Lesson Learned
- General한 모델은 오히려 domain-specific한 task에 대한 정확도가 낮을 수 있다.
- domain-specific한 task에 대한 정확도를 높이기 위해서는 작은 크기의 모델을 사용하는 것이 더 나을 수 있다.
Detail
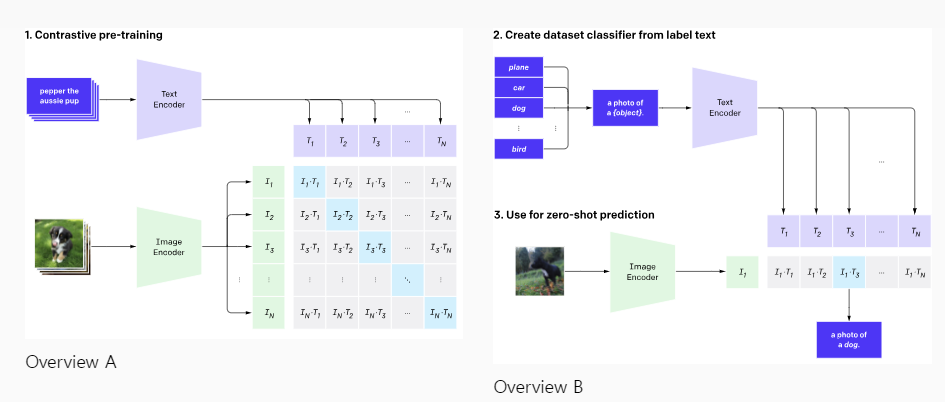
다들 'CLIP'' 모델이라고 들어보셨나요?
CLIP은 Text와 Image간의 관계성을 모델링한 연구입니다.
그렇기 때문에 Text와 Image의 유사도를 구하는 것이 가능합니다.
출처: https://openai.com/index/clip/
이번에 제가 진행하고 있는 프로젝트에서는
model_path = "openai/clip-vit-base-patch32"
를 사용해서 의류 이미지와 텍스트 사이의 유사도를 구했습니다.
예를 들어
