📒 Pandas II
어제에 이어서 Pandas에 관한 강의였다.
강의 자체는 어렵지 않았지만 워낙 데이터를 다루는 방법이 다양하기 때문에
각 상황에서 여러가지 문법들을 자유자재로 사용할 수 있는가가 중요할 것 같다.
지금 당장은 모든 문법에 익숙해지는 것이 당연히 힘들 것이다.
천천히 하나씩 하나씩 적용해나가면서 스펙트럼을 넓혀보자.
📝 GroupBy
- SQL group by 명령어와 같다.
- split -> apply -> combine 과정을 거쳐 연산한다.
df.groupby("Team")["Points"].sum() # Team을 기준으로 Points의 sum을 반환해준다.
df.groupby(["Team", "Year"])["Points"].sum() # 한 개 이상의 column을 묶을 수 있다.
grouped.add_prefix("points_") # column에 prefix 추가
df["Team"].value_counts() # Team별로 갯수 count- Groupby 명령의 결과물도 결국은 dataframe 이다.
- N개의 column으로 groupby를 할 경우, index가 N개 생성된다.
- unstack()은 group으로 묶인 데이터를 풀어준다.
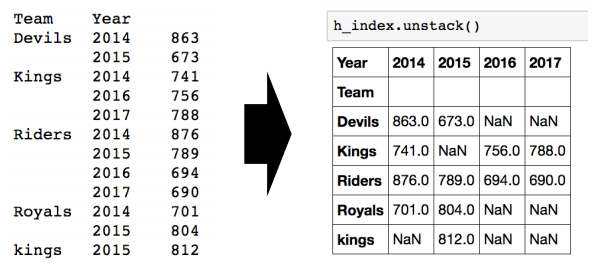
- index의 level도 변경할 수 있다.
- sort_index(level=n)은 n level 기준으로 정렬해준다. (sort_values 도 가능)
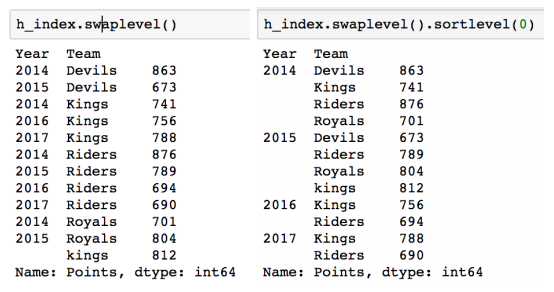
- Groupby에 의해 split된 상태도 추출 가능하다.
grouped = df.groupby("Team")
for name, group in grouped:
print(name) # Key
print(group) # DataFrame
# Aggregation : 요약된 통계정보를 추출
grouped.agg([np.sum, np.mean, np.std]) # group 된 상태에서 column에 함수 적용
df.get_group("Devils") # 특정 Key 값을 가진 그룹의 정보만 추출 가능
df_phone.groupby(["month", "item"]).agg(
{ #이런식으로도 사용 가능하다.
"duration": [min, max, sum],
"network_type: "count",
"date": "first"
})
# Transformation : 해당 정보를 변환
score = lambda x : (x - x.mean()) / x.std() # 정규화
grouped.transform(score) # Key 별로 요약된 정보가 아닌 개별 데이터의 변환
# Filtration : 특정 정보를 제거하여 보여주는 필터링
df.groupby("Team").filter(lambda x: len(x) >= 3) # 특정 조건으로 데이터 검색 📝 Pandas etc.
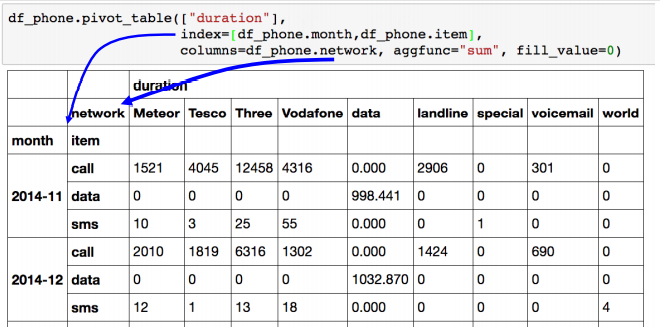
✏️ Pivot Table
- Index 축은 groupby와 동일하다.
