RISC-V 방식도 처음부터 지금까지 꽤나 많이 발전을 한것 같다.
현재의 RISC-V 방식을 배우기전에 지금까지의 발전들에 대해서 알아보겠다.

RISC는 명령어 길이가 고정되어있는것을 안다.
맨 처음에는 4Byte(32Bit)를 2개로 나뉘어
Type-A 에는 피연산자 2개
Type-B 에는 연산자 1개를 넣고 남는 5Bit는 안쓰고 놔둔다.
이런 방식일때 서로 다른 Instruction을 몇개 만들수 있을까?
Opcode 가 6bit 씩 두개가 있기에 2의 6제곱 + 2의 6제곱을 하면 되지 않아? 라고 생각할수 있지만
만약 Type-A의 opcode 가 111111 이고 Type-B의 opcode가 111111 이게 된다면 컴퓨터는 두개를 구분하지 못하게 된다. 그래서 두개를 구분해야하고
한비트를 구분하는 Bit를 사용하게 된다면 2의 5제곱 + 2의 5제곱을 해서 총 64개의 instruction을 가질수 있게 되는것이다.
하지만 이런 방식을 쓰게되면 64개 밖에 못써서 작다고 생각했나보다,,,,
(내생각임)
그래서 나온 다음 방식은 이렇다.

아까 처음 방식에서 Type-B의 남는 5Bit는 비워뒀다 했다.
하지만 비워두면 너무 아깝다고 생각했는지 그 Bit를 opcode 로 돌려버렸다.
자 이렇게 하면 instruction 의 수는 몇개가 될수있을까?
간단하게 생각하면 한 bit는 똑같이 구별할수있게 비워두고
2의 5제곱 +2의 10 제곱을 더하면 = 1056 이러면 되지 않을까 생각했는데
이 방법보다 더 많이 만들수가 있었다.
만약 Type-A에서는 한개의 명령어만 쓰고
Type-B 에서는 A에서 쓰지않는 명령어를 제외하고 다 사용하게 된다면
1+(2의 6제곱 -1)*2의 5제곱 으로 =2017개를 만들수나 있다.
만약 Type-A에서 10개의 명령어를 사용한다면
10+(2의 6제곱 -10)*2의 5제곱 이라 표현할수있는것이다.
