최종 프로젝트
1.최종 프로젝트 주제 의견 제출용

최종 프로젝트 주제 의견 제출용 배운 내용을 적용하기 쉽고, AI 활용 방안쪽에서 참신한 아이디어들을 접목 시키는 방향으로 생각 해 봤다. 지역별 커뮤니티(이벤트 만남 중심) 플랫폼내용 : 사용자가 지역별 모임 (독서, 영화, 러닝, 봉사, 여행 등)에 참가 신청을 할
2.와이어 프레임 초안

프로젝트 와이어 프레임 초안을 대략 구성하는데 팀원들과 많은 회의를 거쳤다. 아직 작성할게 많고 수정할 것도 많아서 갈 길이 멀다~
3.와이어 프레임 초안 완성 / 5분 기록 보드
4.SRS (Software Requirements Specification)
Software Requirements Specification(SRS)은 소프트웨어 개발 프로젝트에서 요구사항을 명확하고 체계적으로 문서화한 공식적인 문서입니다. SRS는 개발팀, 이해관계자, 사용자 간의 소통을 원활하게 하고, 개발 및 유지보수 단계에서 참조할 수
5.회원가입 로직 논의(취향 데이터 수집)
회원가입 과정은 단순히 계정을 생성하는 것을 넘어 유저 맞춤형 서비스를 제공하기 위해 필수적인 데이터를 수집하는 중요한 단계입니다. 특히, 게임 추천 서비스에서는 유저의 게임 취향 데이터를 얼마나 정확히 수집하느냐가 서비스의 품질에 직결됩니다.이번 프로젝트에서는 유저가
6.TIL: Django 모델 설계 시 의사결정 과정 - Review 모델 사례
별점(score) 모델 필드 설정 참고 :DecimalField(https://docs.djangoproject.com/en/4.2/ref/models/fields/오늘은 Django를 활용해 Review 모델을 설계하며, 의사결정 과정과 주요 고려사항을 기록
7.Django ReviewComment와 ReviewLike 모델 설계 시 의사결정 과정
Django 모델 설계 시 의사결정 과정 - ReviewComment와 ReviewLike 모델 사례 오늘은 Django를 활용해 ReviewComment와 ReviewLike 모델을 설계하며, 의사결정 과정과 주요 고려사항을 정리했습니다. ERD 구조를 기반으로 각
8.DRF serializer.py 설계 및 의사결정 과정
오늘 작업한 내용은 Django Rest Framework(DRF) 기반의 serializer.py를 설계하고, Review, ReviewComment, ReviewLike 모델을 직렬화하는 과정에서의 주요 의사결정을 정리했다.Review, ReviewComment,
9.[트러블슈팅] Django와 PostgreSQL 연결 이슈: 가상환경에서 환경변수 문제 해결
트러블 슈팅 개요 Django 프로젝트를 PostgreSQL과 연결하려고 할 때, 가상환경(venv)에서 PostgreSQL CLI 도구(psql)가 제대로 동작하지 않는 문제가 발생했습니다. 가상환경의 PATH 환경변수 설정과 관련된 문제였습니다. 문제 pyth
