📒 그래프 신경망 기본
드디어 그래프로 딥러닝 모델을 만드는 법을 배웠다.
앞서 배운 다른 기술들에 비해 수학적 수식이 적어 이해가 더 잘 됐다.
뭐든지 많이 해보는 것이 정답인 것 같다.
다음주는 특강 주간이니까 다양한 Dacon에 참여해보는 것을 목적으로 해야겠다.
📝 그래프 신경망
그래프 신경망은 그래프와 정점의 속성 정보를 입력으로 받는다.
그래프의 인접 행렬을 A라고 하면, 인접 행렬 A는 | V | X | V |의 이진 행렬이다.
각 정점 u의 속성(Attribute) 벡터를 Xu라고 하면, Xu는 m차원 벡터이고, m은 속성의 수를 의미한다.
그래프 신경망은 이웃 정점들의 정보를 집계하는 과정을 반복하여 임베딩을 얻는다.
대상 정점의 임베딩을 얻기 위해 이웃들 그리고 이웃의 이웃들의 정보를 집계한다.
각 집계 단계를 층(Layer)이라고 부르고, 각 층마다 임베딩을 얻는다.
0번 층, 즉 입력 층의 임베딩으로는 정점의 속성 벡터를 사용한다.
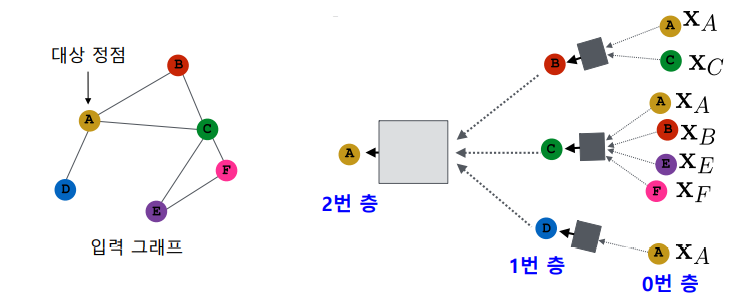
이 때, 대상 정점 마다 집계되는 정보가 상이하다.
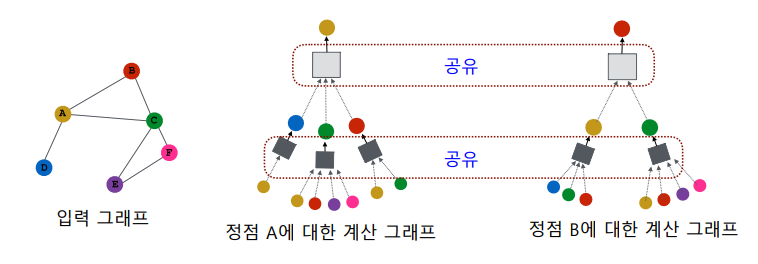
대상 정점 별 집계되는 구조를 계산 그래프(Computation Graph)라고 부른다.
하지만 서로 다른 대상 정점간에도 층 별 집계 함수는 공유한다.
집계 함수는 이웃들 정보의 평균을 계산하고 신경망에 적용하는 단계를 거친다.
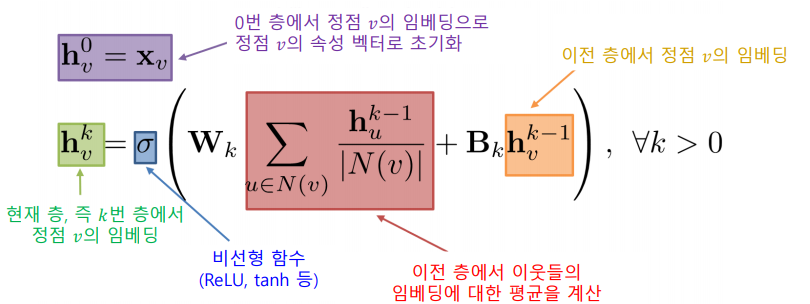
이 때, 마지막 층에서의 임베딩이 곧 출력 임베딩이다.
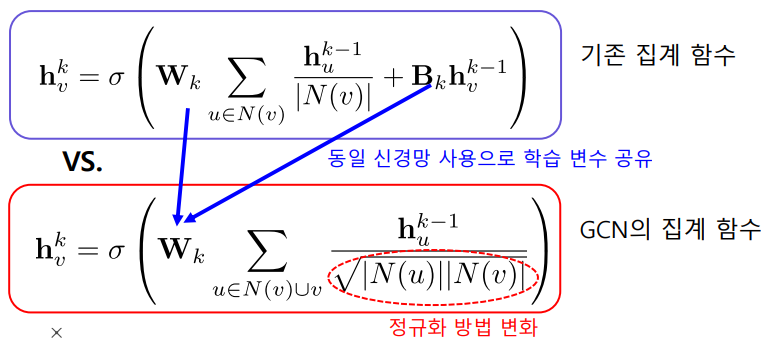
학습변수 Wk, Bk는 층 별 신경망의 가중치를 의미한다.
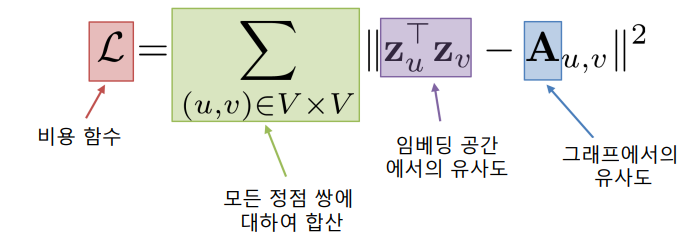
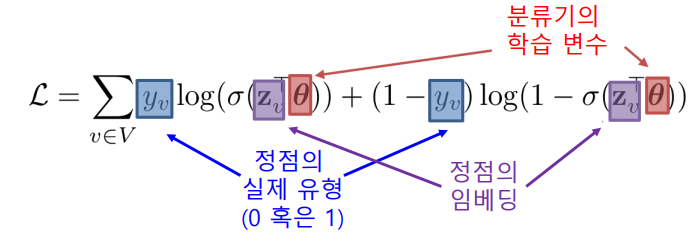
손실함수는 정점간 거리를 보존하는 것을 목표로 할 수 있다.
만약, 인접성을 기반으로 유사도를 정의한다면, 손실 함수는 다음과 같다.
정점 분류가 목표라면 그래프 신경망을 이용하여 정점의 임베딩을 얻고, 이를 분류기(Classfier)의 입력으로 사용하여 각 정점의 유형을 분류할 수 있다. 이 경우 Cross Entropy를 사용하여 End-to-End 학습도 가능하다.
📝 그래프 신경망 변형
다양한 형태의 집계 함수를 사용할 수 있다.
✏️ 그래프 합성곱 신경망
그래프 합성곱 신경망(Graph Convolutional Network, GCN)의 집계함수이다.
✏️ GraphSAGE
GraphSAGE는 이웃의 임베딩을 AGG 함수를 이용해 합친 후, 자신의 임베딩과 연결한다.

