출처 - 김치남
운영체제
운영체제란 필요한 자원을 할당하고 사용자가 좀더 편리하게 컴퓨터 사용할수 있도록 환경을 제공해주는 프로그램이라고 한다....
결국은 하드웨어를 제어하고 소프트웨어를 위한 환경을 제공한다고 함
= 하드웨어를 조작하는 프로그램임
이러한 운영체제의 역할은
CPU 스케쥴링 관리
메모리 관리
디스크 파일 관리
입출력장치 관리
프로세스 관리 등등,, 이라고 한다.
커널
컴퓨터에서 실행될떄는 메모리에 올라가야하는데 운영체제 또한 메모리에 올라가게 된다. 그런데 운영체제 처럼 엄청 큰 규모의 프로그램이 메모리에 올라가게된다면 메모리 공간 낭비가 심할꺼임.
그래서 운영체제 중 항상 필요한 부분만을 전원이 켜짐과 동시에 메모리에 올려놓고 그렇지 않은 부분은 필요할 때 메모리에 올려서 사용하게 된다고한다.
이때 메모리에 상주하는 운영체제의 부분을 커널이라고 한다.
결국 메모리에 올라가있는 운영체제의 부분들임
System Call
운영체제 서비스를 제공받기 위해 커널 모드로 전환하는 방법.
커널 영역의 코드를 실행하고자 할 때 사용되는 인터페이스
프로세스가 하드웨어에 직접 접근해서 필요한 기능을 할 수 있게 해준다.
fork(),exit(),open() 등이 있다고 한다.
운영체제는 사용자가 실행하는 응용 프로그램이 하드웨어 자원에 직접 접근하는 것을 방지하여서 자원을 보호한다.
그래서 사용자모드 커널 모드로 나눠서 사용자 모드는 운영체제 서비스를 받을수 없는 모드이고 커널 모드는 운영체제 서비스를 제공받을수 있다고 한다.
Virtual Machine
소프트웨어 적으로 만들어낸 가상 컴퓨터. 독립적인 운영체제와 응용 프로그램들을 설치 할수 있다고 한다.
이러한 Virtual Machine 또한 프로그램임으로 사용자 모드로 작동
Driver
응용 프로그램과 커널의 인터페이스가 System Call 이라면 커널과 하드웨어의 인터페이스는 Driver가 담당한다.
하드웨어 제작자가 만든 소프트웨어를 디바이스 드라이버라고 한다.
하드웨어의 저수준 세부 정보를 추상화해서 응용프로그램에게 제공한다. 그래서 응용프로그램으로 하드웨어를 직접 관리하고 제어할수 있다고 한다.
Process
프로세스는 실행 중인 프로그램이다. 디스크에 있는 프로그램이 메몰에 올라가게 되면 프로세스가 된다.
실행중인 프로그램으로 사용자가 보는 앞에서 실행되는 Foreground process 와 사용자가 보지 못하는 뒤편에서 실행되는 Background process 두개가 있다고 한다. Background process 에는 Daemon 이라고 상호작용하지 않고 묵묵하게 정해진 일만 하는 게 있다고 한다.
또한 프로세스의 특정 시점의 상태를 표현하는 정보를 Process Context 라고한다.
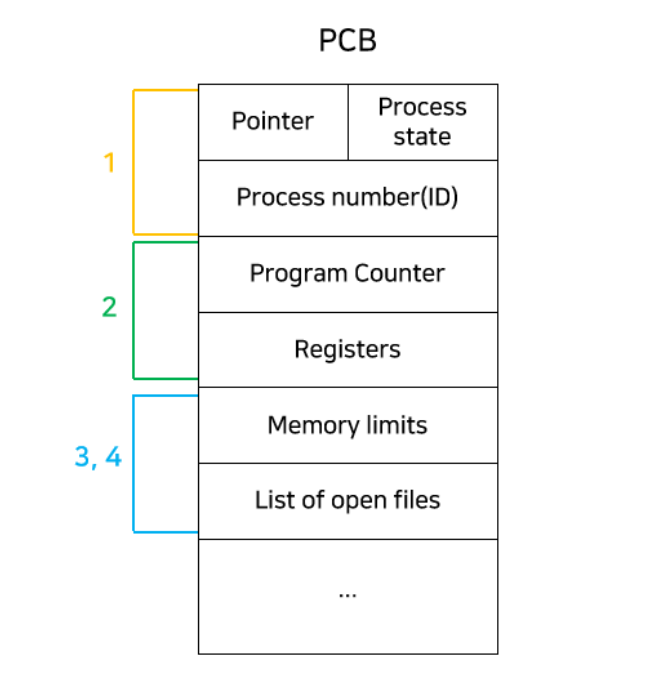
PCB
Process Control Block 으로 프로세스에 대한 메타데이터를 저장한다.
운영체제가 각 프로세스를 간리하기 위해. ㅡ로세스별로 보유하고 있는 자신의 정보 묶음이다.
프로세스 생성시에 커널 영역에 저장되고 종료시에 메모리가 반환되어서 삭제된다.

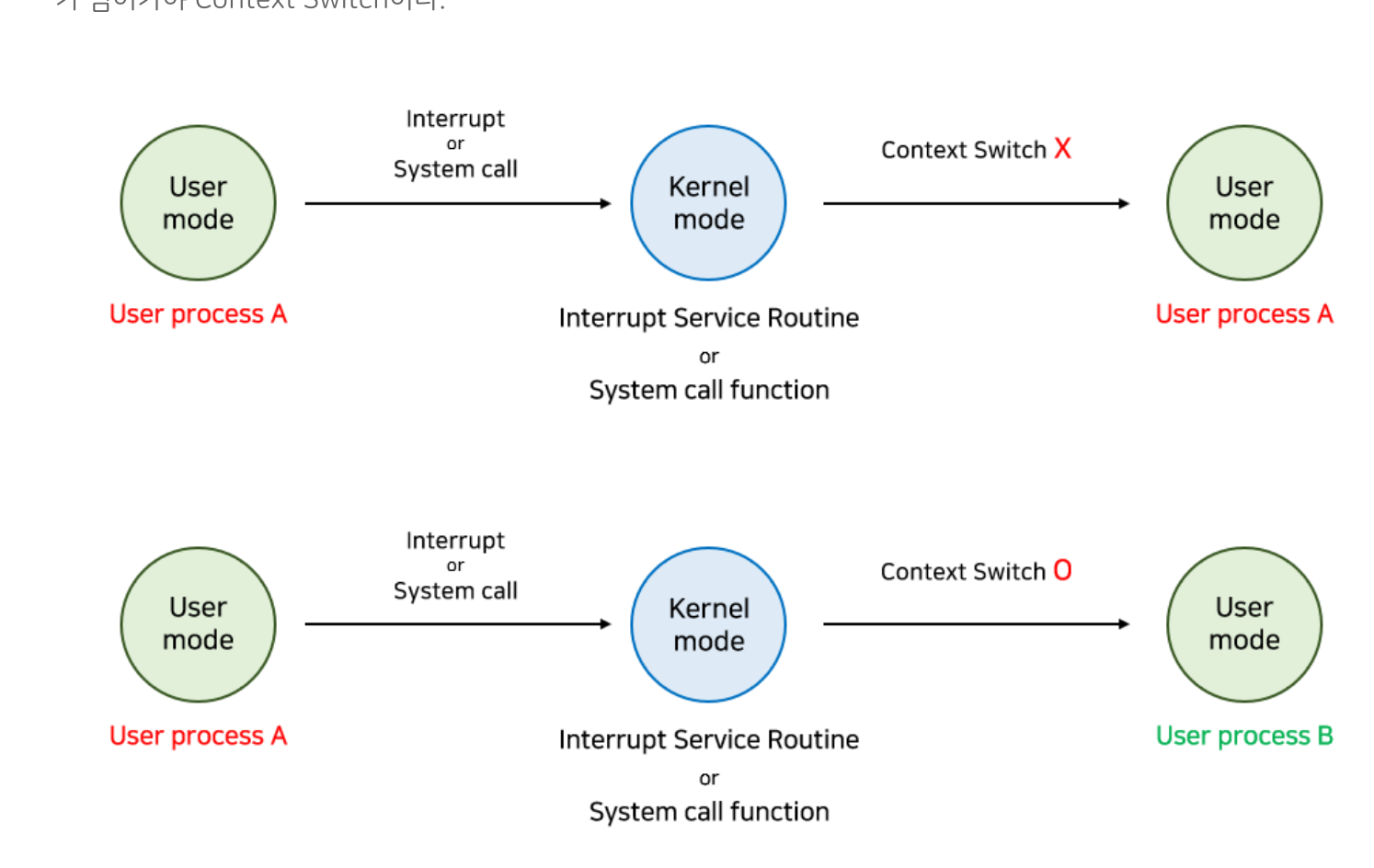
Context Switching
context 는 cpu 가 해당 프로세스를 실행하기 위한 해당 프로세스의 정보이다. 그리고 이러한 context 는 프로세스의 PCB에 저장된다.
cpu 가 어떤 하나의 프로세스를 실행하고 있는 상태에서 인터럽트 요청에 의해 다음 우선순위의 프로세스가 실행되어야 할때 기존의 프로세스의 상태 또는 Context를 저장하고 cpu 가 다음 프로세스를 수행하도록 새로운 프로세스의 상태 또는 context 를 교체하는 작업을 말한다.
결국 프로세스가 실행되고 있다가 interuppt 발생해서 CPU를 한 Process에서 다른 Process . 로넘겨주는 과정.
프로세스에서 프로세스가 넘어가야 Context Switching 이다.
프로세스의 메모리 영역
코드 영역은 실행할 수 있는 코드, 기계어로 이루어진 명령어가 저장
데이터 영역은 프로그램이 실행되는 동안 유지할 데이터
스택 영역은 데이터를 일시적으로 저장하는 공간
힙 영역은 사용자가 직접 할당할 수 있는 저장 공간
Memory Leak
메모리 공간 사용하고 반환하지 않는다면 할당한 공간은 계속 메모리에 남아서 낭비를 초래
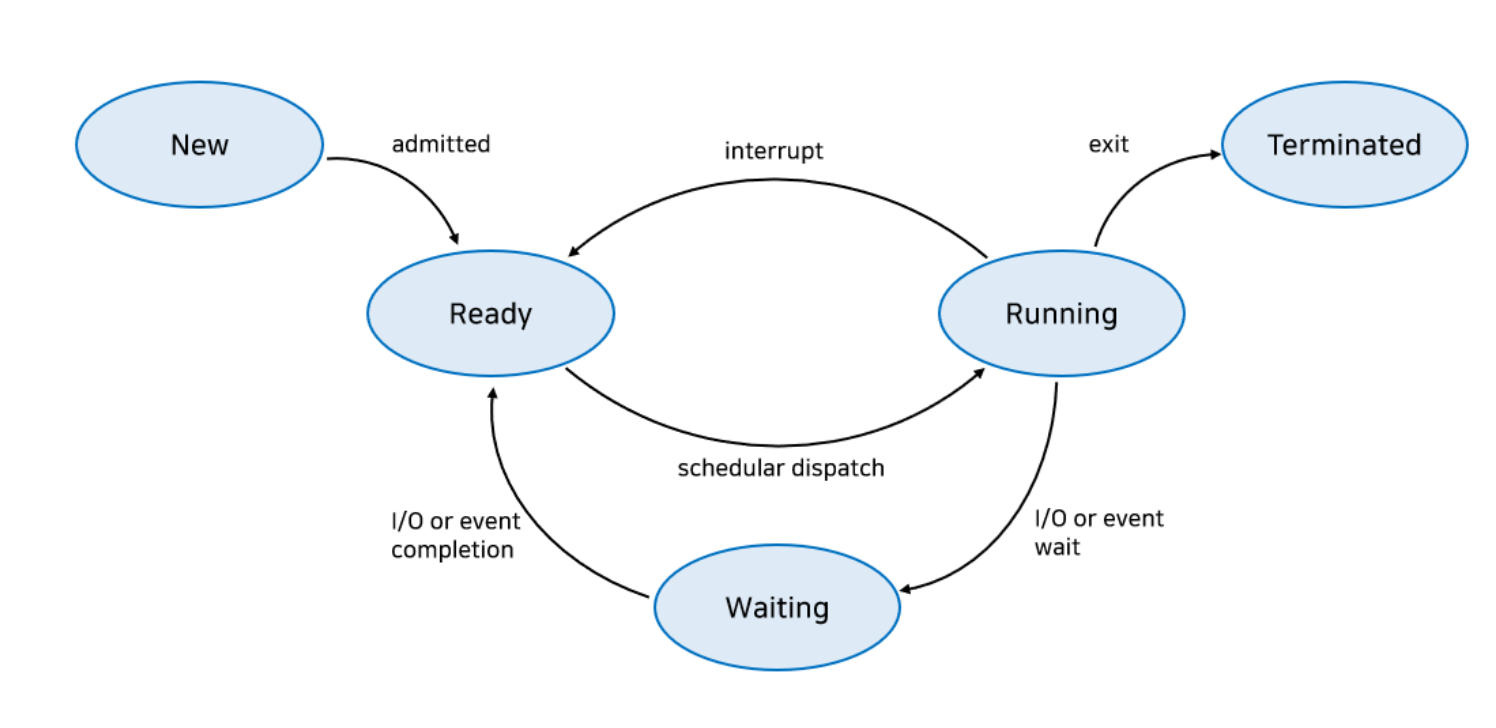
프로세스 상태
//생성
사용자가 요청한 작업이 커널에 등록되고 PCB 가 만들어져 프로세스가 만들어진 상태
Created -> Ready : 메모리 공간을 검사하여서 충분한 공간있으면 메모리 할당하고 준비상태로 바꿈
Created - > Suspended Ready : 공간이 없으면 메모리를 할당하지 않고 보류 준비로 바꿈
//준비
CPU를 할당 받기 위해 기다리고 있는 상태. CPU 만 주어지면 바로 실행할 준비가 된 상태이다.
Ready - > Running(Dispatch) : CPU 를 할당 받으면 실행 상태로 바뀌고 실행된다.
Ready - > Suspended Ready : 준비 상태 였다가 메모리를 뻇긴 상태
//실행
CPU 를 할당 받아 실행 중인 상태
Running -> Ready(Timeout) CPu를 할당 받아 실행하다가 시간 할당량을 소진하여 뻇긴 상태
RUnning -> Blocked: 실행 상태의 프로세스가 입출력이 필요하게 되어 시스템 호출을 하고, 입출력 처리의 종료를 기다리는 상태. 이때 CPU 는 바로 준비 상태의 프로세스 하나를 선택해 실행한다.
// 대기
프로세스가 실행되다가 입출력 처리를 요청하거나, 바로 확보될 수 없는 자원을 요청하면 CPU를 양도하고 요청한 일이 완료되기를 기다린다.
Blocked -> Ready : 입출력이 완료되어 CPU 할당을 기다리는 상태
Blocked - > Suspended Blocked : 메모리의 여유 공간 확보를 위해 대기 상태에서 메모리를 뺏겨 보류 대기 상태로 바뀜
// 종료
프로세스가 종료될 떄 아주 잠시 거치는 상태
모든 자원이 회수되고 PCB를 삭제한다.
프로세스 계층 구조
부모 프로세스 : 새로운 프로세스를 생성한 프로세스
자식 프로세스 : 부모 프로세스에 의해 새롭게 생성된 프로세스
최초 프로세스 : 모든 프로세스 중 최상위 계층에 있는 프로세스로 1번 PID 를 가진다.
IPC
Inter Process Communication : 프로세스 간에 데이터를 주고 받고 상호작용하기 위한 매커니즘
일단 프로세스는 완전하게 독립된 실행 객체.
독립되어있다는것은 서로의 영향이 미치지 않는 장점이 있다. 하지만 독립되어있는 만큼 서로간에 통신이 어려움
이를 위해서 커널영역에서 IPC 라는 내부 프로세스간 통신을 제공.
프로세스는 커널이 제공하는 IPC 설비를 이용해서 통신가능.