10.Django Review APIView 설계
Django로 리뷰 및 댓글 관련 API를 설계하면서 APIView를 활용해 전반적인 기능을 구현하였습니다. 결정: get_permissions 메서드를 사용해 각 HTTP 메서드별로 권한을 분리.GET: 누구나 접근 가능 (AllowAny)POST, PUT, DELE
11.Steam 데이터 DB 구조화
이 프로젝트는 Steam 데이터를 Django 기반 시스템에 저장하는 과정을 구조화한 것입니다. 주요 목적은 사용자의 Steam 프로필, 리뷰, 플레이타임 정보를 수집하여 Django 모델에 저장하는 것이며, 이를 통해 사용자 맞춤형 경험을 제공하거나 통계 자료로 활용
12.Steam API를 활용한 사용자 프로필 및 데이터 관리 자동화
Django와 Selenium, 그리고 Steam API를 활용하여 Steam 사용자 프로필, 리뷰, 플레이타임 데이터를 수집하고 이를 데이터베이스에 저장하는 코드를 살펴보겠습니다. 주요 코드는 management command로 작성되었으며, 아래 핵심 과정을 단계
13.[트러블슈팅] 크롤링에서 API 호출로 대체
Steam에서 특정 사용자의 상위 2개 플레이 시간을 조회하는 기능을 구현하던 중, 기존 크롤링 방식을 사용했을 때 아래와 같은 문제에 직면했습니다.로그인이 필요한 페이지: Steam의 특정 API는 사용자 게임 정보 조회에 로그인을 요구했습니다. Selenium을 사
14.리뷰 API에 카테고리 필터 추가하기
사용자가 카테고리별로 리뷰를 필터링하고, 인기순, 조회순, 최신순으로 정렬할 수 있는 기능을 구현하고자 했습니다. Review 모델에는 이미 문자열 배열 형태의 categories 필드가 있었고, 이를 기반으로 필터링 기능을 추가했습니다.아래는 업데이트된 ReviewA
15.프론트엔드에서 app_id와 game_name을 모달 형식으로 추가한 뒤, 검색 로직 흐름
프론트엔드에서 사용자가 게임을 선택하거나 검색하기 위한 모달 형식 UI를 활용하면서, 이를 백엔드와 연결하여 검색 로직을 구현하는 전체 흐름을 블로그 형식으로 설명합니다.검색 UI를 개선하기 위해 모달 형식을 활용하여 사용자가 게임 이름과 ID를 선택할 수 있도록 구현
16.[트러블슈팅] Review 생성 API 개발 과정
사용자가 리뷰를 작성할 때:app_id를 통해 Game 모델과 매핑하여 관련 데이터를 활용해야 함.리뷰의 categories 필드를 Game 모델의 genres로 자동 설정.추가적으로 응답 데이터에 Game 모델의 name과 header_image를 포함.사용자 입력의
17.[트러블 슈팅] app_id 변경 시 관련 필드 동기화
