
1) Instruction Set Architecture (ISA) 란
컴퓨터가 이해할수있는 언어
ISA는 하드웨어와 소프트웨어의 사이에 있는 interface 라 한다.
Programmer에게 보여지는 Attribute
아직 뭐랄까 느낌은 오는데 정확하게 뭐라고는 설명 못하겠음 ㅎㅎ
크게 RISC 방식과 SISC방식으로 나뉜다고 한다
2) ISA
the attributes of a system as seen by the programmer the conceptual structure(state) and functional behavior(operatrion) 이라고 적혀있는데
컴퓨터는 2개의 state 를 가진다.
1.register
2.memory
그리고 operation 들이 state를 바꾼다.
ISA는 conputer state를 바꾸고 regiter,memory의 state 만 바꾸게 된다.
3) Example : Instructon Set Architecture
RISC 든 SISC 든 일단 기본 방식은 같다고 한다.
6Bit ISA 라고 가정하고 Memory Size는 64B 라 가정한다.
6비트 ISA라는 말은 명령어의 Size 가 6bit 라는 뜻이고
PC는 Program Counter 라는 이름으로 Cpu가 수행해야할 명령어가 저장된 Memory의 주소를 가지는 "Register" 이다.

가장 먼저 register인 Pc의 값을 본다.
pc의 값이 20 이면 memory의 20번쨰 주소를 가서 명령어를 확인한다.
20번주소의 명령어는 lw r1, 1(r0) 이다.
lw는 load word로 word 단위로 load 하겠다는 말이다.
1(r0)는 1은 offset 이고 r0은 register 0 의 값인데 r0의 값인 1과 offset 1을 더해 memory 2번 주소에 있는 값을 r1에 load 해라는 명령어다.
그렇게 되면 r1은 2로 값이 변경되고 pc는 다음 inst를 가리키게 된다.
4) ISA Classification : CISC vs RISC
만약 2:3 번지의 값과 5:2번지의 값을 곱해서 다시 2:3 번지에 store 하는 연산을 하고싶을때의 방식은 두개가 있다
첫번쨰 방법은 CISC 방식으로 소개된 방법인데 실제 memory의 값을 접근해서 곱하는 방식이다.
MULT 2:3, 5:2 라고 소개되어있다
두번쨰 방법은 RISC 방식으로 memory에 직접접근 하지않고 Register 연산후 저장하는 방식이다.
LOAD A, 2:3
LOAD B, 5:2
PROD A, B
STORE 2:3, A
라고 소개되어있는데
위의 방식에서는 메모리에서 2:3과 5:3을 곱해서 다시 2:3에 STORE 한다면
밑으 방식은 2:3에서 값을 A에 LOAD 하고 5:2에서 값을 B에 LOAD 하고 Register A와B를 PROD 한후 A에 넣고 마지막으로 A를 Memory 2:3에 STORE하는 방식이다.
이 두방식은 밑에서 더 자세하게 설명하도록 하겠다.
1)CISC
CISC는 RISC 보다 먼저나온 방식이다.
Intel이 가장 유명하게 사용하고 있는 방식이며
명령어가 복잡하고 길이가 가변적이다
CISC 방식에는 새로운 operation 할수 있는 복잡한 명령어를 만들기에 복잡하고 길이가 가변적일수 밖에없다.
-Backward Compatibility 라는 말이 있는데 CISC 방식은 위에서 말했듯이 새로운 명령어를 기존에 있던것에서 그냥 갖다 붙이기 떄문에 호환성이 좋다고 한다.
장점
어셈블리 프로그래밍을 보다 쉽게 해주고
컴파일러가 simple
메모리 사용이 줄게 된다.
여기서 나는 memory에서 직접적인 연산을 하는데 왜 메모리 사용이 줄었지? 라는 생각을했는데 밑에서 더 자세하게 설명하도록 하겠습니다.
단점
CPU를 design 하기 훨씬 어렵다.
cisc 방식의 특성상 명령어의 명렁도 복잡할뿐만 아니라 길이도 (1~15) 로 가변적이다.
그러기에 구조가 너무 복잡하여 cpu design이 어렵게 된다.
