IP
IP가 필요한 이유는 결국 주소임.
내가 친구의 주소를 모른다면 어떻게 정보 전달을 할수 있나?
전 세계적으로 보면 한국 인터넷 주소 체계와 미국의 인터넷 주소 체계가 같기 때문에 전세계 통신이 가능하다.
UCP,UDP,HTTP
IP 주소를 이용해 Network가 이뤄지며 정보를 주고 받을때 필요한 network 규약들이다.
TCP vs UDP
Tcp 는 Transmission Control Protocl 이다. 데이터를 중요하게 생각하여서 확실하게 주고받을떄는 TCP 를 사용한다. TCP 를 사용해서 통신한다면 보내고 받는다는 메세지를 주고 받은 후에 데이터를 주고 받기 떄문에 신뢰성이 높아진다.
웹이나 메일 파일 공유 등과 같이 데이터를 누락시키지 않은 서비스는 TCP 를 사용한다.
UDP는 User Datagram Protocl 로 어찌됐든 신뢰성은 제처두고 빨리 보내고 싶을때 사용한다. UDP 는 데이터를 보내면 그것으로 끝이기 때문에 신뢰성은 없지만 확인 응답과 같은 절차를 생략할수있으므로 통신의 신속성을 높인다.
VOIP,시간동기,이름 해결과 같이 속도를 필요로 하는 서비스는 UDP 를 사용한다.
Throughput,Delay,Loss
인터넷의 빠르기를 평가하는 요소이다.
Throughput 은 목적지 까지 단위시간동안 배달한 Traffic의 양이다.
Packet Loss 는 Queue 의 사이즈는 한정되어 있어서 Queue에 남은 공간이 없을떄 Loss가 발생한다.
Delay 는 다음 node 로 완전히 전송될 떄 까지 걸리는 시간.
Direct Links vs Indirect Links
Direct Links 는 Node 와 Node 사이 Link 빼고는 없는 연결 방식이다.
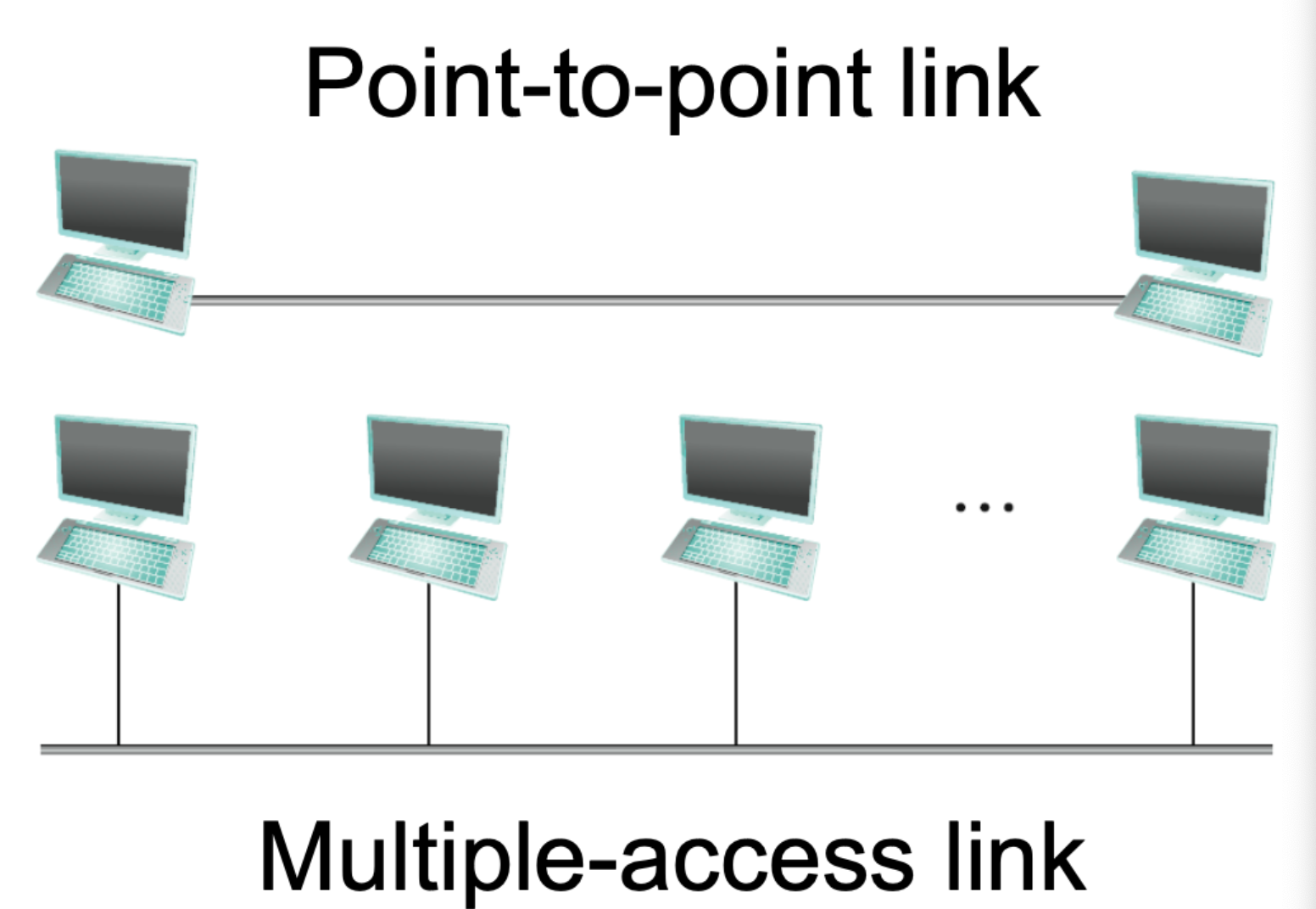
Networking 이 필요한 주체는 Node 이다. 혹은 Hosts라고도 불림
우리는 카카오톡을 실행하고 데이터 블록을 주고 받게 되는데 이떄 이 데이터 블록을 Packet 이라고 부른다.
Indirect Links 는 network 사이에 Switch 라는 장치가 들어오게 되는 연결 방식이다.
Switch 는 데이터가 들어오게 되면 일단 임시저장(Store) 를 한다. 그리고 목표 IP 주소를 보고 다음 스위치로 전달(Forward) 한다.
//
두 연결 방식을 봤을떄는 Direct 보다 Indirect 의 방식을 더 쓴다고 한다.
데이터는 한명씩 보내야 더 정확하게 전달이 가능한데 Direct 방식은 여러명의 대상자에게 정보를 보내려고 한다면 충돌이 발생할수 있다.
Direct 방식은 Link 만 연결되어있고 Switch 가 없기 떄문에 임시저장이 없어서 충돌시에 Error 가 발생할수 있다.
Indirect 방식은 Switch 가 정보를 임시저장해서 데이터끼리 충돌을 줄이기 때문에 더많은 노드가 연결되어서 데이터를 교환할수 있기 때문에 더 많이 쓰인다.
Router
그럼 Switch 로 구성된 network 가 더 커진다면 효과적으로 경로를 찾을수 있을까??
그렇지 않다. Switch 가 많아지고 길어지게 될수록 임시저장의 횟수가 많아지기 때문에 시간이 너무 지연된다는 단점이 있다. 이 해결책으로 나온것이 Router 이다.
Packet
Packet 은 Switch 로 구성된 Network 를 돌아 전달되는 Data 이다.
인터넷에서 전달되는 최소 데이터의 단위 이다.
Why Packet?
150MB 파일에 header 1개가 있는것과 1.5KB 패킷 10만개가 있는것으로 각 패킷마다 header 가 있다고 가정해보자.
Header 가 1개인 packet 의 경우 1Bit에 에러가 났을 경우 주소가 적힌 Header 가 1개이기 때문에 다시 150MB 파일을 전송해야한다. 하지만 10만개 마다 Header가 붙어있다면 10만개 가운데 손실된 Packet 만 다시 보내면 되기 때문에 패킷방식이 더욱 효율적인 셈이다.
하지만 이러한 Packet 도 Packet이 10만개인 경우에는 HEader 도 동일하게 10만개 필요하기 때문에 OverHead가 발생할수 있다.
Network
하드웨어 장비를 연결해 정보를 주고받게 하는 것을 말한다.
전 세계가 연결되어 정보를 전달하기 위해서 이 Network 를 구성한다.
Any to Any Network
일반적으로 4대의 Computer를 연결하기 위해서는 6개의 Link 가 필요하다. Computer 갯수에 따라 링크가 늘어나는 개수를 보면 Exponential 하게 증가하게 된다.
그래서 Any to Any 방식으로 Inter Media Node를 설정하는것이라고 한다. Inter Media Node 는 주로 Switch 나 Router 가 사용된다고 한다. Inter Media Node는 Multiplexing 방식을 이용해서 정보를 처리하게 된다.
Multiplexing
한정된 CPU 리소스를 여러 개 프로세스가 공유하는 것을 말한다.
Node 들은 많은데 링크는 하나로 한정되어 있다. Switch 나 Router가 정보의 우선순위를 정해서 한정된 Link 를 이용하게 한다.
Time Division Multiplexing
시간을 나누는것이다. 한정된 자원을 나눌떄 A,B,C 가 시간을 나눠서 사용하는 것과 비슷하다고 생각하면 된다.
Frequency Division Multiplexing
주파수에 따라 자원을 나눠 쓰는것인데 이거는 A,B,C 가 시간을 나누는것이 아닌 공간 자체를 나눠서 사용하는 방법이다.
Protocol
규칙과 절차다. 둘 이상이 통신을 하기 위해서 정해야하는 둘만의 약속이라 생각하면 된다. 컴퓨터는 이렇게 정의된 Protocl을 기준으로 통신을 하게 된다.
Network Application
Network Application 은 reliable한 정보 전달이 필요하다.
그러고 하나의 시스템이 잘 돌아가기 위해서는 방대한 영역의 개발 및 관리가 필요한데 그걸 한 사람만 하는 것이 가능하지 않다. 여러 계층을 나눠서 각자의 업무를 담당한다.
Application Layer
Application Layer 에서는 Software 실행을 도와주는 다양한 APp을 지원한다.
HTTP,SMTP,DNS,FTP 가 있다.
Transport Layer
Transport Layer 에서는 Data 전송 방식을 결정한다.
TCP,UDP 가 있다.
Netwokr Layer
Network Layer 에서는 주소 체계를 정의한다.
Protocol 에 맞는 IP 를 적고 Routing ALgorithm 을 활용해서 최적의 거리를 정한다.
Link Layer
Link Layer 에서는 Link 종류에 따라 정의된 Protocol 을 정한다.
어떤 Link 인지에 따라서 전송 방식이 다르다.
다 Protocol 이 다르기 때문
Physical Layer
하드웨어의 전파가 어떻게 전송되는지를 결정한다.
Physical Layer
Physical Layer 는 Bit로 된 Data를 전파 신호로 바꿔서 전파로 Data 를 보내는 역할을 한다.
Link 들은 전파의 신호만 날릴수 있다. 이걸 Analog Signal 이라고 한다.
Physical Layer 에서 Digital 로 된 Data 를 Analog 형태의 전파로 변형해주는 과정이 필요하다. 그걸 Modulation 이라고 한다.
Link Layer
각 Node 가 연결되어 있는 Link를 통해서 데이터를 보내는 것을 정의한다.
Node에서 인접한 Node로 보낼때 link Layer 에서 사용하는 주소를 MAC Address 라고 부른다. MAC 주소는 48bit 다.
MAC Address
Device 와 Device 사이에서 통신하기 위한 주소로 사용된다. 자신에게 온 데이터가 아니면 드랍을 시키고 MAC 주소가 일치하는 노드만 올리게 된다.
MAC Address 가 하는 기능은 Switching,Error Correction,Multiple Access 가 정의되어있다.
Error Correction
데이터에 에러가 있는지 없는지를 확인한다.
Multiple Access
링크는 하나지만 동시에 데이터를 보낼때 정보가 뒤섞이고 신호가 충돌이 난다. 서로 데이터를 못보내는 상황이 발생한다. 분산된 시스템에서 최대한 충돌을 피하면서 데이터를 주고받게 하는 것을 말한다.
Network Layer
Ip주소가 네트워크 레이어의 헤더정보로 붙게된다.
IP 주소를 가지고 Router 가 Routing 을 해준다. 이 IP 주소를 가진 Root 는 몇번 Link 로 가는것이 가장 빠른 방법이다. 라는 것을 알고리즘 적으로 찾아내 forwarding 해준다. 목적지까지 패킷을 보내는 경로를 찾는 것에 사용된다.
Transport Layer
6번 Node 가 120번 Node 에게 데이터를 보냈을떄 Error를 어떻게 확인할수 있나? 그건 ACK 이다. 그냥 120번 Node 가 6번 Node 한테 ACK 을 보내면 된다.
하지만 ACK 을 받지 못했다면 6번 입장에서 LOss 라고 판단해서 재전송을 한다.
TCP
Transmission Control Protocl 로 데이터가 손실없이 목적지까지 전달되는것을 보장해주는 전송 프로토콜이다. 데이터를 받은 사람이 ACK 을 보내줌으로써 보장한다.
TCP 는 Congestion Control 이라는 알고리즘을 수행한다.
Network 는 공용 자원으로 모두가 사용할수 있는 곳인데 이런 경로에 모두가 데이터 보내면 Loss가 발생할수 밖에 없다. 이걸 병목 현상인데 이걸 피하기 위해서 속도를 조절 및 제저해줄 필요가 있다.
네트워크가 느리지 않으면 전송속도를 점점 늘려나가고 Congestion 이 날것 같으면 다시 줄였다가 늘렸다가를 반복한다.
모든 네트워크들은 TCP 를 따른다.
Application Layer
실제 Application 이 동작하는 계층이다.
HTTP,POP3,SMTP,DNS
Network Core
네트워크를 연결하기 위해 Router 라는 장비를 통해 Network 가 연결된다.
