▶️ 원본 영상: https://youtu.be/LkkgtNtuEoU
1️⃣ AWS Glue 개요
- 완전 관리형 ETL 서비스
- 개발자 친화적 : Apache Spark 환경, Python과 Scala 코드 지원
- 데이터 분석을 위한 준비
데이터 카탈로그****: 데이터에 대한 하나의 단일된 뷰데이터의 이동과 변환 작업(**ETL**),Job 스케줄링
💡 ETL은 데이터의 추출, 변환, 로드 프로세스를 가리킵니다.
데이터는 데이터 소스에서 스테이징을 거쳐 데이터 웨어하우스로 이동합니다.
민감한 보안 데이터를 정리한 후 데이터 웨어하우스에 로드하기 때문에 데이터 개인 정보 보호와 규정 준수에 도움이 됩니다.💡 ELT은 데이터 웨어하우스를 활용하여 기본 변환을 실행하며 데이터 스테이징을 할 필요가 없습니다.2️⃣ 데이터 카탈로그
데이터를 쉽게 찾고 관리
- 데이터 카탈로그는 데이터에 대한 하나의 단일된 뷰
- Athena에서는 이 카탈로그로 데이터 조회 가능
- 데이터 카탈로그는 테이블의 상세 정보를 포함하고 있음
