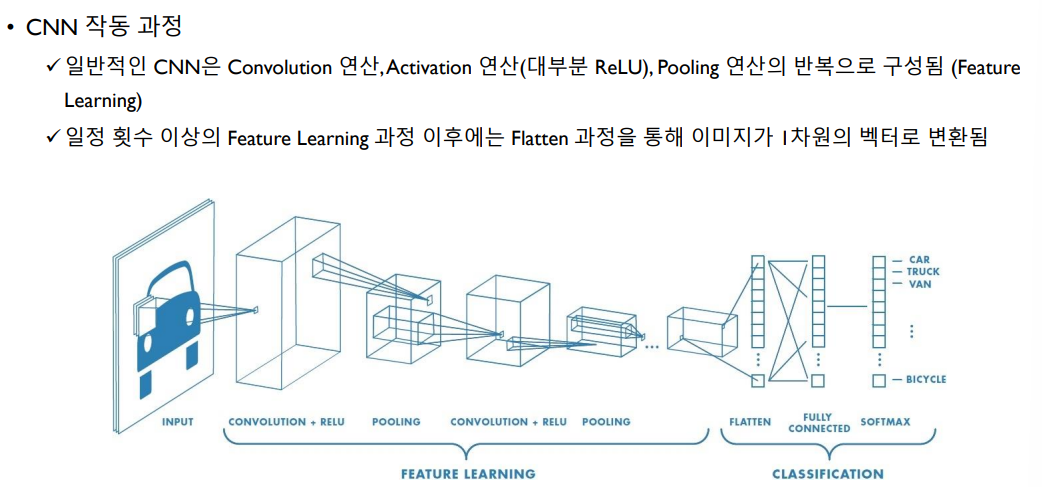
Convolutional Neural Network
CNN은 주로 이미지로부터 필요한 feature를 스스로 학습 시킬수 있도록하는 신경망 구조이다. 이미지의 모든 픽셀을 서로 다른 weight parameter로 연결하면 너무 많은 파라미터의 개수가 너무 많아진다. 따라서 nXn matrix의 filter(kernel)와 이미지 데이터가 갖는 특징인 Spatially-locality(인접한 픽셀끼리는 같은 색을 가진 확률이 높은 특징)을 이용하여 이미지의 feature를 학습한다.
CNN 시계열 회귀
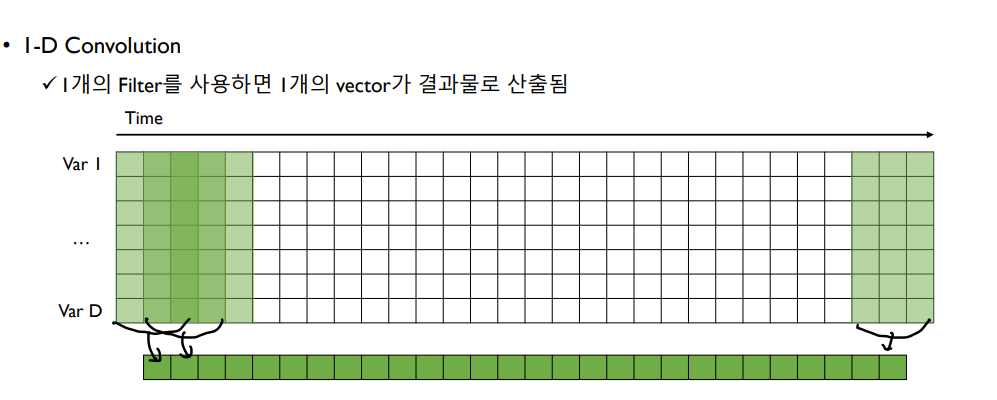
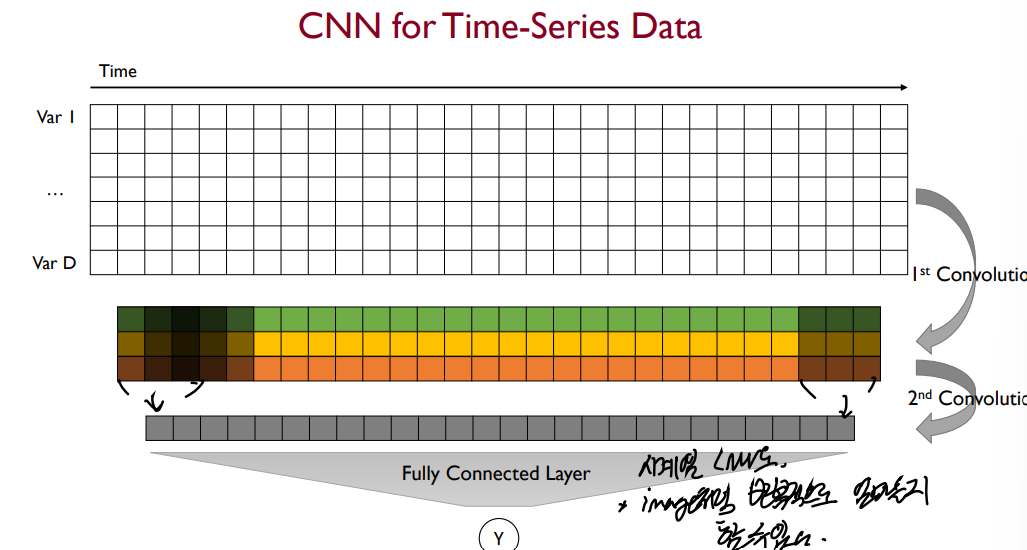
CNN 모델에 시간 정보가 있는 시계열 데이터를 사용하기 위해서는 이미지 데이터와의 차이점을 알아야 한다. 시계열 데이터는 이미지 데이터와는 다르게 변수들 사이의 공간 연관성(Spatial Correlation)이 존재하지 않는다. 따라서 기존 CNN에서의 filter는 두 축을 기준으로 Convolution을 진행했지만(2-D Convolution) 시계열 데이터를 가진 CNN은 시간 축 단 하나만을 기준으로 Convolutin을 진행한다. 따라서 기본적으로 filter의 세로 길이가 전체 변수의 개수로 쓰인다.

Dilated Convolution
위 방법(Standard Convoluton)은 인접한 시점의 데이터들에 대해서만 Convolution을 진행한다. 이 방법에서 좀 더 효율적인 처리를 위해 Convolution하는 시점의 데이터를 띄엄띄엄 떨어진 시점과도 진행하는 방식을 Dilated Convoltion이라고 하며, 긴 길이에 시계열 데이터를 한번에 처리하기 위해서 빠르고 효과적인 방법이다.
Transformer
Transformer 모델은 자연어 처리를 위한 언어 모델로 Attention을 병렬적으로 사용하는 구조를 갖는다.
개괄적으로는 인코더 파트와 디코더 파트를 가지며, 각각 6개의 인코더, 디코더 블럭이 존재한다.
Transformer 모델에 입력값은 임베딩 벡터이다. 각 단어의 의미론적 관계(semactic relationship)를 유지하도록 하는 벡터값으로 단어를 표현하는 것을 임베딩 벡터라고 하는데, 모든 단어가 정해진 차원의 임베딩 벡터(512차원 등, Hyperparameter)로 구성된다.
