[백엔드] Web Application의 상호보완적 Eventually Consistency #8 - Batch의 영속화 - Batch Database 구성 과정 및 시행착오에 대한 기록
백엔드
1. 개요
Spring Batch는 job Repository를 통해 job/step/tasklet의 세부적인 상태정보 및 진행내역 등을 메타데이터화 하며, 이를 최종적으로 데이터베이스에 저장한다.
만약 연결된 데이터베이스가 따로 없다면 자체적으로 H2 DB에 저장해야 하며, 그렇기에 H2 등 데이터베이스의 연결이 없거나, 연결이 되어있어도 Spring Batch의 job repositroy와 연동이 불가능한 스키마 등이 없다면 DB 오류가 발생한다.
이만큼 Spring Batch와 Database는 필수불가결한 관계이다.
지금까지의 Spring Batch는 기본적인 h2 의존성을 추가하여, 자체적인 h2 db를 이용하는 과정이었다면, 이제부터는 RDBMS를 활용하여 관리하는 과정에 대해 분석해보고자 한다.
그 시작으로 RDBMS(PostgreSql)을 구성하는 작업과, 이에 대해 시행착오를 겪었던 수많은 경험들을 기록하고자 한다.
2. ASIS - H2 DB
postgreSql을 연동하기 전에, 기존의 H2 Database를 사용하였던 과정에 대해 의존성 부분부터 이해해보고자 한다.
이러한 이해를 바탕으로 TOBE - PostgreSql DB를 연동하는 과정까지 연장해보고자 한다.
먼저 최초 기본 설정은 아래와 같으며, gradle을 빌드하기 위해 어떠한 정보들을 넣어야 하는지 살펴보도록 하자.
allprojects {
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
repositories {
mavenCentral()
}
apply plugin: 'java'
apply plugin: 'org.springframework.boot'
apply plugin: 'io.spring.dependency-management'
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-json'
implementation 'org.springframework.boot:spring-boot-starter-batch'
runtimeOnly 'com.h2database:h2'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
testCompileOnly 'org.projectlombok:lombok'
testAnnotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'org.springframework.batch:spring-batch-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
tasks.named('test') {
useJUnitPlatform()
}
}여기서 주목해야 할 점은
implementation 'org.springframework.boot:spring-boot-starter-batch'
runtimeOnly 'com.h2database:h2'이다.
이에 대한 의미는 아래와 같다.
batch 의존성을 설정한다.
더불어 컴파일 시점에는 h2 내장모듈을 필요로 하진 않지만, 실제 실행 시 h2와 연동될 수 있도록 드라이버 등의 모듈을 runtime시점에 사용한다.
더 자세히 살펴보자.
2-1. H2를 사용한다면 데이터를 어떻게 저장하는가?
TOBE저장소인 RDBMS(PostgreSql)을 사용한다면 응당 데이터를 영구적으로 저장할 것이다.
그러나 H2를 사용한다면, 임시저장 or 영구저장은 설정에 따라 달라지긴 하지만 본질적으로는 임시적인 저장으로 바라보는 것이 좋겠다.
Spring Batch를 외부 DB 설정 없이 실행했다면 기본적으로 H2 Database(인메모리 or 파일모드) 를 사용하는데, 여기서 핵심은 H2가 인메모리로 동작했는가? 파일 DB로 동작했는가?에 따라 데이터를 어떻게 저장하느냐, 그 방법이 달라진다.
2-2. 환경설정에 따른 데이터 저장 과정
각 인메모리, 파일모드에 대한 데이터 저장과정을 분석해보록 하자.
- H2 DB는 애플리케이션 종료 후에도 내용을 유지하는가?
1) 인메모리(In-memory) H2 (jdbc:h2:mem:...)
말 그대로 메모리에 임시적으로 저장하며, 애플리케이션 종료 시 혹은 젠킨스와 같은 JVM 동작이 종료된다면, 메모리에 남겨진 모든 데이터는 사라진다. 참고로 배치 자체적인 종료는 DB를 유지한다.
