어있기 때문에 조회 성능이 향상하는가? 인덱스를 사용하여 조회성능이 향상
21.[백엔드] 조회성능향상을 위한 추가 방안(대용량 데이터와 같은 근본적인 한계 상황에서 페이징 처리를 하는 이유를 중심으로)
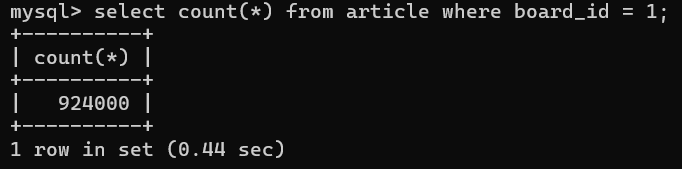
일전의 인덱스를 통한 조회성능향상에 이어, "근본적으로 데이터가 너무 많아 조회성능을 향상하고 싶은 상황"에 대해 공부한 내용을 기록하고자 한다.데이터가 많아진다면, 아무리 인덱스를 잘 구성하고 쿼리를 잘 사용하여 Covering index를 활용한다고 한들 물리적인
22.[백엔드] PK채번을 위한 다양한 방안들
지금까지 생각없이 UUID/Time Stamp/Auto Increment 등 단일DB에서 유일성을 보장하기 위한 채번방안만을 고려하였는데, 이를 넘어 분산DB 환경 및 인덱스 환경까지 고려한 적절한 채번방안을 마련해야 한다는 것을 깨닫게 되었다.이에 대해 공부하면서 정
23.[백엔드] 계층형 데이터를 DBMS차원에서 손쉽게 관리할 수 있는 방안(불필요한 조회비용 감소) - 계층구조의 문자열화 및 MySQL Collation을 중심으로
지금까지 데이터 관리를 할때 계층 구조가 존재할 경우(MIS/Back Office) 단순히 ID/PARENT_ID 두가지 항목만을 관리하였다.두 항목만을 관리항목으로 고려하였기에, 데이터를 표현할때는 CONNECT BY와 LEVEL을 활용하였고, 이러한 데이터 구조와
24.[백엔드] MSA 및 분산DB 환경에서 트랜잭션의 성능을 보완할 수 있는 방안(동시성 문제를 테이블 비정규화 등의 데이터 모델링의 방향으로 접근하면서)
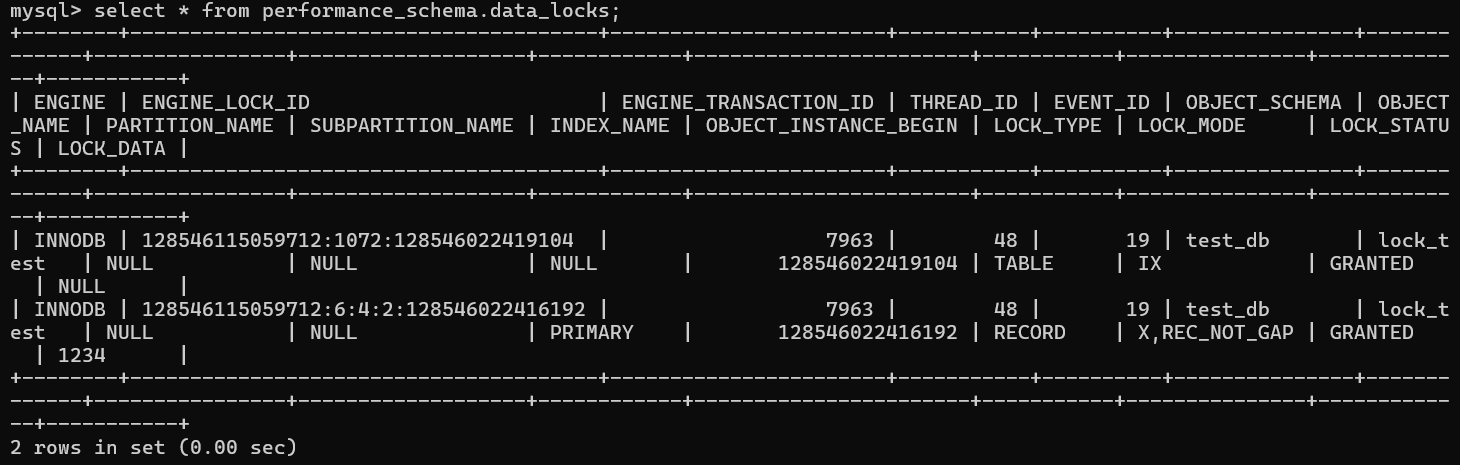
금번의 개인 프로젝트는 각 서비스마다 별도의 Database를 두는 MSA 환경으로 진행하고 있는데, 그러다보니 일전에는 단순하게 생각했던 부분들이 지금의 환경에서는 좀 더 깊게 생각해볼 문제라는 것을 알게되었다.이번에 게시글(Article), 좋아요(like) 기능을