여기까지가 현재의 RISC-V 방식 전까지이고 이제 RISC-V에 대해 알아보겠다
1) Instruction Format @RISC-V

RISC Type 도 여러개가 있다
이렇게 많은걸 볼수가 있는데
R-Type 은 Register 끼리 연산을 할때 사용하는거고
I-Type 은 임의 값을 가져와서 연산을 할떄
S-Type 은 Store 이라 할수있다.
I와 S Type은 메모리에 접근한다.
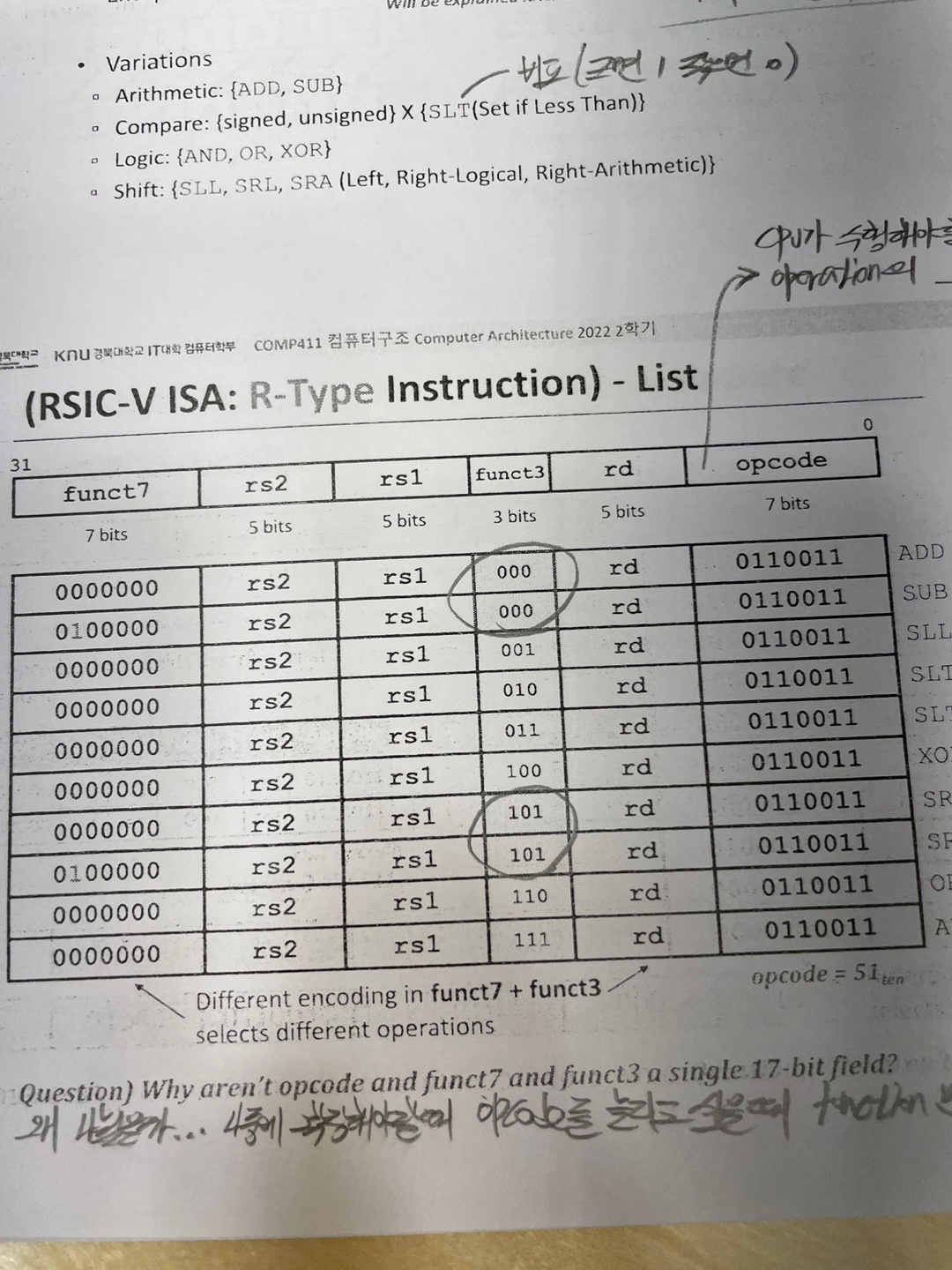
2) R-Type Instruction
1) Arithmetic
Arithmetic 연산은 3개의 피연산자가 필요하다.
각 피연산자들은 Register 들인데 Register에 피연산자들의 값을 미리 넣어 둬야한다.( LOAD)
RISC 방식은 알다시피 메모리에 있는 데이터가 직접적으로 접근되지않는다.
그래서 컴파일러는 Register들을 많이 사용해야한다.(Register가 Memory보다 훨 빠르기떄문)
2) Format
R-Type instruction format 은 64Bit 임에도 32Bit 이다.

func7 rs2(source register) rs1 func3 rd(destination register) opcode 이런 형식이다.
이러한 형태를 가지는데 funct7 와 funct3 가 있는 이유는 opcode 의 종류를 확장하기 위해 있다.
그래서 만약 add x9 x20 x 21 이라는 연산을 하게 된다면
0000000 10101(21) 10100(20) 000 01001(9) 0110011(51) 이다.
add 연산은 func7 func3 opcode 를 했을때 0000000 000 0110011 이다.
그리고 R-type의 opcode 는 51의 2진수로 고정이다. funct7 과 funct3에 따라 연산이 바뀌게된다.
