
DB
데이터의 저장소, 데이터의 집합
DBMS
데이터베이스를 운영하고 관리하는 소프트웨어
다양한 데이터가 저장되어 있는 데이터베이스는 여러명의 사용자나 응용 프로그램과 공유하고 동시에 접근이 가능해야한다.
Weak Entity
자체적인 고유 식별자를 가지지 않는 Entity
부모 Entity에 종속적이며, 부모 Entity와의 관계를 통해 의미를 가진다.
부모가 없으면 Weak Entity 또한 존재할 수 없다.
Strong Entity
자체적인 고유 식별자를 가지는 entity 이다.
DB에서 독립적으로 존재할 수 있으며, 다른 Entity와의 관계를 나타낼수 있다.
Relation
2차원 표를 이용해서 데이터 상호 관계를 정의하는 데이터베이스
Entity 와 RelationShip을 모두 Relation이라는 표로 표현하기 때문에 ENtity를 Entity Relation과 Relationship Relation 이 존재하다.
Tuple
Relation 을 구성하는 각각의 행을 말하며 속성의 모임.
파일 구조에서 Record 와 같은 의미
Tuple 의 수를 Cardinality , 또는 기수라고 한다.
Attribute
테이터베이스를 구성하는 가장 작은 논리적 단위이며 개체의 특성을 기술한다. 파일 구조상의 데이터 항목 또는 데이터필드에 해당한다. 속성의 수를 Degree or 차수 라고 부른다.
Domain
하나의 Attribute가 취할 수 있는 같은 Type 의 원자들의 집합이다. 도메인은 실제 속성값이 나타낼때 그 값의 합법 여부를 시스템이 검사하는데도 이용
Schema
데이터베이스의 구조와 제약조건에 관한 전반적인 명세를 기술.
데이터베이스를 구성하는 Entity,Attribute,Relationship 및 데이터 조작시 데이터 값들이 갖는 제약조건 등에 관한 전반적이 내용을 정의한다.
Schema 의 3계층
External Schema
서브 스키마 즉 사용자 뷰이다.
사용자나 응용 프로그래머가 각 개인의 입장에서 필요로 하는 데이타베이스의 논리적 구조를 정의한다.
Conceptual Schema
전체적인 뷰이다.
개채 간의 관계와 제약조건을 나타내고 데이터베이스의 접근 권한,보안 및 무결성 규칙에 관한 명세를 정의한다.
Internal Schema
내부 스키마이다.
실제로 데이터베이스에 저장될 Record의 물리적인 구조를 정의하고 저장 데이터 항목의 표현 방법,내부 Record의 물리적 순서를 나타낸다.
Data Independence
Centralized 된 DBMS에 부분적으로 Data Schema 를 수정하고자 할 때 어떤 식으로 나눌지에 대해서 정의한다.
Logical Data Independence
논리적인 부분 만을 수정한다. Schema 에서 논리적인 부분을 conceptual 부분을 의미하고 External Schema 의 수정 없이 conceptual 부분만 수정하는 걸 의미한다.
Physical Data Independence
External,Conceptual schema 를 제외한 채 Internal 부분만을 수정하는 것을 의미
DB의 Performance를 높이기 위해서 일부 데이터 값의 구조를 변경할수는 있지만 전반적인 DB의 구조를 바꾸지는 않는다.
DDL
Data Definition Language 로 데이터 정의어 이다.
Table과 같은 Data 구조를 정의하는데 사용디ㅗ는 명령어들로 데이터 구조와 관련된 명령어들을 말한다.CREATE,ALTER,DROP,RENAME,TRUNCATE
DML
Data Manipulation Language 로 데이터 조작어 이다.
데이터베이스에 들어있는 데이터를 조회하거나 변형을 가하는 종류이다.
SELECT,INSERT,UPDATE,DELETE
DCL
Data Control Language 로 데이터 제어어 이다.
데이터베이스에 접근하고 객체들을 사용하도록 권한을 주고 회수하는 명령어들을 말한다.
GRANT,REVOKE
Declarative
SQL은 어떤 데이터를 가지고 올지 구체적으로 명시한다는 특징을 가진다.
Key
DB에서 조건에 만족하는 Tuple을 찾거나 순서대로 정렬할때 다른 Tuple 과 구별할 수 있는 유일한 기준이 되는 Attribute
Candidate Key
후보키 중에서 선택한 주키
한 Relation 에서 특정 Tuple을 유일하게 구별할 수 있는 속성
Alternate Key
후보키가 둘 이상일때 기본키를 제외한 나머지 후보키들을 말한다.
Super Key
한 Relation 내에 있는 속성들의 집합으로 구성된 키
Relation을 구성하는 모든 Tuple에 대해 유일성은 만족하지만, 최소성은 만족시키지 못한다.
ForeignKey
참조되는 Relation의 기본키와 대응되어 Relation 간에 참조 관계를 표현하는데 중요한 도구
Integrity Constraint
DB의 정확성,일관성을 보장하기 위해 저장,삭제,수정 등을 제약하기 위한 조건
1.개체 무결성
각 Relation 의 기본키를구성하는 속성은 NULL 이 되어서는 안된다.
2.참조 무결성
외래키 값은 NULL이거나 참조하는 Relation의 기본키 값과 동일해야함
3.도메인 무결성
속성들의 값은 정의된 도메인에 속한 값이어야한다.
ex)성별에는 남,여 말고 다른 데이터가 들어가서는 안된다.
4.고유 무결성
특정 속성에 대해 고유한 값을 가지도록 조건이 주어진 경우,Relation의 각 Tuple 이 가지는 속성 값들은 서로 달라야한다.
5.NULL 무결성
Relation의 특정 속성값은 NULL이 될수 없다.
6.키 무결성
각 Relation은 최소 한개 이상의 KEy가 존재해야한다.
ERD
Entity Relationship diagram: 테이블간의 관계를 설명해주는 다이어그램이며, 이를 통해 프로젝트에서 사용되는 DB의 구조를 한눈에 파악할 수 있다.
Anomaly(이상현상)
Anomaly가 DB에 존재하면 그 DB에는 Date의 Integrity이 보장되지 못한다.