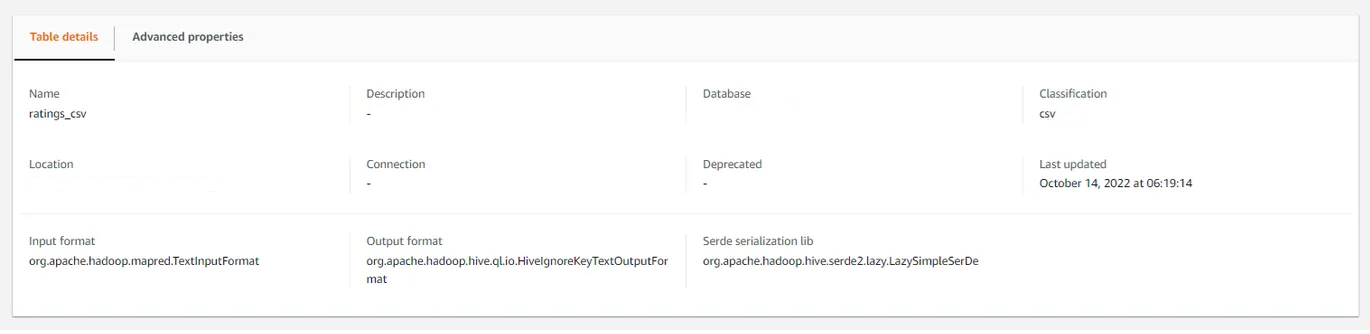
- 테이블 속성 : 테이블 이름, 설명, 데이터베이스, 데이터 종류, 위치, 마지막 업데이트 일자 등
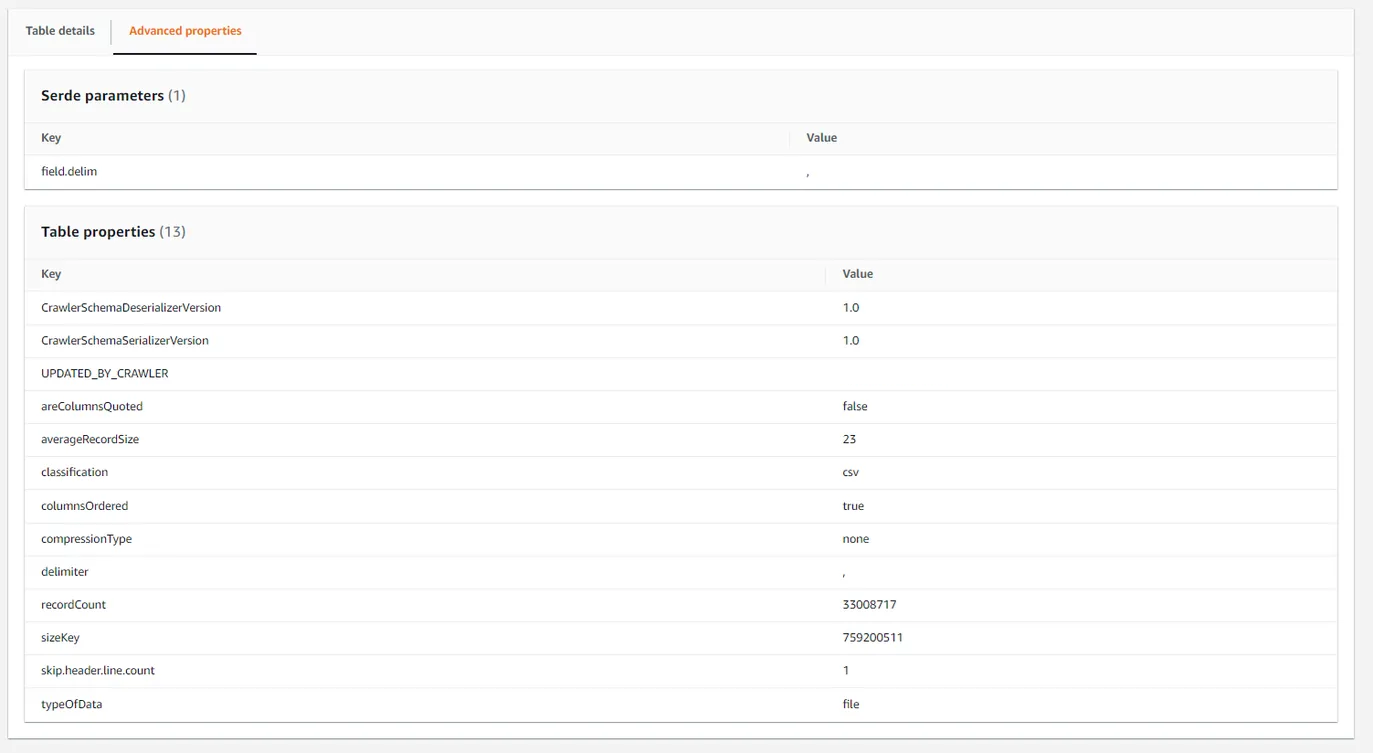
- 데이터 분포 통계 : 레코드 수, 평균 레코드 크기, 크롤러 이름 등
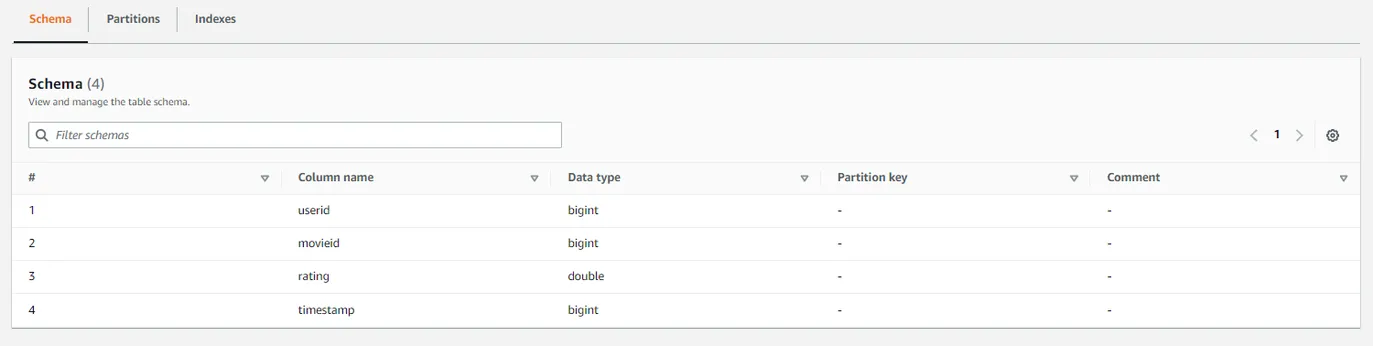
- 테이블 스키마 : 컬럼 이름, 데이터 타입, 파티션 키 등
- 테이블 속성 : 테이블 이름, 설명, 데이터베이스, 데이터 종류, 위치, 마지막 업데이트 일자 등
- 자동적으로 파티션 구조 파악 : 디렉토리 구조가 키값으로 이루어져 있다면 자동적으로 파티션 구조를 파악하여 파티션 컬럼을 생성
- 예) year=2022, month=12, day=10…
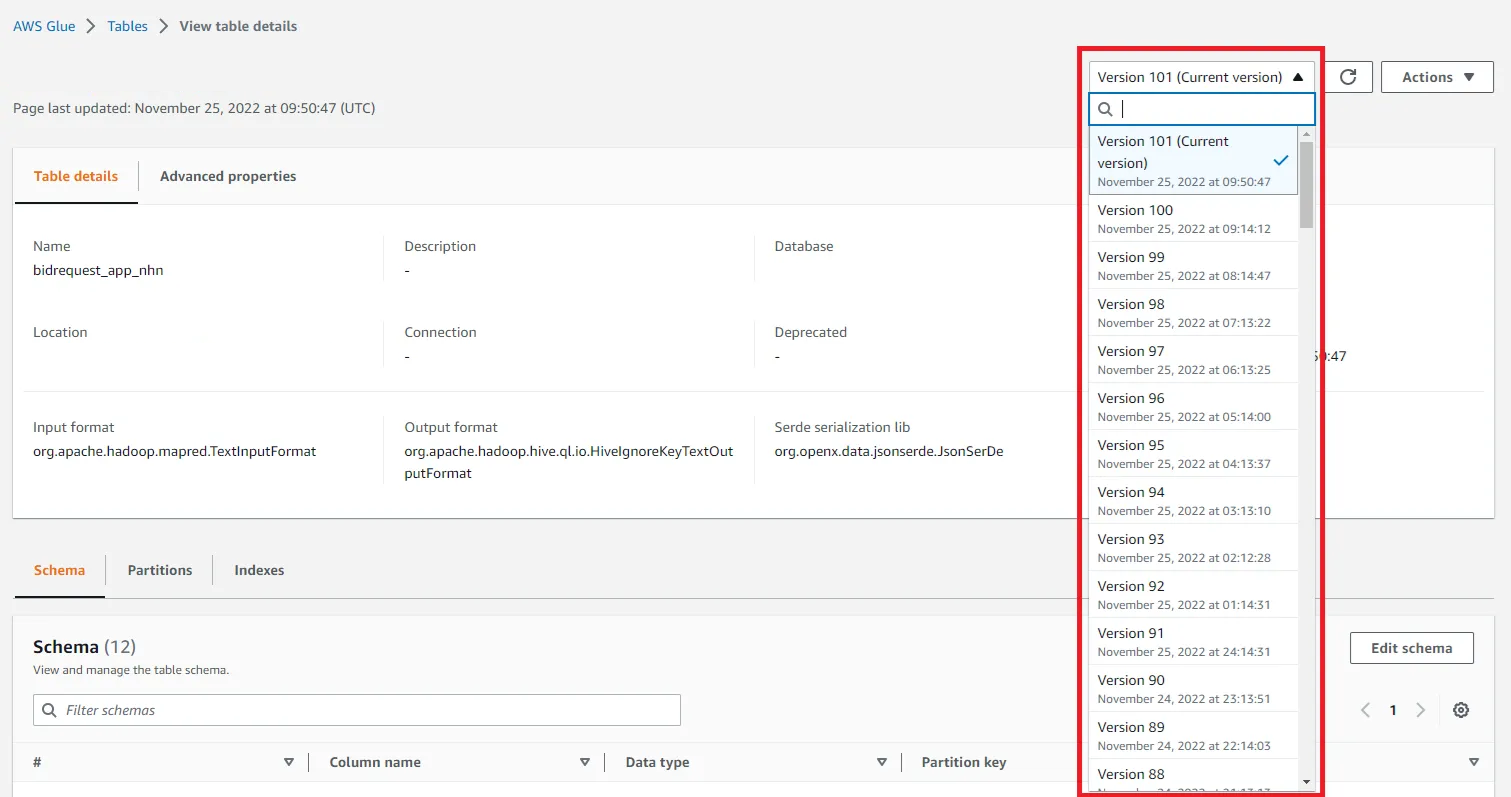
- 스키마 변경 탐지 및 버전 관리 : 주기적으로 Glue의 크롤러를 실행하면, 변경된 스키마에 대한 탐지와 버전 관리 가능