25.[백엔드] 고가용성과 확장성을 고려한 조회수 처리 구현 방안(파생요소가 아닌 정규화된 데이터이지만 트래픽 등 기능적/환경적 제약으로 인해 RDB가 아닌 Redis를 활용하기까지의 설계 과정)
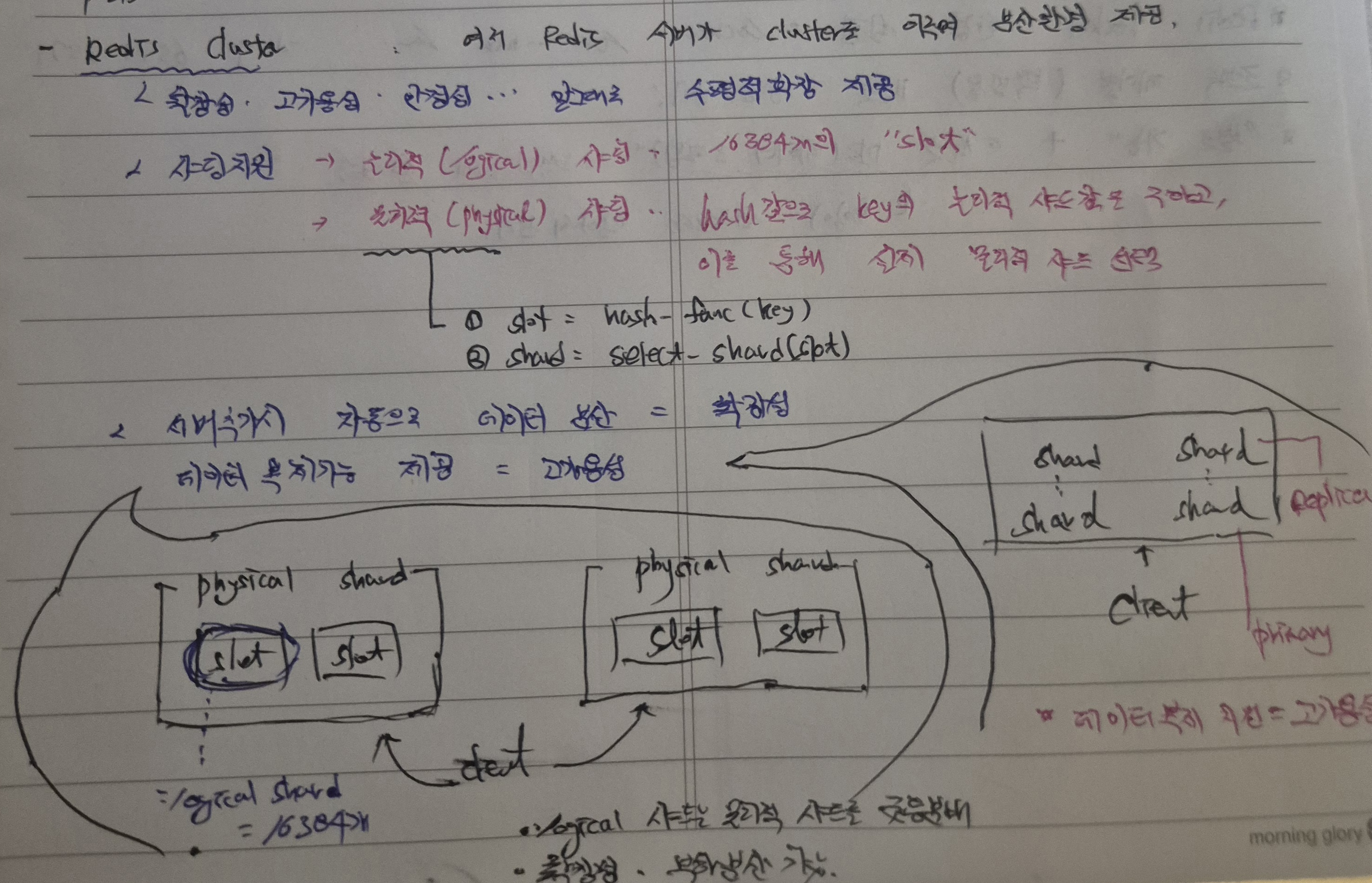
개인 프로젝트를 진행하면서 "조회수"라는 비교적 간단한 기능을 구현할때 기능적/환경적 요인을 고려할때 꽤 흥미있는 장치를 결합할 수 있지 않을까라는 생각을 하게 되었다.일전의 게시글 및 게시글 좋아요 수와 달리, 조회수는 데이터의 실시간 처리가 즉각적으로 이루어지지 않
26.[백엔드] Kafka 완전정복 - 데이터 순차처리 보장 및 안전한 관리를 위한 가장 보편적인 방안/내부적인 구조와 동작원리를 깊게 파악하며(중요도 ★★★★★★★★★★)
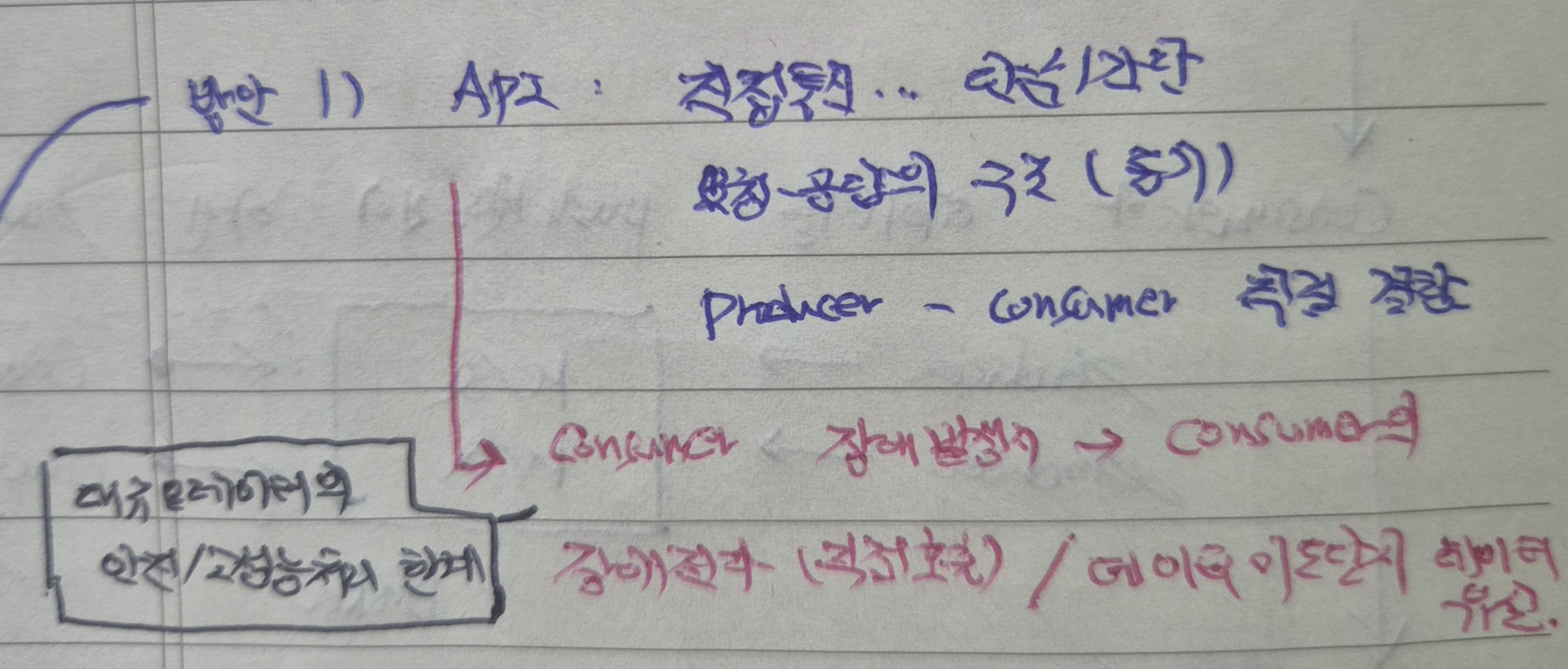
대용량 트래픽이 발생할 수 있는 상황에서 순차처리와 안정성 등의 고가용성을 보장하기 위한 도구로 Kafka를 많이 사용한다.일전에 Kafka에 대해 한번 정리한 적이 있긴한데, 이번에 다시 한번 살펴보면서 잘못 알고 있었던 내용들을 바로 잡고, 이에 따라 Kafka에
27.[백엔드] 분산 트랜잭션의 원자성과 분산 환경의 데이터 일관성을 보장하기 위한 Producer 전략 구상하기

지금까지 구성한 Event 도메인 객체나 EventListener 등은 Message를 Broker로부터 전달받아 이를 처리하는 Consumer에 대한 내용들이었다.이제 Producer를 어떻게 구성할 것인지 그 전략에 대해 구상해볼 차례이다.Producer 역시 마찬
28.[백엔드] Client의 기능소비 및 트래픽 불균형 상황에서 프로젝트의 관리효율 및 확장성을 개선할 수 있는 방안(CQRS Pattern을 도입하는 이유와 기대효과를 살펴보면서)
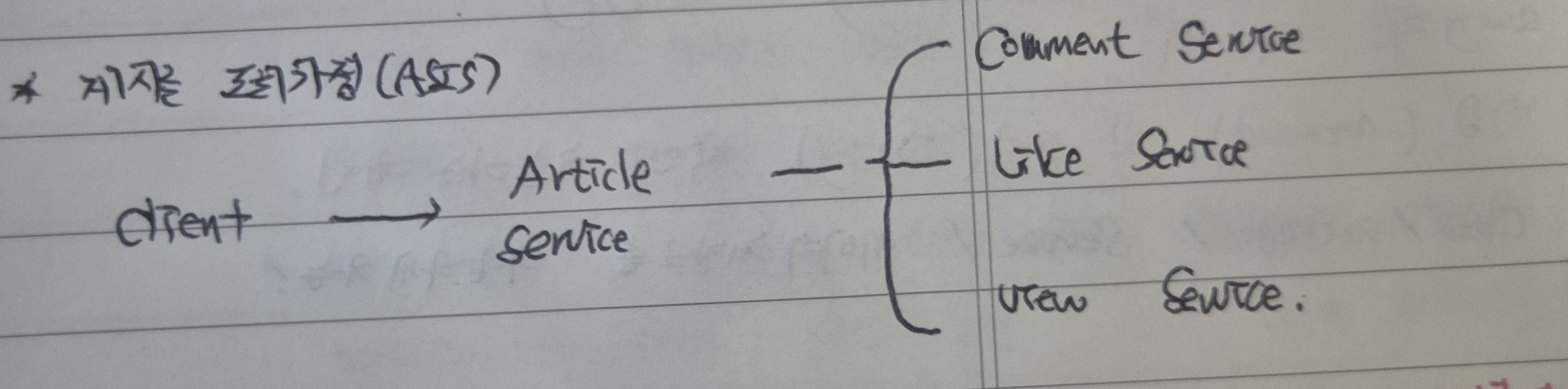
1. 개요 게시글 작성/댓글/인기글/좋아요/조회 등 각각 도메인에 대해 독립적인 데이터베이스와 서비스를 구성한 MicroService Architecture의 기본적인 골격을 드디어 완성하였다.