Deletion Anomaly
어떤 값을 삭제하기 위해 Tuple 을 삭제하게 되면 해당 Tuple 안에 있는 모든 정보가 함께 삭제되기 때문에 발생하는 문제.
Insertion Anomaly
새로운 Tuple을 삽입할 때, 특정 속성의 값이 존재하지 않아 불필요하게 null을 삽입하면서 발생하는 문제.
Update Anomaly
어떤 정보를 Update 할때, 그에 대응되는 모든 정보를 모두 함께 Update 해야 하기 때문에 발생하는 문제,
Functional Dependency(함수적 종속)
어떤 X가 Y를 함수적을 ㅗ결정할 때 , X를 결정자,Y를 종속자 라고 할수있고 X-> Y로 나타낼수 있따.
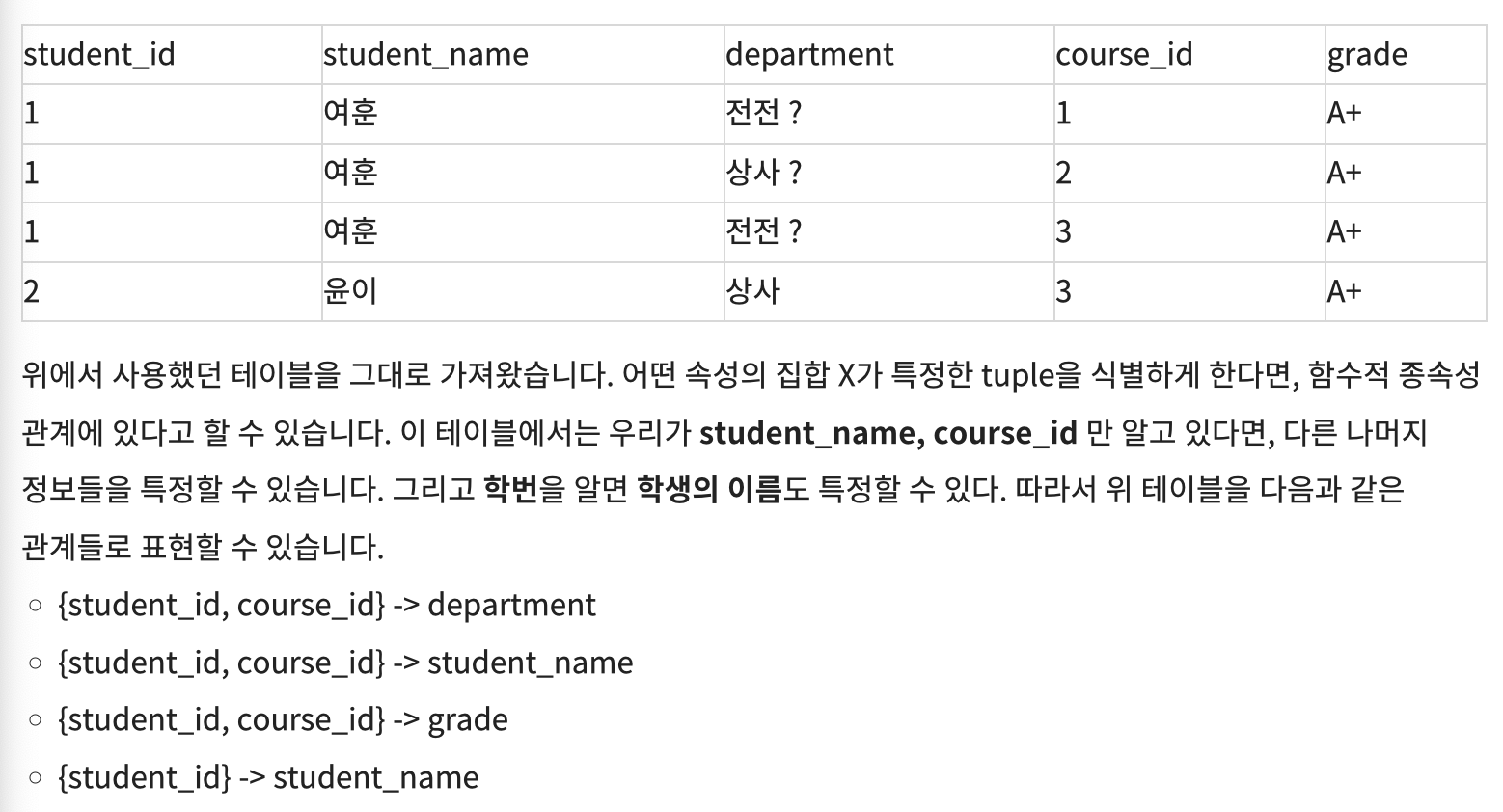
Partial Functional Depedency(부분적 함수적 종속)
함수적 종속성을 만드는 속성의 집합 중 일부가 함수적 종속성을 가지는 것을 의미한다.
정규화(Normalization)
정규화의 기본 목표는 Table 간에 중복된 Data 들을 허용하지 않는 다는 것.
Integrity 를 유지할수 있고 DB의 저장 용량 역시 줄일 수 있다.
제 1 정규화
Table 의 column이 원자값을 갖도록 Table 을 분해하는것.
