Fully Convolutional Networks(FCN)의 주요 특징과 기존 CNN 기반 분류 모델과의 차이점은 무엇인가요?
Fully Convolutional Networks(FCN)
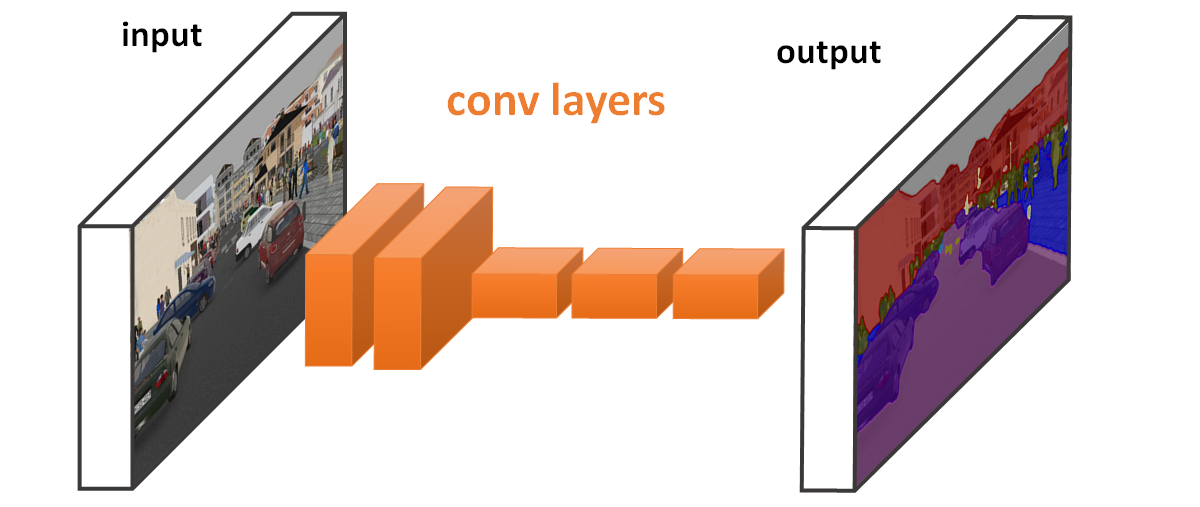
FCN은 이미지 분할(Segmentation)을 하는 딥러닝 모델이다. 기존의 CNN 기반 분류(Classification) 모델과 달리, Convolutional Layer만 사용하여 입력 이미지의 공간적 정보를 유지하고, 픽셀 단위로 클래스를 예측하는 것이 특징이다.
FCN의 주요 특징
1) 완전한 컨볼루션 구조

기존 CNN 분류 모델에서는 마지막에 사용되는 Fully Connected Layer (FC Layer)로 고정된 크기의 클래스 확률을 출력한다.
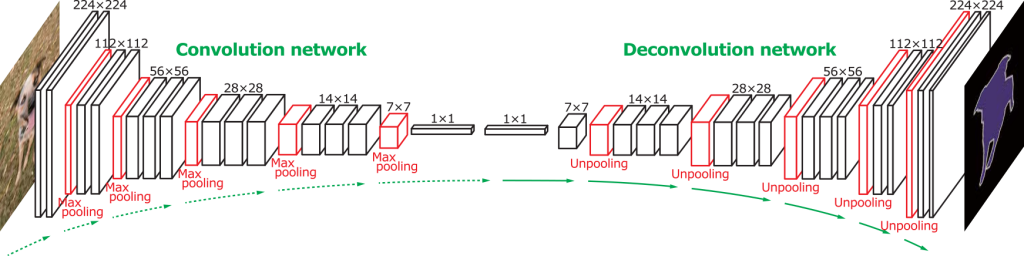
반면, FCN은 Fully Connected Layer를 제거한다. 그리고 기존 CNN처럼 하나의 클래스 확률값을 예측하는 것이 아니라, 각 픽셀이 어떤 클래스에 속하는지를 예측하는 출력 맵(Feature Map)을 생성한다.
2) 업샘플링(Upsampling) 사용
CNN 모델은 컨볼루션과 풀링(Pooling) 연산을 반복하면서 이미지를 점점 작게 압축하여 중요한 특징만 추출하는 다운샘플링(Downsampling)을 수행한다.
그러나 이렇게 이미지 크기가 줄어들면, 개별 픽셀이 어떤 객체에 속하는지 예측하지 못하는 문제가 발생한다.
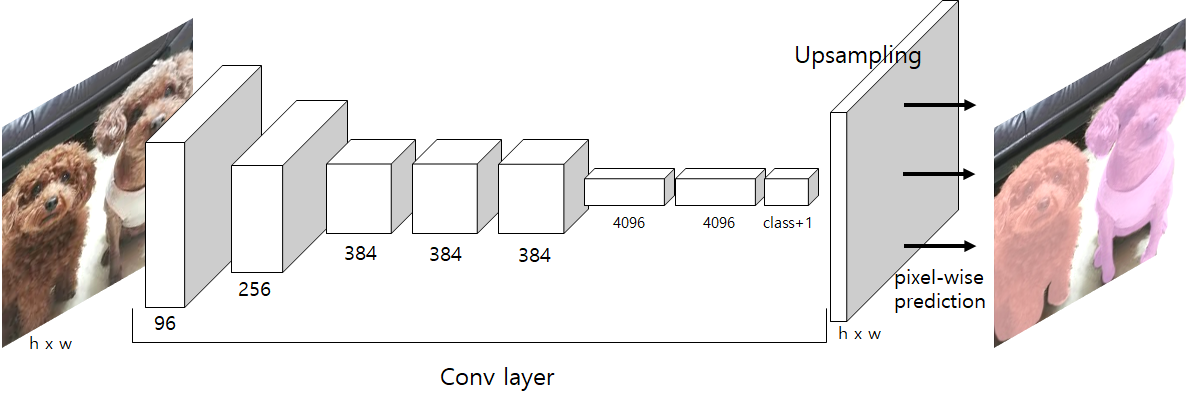
따라서 FCN에서는 축소된 특징 맵을 다시 원본 크기로 복원하는 업샘플링(Upsampling)을 사용한다. 이를 통해 입력 이미지의 모든 픽셀에 대한 예측 결과를 생성할 수 있다.
| 비교 | CNN | FCN |
|---|---|---|
| 출력 형태 | 하나의 클래스 라벨 | 입력 이미지와 동일한 크기의 픽셀별 클래스 예측 결과 |
| Fully Connected Layer | O | X (오직 Convolution + Upsampling) |
| 입력 크기 제약 | 고정된 크기 | 가변적인 크기 입력 가능 |
| 공간 정보 유지 | Fully Connected Layer로 인해 손실 | 컨볼루션 기반 구조로 공간 정보 유지 |

개발 공부ᕦ(ò_óˇ)ᕤ