- Column에 추가로 labeling 값을 추가하여 aggregation 하는 형태이다.
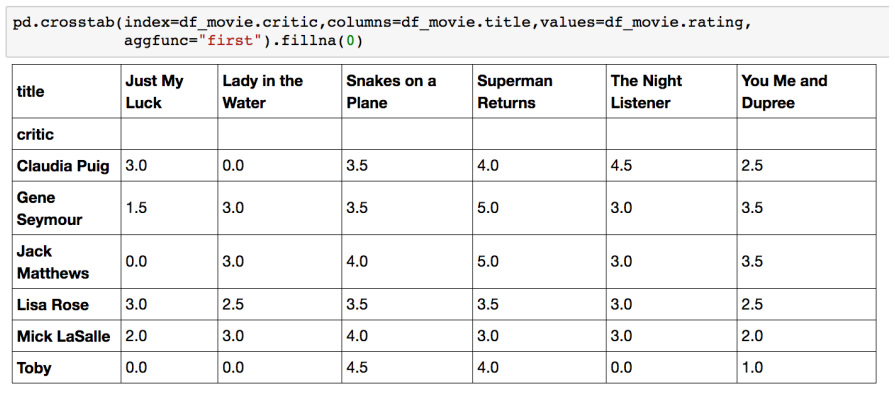
✏️ Crosstab
- 특히 두 column에 교차 빈도, 비율, 덧셈 등을 구할 때 사용한다.
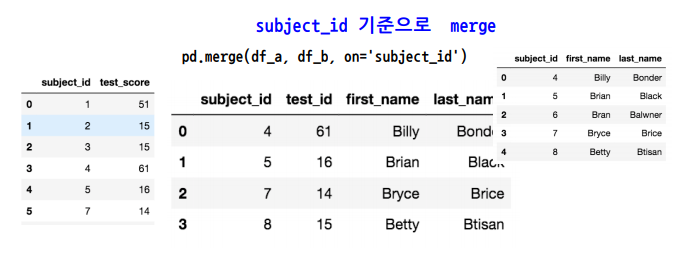
✏️ Merge
- SQL 에서 많이 사용하는 Merge와 같은 기능으로, 두 개의 데이터를 하나로 합친다.
- left_on과 rigth_on을 따로 설정하여 다른 이름을 갖는 Column끼리도 가능하다.
- default는 inner join이며, how = "" 를 통해 left, right, outer 모두 가능하다.
✏️ Concat
- 같은 형태의 데이터를 붙이는 연산 작업
df_new = pd.concat([df_a, df_b]) # 아래로 붙인다. (같은 Column)
df_new = pd.concat([df_a, df_b], axis = 1) # 옆으로 붙인다.✏️ Persistence
- 데이터를 로딩시 DB connection 기능을 제공한다.
import sqlite3
# DB 연결 코드
conn = sqlite3.connect("./data.db")
cur = conn.cursor()
cur.execute("select * from col limit 5;")
results = cur.fetchall()
# DB 연결 conn을 사용하여 dataframe 생성
df_airplines = pd.read_sql_query("select * from airlines;", conn)- XLS 엔진으로 엑셀을 추출할 수 있다.
conda install XlsxWriterwriter = pd.ExcelWriter('./data.xlsx', engine='xlsxwriter')
df_route.to_excel(writer, sheet_name='Sheet1')- 일반적으로 피클을 많이 사용한다.
df.routes.to_pickle("./data.pickle") # 쓰기
df_routes_pickle = pd.read_pickle("./data.pickle") # 읽기📒 확률론 맛보기
📝 딥러닝에서의 확률론
- 딥러닝은 확률론 기반의 기계학습 이론에 바탕을 두고 있다.
- 기계학습에서 사용되는 손실함수(loss function)들의 작동 원리는
데이터 공간을 통계적으로 해석해서 유도한다. - 회귀 분석에서 손실함수로 사용되는 L2-노름은 예측오차의
분산을 가장 최소화하는 방향으로 학습하도록 유도한다. - 분류 문제에서 사용되는 교차엔트로프(cross-entropy)는
모델 예측의 불확실성을 최소화하는 방향으로 학습하도록 유도한다.