수많은 Router 들이 실제 Network를 연결하고 있다.
Access Network
실제 Node와 연결되는 Network를 Access Network 라고 한다.
Core Network
Host들끼리 연결되면 netwokr 끼리 연결을 해줘야하는데 이런 장비를 ROuter 라고 한다. 그 ROuter 들이 연결되어 구성된 network 를 core network 라고 한다.
데이터 전송 방식
Circuit Switching
End to End Resource 가 예약되는 방식이다.
수신자와 발신자 사이에 데이터 주고 받는 방식을 예약하는것이다. 예약된 경로를 통해 아주 안정적으로 데이터를 보낼수 있게 된다.
데이터를 모두 주고 받을 뒤에는 연결을 끊어야한다. 안 끊으면 그 경로를 다른 사람이 쓰지 못하기 때문에 낭비가 된다.
장점으로 일단 연결되면 자신이 사용할수 있는 회선이 생겨서 안정적인 통신이 가능해진다.
단점은 연결되는데 시간이 오래 걸리고 Node가 많아질수록 자원이 부족해진다.
Packet Switching
컴퓨터 네트워크에 사용되는 방식이다.
전용 회선을 만들지 않고 각각의 Packet에 IP주소가 붙어있다. Router 들이 Routing 알고리즘을 통해 목적지 까지 라우팅을 해줘서 경로를 점유할수 없다.
Network 에서 발생하는 지연(Packet Switching)
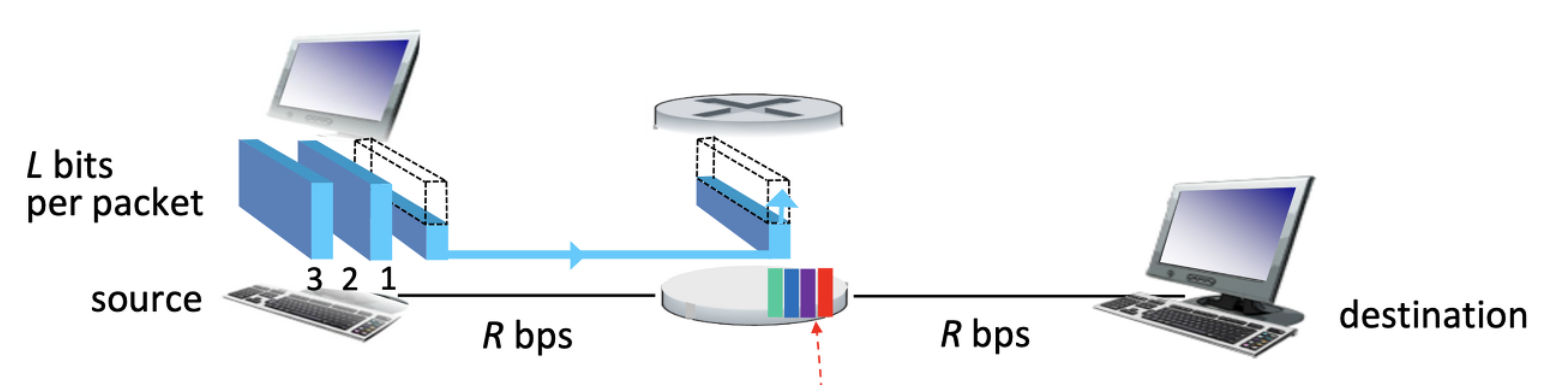
라우터는 Store and forward 방식으로 동작한다. Packet 이 Router 에 도착하면 잠시 저장하고 Packet . 을 어느 링크로 전달할지 결정한다. 그리고 Forwarding 한다.
router에 도착하고 다음 링크로 전달되는걸 Buffering 이라고 한다.
Transmission Delay
전송시간이다.
Transmission Delay 는 Bandwidth(대역폭) 에 영향을 받는다. 전단할 데이터의 크기가 작으면 작을수록 다음 Node에 전달할수 있고 Link(Bandwidth)이 빠르면 빠를수록 신속한 데이터 처리가 가능하다.
Propagation Delay
일반적으로 전파가 전달되는 속도는 거의 빛의 속도이다. 출발지와 목적지 사이에 거리가 멀수록 시간이 . 더드는것이고 전파가 전달되는 속도에도 영향을 받는다.
Node와 node 사이의 거리가 짧으면 짧을수록 전달 시간은 0에 가까운데 멀면 propagation delay를 무시할 수 없다.
Processing Delay
라우터는 Packet의 haeder 에서 ip를 LEad 하고 라우팅 알고리즘을 기반으로 생성된 포워딩 테이블을 보고 어느링크로 보내야하는지 판단한다.
즉 라우터에 머물며 IP를 리드하고 포워딩 테이블을 확인하는 일련의 버퍼링 시간을 processing delay 라고 한다.
queueing delay
그리고 바로 전달되는것이 아니다. 큐에서 순서대로 나가야하기때문에 queueing delay 가 발생한다.
Packet Loss
queue 는 유한한 메모리를 가지고 있다. Packet 이 도착하면 이 메모리에 잠시 저장되었다가 다시 링크로 보내진다. 근데 만약 링크로 보내지는 속도보다 더 많은 패킷이 들어오게 된다면 메모리에서 기다리는 패킷들이 쌓이게 된다. 어느순간 메모리가 가득차게 되고 가득찬 버퍼로 오는 패킷은 loss 이다.
Throughput

sender 와 reveiver 사이에서 어느 정도 속도로 데이터를 보낼수 있느냐를 판단하는 척도
Protocol Layer
Layering 하는 이유는 다양한 것들이 묶여서 일어나는 시스템을 구축할때는 한꺼번에 설계하고 구현하면 디버깅과 유지보수가 어렵게 된다. 그래서 최대한 모듈 단위로 단순화하고 모듈화 하기 위해서 레이어링 을 하게된다.
유지보수에 좋고 시스템 업데이트하기가 좋다. 또한 레이어 서비스에 변화를 주고 싶을때 상/하위 레이어에 영향을 주지 않고 변화를 줄 수 있어서 시스템을 효과적으로 업데이트 할 수 있다.
ISP
Internet Service Provider 로 인터넷에 접속할 떄 가장 종단의 네트워크를 제공하는 서비스 프로바이더다.
Network Security
컴퓨터 네트워크를 어떻게 공격할수있는지 또 어떻게 보안할수 있는지 고민 하는 분야.
Malware
컴퓨터에 Malware 를 심고 host안에서 Virus,Worm 같은 것들을 퍼트린다.
VIrus 는 일반적으로 어떤 오브젝트를 닫고 실행하면 감염이 된다
Worm 은 어떤 오브젝트를 받기만 하면 실행이 되면서 점점 스스로 감염되게끔 한다.
DDOS
Denial of Service 의 약자.
보거스 트래픽을 발생시키게 해서 공격 대상이 되는 특정 서버를 다운되게 한다.트래픽은 엄청 많이 발생 시켜서 정작 중요한 리소스는 처리되지 못하게 한다.
Sniffing
스니핑은 브로드캐스트미디어에서 발생된다. Bad guy 가 사용자가 발생한 트래픽을 엿듣는것.
Spoofing
서버에 패킷을 보낼때 소스 Address를 바꿔 보내는것. Fake Address를 이용해서 공격한다.
자신은 C인데 마치 B인것 처럼 오해하게끔 패킷을 보내서 서버가 잘못된 처리를 유도
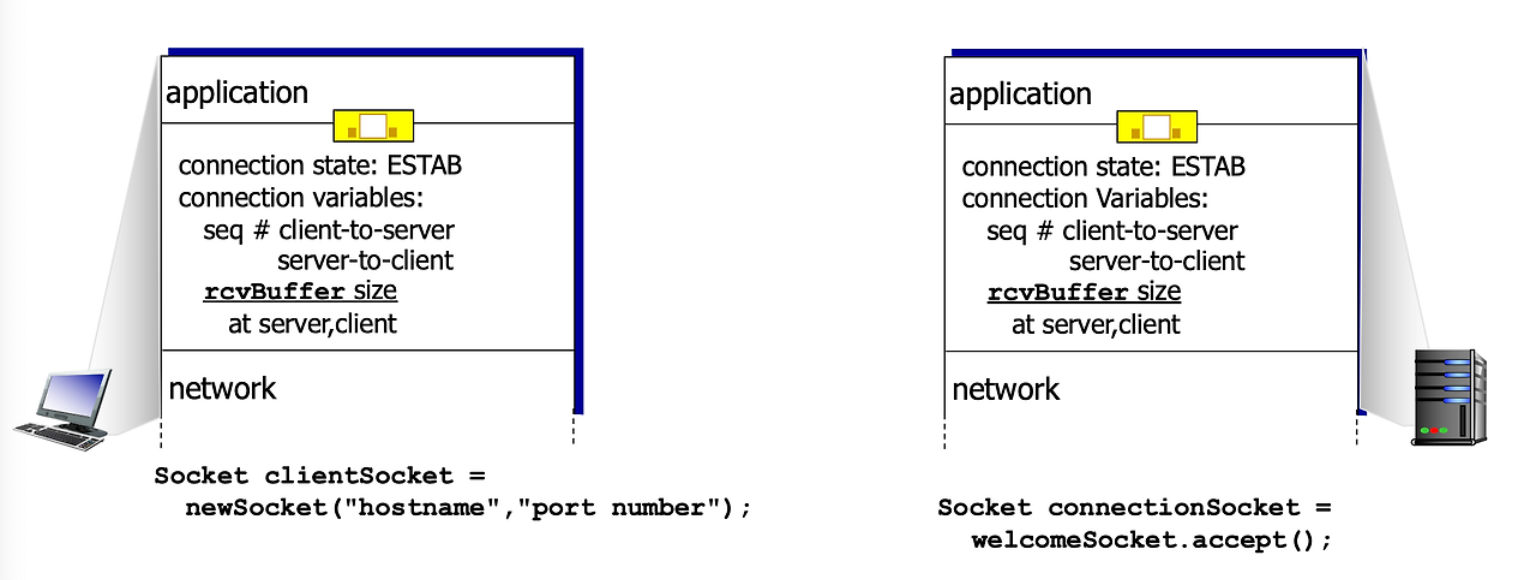
Socket
프로세스가 서로 네트워킹을 하기 위해 메세지를 주고 받는다. 이때 Application 에서 Transport로 메세지를 내려준다. 이때 내려준 인터페이스를 Socket 이라고 한다. Socket 은 Application 과 Transport 사이에서 소프트웨어 인터페이스 소켓이 서로 소통할 수 있게 도와주는 역할
Identifier : IP & PORT
수신자가 Message를 받기 위해서는 반드시 Unique 한 identifier 가 필요하다. 주소가 Unique 하지 않으면 원하는 목적지로 Data 를 보내지 못한다.
Host를 구분하기 위해서는 IP 주소로 구분한다. 근데 Host B 에서 돌아가는 Process 를 구분하는건 어떻게 하나? 이건 Port # 로 하면 된다.
Application 종류에 따라 정해져있는 포트번호가 있고 자신이 설정해도 된다.
HTTP 는 80,Mail은 25 를 쓴다.
Application Layer Protocol
Application Layer 에서 Applicatoin Data 를 전달하기 위해서는 Application Layer Protocl 을 사용한다. syntax, semantics 로 정의된다.
syntax : 메세지 안에있는 필드들, 그 필드들이 어떤 방식으로 서술되는지를 정의합니다.
semantics : 필드 안에 정보들이 어떤 의미들을 갖는지를 정의합니다.
Transport Layer
Transport Layer 에서는 data integrity(무결성) 을 보장 하느냐 마느냐를 담당한다.
TCP
100% reliable 한 Transport 기능을 제공한다. 손실이 발생하지 않도록 보장하고 loss 발생하면 재 전송을 해서 완전하게 전송될때 까지 재전송을 한다.
그래서 데이터가 잘 갔는지 못갔는지 확인하려면 커넥션이 필요하다 . Client,Server 사이에 TCP Connectoin 을 맺고 Conncection 을 통해서 Data를 Reliable 하게 전송
UDP
ACK 없이 그냥 Data 던져주고 끝 그냥 목적지 IP 주소와 PORT# 던저주고 끝.
Why UDP?
기본적으로 complexity 가 낮아서 client,server 한테 부하가 적다.
Connection setup이 필요없기에 바로 데이터를 보낼수 있어서 속도도 굉장하게 빠르다.
즉 적은 데이터를 빨리 보낼때 좋은 프로토콜이다.
근데 UDP 를 너도 나도 쓰면 과도한 데이터가 네트워크에 발생해서 congestion 늘어 날수 있다.
TCP는 reliable 한 전송 뿐만 아니라 congestion을 컨트롤 하는 기능도 포함 되어있다.
WEB & HTTP
웹 서비스를 네트워킹 할 떄 사용 되는 Protocol 을 HTTP 라고 한다.
웹을 다운 받으려면 HTML 을 받고, 다른 부가적인 오브젝트들을 받으면서 최종적으로 페이지가 구성된다.
URL

각각의 Object 는 URL 로 구분이 된다. URL 은 hsot name 과 오브젝트가 있는 경로의 조합으로 오브젝트가 구분된다.
HTTP Protocol 동작 절차

Web Application Layer Protocol 은 client 와 Server 로 구성되는 경우가 가장 일반적이다. Client 에는 크롬,사파리 처럼 Web Browser가 설치되어있고 Server는 다양한 Browser를 지원하기 위해 Apache web server를 사용한다.
Client 는 Object를 요청하고 Object를 받으면 화면에 띄어준다.
Server 는 Client 가 Service 요청하면 Object 를 다시 보내준다.
HTTP Protocol 은 TCP 를 사용한다. 80 포트 사용

HTTP : Stateless
HTTP 는 상태를 기억하지 않는다. 여러 client 로 부터 HTTP Request 오면 그냥 Request 에 해당하는 Response 를 날려주고 끝낸다. Request 가 누구한테 왔는지 상태를 저장하지 않는것을 의미한다.