✨ 데이터 카탈로그로 만들어진다면
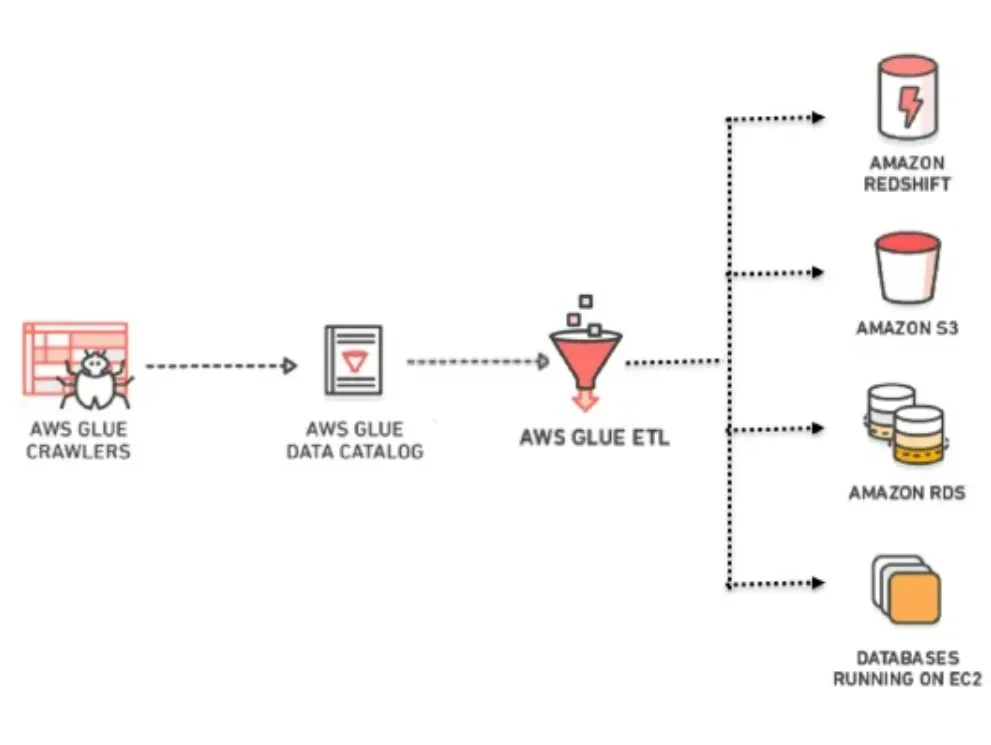
- 필요한 데이터를 검색
- 데이터 ETL 작업 수행
- Athena, EMR, Redshift 등에서 단일된 뷰로 동일한 데이터에 접근/활용 가능
3️⃣ AWS Glue ETL
- 서버리스 데이터 변환 작업
Apache Spark기반Pyspark와Scala언어 지원- Zeppelin, PyCharm등 익숙한 환경에서 수정, 테스트가 가능하도록 Dev EndPoint 제공(Python 2.7 지원)
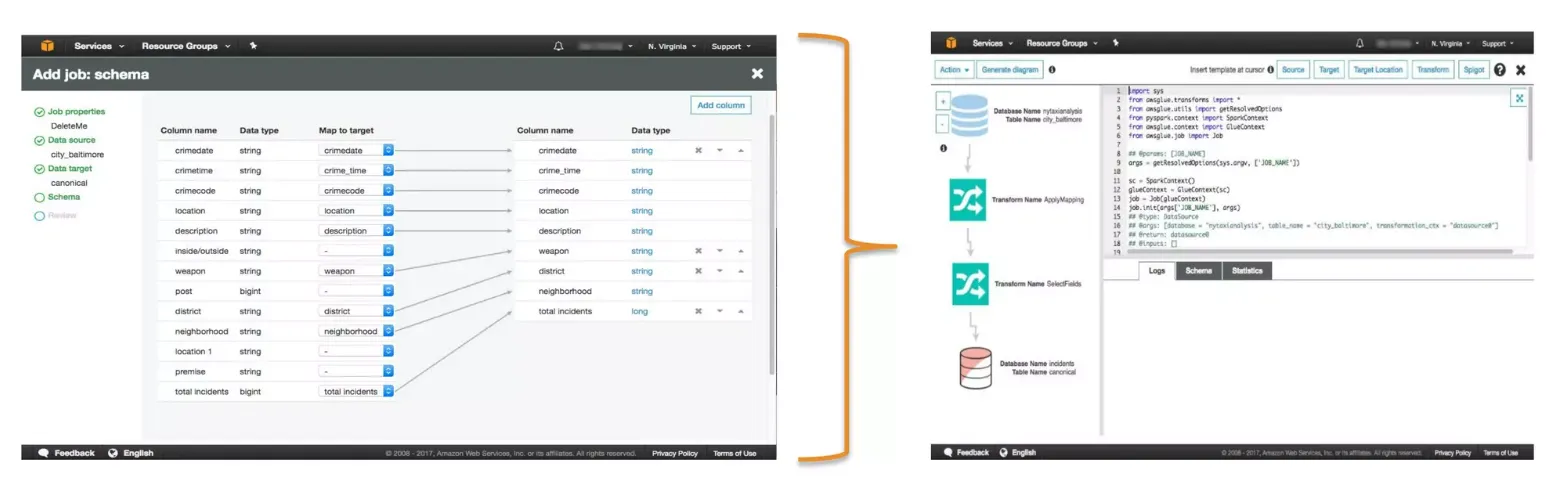
🏷 Job 생성 - 콘솔에서 코드 생성
- 콘솔에서 컬럼 단위의 매핑을 수정하면
- Glue에서 자동적으로 데이터 변환 그래프와 Pysaprk(또는 Scala)) 코드를 생성, 직접 수정 가능
- 직접 사용하는 노트북 서비스로 Dev Endpoint 이용하여 코딩 가능
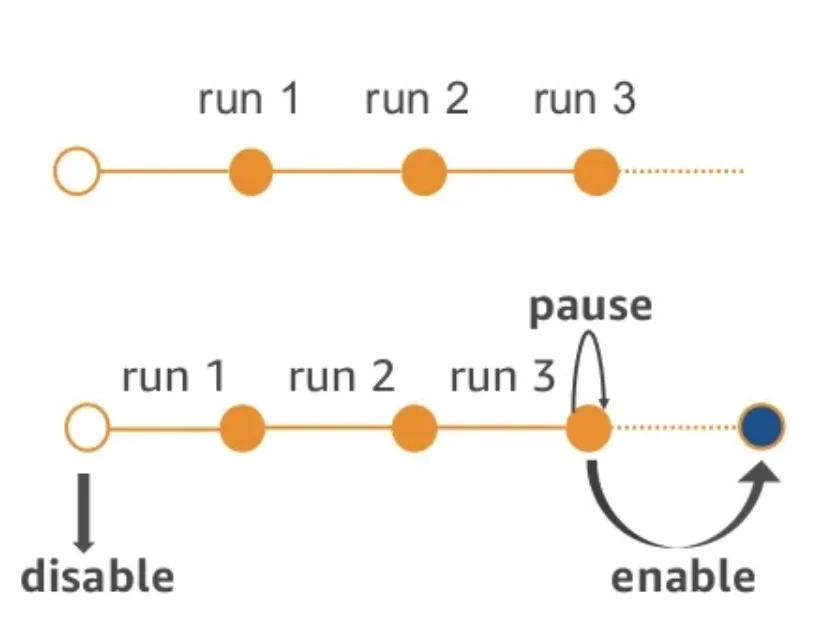
🏷 Job 북마크
