컴퓨터를 설계할때 우리는 어떤 시스템이 더 좋은지 알고있어야한다.
서울에서 부산까지의 시간 , 속도 , 승객 , 승객 처리량 을 각각
Boeing 747 은 1시간,1000km/h,100,100000
Concorde 는 0.5시간,2000km/h,20,40000 이라면은
어느 교통수단이 더 빠르다고 할수있을까?
만약 비행 시간 , 서울에서 부산까지의 시간이라 생각하면 Boeing 은 1시간 Concorde 는 0.5 시간임으로 1/0.5 로 Concorde 가 2배 빠르다.
하지만 처리량(Throughput) 으로 놓고 따지면 Concord는 40000 ,Boeing은 1000000 이다. 그래서 1000000/40000 로 Boeing이 2.5배 빠르게 되는것이다.
이렇게 Performance를 측정하기에는 다양한 기준(? 종류? )가 있다.
이 책에서는 크게 Time,Rate,Ratio 로 나뉜다.
Time은 무언가가 시작해서 끝날때 까지의 시간
Rate는 특정 시간동안 처리되는 Task의 양(개수)
Ratio 는 공백
이제부터 이 기준들에 대해서 알아볼것이다.
1) TIME-The first type of Performance
Time 에도 두개로 나뉜다.
1) Wall-clock,response time,elapsed time
실제로 시작부터 완료까지 걸리는 시간으로써 유저들이 실제로 느끼는 시간이다.
다른 프로그램이나 메모리,디스크 접근시간등 예측불허한것들도 포함하여 측정을하기에 당연하게 성능을 측정하기에 적합하지 않다.
2)CPU TIME
cpu time 은 cpu 가 특정한 명령어을 수행하는데 얼마나 빠르게 수행할수 있는지를 판단하는 성능을 나타난다.
Computer Architecture 에서는 CPU가 중요하다.
1) Measuring Cpu Time : Decomposition of Cpu Time
프로그램 하나의 cpu time을 구하는 방법은 간단하게 말하면
프로그램 하나당 가지고 있는 Cycles * cycle 하나당 소요되는 시간이다.
프로그램은 instruction의 집합이니 프로그램 하나당 가지고 있는 instruction 수 * instruction 하나당 가지고 있는 cycle을 곱하게 된다면 프로그램 하나당 가지고 있는 cycle 개수가 나온다.
여기서 프로그램 하나당 가지고 있는 instruction을 IC 라하자
그리고 instruction 하나당 가지고 있는 cycle을 CPI 라 한다
마지막으로 cycle 하나당 소요되는 시간을 clock cycle time 이라 한다면
우리는 CPU Time 을 쉽게 구할수 있다.
CPU TIME = IC x CPI x Clock Cycle Time
or
clock cycle time은 은 clock rate 와 reciprocal 의 관계이다(역수)
그렇기에 CPU TIME = IC x CPI / Clock Rate 로도 표현 가능한 것이다.