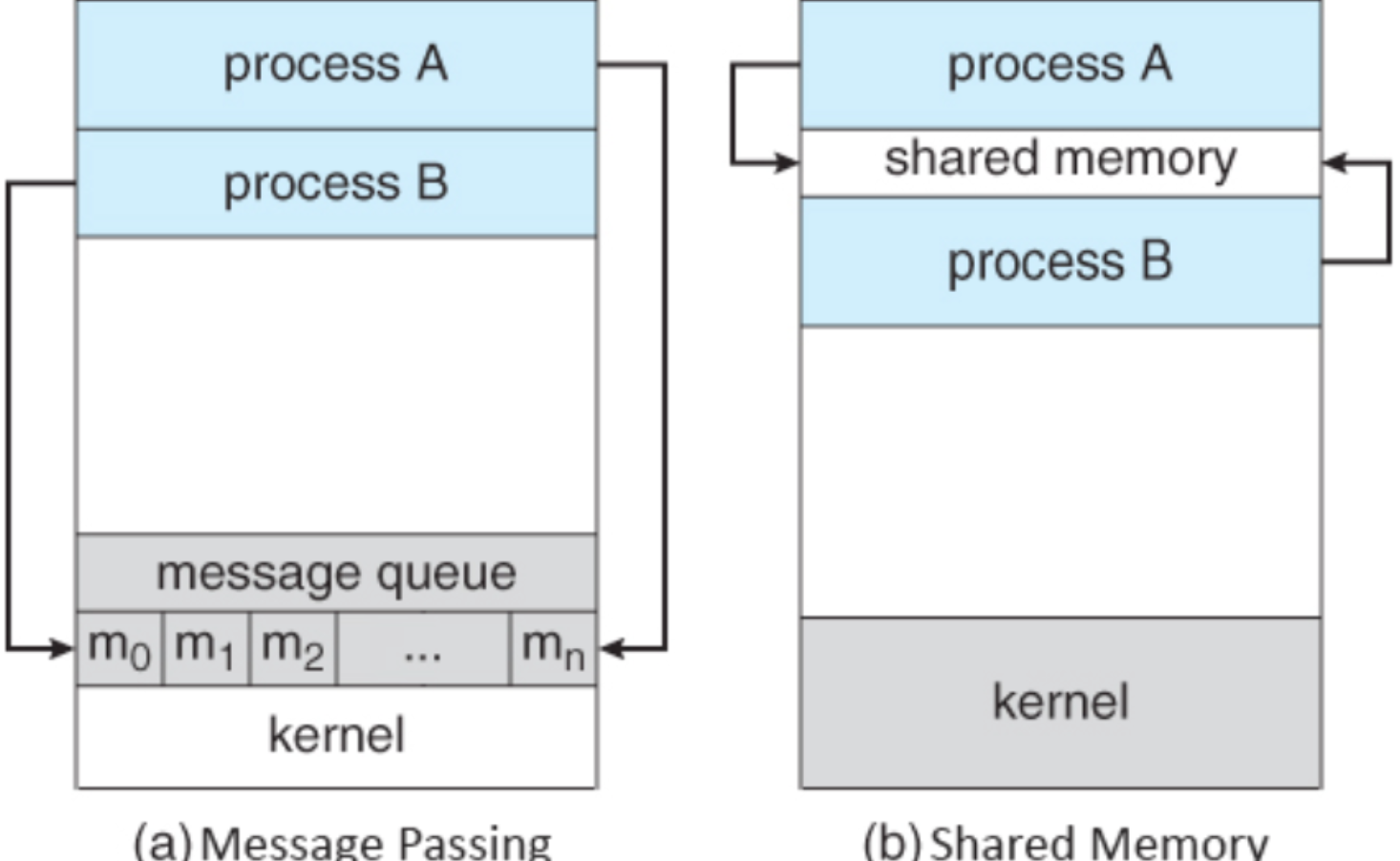
메세지 전달 - 커널이 제공하는 API 를 이용해서 커널 공간을 통해 통신한다.
메모리 공유 - 프로세스끼리 특정 공통의 메모리 영역을 공유하며 상호간 통신하는 방법
Thread
프로세스 하나만을 사용해서 프로그램 실행하기에는 메모리의 낭비가 발생한다.
스레드는 프로세스와 다르게 스레드 간. ㅔ모리를 공유하며 작동한다.
스레드는 결국 프로세스가 할당받은 자원을 이용하는 실행흐름의 단위.
프로세스 내부에서 실행되는 작은 작업 단위, 프로세스는 최소 1개 이상의 스레드를 가진다.
스레드는 프로세스 내에서 각기 다른 스레드 ID,레지스터 값, 스택 영역 가지며 콛,데이터,힙 영역을 공유한다.
실행에 필요한 최소한의 정보만을 유지
Multi Process vs Multi Thread
Multi Process 는 여러 개의 프로세스를 동시에 실행하는 것이고
Multi Thread 는 여러 스레드로 프로세스를 동시에 실행하는것
Multi Processing 은 여러개의 프로세스를 동시에 실행하고 프로세스 서로가 메모리 영역에 직접 접근을 할수 없어서 높은 격리와 안정성을 제공한다.
그래서 하나의 프로세스에 문제가 생겨도 다른 프로세스에 영향을 주지 않는다.
메모리공간이 많이 필요하고 Context Switching 오버헤드가 크다
Multi Threading 은 여러 스레드로 프로세스를 동시에 실행하니까 서로의 메모리 공간을 공유하게 된다. Context Switching 오버헤드가 적고 프로세스에 비해 스레드를 생성하는 시간은 빠르다고 한다.
하나의 스레드에서 발생한 문제가 다른 스레드에 영향을 줄수 있음으로 데이터 일관성 유지와 동기화가 중요하다.
CPU 스케쥴링
운영체제가 프로세스들에게 공정하고 합리적으로 CPU 자원을 배분하는것.
프로세스마다 우선순위가 다르기 떄문에 스케쥴링이 필요하다.
I/O Bound Process,CPU Bound Process
I/O Bound Process 는 I/O Burst 비율이 높은 프로세스
CPU Bound Process 는 CPU Burst 비율이 높은 프로세스이다.
우선순위는 I/O 가 CPU 보다 높으며 우선순위는 PCB에 명시된다고 한다.
Ready Queue , Waiting Queue
Ready queue 는 CPU 소유권을 갖고자 하는 프로세스들이 서는 줄
Waiting Queue 는 입출력 장치를 이용하기 위해 대기 상테에 접어든 프로세스들이 서는 줄 // 입출력이 완료되어서 인터럽트가 발생하면, 운영체제는 해당 Waiting queue 에서 작업이 완료된 프로세스를 찾아 Ready queue 로 이동시킨다고 한다.
Preemptive & Non-Preemptive
Preemptive Scheduling 은 프로세스가 CPU 를 사용하고 있더라도 운영체제가 프로세스로 부터 CPU 소유권을 강제로 뺴앗아 다른 프로세스에게 할당할 수 있는 스케쥴링 방식