규모가 크지 않는 환경에서는 애플리케이션과 batch를 보통 동일한 환경에서 실행하기에, 애플리케이션을 끄면 JVM까지 종료되므로, 내부적인 DB는 당연히 삭제된다(*배치종료 시에는 유지).
그러나 실무에서는 젠킨스과 같은 외부환경에 batch를 실행하므로 해당 환경의 종료 시 데이터는 삭제된다.
2) 파일(File) H2 (jdbc:h2:file:...)
애플리케이션 종료 후에도 파일로 저장되어 데이터가 이론적으로는 유지된다. DB 파일이 로컬 폴더에 생성되므로 이를 로드하면 이전의 데이터를 확보할 수는 있다(*.mv.db 형태).
- 지금 사용 중인 H2가 인메모리인지 파일인지 확인하는 방법
application.yml 또는 application.properties 확인을 하는 것이 가장 간단한 방법이다.
단순 h2/batch 의존성 설정이 아니라 직접 db를 연결하였다면, 커스터마이징한 db를 활용하게 되므로 해당 db에 spring batch 데이터를 영속적으로 저장할 수 있다.
spring.datasource.url=jdbc:h2:mem:testdb이의 경우 인메모리(h2)에 저장하며, JVM 종료 시 데이터는 소실된다.
spring.datasource.url=jdbc:h2:file:./data/testdb위와 같이 파일 생성 시, 파일을 생성하는 경로를 지정한다.
/data/batchdb.mv.db
/data/batchdb.trace.db (있을 수도 있음)해당 경로에 위와 같은 job 실행정보를 파일 형태로 저장할 수 있으며, 파일형태로 저장하기에 데이터의 영속화가 이론상으로는 가능하다.
2-3. Spring Batch 기본설정에 의한 동작
설정을 따로 하지 않았다면 Spring Boot 기본값은 mem:testdb로 설정되어, 인메모리 DB를 통한 데이터 유지가 진행되어 기본적으로는 데이터 영속화가 이루어지지 않는다.
다만 H2내부적으로 Schema/table 모두 자동 생성되기에, 이에 대한 설정은 따로 해줄 필요는 없다. H2 저장할 경우 브라우저에서 h2 관련 콘솔(단순히 해당 url로 접속만 해주면 됨)을 직접 실행할 수도 있다.
참고) h2 데이터베이스 사용 시 gradle 설정
spring.h2.console.enabled=true
spring.h2.console.path=/h2-console브라우저로 접속 가능 및 콘솔 확인 가능하다.
http://localhost:8080/h2-console2-4. table이 없다면 Spring Batch는 동작 불가
table이 없다면 배치 실행이 불가능하다.
Spring Batch는 메타데이터 테이블(BATCH_~~~)이 없으면 기본적으로 오류가 나게 되므로, 가장 간단한 배치라도 실행 내역을 최소한 어떤 DB(H2 포함)에 저장해야 정상적으로 동작한다.
Spring Batch는 항상 메타데이터 저장소(JobRepository)와 이를 영속화할 DB 테이블을 무조건 필요로 한다.
Spring Batch는 다음과 같은 정보가 있어야, 그리고 이를 기록하고 관리할 수 있어야 배치를 관리할 수 있기 때문이다.
- 어떤 Job이 실행되었는지 (Job Instance)
- 언제 실행되었는지 (Job Execution)
- 실행 결과는 성공인지 실패인지
- Step 별 상태
- 재시작(restart) 가능 여부
이 구조는 반드시 DB 테이블에 저장되어야 하며, Spring Batch는 이를 어떤 테이블 혹은 스키마에 저장할지 명세화를 한 상태이다.
만약 H2(인메모리)에서 해당 테이블이 없거나 자동 설정 불가능(비활성화) 시,
Cannot determine embedded database driver class for database type NONE라는 로그를 볼 수 있고,
외부 DB를 연결할 경우 DB Exception이 발생하여 다음의 로그를 볼 수 있다.
Table "BATCH_JOB_INSTANCE" not foundSpring Boot는 이런 오류를 피하기 위해, 기본적으로 내장 H2 + 메타테이블 자동 생성을 자동으로 활성화한다.
