📒 Python Data Structure
Python에서 자료구조를 사용하는 법에 대한 강의였다.
학교에서 자료구조 수업 도우미를 1년간 했기에 자신있는 분야였다.
파이썬 Collections 내부에 처음보는 이름도 있어서 신기했다.
오늘 강의가 끝나면 Collections 파일을 뜯어볼 생각이다.
📝 Stack
- 나중에 넣은 데이터를 먼저 반환하도록 설계된 메모리 구조
- LIFO(Last In First Out)의 구조를 갖는다.
- 데이터의 입력을 Push, 출력을 Pop이라고 한다.
- 파이썬에서는 List를 사용하여 Stack을 쓸 수 있다.
>>> a = [1, 2, 3, 4, 5]
>>> a.append(6) # Push
>>> a.pop() # Pop
6
>>> a.pop() # pop을 return 값도 가지며, 자료도 변화시킨다.
5📝 Queue
- 먼저 넣은 데이터를 먼저 반환하도록 설계된 메모리 구조
- FIFO(First In First Out)의 구조를 갖는다.
- 데이터의 입력을 enqueue, 출력을 dequeue라고 한다.
- 파이썬에서는 List를 사용하여 Queue를 쓸 수 있다.
>>> a = [1, 2, 3, 4, 5]
>>> a.append(6) # enqueue
>>> a.pop(0) # dequeue
1
>>> a.pop(0)
2
>>> print(a)
[3, 4, 5, 6]📝 Tuple
- 값의 변경이 불가능한 리스트
- 선언 시 "[ ]"가 아닌 "( )"를 사용한다.
- 리스트의 연산, 인덱싱, 슬라이싱 등을 동일하게 사용할 수 있다.
>>> t = (1, 2, 3)
>>> type(t)
tuple
>>> t + t
(1, 2, 3, 1, 2, 3)
>>> len(t)
3
>>> t[0] = 5 # 값을 변경할 수 없다.
TypeError: 'tuple' object does not support item assignment
>>> t2 = (2)
>>> type(t2)
int # 값이 하나인 tuple이여도, ','를 반드시 사용하자!✏️ Why use?
프로그램을 작동하는 동안 변경되지 않는 데이터를 저장할 때 주로 사용한다.
함수의 반환 값 등 사용자의 실수에 의한 에러를 사전에 방지할 수 있다.
📝 Set
- 값을 순서없이 저장, 중복을 불허 하는 자료형이다.
- 파이썬에서는 set 객체 선언을 이용하여 객체를 생성할 수 있다.
✏️ 기본 문법
>>> s = set([1, 2, 3, 1, 2, 3]) # s = {1, 2, 3} 도 가능하다.
>>> type(s)
set
>>> print(s)
{1, 2, 3} # 중복 자료는 제거한다.
>>> s.add(4) # 원소 추가
>>> s.remove(2) # 원소 제거. s.discard(2) 와 같은 문법
>>> print(s)
{1, 3, 4}
>>> s.update([1, 2, 5, 6]) # 한 번에 여러개 추가
>>> print(s)
{1, 2, 3, 4, 5, 6}
>>> s.clear() # 모든 원소를 삭제remove()는 존재하지 않는 원소를 지우려고 하면 Error가 난다.
discard()는 원소가 존재하지 않는 경우도 보장시켜준다. ✏️ 집합의 연산
>>> s1 = {1, 2, 3, 4}
>>> s2 = {3, 4, 5, 6}
>>> s1.union(s2) # 합집합. s1 | s2 와 같은 문법이다.
{1, 2, 3, 4, 5, 6}
>>> s1.intersection(s2) # 교집합. s1 & s2 와 같은 문법이다.
{3, 4}
>>> s1.difference(s2) # 차집합. s1 - s2 와 같은 문법이다.
{1, 2}📝 Dictionary
- 데이터를 저장 할 때 구분 지을 수 있는 값을 함께 저장한다. (Hash Table or Map)
- 구분을 위한 데이터 고유 값을 Identifier 또는 Key라고 한다.
- Key 값을 활용하여 Value(데이터 값)을 관리한다.
👉 key와 value를 매칭하여 key로 value를 검색한다. - { Key1:Value1, Key2:Value2, Key3:Value3... }의 형태를 갖는다.
- 내부적으로 Hash Table을 사용해서 구현한다.
>>> country_code = { "America":1, "Korea":82, "China":86 } # 선언. dict()로 생성 가능
>>> country_code.items() # 보통 for 문을 돌릴 떄 사용한다.
dict_items([('America', 1), ('Korea', 82), ('China', 86)]) # 각 tuple 형태이다.
