📒 정점 표현
슬슬 강의가 딥러닝과 가까워지고 있는 것 같다.
빌드업이 워낙 뛰어나셔서 이해가 어려운 부분은 딱히 없었다.
실습 코드만 잘 익혀서 구현력만 키우면 될 것 같다.
📝 정점 표현 학습
그래프의 정점들을 벡터의 형태로 표현하는 것이다. 이는 간단히 정점 임베딩(Node Embedding)이라고도 부른다. 벡터 형태의 표현 그 자체를 의미하기도 한다. 정점이 표현되는 벡터 공간을 임베딩 공간이라고 부른다.
정점 표현 학습의 입력은 그래프이다. 주어진 그래프의 각 정점 u에 대한 임베딩, 즉 벡터 표현 zu가 정점 임베딩의 출력이다.
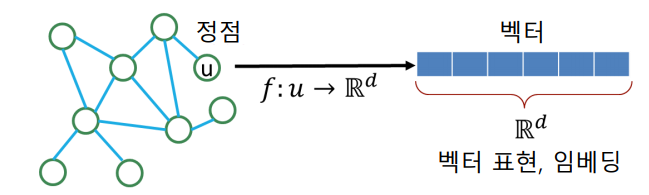
정점 임베딩의 결과로, 벡터 형태의 데이터를 위한 도구들을 그래프에도 적용할 수 있다. 기계학습 도구들이 한가지 예시이다. 대부분의 분류기(로지스틱 회귀분석, 다층 퍼셉트론 등)와 군집 분석 알고리즘(K-Means, DBSCAN 등)은 벡터 형태로 표현된 instance들을 입력으로 받는다.
그래프의 정점들을 벡터 형태로 표현할 수 있다면, 최신의 기계학습 도구들을 정점 분류, 군집 분석 등에 활용할 수 있다. 변환은 그래프에서의 정점간 유사도를 임베딩 공간에서도 보존하는 것을 목표로 한다.
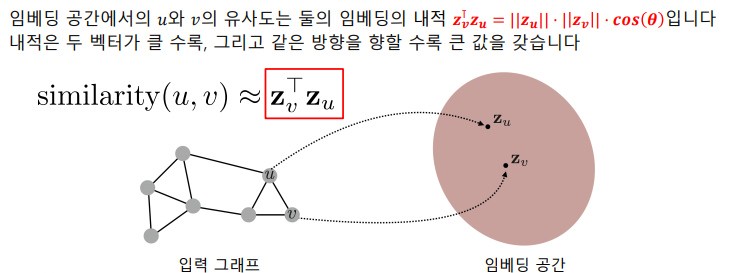
임베딩 공간에서의 유사도로는 내적(Inner Product)를 사용한다.
정리하면, 정점 임베딩은 두 단계로 이루어진다.
- 그래프에서의 정점 유사도를 정의하는 단계
- 정의한 유사도를 보존하도록 정점 임베딩을 학습하는 단계
📝 인접성 기반 접근법
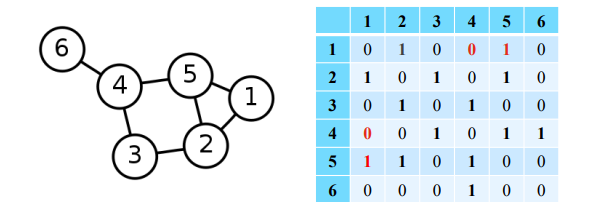
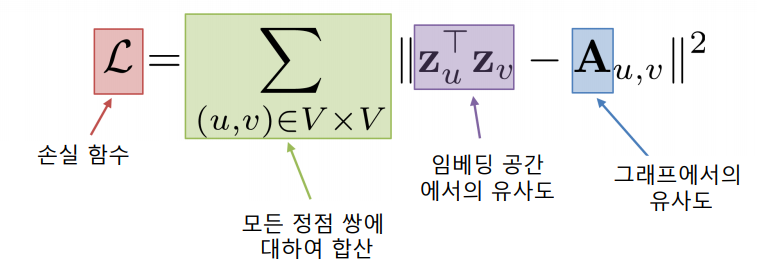
인접성(Adjacency) 기반 접근법에서는 두 정점이 인접할 때 유사하다고 간주한다. 두 정점 u와 v가 인접하다는 것은 둘을 직접 연결하는 간선 (u, v)가 있음을 의미한다. 인접행렬 A의 u행 v열 원소 A(u,v)는 u와 v가 인접한 겨우 1, 아닌 경우 0이다. 인접행렬의 원소 A(u, v)를 두 정점 u와 v의 유사도로 가정한다.