✏️ 확률분포
- 확률분포는 데이터의 초상화이다.
- 데이터 공간을 x X y 라 표기하고 D는 데이터 공간에서 데이터를 추출하는 분포이다.
- 데이터는 확률변수로 (x, y) ~ D 라 표기한다.
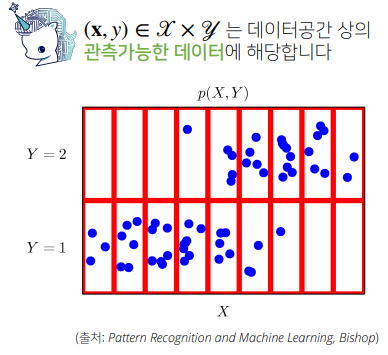
- 확률변수는 확률분포 D에 따라 이산형(discrete)과 연속형(continuous)으로 구분한다.
- 이산형 확률변수는 확률변수가 가질 수 있는 경우의 수를 모두 고려하여 확률을 더해 모델링한다.
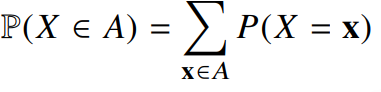
- 연속형 확률변수는 데이터 공간에 정의된 확률변수의 밀도 위에서의 적분을 통해 모델링한다.
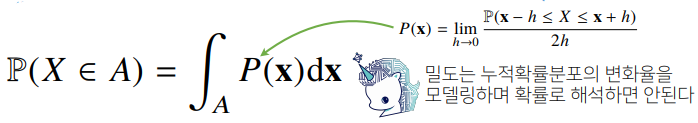
- 결합분포 P(x, y)는 D를 모델링한다. (D는 이론적으로 존재하는 확률분포이므로 사전에 알 수 없다.)

- P(x)는 입력 x에 대한 주변확률분포로 y에 대한 정보를 주지는 않는다.
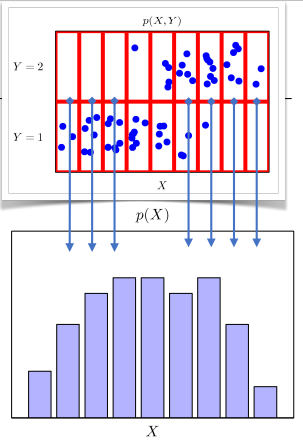
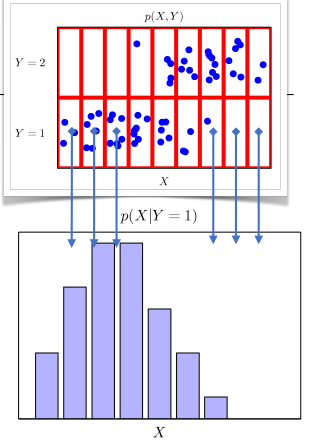
- 조건부확률분포 P(x | y)는 데이터 공간에서 입력 x와 출력 y 사이의 관계를 모델링한다.
👉 특정 클래스가 주어진 조건에서 데이터의 확률분포를 보여준다. (통계적 관계, 예측 모델)
📝 조건부확률과 기계학습
- 조건부확률 P(y | x)는 입력변수 x에 대해 정답이 y일 확률을 의미한다.
- 연속확률분포의 경우는 P(y | x)는 확률이 아닌 밀도로 해석한다.
- 로지스틱 회귀에서 사용했던 선형모델과 소프트맥스 함수의 결합은
데이터에서 추출된 패턴을 기반으로 확률을 해석하는데 사용된다. - 분류 문제에서 softmax(Wϕ + b)은 데이터 x로부터 추출된
특징패턴 ϕ(x)과 가중치행렬 W을 통해 조건부확률 P(y | x)를 계산한다. - 회귀 문제의 경우 조건부 기대값을 추정한다.