>>> country_code.keys() # key 값들만 반환한다.
dict_keys(['America', 'Korea', 'China')]
>>> country_code['Japan'] = 81 # Dict 추가. 기존 Key에 value를 바꿀 수도 있다.
>>> country_code.values() # value 값들만 반환한다.
dict_values([1, 82, 86, 81])
>>> "Korea" in country_code.keys() # Key 값에 특정 값이 있는지 확인. value도 가능
📝 Deque
- Stack과 Queue를 지원하는 모듈
- List에 비해 효율적인(빠른) 자료 저장 방식을 지원한다.
- rotate, reverse 등 Linked List의 특성을 지원한다.
- 기존 list 형태의 함수를 모두 지원한다.
>>> from collections import deque
>>> deque_list = deque() # 생성자
>>> for i in range(5):
... deque_list.append(i) # 뒤에 추가
>>> deque_list.appendleft(5) # 앞에 추가
>>> deque_list # extend([]), extendleft([]) 문법도 사용 가능하다.
deque([5, 0, 1, 2, 3, 4])
>>> deque_list.rotate(1)
>>> deque_list
deque([4, 5, 0, 1, 2, 3])
>>> deque_list.pop() # 뒤에서 제거
3
>>> deque_list.popleft() # 앞에서 제거
4
# insert, remove 등으로 인덱스에도 접근 가능하다.📝 OredredDict
Dict Type의 값을 key 또는 value로 정렬할 때 사용 가능하다.

📝 defaultdict
- Dict type의 값에 기본 값을 지정한다.
- 신규 값을 생성시 사용하기 편하다.
>>> from collections import defaultdict
>>> d = defaultdict(labda : 0) # 초기값은 함수 형태로 넣어야된다.
>>> d["first"]
0d = dict()
d["Key"]=d.get("Key",0) + 1 # get을 사용해서도 가능하다. 📝 Counter
Sequence type의 data element들의 갯수를 dict 형태로 반환한다.
>>> from collections import Counter
>>> bat_count = ["B", "S", "B", "B", "S"]
>>> Counter(bat_count)
Counter({ 'B':3, 'S':2 })📒 Pythonic code
파이썬 스타일의 코딩 기법과 파이썬 특유 문법을 활용해 효율적 코드 작성법을 알려주셨다.
고급 코드를 작성하기 위해서는 이러한 문제도 꼭 필요하다고 생각한다.
C++ 스타일에 익숙한 나에게 정말 유용한 강의였다.
📝 split & join
text data를 핸들링하는 것에 대한 기초적인 문법이다.
>>> items = 'zero one two three'.split() # 빈칸을 기준으로 문자열 나누기
>>> print(items)
['zero', 'one', 'two', 'three']
>>> example = 'python,java,javascript'
>>> examples = example.split(',') # ','를 기준으로 문자열 나누기
>>> print(examples)
['python', 'java', 'javascript']
>>> p, j, js = example.split(',') # 패킹, 언패킹도 가능
>>> '-'.join(examples) # join 문법. 사이에 '-'를 추가해서 문자열로 반환
'python-java-javascript'
📝 list comprehension
- 기존 List를 사용하여 간단히 다른 List를 만드는 기법
- 일반적오르 for + append 보다 속도가 빠르다.
>>> result = [i for i in range(5)] # 기본 문법(for range)
>>> result
[0, 1, 2, 3, 4]
>>> result = [i for i in range(10) if i % 2 == 0] # if문으로 filter 추가 가능
>>> result
[0, 2, 4, 6, 8]
>>> word1 = 'ab'
>>> word2 = 'cd'
>>> result = [i + j for i in word1 for j in word2] # 2중 for문도 가능
>>> result
['ac', 'ad', 'bc', 'bd']
>>> result = [ [i + j for i in word1] for j in word2] # 뒤의 for문이 먼저 동작
>>> result
[['ac, bc'], ['ad, 'bd']]📝 enumerate & zip
✏️ enumerate
list의 element를 추출할 때 번호를 붙여서 추출해준다.
>>> for i, v in enumerate('ABC'): # 기본 문법(list도 가능!)
... print(i, v)
0 A
1 B
2 C
>>> {v : i for i, v in enumerate('ABCD')} # dictionary로 만들기
{'A' : 0, 'B' : 1, 'C' : 2, 'D' : 3}✏️ zip
두 개의 list의 값을 병렬적으로 추출한다.