AGG 함수는 평균, 풀링, LSTM 등이 사용될 수 있다.
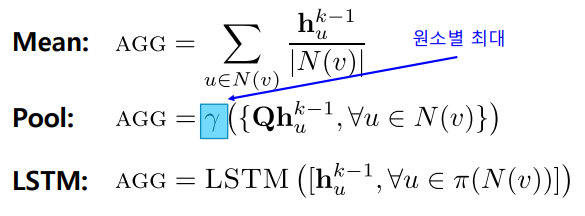
📒 그래프 신경망 심화
그래프 신경망의 마지막 수업이다.
제일 흥미있게 들었던 수업이라 아쉽다.
더 공부를 하고 싶은데 어떻게 공부를 할 지 잘 모르겠다.
📝 어텐션
기본 그래프 신경망에서는 이웃들의 정보를 동일한 가중치로 평균을 낸다.
그래프 합성곱 신경망에서 역시 단순히 연결성을 고려한 가중치로 평균을 낸다.
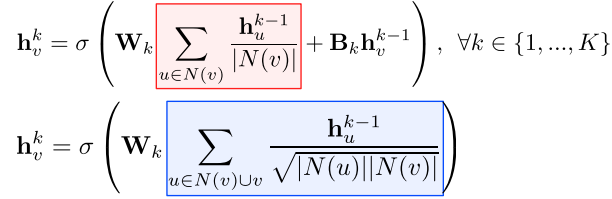
그래프 어텐션 신경망(Graph Attention Network, GAT)에서는 가중치 자체도 학습한다.
실제 그래프에서는 이웃 별로 미치는 영향이 다를 수 있기 때문이다.
가중치를 학습하기 위해서 셀프-어텐션(Self-Attention)이 사용된다.

