Supervised Learning
지도학습은 Label(정답이 있는,지도된) 데이터를 기반으로 mapping 함수 g(X->Y)를 학습시켜 unseen data x'에 대한 y값을 예측하는 것이다.
labeled data는 여러 feature들로 표현될 수 있다. 예를 들어 자동차가 input data일 때, 자동차의 종류에 따라 가질 수 있는 feature는 가격이 될 수도 있고 엔진의 힘 등이 될 수도 있다.
input data의 feature를 분석하기 위해서는 해당 데이터에 대한 Domain knowledge가 요구되었으나, 최근에는 강화학습을 통해 이 feature들 또한 학습 가능하다고 한다.
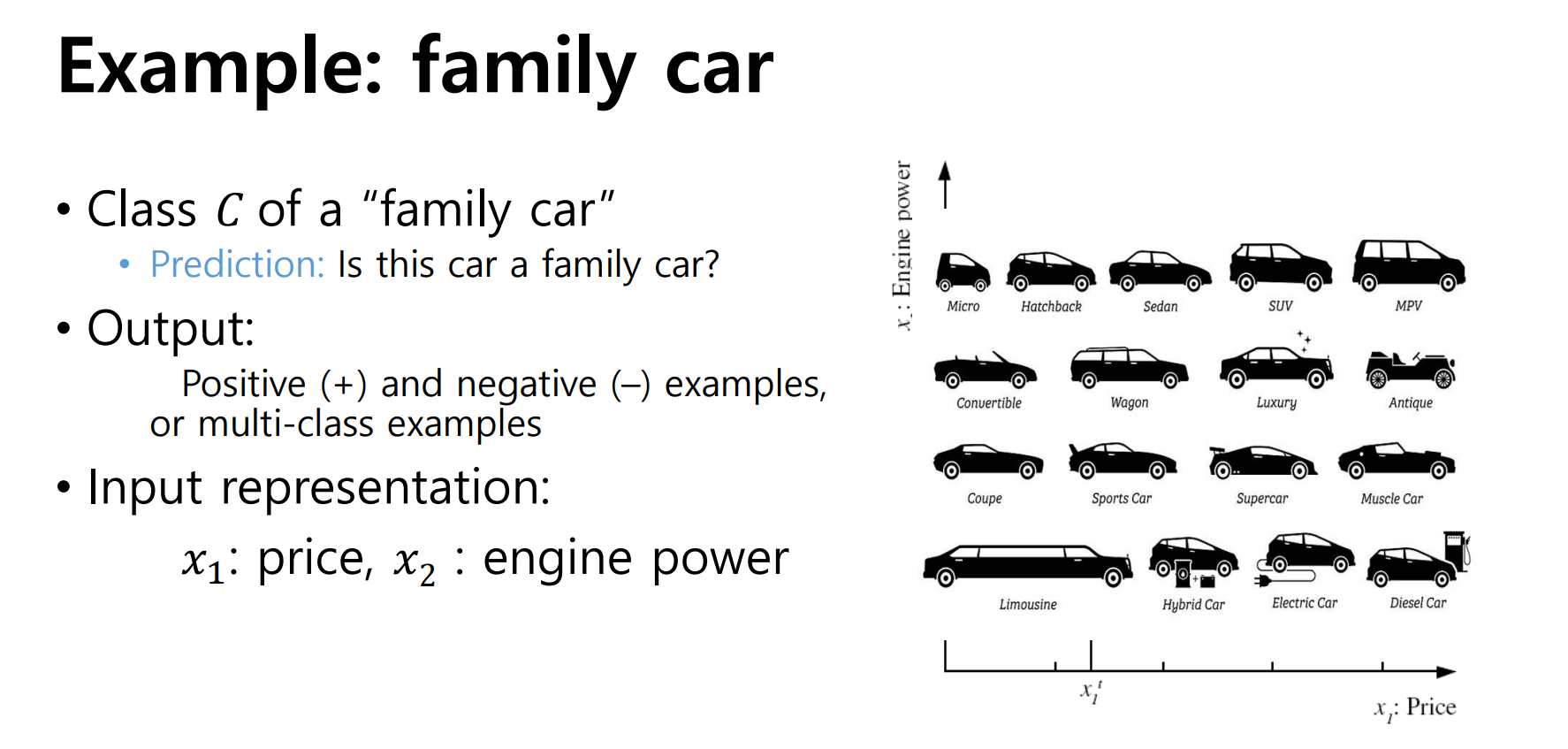
위 사진처럼 자동차의 feature에 따라 가족용 차량인지 구분하는 Y값(label)을 예측할 수 있다. 여기서 unseen data x'에 대한 예측을 한 값과 실제 x'의 label의 차이를 Error라고 부른다.
