데이터 관리와 분석
1.[데이터 관리와 분석] Conceptual DB design & DB implementation - 1차 프로젝트
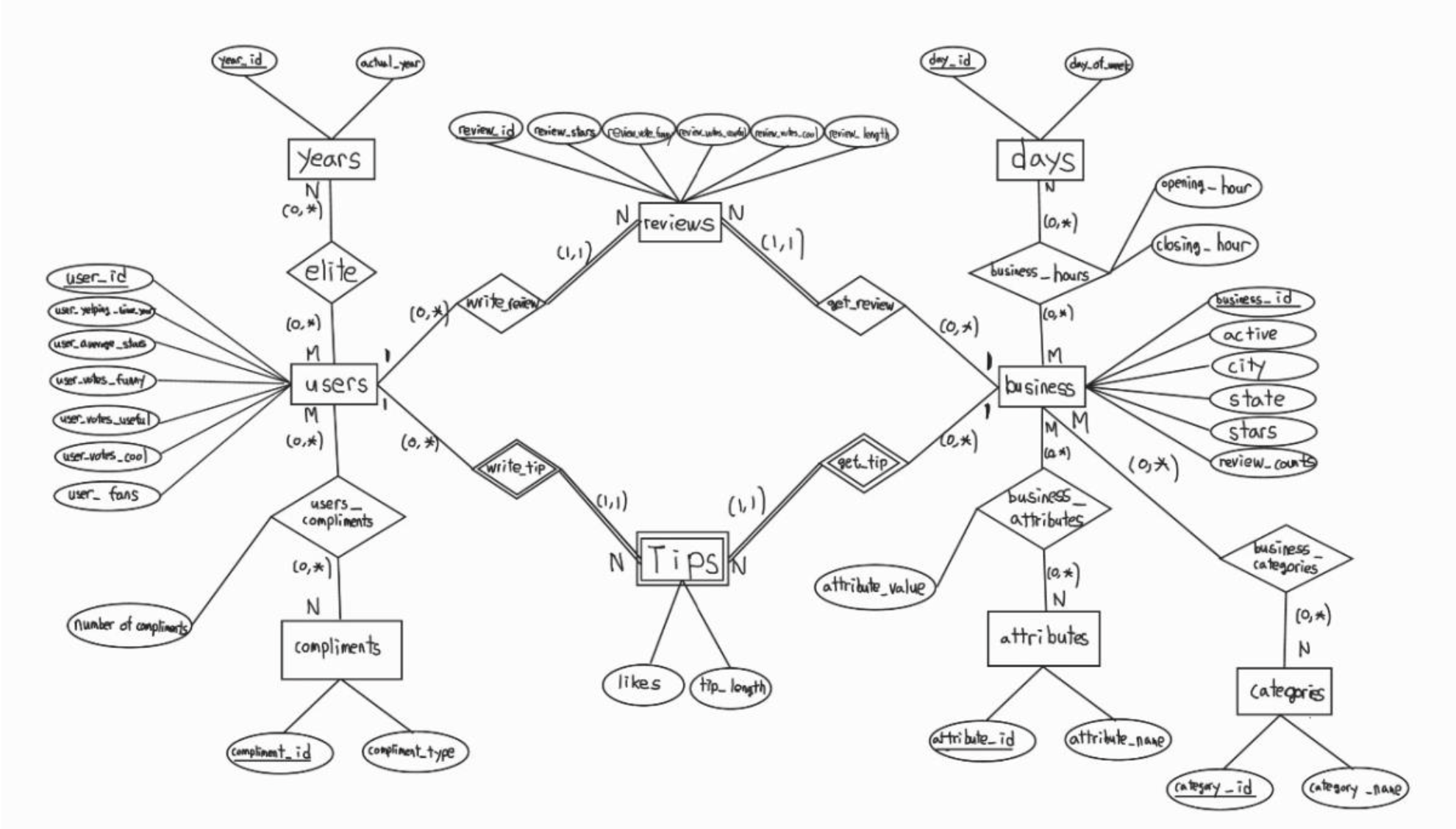
2021년 2학기 데이터 관리와 분석 전공 강의에서 진행하였던 프로젝트를 정리하고자 한다. 한 학기동안 DB에 대해서 이해하고 SQL을 통해 이를 다루는 법을 배웠다.