각 리퀘스트에 대한 상태정보를 기억하지 않아서 서버에 부담을 줄인다.
HTTP Connection
User 가 URL 을 입력하면 HTTP Client 가 Server 에 TCP Connection 을 연결 요청한다. 서버가 80 포트에서 요청 받고 Accept 하면 client 에게 TCP 요청 수락한다는 메세지 보냄.
이렇게 connection 이 만들어지면 SErver 는 request 를 받는다 그런다음에 client 가 요청한 object를 response 에 담아서 client 한테 전달.
이렇게 전달이 끝나고 Object 한개를 받으면 TCP Connection 닫는다.
근데 이게 10개 이상을 전달해야하는데 TCP 연결을 열고 닫는데 너무 오래걸리지 않나?
결국 이 HTTP Conenction 을 하고 데이터를 전달하는데는 2RTT + Transmission Delay 가 발생한다.
이러한 문제를 해결 하기 위해서 TCP Connection 을 한개만 여는것이 아니라 여러개를 병렬로 여는 방식을 사용한다.
위의 방식이 Non-Persistent HTTP 방식이였다.
Persistent HTTP
Object 를 여러개 받으니까 TCP 를 닫지말고 열어둬서 재 활용하자
현재 Default 로 사용되고 있는 형식이다.
하지만 무한정 남겨주면 안되는것이 Server 입장에서 TCP Connection 을 남겨두는건 Server 와 client 의 Resource 를 잡아먹는 것이기 때문.
HTTP Resonse Satus code
200 - OK
301 Moved Permanetly - 서버의 위치가 바뀌어서 새로운 주소 알려줌
400 Bad Request - 너가 요청한 Request 이해할수없다
404 Not Found - Server에서 요청한 Object 가 존재하지 않고 어디로 이전했는지도 모름
505 HTTP Version Not Supported - HTTP version 이 맞지 않음
Cookies
HTTP 는 Stateless Protocol 이다. 그렇게 Server 의 부담을 최대한 줄여주고 많은 connection 을 Server에서 처리할수 있게 하기 위함.
하지만 Web Service를 제공하는 웹 서비스 Provider 입장에서는 State 를 관리하고 싶다. 이걸 Cookie 라고 한다.
HTTP Response Message 에 cookie Header 를 추가하고 Cookie 번호를 가지고 특정 사람의 상태를 추적
User 마다 Cookie # 를 가지고 Request 를 보낼떄 마다 자신의 cookie ID 를 Server에게 알려줌
Web server 에서도 cookie ID 가 어떤 HOST 인지 Mapping 을 한다.
Web Caches(Proxy Server)
웹 서비스를 사용할떄 지연을 줄이는게 굉장하게 중요하다.
Web Caches 는 서버의 개입 없이 클라이언트의 Request 를 처리하고자하는 목적에 의해서 등장. 유저는 1차적으로 Original Server에 요청하는게 아니라 나한테 가까이 있는 Proxy Web server에 요청한다.
그 Proxy Server 가 내가 요청하는 Object가 있다면 서비스를 해주면 된다.
DNS(Domain Name Service)
IP 주소 대신 www.naver.com 이라는 호스트 주소를 사용한다.
IP 주소를 외우기 어려우니까 Host 주소와 IP 주소를 Maaping 해줄 무언가가 필요해서 DNS 만들었다.
분산된 DB와도 같다.

계층 구조를 사용한다.
하나의 서버에서 모든걸 감당하다 오류가 발생하면 전세계 사람들은 인터넷을 사용할수 없음
하나의 서버에 Traffic 이 너무 몰림
한국에서 미국까지 하나의 서버의 거리로는 못감
유지보수도 힘듬
- 확장성이 떨어지기 때문
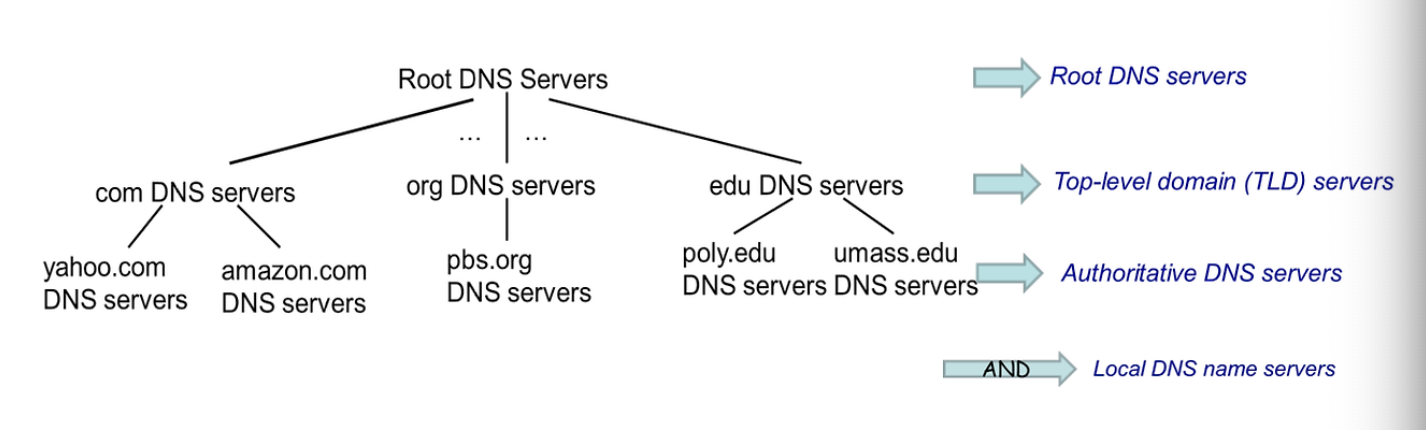
Local DNS SErver의 문제점
즉 캐싱의 문제점이다. 사람들이 www.naver.com 을 너무 많이 입력해서 네이버의 IP 주소를 캐싱하는데 이걸 계속 저장해두면 네이버에서 업데이트한 내용을 확인하는것보다 cacheing 한 내용을 계속확인하게 될꺼다. 즉 싱크가 안맞게 된다. 이걸 해결하기 위해서 TIME OUT 의 값을 운영하고 있다. 캐싱해둬도 일정 시간 지나면 날려버려줘야함
Load Distribution
DNS 는 IP주소 Mapping 말고도 Load Distribution 의 역할도 한다.
네이버는 여러대의 Server를 가지고 있다. Load를 분산하기 위함.
네이버 주소를 검색창에 입력하면 DNS Server 가 IP 주소들 중 하나의 주소로 안내해준다. Connectoin broker의 IP 주소로 안내받으면 또 Broker가 관리하고있는 N개의 노드를 파악해서 Node가 적은 방향으로 안내한다.
P2P Architecture
임의의 End System이 직접 Communication 하는 구조. P2P 에서는 임의의 엔드시스템을 Peer 라고 부른다.
Peer 들은 간헐적으로 서비스를 원할때 연결된다.
MultiVideo
넷플릭스는 전체 Network Traffic의 37%를 차지하고있다. 유저수,Traffic이 빠르게 증가하고 있는데 감당하기 위해 Scalability 를 고려해야함
또한 모두 다른 환경에 처해있기에 Mobile/PC 의 통신속도가 다르다. 이걸 이기종성 이라고 하는데 우리가 어떻게 안정적인 Video Streaming 을 제공할수 있느냐에 대한 문제가 있다.
MultiVideo 압축
비디오는 이미지의 시퀀스.
엄청 많은 이미지가 전송되는격임. 이러한 이미지는 Frame 으로 이뤄져있고 Frame 은 Pixel 로 이뤄져있음
Pixel 은 색깔을 나타내기 위한 값이 들어있다.
이미지 내에서 압축(Spatial coding)
비슷한 색깔과 그 색깔이 몇번 반복되는지 보내느것으로 데이터의 양을 줄일수 있다.
이미지 차이로 압축(Temporal coding)
연속적인 프레임안에는 이미지가 비슷. 그래서 같은 이미지를 2번 보낼필요있나?
그냥 프레임 간의 차이만 전달
MultiMedia 비디오 전송
CBR(Constance Bit Rate)
비디오가 인코딩 되는 속도를 고정
VBR(Variable Bit Rate)
비디오 인코딩 속도가 Spatail/Temporal 방식에 따라서 계속 변경된다
저장된 비디오 스트리밍
비디오 서버에는 압축된 영상의 비디오가 저장되어있다.
이러한 데이터는 internet 을 통해 Client 로 전달된다.
Network 가 안좋을수도 있는 상황에서 Client 에게 비디오를 끊임없이 보낼수 있는 알고리즘이 없을까에 대한 부분
DASH
그래서 DASH 가 나옴
Dynamic Adaptive Streaming Over HTTP
HTTP라고 쓴 이유는 대부분의 Video Streaming 이 웹 기반으로 전송이 될거라는 전제하에 만들었다고 한다.
DASH 의 특징은 Intelligence 를 Client 에 넣었다는 것이 특징이다.
CDNs(Content Distribution Networks)
컨텐츠를 수백만명에게 전송을 해야하는데 하나의 서버로는 커버가 불가능하다.
Single Point of Failure 발생
Point of Network Congestion - 과부하
Long Path to Distant Client - 여러 지역과 서버의 거리가 멀어짐
Multiple Copies Of video sent over outgoing link - 여러 유저들에게 카피가 전송되는데 outgoing 링크가 보틀넥 링크가 될수 있기 떄문.
그래서 우리는 Distribute 한 CDN 방식을 채택한다.
분산배치된 CDN Node에 Content 의 복사본을 저장해두는것이다.
Client 는 가장 가까운 곳에서 Content 를 보니까 빠르게 받을수 있다.
Origin Server에서 다운받게 되면 굉장히 많은 Network 를 거쳐서 자원이 소모 됐을텐데 CDN 사용함으로써 자원을 많이줄일수 있다.
또한 Origin Server의 부하도 줄일수 있다.
Origin Server 는 Manifest 파일만 전달하고 끝
그리고 CDN 서버가 가깝다고 해도 Congestion 이 크면 다른 경로로 Content 받기 가능.
Transport Layer Service
Logical Communication
Logical Communication 이란 서로 통신하는 Process 들이 물리/직접적으로 연결되어 있는건 아니지만 가까이 연결된것과 같이 만드는것
Transport vs Network
Transport 는 End to End Communication 을 지원한다.
Routing 은 Netwokr Layer 까지 역할을 수행하고, Netwokr Layer 에서 처리하는 IP주소를 처리해서 Routing을 담당하고 있다.
결국 두 Layer 모두 Data 를 전달하는 역할을 하지만 역할의 범위가 다르다.
Transport 는 Process 간의 communication 을 담당하고 Application 으로 부터 Meesage를 Port # 를 사용해서 식별이 가능하다.
Network 는 Host 들 간의 Logical Communication 을 담당한다. Router 도 IP 주소를 가지고 Routing 을 한다.
UDP
UDP 는 Unreliable/unordered delivery 이며 PORT # 를 사용한다.
아주 가벼운 Error Checking 기능이 있다. 복원이 있는건 아님
UDP FOR DNS
DNS query 할때 UDP 사용한다고 한다. DNS 작업은 매우 자주 일어나기때문에 빠른 서비스가 필요하다. 그래서 UDP
손실 나도 다시 DNS Query 하면 된다.
UDP : checksum
UDP 를 통해서 데이터를 전송할때 Error 가 발생한거를 알게끔 체크하도록 하는 기능.
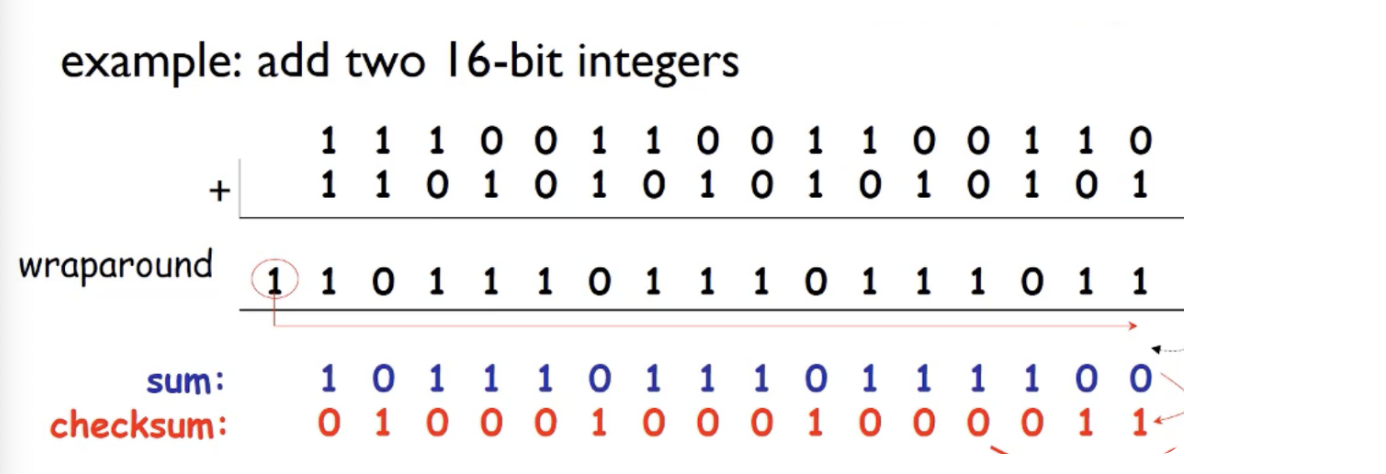
두개 더했을때 Receiver 에 전달된 SUM 과 checksum 을 더했을때 모두 1이면 Error 가 없는것이고 1이 아니면 Erorr 가 있는것.
Multiplexing/Demultiplexing
Multiplexing
Multiple Data Stream 을 하나의 Stream으로 Combined 하는 과정.
목적지 host의 IP 주소 Header 를 붙은 Datagram 으로 전달하기 위함.
Demultiplexing
하나의 Link 로 전달된 Data를 Port#를 활용해서 여러 Process로 mapping 하는 과정.