2-5. Batch 실행 시 내부적으로 사용하는 DB Table
앞서 Spring Batch는 본인이 필요로 하는 스키마 및 테이블에 대한 정보를 명세화하고 있다고 하였는데, 우리는 이를 따라주어야 한다.
Spring Batch에서 H2, PostgreSql 등의 설정 상관없이 표준적으로 사용하는 Table 내역은 다음과 같다.
| 테이블명 | 설명 |
|---|---|
| BATCH_JOB_INSTANCE | job instance 기록 |
| BATCH_JOB_EXECUTION | job 실행 이력 (성공/실패 포함) |
| BATCH_JOB_EXECUTION_PARAMS | job parameter 기록 |
| BATCH_JOB_EXECUTION_CONTEXT | job 실행 컨텍스트 |
| BATCH_STEP_EXECUTION | step 실행 기록 |
| BATCH_STEP_EXECUTION_CONTEXT | step 컨텍스트 |
RDBMS를 사용할때 수동 관리할 경우, 최소한 위의 테이블 내역은 보유하고 있어야 Spring Batch의 정상 실행을 보장할 수 있다.
2-6. Table 생성 시점
Spring Batch는 메타데이터 테이블을 스스로 생성하고 기록한다고 하였는데, 메타데이터 테이블(BATCH_*)은 언제 생성되는지에 대해서도 궁금증을 가져보자.
결론적으로 말하면 빌드 시점이 아니라, 애플리케이션이 동작하여 runtimeOnly의 드라이버 실행을 감지하는 시점, 즉 애플리케이션 런타임 시점에 Spring Batch의 테이블 명세에 의해 생성된다.
즉, 배포(빌드), 의존성 추가 단계에서는 어떤 테이블도 생성되지 않는다.
스프링 애플리케이션이 실행될 때(DB가 초기화될 때) 테이블이 생성된다.
이 과정에 대해 살펴보면 다음과 같다.
1) 의존성 설정
implementation 'com.h2database:h2'
implementation 'org.springframework.batch:spring-batch-core'이걸 추가하는 건 그저 라이브러리나 드라이버를 포함하는 것뿐이다. DB 스키마는 생성되지 않지만, 중요한건 이를 기반으로 Spring Batch의 명세가 동작하는 시점이다.
2) Spring Batch의 메타데이터 명세
schema-h2.sql (Spring Batch 내부 제공)애플리케이션 실행 시, 이 안에 명세된 테이블들의 CREATE TABLE 구문을 스프링이 실행한다. 이 시점에 테이블을 생성한다.
- BATCH_JOB_INSTANCE
- BATCH_JOB_EXECUTION
- BATCH_JOB_EXECUTION_PARAMS
- BATCH_JOB_EXECUTION_CONTEXT
- BATCH_STEP_EXECUTION
- BATCH_STEP_EXECUTION_CONTEXT
즉, “애플리케이션 실행 순간”에 내부적으로 "batch가 이를 감지하고 테이블 sql을 동작"하여 최종적으로 테이블 생성된다.
따라서, 애플리케이션만 실행해도 Spring Batch 테이블 조회는 가능하다.
- 배치 실행 전에도 H2 Console에서 BATCH_* 테이블 조회 가능
- 배치가 한 번도 실행되지 않아도 테이블은 존재함
- 단순히 /h2-console 들어가면 보임
| 시점 | 테이블 생성 여부 |
|---|---|
| build.gradle 의존성 추가 시 | ❌ 생성 안 됨 |
| Spring Application run 시 | ✔ 자동 생성됨 |
| Batch Job 실행 시 | 테이블은 이미 존재, 기록만 INSERT 됨 |
2-7. Spring Batch와 Table 관련 정리
Batch 실행과 Table의 동작원리/연관관계에 대한 내용을 참고사항으로 정리해놓는다. 이 내용은 Batch 실행 과정을 파악 하는데 도움이 될 것이다.