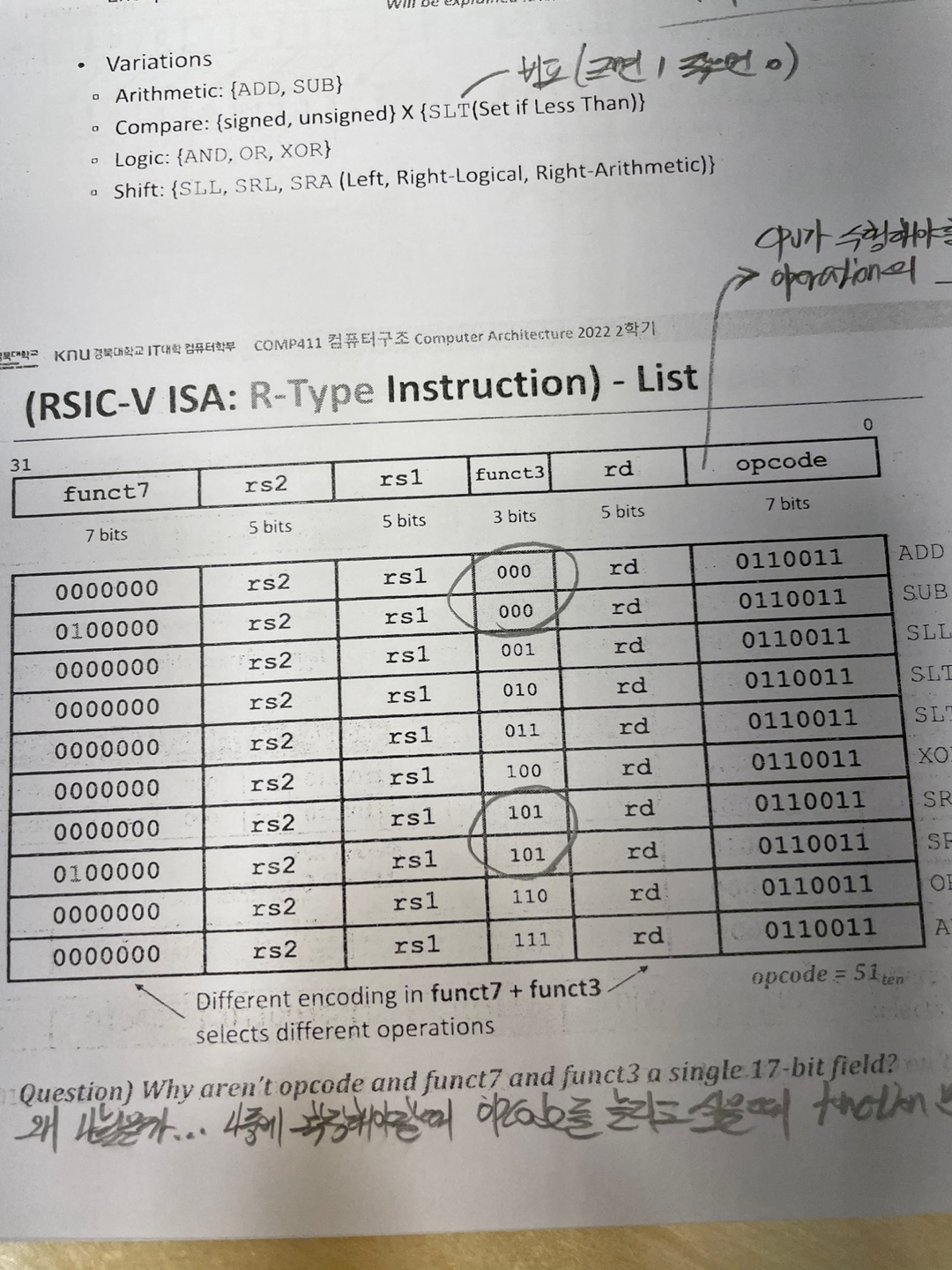
이건 R-Type 들의 List이다.
1) ADD,SUB
Add,Sub 는 위에서 했으니 생략
2) Shift
SLL rd rs1 rs2 라는 말은
rs1의 값을 rs2에 들어있는 값 만큼 shift left logical 연산을 하라는 말이다.
Shift 는 알껀데 왼쪽으로 Shift 면 *2를 하고 오른쪽으로 Shift 면 /2 를 하면 된다.
Shift 연산에는 SLL , SRL , SLA , SRA 가 있다
shift 를 어떻게 함에 따라 나뉘는 4갠데
일단 shift 를 logical 로 할지 arithmetic 인지에 따라 맨 뒤가 L인지 A인지에 따라 다르다
그리고 Shift 를 왼쪽으로 한다면 두번쨰가 L 오른쪽으로 하게된다면 R이다
그래서 만약 Shift right logical 이면 SRL 이 되는것
SRA 를 제외한 3개의 연산은 각 연산에 따라 Shift 후 빈 자리는 0을 넣어주면 되는데 SRA는 원래 sign bit를 맨 앞자리로 복사를 해줘야한다.
만약 00010111 에서 sra 를 수행하면 00001011 이고
10010111 에서 sra 를 수행하면 11001011 이 되는것이다.