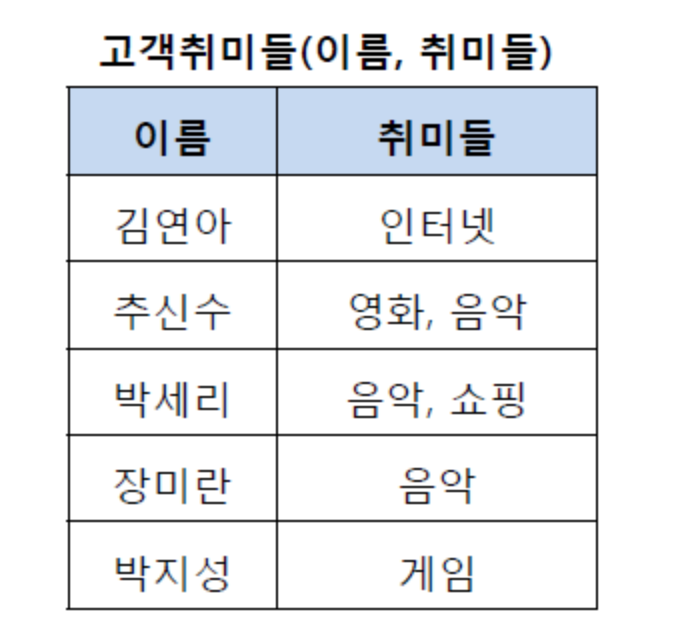
추신수와 박세리가 여러개의 취미를 가지고 있어서 제 1 정규형을 만족하지 못함
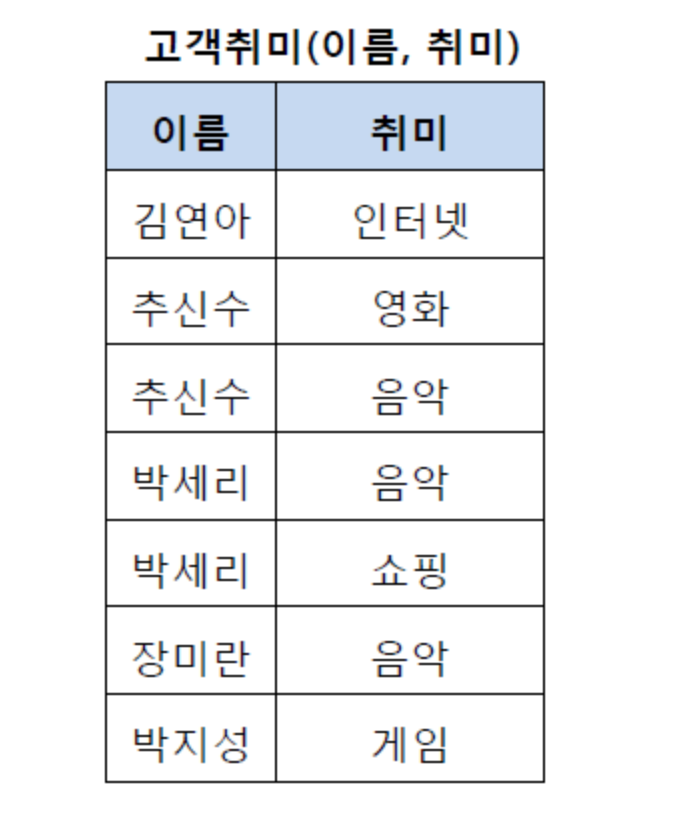
제 2 정규화
제 1 정규화를 진행한 Table에 대해 완전 함수 종속을 만족하도록 Table을 분해하는것.
완전 함수 종속이라는 것은 기본키의 부분집합이 결정자가 되어서는 안된다는 것을 의미
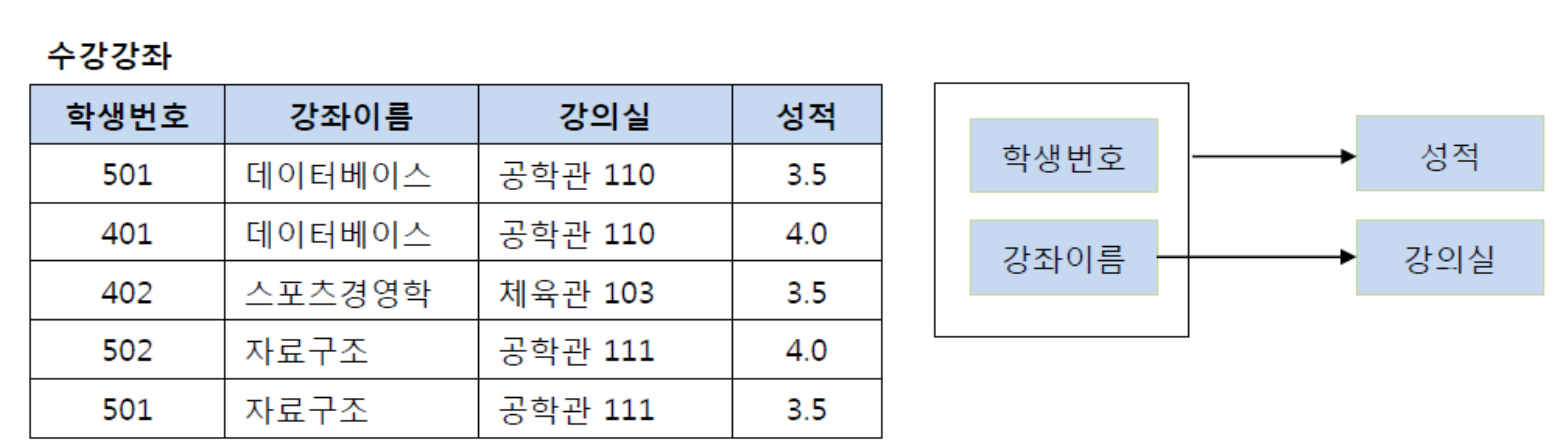
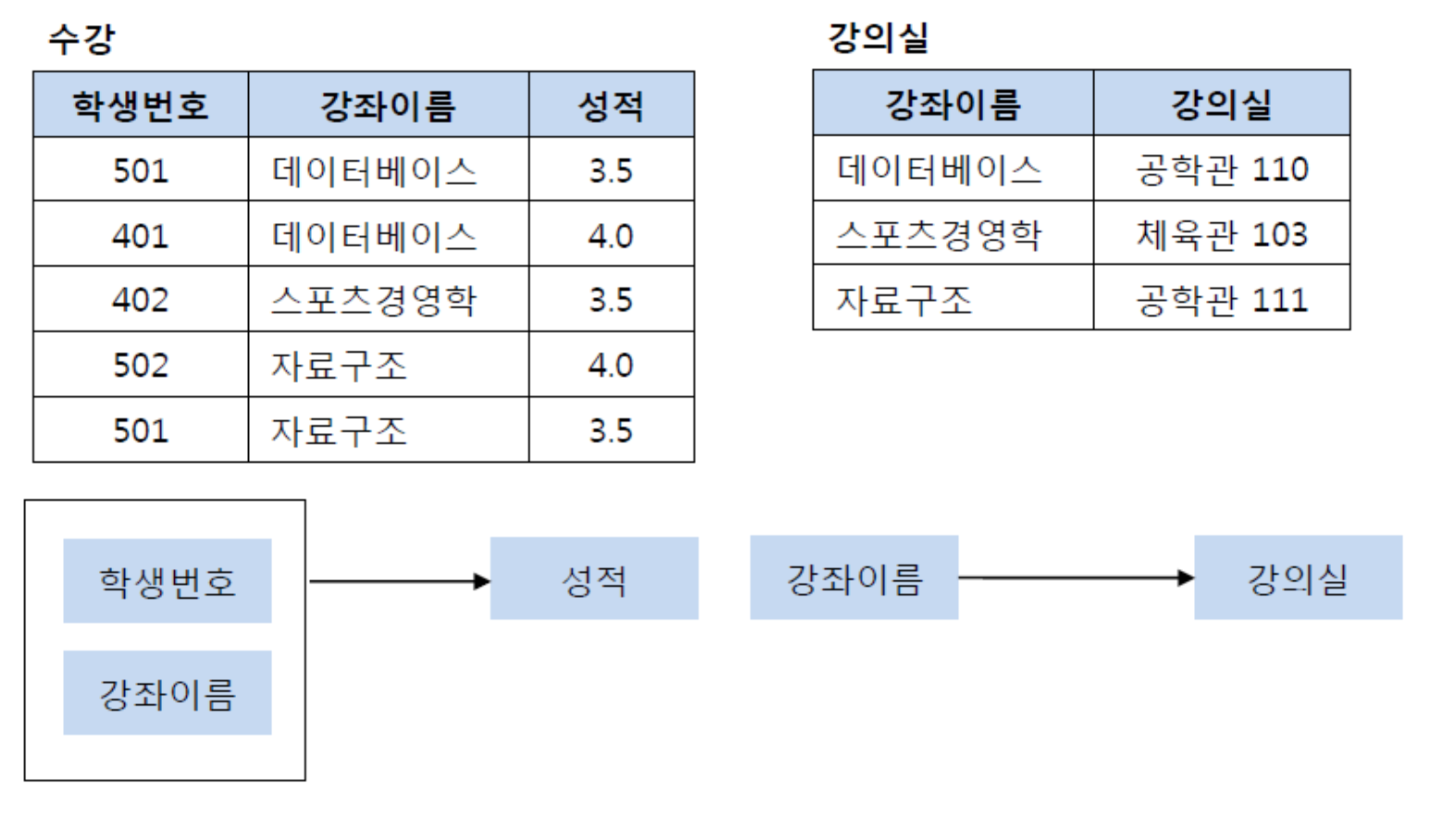
