Data Structures in Assembly
Array 는 One-dimensional , Multi-dimensional , Multi-Level 로 나뉜다. 자료구조를 안다면 쉽게 의미를 알수 있을꺼같은데 각 1차원배열,2차원배열,2레벨 배열이다.
Structs,Unions 도 있다.
Array Allocation

T A[N];
T 는 Data 의 Type ( 자료형)
N 는 Array의 Size 을 말한다.
A 는 배열의 이름이다.
배열은 메모리의 연속적인 공간에 할당되게 된다.
각 자료형의 Size 도 알아야하는데
char 는 1byte
int 는 4byte
double 은 8byte
포인터는 8byte 이다.
포인터는 시스템마다 크기가 다른데 RISC 방식에서는 8byte 라 나와있다.
Array Access

각 자료형의 크기에 따라 그리고 배열의 크기에 따라
만약 자료형의 크기가 8 byte 인 Double 이고
배열의 크기가 10이라하면 메모리에는 총 80Byte 가 연속적으로 할당된다.
그리고 각각의 인덱스에 접근하기위해서는
배열의 첫번쨰 주소+(자료형 크기 인덱스번호) 를 해주면 된다.
위의 예시로 만약 첫번쨰 주소가 100 이였고 2번쨰 인덱스의 주소를 알고싶으면
100+(82) = 116 이 되는것이다.
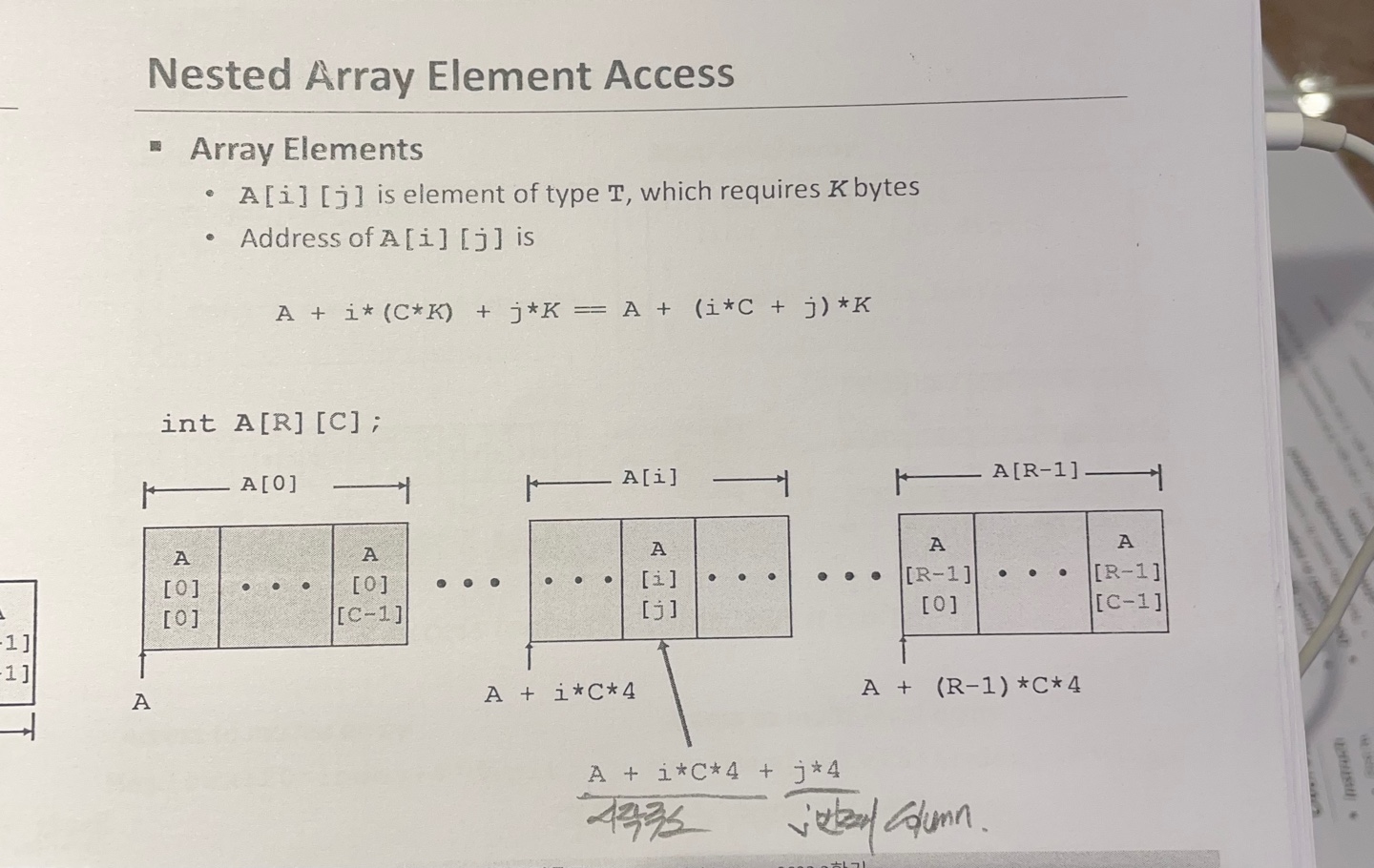
Two-Dimensional(Nested) Array