3) Compare
Compare은 말그대로 비교한다는건데
SLT 와 SLT(u) 가 있다.
SLT(Set Less Than) 이라는 뜻이고 SLT sign comparison 을 수행한다.
SLT x1 x5 x3 이라는 연산은 x5와 x3을 비교하여서 if x5 < x3 이면 1 아니면 0 이라는 값을 x1 에 담는것이다.
만약 SLT x1 10 11 이라면은 x1의 값은 1이라는 말.
SLT(u) 는 unsigned comparison 을 하겠다는 것.
4) And , Or, Xor , Not
and x9 x10 x11
or x9 x10 x11
xor x9 x10 x12
각각 뭘 말하는지 알것이다.
not 은 xor x9 x10 111...1111 하면된다.
3) I-Type Instruction
일단 RISC 는 CISC 보다 Register 가 더 많다.
하드웨어로 구현해야할 명령어가 더 적고 복잡한 나머지들은 다 Software 가 한다.
I-Type 은 자주 사용하는 상수가 있을 경우에는 그 constant 를 메모리에 집어 넣어서 매번 memory에 집어넣어서 매번 memory에 가진 register 끼리 연산을 하기 보단 자주 사용되는 constant 는 직접 연산을 하는것이 memory 접근을 최소화 하기 좋다.
addi x22 x22 4 라는 말은 x22의 값에 4를 더해 x22에 다시 넣는것이다