북마크 기능을 통해 지속적으로 추가되는 데이터에 대한 중복 작업 관리가 가능
- 일 단위로 증가하는 로그 데이터 처리
- 시간 단위로 Kinesis Firehose 데이터 처리
- DB 에 저장된 데이터를 시간 단위로 처리(단일 PK 데이터)
🏷 Job 실행 - 서버리스
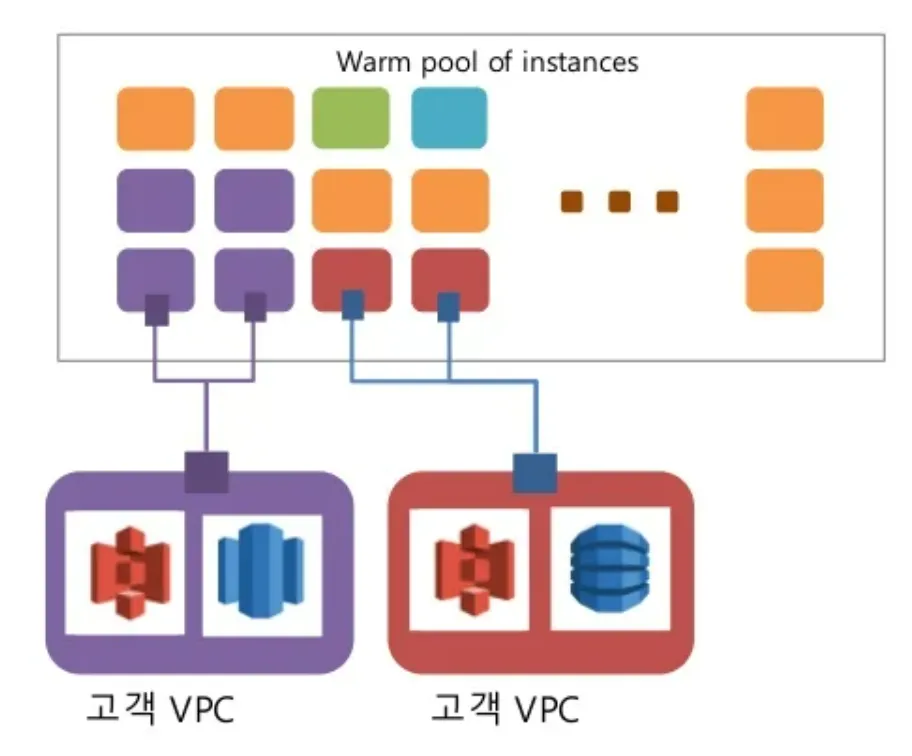
Job을 실행하기 위해서 자동적으로 인프라를 생성하고 사용한 만큼만 과금
💡 서버리스(Serverless) : 클라우드 컴퓨팅의 모델 중 하나로 사용자가 서버를 직접 관리할 필요가 없는 모델- 서버 풀 : Job 시작 시간을 줄이기 위해 미리 설정된 서버 그룹을 운영
- 자동 설정된 VPC와 Role 기반 접근 제어
- 고객의 요구와 SLA를 맞추기 위해서 자동적으로 리소스 확장
💡 SLA : 고객이 공급업체에게 기대하는 서비스 수준을 기술한 문서- Job 실행을 위해 사용한 리소스에 대해서만 비용 지불
4️⃣ AWS Glue ETL 주요 단계
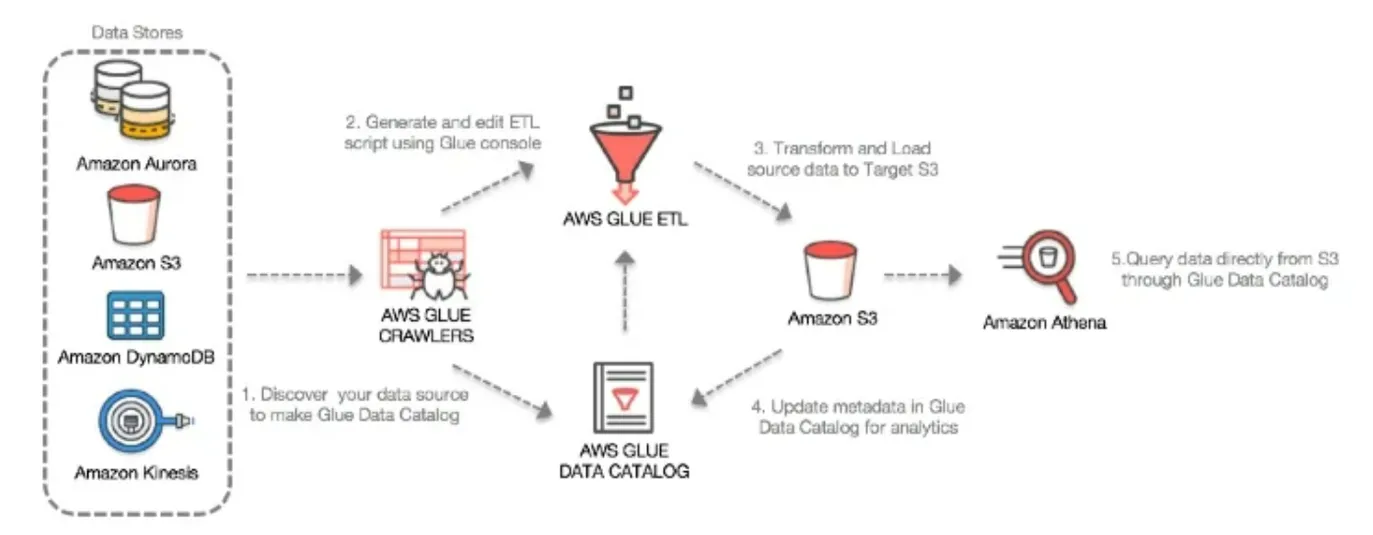
