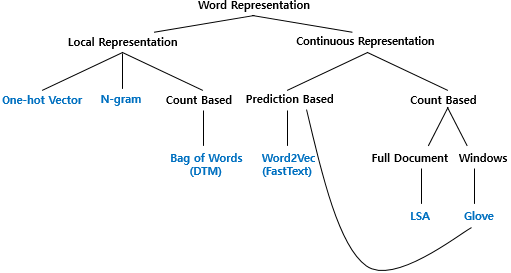
word representation의 분류
{kind=link}
출처 : pytorch로 시작하는 딥러닝 입문 https://wikidocs.net/217499
word representation의 필요성
컴퓨터는 인간이 쓰는 단어를 그 자체로 이해하지 못한다. 이미지를 RGB 값의 텐서로 표현해서 집어넣어주듯 텍스트를 단어로 쪼개고(Tokenization, Cleaning, Normalization, Stemming, Lemmatization, Stopword 제거...) 그 단어를 컴퓨터가 이해할 수 있도록 변형해주는 과정이 필요하다.
-
Tokenization : corpus에서 token이라 불리는 단위로 나누는 작업. 보통 단어를 기준으로 나눈다. 영어는 띄어쓰기를 기준으로 나눠도 단어 토큰이 구분이 쉬운 편이고 한국어는 띄어쓰기만으로는 단어 토큰을 구분하기 어렵다.
-
Cleaning, Normalization : 노이즈를 제거하고 표현 방법이 다른 단어를 통합한다. 주로 대,소문자 통합, 등장 빈도가 적은 단어 제거, 길이가 짧은 단어를 제거하는 방법 등이 있다.
-
Stemming : 정규화 기법 중 하나이다. 어간 추출을 위해 단어의 어미를 대강 자르는 작업이다.
-
Lemmatization : 정규화 기법 중 하나이다. 표제어(사전 기본형)를 추출하여 서로 다른 단어여도 하나의 단어로 일반화시키는 목적을 갖고 있다. 단어의 뿌리를 찾는다. am, are, is 를 be 로 바꾸는 것처럼. 단어의 형태가 적절히 보존되는 양상을 보이는 특징이 있다.
-
Stopword 제거 : 큰 의미가 없는 단어를 제거하는 작업이다. i, me, my 같은 문장에서 자주 등장하지만 실제 의미 분석을 하는데 기여하는 바가 없는 단어를 제거한다. 목적에 따라 사용자가 직접 추가할 수도 있다.
1. One-hot-encoding
단어를 벡터로 표현하는 방법 중 하나이다. 그 중에서도 가장 단순하다. 데이터 셋(말뭉치)에 등장하는 모든 단어를 모아놓은 집합을 생각해보자. n개의 단어가 있다고 생각해보면 그 집합에 있는 단어에 1부터 n까지의 번호를 붙인다. 만약 전체 10개의 단어가 있고 '저녁'이라는 단어에 3이라는 숫자를 붙였다면 단어 '저녁'은 = [0,0,0,1,0,0,0,0,0,0,0] 으로 index 3만 1이고 나머지는 0인 벡터로 표현이 가능하다.
직관적이고 쉽게 표현이 가능하지만 단어간 유사도를 표현하지 못한다는 단점이 있다. 또한, 단어 집합이 커지면 ex) 10만 모든 단어의 벡터가 단 하나의 값만 1을 가지고 나머지 9만 9999개의 값이 0인 상황처럼 저장공간이 매우 비효율적이다.