Review 모델에서 app_id를 수정하면 game_name과 header_image는 자동으로 변경되었지만, categories 필드는 수정된 app_id에 연동되지 않고 기존 값이 그대로 유지되는 문제가 발생했습니다.Review 모델의 @property를 사용하여
18.차단 기능 구현 의사결정 과정
Block 기능특정 유저를 차단하거나 차단 해제할 수 있도록 API를 제공차단된 유저의 리뷰가 블러 처리되거나 제외됨차단된 유저와의 채팅 제한처음에는 Django의 Many-to-Many 필드를 사용하려고 했습니다. 하지만 아래와 같은 이유로 명시적인 Block 모델을
19.차단한 사용자의 리뷰 블러 처리 구현
우리 프로젝트의 주요 요구사항 중 하나는 사용자가 차단한 유저의 리뷰를 블러 처리하는 기능이었습니다. 이 기능은 사용자 경험을 개선하기 위한 중요한 요소로, 리뷰를 조회할 때 차단된 사용자의 리뷰를 숨기거나 대체 메시지로 표시해야 했습니다.회원: 차단한 사용자의 리뷰를
20.친구 요청 및 친구 관리 기능 구현 과정
처음에는 친구 요청과 친구 관리를 단순하게 처리하려 했으나, 구현 과정에서 여러 경우의 수를 고려해야 했습니다:친구 요청 상태 관리 (type 필드):type=0: 대기 중type=1: 수락(친구 관계 형성)type=-1: 거절친구 요청과 친구 관리의 분리:친구 요청과
21.[트러블 슈팅] 친구 요청 및 친구 관리 기능 구현
상황: 초기에는 type 필드를 활용하여 요청 상태를 0(대기), 1(수락), -1(거절)로 관리하려 했습니다. 그러나 데이터베이스에 거절된 요청을 계속 유지하는 방식은 복잡성을 증가시키고, 성능 저하 가능성이 있었습니다해결:거절된 요청은 데이터베이스에서 삭제요청 수락
22.[트러블 슈팅]알림 모델 개선
알림 유형 구분의 어려움:알림 유형을 숫자(int)로 관리하다 보니, 코드에서 의미를 직관적으로 파악하기 어려움예: type=1이 무엇을 의미하는지 명확하지 않음알림 상태 관리의 불편함:알림의 읽음 여부(is_read)를 별도로 관리하지 않아, 사용자가 읽은 알림을 처
23.[트러블슈팅] 리뷰 작성할 때 content 필드에 데이터가 저장되지 않는 문제와 블러 처리 구현
새 리뷰를 생성할 때, POST 요청에 포함된 content 값이 데이터베이스에 저장되지 않는 문제가 발생했습니다. 이와 동시에 차단된 사용자의 리뷰를 조회할 때 내용을 블러 처리하는 기능을 구현하려고 했습니다. 하지만 두 기능이 충돌하면서 아래와 같은 문제가 발생했습
24.[트러블 슈팅] 신규 유저 Steam_data 즉시 반영 필요
기존 로직(전체 DB를 일괄 업데이트하는 커맨드)으로는 새로 가입한 유저가 스팀을 연동했을 때 즉각적으로 DB에 반영되지 않는 문제가 있었다.이를 해결하기 위해 신규 유저가 스팀 계정을 연결하자마자 DB에 정보를 저장할 수 있도록 별도의 모듈 함수를 만들고 기존 회원가
