📒 Exception / File / Log Handling
완성도 높은 프로그램을 개발할 때 예외처리와 로깅은 필수다.
내가 아직 익숙하게 사용하고 있지는 않아서 집중해서 들었다.
argparser는 따로 공부해야 되겠다.
📝 Exception
✏️ 예상 가능한 예외
- 발생 여부를 사전에 인지할 수 있는 예외
- 사용자의 잘못된 입력, 파일 호출 시 파일이 없는 경우 등
- 개발자가 반드시 명시적으로 정의해야 된다.
- 보통 if문으로 처리할 수 있다.
✏️ 예상 불가능한 예외
- 인터프리터 과정에서 발생하는 예외로, 개발자의 실수이다.
- 리스트의 범위를 넘어가는 값 호출, 정수를 0으로 나눔 등 (런타임 에러)
- 수행이 불가능할 시 인터프리터가 자동으로 에러를 호출하고 프로그램을 종료한다.
- Exception Handling을 사용해서 처리할 수 있다. (파이썬에서 권장)
✏️ Exception Handling
try ~ except 문법을 사용한다.
try:
# 예외 발생 가능 코드
except <Exception Type>:
# 예외 발생시 대응하는 코드
else:
# 예외가 발생하지 않을 때 동작하는 코드
finally:
# 예외와 관련 없이 항상 실행되는 코드try 구문을 실행시키면서, Exception Type에 해당하는 에러가 발생하면 except 구문으로 이동한다.for i in range(10):
try:
print(10 / i)
except ZeroDivisionError: # exception이 발생해도 프로그램이 종료되지 않는다.
print("Not divided by 0")
except Exception as e:
print(e) # 무슨 에러인지 출력할 수 있다. 보통 마지막에 사용 (권장 x)if-else 구문과도 비슷하다.✏️ Built-in Exception
기본적으로 제공하는 예외이다.
| Esception 이름 | 내용 |
|---|---|
| IndexError | List의 Index 범위를 넘어갈 때 |
| NameError | 존재하지 않는 변수를 호출 할 때 |
| ZeroDivisionError | 0으로 숫자를 나눌 때 |
| ValueError | 변환할 수 없는 문자/숫자를 변환하려고 할 때 |
| FileNotFoundError | 존재하지 않는 파일을 호출할 때 |
훨씬 종류가 다양하며, 개인이 만들수도 있다.
✏️ raise 구문
필요에 따라 강제로 Exception을 발생시킨다.
while True:
value = input("변환할 정수 값 입력")
for digit in value:
if digit not in "0123456789":
raise ValueError("숫자값을 입력") # 코드를 멈춘다.
print("정수값으로 변환된 숫자 -", int(value))✏️ assert 구문
특정 조건에 만족하지 않을 경우 예외를 발생시킨다.
주로 함수에서 사용한다.
def get_binary_number(decimal_number):
assert isinstance(decimal_number, int) # 코드를 멈춘다.
return bin(decimal_number)📝 File Handling
✏️ 파일의 종류
- 기본적인 파일 종류로 text 파일과 binary 파일이 있다.
- 컴퓨터는 text 파일을 처리하기 위해 binary 파일로 변환시킨다. (pyc파일)
- 모든 text 파일도 실제로는 binary 파일이다.
| Binary 파일 | Text 파일 |
|---|---|
| 컴퓨터만 이해할 수 있는 형태인 이진형식으로 저장된 파일 | 인간도 이해할 수 있는 형태인 문자열 형식으로 저장된 파일 |
| 메모장으로 열면 내용이 깨져보인다. | 메모장으로 내용 확인이 가능하다. |
| 엑셀파일, 워드 파일 등등 | HTML 파일, 파이썬 코드 파일 등등 |
✏️ Python File I/O
파이썬은 파일 처리를 위해 'open' 키워드를 사용한다.