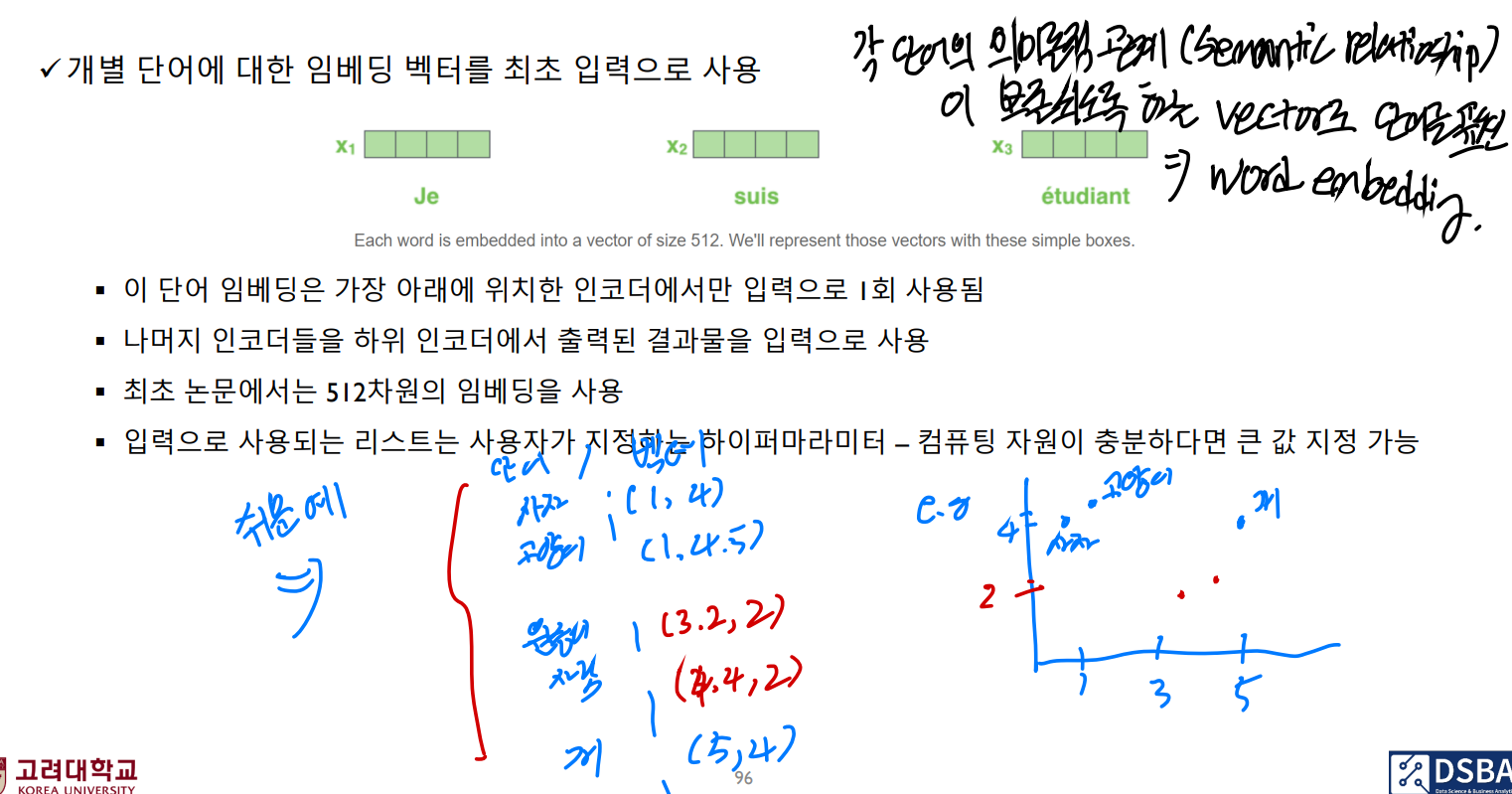
또한 Transformer는 RNN의 구조와는 달리 단어를 순차적으로 받지 않고 한번에 받는 구조이기 때문에 입력 시퀀스에서 단어들의 위치 관계를 표현해줄 필요가 있다. 따라서 단어 벡터들의 위치 정보를 나타내는 과정인 포지션 인코딩이 필요하다.