이런 단점들을 해결하기 위해 나온것이 바로 밑에 있는 RISC 방식이다.
2)RISC
RISC는 CISC 방식에서 새로 나온 개념이며
Simple 하고 Standardized instruction 이다.
왜 Standardized instruction 이라면 CISC 는 위에서 말했듯이 길이가 (1~15)로 가변적이다 하지만 RISC 는 길이가 4Byte로 길이가 고정적이다.
그런 이유로 standardized instruction 이라 한다.
Simple 하고 동일된 형태로 하는게 더 좋지않나? 라는 생각으로 나온것이 RISC
장점
길이가 4Byte로 고정적이기에 CPU design이 훨씬 쉽게 된다.
CPU design 이 쉽게된다는 말은 성능을 높이기도 쉽다는 말이 된다.
instruction 이 4Byte로 고정됨으로써 하나의 instrcution 을 수행하는데 더 높은 Clock speed 를 낼수있게 된다.
CISC 에서 한 명령어로 수행할수 있는것을 RISC에서는 4개의 명령어를 사용하여 수행하기 떄문
단점
line의 개수가 늘어남에 따라 IC가 늘어나게된다.
메모리의 사용이 많아진다.
여기도 사실 register에서 연산을 하게 되는데 왜 메모리의 사용이 많아지는지 궁금했는데 밑에서 설명하겠습니다.
5) CISC vs RISC

CISC 방식와 RISC 방식의 차이점에 대해 알아볼텐데
사실 여기 부분은 김명석 교수님 말처럼 외우는것보다 왜 이렇게 되는지 이해하는게 젤 중요하다
cycle per instruction
->
RISC 방식은 가능한 하나의 Cycle에 완료될수 있는 형태가 Simple 하다 (4byte) 로 고정
하지만 CISC 방식은 instruction 당 수행하는 크기가 다르기에 각 instruction 마다 clock cycle 이 당연하게도 다를것이다.
instructions per program
->
RISC 방식은 한 instruction 당 4Byte로 고정되어서 길이가 가변적인 CISC 방식보다 instrcution 의 수가 더 많아질것이다. CISC의 방식은 명령어를 그냥 갖다 붙이기 때문에.
Emphasize for performance
->
한 instruction당 simple 해진 RISC 방식은 한 instruction 을 수행하기에는 CISC 방식보다 더 적은 cycle로 수행을 하게 될것이다.
그렇게 됨으로 CPI 에서는 RISC가 CISC 보다 더 좋다 말할수있다.
하지만 길이를 4Byte로 고정하여 하나의 명령어를 수행하는 CISC와는 달리 RISC는 명령어의 수가 늘어남에있어 IC는 RISC가 CISC 보다 더 높아진다고 볼수있다.
Code Size
->
당연하게 RISC 가 CISC 보다 더 많은 Code size를 가지고있다
Design
->
CISC 는 memory에서만 연산을 하는 방식이라고 소개하였다. 그래서 HardWare-centric 이라 할수있고 Register에서 연산을 하는 RISC 방식은 SoftWare-centric 이라 할수텍스트있다.
Required memory
->
나는 개인적으로 memory에서 직접적인 연산을 하는 CISC 방식이 RISC 방식보다 훨 많은 Memory 사용을 할것이라 예상했는데 실제로는 RISC 가 Memory 사용이 훨 많은것이라 나와있었다.
그래서 나는 왜? 라는 의문을 할수밖에 없었고 그런 부분도 교수님이 너무 잘 설명해 줬다.
RISC 방식의 Inst 들을 고정적인 크기로 나눔에 있어서 inst가 늘어날수 밖에 없었다. 그렇게 각 inst들은 명령어를 가지게 되는데 그 inst가 Memory에 있기 때문에 RISC 방식이 CISC 방식보다 더 많은 memory 사용량을 가지게 되는것이다!
Implemetaiton complexity
->
당연하게 Hardware-centirc인 CISC 방식이 구현하기에 더 어렵다.
