📒 시각화 도구
파이썬에는 신기한 시각화 도구가 많았다.
사용법 자체는 어렵지 않았고, 내용도 그렇게 많지 않았다.
코드를 바꿔가면서 이것저것 해보느라 시간이 좀 많이 걸렸다.
앞으로 큰 어려움 없이 유용하게 사용할 수 있을 것 같다.
📝 Matplotlib
- Pandas와 연동하여 다양한 graph를 지원한다.
- pyplot 객체를 사용하여 그래프들을 쌓은 다음 flush하여 데이터를 표시한다.
import matplotlib.pyplot as plt
X = range(100)
Y = [value**2 for value in X]
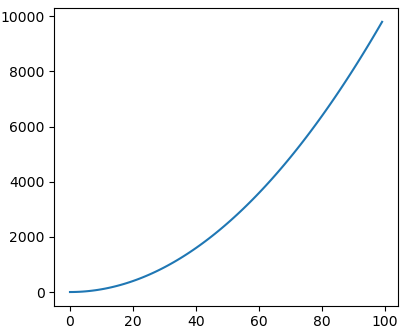
plt.plot(X, Y)
plt.show()- figure에 쌓였다가, show를 하면 다음과 같이 시각화하여 보여준다.
- 최대 단점으로 argument를 kwargs로 받는다.
👉 고정된 argument가 없어서 shift + tap으로 확인하기가 어렵다. - figure 객체 위에 생성되며 pyplot 객체 사용시, 기본 figure에 그래프가 그려진다.
- Matplotlib는 Figure 위에 여러 개의 Axes를 생성하여 구성된다.
fig = plt.figure() # figure 반환
fig.set_size_inches(10, 5) # 크기 지정(가로, 세로)
ax_1 = fig.add_subplot(1, 2, 1) # (row, column, index)
ax_2 = fig.add_subplot(1, 2, 2) # 두개의 plot 생성
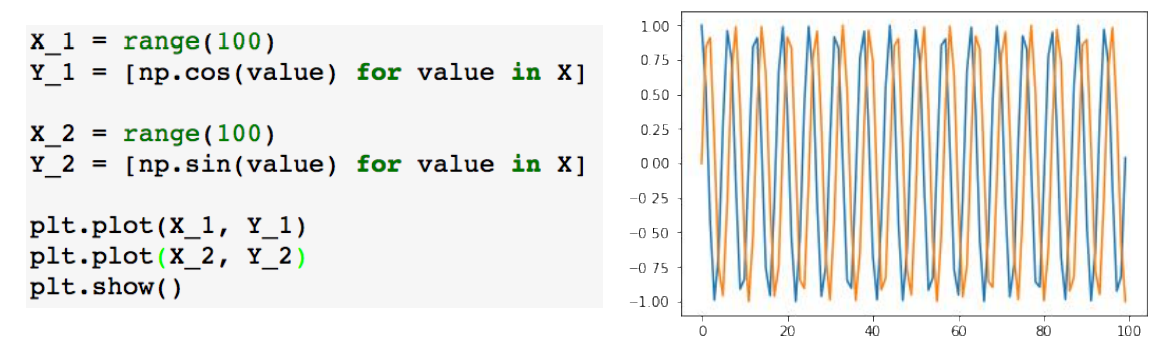
ax_1.plot(X_1, Y_1, c="b") # color까지 설정
ax_2.plot(X_2, Y_2, c="g")
plt.show()
- subplot의 순서는 gird로 작성한다.
- 이밖에도 c(color), ls(linestyle), title, legend, grid 등 설정이 가능하다.
import matplotlib.pyplot as plt
X = range(100)
Y_1 = [value + 50 for value in X]
Y_2 = [value + 100 for value in X]
plt.style.use("ggplot") # 스타일 적용
plt.plot(X, Y_1, c='b', ls='dashed', label='Y1')
plt.plot(X, Y_2, c='r', ls='dotted', label='Y2')
plt.title("$y = \\frac{ax + b}{test}$") # Latex 문법 가능
plt.legend(shadow=True, fancybox=True, loc="lower right") # 범례
plt.show()
📝 Matplotlib graph
✏️ scatter
- scatter 함수를 사용하여 산점도를 나타낼 수 있다.