여기서 기본키는 학생번호,강좌이름이라고 한다.그리고 (학생번호,강좌이름)인 기본키가 성적을 결정한다고 한다.
근데 강의실이라는 Column은 기본키의 부분집합인 강좌이름에 의해 결정될수 있다. 강좌이름 -> 강의실
즉 기본키의 부분키인 강좌이름이 결정자이기 떄문에 위의 테이블에서 강의실을 분해하여 별도의 테이블을 관리해서 제 2정규형을 만족시킬수 있다.
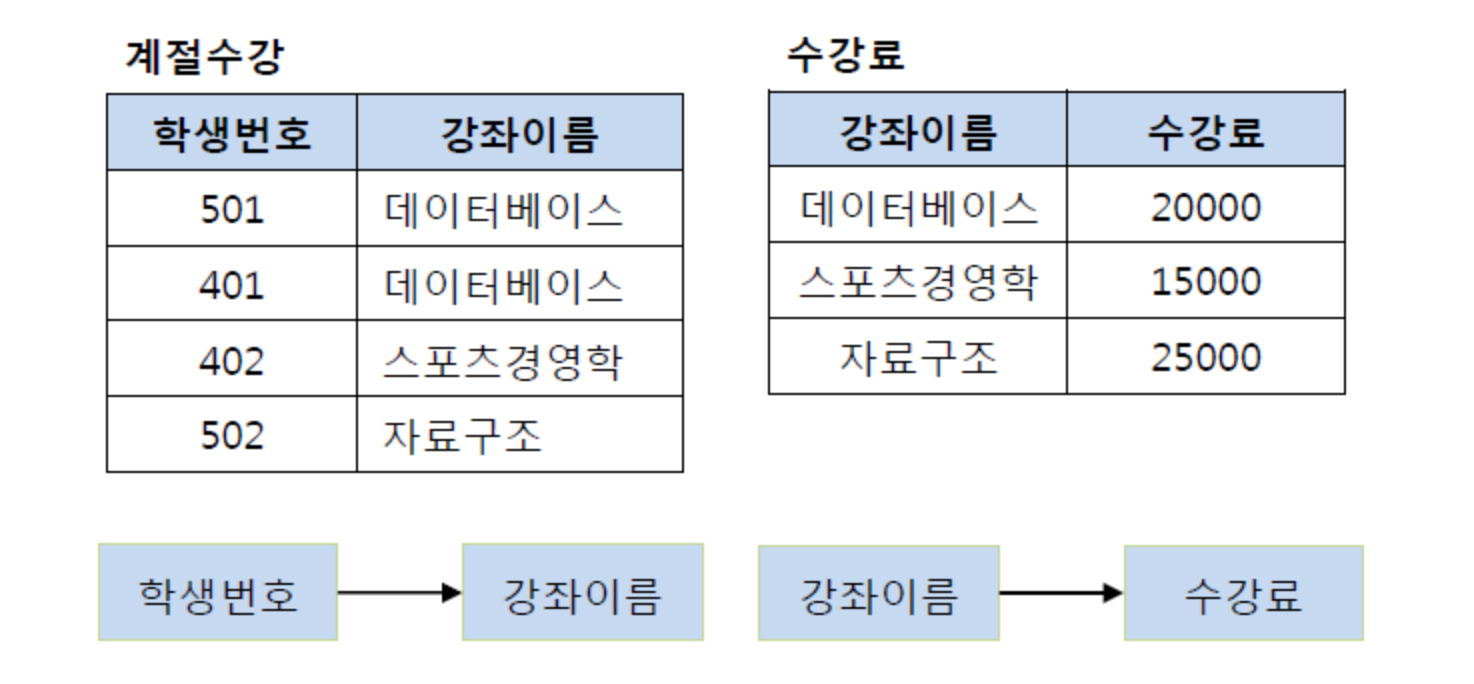
제 3 정규화
제 3 정규화는 제 2 정규화를 진행한 Table에 대해 이행적 종속을 없애도록 Table을 분해 하는것. 이행적 종속이라는 것은 A->B,B->C 가 성립할때 A->C가 성립되는 것을 의미한다.