Non-Preemptive Scheduling 은 하나의 프로세스가 CPU 소유권을 갖고 실행중인 경우, 해당 프로세스가 종료되거나 스스로 Blocked 상태에 접어들기 전 까지는 다른 프로세스가 끼어들수 없다.
CPU Scheduler, CPU Dispatcher
CPU Scheduler 는 CPU 스케쥴링 알고리즘이 적혀있는코드
CPU DIspatcher 는 새롭게 선택된 프로세스가 CPU를 할당받고 작업을 수행할 수 있도록 환경설정을 하는 운영체제의 코드
FCFS
First Come First Serve의 의미로 Ready QUeue 에 먼저 들어온 Process 부터 CPU 소유권을 할당한다.
Convoy Effect 가 발생할수 있다.
Convoy Effect
실행시간이 짧은 프로세스가 실행시간이 긴 프로세스에 의해 기다리게 되어서 평균 대기 시간이 증가하는 현상이다.
SJF
Shortest Job First 의 의미로 Ready queue에 삽입된 프로세스들 중 CPU 이용 시간의 길이가 가장 짧은 프로세스 부터 CPU 소유권을 할당하는 방식
평균 대기 시간이 가장 짧고 Starvation 발생 할수도 있다.
실행 시간 예측이 어려워, 과거로 부터 얻은 정보를 기반으로 실행 시간을 예측한다.
Starvation
우선순위가 낮은 프로세스가 Ready queue에 계속 머물러있음에도 불구하고 우선순위가 높은 프로세스에 의해 연기되어서 CPU 자원을 할당 받지 못하는 현상
Aging
프로세스가 Ready queue 에 머물렀던 시간에 따라 우선순위를 높이는 방법으로, 우선순위가 낮은 프로세스의 Starvation 을 방지할수 있다.
HRN
Highest Response Ratio Next: 프로세스의 대기 시간과 CPU 이용 시간을 고려하여 응답 시간을 최적화하는 스케쥴링 기법
RR
Round Robin Scheduling : 각각의 프로세스들에게 동일한 타임 슬라이스를 할당하여 CPU 소유권을 주고, 해당 시간 내에 작업을 끝내지 못하면 Readdy QUEUE의 맨 뒤로 이동하게 된다.
타임 슬라이스의 크기가 중요하다.
너무 길면 FCFS 처럼 Convoy Effect 가 발생할수도 있고
너무 짧으면 Context Switching 이 자주 발생하여 성능이 저하될 수 있다.
SRT
Shortest remaining time First: CPU 이용 시간이 더 짧은 프로세스가 중간에 들어오면, 현재 수행중인 프로세스를 중지하고 해당 프로세스에게 CPU 소유권을 할당한다.
SJF 스케쥴링링 알고리즘의 선점형 버전
Multi Level Queue
다단계 큐: 우선순위별로 Ready queue를 여러개 사용하는 스케쥴링 방식으로 각각의 Ready queue는 서로 다른 스케쥴링 기법을 사용할수 있다.
우선순위가 가장 높은 큐에 있는 프로세스 부터 순차적으로 처리하는 방법으로 상대적으로 우선순위가 낮은 큐에는 Starvation 이 발생할수도 있다.
프로세스들이 큐 간 이동이 불가하다.
MUlti Levle Feedback Queue
다단계 피드백 큐: 프로세스들이 큐 간 이동이 가능하다

Synchronization
Synchronization 은 멀티 스레드, 멀티프로그래밍 환경에서 일어나는 문제들을 해결 하는 방법이다. 두개 이상의 프로세스들이 Shared Memory 에 접근하려는 경우 레이스 컨디션이 발생한다. 이러한 상황을 해결해줘야한다.
두개 이상의 멀티 스레드가 사용되는 멀티 프로그래밍 환경에서 SHared Data 를 사용하는 경우 동기화가 필요하다. - >. 스레드들의 실행순서를 조절하기 위한 것.
공유 데이터의 동시 접근은 데이터의 불일치 문제를 발생시킬수 있다.
실행 순서 제어를 위한 동기화 - 프로세스가 올바른 실행 순서로 실행 되는것
상호 배제를 위한 동기화 - Critical Section 에 동시에 접근하지 못하도록 하는 것// race condition 이 발생하지 않도록 하는 것

Shared resource
공유 자원으로 여러 프로세스 또는 스레드가 동시에 접근할 수 있는 메모리,코드,변수 등의 자원을 의미한다.
공유 자원은 공동으로 이용되기 때문에 누가 언제 데이터를 읽거나 쓰느냐에 따라 그 결과가 달라질수 있다. 이를 데이터 불일치라고 한다. 2개 이상의 프로세스나 스레드가 공유 자원을 병행해서 읽거나 쓰는 상황을 Race Condition 이라고 한다.
Critical Section
Critical Section 은 코드 상에서 경쟁 상태가 일어날 수 있는 특정 부분을 말한다.
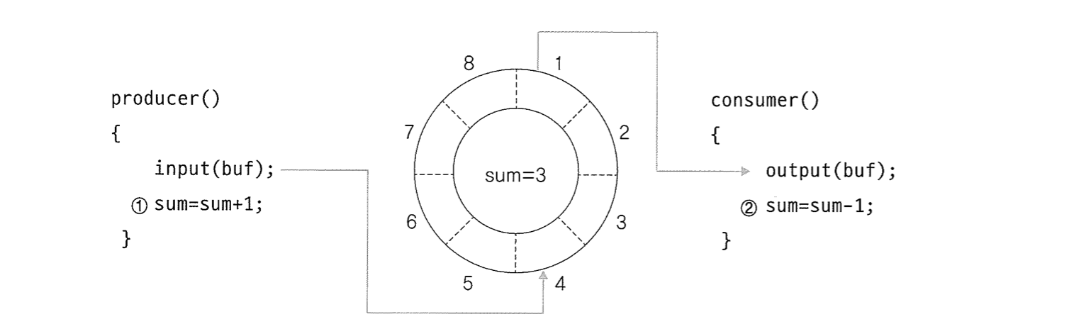
그림 처럼 생산자와 소비사가 서로 SUM의 값에 접근해서 바꾸려 할 떄 접근 순서에 대한 처리를 하지 않으면 예상치 못한 결과가 나올수 있따. 그래서 SUM의 값을 조작하려는 부분을 임계구역이라고 한다.
Critical Section Problem
임계 구역 문제를 해결하는 방법은 여러가지인데 어떤 방법이든 3가지 조건을 만족해야한다.
// Mutal Exclusion(상호배제)
한 프로세스/스레드가 Critical Section 에 들어가면 다른 프로세스/스레드는 Critical Section 에 들어갈 수 없다.
// Bounded Waiting(한정대기)
어른 프로세스/스레드도 Critical Section 에 진입하지 못하여 무한 대기 하지 않아야한다.
// Progress Flexibility(진행의융통성)
임계 구역에서 작업중인 프로세스/스레드가 없다면 언제든 들어와서 작업할 . 수있어야한다. 즉. Critical Section이 비어있기만 하다면 . 한 프로세스/스레드가 다른 프로세스/스레드의 영향을 받지 않고 Critical Section에 들어와 작업 할수있어야한다.
임계 구역 문제를 해결하는 단순한 방법은ㅇ LOCK 이다.
임계구역 들어가기 전에 해당 구역 진입 지점을 잠구고 작업이 끝나면 Lock 을 해제해서 동시에 동기화 신호를 보내서 다른 프로세스/스레드가 들어와도 좋다는 사실을 알려 임계 구역 문제를 해결할수있다.
Mutal Exclusion

현재 P1에서 while(lock==true) 를 통과하고 lock=true 를 실행하기 전에 Context Switching 이 일어나면 p2도 while(lock=true) . 를통과하게 돼서 임계구역으로 들어오게 된다.
Bounded Waiting
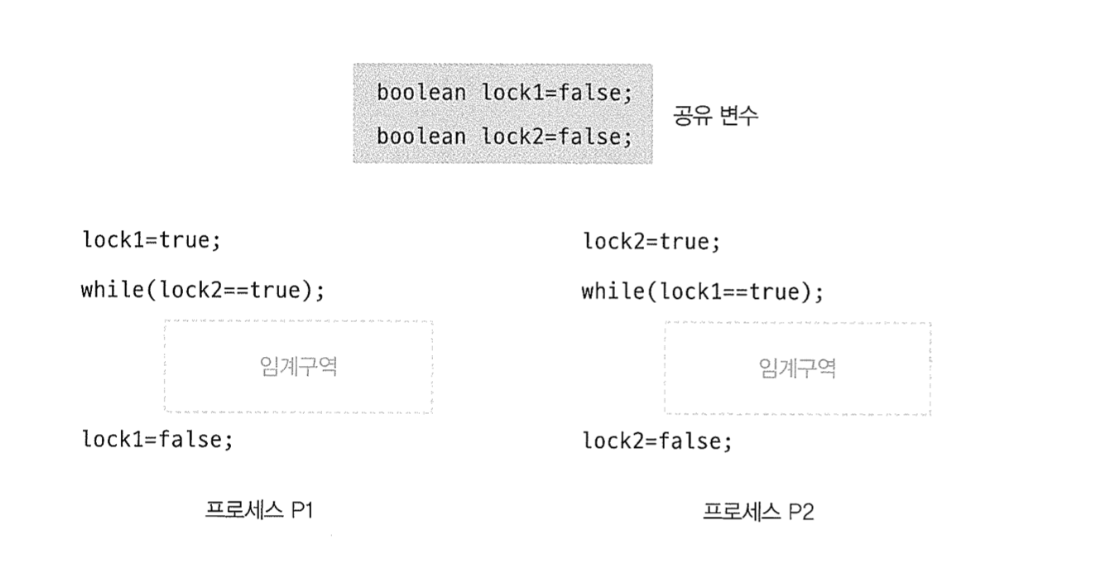
p1의 lock1=true 를 실행하자마자 context Switching 이 발생해서 p2로 넘어가고 p2의 lock2=true를 실행하자마자 context switching 이 발생했다면 p1,p2 둘다 무한루프에 걸려서 Critical Section 에 접근하지 못한다. 둘다 무한 대기해버림.
Progress Flexibility