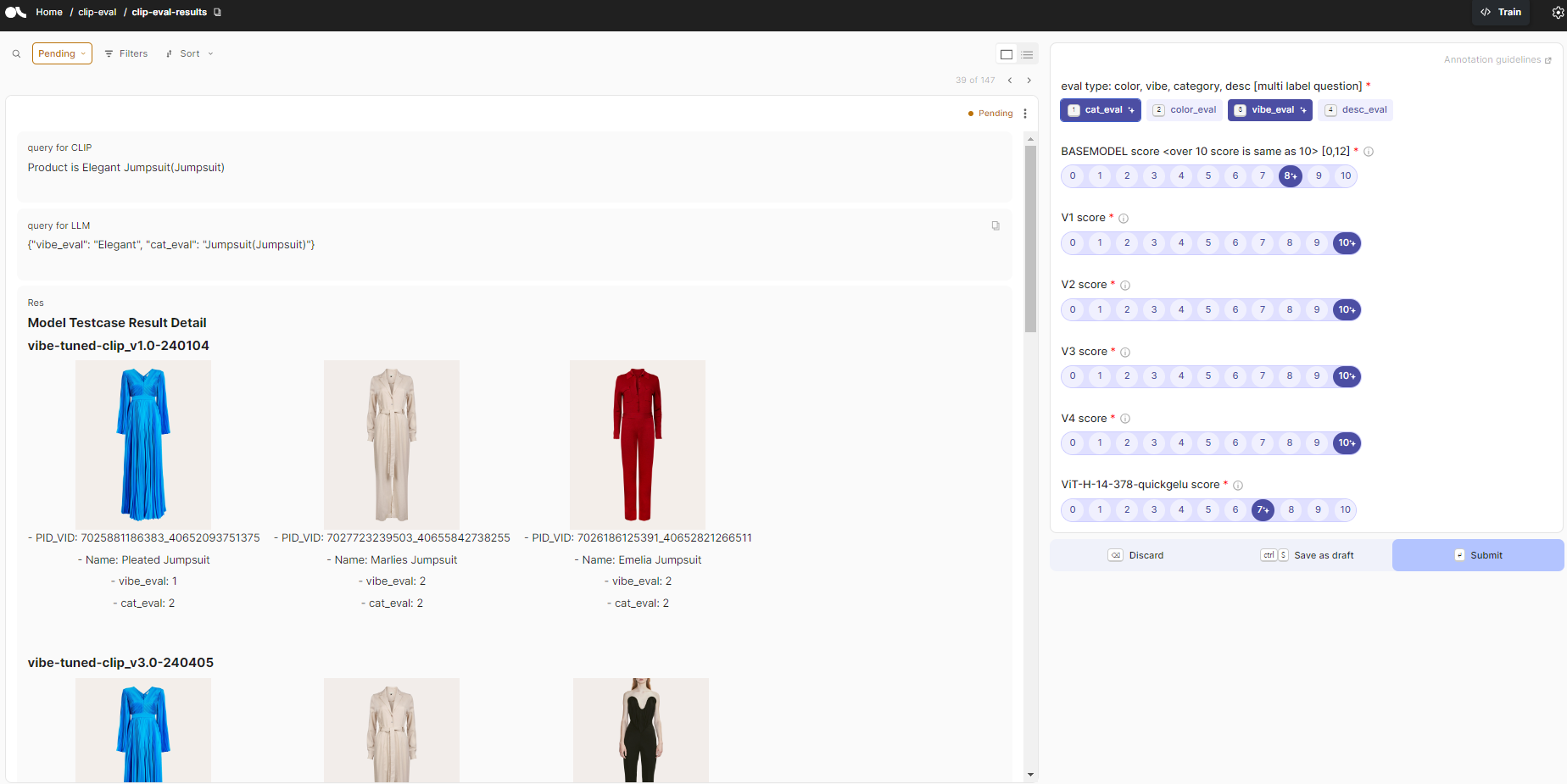
Product is Elegant Jumpsuit(Jumpsuit)라고 검색하면,
Clip을 통해 제품 의류 이미지와 유사도를 구해
상위 매칭되는 제품을 사용자에게 보여주는 방식입니다.
해당 프로젝트에서는 Clip의 성능이 프로젝트 퀼리티에
큰 영향을 미치기에 아주 중요한 요소입니다.
하지만 아무래도 CLIP은 General 목적으로 학습된 모델이다보니
패션 쿼리를 중점으로 하는 해당 프로젝트에서는 낮은 정확도를 보였습니다.
그래서 Finetuning을 진행했고 아래 사진이 evaluation한 결과입니다.
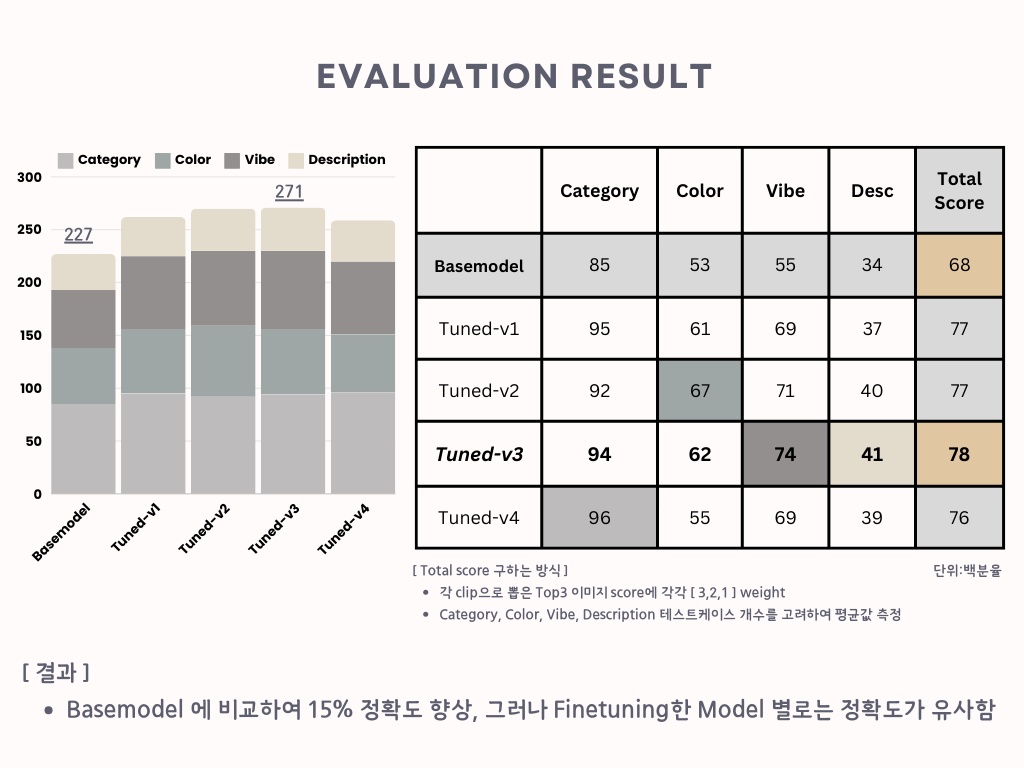
이미지를 보시면 패션 쿼리에 대해서
Tuned-v3 버전 모델이 Basemodel의 정확도보다
15% 향상된 것을 볼 수 있습니다.
