Non-sequential vs. Sequential
두 특성의 차이는 시간 정보를 포함하는 데이터인지 아닌지에 따라 나뉜다.
Non-Sequential Data
우선 Non-sequential 데이터는 데이터 표현에서 시간 정보를 포함하지 않는다. 또한 관측치 수(Sample)와 변수의 수(Feature)의 곱으로 표현되며 각 Sample에 따라 Y값(예측치)를 갖는다. 예를 들어 Sample(X)를 고객, Feature를 해당 고객이 이용 중인 금융 상품이라고 하고, Y를 어떤 대출 상품을 이용 중인지 여부를 예측하는 값이라고 하자. 그러면 Y값은 X에 대한 Feature에 대해서 각각 예측된다.
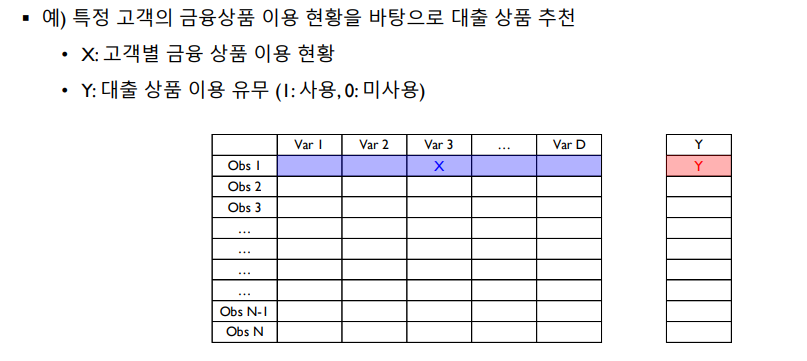
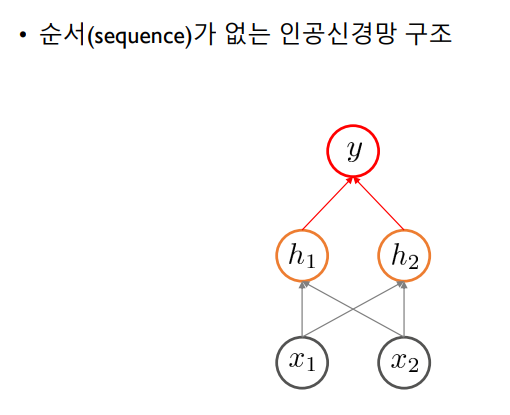
시간 정보를 포함하지 않으므로 Non-sequential data는 순서를 가지지 않는다.따라서 Non-sequential Data를 인공신경망 구조에서 사용하면, hidden node에서 Output까지의 정보 전달이 직접적으로 이루어지게 된다.
Sequential Data
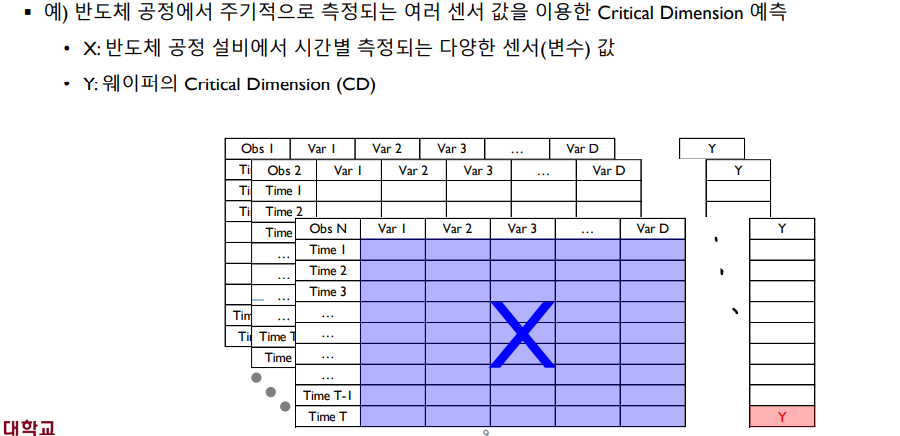
Sequential Data는 순차적으로 생성되는 데이터로 시간 정보를 갖고 있다. 따라서 Object(Sample)에 대한 시간(Time, 측정 시점 수)과 변수의 수(Feature)의 곱으로 표현된다. 그러므로 Sequential Data는 3차원 Tensor로 표현된다. 또한 Y값은 Non-sequential Data와 마찬가지로 한 Object에 따라 하나의 값을 갖는다. 예를 들면 반도체 공정에서 주기적으로 동시에 측정되는 센서의 값을 통해 Critical Dimension(에러를 일으키는 측정 시점)를 찾을 때 Sequential Data가 사용될 것이다.