이건 상호배제,한정대기 조건을 충족한다. 하지만 진행의 융통성을 충족하지 않는다. p1 이 끝나면 무조건 p2 가 실행되어야 하고 p1 이 끝나고 또 다시 p1이 실행될수 없기에 임계구역이 비어있다면 어떤 프로세스/스레드도 들어올수 있어야한다는 진행의 융통성 조건을 충족하지 못한다.
Race Condition
경쟁 상태로 공유자원에 대해 여러 프로세스가 동시에 접근을 시도할 때, 타이밍이나 순서 등의 결과값에 영향을 줄 수 있는 상태// Critical Section에서 발생한다
Mutex
상호 배제를 위한 동기화 기법 중 하나로, 어떤 프로세스가 공유 자원을 사용할 때는 Lock 을 통해 잠금을 걸어두고, 사용한 후에는 Unlock 을 통해 잠금을 해제한다.
공유자원에 Lock 이 설정되어있으면 다른 프로세스가 해당 공유자원에 접근하지 못한다.
임계구역에 진입할 떄 열쇠를 받고 나올 떄 열쇠를 반납하는 개념이다.
열쇠를 얻는과정 acquire lock 과 열쇠를 반납하는 과정 release lock이 필요하다.
이때 aquire and release 함수 내부에서 중단된 후 context switching 이 일어나면 안된다.

Busy Waiting

acquire 함수에서 어떤 프로세스가 Critical Section 에 접근하기 위해서는 열쇠가 Release 될떄까지 무한 루프 해야하는 문제이다.
만약 Single Core일 경우 Busy Waiting의 무한 루프는 CPU를 쓸데없이 소모시키므로 다른 프로세스가 생산적으로 사용 할 수 있는 시간을 감소시킨다.
SpinLock
Busy Waiting 을 일으키는 Mutex Lock 을 SpinLock 이라고 한다.
Multi Core 일 경우 다른 코어에서 Busy Waiting 을 하고 있다가 해당 코어에서 바로 Critical Section 에 진입 할 수 있으므로 Context Switching 비용을 아껴준다.
Semaphore
Wait() 와 Signal() 이라는 두개의 함수로 구성된다.
뮤텍스보다 일반화 되어 있는 상호 배제를 위한 동기화 기법으로 공통으로 관리하는 정수값을 이용하여 동기화를 진행한다.
S 가 정수 변수 이며 현재 공유 데이터로 접근 가능한 출입문의 갯수라고 생각하면 된다.
공유 자원에 접근할 수 있는 프로세스의 최대 허용치만큼 동시에 접근 가능하다.
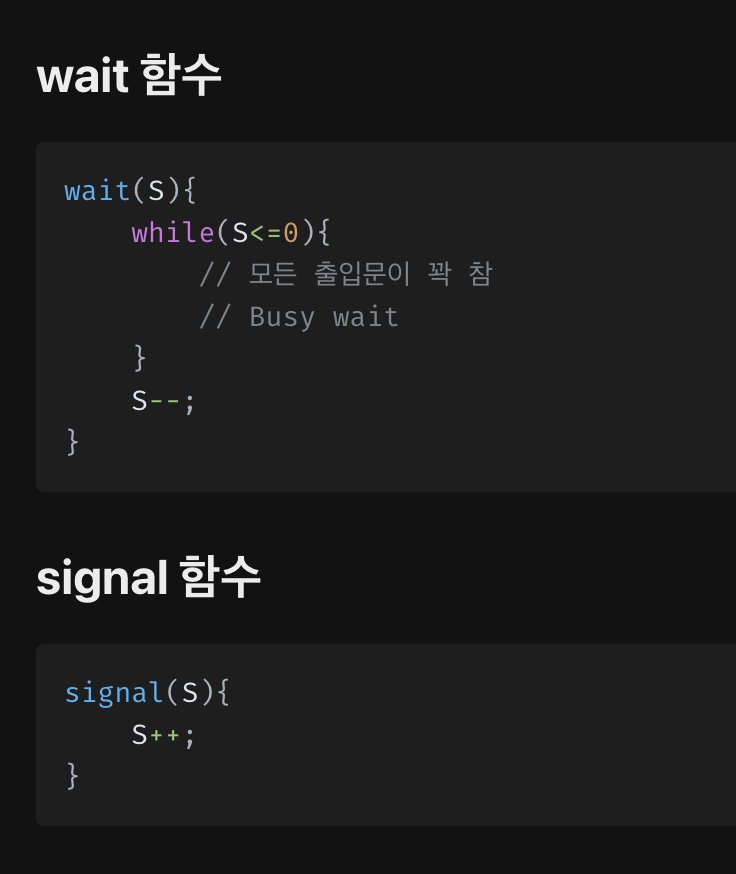

Binary Semaphore
S=1 인 경우로 Mutex 와 비슷하게 동작한다.
Counting Semaphore
S= n(n>1) 인 경우로 S 가 무한대로 증가할수 있다. 이는, 여러개의 인스턴스를 가진 자원에 사용될 수 있다.
컴퓨터에 등록된 프린터가 3개인 경우, 인스턴스는 3개라고 한다.
먼저 S를 사용가능한 자원의 갯수로 초기화 시켜준다.
그다음 프로세스가 자원을 사용할 경우 Wait() 를 사용해서 현재 사용가능한 S의 갯수를 줄인다.
프로세스가 자원을 반납할 경우 Signal을 실행해서 사용가능한 S의 갯수를 늘려준다.
그러다 S가 0인 경우 (모든 리소스가 사용 중인경우) S가 0보다 커질 때까지 Busy Wait 한다.
순서 보장 해결법
Statement1을 가진 Process A 와 Statement2를 가진 Process B 가 동시에 실행 될 경우 Statement1이 무조건 Statement2 보다 먼저 실행되어야 한다고 했을떄 어떻게 순서를 지킬수 있을까?
Semaphore 의 한계점
Timing Error가 발생할 수 있고 추적하기 까다롭다 한다.
Binary Semaphore 를 사용할 경우 각 proess들이 Wait->Signal 순서를 지켜야하는데 이를 지키지 않는 경우가 있다고 한다. 그래서 Critical Section 에 두개의 Process가 동시에 진입하게 되는 문제가 발생.
Semaphore 는 프로그래머의 실수가 유발 될 수 있다. 이러한 가능성을 최대한 낮춰야함.
Monitor
세마포어의 한계를 보완해주는 고차원적인 비동기 방법이다.
공유 자원을 숨기고 공유 자원에 대한 인터페이스를 제공함으로써 동기화를 수행한다.
Mutex,Semaphore 와 같이 임계구역 전후로 함수를 호출할 필요가 없으며 Java 의 synchronized 와 같은 키워드를 사용하듯 사용자 편리함에 초점을 맞춘 동기화 기법이다.
상호 배제를 위한 동기화 - 공유 자원에 접근하고자 하는 프로세스들을 모니터 큐에 넣고 하나씩 꺼내어 실행한다.
DeadLock
DeadLock 은 2개 이상의 작업이 동시에 이뤄지는 경우 다른 작업이 끝나기만 기다리며 작업을 더이상 진행하지못하는 상태이다.
Starvation 은 우선순위가 낮은 Process 가 우선순위가 높은 Process에 의해 뒤쳐져서 CPu 선점을 못하는것이라면
DeadLock 은 여러 Process 가 작업을 진행하다 보니 발생하는 자연적인 현상이다.