- 데이터 소스에 Crawler를 통해 데이터 카탈로그 생성
- 컬럼 단위의 맵핑을 통해 자동 코드 생성
- 편리한 환경에서 자유롭게 코드 수정 및 테스트(/w Dev-Endpoint)
- 실제 운영 환경에서 Job 스케줄링 및 실행
4️⃣ AWS Glue 활용 패턴
❗ 데이터 웨어하우스의 로그데이터 분석
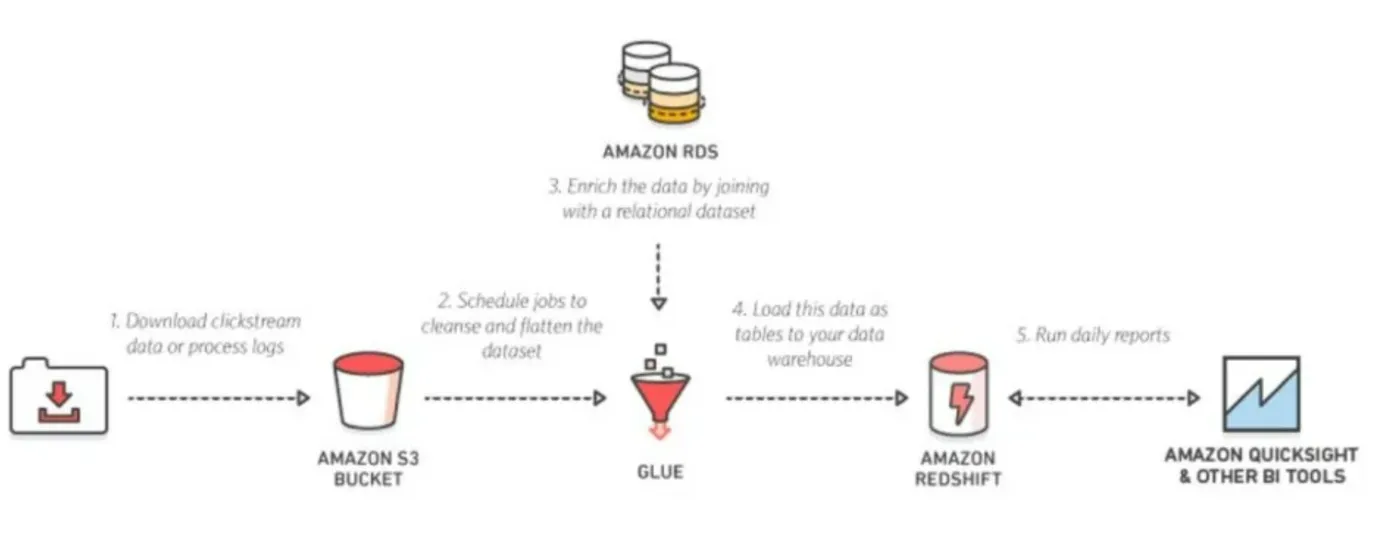
- S3에 저장된 로그와 RDS에 있는 중요한 데이터와 같이
Glue ETL로 작업 진행 - Redshift라는 데이터 웨어하우스에 저장
- 이러한 데이터를 기반으로 일 단위의 리포트를 작성
❗ 다양한 데이터 스토어에 대한 통합된 뷰
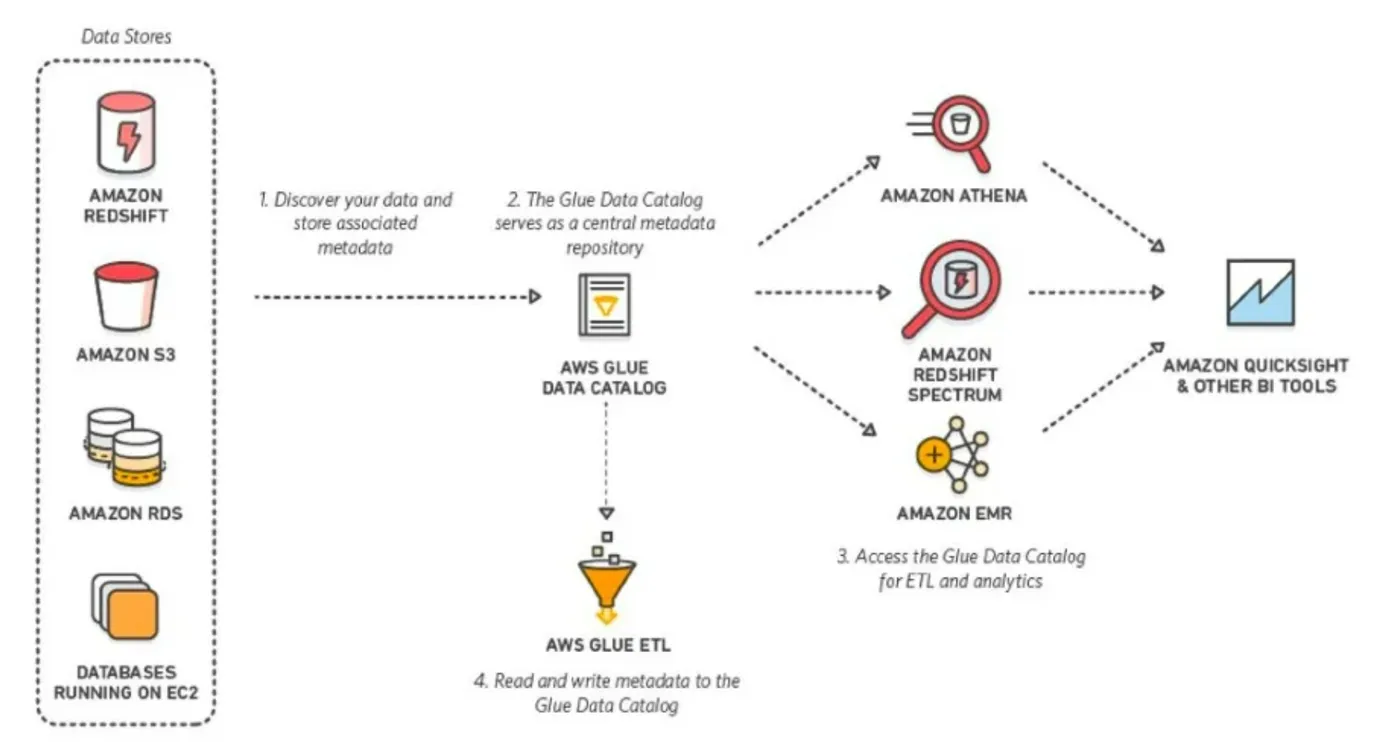
- 다양한 데이터 소스들을 하나의
카탈로그로 통합해서 볼 수 있어, ETL 작업할 때 마치 하나의 DB에 있는 것처럼 사용할 수 있음 - 결과물이 타겟에 저장이 되면
카탈로그가 갱신되고 다양한 툴에서 접근하여 쿼리를 수행할 수 있게 됨