순서가 있는 데이터를 다루는 인공신경망 구조는 hidden node의 입력 변수가 설명 변수 X만이 아니라 이전 상태 T에 대한 정보도 포함하고 있다. 이를 순환신경망 구조라고 부르며, 시계열 데이터를 분석하기 위해서 이러한 신경망 구조가 쓰인다.
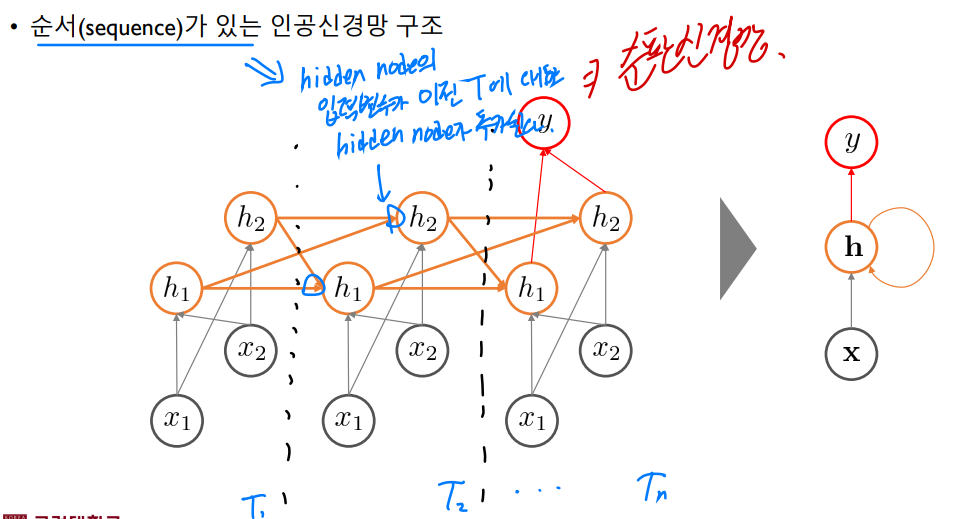
위와 같은 구조의 대표적인 모델이자 순차 데이터를 처리하는 데에 특화된 인공신경망 모델이 RNN이다. 각 hidden state마다 같은 Weight paramter가 사용되므로 원하는 데이터 크기(혹은 길이)만큼 받아서 원하는 데이터만큼 Output을 만들 수 있다.
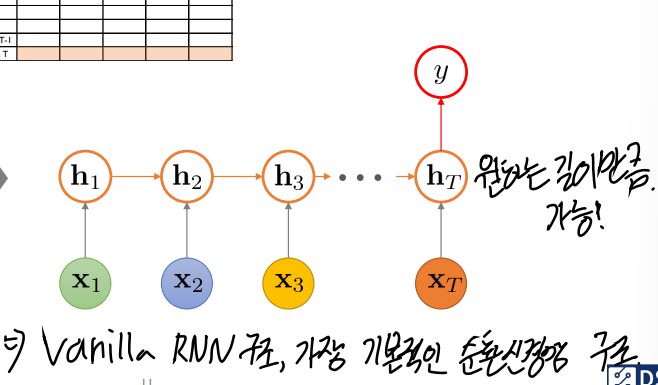
순환신경망(RNN) 시계열 회귀
RNN과 LSTM,GRU
RNN은 위 그림과 같이 벡터로 표현된 입력에 대해서 Weight parameter(W hh, W xh, W hy)이 곱해지고 활성 함수(activation function)을 적용하면서 Output을 만들어낸다. 그리고 예측한 Output을 통해 정답값과 Loss를 계산하고, 이 Loss function의 값을 최소화하기 위해 Gradient의 값을 줄여나가면서 각 Weight parameter를 조정한다(Backpropagation). 이것이 대략적인 흐름이다.