손실 함수(Loss Function)은 아래와 같다. 이 손실 함수가 최소가 되는 정점 임베딩을 찾는 것을 목표로 한다. 이를 최소화 하기 위해 (확률적) 경사하강법 등이 사용된다.
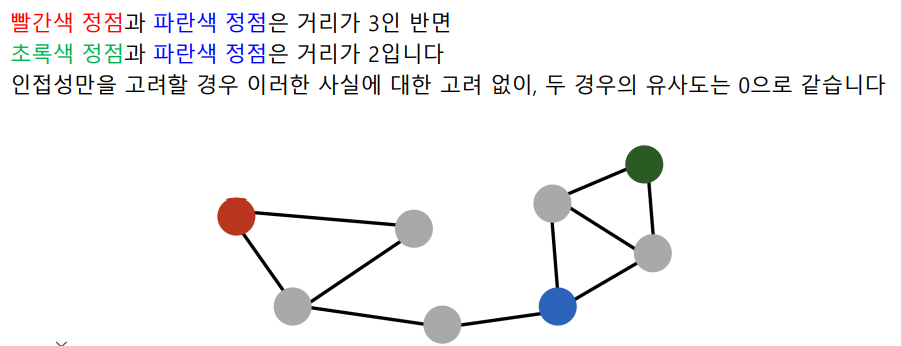
하지만 인접성만으로 유사도를 판단하는 것은 한계가 있다.
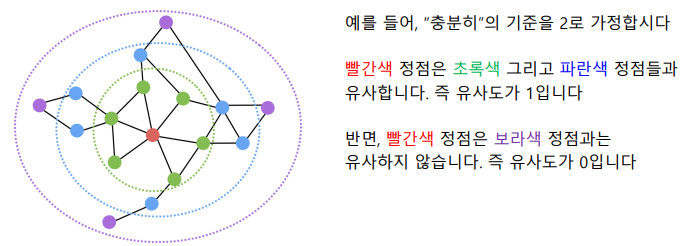
📝 거리/경로/중첩 기반 접근법
거리 기반 접근법에서는 두 정점 사이의 거리가 충분히 가까운 경우 유사하다고 간주한다.
경로 기반 접근법에서는 두 정점 사이의 경로가 많을 수록 유사하다고 간주한다.

중첩 기반 접근법에서는 두 정점이 많은 이웃을 공유할 수록 유사하다고 간주한다.

공통 이웃 수 대신 자카드 유사도 혹은 Adamic Adar 점수를 사용할 수도 있다.
- 자카드 유사도(Jaccard Similarity)는 공통 이웃의 비율을 계산하는 방식이다.
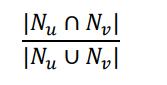
- Adamic Adar 점수는 공통 이웃 각각에 가중치를 부여하여 가중합을 계산하는 방식이다.
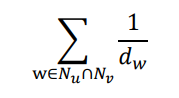
📝 임의보행 기반 접근법
임의보행 기반 접근법에서는 한 정점에 시작하여 임의보행을 할 때 다른 정점에 도달할 확률을 유사도로 간주한다. 임의보행을 사용할 경우 시작 정점 주변의 지역적 정보와 그래프 전역 정보를 모두 고려할 수 있다는 장점을 갖는다. 이는 세 단계를 거친다.
- 각 정점에서 시작하여 임의보행을 반복 수행한다.
- 각 정점에서 시작한 임의보행 중 도달한 정점들의 리스트를 구성한다.
이 때, 정점 u에서 시작한 임의보행 중 도달한 정점들의 리스트를 Nr(u)라고 한다.
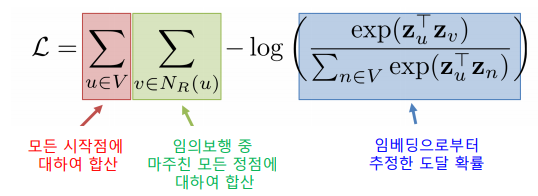
한 정점을 여러 번 도달한 경우, 해당 정점은 Nr(u)에 여러번 포함될 수 있다. - 다음 손실할수를 최소화하는 임베딩을 학습한다.
정점 u에서 시작한 임의보행이 정점 v에 도달할 확률 P(v | zu)을 다음과 같이 추정한다.
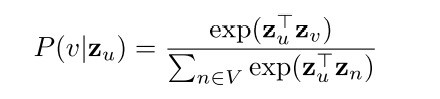
즉, 두 정점의 내적값인 유사도가 높을수록 확률이 크다.