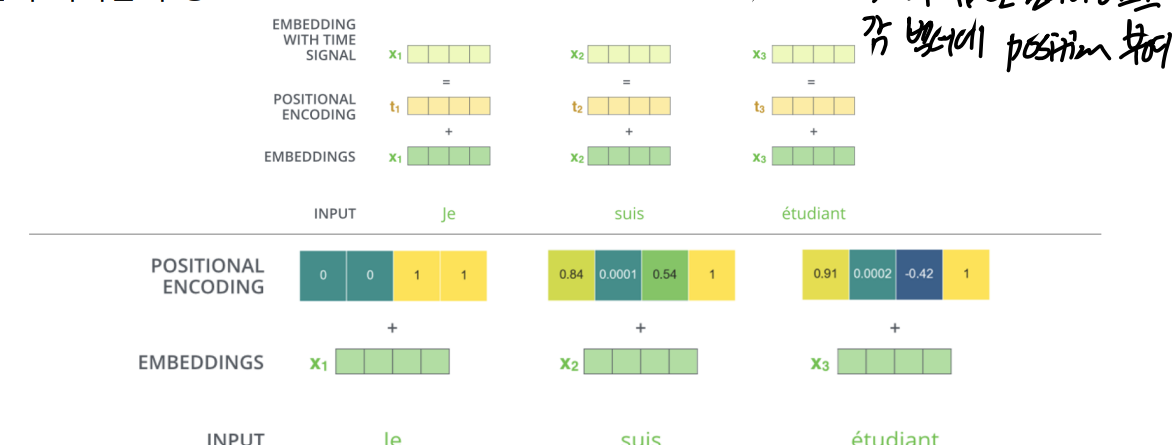
이후 인코딩 과정은 셀프 어텐션과 Feed-forward Neural Network(FFNN), 멀티헤드 어텐션 등의 과정을 거친다
주요하게 볼만한 건 두 단계에서 단어의 위치에 따라 의존성 문제가 다르다는 것이다. 셀프 어텐션 과정에서는 단어의 위치에 의존성이 존재하지만, FFNN 과정에서는 의존성이 존재하지 않아 병렬화가 가능하다.
해당 포스트는 트랜스포머 모델을 활용한 시계열 데이터 분석이 주 목적이므로 트랜스포머 모델 구조에 대한 부분은 추후 다른 포스팅에서 자세한 내용을 다루려고 합니다.
Transformer 시계열 회귀 (TST)
Time-Series Transformer는 트랜스포머 모델을 다변량 시계열 데이터에 최초로 적용한 논문이다. 모델의 인코더 구조만 사용하였으며, Fine-tuning 시에 구조 설계에 따라 Classification, Regression, Missing value imputation 등 다양한 Task에 적용할 수 있다.