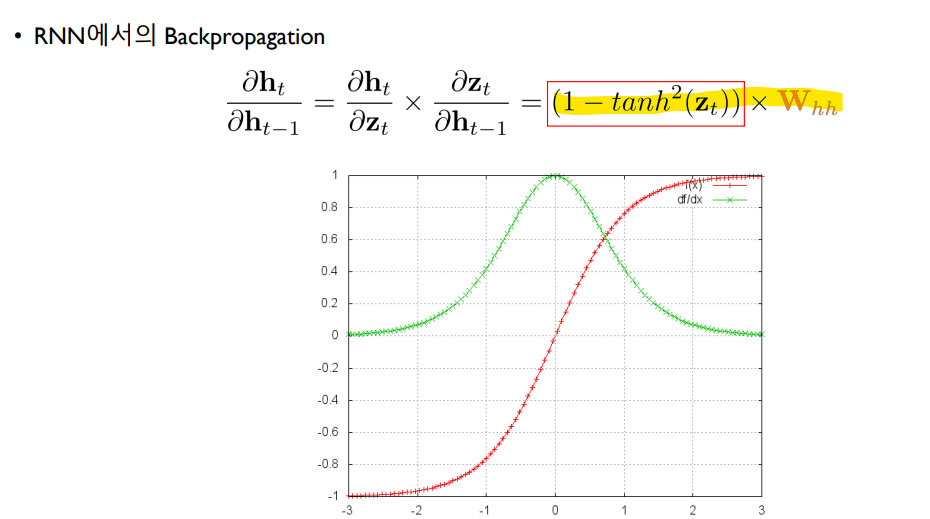
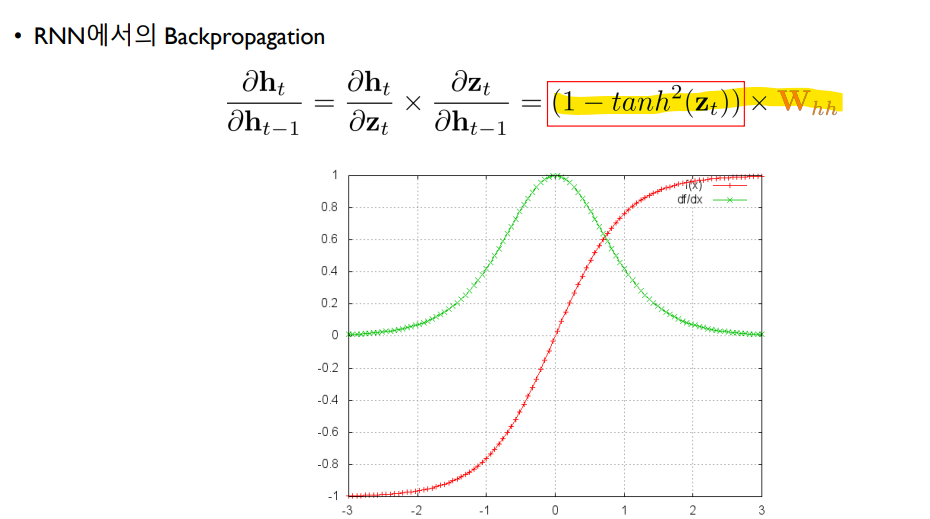
하지만 이 RNN에서의 Backpropagation은 치명적인 문제점이 있는데, Tanh나 Sigmoid와 같은 activation function을 쓰다보면 1보다 작은 값을 Chain rule을 통해 계속 곱하다보니 파라미터를 조정하는 Gradient 정보가 점점 작아지는 문제가 생겨 parameter의 값들의 업데이트가 안된다는 점이 있다.
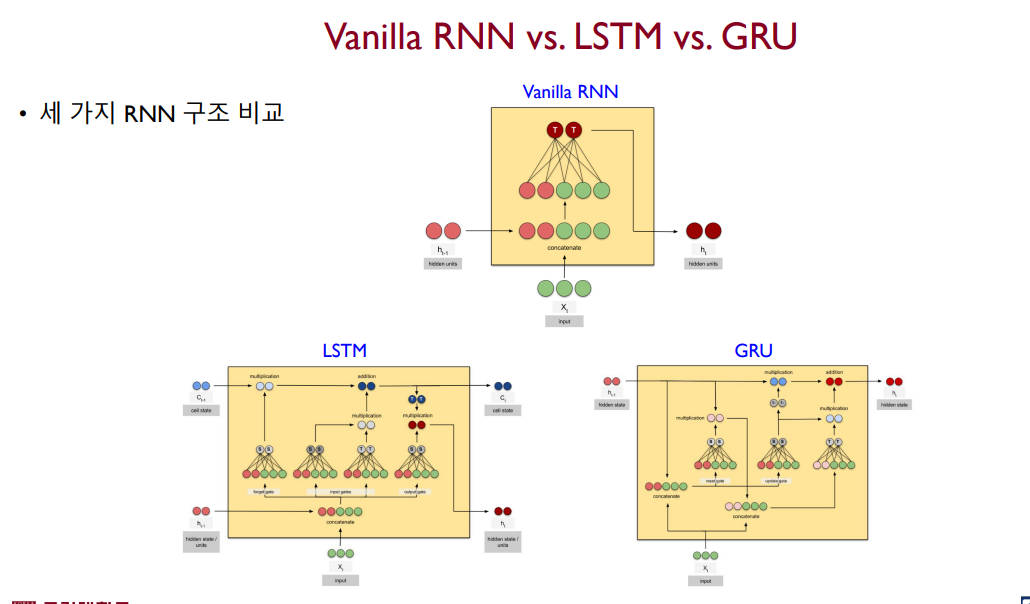
따라서 순환신경망에서는 LSTM, GRU라고 하는 계량된 구조의 모델이 있다. LSTM은 activation function의 영향을 적게 받는 cell state라고 하는 정보를 hidden state와 함께 가져 긴 시퀀스 입력에 대한 Short-term memory 특성을 줄여준다. (완전히 없애진 못함) 하지만 Gate라고 하는 학습 시켜야 할 trainable parameter가 3개 존재하기 때문에 학습이 어렵다는 단점이 있다.
