📒 Bag-of-Words
텍스트마이닝에서 딥러닝이 적용되기 이전 많이 사용한 기법이다.
수식자체가 간단해서 어려운 내용이 별로 없었다.
교수님께서 설명을 굉장히 잘해주셔서 이해하기가 쉬웠다.
NLP의 큰 종류에 대해서도 다뤄주셨다.
📝 Bag-of-Words
-
Uinque한 Word들을 모아서 Vocabulary를 구축한다.
Example Sentences : "John really really love this movie", "Jane really likes this song"
Vocabulary : {"John", "really", "loves", "this", "movie", "Jane", "likes", "song"} -
각각의 word를 one-hot vector로 만든다.
단어쌍간의 거리는 모두 sqrt(2) 이고, cosine 유사도는 0이다.

-
문장/문서의 one-hot vector의 합을 Bag-of-Words라고 부른다.
Sentence 1 : "John really really loves this movie" = [1 2 1 1 1 0 0 0 0]
Sentence 2 : "Jane really likes this song" = [0 1 0 1 0 1 1 1]
📝 NaiveBayes Classfier
- 문서를 정해진 카테고리 혹은 클래스로 분류하는 기법이다.
- document d를 class c로 구분하는 것에 Bayes` Rule을 사용한다.

✏️ Example



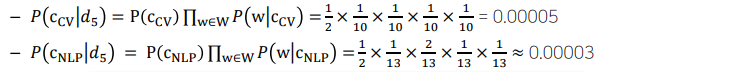
- 한 단어의 Prob이 0이 되면, 다른 단어들이 높은 값을 갖더라도 0을 가질수 밖에 없다.
📒 Word Embedding
어떻게 텍스트를 벡터로 만들 생각을 했을지 신기하다.
데이터가 몹시 커졌을 때 Word2Vec이 어떤 그래프를 그릴지 궁금하다.
이론을 듣고나서 이게 실제로 좋은 결과값을 낸다는 것이 신기했다.
📝 Word Embedding
- 자연어가 단어들의 기본 단위로 Sequence로 볼 때, 단어를 특정 좌표 혹은 vector로 변환해주는 기법이다.
- 한 단어와 다른 단어의 거리를 통해 유사도를 측정할 수 있다.
- 단어들의 관게를 통해 의미 및 긍정, 부정 등을 예측할 수 있다.
📝 Word2Vec
- 같은 문장에서 나온 근접한 단어들은 관련성이 높다는 가정을 사용한다.
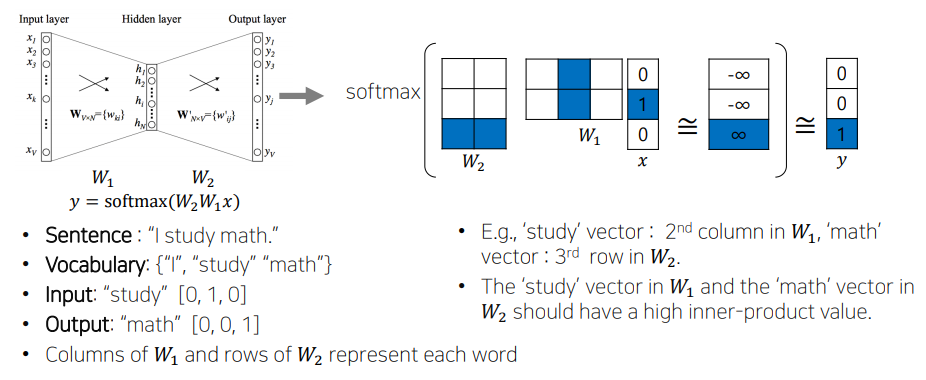
- 비슷한 관계는 비슷한 벡터값을 갖는다.
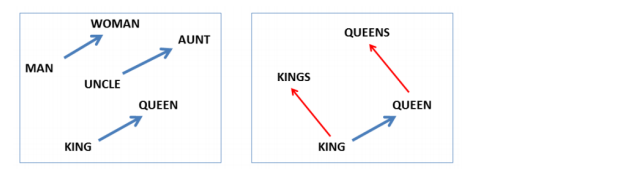
- 이 벡터값을 이용해서 단어를 찾아낼 수 있다.
📝 GloVe
- 입력 및 출력 쌍들에 대해 한 window에서 동시에 나타난 횟수를 이용한다.
- 미리 단어 쌍의 동시 횟수를 계산해서 gradient로 사용함으로써 중복 계산을 방지한다.
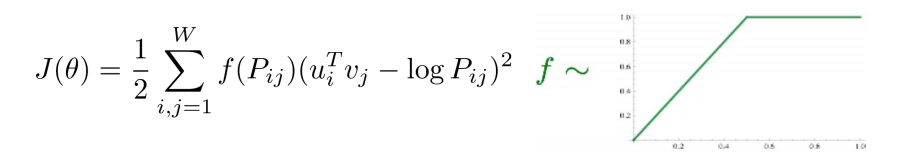

Beginner