- 산점도 : 직교 좌표계를 이용해 두 개 변수 간의 관계를 나타내는 방법
import matplotlib.pyplot as plt
import numpy as np
data_1 = np.random.rand(512, 2) # 512 X 2 크기
data_2 = np.random.rand(512, 2)
plt.scatter(data_1[:, 0], data_1[:, 1], c='b', marker='x')
plt.scatter(data_2[:, 0], data_2[:, 1], c='r', marker='^')
plt.show()
✏️ bar chart
- bar 함수를 사용해서 막대 그래프를 만들 수 있다.
import matplotlib.pyplot as plt
import numpy as np
data = [[5., 25., 50., 20.],
[4., 23., 51., 17.],
[6., 22., 52., 19.]]
X = np.arange(4)
plt.bar(X + 0.00, data[0], color='b', width=0.25)
plt.bar(X + 0.25, data[1], color='g', width=0.25)
plt.bar(X + 0.50, data[2], color='r', width=0.25)
plt.xticks(X + 0.25, ("A","B","C","D"))
plt.show()
✏️ histogram
- hist 함수를 사용해서 분포 차트를 표현할 수 있다.
import matplotlib.pyplot as plt
import numpy as np
X = np.random.randn(1000)
plt.hist(X,bins=100) # 히스토그램을 몇개로 나누냐
plt.show()
✏️ boxplot
import matplotlib.pyplot as plt
import numpy as np
data = np.random.randn(100, 5)
plt.boxplot(data)
plt.show()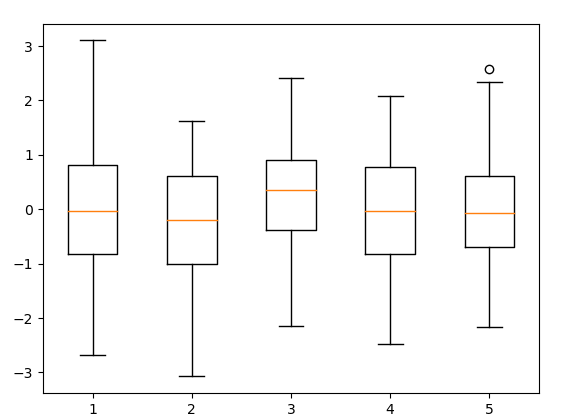
✏️ Seaborn
- matplotlib를 좀 더 쉽게 사용하기 위해서 지원하는 도구이다.
- 복잡한 그래프를 간단하게 만들수 있는 wrapper이다.
- 정리하기는 힘들고.. 여기서 그 때 그 때 찾아보자.
📒 통계학 맛보기
40분짜리 강의를 듣는데 3시간이 필요했다.
그런데도 이해를 완벽하게 하지 못했다.
주말동안 통계학도 공부해야겠다.
📝 모수
- 통계적 모델링은 적절한 가정 위에서 확률분포를 추정하는 것이 목표이다.
- 모집단의 분포를 정확하게 알아낸다는 것은 불가능하므로, 근사적으로 확률분포를 추정한다.
- 데이터가 특정 확률분포를 따른다고 선험적으로 가정
👉 그 분포를 결정하는 모수(parameter)를 추정하는 방법이 모수적(parametric) 방법론 - 데이터에 따라 모델의 구조및 모수의 개수가 유연하게 바뀌면 비모수 방법론
✏️ 확률분포 가정하기
- 데이터가 2개의 값(0 또는 1)만 가지는 경우 -> 베르누이분포
- 데이터가 N개의 이산적인 값을 가지는 경우 -> 카테고리분포, 다항분포
- 데이터가 [0, 1] 사이에서 실수 값을 가지는 경우 -> 베타분포
- 데이터가 특정 구간이 아닌 0 이상의 값을 가지는 경우 -> 감마분포, 로그정규분포
- 데이터가 R 전체에서 값을 가지는 경우 -> 정규분포, 라플라스분포
✏️ 데이터로 모수 추정하기
- 데이터의 확률분포를 가정하면 모수를 추정할 수 있다.