❗ S3 데이터레이크에 대한 쿼리 수행
💡 데이터레이크 :
- 하나의 저장소에 여러 가지 종류를 저장하고, 다양한 툴들이 붙어서 다양한 요구사항에 맞게 데이터를 잘 활용할 수 있는 아키텍처 접근
- AWS에선 S3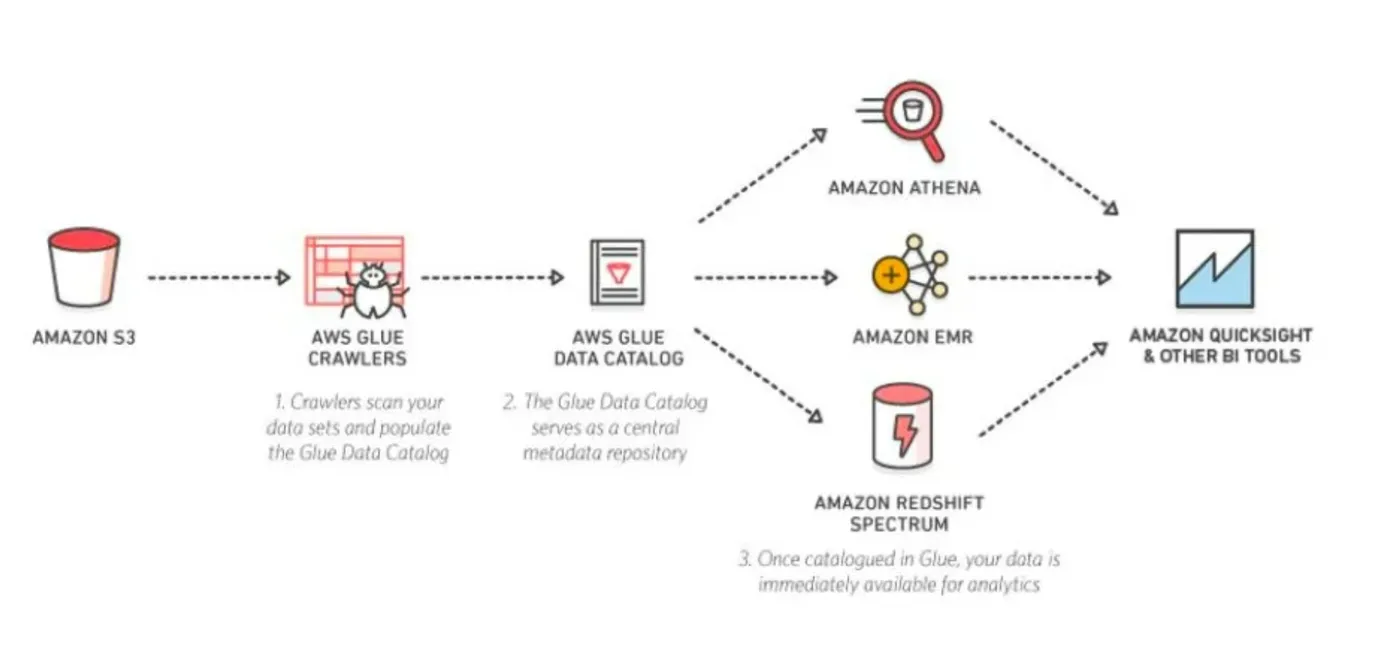
- 다양한 종류의 데이터가 S3에 저장
- Athena로 쿼리를 날리거나, Hive에서 대량의 배치 처리, Spark에서 머신러닝, Redshift에 저장된 테이블 간의 쿼리 등으로 데이터를 활용
- 다른 BI툴로 진행할 수 있음
❗ 이벤트 기반 ETL 파이프라인
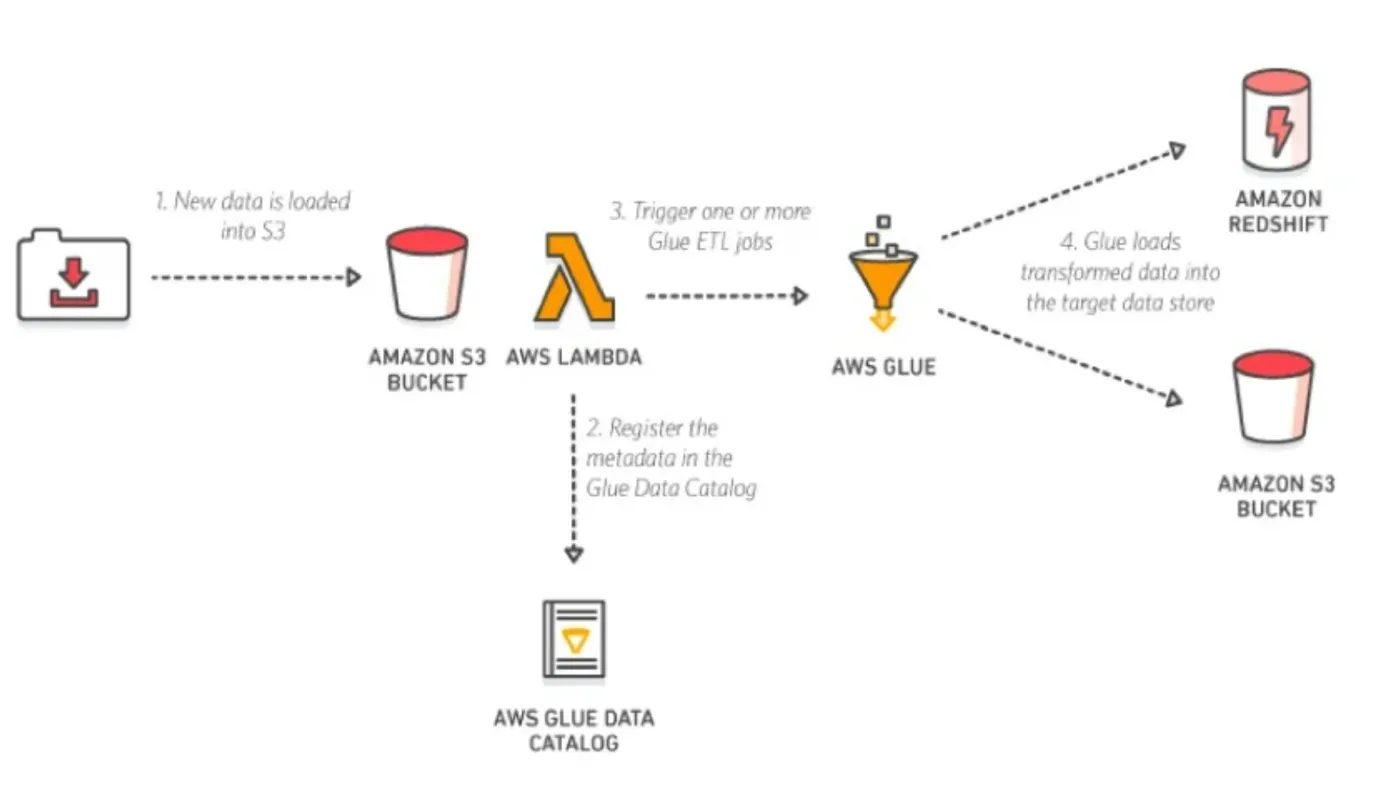
- S3에 새로운 데이터가 들어옴
- lambda의 trigger을 이용해 Glue의 카탈로그를 만들고 ETL 작업을 실행
- 결과물을 원하는 타겟에 등록하여 데이터 소스 활용
📃 사용 방법
📍 Crawler
데이터 카탈로그 생성
Create crawler버튼 클릭
- 크롤러의 이름, 설명, 그리고 태그 지정.