TCP
TCP 는 Source IP 주소,Source Port # ,Dest IP 주소,Dest Port #에 의해서 구분된다.
TCP 는 동시에 여러개의 TCP Socket 을 지원학 ㅔ된다. Web server 일 경우 web Client들이 Server 와 TCP Connection 을 여러개 맞는다. 각각 Client 들의 Socket 을 관리해야하는데 위 4개에 의해서 구분된다.
TCP 는 Timeout 값을 결정하는것이 중요하다.
RTT 값을 측정해서 timeout 의 기준점을 삼아야한다.
하지만 RTT 는 변동성이 너무 심하다. 이 변동성을 잡기 위해 Moving Average 를 활용했다.
과거까지 moving average를 한것과 현재 측정한 RTT 를 가중치 평균을해서 계속 업데이트 해야한다.
Fast Transmit
TCP 는 Timeout 이 터져야 Packet 을 재전송할수있다. 근데 Timeout 을 기다리는게 시간이 너무 오래걸릴수있음.
ACK 은 항상 앞의 Packet에 대한 ACK 이 날라온다. Sender는 중복된 ACK이 계속 온다는 말로 이 다음 Packet 이 Loss 가 될 확률이 높다는 것을 알 수 있다.
그래서 fast retransmit 을 한다.
duplicate ack 을 받으면 그냥 timeout 되기 전에 재전송한다.
TCP=GO-BACK-N + SR
TCP 는 Go Back N 과 SR 방식이 적절하게 섞여있는 형태라고한다.
Flow Control
congestion control 이 윈도우 사이즈를 결정하기 위한 기능이다.
윈도우 상황이 좋으면 윈도우 사이즈를 최대한 키우고 반대면 줄임.
근데 윈도우사이즈 키우는것도 수신단이 읽어들이는 속도보다 네트워크를 통해서 밀려 들어오는 데이터가 많다면 안된다. 메모리 사이즈는 무제한이 아니기 때문에 로스가 일어날 수있다.
윈도우 사이즈를 결정할 때 네트워크 상황도 고려해야하고, 수신단이 얼만큼의 속도로 데이터를 받을 준비가 되어있는지도 고려해야한다.
그래서 flow control 로 수신자의 남은 버퍼 사이즈를 알려준다.
connection management
connection 을 맺으면 connection 상태를 관리한다. connection 이 유지할 동안은 header 에 적힌 내용을 관리하게 된다.
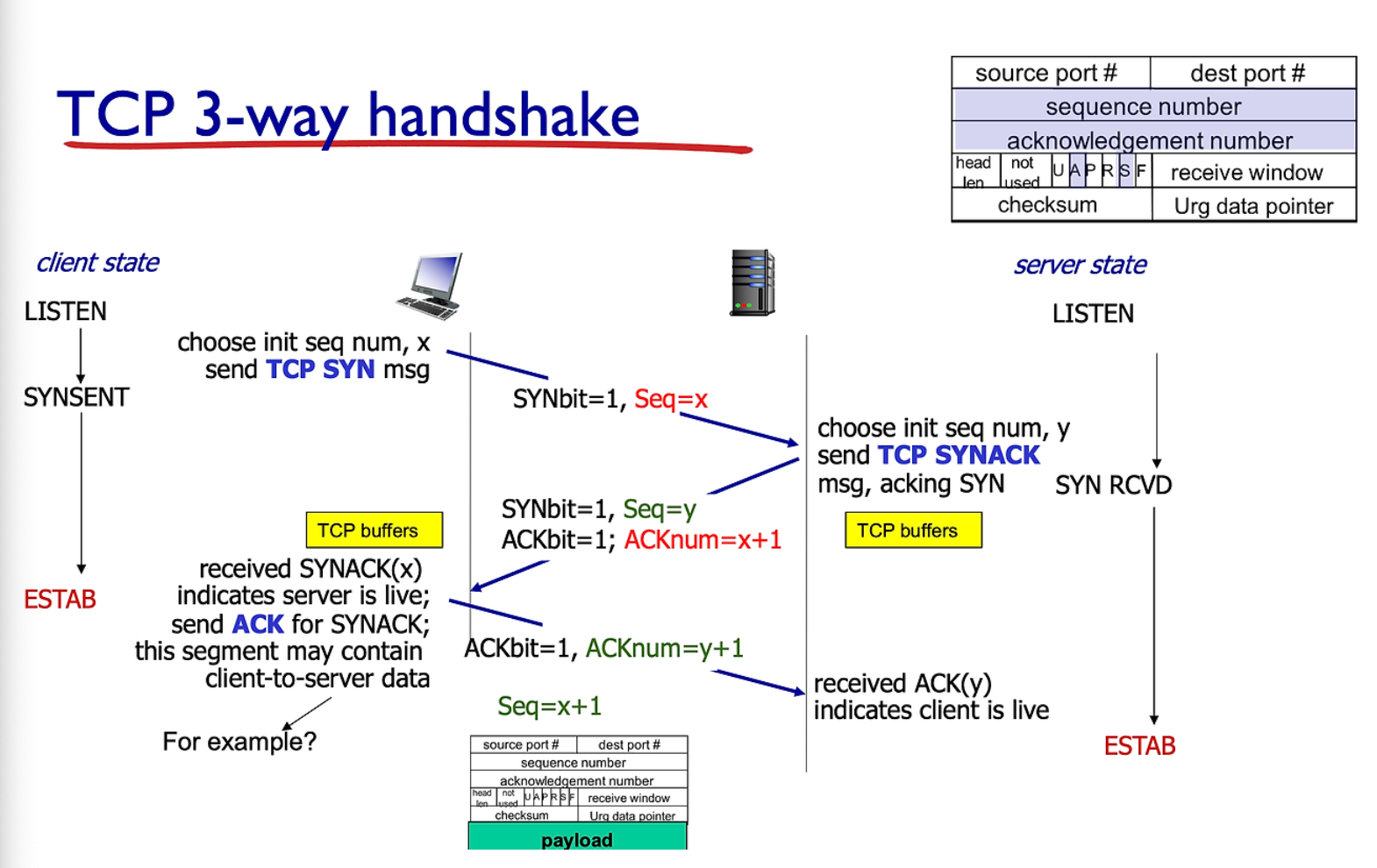
근데 왜 3 hand shake 가 필요하나?
client 가 서버가 살아있는지 모르기 떄문에 죽어있다가 데이터가 낭비될 수 있다.
2way 는 왜 안되냐?
연결을 시도했는데 Client 가 연결을 끊어버리면 Server 가 낭비 될수 있다.
closing a connection
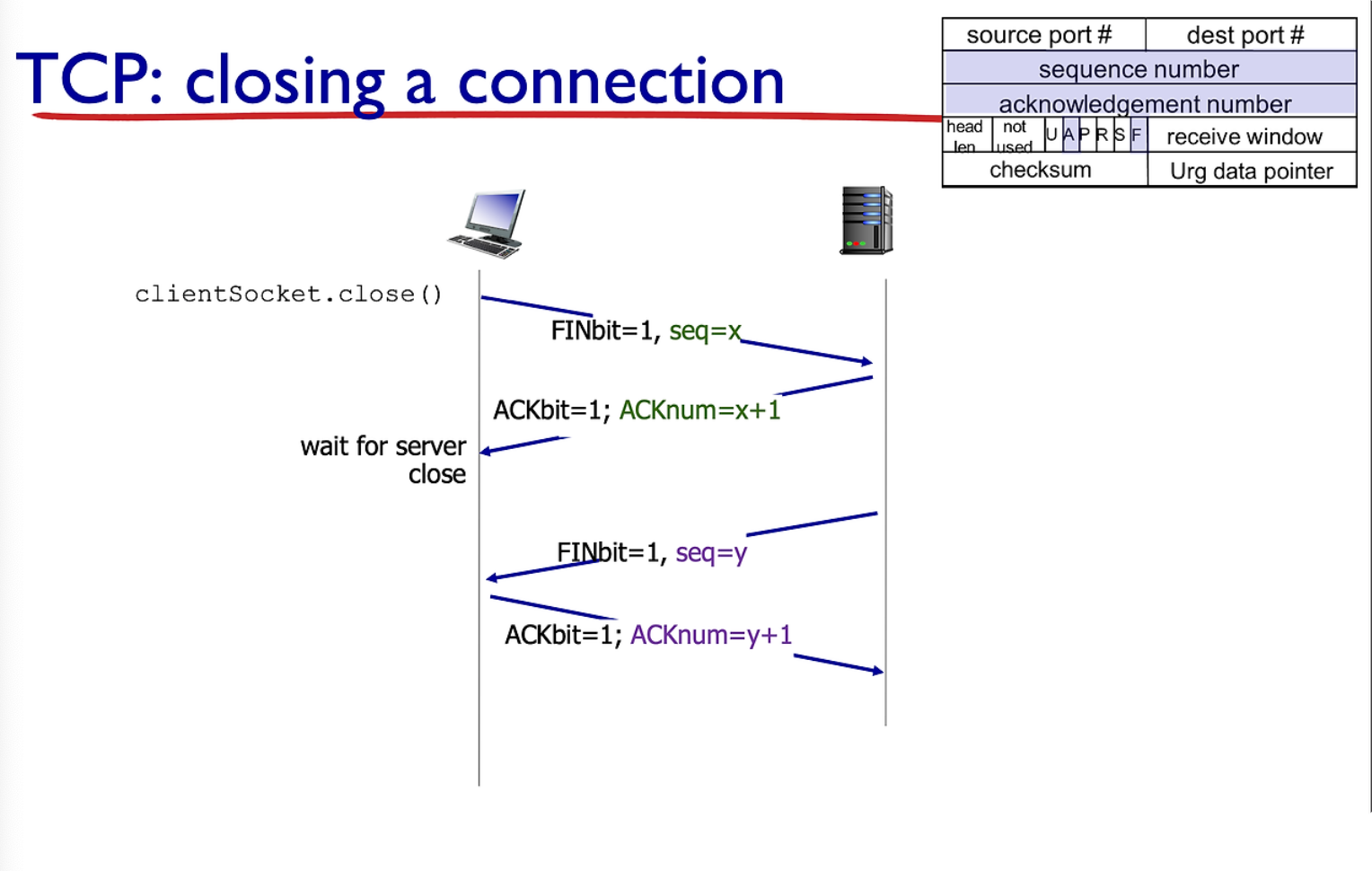
연결을 끊을때는 양쪽에서 끊는다.
FINbit를 1로 세팅하면된다. ack 을 통해 반응을해주면서 FINbit를 교환하게 된다.
Congestion control
flow control 은 Receiver 가 받을수 있는 속도 만큼만 보내자 였다.
congestion control 은 network 가 감당 할수 있을 만큼 윈도우 사이즈를 결정하는 알고리즘
Congestion control 필요한 이유
네트워크 congestoin 이 심하다 라는 건 network 가 막힌다는 뜻.
packet loss 가 많이 발생할꺼고 delay 가 증가할꺼임
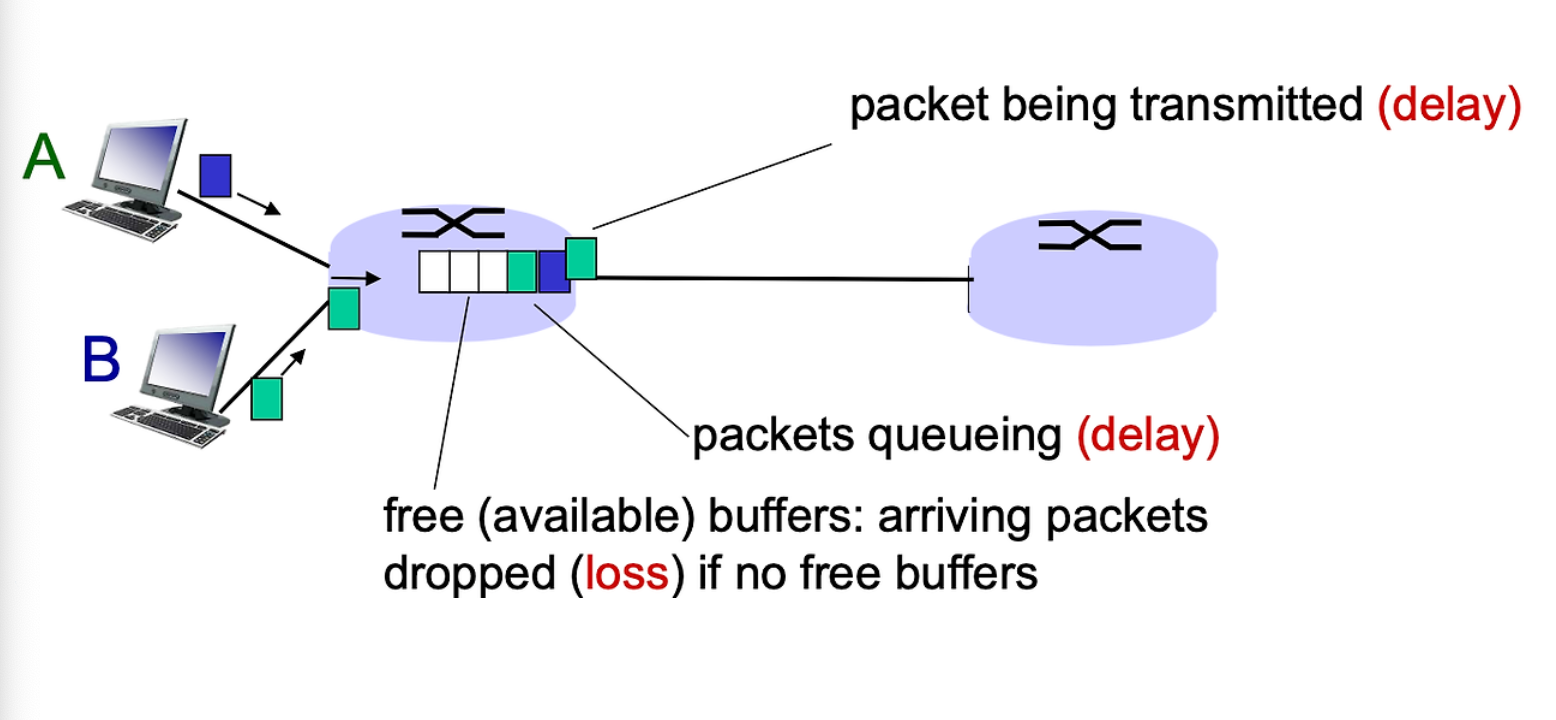
packet 들이 router 에 들어오게 된다. router 는 유한한 메모리를 가지고 있는데 link 로 내보내는 속도보다 router 에 쌓이는 packet 의 수가 많으면 그리고 router가 다 차버리면 packet 은 loss 가 생길수 밖에없다.