- 정규분포의 모수는 평균과 분산으로, 이를 추정하는 통계량은 다음과 같다.

불편 추정량 : 표분산과 모분산의 차이를 줄이기 위해서 - 통계량의 확률분포를 표집분포(sampling distribution)라 부르며, 표본평균은 N이 커질수록 정규분포를 따른다.
👉 이를 중심극한정리라 부르며, 모집단의 분포가 정규분포를 따르지 않아도 성립한다.
📝 최대가능도 추정법
- 확률분포마다 사용하는 모수가 다르므로 사용하는 적절한 통계량이 달라진다.
- 이론적으로 가장 가능성이 높은 모수를 추정하는 방법 중 하나는 최대가능도 추정법(MLE)이다.

- 데이터 집합 X가 독립적으로 추출되었을 경우 로그가능도를 최적화한다.
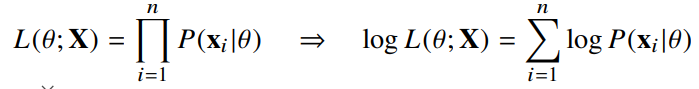
👉 데이터의 숫자가 수억 단위가 된다면 컴퓨터의 정확도로 MLE를 계산할 수 없다.
👉 데이터가 독립인 경우, 로그를 사용하면 가능도의 곱셈을 로그가능도의 덧셈으로 바꿀 수 있다.
👉 경사하강법으로 가능도를 최적화 할 때 로그 가능도를 사용하면 연산량이 O(n²)에서 O(n)으로 줄어든다.
👉 손실함수의 경우 경사하강법을 사용하므로 음의 로그가능도를 최적화하게 된다.
✏️ 정규분포 최대 가능도
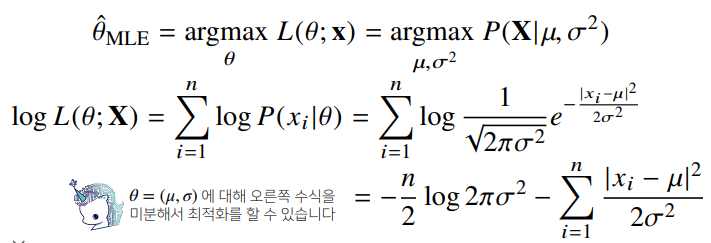
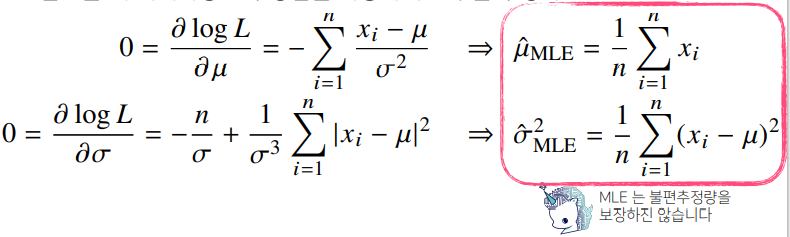
✏️ 카테고리분포 최대 가능도
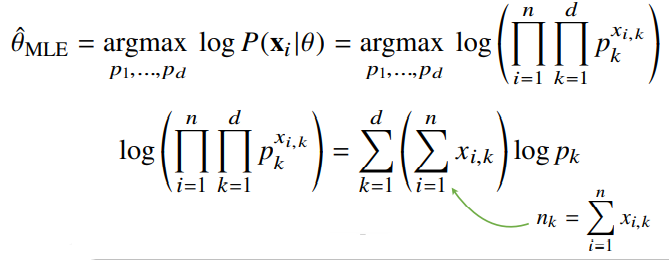
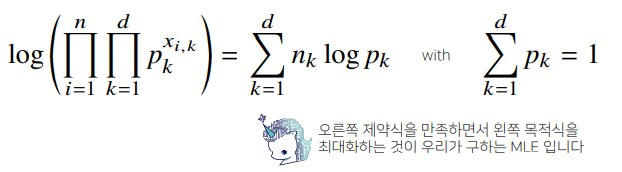
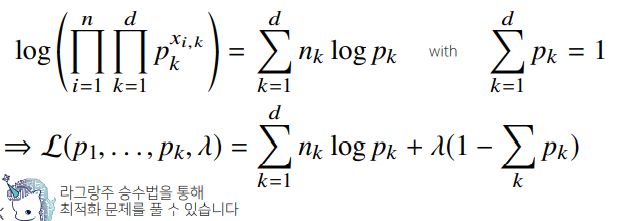