2022년 7월 26일
2.[데이터 관리와 분석] DB mining & Automated Recommendation System - 2차 프로젝트
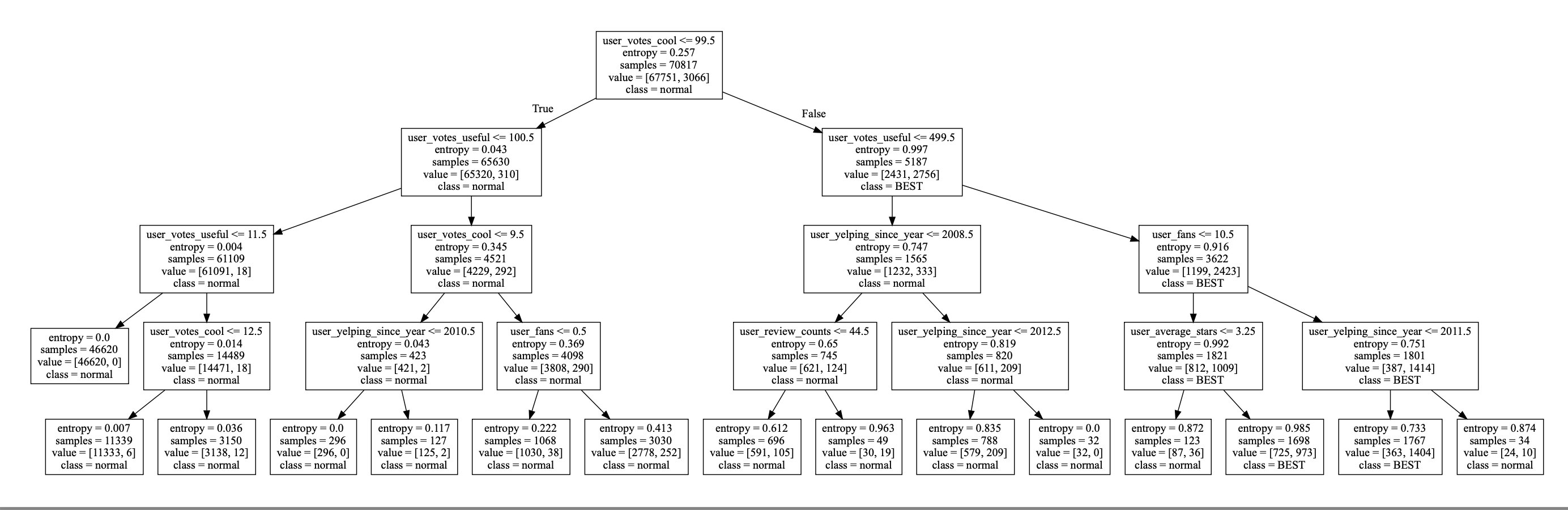
2차 프로젝트 DB mining 및 Automated Recommendation System 구현을 목적으로 한다.
2022년 7월 28일
3.[데이터 관리와 분석] Document search engine & Classification and Clustering - 3차 프로젝트
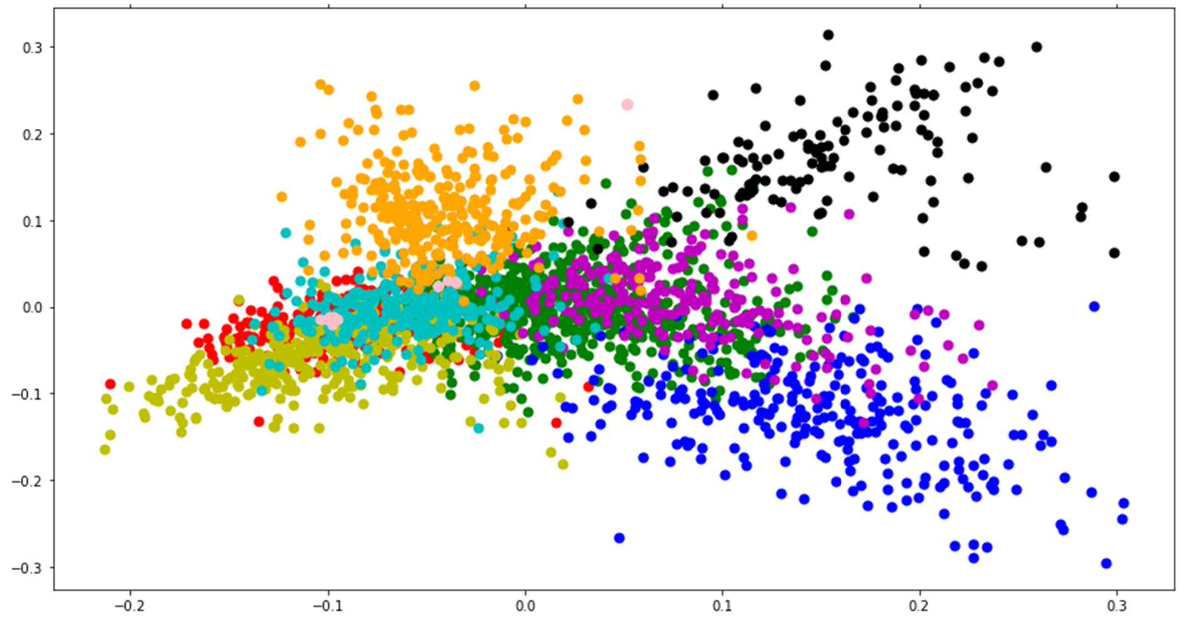
3차 프로젝트 텍스트 데이터에 대해 검색 엔진 모듈, 분류 및 군집화 모델 구현을 목적으로 한다. 3차 프로젝트는 문서 검색 엔진과 문서 분류 및 군집화로 이루어져 있다.