R-Type에서 보면 add x22 x22 x23(4라는 값이 있음) 이라하면 Memory에 접근해서 4라는값을 x23에 넣어줘야하는데 i-Type 을 사용하면 그렇지 않다는 말!
1) Format
Arithmetic operation that uses a constant number 이라하는데
위에서 말한것처럼 상수를 사용하는 연산이다.
ADDI rd rs1 imm(12) 가 양식이다
imm은 지정하고싶은 상수의 값이 들어가고 12비트가 된다. 그리고 상수부분은 항상 음수,양수를 구분한다.

I-Type은 second source register가 필요없기에(상수) R-type 에 있던 rs2 부분을 funct7과 합처 imm 부분이라고 넣어뒀다.
12비트이기에 -2의 11제곱 <= x <= 2의 11제곱 -1 까지 표현가능하다.
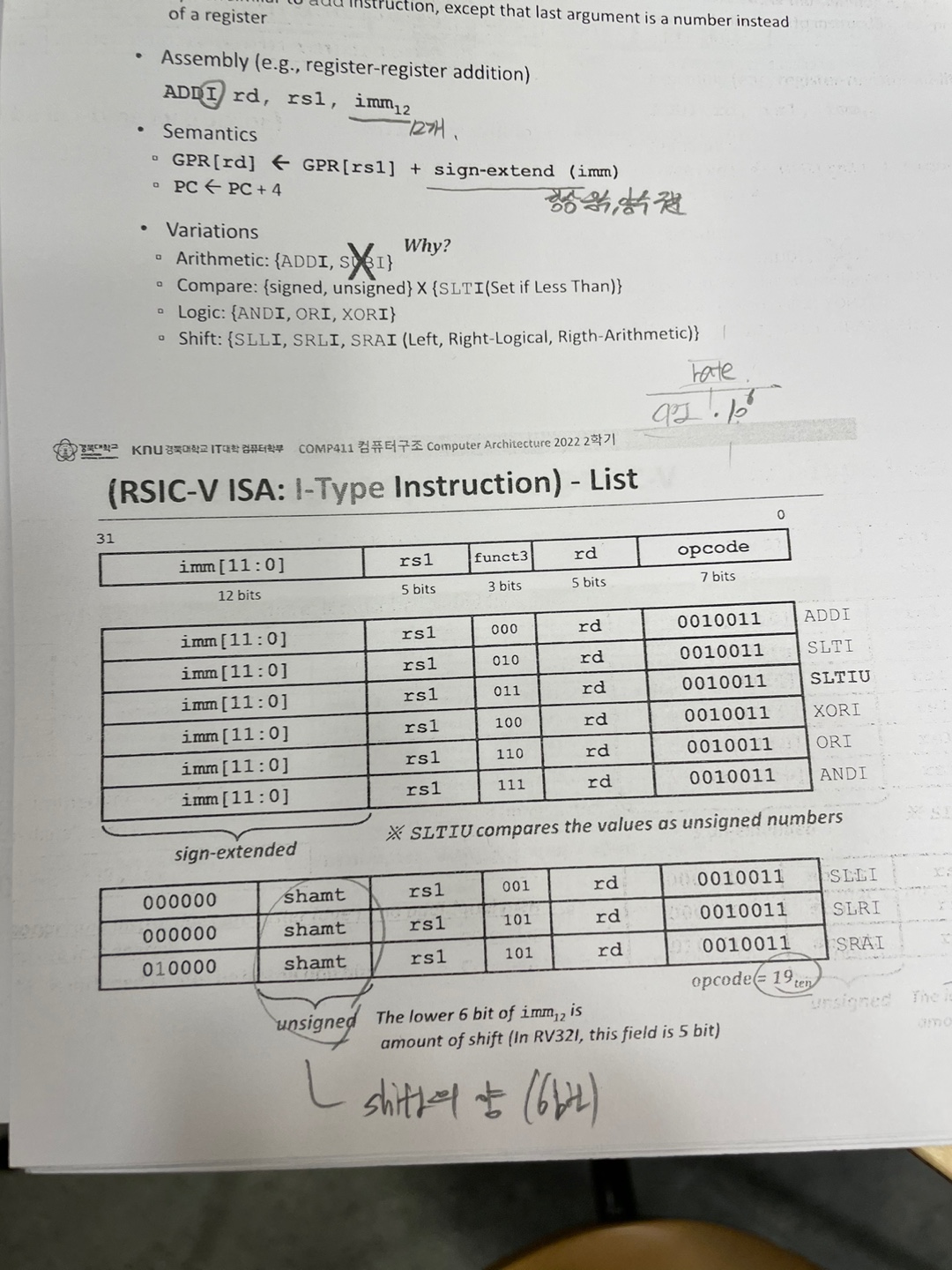
I-Type instructions 의 list 들이고 밑의 3개는 unsigned 라 한다.
2) Load
Memory의 개수는 한정적이여서 모든 Data를 register에 세팅할순 없다.
그래서 data transfer instructions 을 수행해야한다.
(memory에서 register로)
그떄 쓰는 instruction 이 Load 라는 것이다.
ld x2 16(x3) 이라는 말은 16(offset)에 x3에 담겨있는 값을 더해 그 메모리 주소에 가서 값을 x2에 doubleword 단위로 load 하라는 말이다.
LW rd offset(12)+base Register 가 기본 양식이다.