TST의 작동을 크게 두 가지 Phase로 구분할 수 있는데, input 값에 대해 masking으로 학습하는 과정(Pre-training)과 문제 해결을 위한 Fine-tuning과정이다.
Pre-training
Pre-training 과정에는 입력 데이터의 일부를 0으로 바꾸는 Masking 작업 뒤에 Transformer의 입력 차원으로 변환한다. 하지만 fine-tuning 과정에서는 마스킹 없이 그냥 변환이 진행된다.
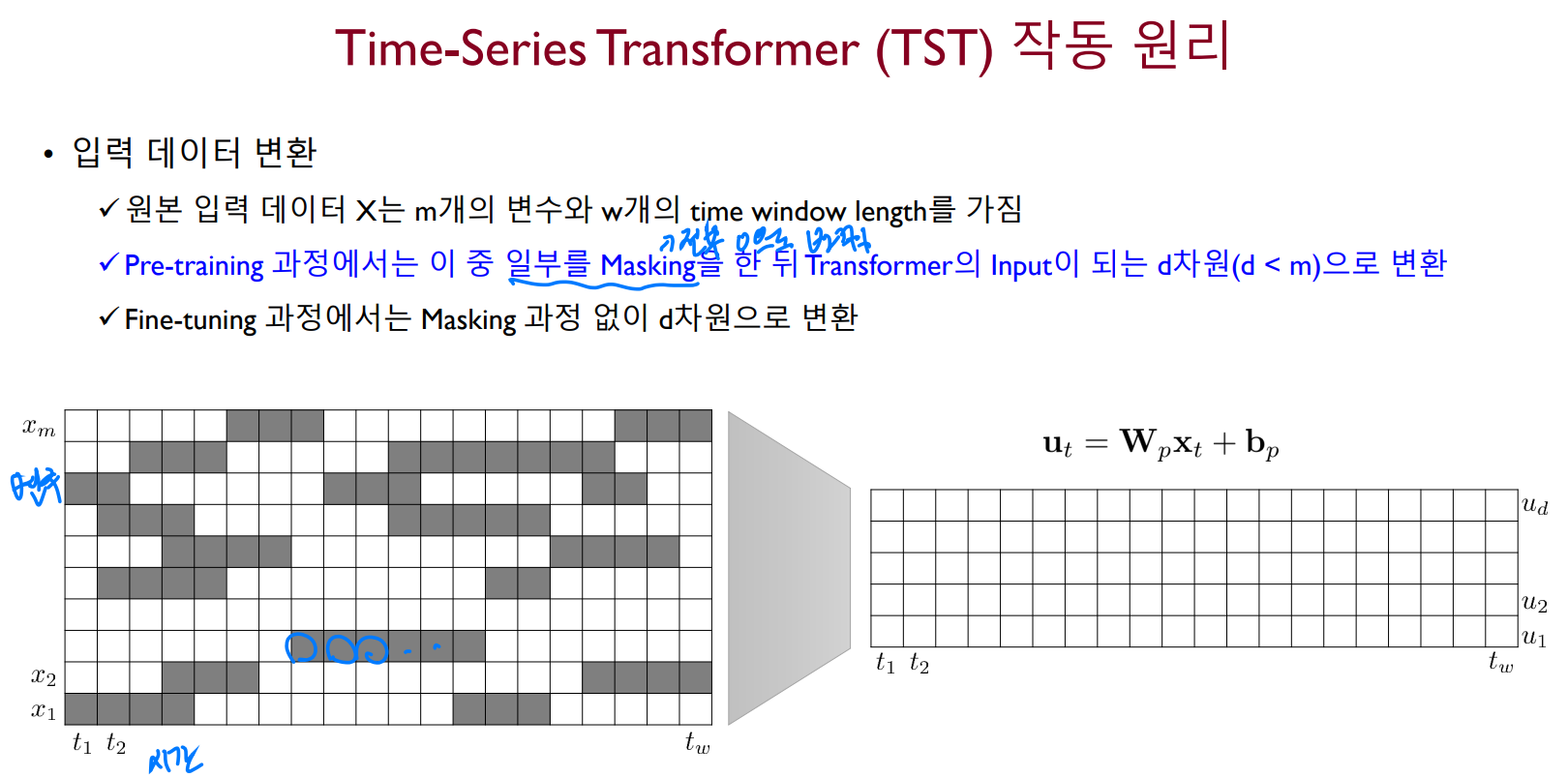
Pre-training의 목적은 마스킹 된 부분의 값을 모델이 정확하게 예측할 수 있도록 하는 것에 있다. 마스킹은 길이가 어떤 분포를 따르도록 마르코프 체인을 적용하여 결정되며, 모든 변수에서 동일한 시점을 Masking하는 것보다 변수 별로 마르코프 체인을 이용하여 독립적으로 결정하는 것이 우수한 성능을 나타낸다고 한다.
이후에는 기존 트랜스포머 모델의 인코딩과 같은 포지션 인코딩, 셀프 어텐션 과정을 거친다.