- H2 의존성을 추가하면 왜 자동으로(애플리케이션 실행 시점에 Batch가 이를 감지하여) 테이블이 생성되는가?
Spring Boot의 자동 구성(Autoconfiguration)이 진행되면서, Spring Batch의 테이블 명세에 따른 테이블 생성도 같이 진행이 되기 때문이다.
Spring Boot는 spring-boot-starter-jdbc 또는 spring-boot-starter-data-jpa가 있을 때
Datasource가 없으면 자동으로 H2를 Embedded DB로 구성한다.
이때 내부적으로, 인메모리 H2 데이터베이스 생성 (jdbc:h2:mem:testdb)하며,
- Hibernate/JPA가 엔티티 기반으로 테이블 자동 생성하기에
- Spring Batch가 메타데이터 테이블(BATCH_*) 자동 생성하기에
batch/jpa 의존성을 추가하면 기본적인 테이블 명세가 동작하여 메타데이터 테이블을 생성할 수 있다.
- Spring Batch 메타테이블(BATCH_*)은 어떻게 자동으로 생성되는가?
앞서 기술한대로 스키마 설정에 의해 다음의 테이블을 자동으로 생성한다. 너무나 중요한 내용이기에 한번 더 상기 차 기록해놓는다.
Spring Batch는 “스키마 자동 생성 기능”을 가지고 있으며, 조건이 맞으면 다음 테이블들을, 실행 시 자동 생성한다.
- BATCH_JOB_INSTANCE
- BATCH_JOB_EXECUTION
- BATCH_JOB_EXECUTION_PARAMS
- BATCH_JOB_EXECUTION_CONTEXT
- BATCH_STEP_EXECUTION
- BATCH_STEP_EXECUTION_CONTEXT
참고로, Spring Boot가 Spring Batch를 감지하면 자동으로 다음 SQL을 실행한다, 즉 애플리케이션 실행 시 batch를 감지하고 애플리케이션 측에서 sql을 실행한다.
따라서 Spring Boot 환경에서 Batch 의존성이 있어야 기본적으로 자동 테이블 생성을 보장할 수 있다.
classpath:org/springframework/batch/core/schema-h2.sql application(boot)/batch/h2 설정만 존재하면 기본적인 인메모리 db 활성화, 배치 실행 내역을 저장할 수 있다.
이때 만약 h2의존성을 제거하면 당연히, Spring Boot는 다른 Embedded DB도 자동 제공하지 않는다(그럴 필요가 없어진다).
이 경우 Datasource가 없어서 Spring Batch가 동작 자체를 못하며 에러 발생, 즉 H2가 없으면 Spring Batch는 자동으로 테이블을 생성할 DB가 없어서 실행 불가하다.
| 항목 | 결과 |
|---|---|
| H2 의존성 O | Batch 메타테이블 자동 생성 → 정상 실행 |
| H2 의존성 X + 외부 DB 설정 X | DB 없음 → Spring Batch 실행 불가 |
| H2 의존성 O + application.yml datasource 없음 | 인메모리 H2 자동 생성 |
| H2 의존성 O + file 모드 H2 설정 | 파일 DB로 메타테이블 & 데이터 영구 저장 |
3. TOBE - PostgreSql
Spring Batch를 postgresql 기반의 메타데이터 환경으로 구성해주기 위해 docker에서 postrgresql를 pull하여 이를 연결하고자 한다.
일반적인 연결과정이지만, 몇가지 시행착오를 겪었는데 이 과정이 postgresql 보안관련한 꽤 중요한 내용들을 담고 있기에 지나치지 않고 기록하게 되었다.
3-0. Question) 왜 docker 컨테이너를 생성한 후에 인증을 진행하지 않는가?
Spring batch를 postgresql로 연동할때, 이는 당연히 내부적으로 postgres/root 등의 소켓 접속이 아닌 localhost를 통한 tcp 접속이기 때문에 반드시 인증을 요해야 한다.
그러나
psql -h localhost -U rootpsql -h localhost -U postgres를 통한 tcp접속 시 인증요청이 이루어지지 않고 바로 내부 컨테이너로 진입할 수 있었다.