그리고 router 안에 있는 packet 들도 자신의 차례가 오기까지 계속 기다려야하기때문에 delay 가 발생한다.
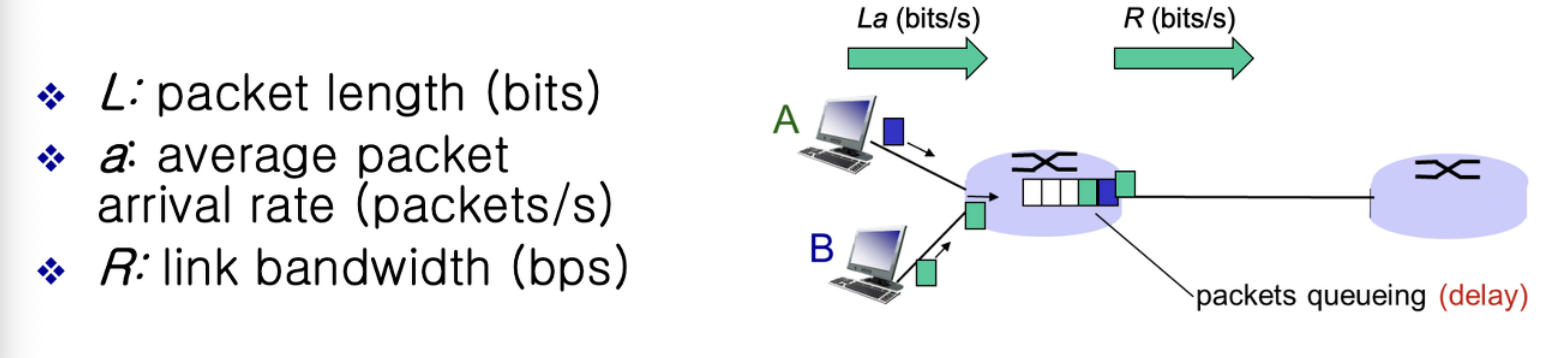
L * R 은 링크로 유입되는 양이고
R은 링크로 내보내는 양이다
이 두개의 비율을 Traffic intensity 라고 하는데 이게 1보다 크면 들어오는게 더 많다는것이다.
가능한 Traffic Intensity 는 1 이하로 유지되게 하는것이 중요하다.
flow control 이랑은 목적이 전혀 다르다. 둘 모두 윈도우 사이즈를 결정하는데 영향을 미치긴 하닞만 목적이 다름.
flow control 은 수신단까지 잘 왔는데 발생하는 loss 를 막기위해 수신자가 transport layer 에서 application layer 까지 올리는 속도보다는 좀 느리게 보낼 필요가 있다.
congestoin control 은 network 단에서 loss 를 줄이는게 목적
Network Layer
Network Layer 는 2가지 계층을 다루게 된다.
전송계층은 실제 데이터가 날라가는 기능을 담당하고
제어계층은 데이터가 원할하게 잘 전달되도록 제어메세지를 다루는 부분.
Router에 데이터가 오면 3번 포트로 전달이 된다. 이걸 data plane(전송계층)
End to End를 따라 Routing 알고리즘이 돌아가는 과정을 Control plane(제어 계층) 이라고 한다.
모든 Router 는 Transport Layer 기능이 구현될 필요 없다. 중간 Router 의 경우 윈도우 사이즈 조정,Loss 재전송만 해주면 되기 ㅐ문이다.
하지만 모든 Router 에 network 기능은 구현되어야한다. Network Layer 의 주요 기능이 Router 이기 때문.
Forwarding
input Port 에서 들어온 Data 를 Output Port 로 Mapping 해주는것을 Forwarding 이라고 한다.
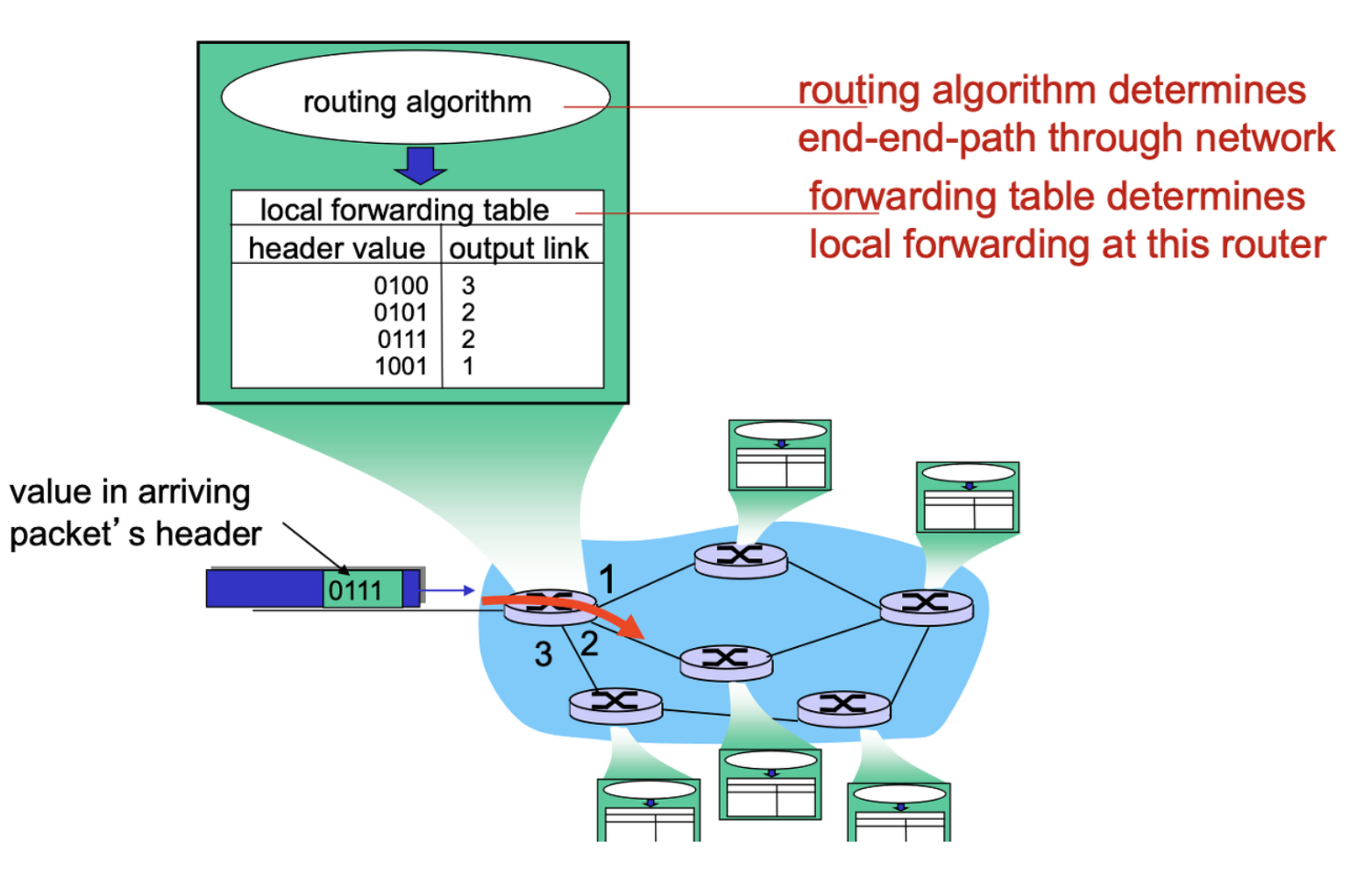
Routing 알고리즘의 Output이 되는 것이 Forwarding Table이다.
Header value 와 output Link 가 매핑되어 만들어져 있다.
Routing Protocol
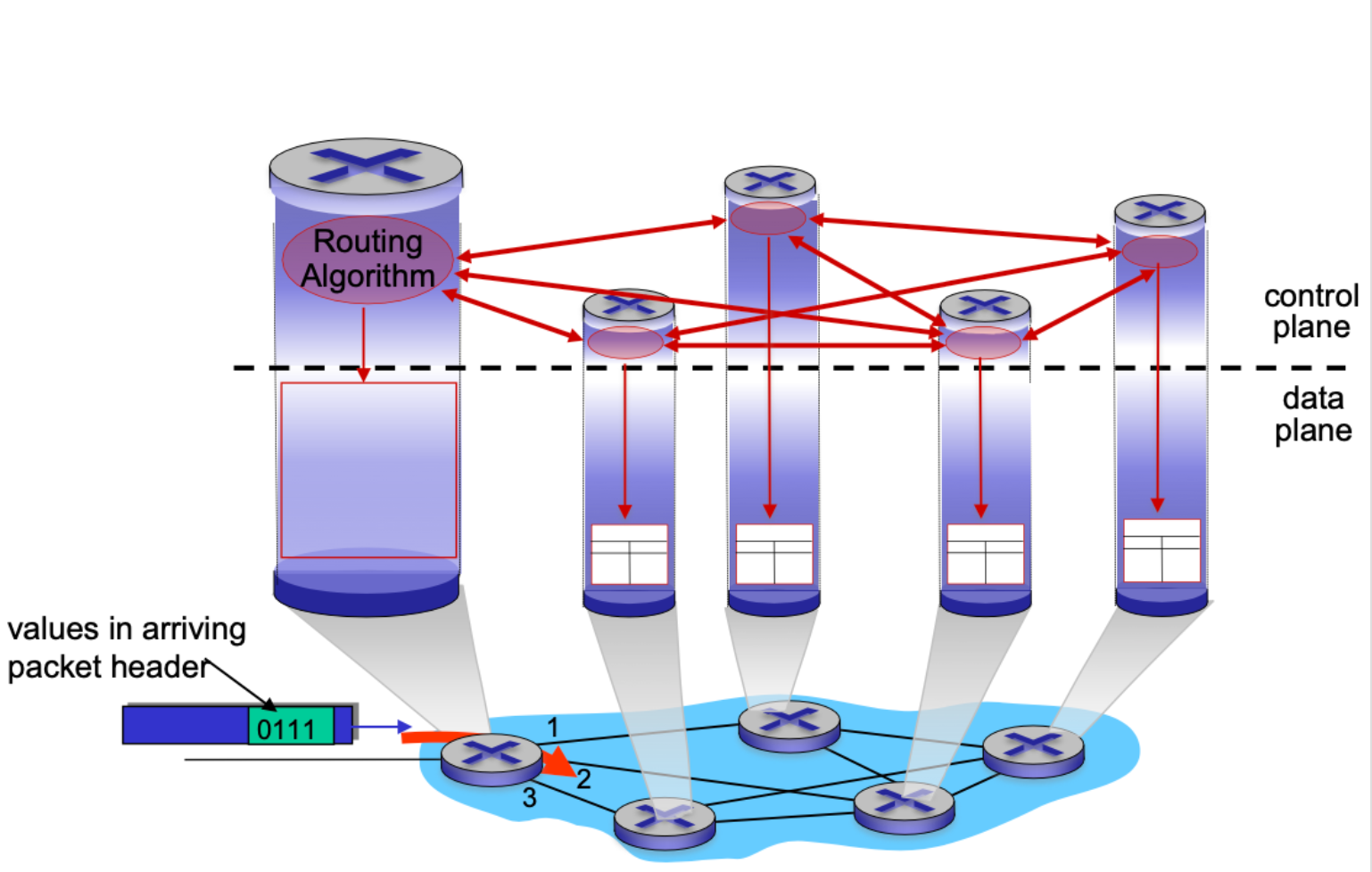
서로 다른 라우터와 유기적으로 작동하여 Routing Path 를 알아낸다. 그래서 Router 들 기리 정보를 주고 받을 protocol 이 필요하다.
Protocl을 주고 받으며 Routing Path를 알아낼수있다.