T A[R][C];
똑같이 T 는 자료형을 나타내고
A 는 배열의 이름
R은 행의 수 C 는 열의 수를 나타낸다.
Nested Array 는 RC자료형의 크기만큼 메모리에 연속적으로 할당된다.
만약 A[i][j] 의 주소를 알고싶으면
배열의 첫번쨰 주소+i(C자료형의크기)+(j자료형의크기)를 하면 된다.
예시로 sea[3][3] 의 주소를 알고싶고 첫번쨰 주소가 76이라면
76+(203)+(4*3) 으로 148의 주소를 가진다.
Multi-Level Array

Multi Dimension 이랑은 다른 Multi level Array 이다.
2 - Level Array 는 2번을 거쳐서 접근을 하겠다는 말이다.
int snu[5] = { 1,5,2,1,3};
int knu[5] = {9,8,1,9,5};
int kaist[5] = {9,4,7,2,0};
int * univ[3] = {knu,snu,kaist};
라고 한다면 univ 를 거쳐 snu 를 거치게 된다면 snu의 값을 알수있을것이다.
이렇게 N번을 거쳐서 접근하는 방식을 말한다.
Multi-level Array 에 접근하기 위해서는 2번을 메모리에 접근하기에 성능적인 면에서는 Nested Array가 훨씬 효율적이다.
그리고 Nested Array 는 모두가 연속적이게 할당되는것에 비해 Multi-level 은 1차원배열이 연속적이지만 각각은 연속적으로 할당되지 않을 가능성이 높다.
Structures & Alignment