기존의 Table 에서 학생 번호는 강좌 이름을 결정하고 강좌 이름은 수강료를 결정한다. 그래서 (학생번호 강좌이름), (강좌이름,수강료) 로 분해해야한다.
BCNF 정규화
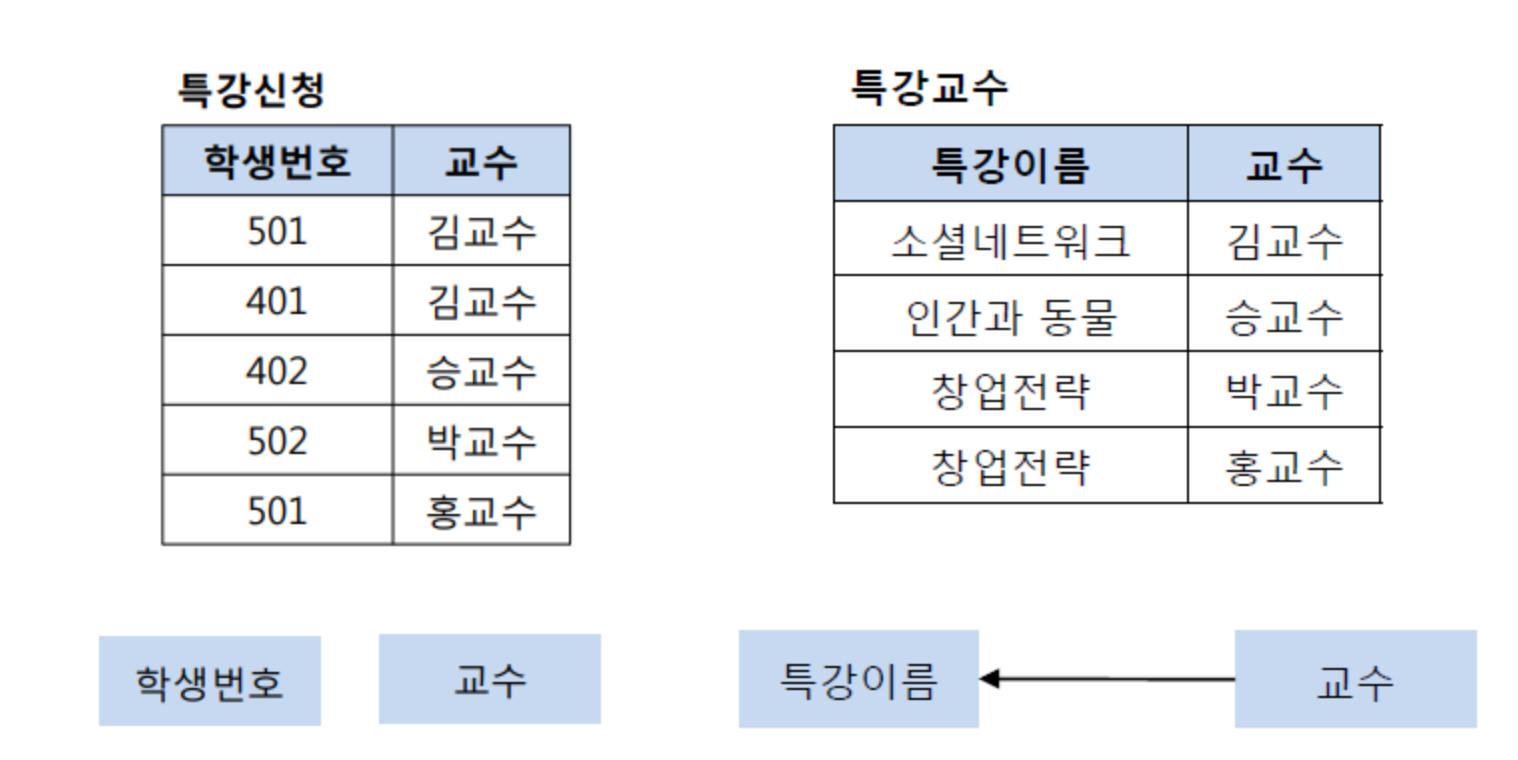
제 3 정규화를 진행한 Table 에 대해 모든 결정자가 후보키가 되도록 Table 을 분해하는것.
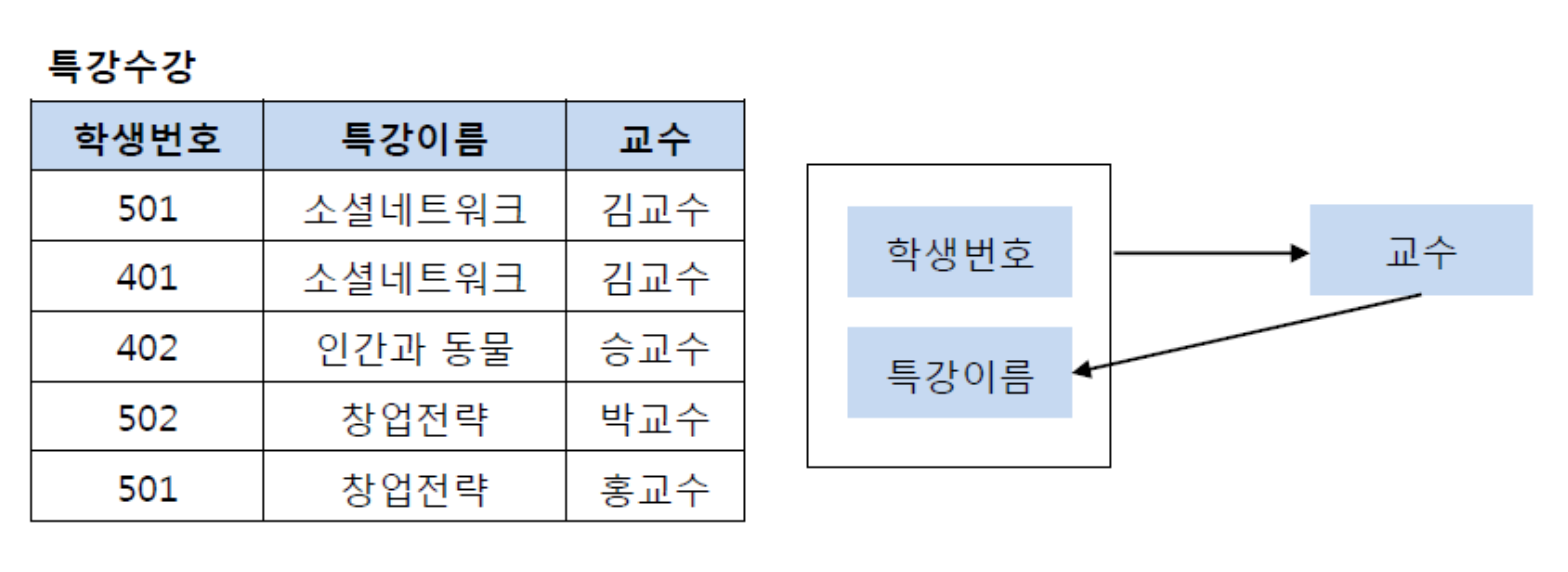
여기서 기본키는 (학생번호,특강이름) 이다. 그리고 기본키가 교수를 결정하고있다. 근데 교수가 특강이름을 결정하고 있음.