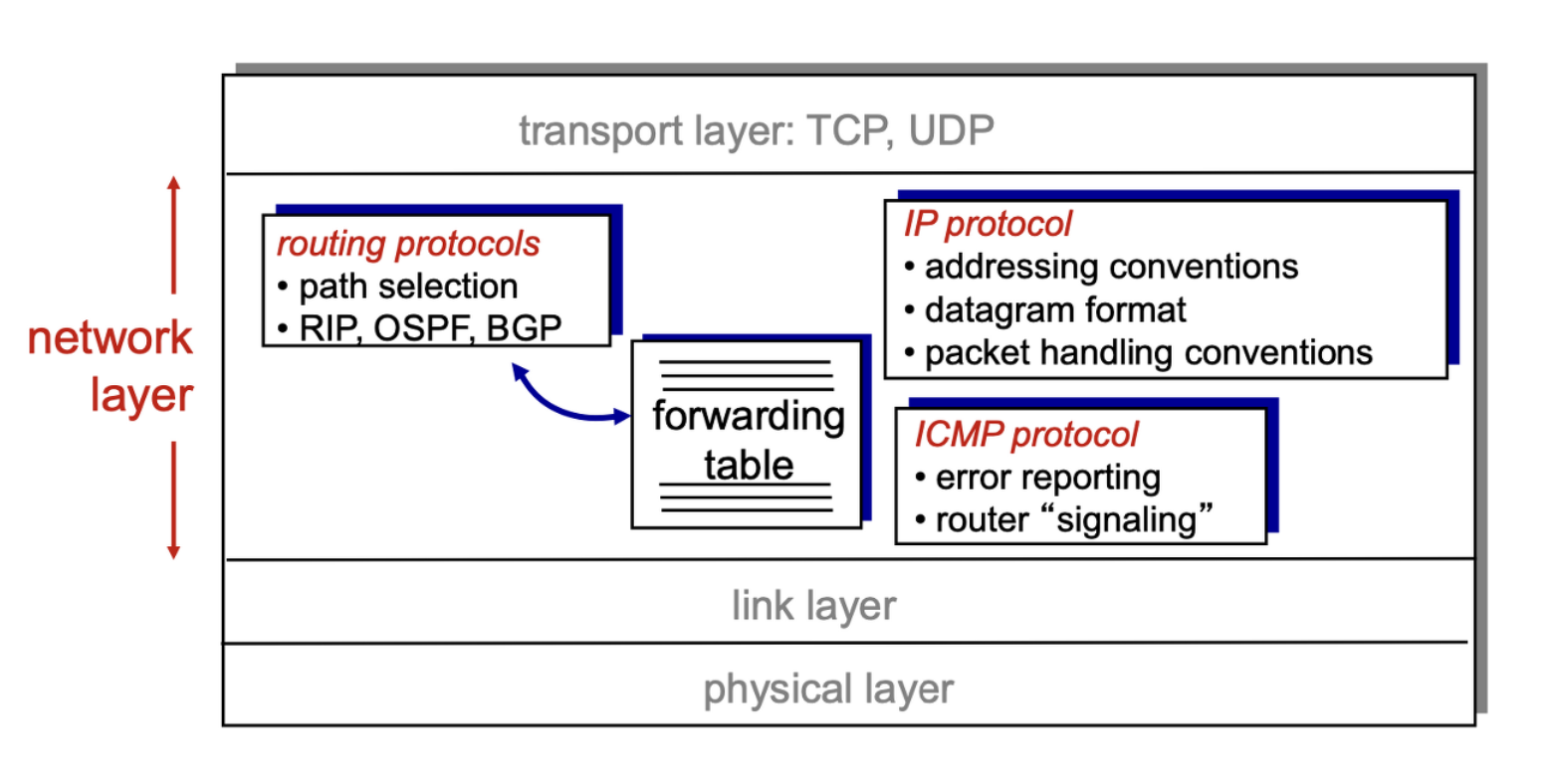
Router 는 IP 주소를 가지고 Routing 을 한다.
IPv4 Addressing
LAN,이더넷 등을 Interface 라고 한다. 호스트가 링크랑 연결하기 위한 Network 카드가 있을텐데 이걸 interface 라고 한다.
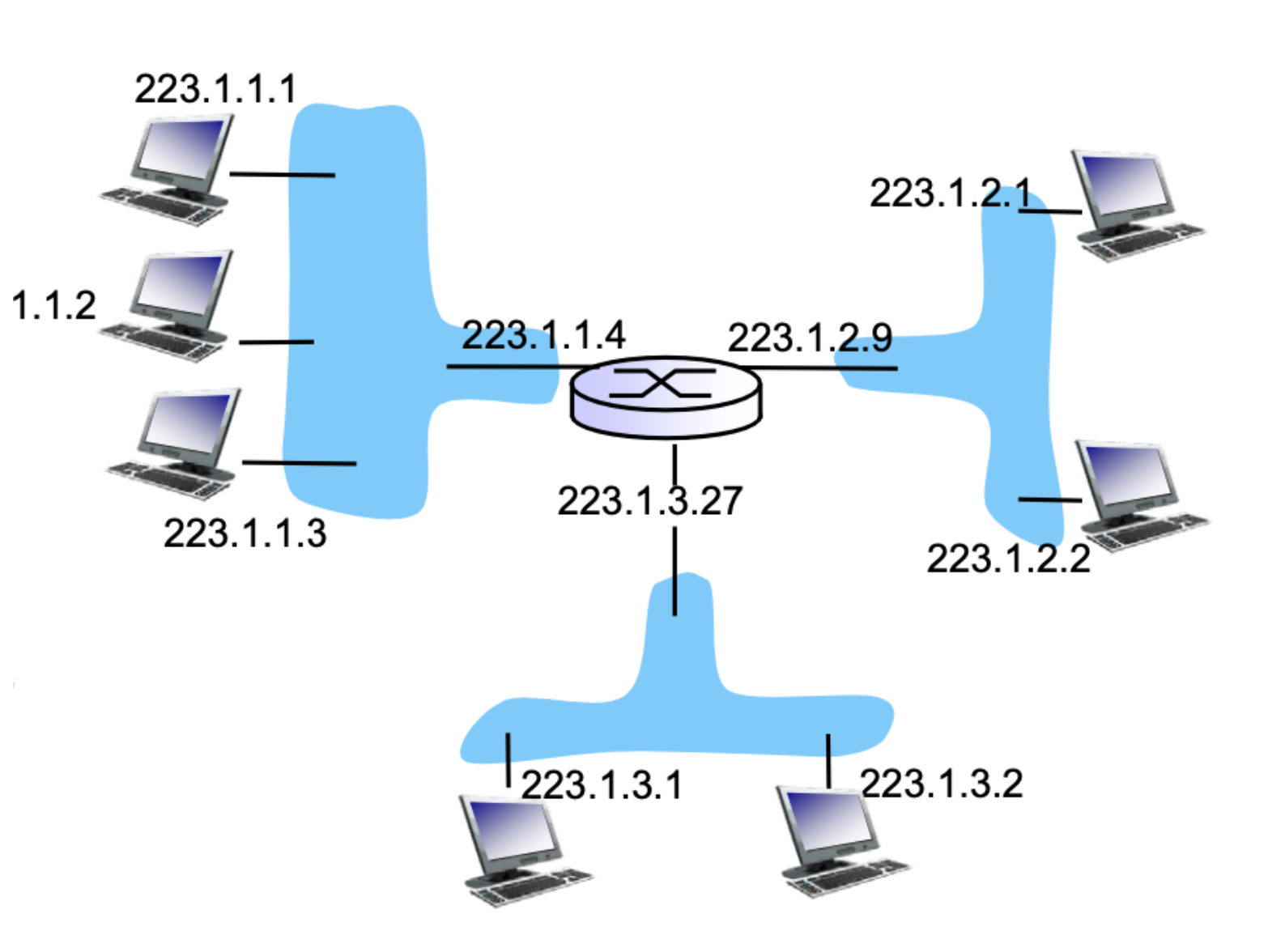
네트워크에서 사용하는 주소 체계는 IP 주소 체계이다.
IP주소는 호스트에 고유하게 할당되는 것이 아닌 내 호스트에 존재하는 인터페이스에 고유하게 할당되어야 하는 것입니다.
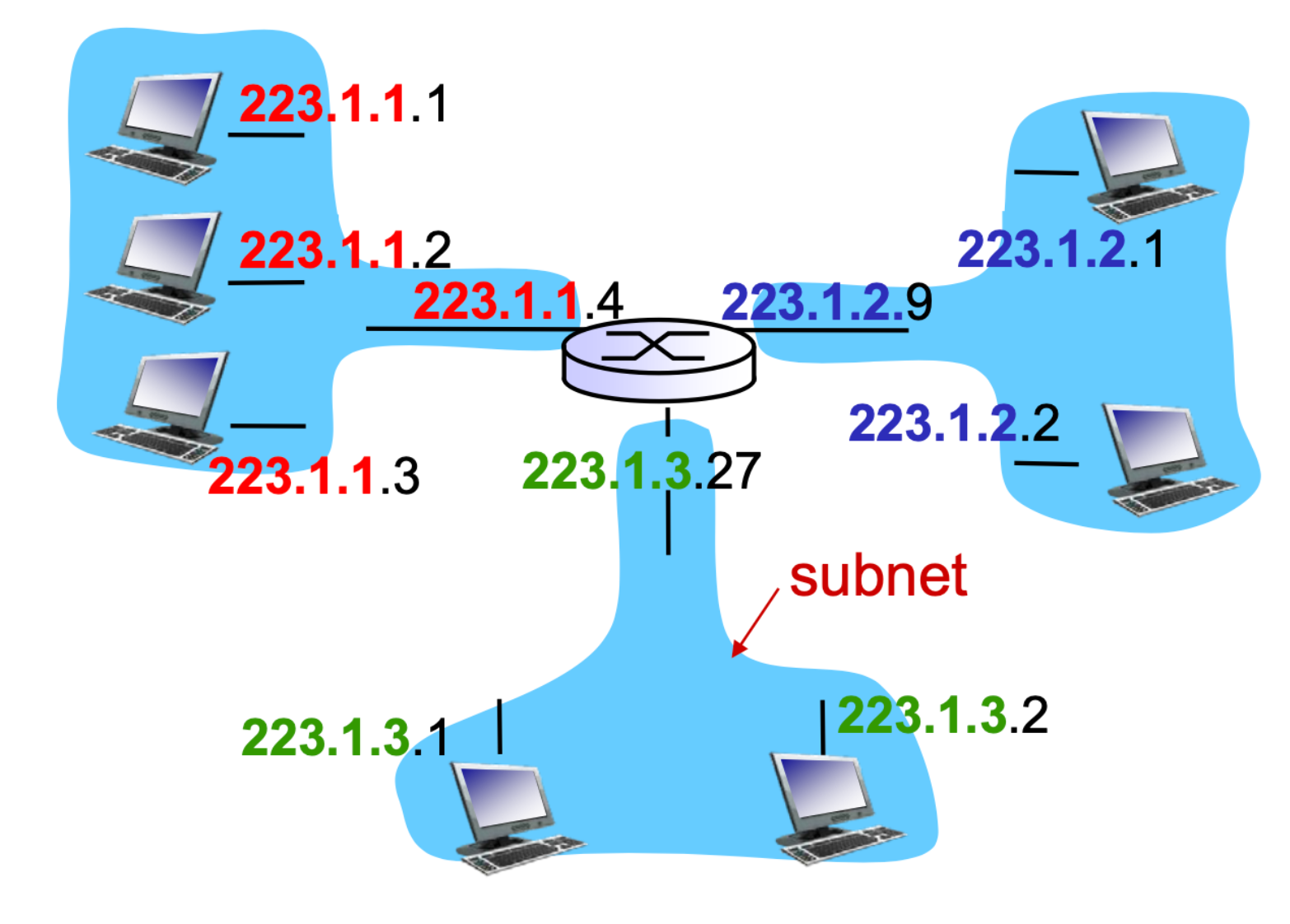
Subnets
subnet 은 network 를 구분 하기 위한 Section 이다.
host 는 동일한 네트워크 내에서 호스트를 구분하기 위한 섹션
subnet 파트가 정해지면(색깔 숫자), 그 나머지가 (검은 숫자) 로 정해진다.
DHCP(Dynamic Host Configuration Protocol)
인터넷에 처음으로 접속하게 된다면 IP 주소가 필요하다.
IP 주소를 할당할수 있는 방법으로는 2가지가 이쓴ㄴ데
직접 주소를 입력하거나 동적으로 IP 주소를 바당오는 DHCP Protocol 을 이용한다
DHCP가 자동으로 IP 주소를 할당해준다. 인터넷을 접속할떄 따로 IP 주소를 세팅하지 않아도 따로 자동적으로 IP 주소를 할당받은것.

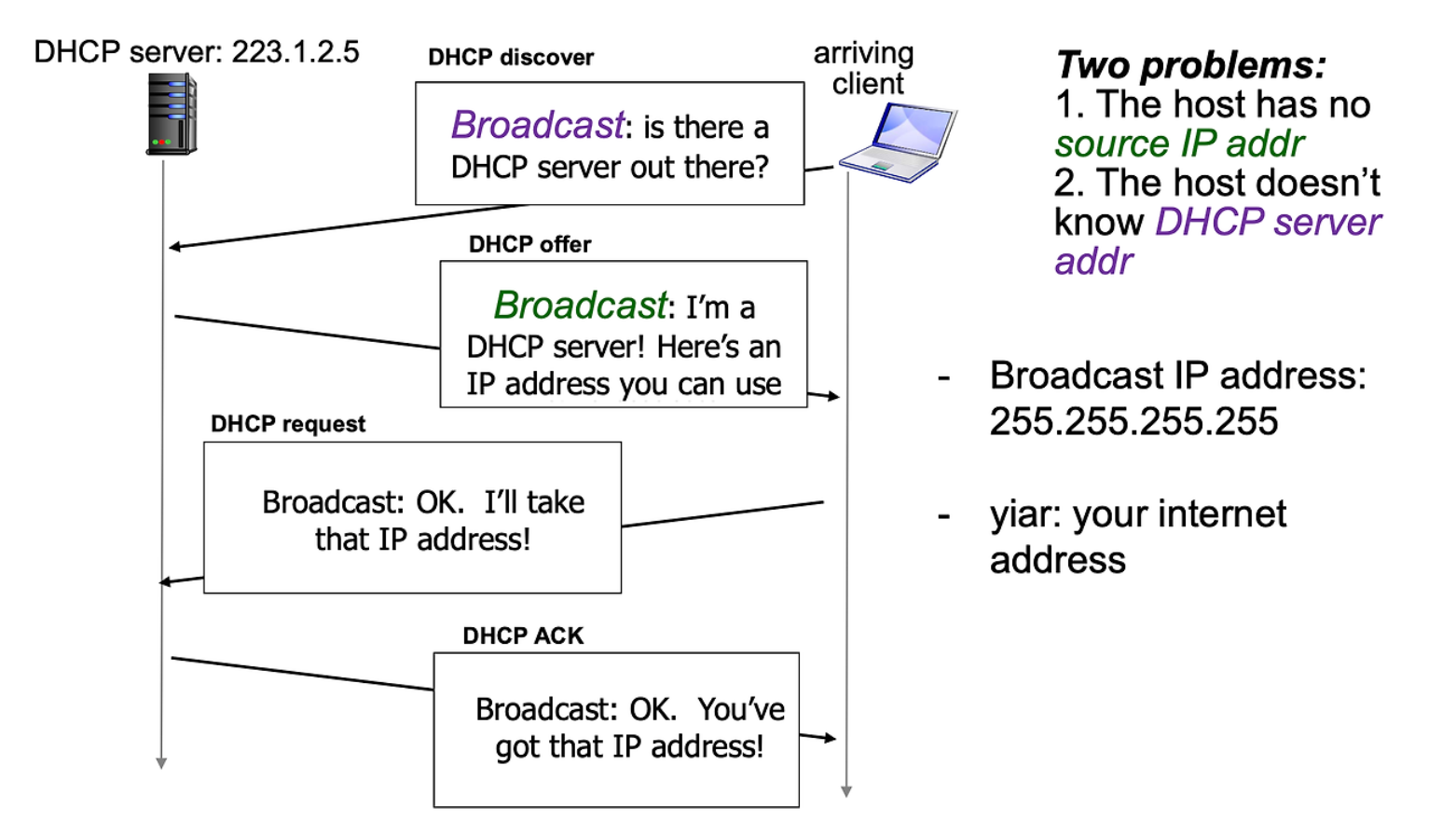
게이트웨이 주소나 DNS 서버 주소도 필수적으로 필요하다. 때문에 DHCP에서는 IP주소 할당 뿐만 아니라 게이트웨이 주소나 DNS 서버도 할당한다.