Fine-tuning
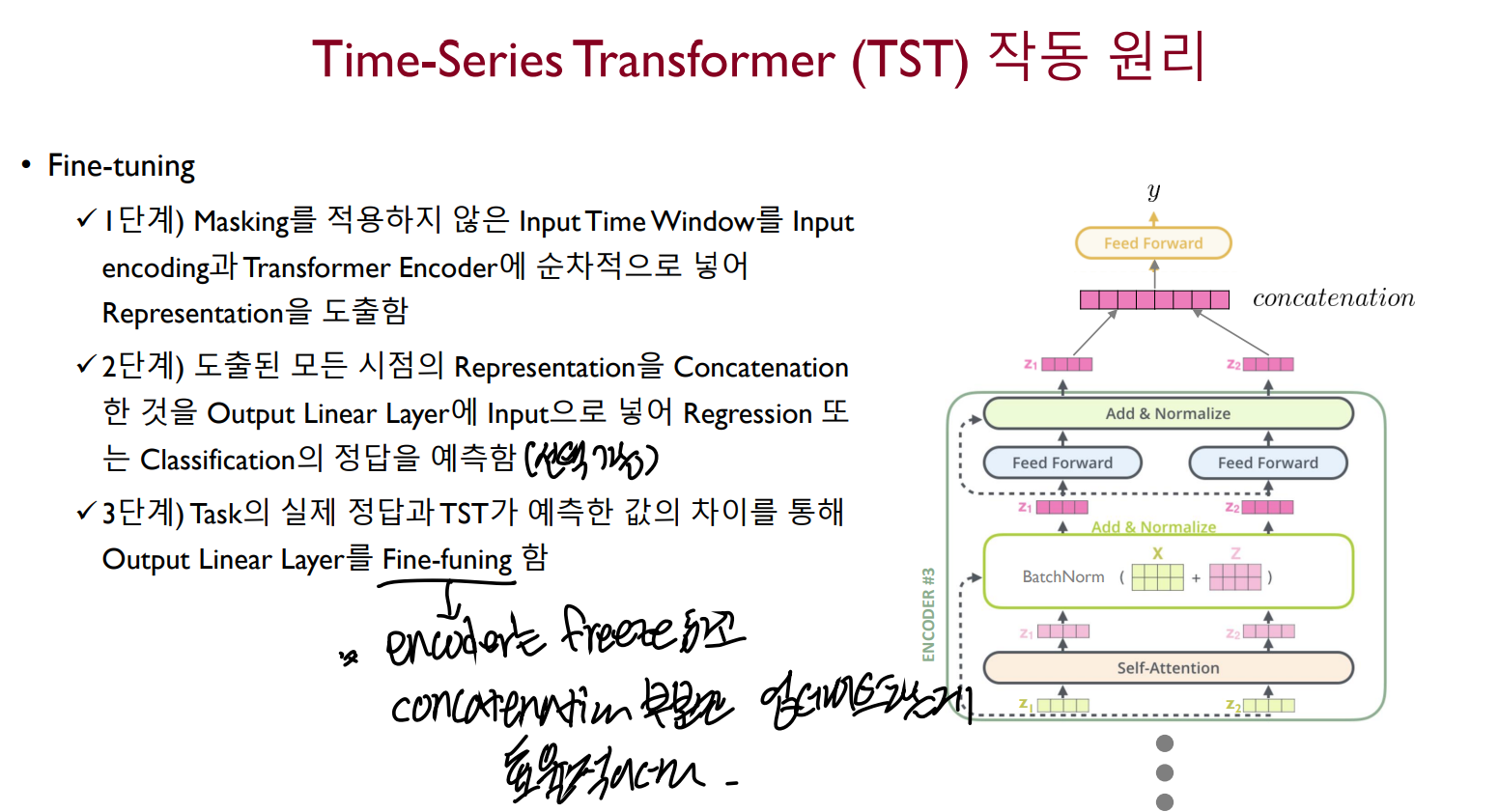
fine-tuning task를 수행하기 위해서는 주로 output layer를 제외한 나머지는 freeze하고 진행한다. output layer의 타입에 따라 regressin을 수행할지, classification을 수행할지 결정할 수 있다.