여기서 교수가 특강이름을 결정하는 결정자 이지만 후보키가 아니다.그래서 BCNF 정규화를 위해서 분해해야한다.
비정규화(Denormalization)
의도적으로 정규화를 위배하여 성능과 편의성을 증가시키는 과정
JOIN비용이 줄고 쿼리가 간단해지므로, 조회 성능은 증가할 수 있다.
테이블 사이즈가 증가하므로 삽입이나 갱신 비용이 증가할 수 있으며, 일관성과 정합성이 저하될 수 있다.
Transaction
데이터베이스의 상태를 변화시키기 위해 일련의 작업을 수행하는 논리적인 단위
DB의 상태를 변화시킨다는 말은 DML 을 사용한다는 것을 의미.
각각의 Transaction 은 상황에 따라 Commit , Rollback 될수 있다.
Commit 은 모든 부분작업이 정상적으로 완료되면 이 변경사항을 DB에 반영
Rollback 은 부분 작업이 실패하면 Transaction 실행 전으로 되돌린다.
Transaction 의 특징
- Atomicity - 원자성
Transaction의 작업이 부분적으로 실행되거나 중단되지 않는 것을 보장한다.
- Constency - 일관정
Transaction 의 작업 처리 결과는 항상 일관성이 있어야 한다.
- Isolation - 격리성,고립성
Transaction 수행 시 다른 Transaction의 작업이 끼어들지 못하도록 보장해야한다.
- Durability - 지속성,영속성
성공적으로 수행된 Transaction 은 영원히 반영되어야 한다.
Phantom Read
다른 트랜잭션에서 수행한 변경 작업에 의해 레코드가 보였다가 안보였다가 하는 현상
→ 트랜잭션1이 A테이블에서 SELECT한 이후 트랜잭션2에서 A테이블에 내용을 추가/삭제(INSERT/UPDATE)하는 상황
Non-repeatable read
하나의 트랜잭션안에서 같은 쿼리를 두 번 실행하여 레코드를 조회했을 때, 다른 값이 나오는 현상
→ 트랜잭션1에서 A테이블을 SELECT 한 후 트랜잭션2에서 A테이블 내용을 변경(UPDATE)하는 상황
Dirty read
커밋되지 않은 상태에서 값을 읽음으로 인해 데이터의 정합성이 깨지는 현상
→ 트랜잭션1에서 A테이블을 SELECT 한 후 트랜잭션2에서 A테이블 내용을 변경하는 상황 가정
→ 트랜잭션2가 해당 변경사항을 commit 하지도 않았는데, 트랜잭션1에서 다시 A테이블을 SELECT하면 해당 변경사항을 읽어들일 수 있게됨
Isolation level
READ_UNCOMMITTED (Lv. 0): 다른 트랜잭션이 커밋하지 않은 데이터를 조회할 수 있다.
Dirty read 발생
READ_COMMITTED (Lv. 1): 다른 트랜잭션이 커밋한 데이터만 조회할 수 있지만, 다른 트랜잭션이 접근한 행을 수정할 수 있다.
조회시에 테이블로부터 값을 가져오는 것이 아닌, UNDO 영역으로 부터 값을 가지고 온다.
Non-repeatable read 발생
REPEATABLE_READ (Lv. 2): 트랜잭션이 시작되기 전에 커밋된 내용에 대해서만 조회할 수 있다.
자신의 트랜잭션 번호보다 낮은 트랜잭션 번호에서 커밋된 데이터만 조회한다.
UNDO 공간에 백업 데이터를 조회: MVCC (Multi Version Concurrency Control)
해당 범위에 새로운 레코드가 추가 되거나 삭제될 수 있으므로, Phantom read 발생
SERIALIZABLE (Lv. 3): 하나의 트랜잭션이 작업중인 테이블의 모든 레코드를 다른 트랜잭션이 접근할 수 없다.
UNDO 영역
데이터베이스 시스템에서 트랜잭션의 변경 사항을 일시적으로 보관하고 이전 상태로 되돌리기 위해 제공되는 공간
REDO
문제가 발생한 뒤에 커밋된 트랜잭션이 수정한 내용을 재반영하는 복구 작업
FORCE: 수정했던 모든 페이지를 Transaction commit 시점에 disk에 반영
→ transaction이 commit 되었을 때 수정된 페이지들이 disk 상에 반영되므로 redo 필요가 없다.
Non-FORCE: commit 시점에 반영하지 않는 정책
→ 일괄적으로 디스크에 기록함으로써 메모리 사용을 최적화
Connection pool
여러 데이터베이스 연결을 미리 생성하여 풀에 저장해두고, 요청이 들어올 때마다 해당 풀에서 사용 가능한 연결을 꺼내서 사용하고 작업을 완료하면 다시 풀에 반환하는 방식으로 동작
→ Spring boot HikariCP
Redis
NoSQL의 일종으로, 메모리에 데이터를 저장하여 매우 빠른 읽기, 쓰기 속도를 제공하는 인메모리 데이터베이스
RAM의 특징인 휘발성을 막기 위한 백업 과정이 존재한다.
snapshot: 특정 지점을 설정하고 디스크에 백업
AOF(Append Only File): 쿼리들을 저장해두고, 서버가 셧다운되면 재실행해서 다시 만들어 놓는 것
RDB
장점: 스키마에 맞춰 데이터를 관리하기 때문에 데이터의 정합성을 보장할 수 있다.