Spring batch를 통한 접속진행 시 반드시 인증요청을 진행해야 하는데, 그것이 이루어지지 않았기에 이를 문제발생으로 간주하고 해결방안을 탐색하게 되었다.
3-1. postgresql 단일 이미지를 2개의 컨테이너로 사용한다.
본인의 경우 기존 spring security에서 postgresql을 사용하고 있기에, spring batch만의 postgresql 환경을 구성해주어야 했다.
이를 위해 일단 (윈도우 파워셀 기준) 아래의 docker run 명령을 입력해주었다.
docker run --name postgres-batch \
-e POSTGRES_USER=root \
-e POSTGRES_PASSWORD=1234 \
-p 5432:5432 \
-d postgres:latest참고로, 기존 spring security 환경에서는 POSTGRES_PASSWORD만 지정해준 상태로 기본 유저를 사용하고 있는 상태였으며 이는 postgres, spring batch 환경은 그 사용자를 root로 설정해주었다.
3-2. 권한정보가 마운트 되는 장소가 다르다.
이게 중요한데, spring security의 경우 postgresql 15.5 ver을, spring batch의 경우 postgresql latest ver을 사용해주었다.
버전이 달라서인지, 같은 이미지를 마운트하려고 해서 그런지 그 자세한 동작원리는 아직 모르겠으나, 두 컨테이너는 볼륨을 서로 다른 저장소에 저장했다.
볼륨 옵션을 따로 지정해주지 않았기에, 같은 볼륨을 그대로 얹히는 불상사가 발생하지 않을까 걱정했는데 다행히 그러지는 않았다.
일단 시작은 그렇고, 이에 따른 권한정보도 다르게 저장이 된다.
postgresql의 기본적인 볼륨 및 권한정보 저장소는
/var/lib/postgresql/data/pg_hba.conf이후의 컨테이너 생성을 통해 만들어진 볼륨 저장소는
/var/lib/postgresql/또한 권한정보 저장소는
/var/lib/postgresql/18/docker이었다. 보면 알 수 있듯이 완전히 다르고 추측불가하다.
참고로, 권한정보의 저장소를 추출하기 위해선 bash환경에서
echo $PGDATAcli를 해주면 된다.
3-3. 참고) 볼륨 마운트 Destination
마운트 경로를 구체적으로 살펴보기 위해 아래 명령어를 git bash에 입력해주었다.
docker inspect spring-security-postgresql | grep -A5 Mounts이 경우,

docker inspect spring-batch-postgresql | grep -A5 Mounts이 경우,

와 같이 나타난다.
일단 기본적으로 보면 볼륨의 Mount Destination이 각각 다른데, 공식문서 상에서는 15.5ver와 latest의 마운트 경로가 다르다고 하므로 유의하자.
참고로, 지금은 볼륨이 각기 다른 저장소에 다르게 지정이 되었는데, 웬만해서는 컨테이너 1개로 진행이 될 것이므로 매우 많은 컨테이너를 생성할 계획이 아니라면 굳이 볼륨을 지정하지 않아도 될 것이다(만약 많이 생성한다면 볼륨지정이 필수적, 해당 볼륨경로 그대로 볼륨이 마운트되기에 관리적으로 편할 수 있다).
더 중요한 점은, 위 마운트 경로는 볼륨정보에 대한 경로가 나타나있고, 권한정보를 수정하기 위해선 #echo $PGDATA로 실제 경로를 확인한 후 직접 수정해주어야 한다는 점이다.
이제 볼륨이 다른 저장소에 저장이 되었음을 확인하였고, 권한정보 데이터가 어디에 마운트되었는지 그 경로까지 확인해주었다.
3-3. 접속방법에 따른 인증요구를 하도록 권한정보를 변경한다.