TST의 성능
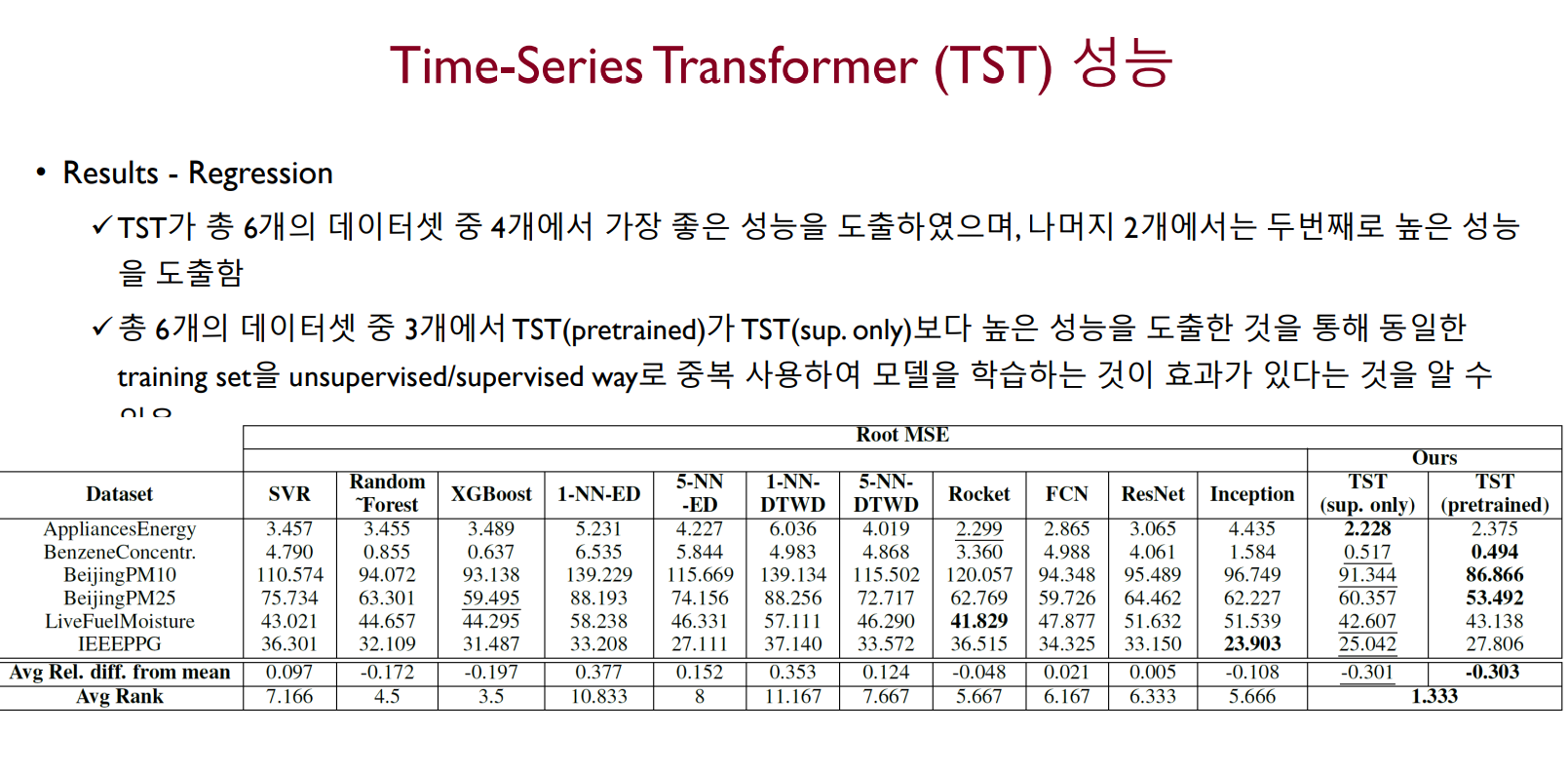
TST(pretrained)가 TST(sup.only)보다 높은 성능을 도출했다는 것은 기존에 Supervised learning만 수행했던 모델(sup.only)보다도 Pre-training을 통해 모델 스스로 학습한 Unsupervised learning을 함께 수행한 모델(pretrained)이 더 좋은 성능을 보였다는 것으로 해석하면 된다.
배운 점

해당 포스트는 LG Aimers 활동 중 고려대학교 강필성 교수님의 강의자료를 기반으로 작성된 글입니다. 학습 정리용으로 작성하였으며, 잘못되었거나 수정해야 할 내용이 있을 수 있습니다. 해당 내용이 있다면 이메일이나 댓글로 알려주세요. 감사합니다.