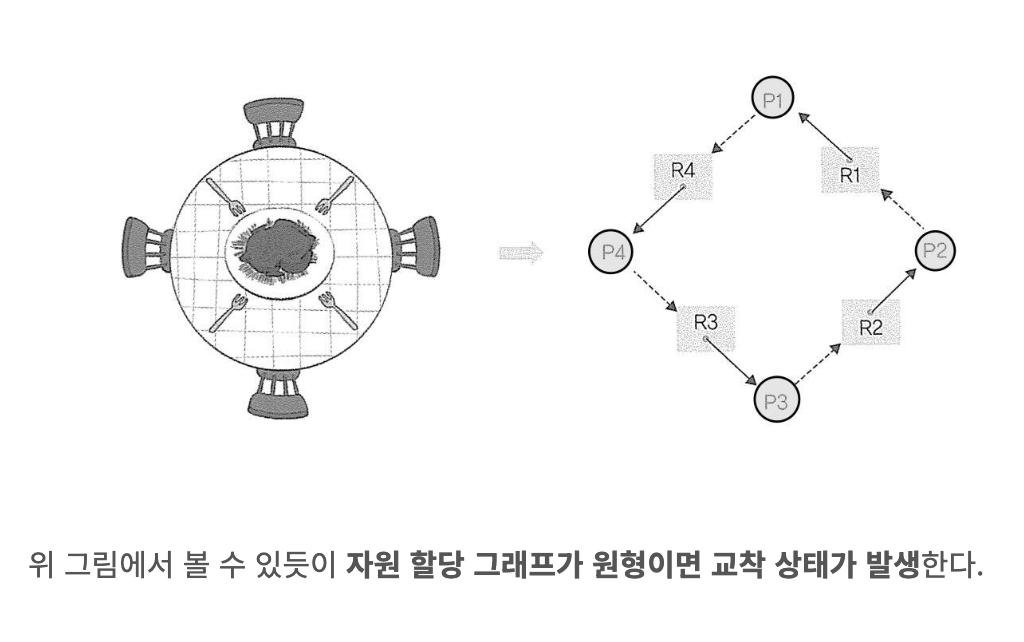
Safe Sequence & Safe State
Safe Sequence 는 DeadLock 없이 안전하게 프로세스들에게 자원을 할당할 수 있는 순서
Safe Sate 는 DeadLock 이 발생하지 않고 모든 프로세스가 정상적으로 자원을 할당받고 실행 및 종료될 수 있는 상태
Unsafe State 는 안전 순서열이 없는 상항
DeadLock 회피
안전 상태를 유지하도록 자원을 할당하는 방식
은행원 알고리즘 - 남아있는 돈의 양을 고려하고, 돈을 빌려줄 경우에도 그 사람이 돈을 갚을 수 있는 능력이 있는지 고려하면서 돈을 빌려주는 원리
DeadLock 검출 후 회복
선점을 통한 회복 - 교착 상태가 해결될 떄까지 하나의 프로세스에 자원을 몰아주는 방식으로 프로세스를 선점하고 교착 상태 여부를 확인하기 위한 오버헤드가 발생할수 있다.
프로세스 강제 종료를 통한 회복 - 가장 단순하면서 확실한 방법이지만 작업 내역을 잃을수 있다.
타조 알고리즘 - 교착 상태 무시
Swapping
메모리에서 사용되지 않는 일부 프로세스를 보조기억장치로 Swap-Out 하고 실행할 프로세스를 메모리로 Swap-In 하는 과정
Swap Space 는 보조기억장치의 일부 영역이다
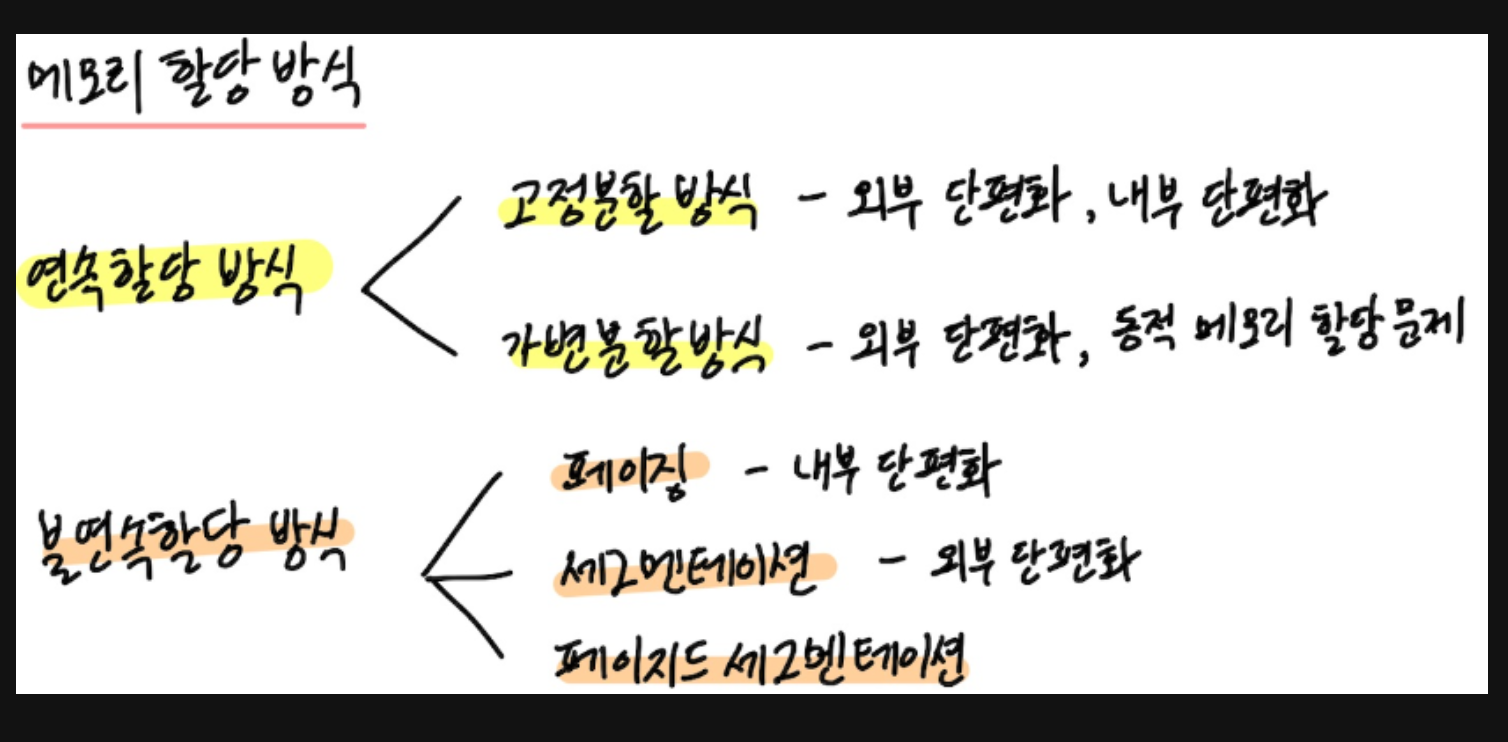
연속 메모리 할당
프로세스에 연속적인 메모리 공간을 할당하는 방식
// 고정분할방식
메모리를 일정 크기의 프레임으로 미리 나누어 관리하는 방식이다

// 가변분할방식
프로세스의 크기에 맞춰 필요한 메모리를 동적으로 할당하는 방식으로 외부 단편화가 발생할 수 있다.

Internal/External Fragmentation
일단 단편화는 RAM 에서 메모리의 공간이 작은 조각으로 나뉘어져 사용 가능한 메모리가 충분히 존재하지만 할당이 불가능한 상태이다.
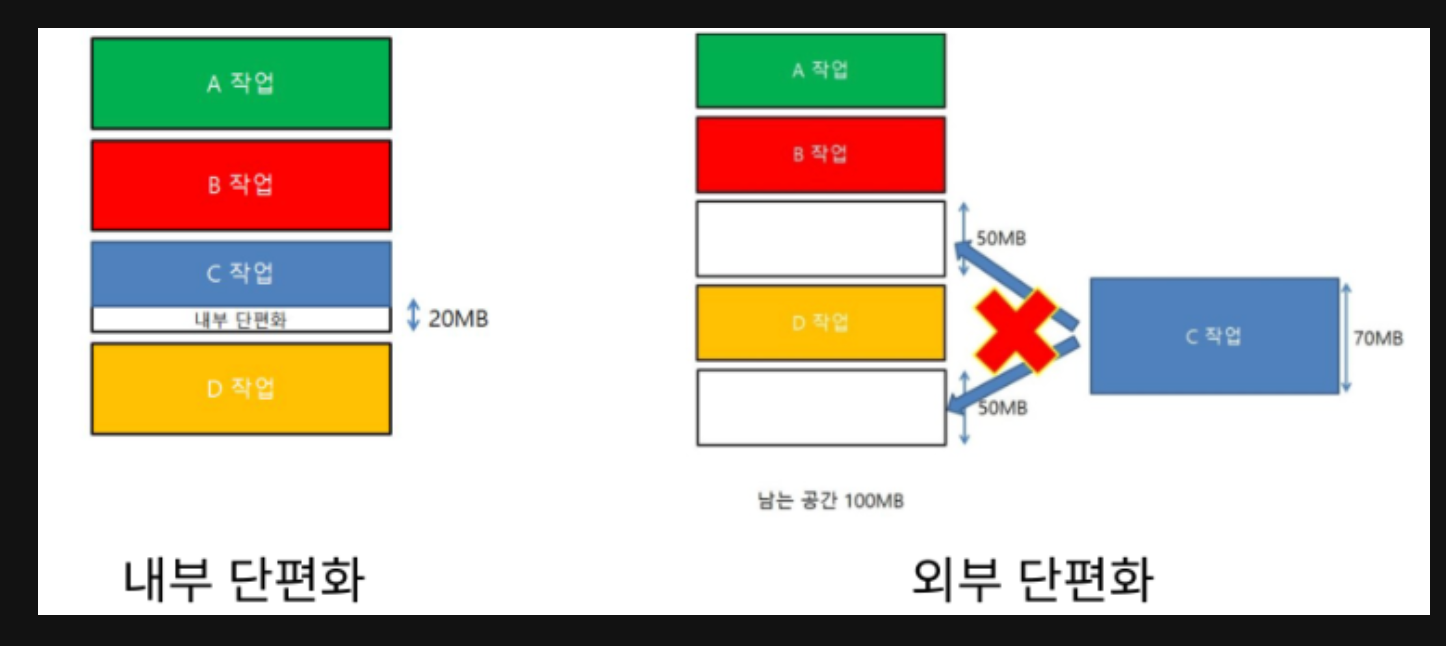
Internal Fragmentation은 메모리에 나뉜 프레임의 크기보다 할당되는 프로세스의 크기가 작아 작은 공간이 남아 낭비되는 현상이다.
가용공간이 프로세스보다 큰것이다.
External Fragmentation 은 남아있는 메모리의 크기가 실행하고자 하는 프로세스보다 크지만 연속적이지 않은 공간에 존재하여 실행하지 못하는 현상이다.
프로세스들이 메모리에 연속적으로 할당되고 반환되며 메모리 사이에 빈 공간이 생기게 된다. 어떤 프로세스를 할당 할 때, 빈공간을 합치며 공간이 충분하지만 연속적으로 메모리를 할당해야 하는 경우에 이를 활용하지 못하여 낭비되는 문제이다.
고마워 김치!
불연속
메모리에 불연속적으로 공간 할당한다.
하나의 프로세스가 물리 메로리 상의 여러 위치에 분산되어 적재되도록 함.
Sementation