각 가중치는 다음과 같은 순서로 계산된다.

여러 개의 어텐션을 동시에 학습한 뒤, 결과를 연결하여 사용한다.
이를 멀티헤드 어텐션(Multi-head Attention)이라고 부른다.
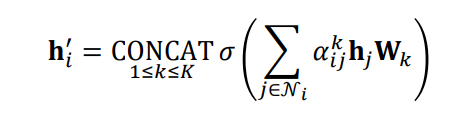
📝 그래프 표현 학습, 풀링
그래프 표현 학습, 혹은 그래프 임베딩이란 그래프 전체를 벡터의 형태로 표현하는 것이다.
개별 정점을 벡터의 형태로 표현하는 정점 표현 학습과 구분된다.
그래프 임베딩은 벡터의 형태로 표현된 그래프 자체를 의미하기도 한다.
이는 그래프 분류 등에 활용된다.
그래프 풀링(Graph Polling)이란 정점 임베딩들로부터 그래프 임베딩을 얻는 과정이다.
그래프의 구조를 고려한 방법을 사용할 경우 그래프 분류에서 더 높은 성능을 얻는다.
아래 미분가능한 풀링(Differentiable Pooling, DiffPool)은 군집 구조를 활용하여 임베딩을 계층적으로 집계한다.
📝 지나친 획일화 문제
지나친 획일화(Over-smoothing) 문제란 그래프 신경망의 층의 수가 증가하면서 정점의 임베딩이 서로 유사해지는 현상을 의미한다. 이는 작은 세상 효과와 관련이 있다.

따라서 그래프 신경망의 층의 수를 늘렸을 때, 정확도가 감소하는 현상이 있다.
그래프의 신경망의 층이 2개 혹은 3개일 때 정확도가 가장 높다.
잔차항(Residual)을 넣는 것, 즉 이전 층의 임베딩을 한 번 더 더해주는 것으로는 효과가 제한적이다.
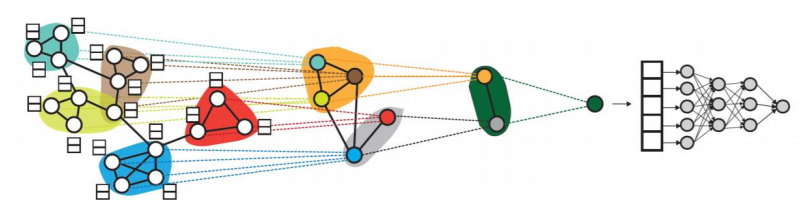
이러한 문제의 대응으로 JK 네트워크(Jumping Knowledge Network)는 마지막 층의 임베딩 뿐 아니라, 모든 층의 임베딩을 함께 사용한다.
APPNK는 0번째 층을 제외하고는 신경망 없이 집계 함수를 단순화하였다.
📝 그래프 데이터의 증강
데이터 증강(Data Augmentation)은 다양한 기계학습 문제에서 효과적이다.
그래프에서 누락되거나 부정확한 간선이 있을 수 있고, 데이터 증강을 통해 보완할 수 있다.
임의 보행을 통해 정점간 유사도를 계산하고, 유사도가 높은 정점 간의 간선을 추가하는 방법이 있다.

그래프 데이터 증강의 결과로 정점 분류의 정확도가 개선될 수 있다.