Unaligned Data 와 Aligned Data 로 나뉜다.
Unaligned Data 는 Memory Alignment 를 고려하지 않은것을 말한다.
그럼 Aligned Data 는 Memory Alignment를 고려했다고 볼수있다.
구조체에서 가장 큰 자료형의 크기를 가지는것을 기준을 잡고 그의 배수에 맞게 메모리에 할당하는 방식이다.
하지만 그렇게 할당하는 방식은 padding data 를 통해 memory 채워넣기 밖에 되지 않기에 memory 낭비가 있을수밖에 없다. 그래서 padding 도 최소가 되어야한다.
How the Programmer can save Space?
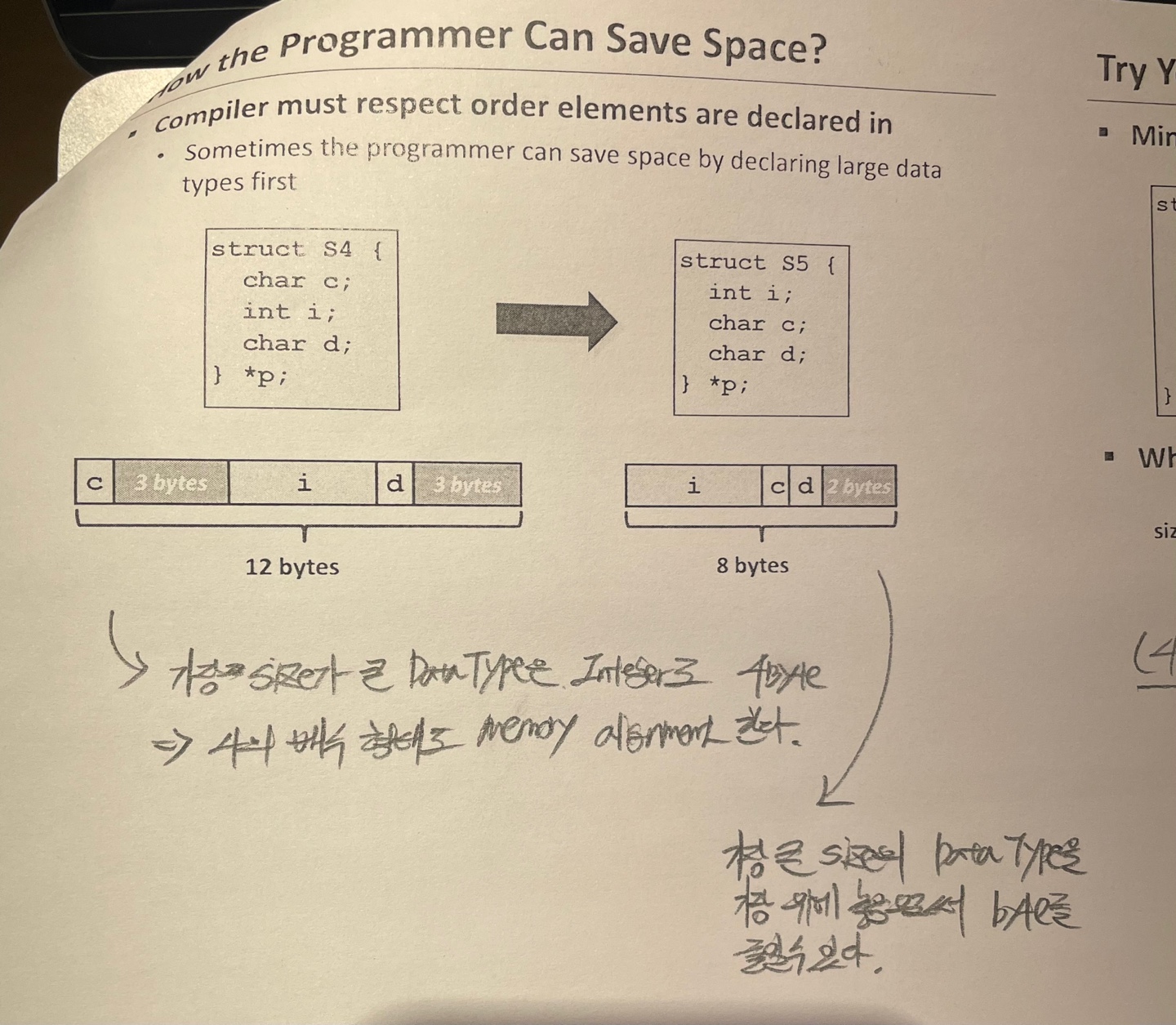
위 그림에서 볼수 있는것처럼 가장 큰 자료형을 가지는 변수를 중간에 두게 되면
Padding data를 각각 3Byte 를 할당해서 12 Byte 를 가지게 되는것을 볼수있다.
하지만 가장큰 데이터를 맨 앞에 둘경우에는 Padding data가 2byte 밖에 필요하지 않아서 8Byte 를 가지게 된다.
이렇게 구조체의 선언을 어떻게 함에 따라서 memory의 낭비를 줄일수 있다.