가상 메모리를 사용해서 내부 단편화 문제를 해결하는 것이다.
가상 메모리를 서로 크기가 다른 논리적 단위인 세그먼트로 분할해서 메모리에 할당을 하여 실제 메모리 주소로 변환을 한다.
각 세그먼트는 연속적인 공간에 지정되어있다.
Mapping 을 위해서 마찬가지로 Segment Table 이 필요하다.
하지만 Process가 필요한 메모리 공간 만큼 할당 해주기 때문에 내부 단편화 문제를 해결할수는 있지만 중간에 메모리를 해제하면 생기는 외부 단편화 문제가 발생한다.
Paging
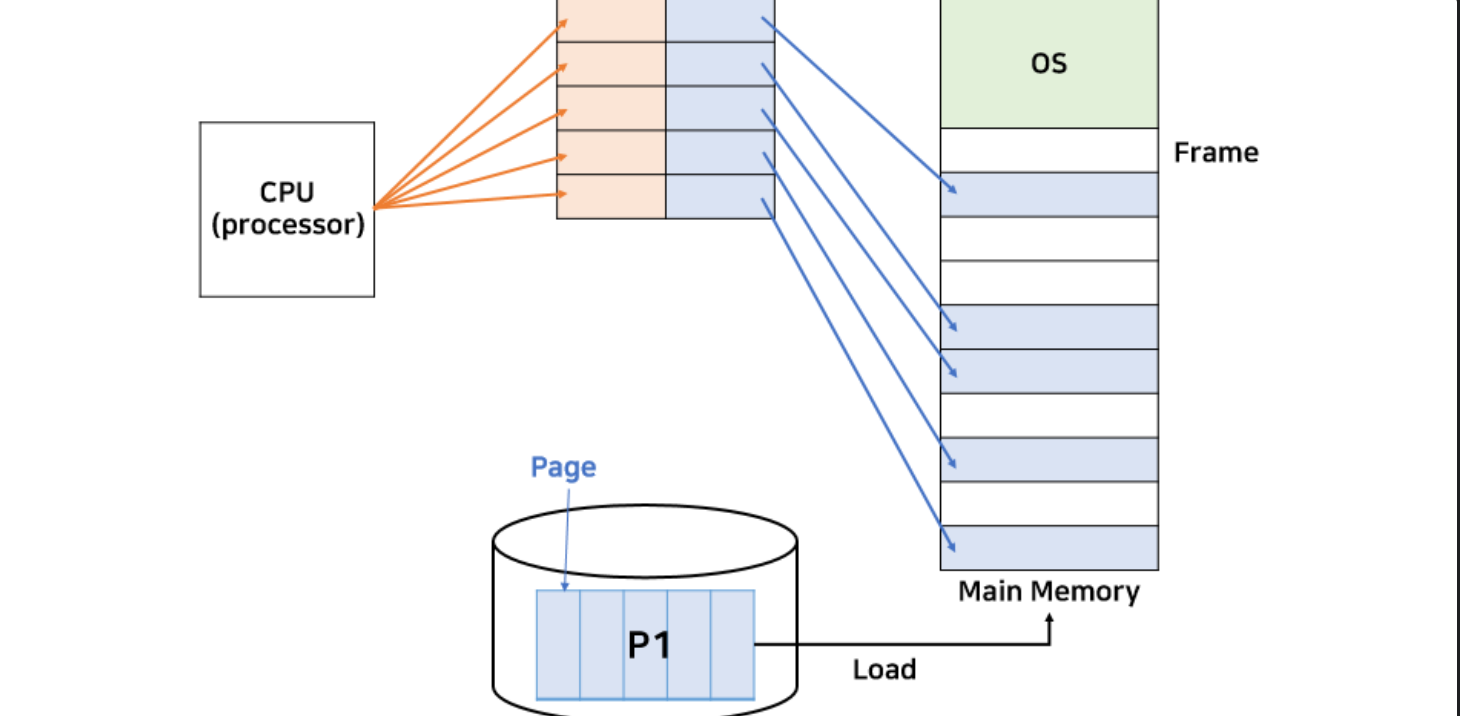
가상 메모리를 사용하여서 외부 단편화 문제를 해결하는 방법이다.
보조기억장치,가상메모리를 같은 크기의 블록으로 나눈 것을 페이지라고 하고 RAM 을 페이지와 같은 크기로 나눈 것을 Frame 이라고 한다.
Paging 은 사용하지 않는 Frame을 Page에 옮기고 필요한 메모리를 페이지 단위로 프레임에 옮기는 방법이다.
Page 와 Frame 을 대응시키기 위해 Page Mapping 과정이 필요해서 paging Table 을 만든다.
Compactation
압축으로 외부 단편회를 해결하기 위해서 메모리 내의 저장된 프로세스를 적당히 재배치시켜 여기저기 흩어져 있는 작은 빈 공간들을 하나의 큰 빈 공간으로 만드는 방법.
// 컴팩션 과정에서 시스템은 하던 일들을 중지해야하고 오버헤드를 일으킬 수 있다.
Virtual Memory
실행하고자 하는 프로그램을 일부만 메모리에 적재하여 실제 물리 메모리 크기보다 더 큰 프로세스를 실행할 수 있게 하는 기술
Page Table
프로세스가 메모리에 불연속적으로 위치해있으면, CPU 입장에서는 이를 순차적으로 실행할수 없다.
따라서 프로세스가 비록 물리메모리에는 불연속적으로 배치되어 있더라도 논리 주소에는 연속적으로 배치되도록 페잊 ㅣ테이블을 이용한다.
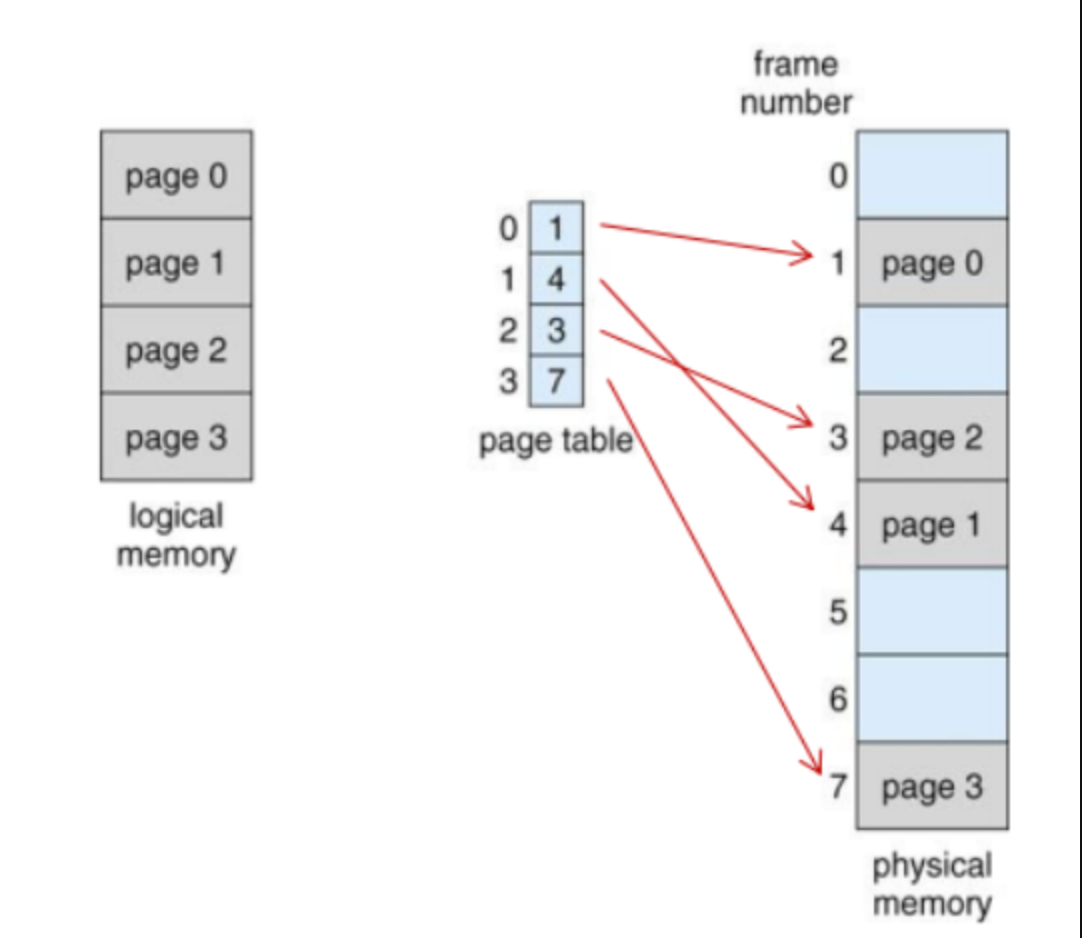
페이지 번호와 프레임 번호를 짝지어주는 이정표이다.
CPU로 하여금 페이지 번호만 보고 해당 페이지가 적재된 프레임을 찾을 수 있게 한다.
PTBR,PTLR
Page Table Base Register - 각 프로세스의 페이지 테이블이 적재된 주소를 가리킨다
Page Table Length Register - 페이지 테이블의 크기를 나타내는 레지스터
TLB
Translation Lookaside Buffer - 페이지 테이블을 사용하면 페이지 테이블을 참조하기 위해 한번, 프레임에 접근하기 위해 한번 총 두번의 메모리 접근이 발생한다.
이를 완화하기 위해서 TLB를 둔다.
TLB 는 페이지 테이블의 캐시로 페이지 테이블의 일부 내용을 저장한다.
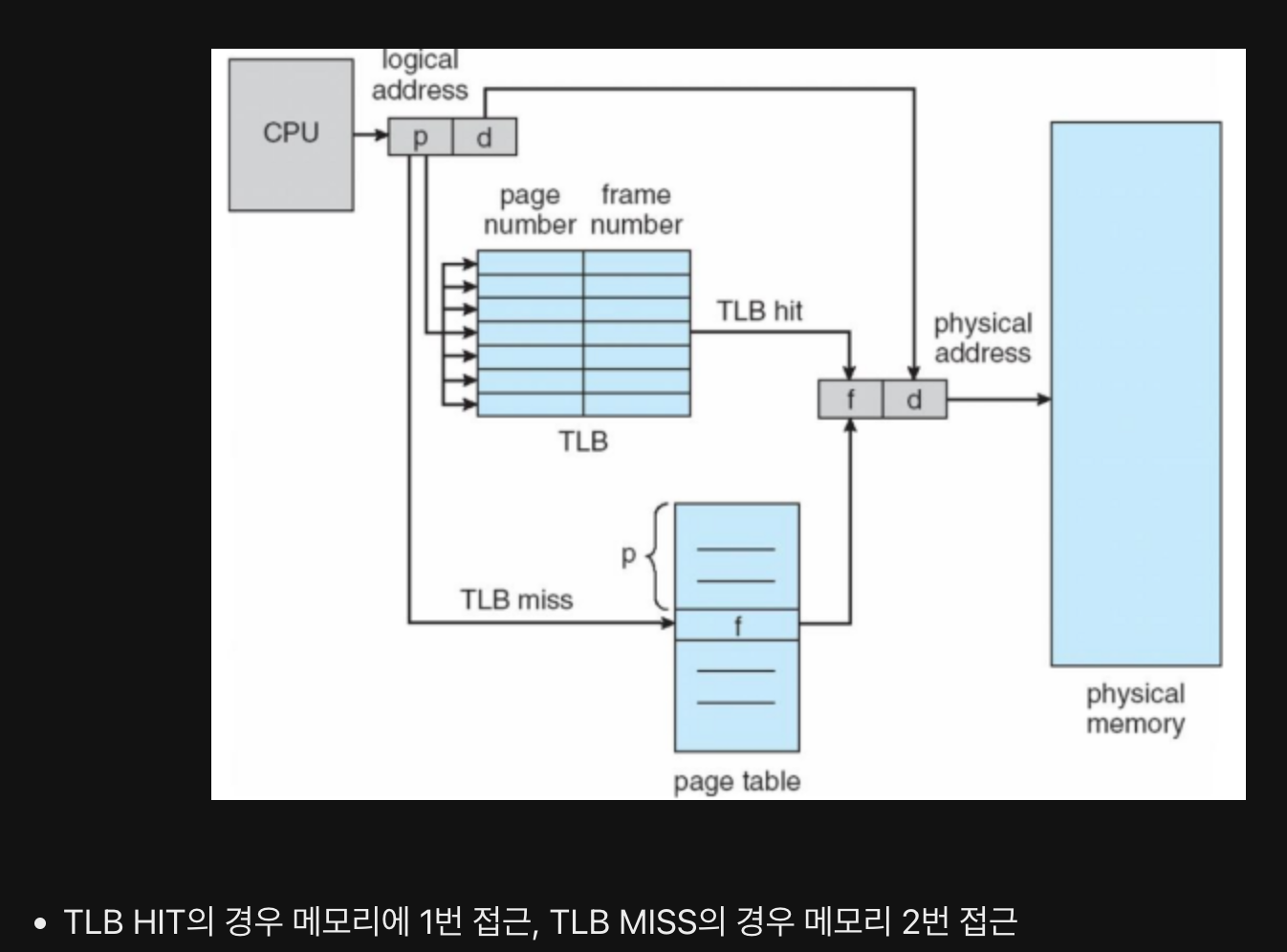
페이징 주소 변환
페이지 번호 + Offset 으로 구성
페이지 테이블을 통해 해당 페이지에 해당하는 프레임을 찾을 수 있고, Offset을 통해 프레임의 시작번지에서 얼마나 떨어진 값에 접근하고자 하는지 알 수 있다.
PTE
Page Table entry - 페이지 테이블 각각의 행으로 유효비트,보호비트,참조비트,수정비트 를 가지고 있다.