# of register
->
memory에서 직접적인 연산을 하는 CISC 보다 RISC가 훨씬 많은 Register들을 가지고 있을수 밖에 없음
Instruction
->
RISC - Smaller number of simple and fixed-length instruction 이라 설명 되어 있는데 태곤이 말처럼 사실 명령어는 더 증가하는데 왜 Smaller 이 되는지 궁금했는데 그게 아니고 한 Instruction 당 4Byte로 고정됨으로써 실행해야할 크기가 줄었기 때문에 위의 말처럼 설명한게 아닌가 싶다.
사실 정확하게 모름 틀렸으면 틀렸다고 댓글 부탁
틀렸음 ㅎㅎ 그냥 RISC 방식에서 쓸수있는 Instruction의 개수가 적은것!
CISC - Larger number of complex and variable length instruction 이라 하는데 이말도 내가 이해한바에 따르면 복잡한 명령어를 하나의 inst로 만들었기에 한 inst를 실행하기에는 RISC 방식보단 더 크지 않나 그래서 위처럼 설명한게 아닌가 싶습니다.....
그럼 CISC 도 그냥 Instruction의 개수가 많은것!!
Pipelining
->
파이프라인이 정확하게 뭔지 아직 안배웠지만
간단하게 설명하자면 RISC는 길이가 고정적임으로 Pipelinig에 더 유리하다...?라고 들음
Power consumption
->
CISC 방식은 하드웨어가 복잡하다 그러기에 전력소모가 더 들게 되고 그에 반대인 RISC 는 전력소모가 적게든다고 볼수있다.
6) Interface Set Architecuture Design Issue
Interface Set Architecutre Design Issue 란 ISA를 설계하는데 생각해야할점들. 이라 생각하려한다.
1. Where are operand stored?
피 연산자들이 어디에 저장되나라는 말인데.
크게 4가지 부분에 저장될수 있다.
Stack,Accumulator,Register-Memory,Register-register
stack과 Accumulator은 잘 사용하지 않고
Register-Memory 에 operand가 담겨있다는 것은 CISC 방식이고
Register-register 방식은 RISC 방식임을 우리는 잘 알고있다.
그래서 첫번쨰. 어디에 피연산자가 저장됨에 따라 ISA를 설계하는데 달라질수있다는것을 말하는것이다.
2. How many explicit operand are there?
피연산자의 개수라는 말이다.
간단한 register instruction인 add 를 보면
add x1 x3 x4 이건 x3의 값과 x4의 값을 더해 x1에 담는 연산이다.
여기를 보면 피연산자가 register가 3개이고
load x1 0(x3)은 0+x3의 메모리 주소의 값을 x1에 담아라는 연산이다.
여기를 보면 피연산자가 memory 1 개 register 2개 이다.
그래서 Register-Register 방식은 피연산자의 개수가 memory는 0개 register 는 3개
Register-Memory 방식은 memory가 1 개 register가 2개이고
memory-memory방식은 memory 2 register 2 , memory 3 register 3 일수도 있는것이다.
3. How is th operand location specified (How to access memory)
어떻게 메모리에 접근하면 좋을까?
뭐,,,이부분은 자세하게는 모르는데 word 단위로 접근한다고 한다.
word란 뭐냐?
word는 data를 처리하는 고정된 size의 기본단위라 한다.
(정해진건 아니고)
그리고 Byte order이 있다.
주소의 가장 높은곳부터 저장할지 낮은곳 부터 할지를 정하는것이다.
가장 높은곳 부터 저장하는 방식을 Big Endian 이라 하고
가장 낮은곳 부터 저장하는 방식을 Little Endian 이라 한다.