>>> alist = ['a1', 'a2', 'a3']
>>> blist = ['b1', 'b2', 'b3']
>>> for a, b in zip(alist, blist): # 병렬적으로 값을 추출
... print(a, b)
a1 b1
a2 b2
a3 c3📝 lambda & map & reduce
✏️ lambda
함수 이름 없이, 함수처럼 쓸 수 있는 익명 함수이다.
수학의 람다 대수에서 유래했다.
"""
def f(x, y):
return x + y
"""
>>> f = lambda x, y : x + y # 기몬 문법. 상단 함수와 동일 로직
>>> f(10, 20)
30✏️ map
sequence형 data가 있을 때 각각의 data를 mapping을 해주는 function이다.
>>> ex = [1, 2, 3, 4, 5]
>>> list(map(lambda x : x ** 2, ex)) # list화 해주어야 됨!
[1, 4, 9, 16, 25]list comprehension, lambda 등으로 대체가 가능하다.
✏️ reduce
map function과 달리 list에 똑같은 함수를 적용해서 통합한다.
>>> from functools import reduce
>>> print(reduce(lambda x, y : x + y, [1, 2, 3, 4, 5])) # 하단 사진 참고
15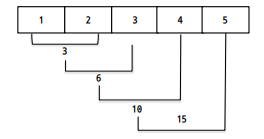
👉 Map-Reduce는 대용량 데이터를 다루는 Legacy library나 다양한 ML 코드에서 주로 사용한다.
📝 generator
✏️ iterable objects
Sequence 자료형에서 데이터를 순서대로 추출하는 object
>>> cities = ['Seoul', 'Busan', 'Suwon']
>>> memory_address = iter(cities) # iterable objects 선언
>>> next(memory_address)
'Seoul'
>>> next(memory_address)
'Busan'
>>> next(memory_address)
'Suwon'
>>> next(memory_address)
StopIteration✏️ generator
- iterable object를 특수한 형태로 사용해주는 함수
- element가 사용되는 시점에 값을 메모리에 반환
👉yield를 사용해 한번에 하나의 element만 반환한다.
>>> gen_ex = (n * n for n in range(100))
>>> print(type(gen_ex)) # 호출 단계에서 하나씩 반환된다.
<class 'generator'>메모리를 아끼기 위해서 대용량 데이터 처리에 사용하면 좋다.
📝 asterisk
✏️ passing arguments
함수에 입력되는 arguments의 다양한 형태이다.
- Keyword arguments
함수에 입력되는 parameter의 변수명을 사용하여, arguments를 넘긴다.
def print_person(name, age):
print(name, age)
print_person("Gyuho", 26)
print_person(name="Gyuho", age="26") # <<<- Default arguments
parameter의 기본 값을 사용, 입력하지 않는 경우 기본값을 출력한다.
def print_person(name, age=20):
print(name, age)
print_person("Gyuho") # age는 자동으로 20이 들어간다.
print_person("Gyuho", 26) # 물론, 값을 넣을수도 있다.- Variable-length arguments
함수의 parameter가 정해지지 않았을 때 사용한다.
asterisk를 사용한다.
✏️ Variable-length asterisk
- 개수가 정해지지 않은 변수를 함수의 parametr로 사용하는 방법이다.
- Keword arguments와 함께, argument 추가가 가능하다.
- Asterisk(*) 기호를 사용하여 함수의 parameter를 표시한다.
- 입력된 값은 tuple type으로 사용할 수 있다.
- 가변인자는 오직 한 개만 맨 마지막 parameter 위치에 사용 가능하다.
- 가변인자는 일반적으로 *args 를 변수명으로 사용한다.
def asterisk_test(*args):
return sum(args)
print(asterisk_test(1, 2, 3, 4, 5))
# 15가 출력된다.✏️ 키워드 가변인자(Keyword variable-length)
- Parameter 이름을 따로 지정하지 않고 입력하는 방법이다.
- asterisk(*) 두개를 사용하여 함수의 parameter를 표시한다.
- 입력된 값은 dict type으로 사용할 수 있다.
- 가변인자는 오직 한 개만 기존 가변인자 다음에 사용한다.
def kwargs_test(**kwargs):
print(kwargs)
kwargs_test(first = 1, second = 2, third = 3)
# {'first':1, 'second:'2, 'third':3} 가 출력된다.⭐️ 이 밖에도 asterisk는 tuple, dic 등 자료형의 값을 unpacking 할 때도 사용된다.