29.[백엔드] gradle init(cli) 및 Spring Initializer curl 등을 통한 구성 시 필요한 부가적인 프로젝트 구성 관련 개발지식

이번에 Spring Framework와 Spring Boot 프로젝트를 모두 직접 구성하고 두 프로젝트의 구현과정을 비교하는 작업을 하였는데, 구현 이전에 프로젝트 구성을 할 때부터 곤란한 상황들을 많이 직면하였다.그런데 단순히 기존 프로젝트 구성 과정에서 누락한 부분
30.[백엔드] Web Application의 상호보완적 Eventually Consistency #8 - Batch의 영속화 - Batch Database 구성 과정 및 시행착오에 대한 기록
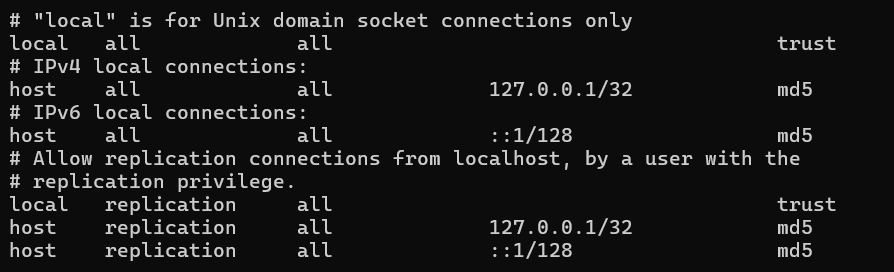
나중에 DB를 이용한 배치 영속성 관리 과정 분석할 때 build.gradle부터 최초 H2(기본설정) / 이후 DB를 이용한 영속성 관리(PostgreSql)에 대해 기록할때 아래 내용을 포함하여 작성할 것.임시저장 or 영구저장은 설정에 따라 달라진다.Spring
31.[백엔드] Oracle, Mysql, Postgresql 별 record 관리방안 및 MVCC level, 이로 인해 발생하는 동시성 문제에 대한 분석(중요도 ★★★★★★★★★)
1. 개요 Database를 선택하는 기준은 오픈소스 기반의 확장성 및 유연성, 안전성, framework 간의 연계성, 비용, Storage Engine, 트랜잭션 기능 지원 등 여러가지 요소가 존재한다. 이 외에도 주요 고려요소 중 하나는 MVCC, 동시성 제어에
32.[백엔드] 단순 가독성 향상을 넘어선 Clean Architecturing의 요소 - Patterns
Spring batch의 itemReader/itemWriter의 itemStream 구현형태, 목적에 대해 분석하면서 template method, factory 패턴이 많은 부분에 적용되어있음을 확인할 수 있었다.일전에 전략패턴과 팩토리패턴을 자동화 체계 구축에 활
33.[백엔드] Redis가 빠른 이유, 인메모리는 필요조건이 아닌 충분조건이다.