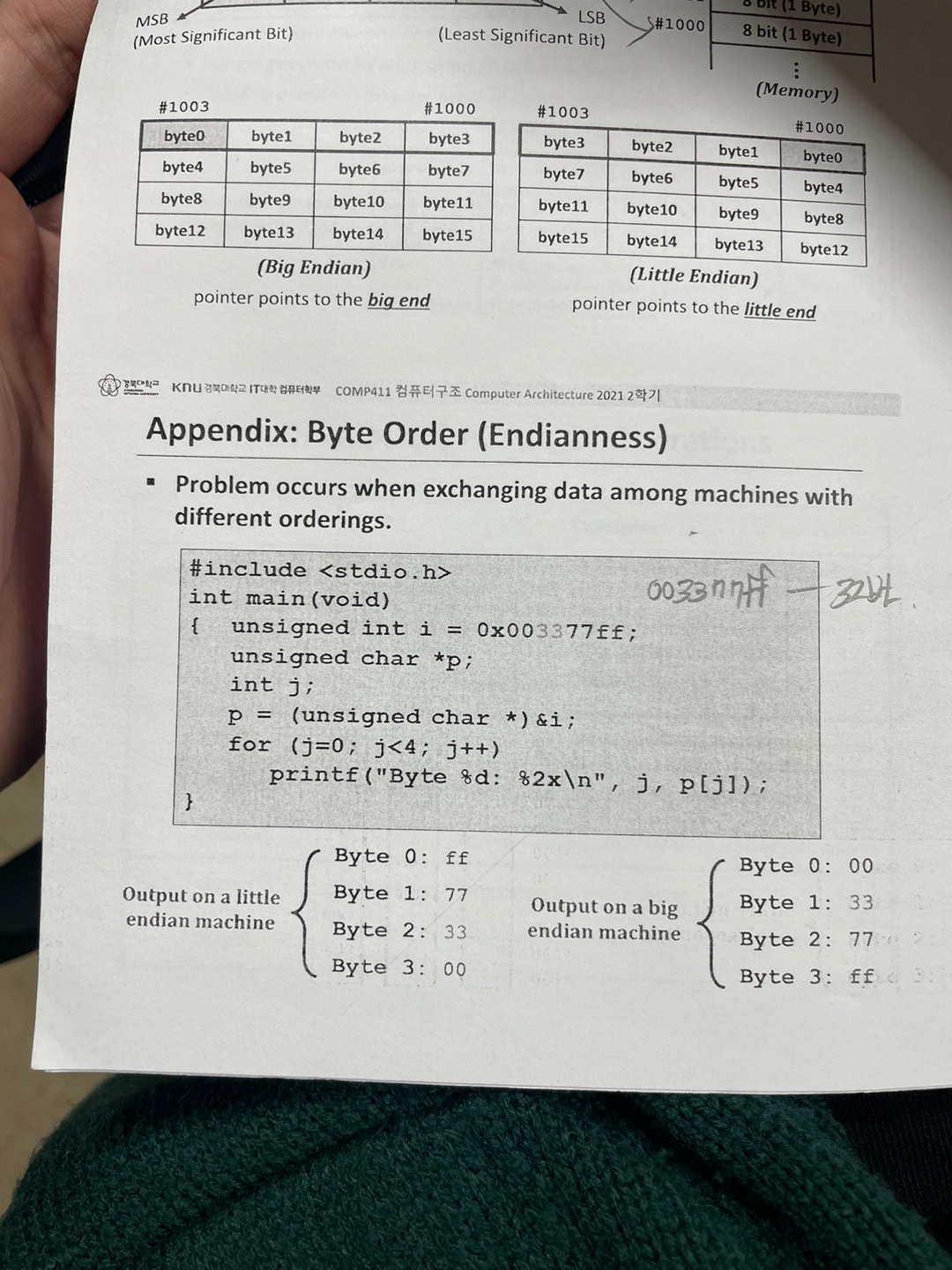
그래서 실제로 littel endian 을 사용한다면 저 코드는 왼쪽처럼 나올것이고
big endian 을 사용한다면 오른쪽 처럼 나오게 될것이다.
보통은 little endian 을 사용한다한다.
옛날에 뭐 모토로라가 big endian 을 썻다는 말은 있다.

접근하는 방식들이다.
위에서 4개만 자주 사용하고 example을 보면 간단하게 무엇을 뜻하는지 알것이다.
4. What type & size of operand are supported?
피연산자들의 크기와 종류이다.
프로그래밍을 한 사람들은 알것이라 가정하고 넘어감
5. what operations are supported?