Copy on write
쓰기 시 복사: Fork() 로 자식 프로세스 생성시에 부모 프로세스가 저장된 프레임과 동일한 위치를 가리킨다.
만일 부모 또는 자식 프로세스가 페이지에 쓰기 작업을 한다면 그 순간 해당 페이지가 별도의 공간으로 복제된다.
// 프로세스 생성 시간 단축 및 메모리 공간 절약 가능
Multilevel page table
모든 페이지 테이블 엔트리를 메모리에 저장하는 것은 메모리 낭비로 이어질수 있으므로 페이지 페이블을 페이징하여 계층적 페이징 구조를 만드는 방법이다.
Outer table 은 메모리에 유지해야하며, 바깥 페이지 번호 + 안쪽 페이지 번호 + Offset를 통해 접근하고자 하는 프레임 주소에 접근할 수 있다.
요구 페이징
Demand Paging 은 프로세스가 메모리에 적재될 때, 처음부터 모든 페이지를 적재하지 않고 실행에 필요한 페이지만을 메모리에 적재하는 기법
순수 요구 페이징은 아무런 페이지도 메모리에 적재하지 않은채 무작정 실행하는 기법
페이지 교체 알고리즘
Page Fault 가 발생할 경우 요청된 페이지를 디스크로부터 옮겨 메모리에 적재해야하는데, 빈 프레임이 없을 경우 페이지 교체 알고리즘을 사용하여 Victime Page 를 정해야한다.
출처 ) https://doh-an.tistory.com/28
// Optimal
앞으로 가장 오랫동안 사용되지 않을 페이지 교체하는것
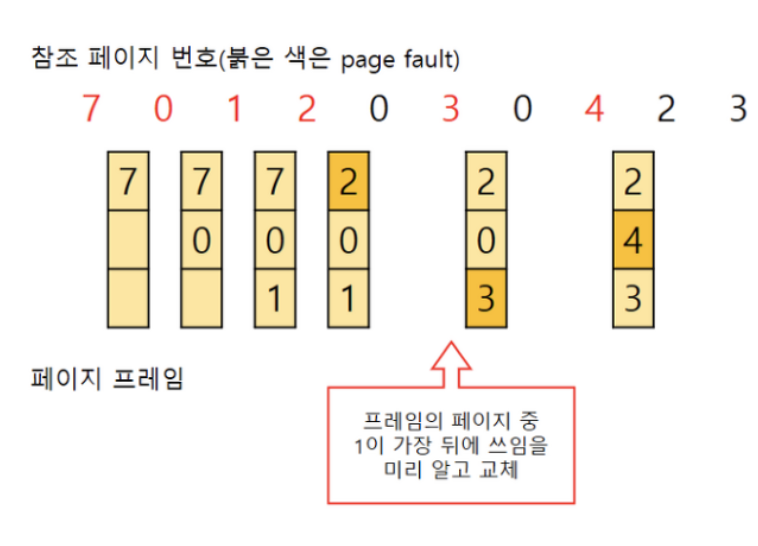
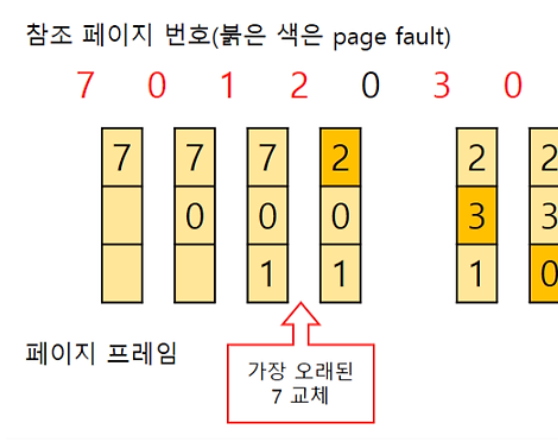
// FIFO
가장 먼저 들어온 페이지를 교체
// LRU
Least Recently Used 로 가장 오랫동안 사용하지 않은 페이지를 교체하는것이다.
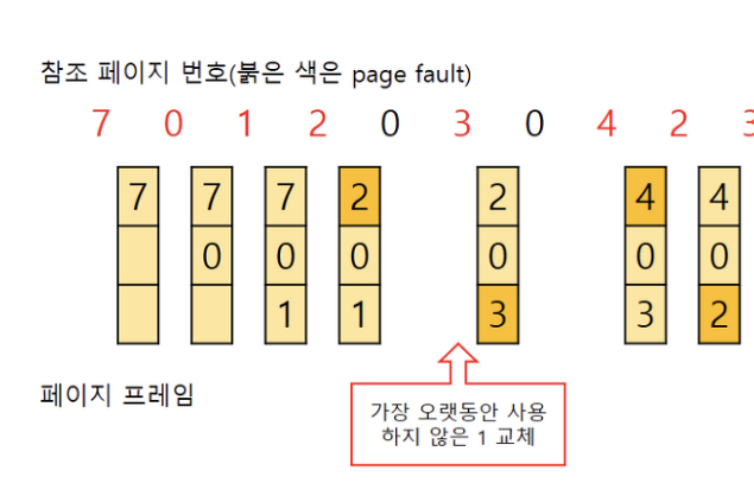
// LFU
Least Frequently Used 로 참조 회수가 가장 낮은 페이지를 교체하는것
// MFU
Most Frequently Used 로 참조 횟수가 가장 많은 페이지 교체
스레싱
빈번한 페이지 교체로 인해 프로세스가 실행되는 시간보다 페이지 교체 하는데 CPU 를 더 많이 사용하는 상황이다. 그래서 CPU Utilization이 저하되고,Page Fault 가 증가한다.
빈번한 Swapping 으로 인해 CPU Utilization 감소 되고 운영체제는 CPU Utilization 을 높이기 위해 더 많은 프로세스에 Load, CPU Utilization 은 계속해서 감소한다.
근본적인 이유는 프로세스가 필요로 하는 최소한의 프레임 수가 부족하기 때문이다.
프레임 할당 방식
정적 할당 방식과 동적 할당 방식이 있다.
정적 할당방식은 두개로 균등 할당과 비례 할당이 있다.
균등 할당 - 모든 프로세스에게 균등하게 프레임을 할당하는 방식
비례 할당 - 프로세스의 크기에 따라 프레임을 할당하는 방식
동적할당은 프로세스를 실행하는 과정에서 배분할 프레임을 결정 한다.
프로세스를 막상 실행해 보니 많은 프레임이 필요하지 않거나, 반대인 경우도 있다고 한다.
Working set - 프로세스가 일정 시간동안 참조한 페이지 집합으로 Working set 을 기억하여 해당 갯수 만큼 프레임을 할당하는 방식
PFF(Page fault frequency) - 페이지 폴트율에 상한선과 하한선을 정하고, 해당 범위 안에서만 프레임을 할당하는 방식

파일
보조 기억 장치에 저장된 관련 정보의 집합이다.
응용 프로그램들은 파일을 임의로 조작할수 없으며, 파일 연산을 위해서는 시스템 콜을 사용해야한다.
Directory(Folder)
파일들을 일목요연하게 관리하기 위한 파일로 해당 디렉토리 내에 담겨있는 대상과 관련된 정보를 가지고 있다.