1. 개요 DP(Dynamic Programming)의 기본적인 접근 방향은 특정 조건의 상황을 이전 단계에서 만족하였고, 그 만족한 경우에 대해 현재 단계에서 누적하는 것이다. 즉, 조건에 부합하기 위해 정방향으로 접근하는 것이 아니라, 이전 단계에서 해당 조건에
34.[백엔드] Database #1 - 정보를 "표현"하는 방법을 고민하다 - 데이터 모델링(본질편)

1. 개요 3년 동안의 여러 실무 상황, 요구사항에 맞춘 개발을 하면서 느낀 점 중 하나는 설계의 중요성이다. 사실 지금까지의 개발을 진행하면서 아쉬웠던 점은 Application 설계(흔히 말하는 시스템 구축), Database 설계를 동일선상에 두면서 생각을 하
35.[백엔드] Database #2 - 인덱스에 대하여(인덱스가 성능적으로 유리한 이유와 데이터베이스 별 인덱스의 물리적 구조/동작방식에 대한 고찰)(*MySQL/PostgreSQL/Oracle)

데이터 모델링을 할 때 빼놓을 수 없는 개념인 인덱스에 대한 개념을 보완해가면서, 각 데이터베이스 별로 물리적인 인덱스 구조 및 동작방식이 다르다는 것을 알 수 있었다.사실 인덱스에 대해 검색해보면 대부분 거의 내용이 비슷하고, Clustered Index나 Secon
36.[백엔드] Database #3 - 정보를 "표현"하는 방법을 고민하다 - 시스템 모델링 1(본질편 확장 : 데이터베이스 설계의 모든 것)
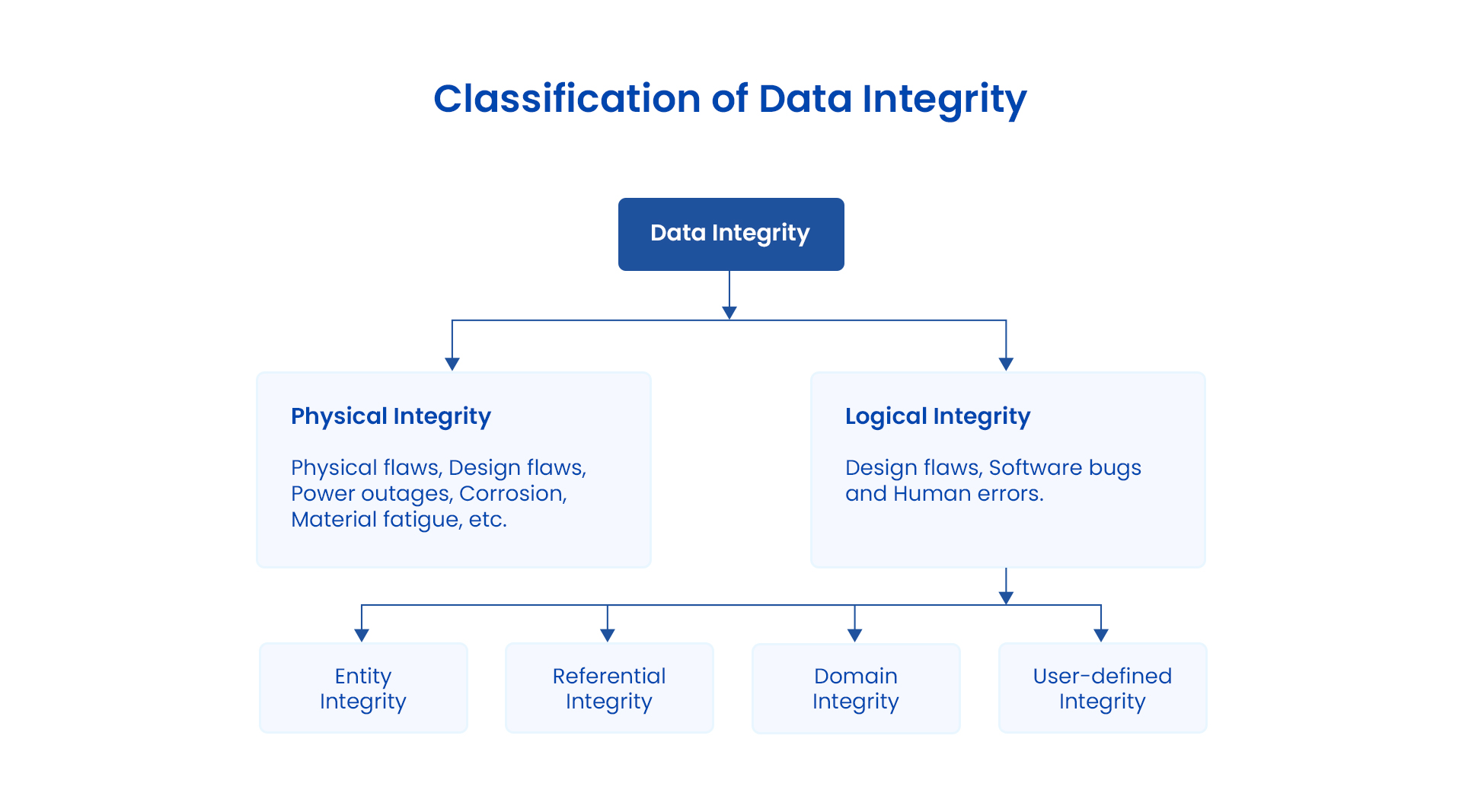
데이터 모델링의 본론을 통해 데이터를 어떻게 표현하고 관리할 것인지, 그 근간과 기본 원리에 대해 살펴보고 분석해보는 과정을 해보았다.사실 본론에서 분석한 내용은 DB설계, 데이터모델링을 이해하기 위한 초석이다.근간을 살펴보았다면, 이번 단계에서는 그 근간을 어떻게 적
37.[백엔드] Database #4 - 시스템 모델링 2(유연성과 확장성을 보장하기 위한 데이터베이스 세부 설계 방안 - Patterns 1)
앞서 시스템 모델링의 근간인 데이터베이스 모델링에 대해 심도 있게, 찬찬히 분석해보았다.일전에 분석한 내용은 실무에서 가장 기초가 되는, 관리/운용 면에서 최소한으로 보장/전제되어야 하는 항목들로, 데이터베이스를 도메인 별로 분리하면서 병목이 발생할 경우 적절한 비정규