단점: 시스템이 커질 수록 쿼리가 복잡해지고 성능이 저하되며 Scale-out이 어렵다(Scale-up만 가능)
ACID Transaction 기능을 제공하므로, 속도보다 정확성이 우선시 될 때 사용한다.
NoSQL
장점: 스키마 없이 Key-Value 형태로 데이터를 관리해 자유롭게 데이터를 관리할 수 있다.
데이터 분산이 용이하여 성능 향상을 위한 scale-up 뿐만아닌 scale-out 또한 가능하다.
단점: 데이터 중복이 발생할 수 있고, 중복된 데이터가 변경될 경우 수정을 모든 컬렉션에서 수행해야 한다.
스키마가 존재하지 않기에 명확한 데이터 구조를 보장하지 않아 데이터 구조 결정이 어려울 수 있다.
JOIN
관계형 데이터베이스에서 두 개 이상의 테이블을 연결하여 필요한 정보를 결합하는 것
INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN, CROSS JOIN, SELF JOIN
Nested loop join
조인할 때, Outer table에서 조인 키 값을 들고 Inner table을 탐색하며 마치 중첩된 반복문과 유사한 형태로 동작하는 조인 기법으로 Inner table의 index 설정이 잘 되있어야 성능에 유리하다.
BNL, Blocked Nested loop: 블록 단위로 나눠서 조인
Index
추가적인 쓰기 작업과 저장 공간을 활용하여 DB Table에 저장된 Data의 검색속도를 향상시키기 위한 자료구조.
DB 내의 특정 Column 이나 조합에 대한 값과 해당 값이 저장된 Record의 위치를 mapping 하여 DB Query의 성능을 최적화하는데 중요한 역할을 한다.
Clustered index
레코드를 해당 열로 정렬 (물리적 재배열)한 후에 데이터 페이지(=leaf page)를 생성한다.
→ 데이터 사본이 없다.
데이터의 추가, 삭제, 수정에도 정렬을 유지해야하므로 DML 과정이 빈번하면 비효율적일 수 있다.
Primary Index는 primary key를 인덱스로 사용하며, Primary Key를 설정하면 해당 키에 대해 Clustered Index가 자동으로 생성된다.
Secondary Index는 기본 키 이외의 다른 열에 대한 인덱스로, 보조적인 검색을 위해 사용
Non-clustered index
레코드의 원본이 정렬되지 않고, 인덱스 페이지만 정렬된다.
→ 별도의 장소에 인덱스 페이지 생성 (인덱스 페이지의 리프 페이지) → index로 구성한 열 기준으로 정렬
원본이 수정되지 않아 DML 작업이 빠르지만, 탐색이 느리다. (최대 240개)
B-Tree
데이터베이스에서 인덱스를 구성할 때 사용되는 자료구조 중 하나로, 하나의 노드가 여래개의 자식을 가질 수 있으며 데이터가 정렬된 균형있는 상태로 유지된다.
루프 노드, 브랜치 노드, 리프 노드로 구성되어 있으며, 브랜치 노드 및 리프노드에 데이터를 담을 수 있다.
B+Tree
자식 노드가 2개 이상인 B-Tree를 개선시킨 자료구조이며,
BTree 리프노드들을 LinkedList로 연결하여 순차 검색을 용이하게 한다.
기존의 B-Tree는 하나의 데이터 탐색을 위해서는 적합했지만 여러개 또는 모든 데이터를 탐색하기 위해서는 루트노드부터 브랜치 노드를 거쳐 리프노드까지 모든 노드를 방문해야 한다는 단점을 가지고 있다.
리프 노드를 제외하고 데이터를 담아두지 않기 때문에 메모리를 더 확보함으로써 더 많은 key들을 수용할 수 있다. 하나의 노드에 더 많은 key들을 담을 수 있기에 트리의 높이는 더 낮아진다.(cache hit를 높일 수 있음)
풀 스캔 시, B+tree는 리프 노드에 데이터가 모두 있기 때문에 한 번의 선형탐색만 하면 되기 때문에 B-tree에 비해 빠르다.
InnoDB
대용량에 적합한 MySQL 데이터베이스 엔진
MyISAM
적은 디스크 공간을 사용하며, 메모리와 디스크 I/O를 최소화하는데 중점을 둔 MySQL 데이터베이스 엔진
Wiredtiger
고성능 데이터베이스 엔진으로, MongoDB, SQLite 데이터베이스 엔진으로 사용된다.
LSM(Log-Structured Merge Tree)를 사용하여 읽기 성능을 포기하고 쓰기 (저장) 성능을 향상시켰다.
→ 블룸 필터: 느린 읽기 성능을 보완
저널링
데이터 변경에 대한 사항을 로깅하여 체크포인트와 함께 사용되어 오류 발생시에도 데이터를 재생산할 수 있다.
데이터베이스 데드락
격리 수준 변경, 서비스 로직 수정, Wait-die / Wound-die 사용
Wait-Die: 트랜잭션 B가 선점하고 있는 데이터를 A가 요청할 때, A가 먼저 들어온 트랜잭션일 경우 wait(대기) / A가 나중에 들어온 트랜잭션일 경우 die(포기)
Wound-Die: 트랜잭션 B가 선점하고 있는 데이터를 A가 요청할 때, A가 먼저 들어온 트랜잭션일 경우 Wound(선점) / A가 나중에 들어온 트랜잭션일 경우 die(포기)
SQL Injection
공격자가 악의적인 의도를 갖는 SQL 구문을 삽입하여 데이터베이스를 비정상적으로 조작하는 코드 인젝션 공격 기법
→ 인증 우회, 데이터 노출
→ 검증 로직 추가, preparestatement 사용 (쿼리와 데이터 분리)
Stored procedure
데이터베이스에서 미리 정의된 SQL 쿼리와 제어 문을 묶어 일련의 작업을 수행하는 데 사용되는 프로그래밍적인 기능
프로시저 장점
편의성: 반복적인 여러줄의 SQL 작업을 stored procedure를 통해 한번에 처리
캐시: 프로시저를 한번 실행해두면 같은 작업에 대해 캐싱이 된다.