LD,LW,LWU,LH,LHU,LB,LBU
가 있는데 다 뒤에 말에 따른 크기로 Load 를 하라는 말이다.
ld=double word 단위
lw= word 단위
lwu= word 단위를 unsigned 하게
lh= half word 단위
lhu= half 단위를 unsigned 하게
lb= byte 단위
lbu= byte 단위를 unsigned 하게
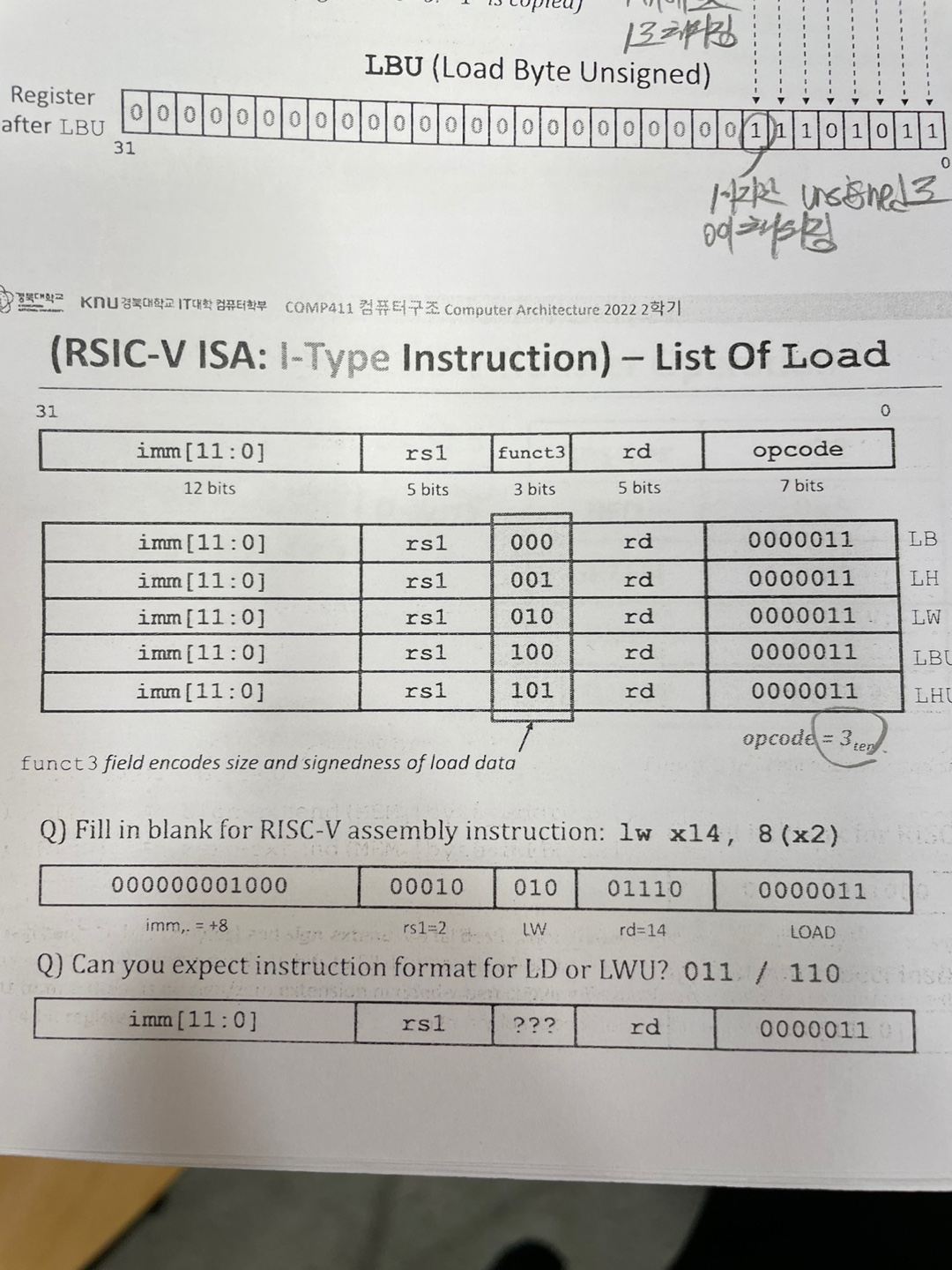
이건 Load 명령어의 list 인데
그래서 만약 lw x14 8(x2)이라면
000000001000(8) 00010(2) 010 01110(14) 000011(3) 이다
4) S-Type Instruction
1) Store

Load 는 rs2가 당연하게도 필요없었다.(왜인지 모르면 바보)
하지만 Store 은 다시 메모리에 넣어줘야하기에 rs2가 필요하다.
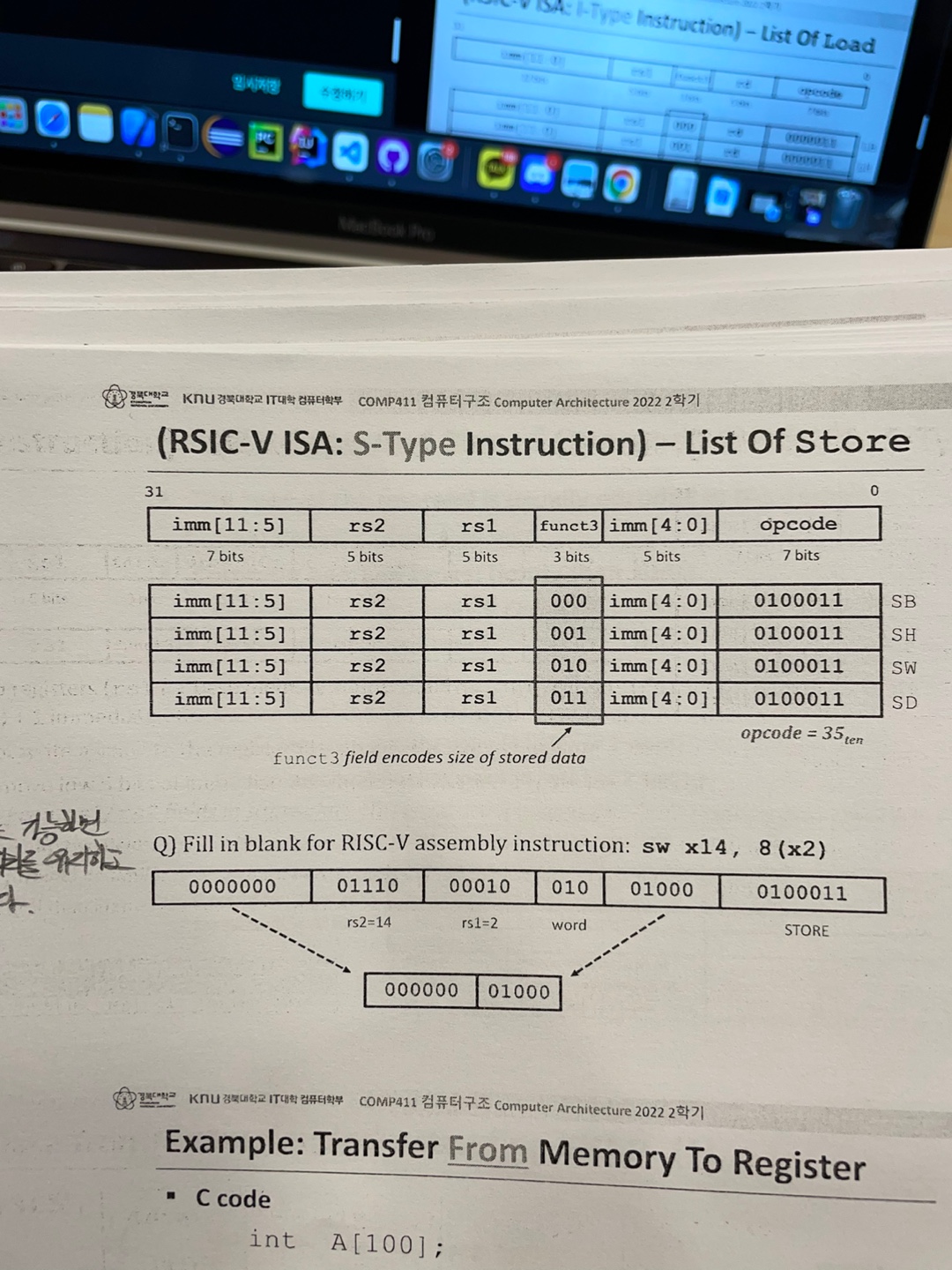
이건 Store instructions 의 lists 인데
그래서 SW x14 8(x2) 는
0000000 01110(14) 00010(2) 010 01000 0100011(35)
특이하게 imm 부분이 나눠져있기에
0000000 01000 을 해서 8이라는 상수를 가진다.
5) S(B)-Type Instruction
S(B) Type 은 Branch 를 나타낸다 If while for 문등 분기문을 나타낸다.