38.[백엔드] Road to MSA #1 - Spring Cloud Framework를 활용한 분산 시스템 구축 방안 End to End(소규모, 제한적 환경에서 K8S 적용 불가 시 차선책)
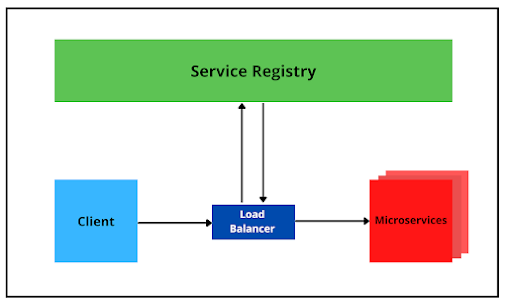
여러 프로젝트를 직접 구축해보기도 하고, 실무에서 다양한 환경, 다양한 사람들을 접하면서 시스템을 구성해보기도 하고, 여러 경험을 하면서 느낀점 중 하나는 제대로 이해하지 못한 채 진행하는 개발은 후의 관리비용을 더 비대하게 만들 뿐이라는 것이다.마치 초기 설계가 잘못
39.[백엔드] Road to MSA #2 - 분산 환경에서의 분산 트랜잭션(Choreography 기반의 SAGA pattern) 및 Kafka/CDC pipeline을 활용한 데이터 동기화 구성 방안
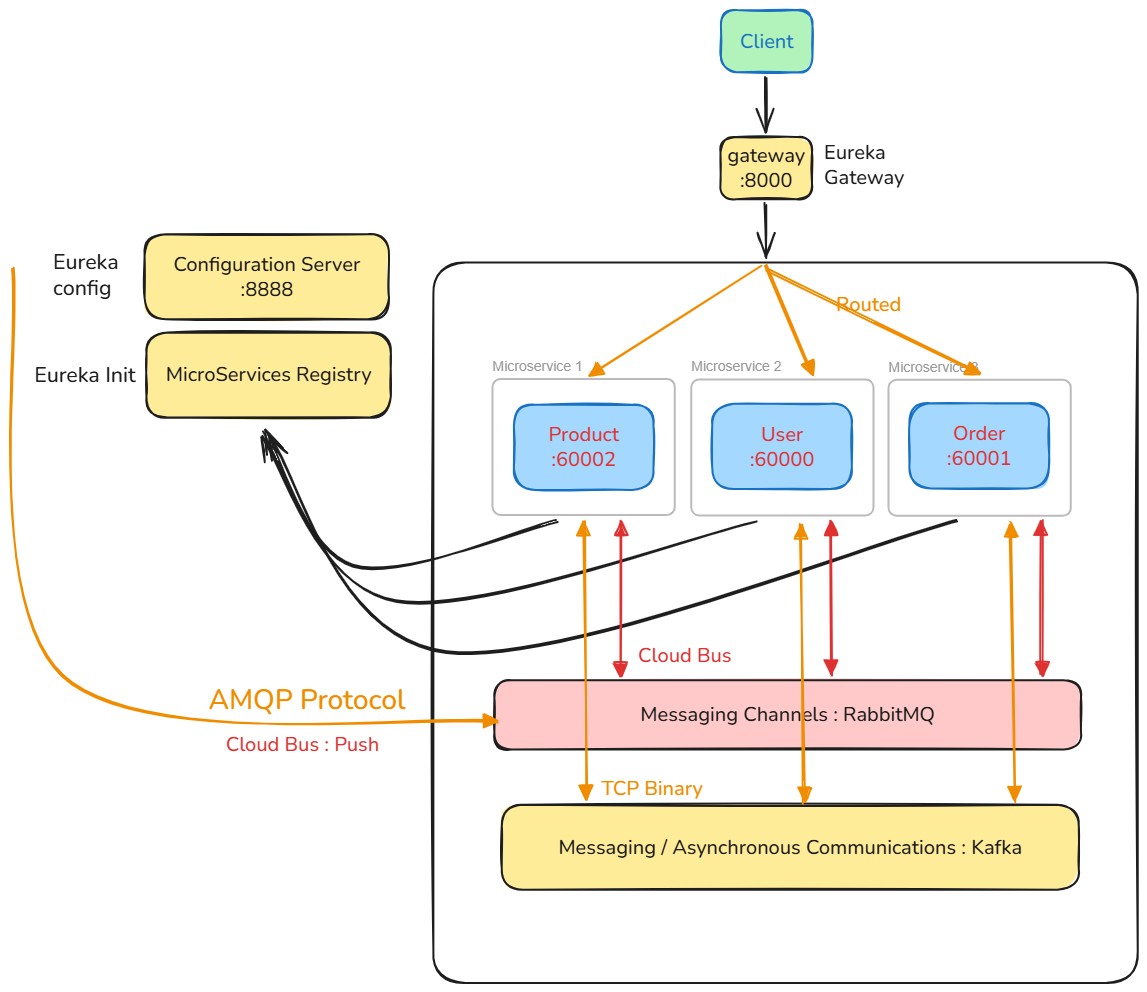
독립적으로 분리된 각 마이크로서비스들은 말 그대로, 서로 의사소통을 할 수 없는 분산되어있는 환경이다. 하지만 분산된 각 도메인 서버에서 다른 도메인 서버의 서비스를 활용해야 하는 경우가 존재한다.예를 들어,사용자 도메인에서 특정 사용자가 주문한 주문 내역을 살펴보고자
40.[백엔드] Database #5 - 시스템 모델링 2(유연성과 확장성을 보장하기 위한 데이터베이스 세부 설계 방안 - Patterns 2)
이 글은 Database #4 - 시스템 모델링 2(유연성과 확장성을 보장하기 위한 데이터베이스 세부 설계 방안 - Patterns 1) 에서 이어지는 내용이다. 5. SOFT DELETE 실무에서 필수적으로 고민해야 하는 중요한 협의사항 중 하나는 삭제에 대한 내용
41.[백엔드] Road To MSA #3 - 분산 트랜잭션 Trouble Shooting(*Circuit Breaker/fallback) 및 MSA 서버 별 분산추적(모니터링) 환경 구성 방안(*Cardinality Explosion)
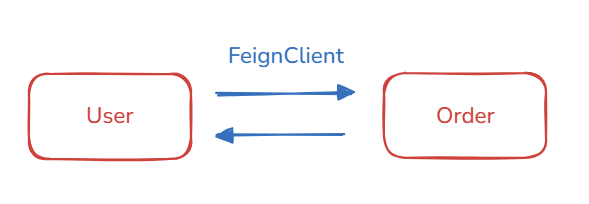
본 내용은 Road to MSA #2 - 분산 환경에서의 분산 트랜잭션(Choreography 기반의 SAGA pattern) 및 Kafka/CDC pipeline을 활용한 데이터 동기화 구성 방안 에서 이어지는 내용이다. 4. 분산환경 Trouble Shooting