DHCP는 DNS 처럼 Application Layer 이고 UDP 를사용한다.
NAT(Network Address Translation)
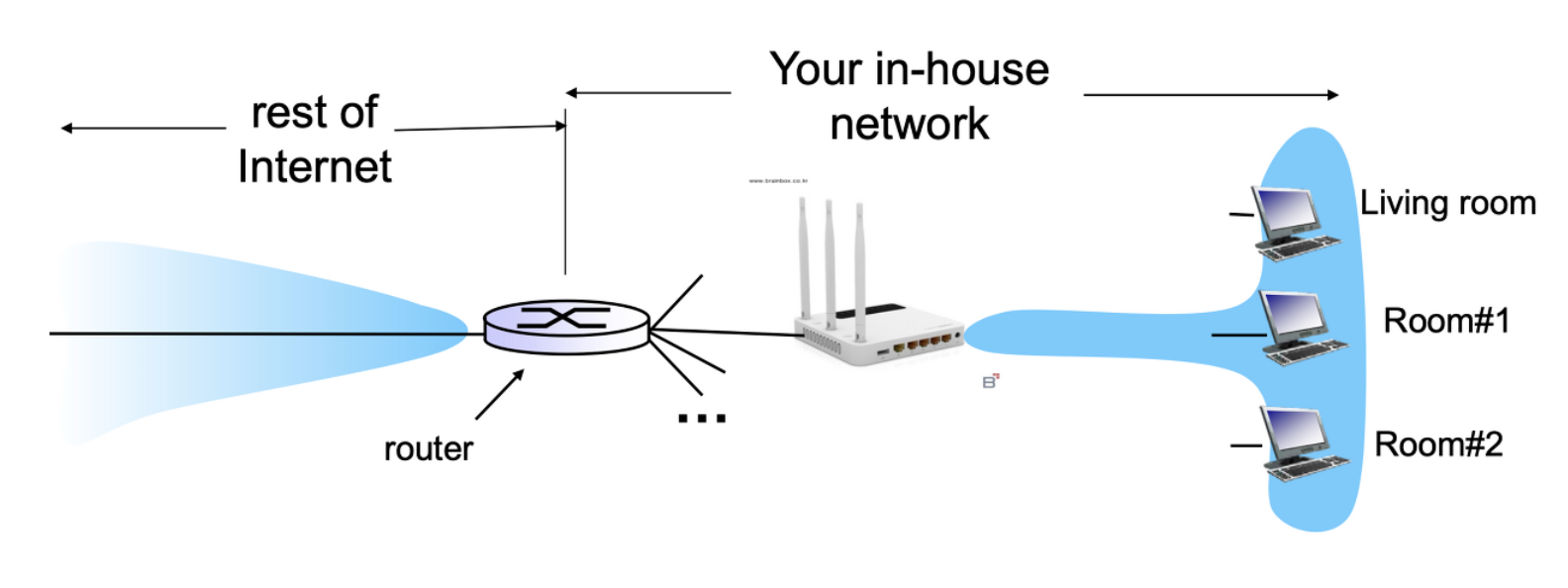
NAT 기술이 도입되어 IP주소를 할당받아 사용할수 있따.
NAT 는 하나의 External IP 주소로 하나의 Network 를 커버하게 해주는 기술
하나의 External IP 주소는 전세계에서 Unique 하게 구별되어야 하는 IP 주소
이와 같이 Local Network 에서 사용할 IP 주소도 필요한데 Internal = Private IP 주소들은 겹처도 된다.
External IP 주소를 아껴써야한다. Private 주소는 겹처도 되기 떄문.
문제는 Private Ip주소와 External IP 주소를 매핑 해줘야한다. 1 to N 매핑이다.
1to N 으로 매핑하면 나갈때는 상관없는데 들어올떄 local 디바이스를 찾아갈때 문제가 된다.
Router
라우터는 2가지 핵심 기능이 있다.
1.Routing Algorithm 을 수행한다.
2.Routing Algorithm 에 의해서 도출된 Forwarding Table 을 기반으로 실제 Forwarding 을 진행한다.
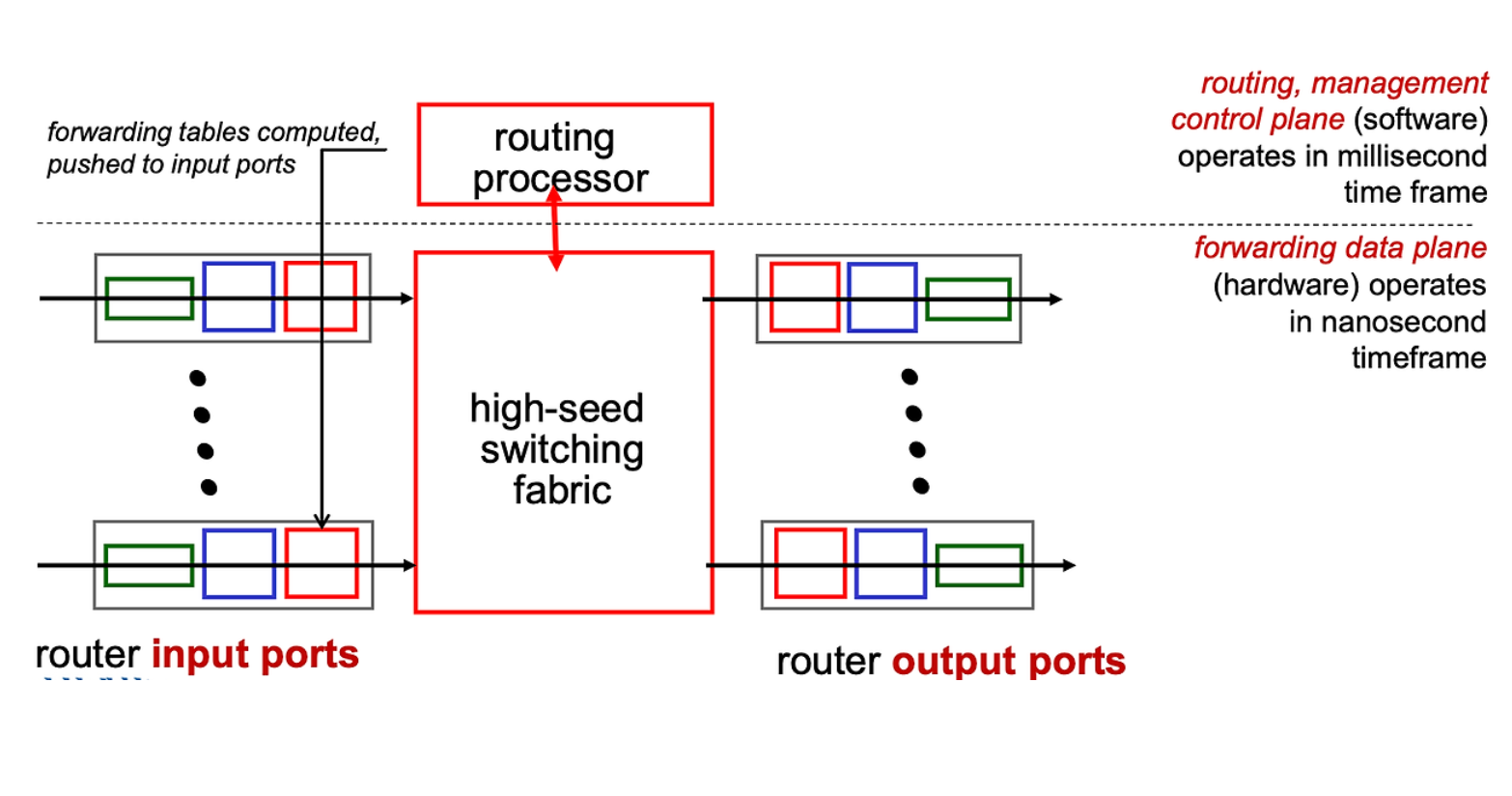
Routing Processor
control plane 에는 router processor가 탑재되어 있다. router processor 는 protocol 을 동작시키고 알고리즘을 동작시키고 forwarding table 을 계산한다.
processor에서 나온 forwarding table 은 data plane으로 넘어간다.
Data Plane
FOrwarding table 은 각각의 Input Port로 전달이 되게 된다.
Input Port는 Forwarding Table 을 Load 하고 들어오는 Datagram을 어떤 Output Port로 보낼지를 판단하고 전달한다.
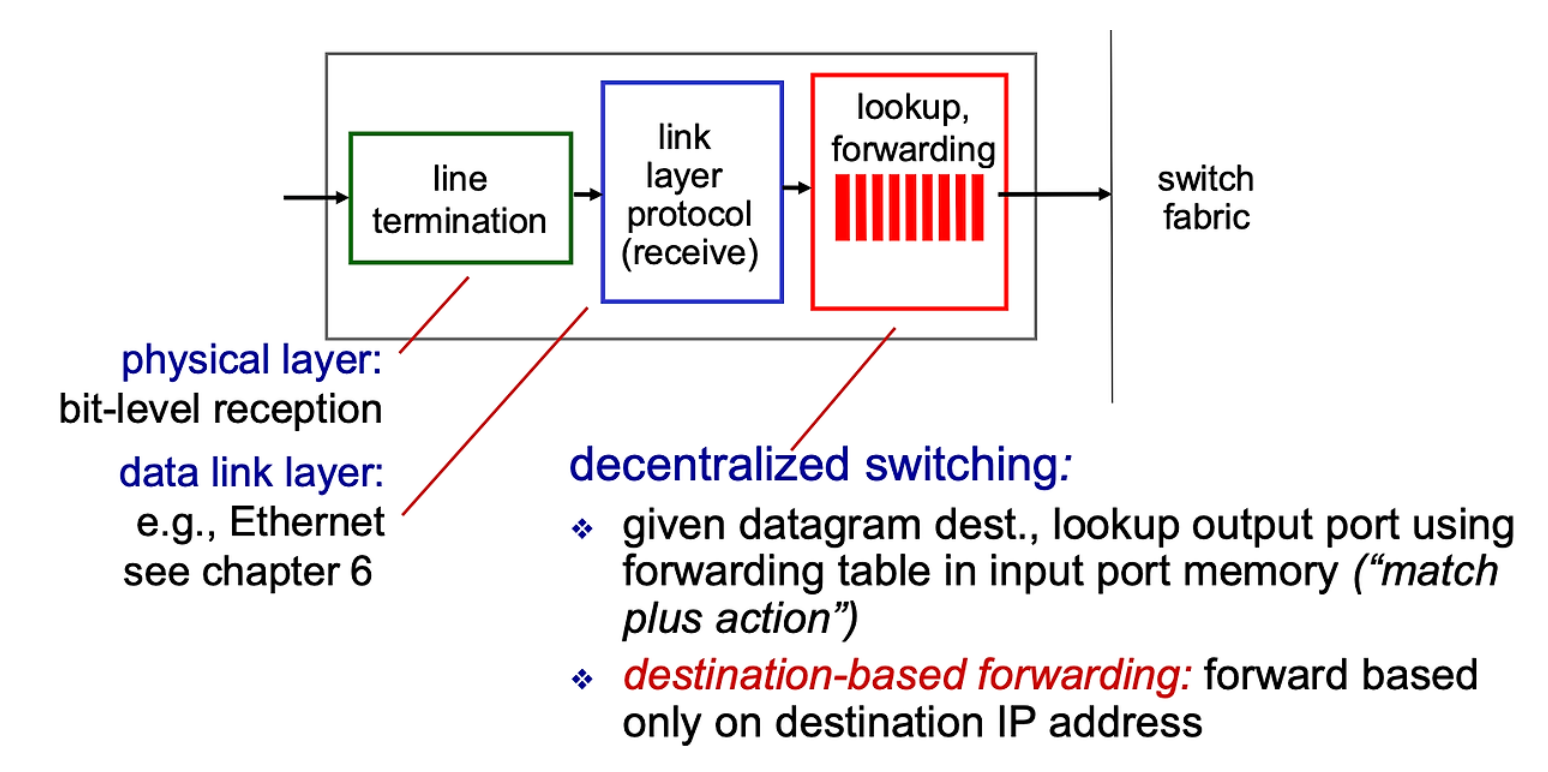
Destination 주소

Dest 주소는 이론적으로 2^32이 존재가능.
이 수많은 주소에서 몇 번 포트로 보낼지 판단하는건 연산 시간이 너무 오래 걸린다. 그래서 범위로 Forwarding Table 이 만들어 진다.,
Prefix Matching

Ip주소에서 Forwarding Table과 Subnet 주소에 해당하는 Prefix 만 비교하면 된다.Host부분을 볼 필요가 없다. 이걸 Prefix Matching 라고 한다.