GRU는 LSTM보다 조금 더 단순한 구조로 별도의 cell state가 존재하지 않는다. 또한 LSTM에 비해 적은 Gate 수를 가짐에도 불과하고 LSTM과 성능 차이가 크게 나타나진 않다고 한다.
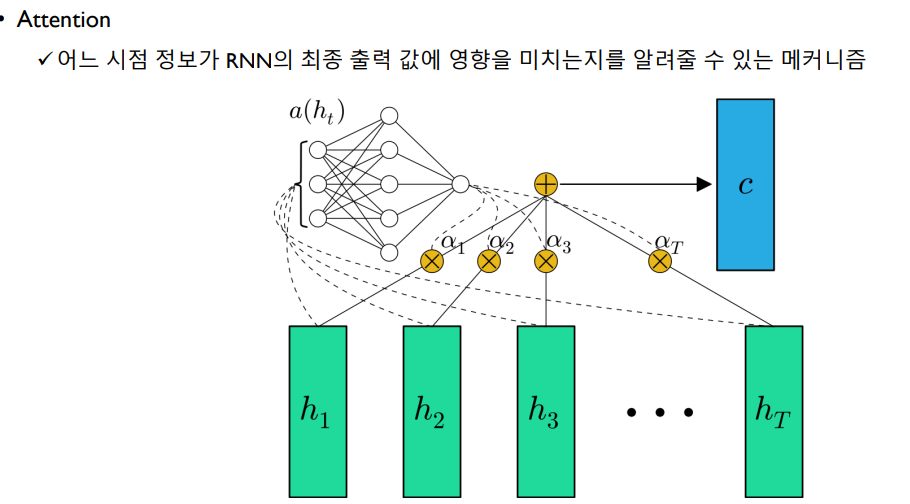
Attention Mechanism
이전까지 RNN 모델은 맨 마지막 hidden node만을 통해 output을 만들어냈다. 하지만 Attention 기반의 RNN은 마지막 뿐만 아니라 다른 모든 hidden node에 대한 정보와 각 hidden node에 대한 attention score(=> context vector)를 통해 output을 만들어낸다.
attention 매커니즘에는 대표적으로 두 가지가 있는데, Bahanau attention과 Luong attention이 있다. 주로 별도의 attention score의 학습이 필요없는 Luong 방식이 쓰인다.
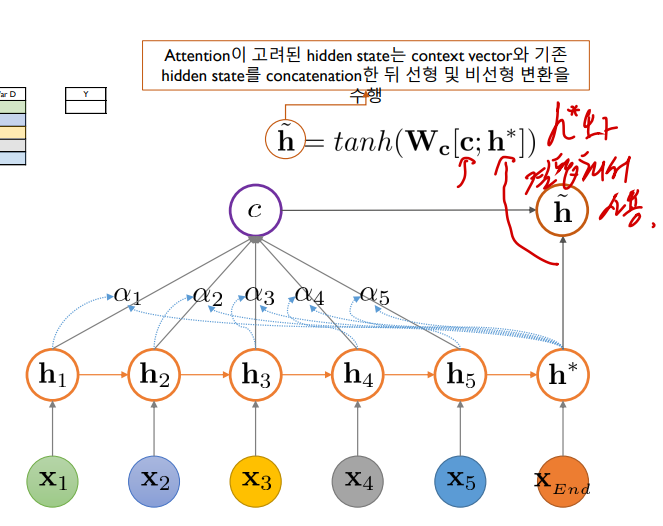
최종 예측에서는 h 틸다라는 값이 사용되며, 이 값은 마지막을 제외한 hidden node들의 정보를 attention score를 통해 담은 context vector와 마지막 hidden node의 contatenation 이후 비선형변환을 한 값이다. 이 h 틸다는 최종적으로 소프트맥스 함수에 대입되어 최종 결과를 예측할 것이다.
배운 점
-
LSTM과 GRU는 어느정도 성능이 비슷하니 웬만하면 GRU를 쓰는 것이 좋다. (더 적은 파라미터 개수)
-
Attention mechanism은 추가한 구조와 그렇지 않는 구조보다 예측 성능의 차이가 크므로 RNN 구조를 쓸 때는 반드시 attention mechanusm을 쓰는 것이 좋다.
해당 포스트는 LG Aimers 활동 중 고려대학교 강필성 교수님의 강의자료를 기반으로 작성된 글입니다. 학습 정리용으로 작성하였으며, 잘못되었거나 수정해야 할 내용이 있을 수 있습니다. 해당 내용이 있다면 이메일이나 댓글로 알려주세요. 감사합니다.