f = open('text.txt', 'r') # 파일 열기
contents = f.read() # 파일의 내용을 string으로 저장
f.close() # 파일 닫기| 파일열기모드 | 설명 |
|---|---|
| r | 읽기모드 - 파일을 읽기만 할 때 사용 |
| w | 쓰기모드 - 파일에 내용을 쓸 때 사용 |
| a | 추가모드 = 파일의 마지막에 새로운 내용을 추가 시킬 때 사용 |
with 구문과 함께 사용 가능하다.
with open('text.txt', 'r') as f: # 별도의 close가 필요 없다.
contents = f.readlines() # line별로 list로 저장한다.
print(type(contents))
# list 출력File Write
f = open('log.txt', 'w', encoding='utf8') # 일반적으로 한글은 utf8. 항상 확인
for i in range(1, 11):
data = '%d Line.\n' % i
f.write(data) # 파일에 string을 쓴다.
f.close()✏️ Python directory
os 모듈을 사용하여 directory를 다룰 수 있다.
import os
try:
os.mkdir('log') # 폴더를 생성한다.
except FileExistsError as e: # == os.path.exists('폴더명')
print("Already created")파일을 옮길 때는, shutil을 사용한다.
import shutil
import os
after = os.path.join('dir', 'text.txt') # dir 폴더에 text.txt 파일을 넣고, path를 반환최근에는 pathlib 모듈을 사용하여 path를 객체로 다룰 수 있다.
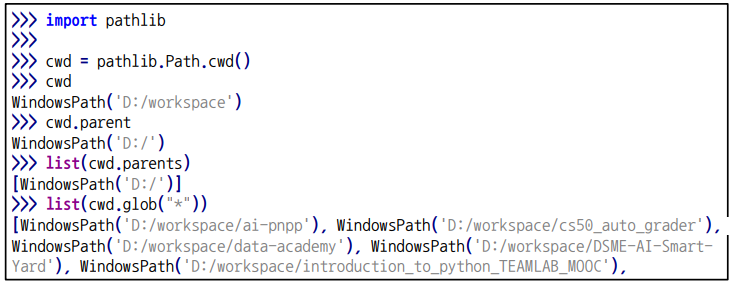
✏️ Log 파일 생성하기

✏️ Pickle
- 파이썬의 객체를 영속화(persistence)하는 built-in 객체
- 데이터, object 등 실행중 정보를 저장하여, 불러서 사용한다.
- 저장해야하는 정보, 계산 결과(모델) 등 다양하게 활용할 수 있다.
import pickle
f = open('list.pickle', 'wb') # b는 binary file을 의미한다.
test = [1, 2, 3, 4, 5]
pickle.dump(test, f) # test를 f에 저장한다.
f.close()
del test # 객체 삭제 (메모리에서 지워진다.)
f = open('list.pickle', 'rb')
test_pickle = pickle.load(f)
test_pickle
# [1, 2, 3, 4, 5] 가 살아서 돌아온다.
f.close()📝 Log Handling
✏️ 로그 남기기
- 프로그램이 실행되는 동안 일어나는 정보의 기록을 남긴다.
- 유저의 접근, 프로그램의 Exception, 특정 함수의 사용 등의 상황
- Console 화면에 출력, 파일에 남기기, DB에 남기기 등의 기록
- 기록된 로그를 분석하여 의미있는 결과를 도출 할 수 있다.
- 실행시점에서 남겨야 하는기록과 개발시점에서 남겨야하는 기록을 분리한다.
✏️ logging 모듈
프로그램 진행 상황에 따라 다른 Level의 Log를 출력한다.