2) More on CPI
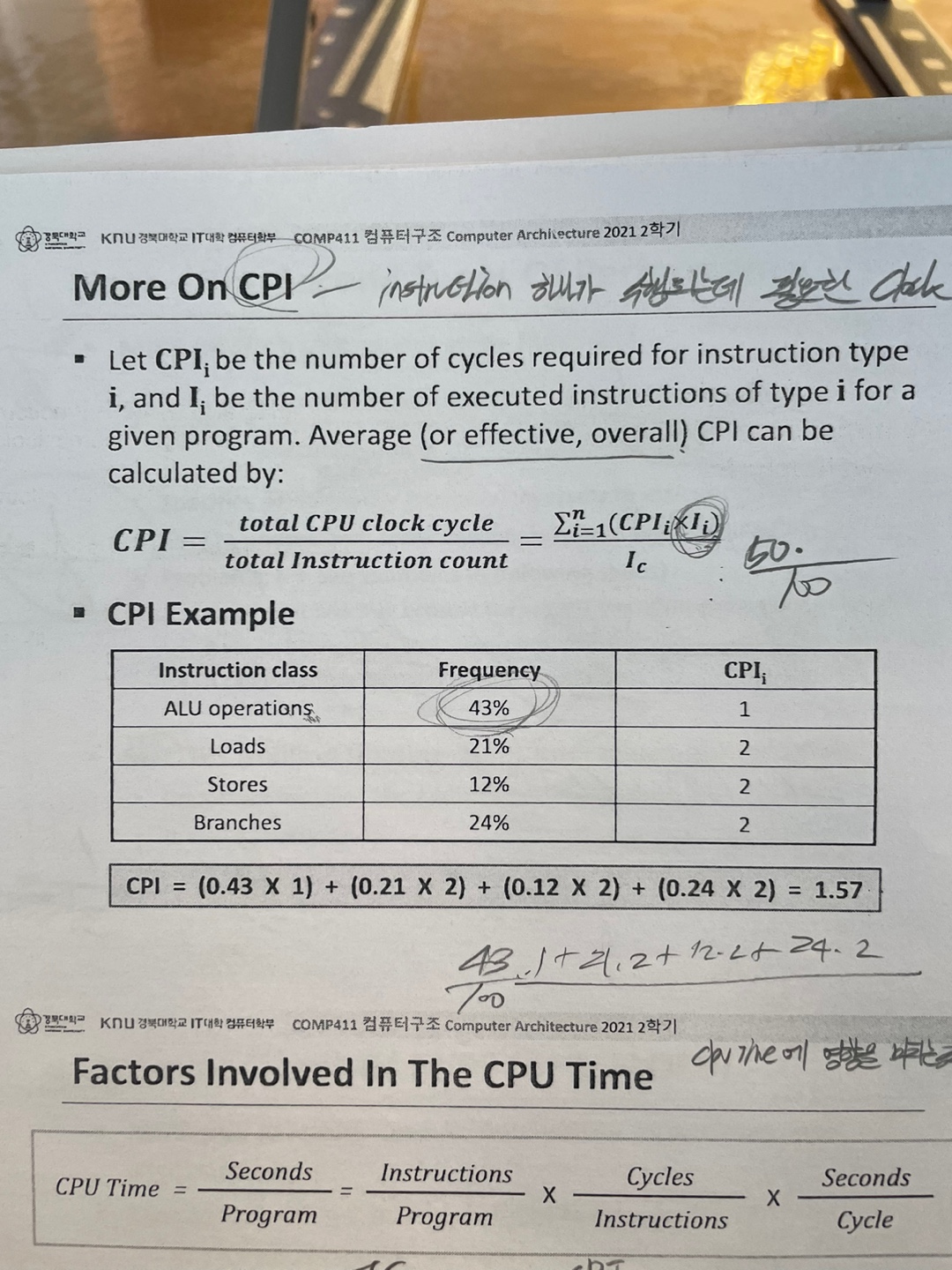
만약 instruction 이 다르다면 각각 다른 cycle을 가지게 된다.
그럴떄 avg CPI 를 구하는 방법이다.
각 instrcution 의 cycle을 구한뒤 total instruction count(IC) 로 나누면 된다.
그래서 CPI Example 처럼 값이 나오게 되는것이다.
여기서는 frequency(rate 이긴 한데 우리가 말하는 clock rate랑은 다른 그냥 전체적인 비율을 말하는것 같음) 가 전체중 43%를 차지하고 있다는 말을 그냥 나는 total instruction count 를 100이라 가정하고 ALU operation의 IC를 43이라 가정한다.
그렇게 된다면
((431)+(212)+(122)+(242))/100 을 하게 된다면 1.57의 값이 나오는것이다.
여기서 갑작스러운 문제.