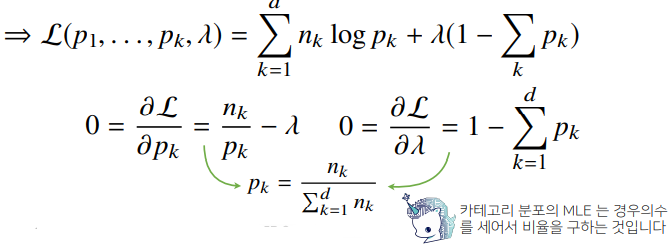
✏️ 딥러닝에서 최대가능도 추정법

✏️ 쿨백-라이블러 발산
- 쿨백-라이블러 발산(KL Divergence)은 다음과 같이 정의한다.
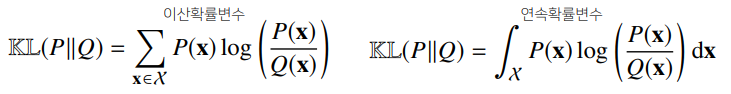
- 이를 다음과 같이 분해할 수 있다.
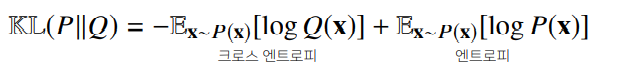
- 분류 문제에서 정답레이블을 P, 모델 예측을 Q라 둔다고 생각하면,
최대가능도 추정법은 쿨백-라이블러 발산을 최소화하는 것과 같다.
📒 [퀴즈] 통계학 맛보기- 1~5
5/5 Solve
📝 Q1
Q) 다음과 같은 표본 X가 있을 때, X의 평균을 구하시오 (정수값으로 입력).
X = {1, 2, 3, 4, 5}A) 3
(1 + 2 + 3 + 4 + 5) / 5 = 15 / 5 = 3📝 Q2
Q) 다음과 같은 표본 X가 있을 때, X의 표본분산을 구하시오 (소수점 첫째자리까지 입력).
X = {1, 2, 3, 4, 5}A) 2.5
(4 + 1 + 0 + 1 + 4) / (5 - 1) = 10 / 4 = 2.5📝 Q3
Q) 다음과 같은 표본 X가 있을 때, X의 표본표준편차를 구하시오 (정수로 입력).
X = {2, 4, 6}A) 2
sqrt{ (4 + 0 + 4) / 2 } = sqrt(8 / 2) = sqrt(4) = 2📝 Q4
Q) 정답 레이블을 one-hot 벡터로 표현한다면 하나의 정답 레이블 벡터의 크기는 1이다.
A) 아니오. (레이블의 길이)
📝 Q5
Q) KL(P || Q) 는 KL(Q || P) 와 같다.
A) 아니오. (교환법칙 성립 x)

Beginner