42.[백엔드] Road To MSA #4 - CI/CD pipeline 구축 방안
Cloud Native 환경은, 말 그대로 Cloud 서버에 프로젝트를 배포하고, 이를 운용 및 관리하기 위한 목적으로 설계된 환경을 일컫는다.기존 Monolithic 프로젝트의 전체 프로젝트의 변경점 발생 및 전면 재배포의 비효율적인 동작을, 각기 다른 도메인과 인스
43.[백엔드] Redis에 대한 고찰(*Redis에서 발생가능한 다양한 실무적 상황과 이에 대한 Trouble Shootings) #1 - Redis 자료구조와 데이터 영속화
1. 개요 일전에 Redis의 인메모리는 필요조건이 아닌 충분조건이다 라는 제목으로 Redis의 내부 원리, Redis가 빠른 이유는 단순 인메모리(RAM)의 1~100 ms 단위의 I/O응답시간이 아닌 그러한 응답시간이 가능하도록 설계된 사상에 의한 점인것에 대해
44.[백엔드] Redis에 대한 고찰(*Redis에서 발생가능한 다양한 실무적 상황과 이에 대한 Trouble Shootings) #2 - Redis의 Model과 실무 적용을 위한 Patterns
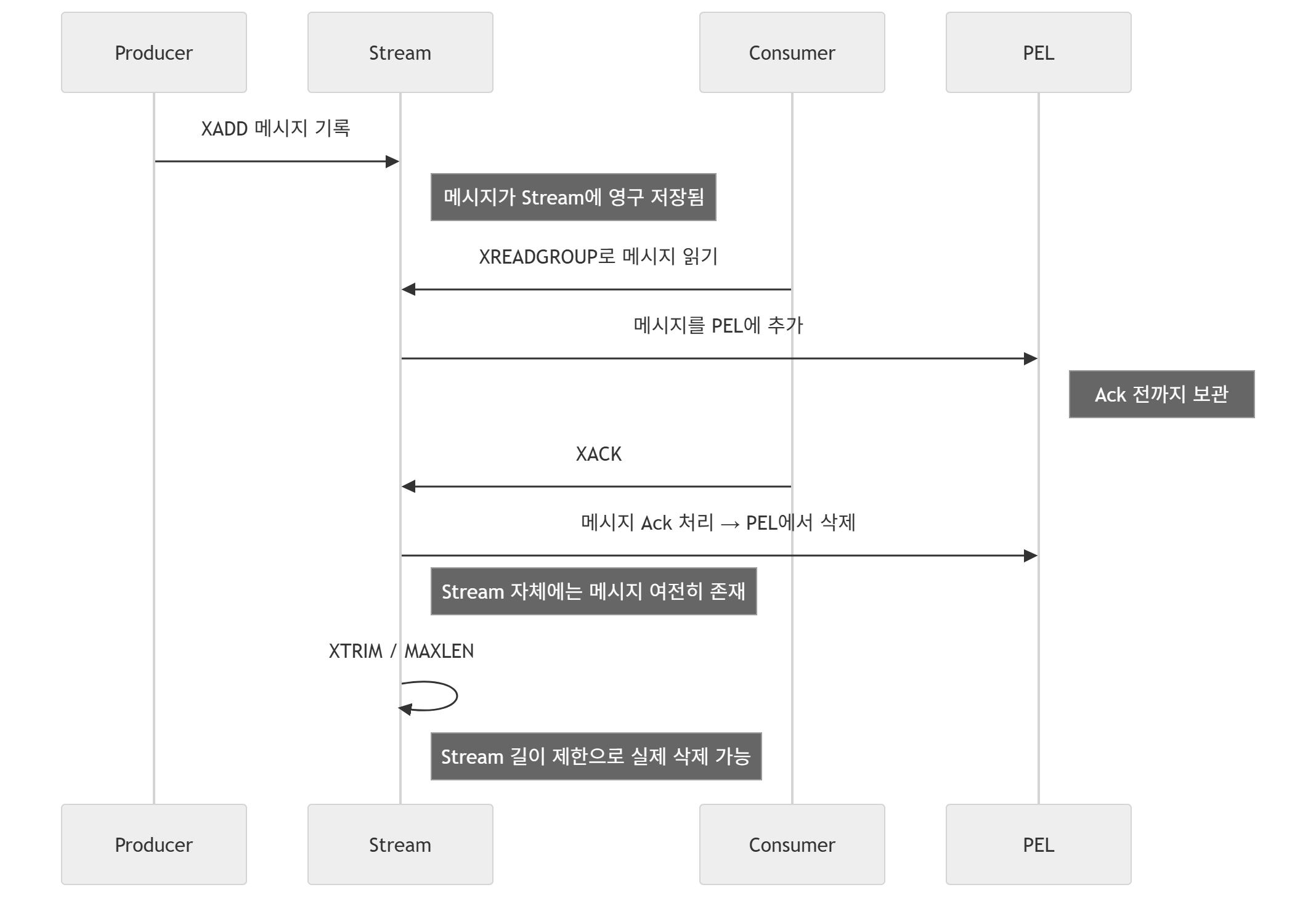
이 글은 Redis에 대한 고찰 - Redis 자료구조 및 데이터 영속화 에 이어지는 내용으로, Redis의 Pub/Sub 모델 및 이를 실무적으로 어떻게 활용할 수 있을지 이론적으로 분석하고 고민한 내용에 대해 기술하고자 한다. Redis의 인메모리 기반 동작 및
45.[백엔드] Road To MSA #6 - Distributed Environment에 대한 고찰(*실무에서 분산환경을 구축하기 위한 설계적 관점)
1. 개요 지금까지 MSA 환경을 구축하고, 이 환경을 구축함으로 인해 대규모 트래픽을 처리할때 어떠한 점에서 유리한지 체득하는 관점에서 많은 시행착오를 겪어왔다. 하지만, 이러한 구현도 중요하지만 그에 못지 않게 이 구조가 왜 필요하고, 이 선택의 비용은 어떻게 되는지에 대해 한번 고민해보는 것도 필요하기에, 분산환경이라는 기본적 내용에 대해 분석해보...