- 데이터와 분류자 선택
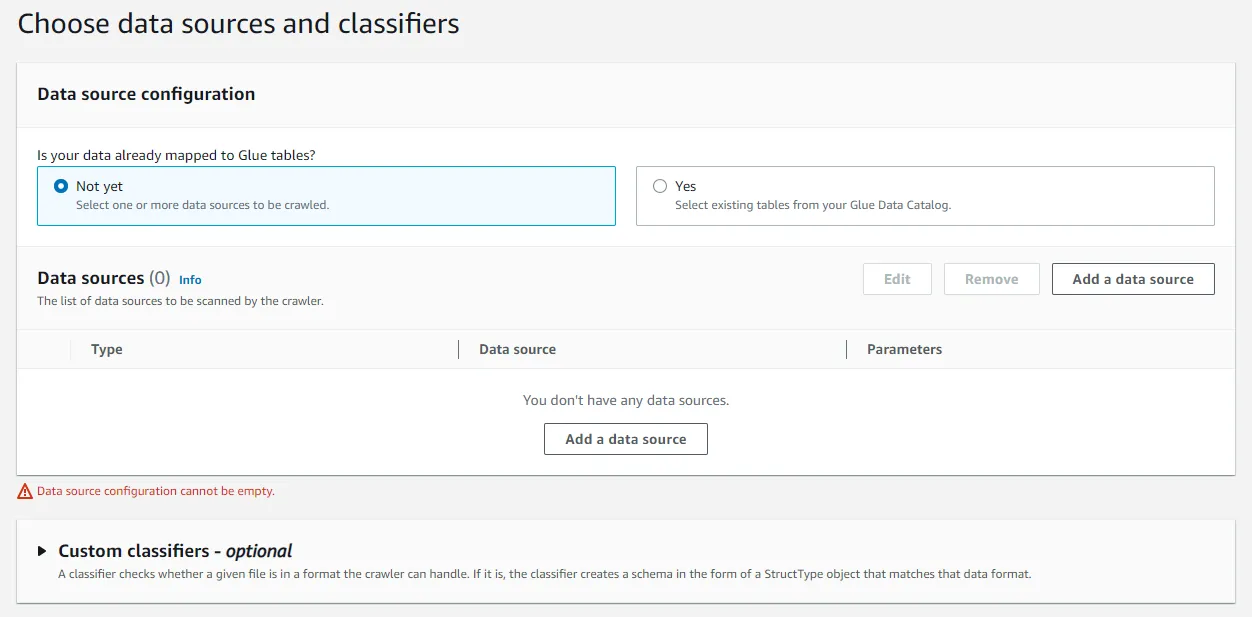
💡 분류자는 AWS Glue Data Catalog에 메타데이터 테이블을 정의할 때 분류자를 사용합니다. 이 때 데이터를 인식하지 못하거나 확실성이 없을 때 사용자 지정 분류자를 생성합니다.Not yet: 데이터가 Glue Table에 아직 매핑되지 않은 경우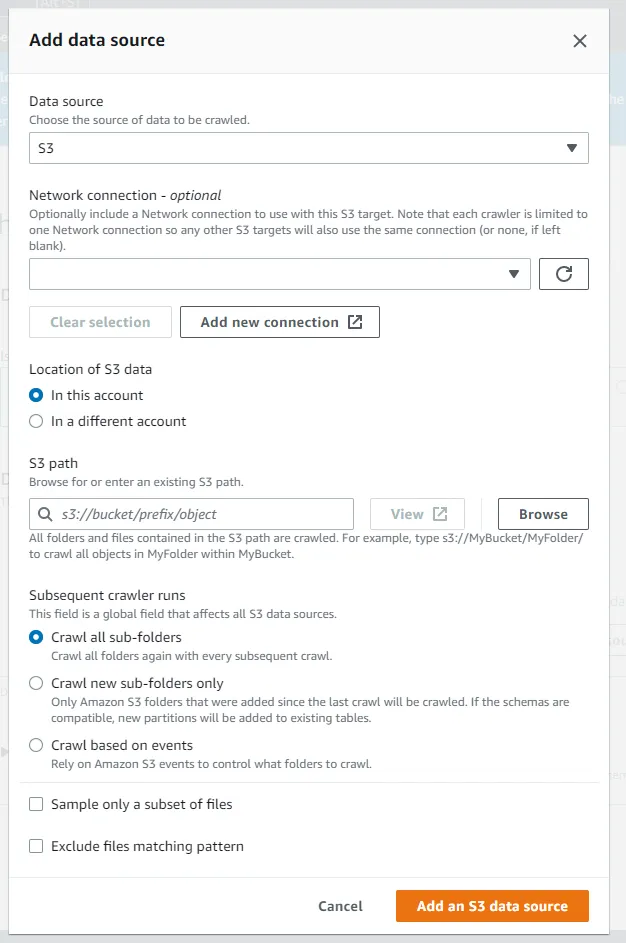
- 데이터 소스, 위치, 경로, 크롤링 방식 지정
Yes: 데이터 카탈로그가 이미 있는 경우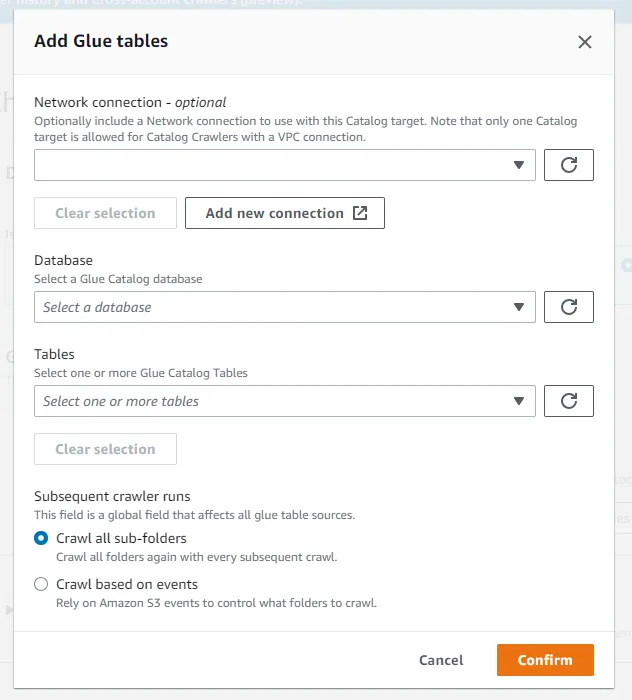
- 이미 있는 데이터 카탈로그의 데이터베이스와 테이블 이름 지정
- 이미 있는 데이터 카탈로그의 데이터베이스와 테이블 이름 지정
- Subsequent crawler runs
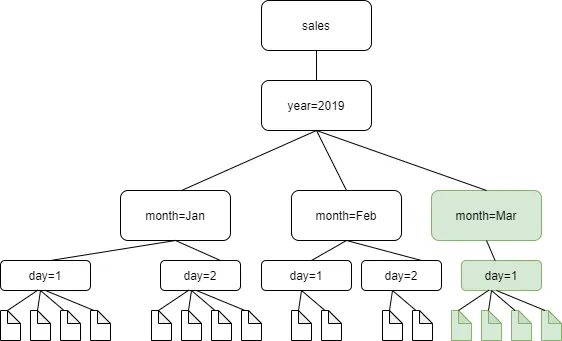