👉DEBUG > INFO > WARNING > ERROR > CRITICAL
import logging
logger = logging.getLogger('main')
logging.basicConfig(level=logging.DEBUG) # 레벨 설정
logger.setLevel(logging.INFO)
logging.debug('개발시 처리 기록을 남겨야하는 로그 정보')
logging.info('처리가 진행되는 동안의 정보')
logging.warning('사용자가 잘못 입력한 정보나 처리는 가능하나 의도치 않는 정보가 들어올 때')
logging.error('에러가 났으나, 프로그램은 동작할 수 있을 때')
logging.critical('잘못된 처리로 데이터 손실이나 더 이상 프로그램이 동작할수 없을 때')
steam_handler = logging.FileHandler(
'my.log', mode='w', encoding='utf8')
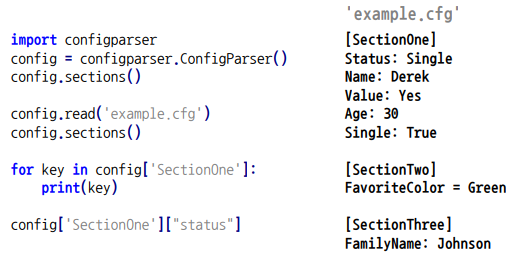
logger.addHandler(steam_handler) # 로그를 파일로 남기는 방법✏️ configparser
- 프로그램의 실행 설정을 file에 저장할 수 있다.
- Section, Key, Value 값의 형태로 설정된 설정 파일을 사용한다.
- 설정 파일을 Dict Type으로 호출 후 사용한다.
📒 Python data handling
파이썬에서 다룰 수 있는 CSV, 웹, XML, JSON 네 가지 데이터 타입에 대해 배웠다.
Data Science에서 다양한 데이터 타입을 다룰 수 있는 능력은 필수적이다.
이 밖에도 이미지, 소리, 영상 파일을 다루는 방법도 공부해야겠다.
📝 CSV(Comma separate Values)
- 필드를 쉼표(,)로 구분한 텍스트 파일이다.
- 엑셀 양식의 데이터를 프로그램에 상관없이 쓰기 위한 데이터 형식이다.
- 탭(TSV), 빈칸(SSV) 등으로 구분해서 만들기도 한다.
- 일반 텍스트 파일을 처리하듯 파일을 읽어온 후, 한 줄 한 줄씩 데이터를 처리한다.
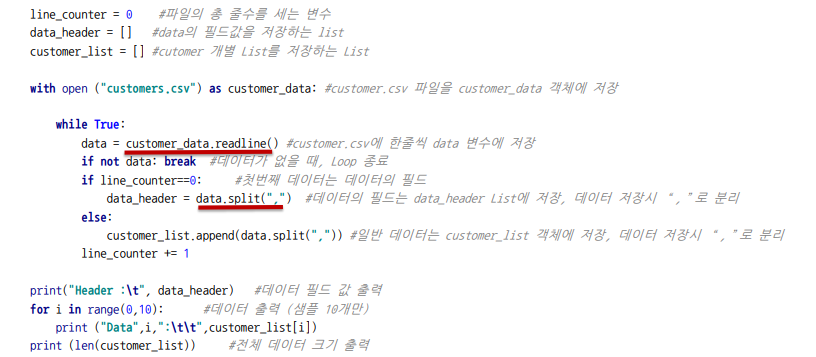
✏️ CSV 모듈
- 데이터 처리시 문장 내에 들어가 있는 ',' 등에 대해 전처리 과정이 필요하다.
- 파이썬에서는 간단히 csv 파일을 처리하기 위해 csv 객체를 제공한다.
import csv
reader = csv.reader(f,
delimiter=',', quotechar='"',
quoting=csv.QUOTE_ALL)| Attribute | Default | Meaning |
|---|---|---|
| delimiter | , | 글자를 나누는 기준 |
| lineterminator | \r\n | 줄 바꿈 기준 |
| quotechar | " | 문자열을 둘러싸는 신호 문자 |
| quoting | QUOTE_MINIMAL | 데이터 나누는 기준이 quotechar에 의해 둘러싸인 레벨 |
📝 Web(World Wide Web)
- 인터넷 공간의 정식 명칭이다.