46.[백엔드] Road To MSA #7 - 분산 환경 트랜잭션에 대한 고찰(*분산 트랜잭션을 구성하기 위한 설계적 관점)
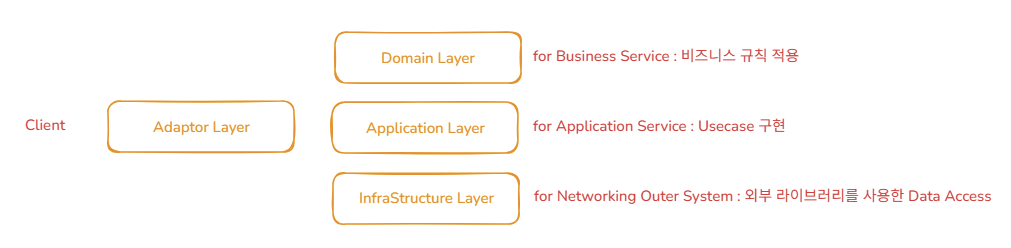
분산 환경(MSA) 구조에 대해 분석하는 것과 더불어, 이번에는 분산 환경에서 트랜잭션의 일관성을 확보하고, 데이터의 정합성을 확보하기 위한 분산 트랜잭션 구성 방안에 대해 구현 그 자체보다는, 구현하기 위해 어떠한 점을 고려해야하며, 어떠한 부분을 후순위로 희생해야
47.[백엔드] Database #6 - 시스템 모델링 3(유연성과 확장성을 보장하기 위한 데이터베이스 세부 설계 방안 - 분산 환경에서의 데이터 모델링)

대규모 트래픽을 하나의 단일 인스턴스가 아닌 도메인별 인스턴스로 분리하여 시스템을 구축하였다면, 각 독립적인 인스턴스 간의 상호작용 및 데이터 일관성 등 뿐만 아니라 도메인에 집중되는 트래픽에 대비하여 분산 데이터 모델링, 즉 샤딩에 대해서도 고민해보아야 하겠다.샤딩은
48.[백엔드] 시스템과 가장 쉽고 강력하게 상호작용 할 수 있는 방법 - Logging에 대하여(System Interaction의 관점에서)
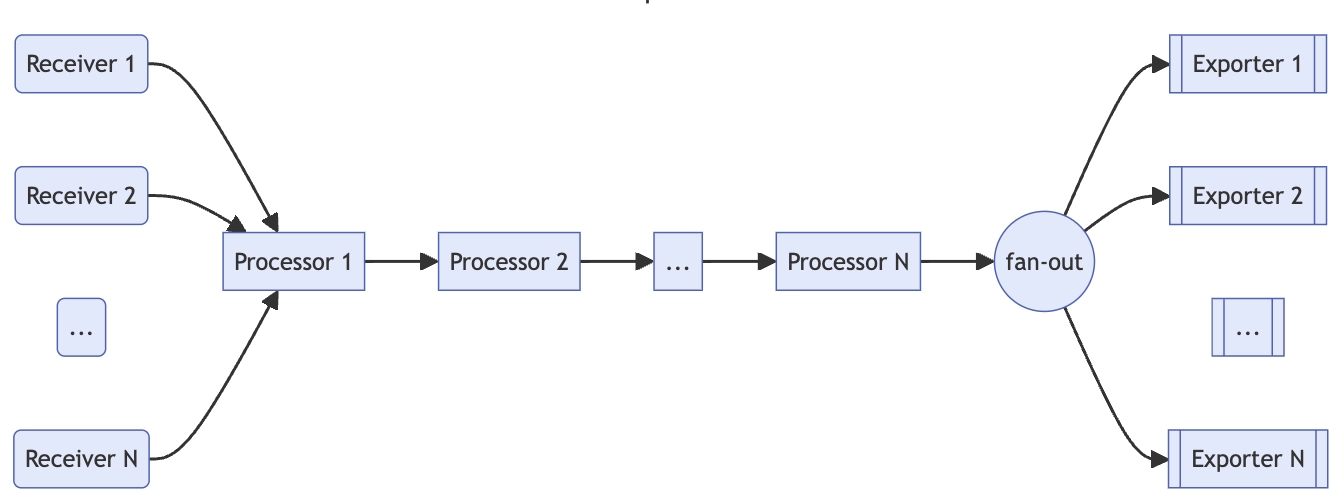
지금까지 Devops, Docker, MSA 등 여러 프로젝트를 진행하면서 느낀점은 내가 과연 로그 활용을 잘 하고 있다고 단언할 수 있을까하는 생각이었다.아무 생각없이 도커 컨테이너의 docker log를 확인하거나, 디버깅을 하거나, 디버깅을 할때도 slf4j를 이
49.[백엔드] Redis에 대한 고찰(*Redis에서 발생가능한 다양한 실무적 상황과 이에 대한 Trouble Shootings) #3 - TDD기반의 Redis Patterns & trouble Shootings 1
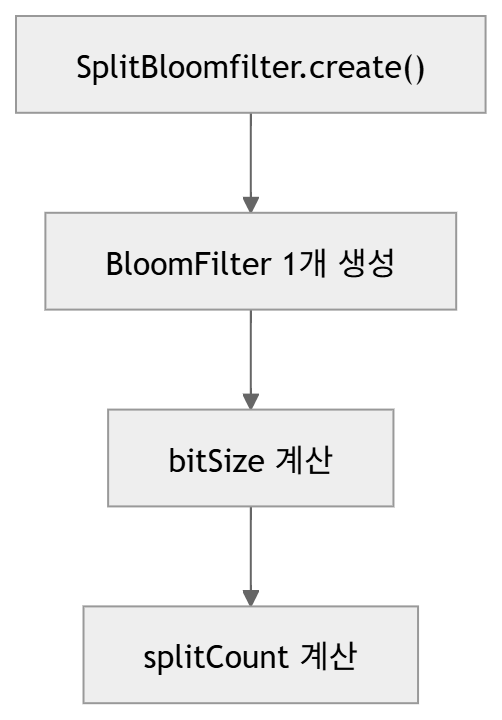