절대 경로 - 루트 디렉토리에서 시작하는 경로
상대 경로 - 현재 디렉토리에서 시작하는 경로
파일 시스템
파일과 디렉토리를 보조기억장치에 일목요연하게 저장하고 접근할 수 있게 하는 운영체제 내부 프로그램
Partitioning
저장 장치의 논리적인 영역을 구획하는 작업
Formatting
파일 시스템을 설정하여 어떤 방식으로 파일을 저장하고 관리할 것인지를 결정하고, 새로우 ㄴ데이터를 쓸 준비를 하는 작업
파일 할당 방식
파일과 디렉토리는 블록 단위로 읽고 쓴다
연속할당 방식과 불연속할당 방식이 있는데
불연속할당 방식에는 연결할당과 색인할당으로 나뉜다
연결할당이 발전해서 FAT 가 됐고 색인 할당이 발전해서 유닉스 파일 시스템이 됐다.
연속 할당
보조기억장치 내 연속적인 블록에 파일을 할당하는 방식
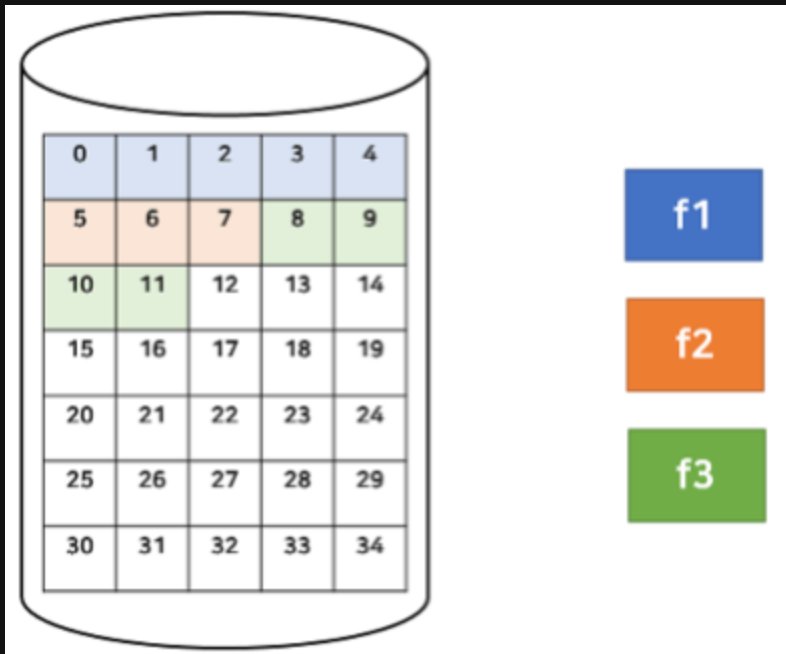
디렉토리 엔트리 - 파일이름 + 첫번째 블록 주소 + 길이
외부 단편화가 발생한다.
연결 할당
각각의 블록에 다음 블록 주소를 저장하여 각 블록이 다음 블록을 가리키는 연결리스트 형태로 할당하는 방식
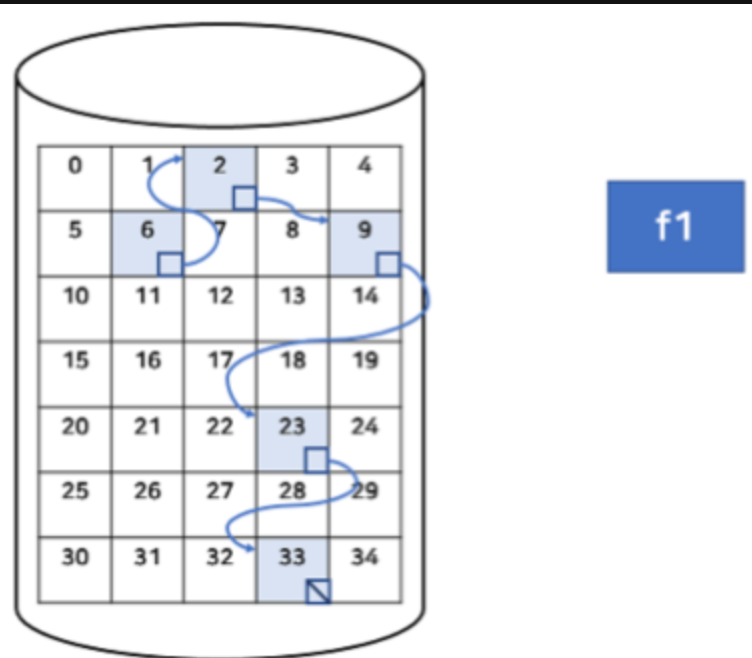
디렉토리 엔트리 - 파일이름 + 첫번째 블록 주소 + 길이
Random access가 불가능 하여 읽는 속도가 느리고, 하나의 블록에 오류가 발생하게 되면 이후 블록에는 접그할 수 없게 된다.
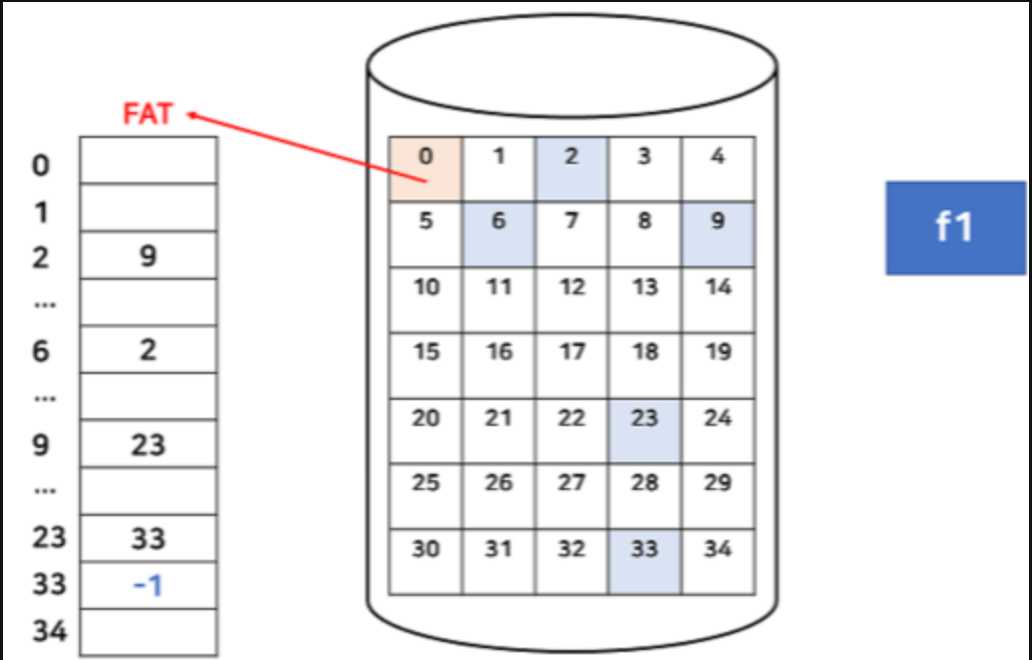
FAT
File Allocation Table - 연결 할당 방식에서 발전된 형태로, 연결리스트로 파일 할당을 관리하는 것이 아닌 테이블 형태로 파일을 할당을 관리한다.
Random Access 가 가능하며 특정 블록에 접근이 불가하더라도 테이블을 참조하여 이후 블록을 접근할수 있다.
디렉토리 엔트리 - 파일 이름 + 파일의 첫번쨰 주소
색인 할당
파일의 모든 블록 주소를 색인 블록이라는 하나의 블록에 모아 관리하는 방식으로 임의 접근이 쉽다.
디렉토리 엔트리 - 파일이름 + 색인 블록 주소
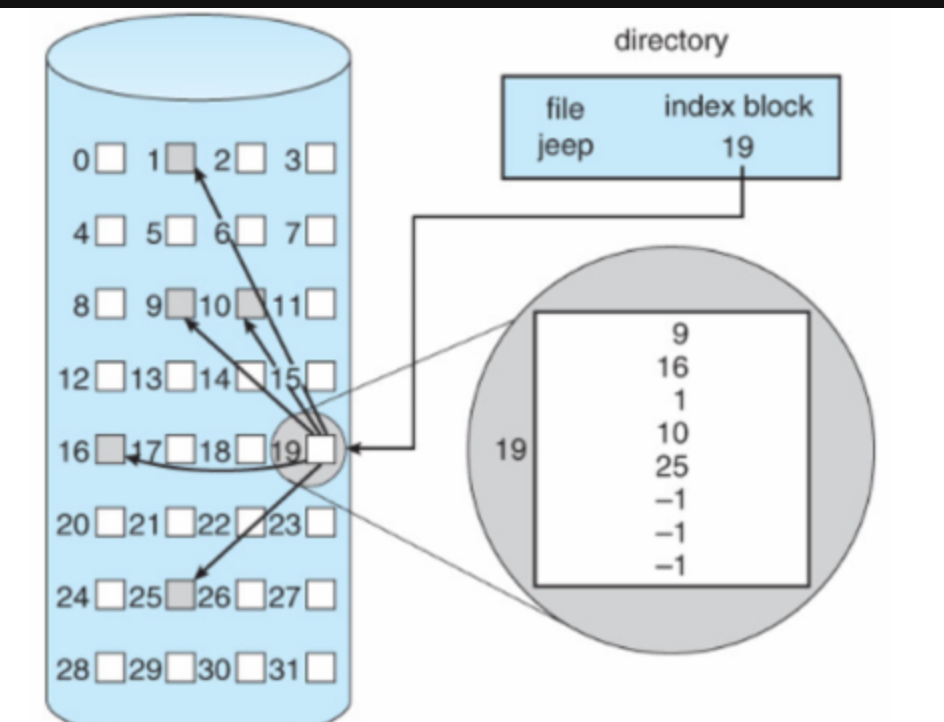
I-Node
색인 할당 기반의 유닉스 파일 시스템으로 색인 블록을 I-Node 라고 한다.
I-Node 에는 파일 속성 정보와 15개의 블록 주소가 저장된다.
그 외 파일 시스템
NTFS - 윈도우 운영체제에서 사용되는 파일 시스템
EXT - 리눅스 운영체제에서 사용되는 파일 시스템
저널링
작업 로그를 통해 시스템 크래시가 발생했을 떄 빠르게 복구하기 위한 방법
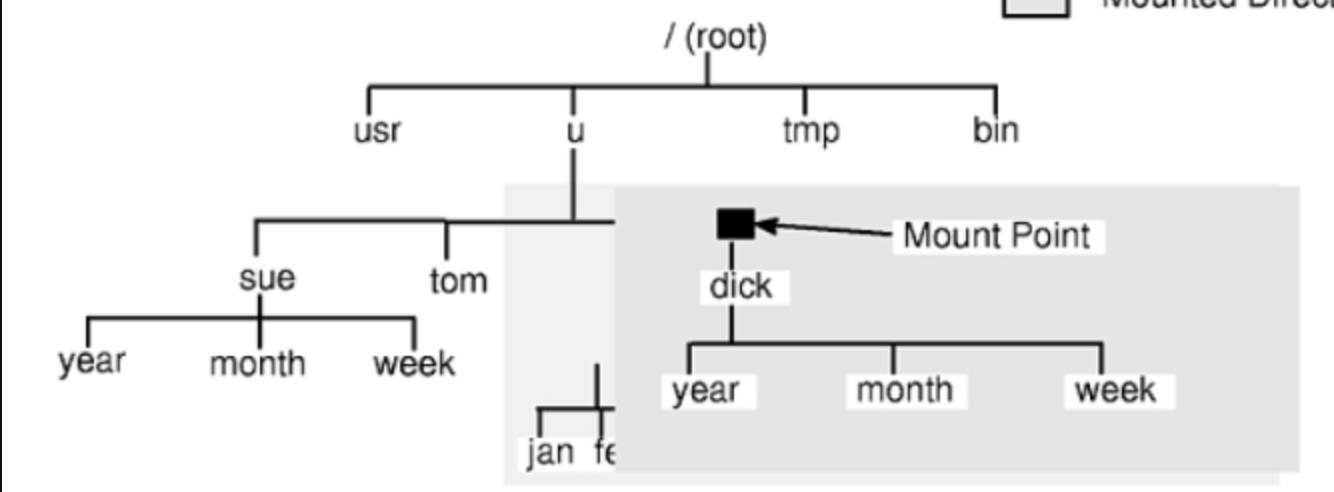
마운트
한 저장 장치 파일 시스템에서 다른 저장 장치 파일 시스템에 접근할 수 있도록 파일 시스템을 편입 시키는 작업