25.[트러블 슈팅] 게임 상세 페이지에서 클릭한 리뷰 강조
요구사항: 리뷰 목록에서 특정 리뷰를 클릭했을 때, 게임 상세 페이지에서 해당 리뷰를 눈에 띄게 표시하고 나머지 리뷰와 구분하여 관리하고 싶었습니다.현상: 기존 API 구조가 이를 지원하지 않았습니다. review_id를 통한 클릭한 리뷰의 강조가 필요하다고 생각했습니
26.페이지네이션 구현과 코드 리팩토링
기존 코드에서 페이지네이션이 없었던 ReviewSearchAPIView를 개선하여, 페이지네이션 기능을 추가하고, 클라이언트가 요청한 페이지에 따라 데이터를 효율적으로 반환하도록 수정했습니다.모든 데이터 반환: 검색 결과를 한 번에 모두 반환하여, 결과가 많아질 경우
27.배포단계 문제
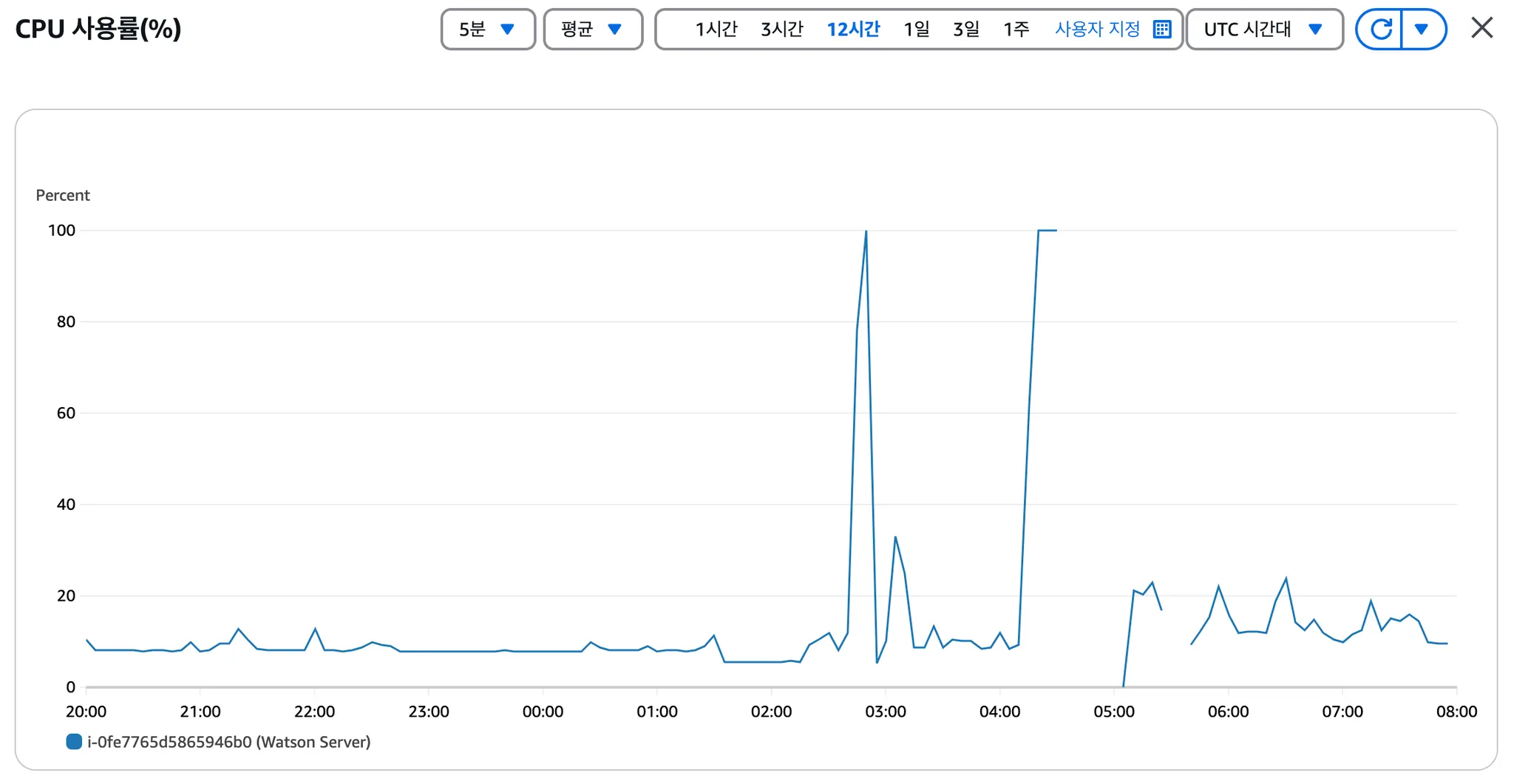
팀원이 작성한 트러블 문서를 정리했습니다.문제 상황:Selenium을 사용한 크롤링 과정에서 헤드리스 브라우저가 예상보다 많은 메모리를 사용했습니다.동시 접속 시 CPU 사용률이 100%까지 치솟아 서버가 불안정했습니다. 해결 방법:RAM 스왑 설정: \- 하드
28.[트러블 슈팅]셀레니움 방식 크롤링 수정
AWS 서버에서 Selenium을 이용해 리뷰를 크롤링하는 코드를 실행했더니 CPU 사용량이 100%에 근접하는 현상이 발생하였다. EC2 같이 스펙이 낮은 서버에서 헤드리스 크롬(Chromedriver)을 구동할 경우, 브라우저 엔진이 동작하면서 리소스 사용량이 크
29.steam_data 로직 수정
기존에 Selenium을 사용하던 부분을 전부 제거하고, requests와 BeautifulSoup로 대체했다.steamId가 항상 64비트라고 가정하여, 커스텀 URL 변환(resolve_vanity_url)이나 steam_id_str.isdigit() 같은 로직도
30.프로젝트 리팩토링 피드백
프로젝트에 사용하지 않는 파일이 깃허브에 업로드되어 있어 관리 효율성이 떨어짐조치: 사용하지 않는 파일과 코드를 확인 후 삭제모델의 주석 대신 verbose_name 속성을 사용하여 각 필드의 역할을 명확히 설명하는 Django 권장 방식을 따름verbose_name은
31.프로젝트 발표 회고
다른 조들의 발표를 경청하면서 모두가 정말 열심히 준비했다는 걸 느꼈다. 각 팀이 각자의 방식으로 고민하고, 개발하고, 완성해가는 과정이 고스란히 발표에 담겨 있어서 감탄스러웠다. 다만 A, B 발표장이 나뉘어 있어서 다른 발표장의 조들이 어떤 발표를 했는지 직접 듣지
32.모의 면접 질문 리스트 정리
어떤 기능을 하는 프로젝트인가요?타 비슷한 프로젝트에 비해서 장점이 무엇인가요?프로젝트의 핵심 목표는 무엇인가요?추천 로직이 어떻게 되나요? (홈 + 챗봇)추천 시스템에서 사용한 알고리즘은 무엇인가요?추천 결과의 정확도를 어떻게 평가했나요?프로젝트 진행 중 갈등이 발생