✏️ Node2Vec
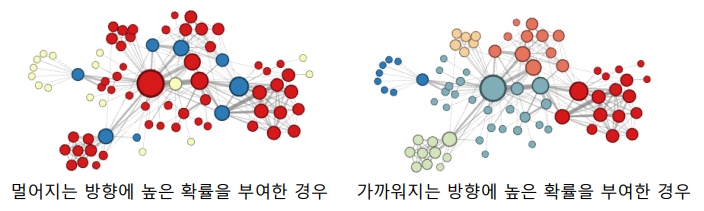
정점의 이웃을 균일한 확률로 선택하는 DeepWalk와는 달리 Node2Vec은 2차 치우친 임의보행(Second-order Biased Random Walk)을 사용한다. 현재 정점과 직전에 머물렀던 정점을 모두 고려하여 다음 정점을 선택한다. 직전 정점의 거리를 기준으로 경우를 구분하여 차등적인 확률을 부여한다.
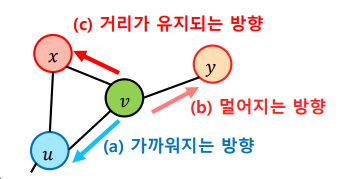
부여하는 확률에 따라서 다른 종류의 임베딩을 얻는다.
멀어지는 방향에 높은 확률을 부여한 경우, 정점의 역할이 같은 경우 임베딩이 유사하다.
가까워지는 방향에 높은 확률을 부여한 경우, 같은 군집에 속한 경우 임베딩이 유사하다.
임의보행 기법의 손실함수는 중첩합 때문에 계산에 정점의 수의 제곱에 비례하는 시간이 소요된다.
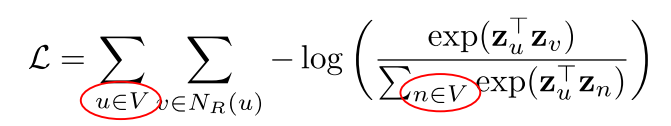
따라서 많은 경우 근사식을 사용한다. 모든 정점에 대해서 정규화하는 대신 몇개의 정점을 뽑아서 비교하는 형태이다. 이 때 뽑힌 정점들을 Negative Sample이라고 한다. 연결성에 비례하는 확률로 이를 뽑으며, Negative Sample이 많을수록 학습이 더욱 안정적이다.
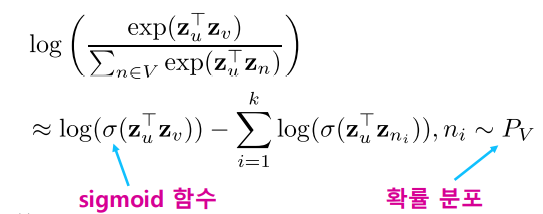
📝 변환식의 한계
변환식(Transdctive) 방법은 학습의 결과로 정점의 임베딩 자체를 얻는다는 특성이 있다. 정점을 임베딩으로 변화시키는 함수, 즉 인코더를 얻는 귀납식(Inductive) 방법과 대조된다.
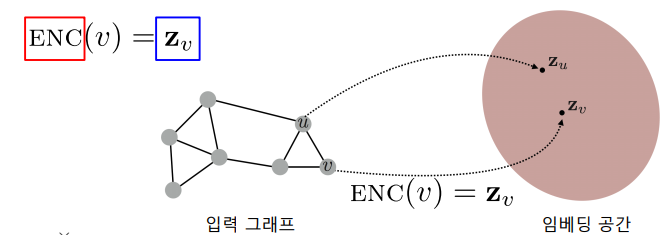
변환식 임베딩 방법은 여러 한계를 갖는다.
- 학습이 진행된 이후에 추가된 정점에 대해서는 임베딩을 얻을 수 없다.
- 모든 정점에 대한 임베딩을 미리 계산하여 저장해두어야 한다.
- 정점이 속성(Attribute) 정보를 가진 경우에 이를 활용할 수 없다.
📒 추천 시스템
어제 배운 추천 시스템이 실제 그래프에서 어떻게 적용될 수 있는가에 대해 배웠다.
넷플릭스 챌린지도 언급해주셨는데, 얼른 나도 저런 챌린지에 참여해보고 싶다.
Dacon을 하나하나 해보면서 실력을 길러야겠다.
📝 잠재 인수 모형
잠새 인수 모형(Latent Factor Model)의 핵심은 사용자와 상품을 벡터로 표현하는 것이다.