Conditional Branch 와 Unconditional Branch 가 있다.
Conditional Branch 는 조건문이 맞으면 그자리로 가!! 라는말이고
(BNE,BLT)
Unconditional Branch 는 그냥 가!! 라고 한다,.,,,
(JUMP)
1)Format
BEQ rs1 rs2 Label 이라는 방식인데, rs1 , rs2가 같으면 Label 로 가라는 연산이다.
원래는 명령어를 수행후 PC=PC+4로 연산을 하는데 SB-Type 은 좀 다르다.
만약 BEQ rs1 rs2 Label 이라 하면
내가 옮겨서 수행해야할 명령어가 있는 메모리 주소를 Target 이라하자.
Target= pc+imm(13)
만약 rs1 rs2가 같으면 Label로 가고 그렇지 않으면 Pc+4로 간다
2) Branch
beq,bne,blt,bge,bltu,bgeu가 있다.
beq 는 rs1 과 rs2가 같으면 l1로 가라는 말이다.
branch if equal 이라는 뜻.
bne 는 branch if not eqaul
blt 는 branch if lees than으로
blt rs1,rs2 L1이 있으면 만약 rs1이 rs2보다 작으면 L1으로 가고 그렇지 않으면 Next로 가게된다.
bge는 rs1, rs2 L1이 있으면 만약 rs1이 rs2이 크거나 같으면 L1으로 가고 그렇지 않으면 Next로 가게된다.
bltu,bgeu 는 비교할때 Unsigned 로 비교하는것이다.
6) U-Type Instruction