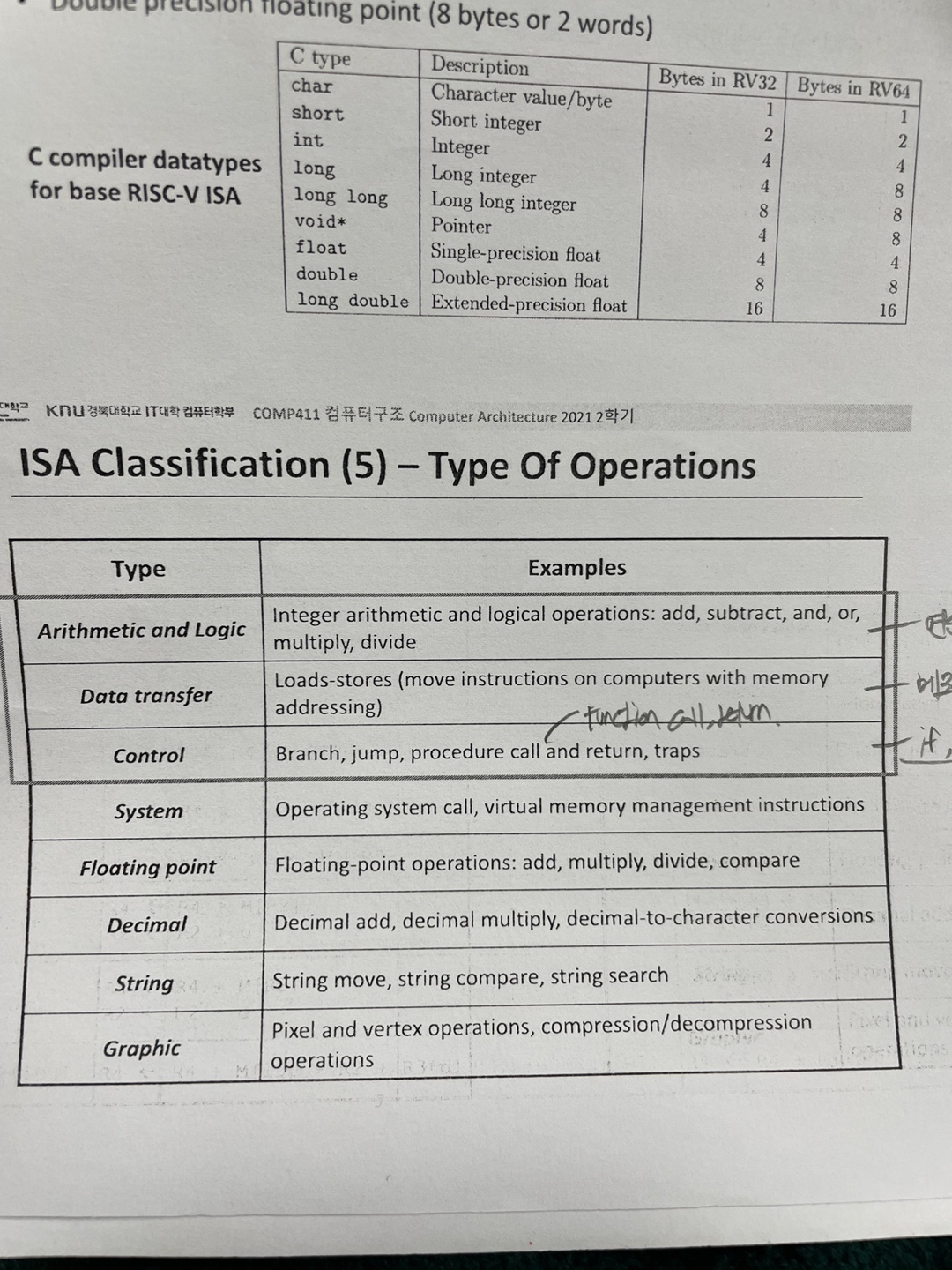
사진에서도 보다시피 많은 type 이 있지만 우리는 위의 3개를 다룰것이다.
Arthimetic and logic
-> 연산자를 뜻한다 add,sub,,,,
Data transfer
-> 메모리 접근
Control
-> 분기문 if while for,,,