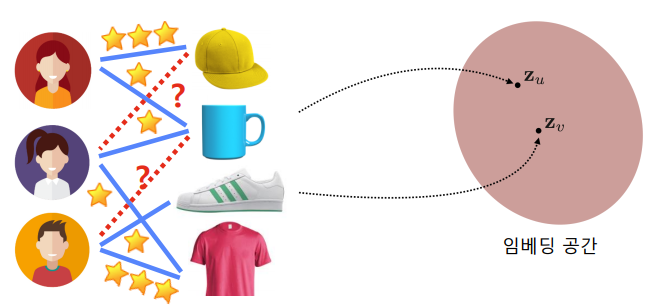
아래는 사용자와 영화를 임베딩한 예시이다.
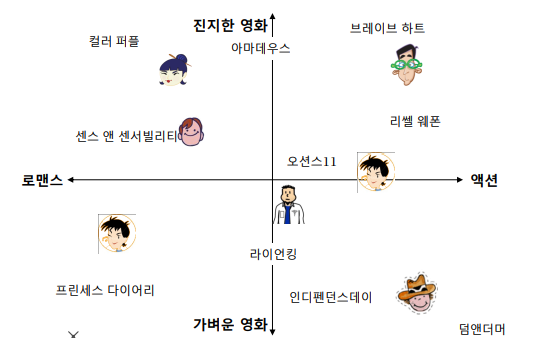
잠재 인수 모형에서는 고정된 인수 되신 효과적인 인수를 학습하는 것을 목표로 한다.
👉 학습한 인수를 잠재 인수(Latent Factoor)라고 부른다.
사용자와 상품을 임베딩하는 기준은 다음과 같다.

행렬 차원에서는 다음 그림과 같다.
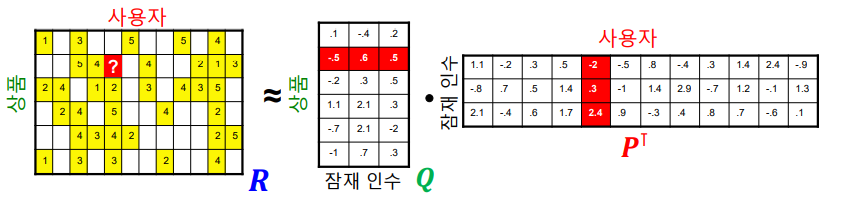
잠재 인수 모형은 다음 손실함수를 최소화하는 P와 Q를 찾는 것을 목표로 한다. Overfitting을 방지하기 위해서 정규화 항을 손실 함수에 더해준다.

이를 찾기 위해 보통 확률적 경사 하강법을 사용한다.
📝 고급 잠재 인수 모형
✏️ 사용자와 상품의 편향을 고려
각 사용자의 편향은 해당 사용자의 평점 평균과 전체 평점 평균의 차이이다.
각 상품의 편향은 해당 상품에 대한 평점 평균과 전체 평점 평균의 차이이다.
개선된 잠재 인수 모형에서는 평점을 분리한다.
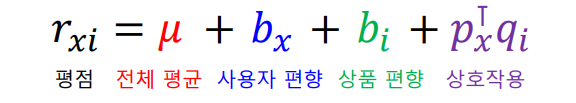
손실 함수는 다음과 같다.
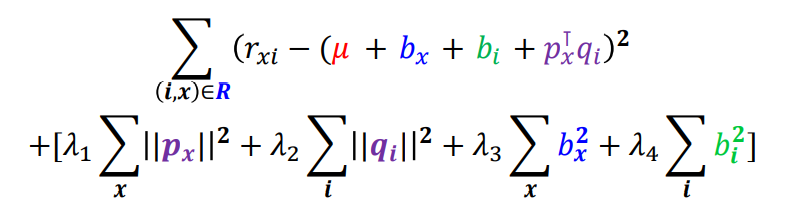
✏️ 시간의 편향을 고려
평점이 시간에 따라 변화하는 경우도 많다.
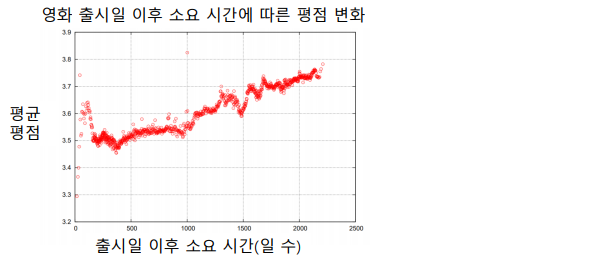
이를 개선하기 위해 사용자 편향과 상품 편향을 시간에 따른 함수로 가정한다.