한 input data가 있을 때, 이를 trian, validation, test set으로 나누는데 test set의 error를 모델의 error라고 보면 된다.
지도학습의 목표는 크게 두 가지가 있다.
- test set의 error를 train set의 error를 비슷하게 하여 예측값의 일관성을 높이는 것
-> unseen data에 대해서 정확도를 갖고 있는지 확인 - train set의 error를 0에 근사하여 예측값의 정확도를 높이는 것이다. -> 잘 학습되었는지 확인

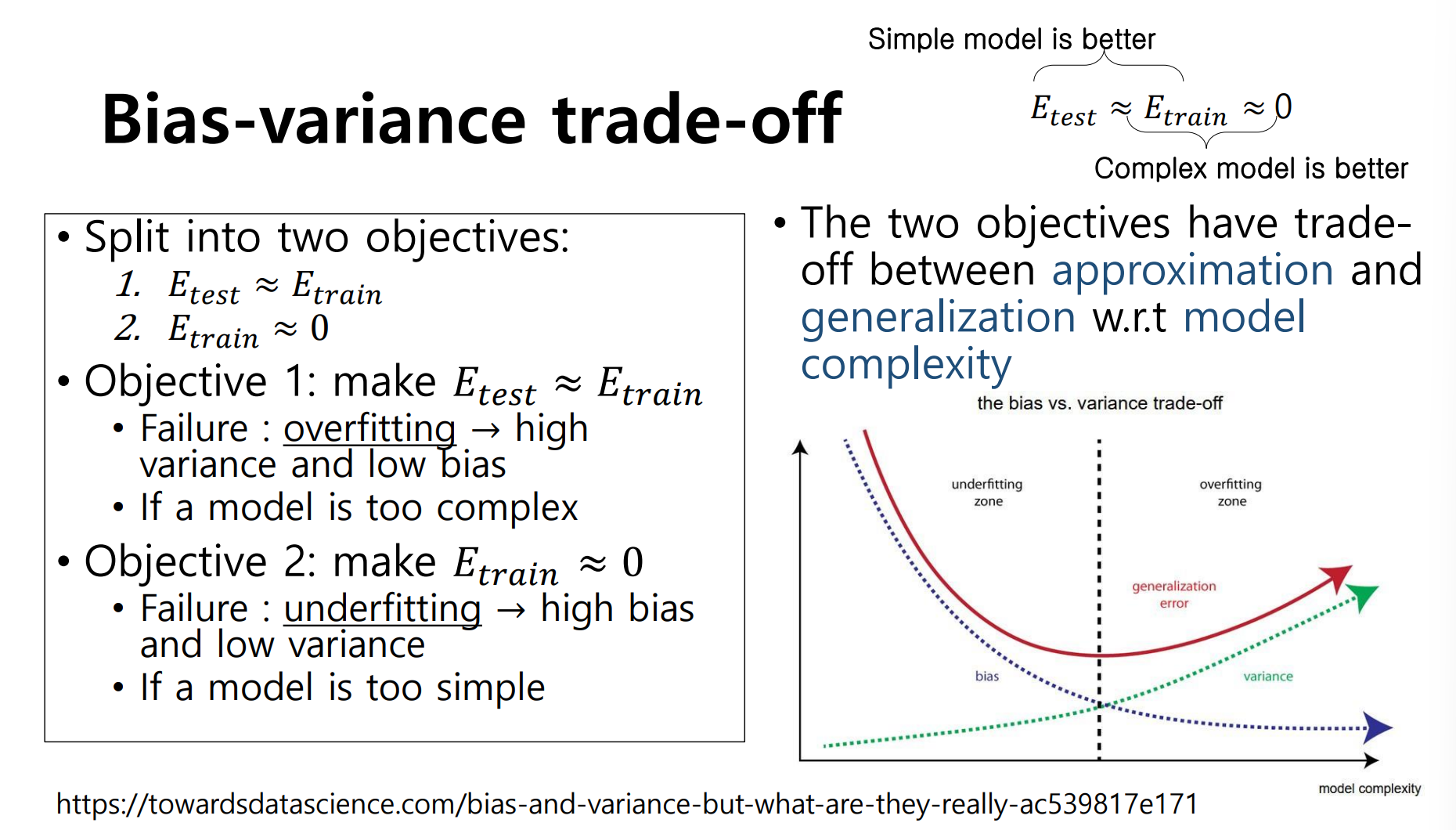
variance와 bias는 Trade-off 관계에 있다. 따라서 완벽한 모델은 없기 때문에 두 값 사이의 적절한 값을 찾아가는 과정이 중요할 것이다.
Gradient Descent
모델을 선형적으로 구성하기 위해서는 input data와 linear combination이 될 model parameter가 필요하고, 모델의 예측값이 잘 나오도록 이 값들을 학습을 통해 업데이트할 필요가 있다. 지도학습은 이를 위해 Gradient Descent라는 방식으로 model parameter를 업데이트한다.

위 이미지에서 α(알파)값은 learning rate로 기존 파라미터 값을 얼마나 업데이트할지 결정하며, 사용자에 의해 결정되는 hyper parameter이다.
Gradient Descent를 하는 방법에도 여러가지가 있는데, 모델 파라미터의 업데이트를 결정하는 주기에 따라 다르다.
- 전체 sample에 대한 Gradient로 진행하는 Batch GD
- sample 하나하나마다 진행하는 Stochastic GD,
노이즈가 있는 data set에 대해 쉽게 영향을 받는다. - 사용자가 정한 한 batch 크기만큼 진행하는 mini-batch GD
이러한 방법들은 loss function의 local minimum에 빠져 최적화된 gradient를 계산하지 못하는 경우가 생기는데, 여기서 momentum이라는 개념이 도입된다.
momentum은 학습에 과거 파라미터가 업데이트 되어갔던 경향을 누적하여 반영한다. 따라서 보다 노이즈 데이터에 대해 안정적이며 global minimum을 찾을 수 있는 확률이 높아질 것이다.