트래픽 감소: 클라이언트에서 직접 SQL문을 작성하지 않고 프로시저명에 매개변수만 담아 보내기 때문에 트래픽이 감소한다.
에러가 발생했을 때, 디버깅 과정이 힘들 수 있다.
DBMS 구조
Stored system & Query processor로 구성
56. Buffer manager
Stored system 내에 page buffer (main memory) 영역을 관리하는 모듈로, Block (Page) 단위로 디스크로부터 데이터를 읽어오거나 쓰며, 버퍼를 관리한다.
Spanned records
레코드의 크기가 하나의 블록 또는 공간에 맞지 않아 여러 개의 블록 또는 공간에 걸쳐 저장되어야 하는 상황으로 포인터를 사용하여 다음 Block을 가리킨다.
Unspanned records: 레코드의 크기가 하나의 블록에 완전히 저장될 수 있는 경우
Blocking factor
블락당 수용할 수 있는 레코드 갯수
File of unordered records
Heap files, sorted files
Check point
로그 파일에 체크포인트를 기록하고, 장애 발생 시 Check point 이전에 처리된 트랜잭션은 회복 작업에서 제외하고 이후에 처리된 내용에 대해서만 회복 작업을 수행하는 회복 기법
→ 회복 과정에서 너무 많이 되돌아가지 않도록 하는 목적
Vertical partitioning
데이터를 열 단위로 분할하여 관리하는 것
사용 이유
자주 사용되지 않는 열 별도로 관리
자주 사용되는 속성들을 모은 테이블을 만들기 위해
민감한 정보에 접근을 제한
Horizontal paritioning
테이블을 행 단위로 분할하여 관리하는 것
특정 기준, 그룹 별로 관리함으로써 검색 속도를 향상시킬 수 있다.
Sharding
Horizontal partitioning으로 나눠진 파티션을 독립된 서버에 저장하는 방식
같은 서버에서 테이블이 나눠진 Horizontal Partitioning 에서는 서버에 트래픽이 몰려올 때 부담을 갖게되므로, 서버를 나눠서 저장한 샤딩 방법에서는 트래픽을 분산시키는 효과를 볼 수 있다.
Replication
여러 개의 복사 DB를 권한에 따라 수직적인 구조로 구축하는 방식
DB 요청의 60~80% 정도가 읽기 작업이기 때문에 Replication만으로도 충분히 성능을 높일 수 있다.
비동기 방식으로 운영되어 지연 시간이 거의 없다.
노드들 간 데이터 동기화가 보장되지 않아 일관성있는 데이터를 얻지 못할 수 있다.
Master-slave(replica) 구조
Clustering
여러 개의 DB를 수평적인 구조로 분산하는 방식으로, DB 간의 데이터를 동기화하여 항상 일관성있는 데이터를 얻을 수 있다.
1개의 DB가 죽어도 다른 DB가 살아 있어 시스템을 장애없이 운영할 수 있다. (높은 가용성)
기존에 하나의 DB서버에 몰리던 부하를 여러 곳으로 분산시킬 수 있다. (로드밸런싱)
저장소 하나를 공유하면 병목현상이 발생할 수 있다.
Unique
Unique 키는 유일성을 가지기 위해 설정해 놓은 키
→ Primary 키는 오직 하나만 생성할 수 있지만, Unique키는 여러개 생성이 가능하며, NULL 값을 허용
Trigger
특정 Table에 insert,delete,update,같은 DML 이 수행되었을때 DB 에서 자동으로 동작하게 작성된 Program
EX) 주문정보테이블에 실시간으로 데이터가 입력될 때마다 트리거가 발동되어 자동으로 일자별판매집계테이블에 일자별, 상품별 판매수량과 판매금액을 계산해 업데이트 하는 작업을 하도록 하고, 사용자들은 미리 계산된 일자별판매집계테이블을 조회하게 하여 실시간 조회를 지원하게 하는 것
해시 테이블
컬럼의 값으로 생성된 해시를 기반으로 인덱스를 구현하며, O(1) 시간복잡도를 가진다.
부등호(<,>)와 같은 연속적인 데이터를 위한 순차 검색이 불가능하기 때문에 사용에 적합하지 않다.
DB Lock
데이터베이스에서 동시에 여러 트랜잭션이 데이터를 접근하고 변경하는 것을 제어하기 위한 메커니즘
→ 격리 수준을 유지하고 구현하는 데 사용되는 실제적인 메커니즘
공유락(LS, Shared Lock): Read Lock라고도 하는 공유락은 트랜잭션이 읽기를 할 때 사용하는 락
→ 데이터를 읽기만하기 때문에 같은 공유락 끼리는 동시에 접근이 가능
베타락(LX, Exclusive Lock): Write Lock라고도 하는 베타락은 데이터를 변경할 때 사용하는 락
→ 트랜잭션이 완료될 때까지 유지되며, 베타락이 끝나기 전까지 어떠한 접근도 허용하지 않는다.
Elastic search
동의어나 유의어를 활용한 검색이 가능하며, 비정형 데이터의 색인과 검색이 가능하고, 역색인 지원으로 매우 빠른 검색이 가능
Optimizer
DBMS 의 핵심 엔진. DBMS 의 두뇌는 옵티마이저 이다.
옵티마이저는 SQL을 가장 빠르고 효율적으로 수행할 최적의 처리 경로를 생성해주는 DBMS 내부의 핵심 엔진
규칙 기반 옵티마이저: 미리 정해진 규칙대로 실행 계획을 세운다.
→ 유동성↓
비용 기반 옵티마이저: 처리하는데 예상되는 소요시간, 자원 사용량 등을 고려해서 실행 계획을 세운다.
Database dictionary (Catalog)
데이터베이스 전반적인 데이터 항목들에 대한 정보를 저장한다.
→ 사용자 정보, 데이터베이스 스키마 정보, 무결성 제약조건에 관한 정보 등이 저장된다.