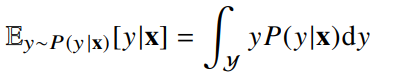
- 딥러닝은 다층신경망을 사용하여 데이터로부터 특징패턴 ϕ를 추출한다.
✏️ 기대값
- 데이터를 대표하는 통계량이다. (평균과 비슷함)
- 확률분포를 통해 다른 통계적 범함수를 계산하는데 사용된다.

- 기대값을 이용해 분산, 첨도, 공분산 등 여러 통계량을 계산할 수 있다.
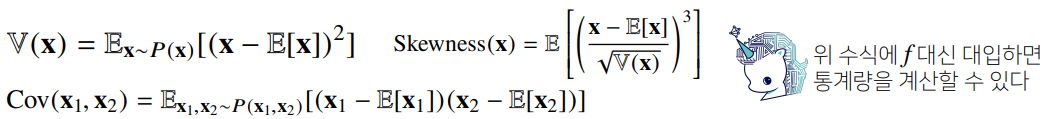
📝 몬테카를로 샘플링
- 기계학습의 많은 문제들은 확률분포를 명시적으로 모를 때가 대부분이다.
- 확률분포를 모를 때 데이터를 이용하여 기대값을 계산할 때 몬테카를로 샘플링을 사용한다.
- 몬테카를로 샘플링 방법은 이산형이든 연속형이든 상관없이 성립한다.
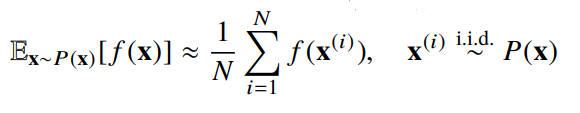
- 독립추출만 보장된다면 대수의 법칙(law of large number)에 의해 수렴성을 보장한다.
- 몬테카를로는 기계학습에서 매우 다양하게 응용되는 방법이다.
✏️ 예제

import numpy as np
def mc_int(fun, low, high, sample_size=100, repeat=10):
int_len = np.abs(high - low)
stat = []
for _ in range(repeat):
x = np.random.uniform(low=low, high=high, size=sample_size)
fun_x = fun(x)
int_val = int_len * np.mean(fun_x)
stat.append(int_val)
return np.mean(stat), np.std(stat)
def f_x(x):
return np.exp(-x**2)
mc_int(f_x, low=-1, high=1, sample_size=10000, repeat=100))📒 [퀴즈] 확률론 맛보기- 1~5
5/5 Solve
📝 Q1
Q) 이산형 확률변수는 확률변수가 가질 수 있는 경우의 수를 모두 고려하여 확률을 더해서 모델링한다.
A) 예
📝 Q2
Q) 연속형 확률변수의 한 지점에서의 밀도 (density) 는 그 자체로 확률값을 가진다.
A) 아니오 (밀도 위에서의 적분으로 모델링)
📝 Q3
Q) 몬테카를로 샘플링 방법은 변수 유형 (이산형, 연속형) 에 상관없이 사용할 수 있다.
A) 예
📝 Q4
Q) 각 면이 나올 확률이 균등하고 독립적인 정육면체 주사위를 던진다고 하자. 확률변수 X는 주사위의 각 면의 숫자를 나타낸다고 할 때 (X ∈ {1, 2, 3, 4, 5, 6} ), X의 기대값을 구하시오 (소수점 첫째자리까지 입력).
A) 3.5
(1 + 2 + 3 + 4 + 5 + 6) * (1 / 6) = 21 / 6 = 3.5📝 Q5
Q) 각 면이 나올 확률이 균등하고 독립적인 정사면체 주사위를 던진다고 하자. 확률변수 X는 주사위의 각 면의 숫자를 나타낸다고 할 때 (X ∈ {1, 3, 5, 7} ), X의 분산을 구하시오 (정수값으로 입력).
A) 5
E(X) = (1 + 3 + 5 + 7) * (1 / 4) = 16 / 4 = 4
V(X) = { (1 - 4)² + (3 - 4)² + (5 - 4)² + (7 - 4)² } * (1 / 4)
= (9 + 1 + 9 + 1) * (1 / 4) = 20 / 4 = 5 
Beginner