하지만 Tuning을 아무리 계속해도 Tuned-v3보다
더 성능이 안좋아지는 모습을 보였습니다.
그래서 모델을 Finetuning하는 것을 잠시 멈추고,
좀 더 큰 데이터셋인 Laion으로 학습하여
General Case에 대한 정확도가 더 높은 새로운 CLIP 모델을
Test해보기로 결정했습니다.
새로운 CLIP 모델들은 아래 링크에서 확인할 수 있습니다.
https://laion.ai/projects/
https://github.com/mlfoundations/open_clip
아래 코드를 입력해보면
import open_clip
model_infos = open_clip.list_pretrained()
for i, model_info in enumerate(model_infos):
clip_model, trainset = model_info
print(f"Model {i + 1}: {clip_model} trained on {trainset}")openclip에서 제공하는 121개의 CLIP을 확인할 수 있습니다.
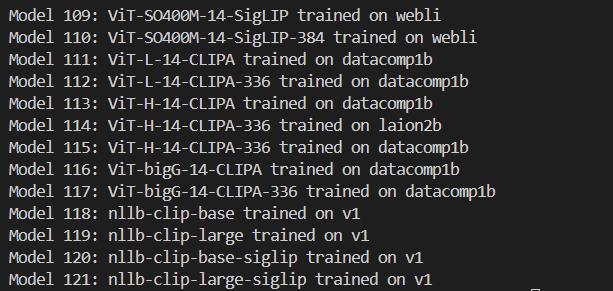
이 중 저는 새로 released된 CLIP 중에 가장 zero-shot 정확도가 높다는 ViT-H-14-378-quickgelu을 먼저 Test해보고자 합니다.
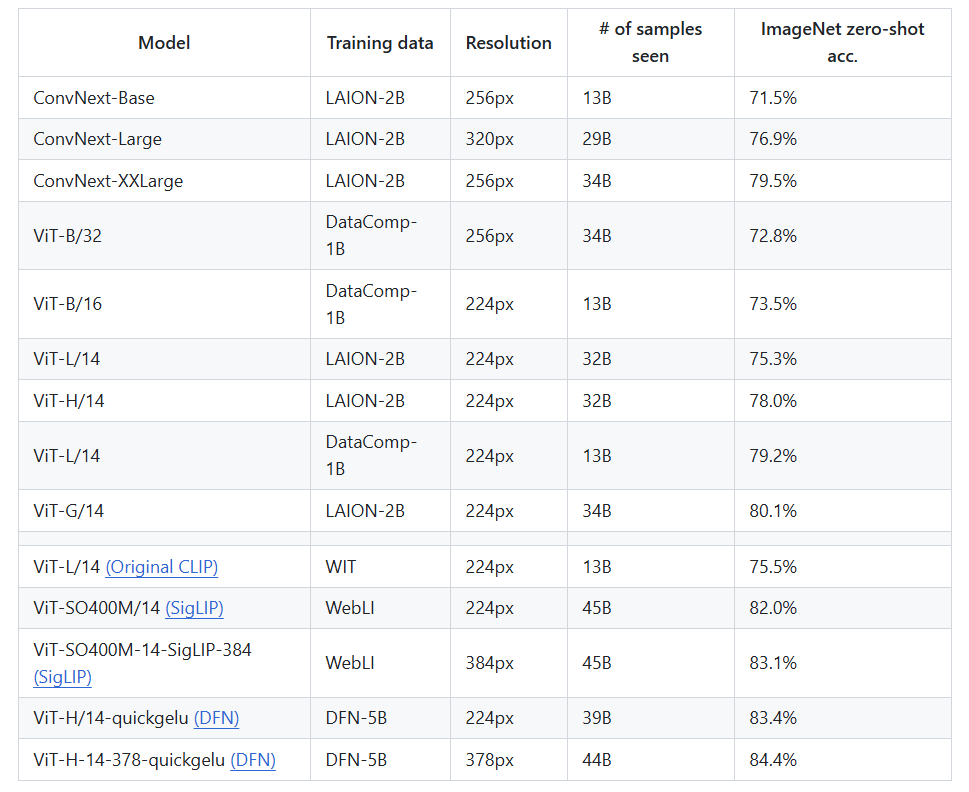
기존에 사용했던 VIT-B/32와 ViT-H-14-378-quickgelu 는
zero-shot 정확도가11.6% 가 차이나기 때문에
더 나은 결과가 나올 것이라 기대했습니다.