권한정보 데이터가 어디에 마운트되었는지 확인하였으니, 실제 그 경로에 들어가서 인증요구를 진행하도록 설정을 변경하는 과정을 진행해보고자 한다.
hba_pg.conf
권한 정보는 hba_pg.conf라는 파일에 저장이 되는데, 이 파일의 경로를 위 echo $PGDATA를 입력하여 직접 추출한 경로를 통해 확인할 수 있다.
bash 환경에서 spring security의 권한 정보는(기본값)
cat /var/lib/postgresql/data/pg_hba.conf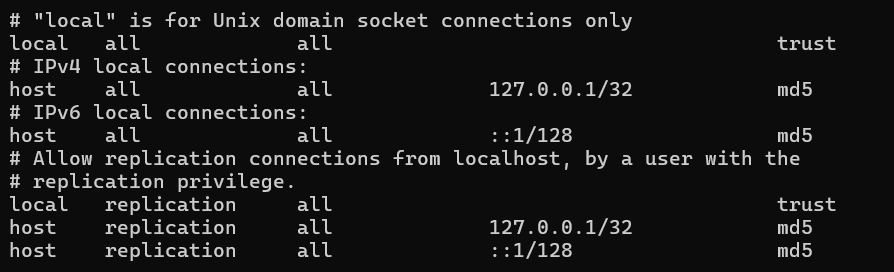
spring batch의 권한 정보는
cat /var/lib/postgresql/18/docker/pg_hba.conf위와 같다.
원래는 IPv4, IPv6의 인증요구를 trust로 되어있었는데, 인증요구로 바꾸기 위해선 위와 같이 모두 md5로 지정해주어야 한다.
이를 위해
sed -i 's/127.0.0.1\/32 trust/127.0.0.1\/32 md5/' /var/lib/postgresql/data/pg_hba.conf
sed -i 's/::1\/128 trust/::1\/128 md5/' /var/lib/postgresql/data/pg_hba.conf의 cli를 실행하여, 각각의 컨테이너 bash환경에서 각각의 권한정보 파일에 들어가서 수정해주면 된다.
3-4. 해결
이 방법을 적용하고 최종적으로 인증정보를 요구하도록 변경해줄 수 있었다.
psql -h localhost -U postgrespsql -h localhost -U root위와 같이 소켓 통신을 통해 접속이 가능하며,
각각의 컨테이너 실행 후에 (Spring security-postgres, Spring batch - root)는 반드시 그 컨테이너의 사용자 이름으로 접속을 하자.
그렇지 않으면 애초부터 접근불허오류가 발생한다.
root@ae8f5cce1623:/# psql -h localhost -U postgres psql: error: connection to server at "localhost" (::1), port 5432 failed: FATAL: role "postgres" does not exist각 독립적인 컨테이너에서 동일한 이미지를 pull 받을 시에는 웬만해선 POSTGRES_USER 정보를 다르게 설정하여, 다른 사용자정보로 접속하도록 하자.
4. 메타데이터를 저장하기 위한 테이블 관련 설정
현재 테스트 환경은 메타데이터 전용 테이블을 자동으로 생성하도록 그 환경을 설정해주었지만, 자세하게 살펴보면 적용대상이나 동작원리 자체가 다르다.
sql:
init:
mode: always
schema-locations: classpath:org/springframework/batch/core/schema-drop-postgresql.sql위 설정은 애플리케이션을 실행할때마다 항상 위 sql을 실행하라는 것이다. 이는 애플리케이션 전역적으로 적용되며, 내장된 sql 뿐만 아니라 개발자가 직접 생성한 sql 역시 그 적용대상이다.
이는 Batch 전용이 아니라, 모든 sql에 대해 적용할 수 있다.
batch:
jdbc:
initialize-schema: always이 설정이 켜져 있으면 Spring Batch가 아래 파일을 찾아 실행하는데,
org/springframework/batch/core/schema-postgresql.sql
말 그대로 BATCH_JOB_INSTANCE, BATCH_JOB_EXECUTION 등 필수 테이블 생성한다.
결론적으로, application 실행 시점에 drop schema가 실행되어 모든 batch 테이블을 삭제하고, 동시에 initialize schema가 실행되어 모든 batch 테이블을 생성한다.
이때 설정이 always로 되어있으므로, 실행시점에 무조건 발생하며, 실무에서는 당연히 수동으로 관리해주어야 한다.