Longest Prefix Matching

input , Output 연결하는 방법
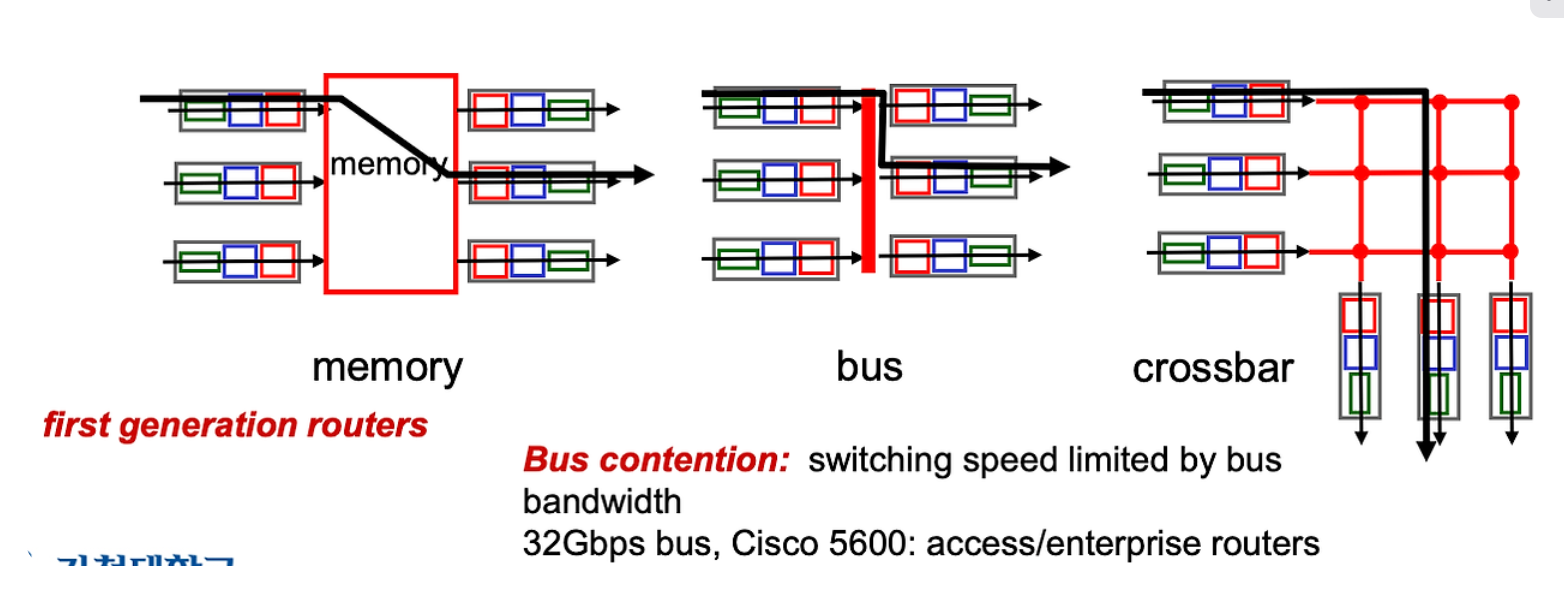
첫번째로는 중간에 메모리를 주는거다. 메모리에 임시저장을 하고 output Link 로 전달한다.
근데 메모리 자체도 비싸고 메모리에 보틀넥도 많이 발생해서 Forwarding 이 느려저서 1세대 router 에서 사용하는 방식이라한다.
두번째로는 중간에 Bus 를 두는 것.버스는 고속으로 데이터를 전달할수 있어서 효율적이지만 버스 링크를 여러 개의 input port를 쉐어하다 보니 실제로 큐잉이 발생하는 부분이 된다. 그래서 Traffic 이 물릴땐 버스에서 보틀넥이 발생한다.
마지막은 crossbar로 설계한 방식이다.
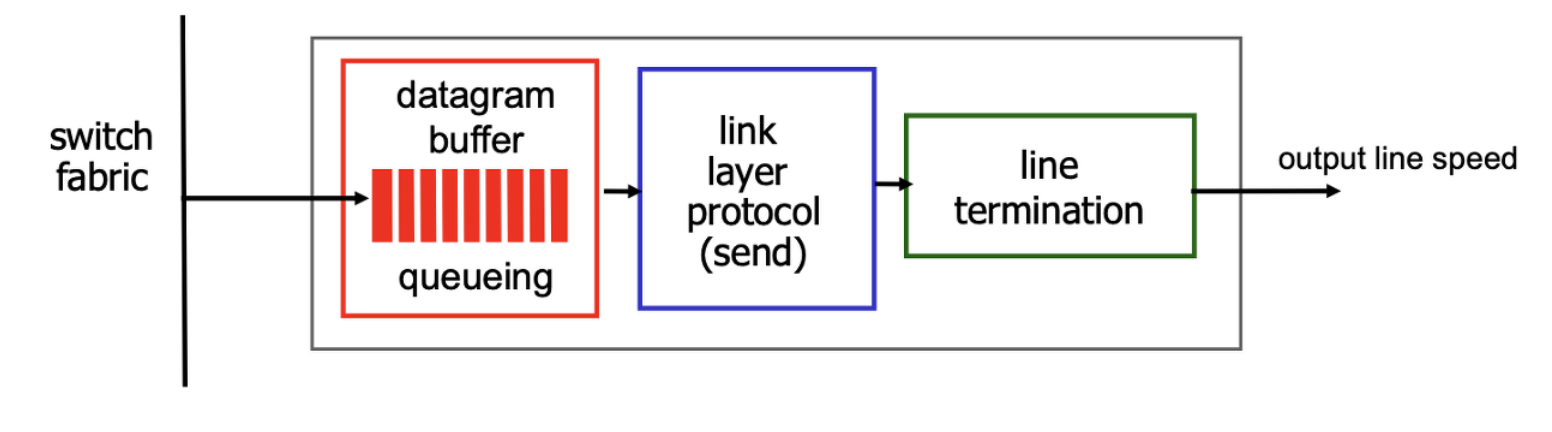
이렇게 output port 로 packet이 전달이 되면 packet 은 buffer에 임시로 머무른 다음에 Link Level Protocl 로 들어가 전파로 전달되게 된다.

이렇게 datagram 을 output Link 로 보내줘야하는데 링크 capacity 가 존재한다. link capacity보다 빠르게 내보낼 수 없다. 못 나가는 데이터들이 queueing 되어 대기하게 되고, 버퍼가 꽉찬 상태에서 새로운 데이터 그램이 들어오면 loss 발생하는거다.
Firewalls
firewalls 는 장벽 역할을 한다. 어떤 조직에 내부 네트워크를 바깥에 인터넷으로부터 보호하기 위한 용도로 사용하기 위한 장비다.
특정 Packet은 통과시켜주고 특정 Packet은 통과시켜주지 않는 식으로 외부 Traffic 을 차단해주는 역할을 한다.
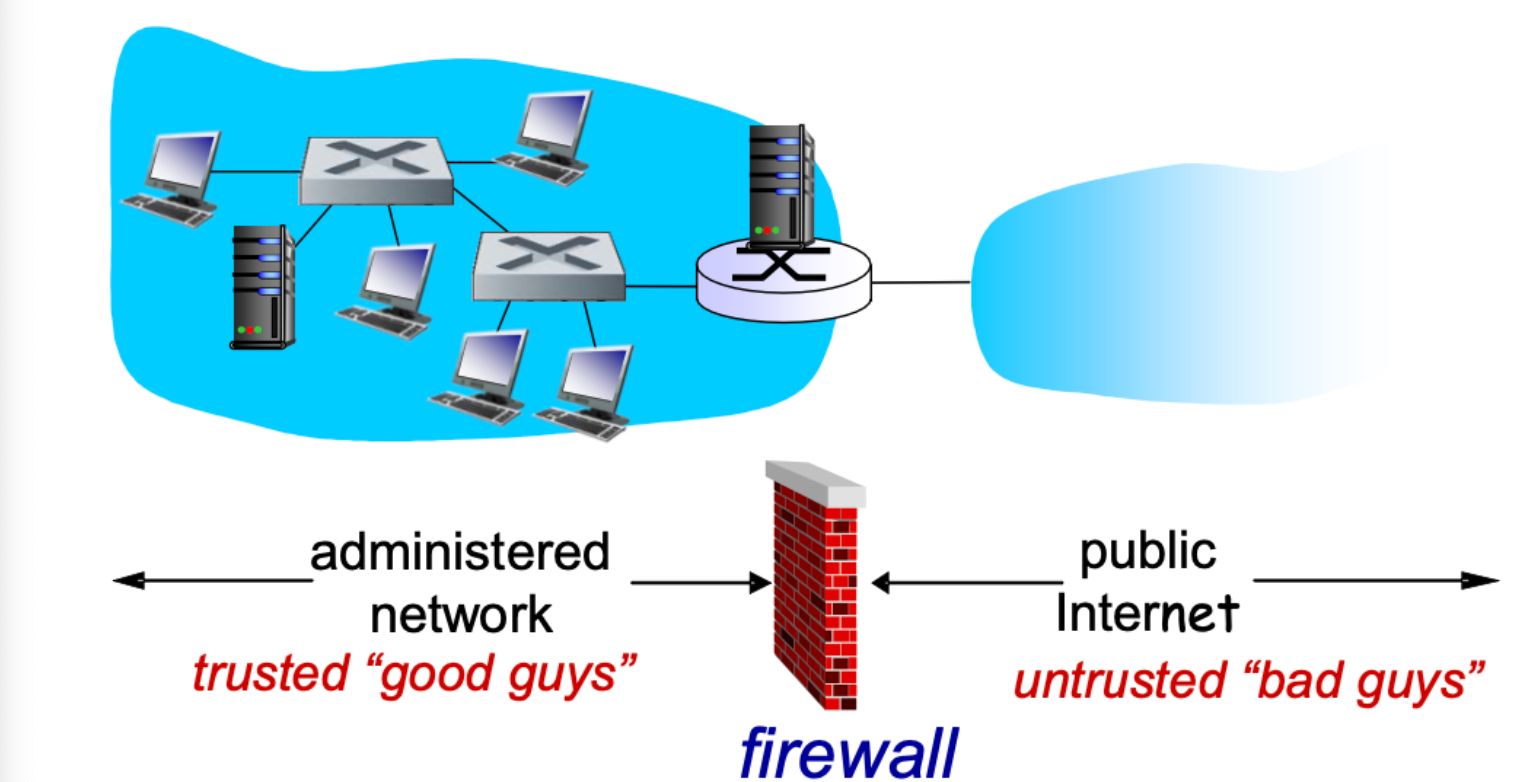
Gateway 방화벽이 설치되어 있는 경우가 많다. Gateway에 Firwall 이 설치되면 packet 단위 Packet으로 보면서 통과 여부를 관리한다.
Routing Algorithm
Global Infromation
산 전체에 대한 Topology 를 알고 어떤 경로로 가야 제일 빨라 가는지 계산한 후에 경로를 따라 가는것
근데 연산량이 많이 깨문에 전체 routing path 에 적용하는건 무리가 있다.
또한 Cost는 계속 변할수 있다.
Decentralized information
그래서 정보 획득 비용이 적고, 연산량도 적은 decentralized information 을 사용함.
하지만 이것도 최적의 경로를 보장하지 못하고 반복해서 실행하다 보면 최적으로 수렴하지만 시간이 너무 오래 걸린다. 최적의 경로가 목적이 아닌 적당히 반복해서 실행하다 보면 최적으로 수렴한다는 원리로 점진적으로 개선한다는 방향을 두고 적용하는 알고리즘
// global Information 은 Link State, Decentralized
// Information 은 Distance Vector 알고리즘이다.
Distance Vector 의 장점과 단점
Link Cost가 바뀌게 되면 node는 Local Link Cost의 변화를 감지한다. Distance Vector를 재계산하게 된다. 값의 변화가 있으면 이웃에게 알려줌
DV는 좋은 뉴스는 되게 빨리 전파된다 그래서 상대방의 DV 알고리즘을 빠르게 수렴시킨다라는 장점이있다.
단점은 Link Cost가 오히려 커진다. Link 가 끊어지면 무한대로 바뀔수도 있다.
DV vs LS
그래서 링크 스테이트 알고리즘은 각각의 노드들이 다른 모든 노드들과 이제 이야기를 하는 구조입니다.
바로 플로딩이라는 절차를 통해서 내가 갖고 있는 정보들을 다른 모든 노드에게 전파시키는 과정을 거치게 됩니다. 그래서 각각의 이제 링크의 코스트들을 이제 말해주는 거죠. 그 다음에 그렇게 해서 전체 토폴로지를 만든 다음에 우리가 배웠던 다익스트라 알고리즘을 각각의 노드들이 직접 돌리게 되죠. 그래서 각각의 노드들은 다익스트라 알고리즘을 통해서 모든 데스티네이션에 대해서 최적의 아웃풋 링크를 도출하게 됩니다. 그래서 나중에는 ip 주소만 보고서 얘는 몇 번 링크로 보내는 게 제일 좋다라는 거 바로 알 수 있죠.
디스턴스 벡터 알고리즘도 똑같이 이제 모든 데스트네이션에 대해서 이제 아웃풋 링크를 결정하는 건데 이제 방법이 좀 다르죠 각각의 노드들이 자신과 직접 연결된 이웃과만 소통을 합니다. 그래서 플로팅 모든 노드에 전파시키는 게 아니라 자기 노드한 자기 이웃 노드한테만 전파를 시킵니다. 그리고 이웃 노드는 자기 이웃 노드한테 받은 정보를 가지고서 디스턴스 벡터 매번 업데이트를 합니다. 그리고 그 업데이트한 결과를 가지고 라우팅을 매 순간 수행을 합니다. 업데이트할 때 이제 사용하는 이큐에이션은 우리가 벨만 포드 이큐에이션이다라고 이야기를 했었습니다.