1. 개요 일전에 Redis에서 적용 가능한 다양한 설계 전략에 대해 살펴보았는데, 이러한 설계 전략을 적용하였을때 구체적으로
50.[백엔드] Road To MSA #5 - Kafka Patterns - 분산 시스템의 메시징 처리 실패 상황에 대한 Trouble Shootings 1(DLT/Retry)
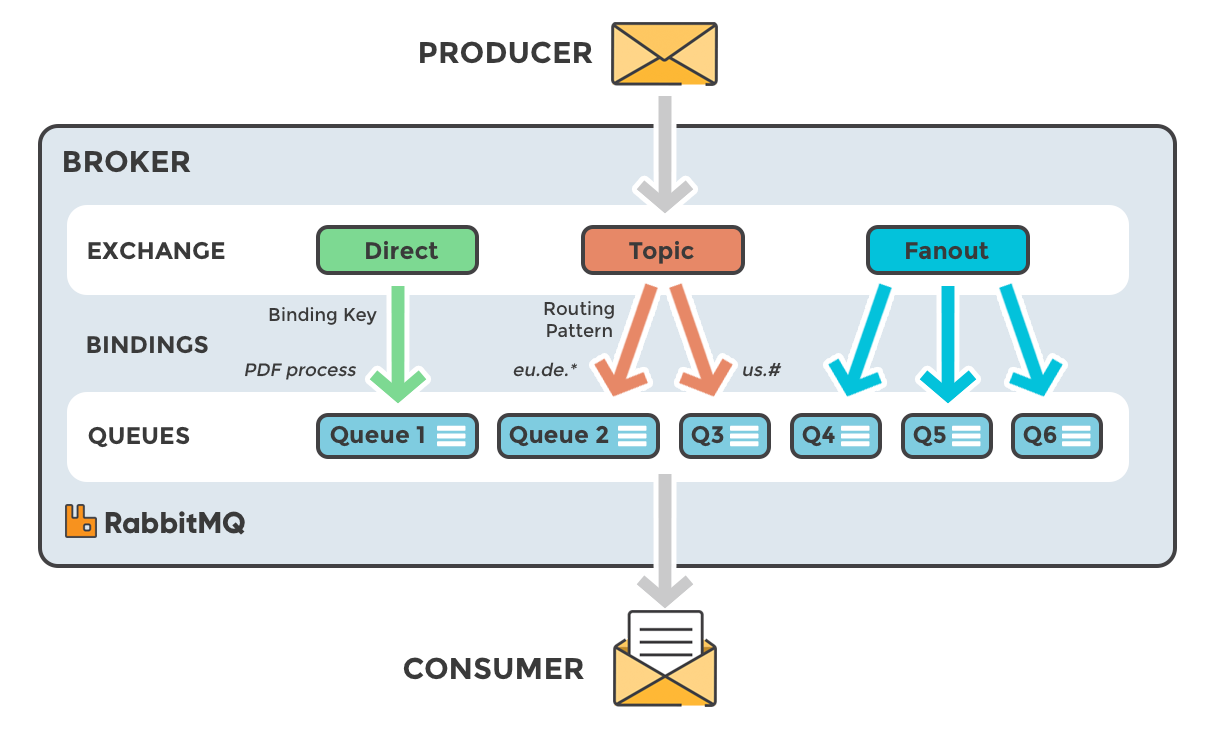
분산 시스템에서 시스템 규모가 커질수록 단순히 메시지를 보내고 처리하는 것보다, 그 이상의 특화된 능력, topic 및 partition에 기반하여 메시지를 관리하고, 처리할 수 있는 Kafka의 중요성은 그만큼 커질 수 밖에 없다.가령, RabbitMQ의 경우 메시지
51.[백엔드] Redis에 대한 고찰(*Redis에서 발생가능한 다양한 실무적 상황과 이에 대한 Trouble Shootings) #4 - TDD기반의 Redis Patterns & trouble Shootings 2
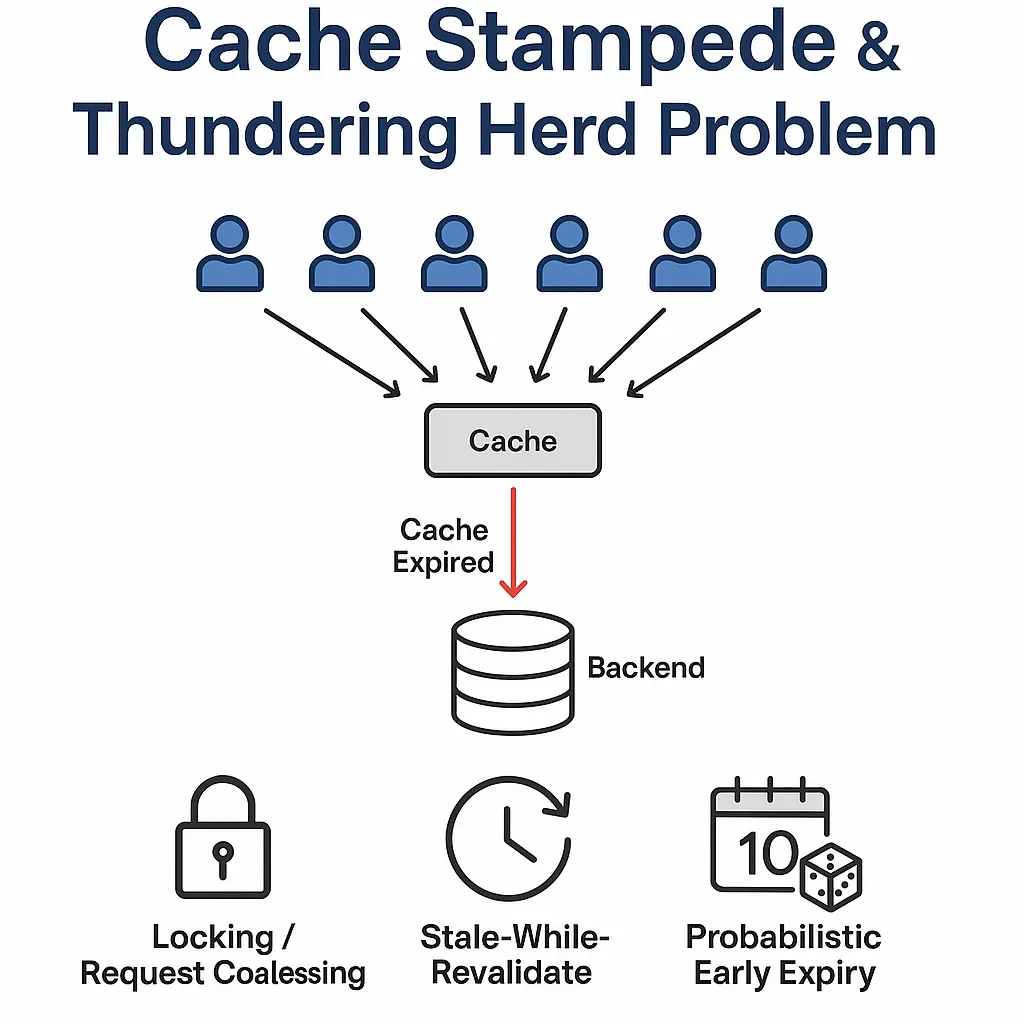
이 글은 일전에 작성하였던 Redis Trouble Shootings 1편 - Cache Penetration 에서 이어지는 내용으로, 실무에서 접할 수 있는 Redis 설계 문제 중 Cache Stampede에 대해 다루고자 한다.Application에서 Redis와
52.[백엔드] Road To MSA #6 - Kafka Patterns - 분산 시스템의 메시징 처리 실패 상황에 대한 Trouble Shootings(Outbox) 및 멱등성 보장 전략(*설계 전략 별 trade offs)
이 글은 \[Road To MSA 위와 같이 Consumer 측에서 메시지를 처리하지 못하여 재시도를 하거나, DLT Topic에 별도로 보관하여 이를 처리하는 방안은 일시적인 오류에 대해 임시로 재시도하거나, 이후 실패 시 payload에 따라 별도 처리하는 방법을