2022년 7월 30일
4.[데이터 관리와 분석] TF-IDF
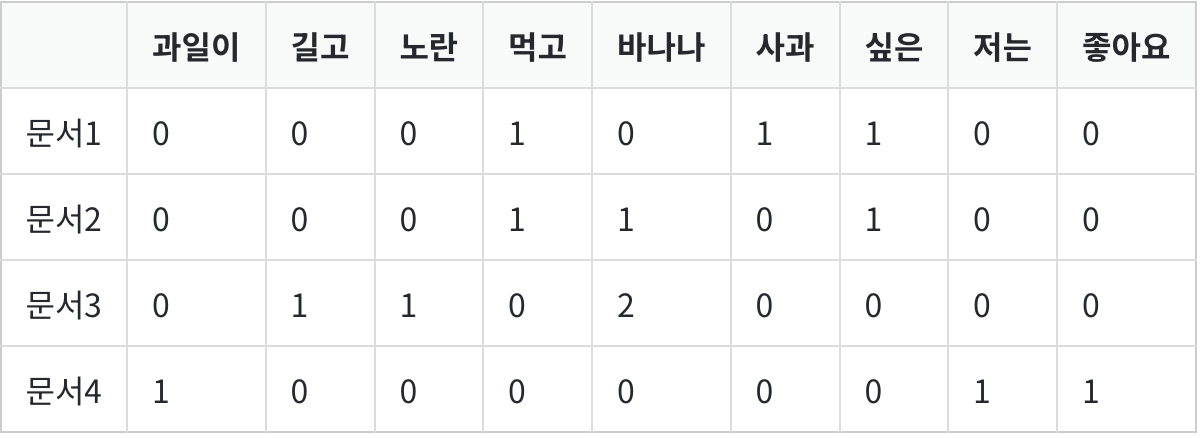
tf-idf란 단어의 중요도를 계산하는 가장 대표적인 기법이다.
2023년 11월 22일
5.[선형대수학] SVD를 위한 기초

SVD 하기 전에 대각화를 알아야 되고 대각화를 알기 전에 고유값(eigen value)과 고유 벡터(eigen vector)에 대해 알아야 한다.. 맨날 까먹어서 정리한다.
2023년 11월 22일
6.[선형대수학] SVD를 위한 기초
SVD 하기 전에 대각화를 알아야 되고 대각화를 알기 전에 고유값(eigen value)과 고유 벡터(eigen vector)에 대해 알아야 한다.. 맨날 까먹어서 정리한다.
2023년 11월 22일
7.[데이터 관리와 분석] PCA
공분산 행렬을 먼저 이해할 필요가 있다.
2023년 11월 23일
8.[word representation] 1. word represntation 분류
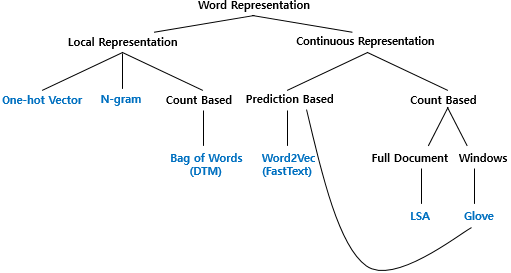
word representation의 필요성
2023년 11월 27일