4-1. application.yml / applciation.properties 설정방법 유의
application.yml와 application.properties는 애플리케이션 측에서 파싱하는 방법이 서로 다르므로, 반드시 유의하도록 한다.
- application.properties
key=value 형식, ..~~ = value.
계층구조 없이 온점으로 표현한다.
spring.datasource.url=jdbc:...
spring.sql.init.mode=always- application.yml
yaml 전용 파서, 들여쓰기를 활용한다.
spring:
datasource:
url: jdbc:...
sql:
init:
mode: always더불어, 기존의 사용자이름에 맞게 기본DB를 생성하므로, root 이름으로 했다면 root의 DB가 생성된다.
-> \dt, select current_database(); 로 확인하자.
5. 결론
일단 볼륨지정을 통한 컨테이너 생성, 볼륨 마운트 경로, pg_hba.conf(PGDATA) 경로가 모두 다르고 해당 경로를 탐색하는 과정도 모두 다르기에 이를 해결하기까지 꽤 많은 시간을 소요할 수 밖에 없었다.
하지만 기본을 지키기 위해, 당연히 웹에서 접속하는 것은 비밀번호를 요하는 조건이 필수적이므로 이를 문제점으로 간주하고 여러 해결방안을 모색하였다.
그 과정 속에서 docker 이미지를 내려받고 컨테이너를 생성하기까지의 과정에 대해 더 면밀히 살펴보고 이해할 수 있었고, 나아가 postgresql에 대한 세부적인 사항들도 무사히 살펴볼 수 있었다.
이제 본격적으로 Spring Batch를 RDBMS와 연동하여 job/step을 어떻게 관리할지 그 방법에 대해 분석해보도록 한다.
참고. Oracle vs MySql vs Postgresql
먼저 핵심요소에 대해서만 비교하면 다음과 같다.
| DBMS | 동시성 제어 방식 | Lock 구조 | 트랜잭션 격리 모델 |
|---|---|---|---|
| Oracle | 완전 MVCC 기반 (Undo Records) | Row-level Lock, Multi-Version Read Consistency | Oracle Snapshot Isolation (Read Consistent) |
| MySQL (InnoDB) | MVCC 사용하나 undo 로그 방식이 간단함 | Row Lock + Gap Lock/Pseudo Gap Lock | 기본: REPEATABLE READ (InnoDB만의 RR은 Phantom Read를 막음) |
| PostgreSQL | 순수 MVCC (Undo 없이 “tuple versioning”) | Row-level Lock + Visibility Map | Snapshot Isolation 기반 |
동시성을 관리하는 기준으로 각 DB에 대해 쉽게 정리하면, 다음과 같다.
- Oracle의 동시성 관리 방식 — Undo 기반 “일관된 스냅샷 제공”
읽는 동안, 읽기 시점의 과거 데이터를 Undo에서 꺼내서 보여준다(즉, 읽는시점과 쓰는(pending) 시점이 같을때, 읽기는 쓰기를 기다리지 않고, "Undo"에 있는 스냅샷을 그대로 읽어온다.
따라서 읽기는 절대 쓰기를 기다리지 않는다 = Non-blocking read, 더불어 이러한 Undo를 관리하는 별도의 공간적 비용이 필요하며, 오래된 트랜잭션이 있을 경우 ORA-1555 DB예외가 발생할 수 있다.
- MySQL(InnoDB)의 동시성 관리 방식 — Undo + Gap Lock을 통해 일정 수준의 격리 보장, MySQL도 Undo 기반의 MVCC를 사용하며 읽기는 보통 쓰기를 막지 않는다(Oracle보다는 단순한 구조).
그 유명한 Repetable Read 수준의 동시성 관리가 가능한 이유는, 한 트래잭션이 데이터를 읽고 있을때 Gap Lock을 걸어서, INSERT와 같은 데이터 변경 행위를 애초부터 불가능하게 만들며 이로 인한 Phantom Read를 차단한다.