아래 코드는 ViT-H-14-378-quickgelu 테스트 코드입니다.
def test_open_clip():
import torch
from PIL import Image
target_model_info = {
"name": "ViT-H-14-378-quickgelu",
"trainset": "dfn5b",
}
model, _, preprocess = open_clip.create_model_and_transforms(
target_model_info["name"], pretrained=target_model_info["trainset"]
)
model.eval() # model in train mode by default, impacts some models with BatchNorm or stochastic depth active
tokenizer = open_clip.get_tokenizer(target_model_info["name"])
image = preprocess(Image.open("data/CLIP.png")).unsqueeze(0)
text = tokenizer(["a diagram", "a dog", "a cat"])
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", text_probs) # prints: [[1., 0., 0.]]
print("Label probs:", text_probs.argmax(dim=-1)) # prints: [0]
print("Image vector size: ", image_features.size())
print("Text vector size: ", text_features.size())
test_open_clip()기존에 사용하던 Clip 모델은 512차원 벡터를 반환해주었는데
해당 모델은 1024차원 벡터를 반환한다는 점이 약간 마음에 걸렸지만 정확도 테스트를 계속 진행했습니다.
기존 Evaluation 방식과 동일하게
ViT-H-14-378-quickgelu 의 정확도를 측정해봤는데
되게 낮게 측정되는걸 확인했습니다.
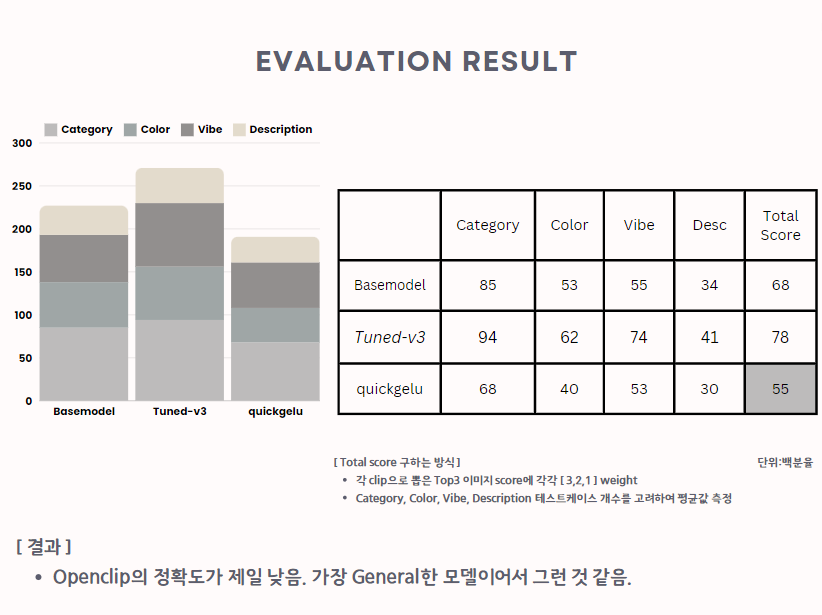
제 예상으로는 너무 general한 모델이어서
오히려 fashion 이미지 분류에 대해서는
더 낮은 정확도를 나타내는 것 같습니다.
패션 도메인에서 CLIP 정확도 향상을 위한
Breakthourgh가 되어 줄 것이라고 예상했는데
예상에서 벗어나서 좀 아쉽습니다.
어떻게 하면
텍스트를 통한 패션 이미지 검색 정확도를 더 높일 수 있을지
다른 방법을 더 고민해봐야할 것 같습니다.