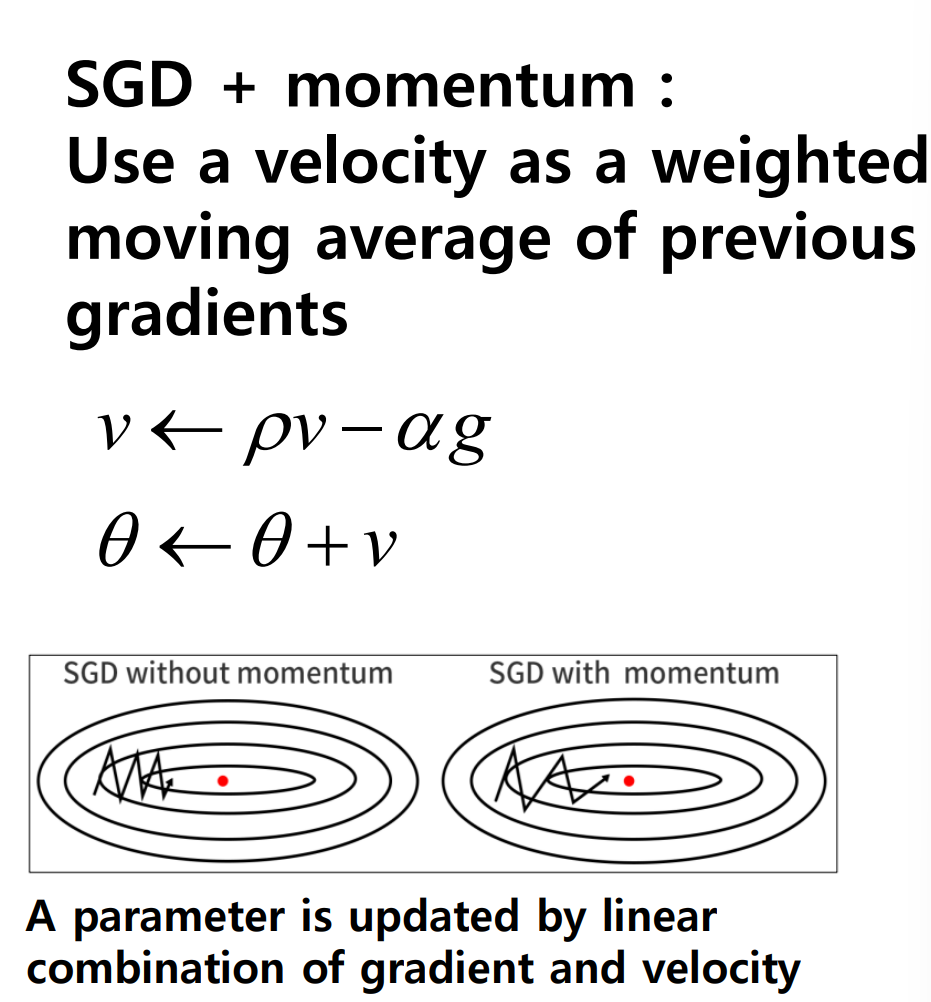
가장 많이는 Gradient descent 알고리즘은 Adam일 것이다. 대부분의 지도 학습에서 Adam 방식이 가장 기본적인 선택이다. learning rate와 momentum을 adaptive하게 변경 해가며 학습을 진행하고, 이 두 값으로부터 파라미터를 업데이트하는 수식을 가진다.

Emsemble Learning
앙상블 학습은 서로 다른 학습된 모델(classifiers, expert)이 Y값을 예측하도록 하는 방법이다. 예측 정확도가 높아질 뿐만 아니라, 구현도 간단하고 parameter tuning이 많이 필요없기 때문에 주로 쓰이는 지도학습 기법이다.
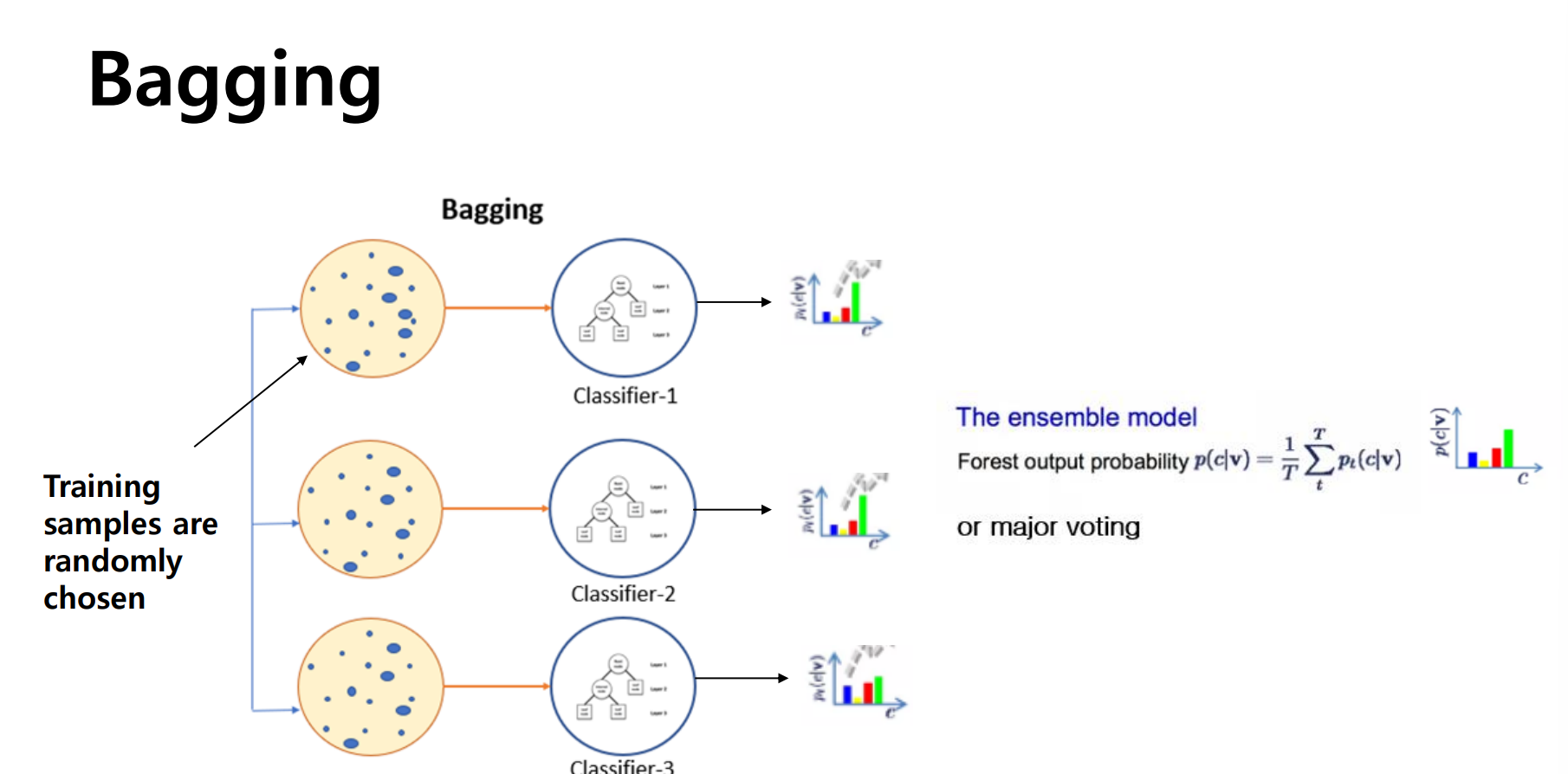
Bagging
Bagging은 모델의 중복과 상관없이 여러 개의 classifier가 train data set을 랜덤하게 나누고 각 모델이 이를 선택하여 학습하도록 하고, 그 결과를 voting이나 averaging으로 예측하는 방법이다.
모델의 학습을 병렬적으로 처리할 수 있으며, voting이나 averaging을 통해 결과를 내기 때문에 variance를 줄여준다는 장점이 있다. 대부분의 경우에서 많은 classifier를 가질 수록 좋은 성능을 보인다.
Boosting
Boostring은 classifier에 데이터를 순차적으로 대입하여 어떤 sample에서 예측이 잘 안되었는지(missclassfied points)에 따라 weight를 부여하여 모델을 학습하는 방법이다.
모델의 복잡도가 낮아 bias가 높은 classifier를 weak classifier라고 하는데, 이를 순차적으로 사용하여 점차적으로 예측력을 높이는 방법이다. 대표적인 알고리즘으로 AdaBoost가 있다.


해당 포스트는 LG Aimers 활동 중 이화여자대학교 강제원 교수님의 강의자료를 기반으로 작성된 글입니다. 학습 정리용으로 작성하였으며, 잘못되었거나 수정해야 할 내용이 있을 수 있습니다. 해당 내용이 있다면 이메일이나 댓글로 알려주세요. 감사합니다.