- PostgreSql의 동시성 관리 방식 — 테이블의 각 row에 xmin(생성버전), xmax(삭제버전) 을 저장하여 관리하는 방식으로, 읽을 때 Undo가 아니라 row 자체의 버전을 보고 보이는지 판단하는, “튜플 버전이 여러 개 존재”하는 방식이다.
쉽게 말하면 생성버전과 삭제버전이 읽기, 쓰기 트랜잭션이 발생할때마다 달라지며, 각각의 트랜잭션 발생시 해당 버전의 조건이 동일한 스냅샷만 보이게 된다.
각각의 스냅샷을 가지는 트랜잭션은 독립적인 환경에서 자유로운 트랜잭션 처리를 진행할 수 있다.
MySQL은 "멀티유니버스", 즉 평행세계가 존재하지 않고 Oracle, PostgreSql은 평행세계가 존재하기에 이로 인한 트랜잭션 차단/MVCC 경합 정도의 차이가 발생하게 된다.
쉽게 말하면, MySql은 평행우주가 존재하지 않고, 테이블 그 자체 하나, 단독적인 세계만 존재하고 관리하기에 update 중간에 다른 트랜잭션이 이를 읽으면 update한 row가 반영되는 "phantom read"가 발생한다(Repeatable Read는 읽은 시점에서의 컨텍스트 일관성만 보장하고, 전체DB로 보았을때는 이러한 일관성을 보장해줄 수 없다).
이에 반해 Oracle이나 Postgresql은 애초부터 각 트랜잭션에게 "독립된 환경의 평행우주"를 제공하기에, 쓰기가 진행된다 하더라도, commit 이전의 스냅샷으로 제공되며 이들은 모두 독립된 환경이다(충돌을 제외하고는 서로가 서로에게 영향을 주지 않는 상황).
동시성 관점에서 Oracle이나 Postgresql을 살펴본다면, commit 시점에서 충돌을 감지한다는 기본 사상은 있으나 구현난이도가 매우 높다. MySQL의 Repeatable Read는 이보다는 단순할 수 있지만, 그만큼 개발자 입장에서 고려해야할 동시성 제어 관련 항목들이 많이 존재할 수 밖에 없다.
참고로, Oracle의 경우 경험상 wirte conflict를 DB내부적으로 막기에는 한계가 있기에(TPS가 높아지면), 배타락이나 공유락 등의 추가조치가 필요할 수 있다.
한눈에 정리
-
Oracle -> 락기반 충돌 방지(그런데 한계가 있을 수 있음)
-
MySql/PostgreSql -> snapshot version기반의 충돌 방지
-
Oracle/PostgreSql -> 스냅샷을 평행우주처럼 트랜잭션별로 격리된 환경으로 제공
-
MySql -> 스냅샷을 격리된 환경에서 제공불가, DB 단일 전체스냅샷으로만 관리
마지막으로 Schema 등의 인스턴스 관리 체계를 중점으로 정리하면 다음과 같다.
Oracle의 경우, DB > Schema > Table 순으로 이어진다. 보통 테이블을 검색할때 Schema까지 명기한다.
Oracle Instance (SGA + Background Processes)
└── Database (물리 파일 집합)
├── Tablespace
│ └── Datafile
└── Schema (User)
└── Table, View, Index ...
MySQL의 경우, DB(Schema) > Table 순으로 이어진다. 테이블을 검색할때 DB(Schema) 환경 내에서 이루어지기에 따로 Schema를 명기하지 않고, 바로 테이블을 검색한다.
use user;MySQL Server Instance
└── Database (= Schema)
└── Table (각 테이블이 실제 파일로 저장)
Postgresql의 경우, DB > Schema > Table 순으로 이어진다. Oracle과 유사하게, DB수준의 이동이기에 Schema.Table와 같이 테이블 검색 시 Schema를 명기해주어야 한다.
PostgreSQL Cluster (initdb로 생성된 전체 인스턴스)
└── Database
└── Schema
└── Table
참고로, postgresql의 경우 기본 스키마로 public, 기본 DB로 postgres를 제공한다(DB이지, "테이블"이 아니다!).