문득 태곤이가 cycle이 많으면 좋은거야? 라고 질문한적이 있다.
나는 clock cycle time 만을 생각해 당연하게 cycle이 많으면 clock cycle time도 줄어 들기에 cycle 이 많으면 좋다! 라고 얘기해 줬는데 이부분은 내가 너무 잘못 생각했음.
누구는 cycle이 낮으면 좋고 높으면 좋다 하지만 정말로 다 틀린거다.
cycle이 많고 적고에 따라 성능이 좋고 안 좋고를 따질수 없다가 내 결론이다.
왜냐. cycle이 많으면 cpi는 높아진다 하지만 clock cycle time은 낮아진다. 반대로 cycle이 적으면 cpi는 낮아지지만 clock cycle time은 높아진다. cpu time 을 줄이기위해선 ic, cpi ,clock cycle time을 다 낮춰야하는데 cycle의 개수로 인한 cpi 와 clock cycle time의 관계는 반대가 된다는 말이다. 그럼으로 cycle 이 높아진다고 좋아지는것도 아닌 낮아진다고 좋아지는것도 아닌 단지 IC,CPI,clock cycle time을 다 줄여야 좋다는것이다.
2) Rate- the second types of Performance
다음의 성능을 판단할떄의 기준은 Rate 이다.
Rate 는 일정시간동안 얼마나 많이 처리되는가를 나타내는데
MIPS 와 MFLOPS 가 있다
1) MFLOPS
MFLOPS 는 floation-point 인데 강의에서는 크게 다루지 않는다
2) MIPS
MIPS 는 Million instruction per seconds 라는 의미로 instruction 을 초당 몇 백만개 처리하나를 나타낸다.
-> 직관적이며 사용하기도 쉽다.
MIPS는 크면 클수록 빠르지만 CPU 가 더 빨라지진 않는다.
하지만 MIPS에는 문제점들이있다.
일단 다음에 공식이 나오겠지만 instruction의 능력을 고려하지 않는다.
그렇기에 정확하지 않고 결과가 동일한 컴퓨터에서도 다를수있다.

MIPS 는 말 그대로 million instruction per second 다 초당 수행되는 instruction의 개수인데 그럼 당연하게
MIPS = total instruction count / (cpu time x 10^6) 을 하면 된다. 여기서 cpu time 은 instruction count x cpi / clock rate 이기에 정리하게 된다면
MIPS = Clock rate / CPI * 10 ^ 6
3) Benchmarks
Benchmarks 는 성능 비교이다.
실제 사용자의 사용패턴을 흉내내서 평가한다.
2 개의 standard benchmarks 가 있는데
SPEC , TPC 이다.
SPEC 는 cpu performance 를 측정하기 위함이고
TPC 는 data base system 을 측정하기 위함이다.
4) Amdahl's Law
암달의 법칙은 특정 부분의 개선에 의한 전체적인 성능의 향상 정도는 그 개선된 부분이 사용되는 부분의 양에 의해 제한된다는 것을 의미한다.

f 를 병렬적으로 수행되는 code 라하고
1 - f 를 병렬적으로 수행할수 없는 code 라 하자.
만약 f 부분을 n 만큼 개선을 시켜도 1-f 는 바뀌지 않기에 1-f 보다 줄일수 없다는 말이다.
예시로
프로그램을 100초에 수행하는 컴퓨터를 두고 곱셈 연산이 차지하는 비중을 80초라한다. 이때 곱셈 연산을 n배 빠르게 수행하게 한다면 해당 프로그램 실행시간은
(80 / n ) + (100 - 20) 이다
n이 아무리 크더라도 해당 프로그램의 실행시간을 20초보다 줄일수 없다는 것이다.
그래서 성능을 늘리기 위해서는 process 의 개수를 늘리는 것도 중요하지만 code 를 짤때 parallel 하게 동시 진행 될수 있는 형태의 code 의 portion 을 늘려야한다.