- 데이터 송수신을 위한 HTTP 프로토콜을 사용한다.
- 데이터를 표시하기 위해 HTML 형식을 사용한다.
✏️ HTML
- 웹상의 정보를 구조적으로 표현하기 위한 언어이다.
- 제목, 단락, 링크 등 요소 표시를 위해 Tag를 사용한다. (MarkUp Language)
- 모든 요소들은 '< >' 안에 둘러싸여 있다.
- 모든 HTML은 트리 모양의 포함 관계를 갖고 있다.
import urllib.request
url = 'https://gyuholee.com'
html = urllib.request.urlopen(url)
html_contents = str(html.read())✏️ 정규식(regular expression)
- 정규 표현식, regexp 또는 regex 등으로 불린다.
- 복잡한 문자열 패턴을 정의하는 문자 표현 공식이다.
- 특정한 규칙을 가진 문자열의 집합을 추출한다.
- Jump to Python Link (이보다 더 완벽할 수가 없다.)
⭐️ 정규표현식 살펴보기
⭐️ 정규표현식 시작하기
⭐️ 강력한 정규 표현식의 세계로
📝 XML(eXtensible Markup Language)
- 데이터의 구조와 의미를 설명하는 TAG(MarkUp)를 사용하여 표시하는 언어
- Tag와 Tag사이에 값이 표시되고, 구조적인 정보를 표현할 수 있다.
- HTML과 문법이 비슷한 대ㅛ적인 데이터 저장 방식이다.
- 정보의 구조에 대한 정보인 스키마와 DTD 등으로 메타정보가 표현된다.
- 컴퓨터간에 정보를 주고받기 매우 유용한 저장 방식으로 쓰고 있다.
- 파이썬에서는 가장 많이 쓰이는 parser인 beautifulsoup으로 파싱한다.
<?xml version="1.0"?>
<books>
<book>
<author>Carson</author>
<price format="dollor">31.95</price>
<pubdate>05/01/2001</pybdate>
</book>
<pubinfo>
<publisher>MSPress</publisher>
<state>WA</state>
</pubinfo>
<book>
<author>Sungchul</author>
<price format="dollor">29.95</price>
<pubdate>05/01/2012</pybdate>
</book>
<pubinfo>
<publisher>Gachon</publisher>
<state>SeoungNam</state>
</pubinfo>✏️ beautifulsoup
- HTML, XML 등 MarkUp 언어 Scraping을 위한 대표적인 도구
- 공식 사이트
# 설치 가이드
(base) λ conda install lxml
(base) λ conda install -c beautifulsoup4from bs4 import BeautifulSoup # 모듈 호출
whth open("books.xml", "r", encoding="utf8") as books_file:
books_xml = books_file.read()
soup = BeautifulSoup(books_xml, 'lxml') # (파일, 파서)로 객체 생성
for book_info in soup.find_all("author"):
print(book_info)
print(book_info.get_text())
# 출력
# <author>Carson</author>
# Carson
# <author>Sungchul</author>
# Sungchul📝 JSON(JavaScript Object Notation)
- 원래 웹 언어인 JavaScript의 데이터 객체 표현 방식이다.
- 데이터 용량이 적고, Code로의 전환이 쉬어 XML의 대체제로 많이 활용된다.

- json 모듈을 사용하여 손 쉽게 파싱 및 저장이 가능하다.
✏️ json 모듈
- 데이터 저장 및 일기는 dict type과 상호 호환 가능하다.
- 각 사이트마다 Developer API의 활용법을 찾아서 사용하면 된다.
import json
# 읽기
with open("example.json", "r", encoding="utf8") as f:
contents = f.read()
json_data = json.loads(contents)
print(json_data["properties"]
# 쓰기
dict_data = {}
with open("data.json", "w") as f:
json.dump(dict_data, f)
Beginner