Crawl all sub-folders: 하위 폴더 모두 크롤링Crawl new sub-folders only: 새 폴더만 크롤링. 아래 사진에서는 month=Mar 폴더만 크롤링Crawl based on events: AWS SQS를 사용하여 크롤링
💡 SQS : 메시지 대기열 서비스. 다른 서비스에서 사용할 수 있도록 메시지를 잠시 저장하는 용도- IAM role 선택
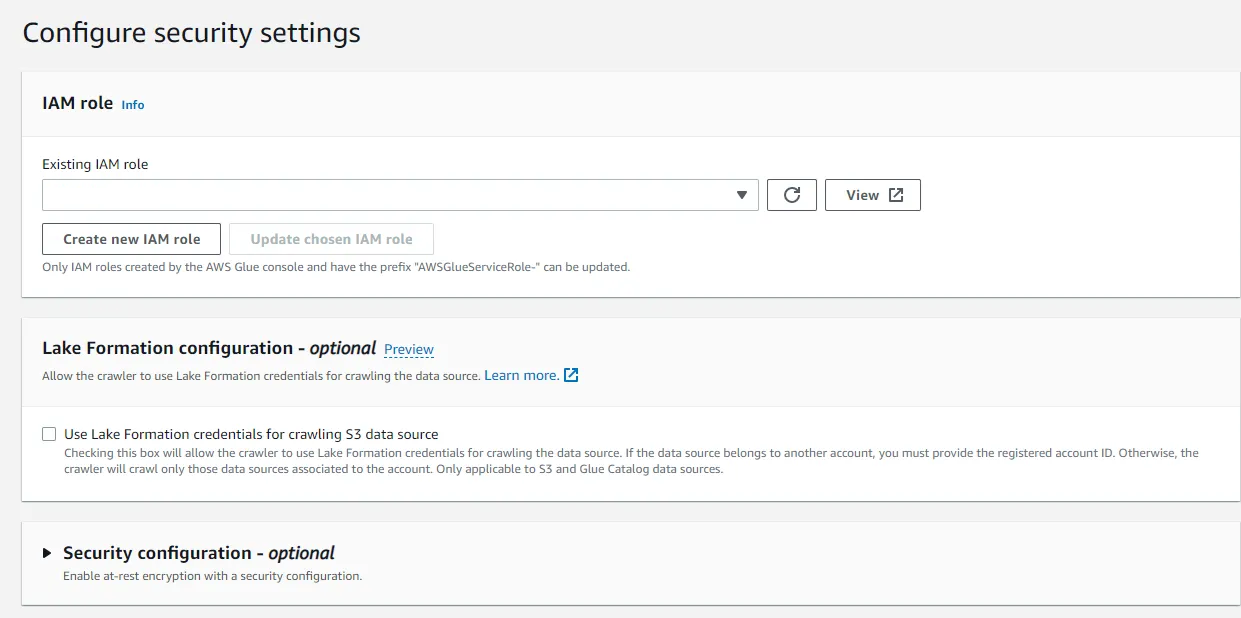
- 데이터베이스를 지정하고, 필요한 경우 테이블 접두어를 지정. 테스트 테이블인 경우
tt를 추가 마지막으로 크롤링 주기를 지정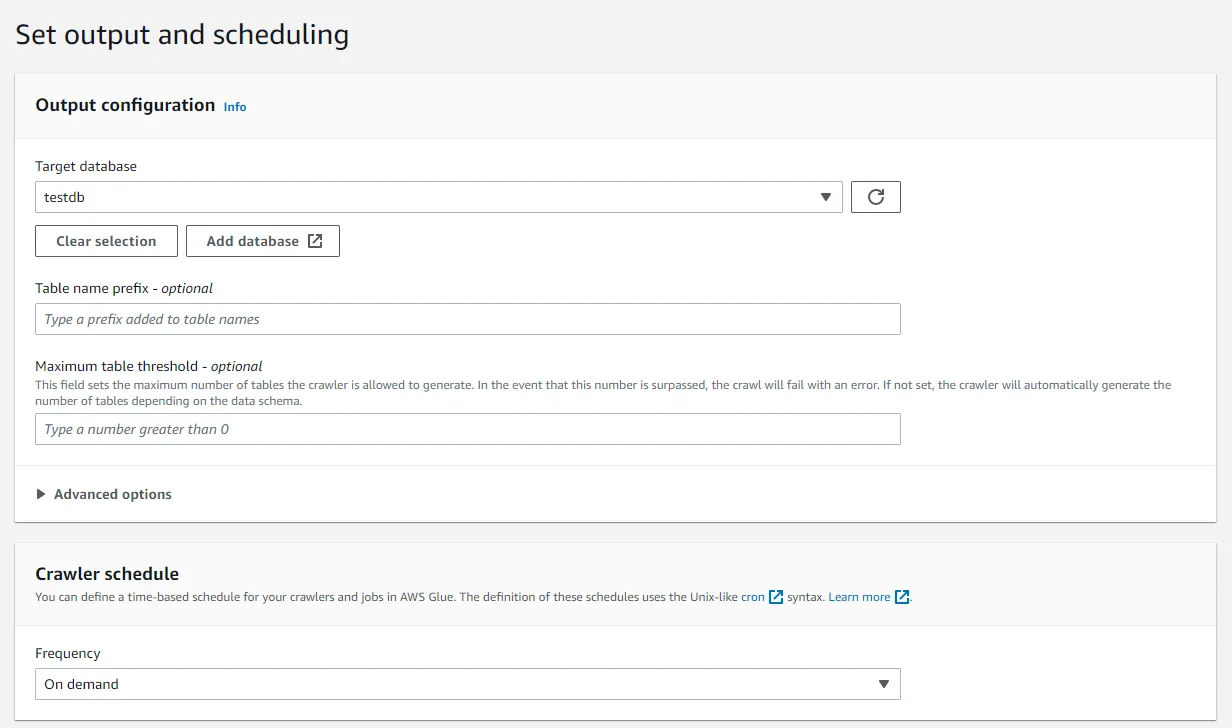
- 3단계에서
Yes을 선택했다면 데이터베이스와 테이블 이름을 지정하지 않음
- 3단계에서
📍 Job
Data ETL
-
Job을 생성 방법 선택. 비주얼 에디터, 스파크 스크립트 에디터, 쉘 스크립트 에디터, 주피터 노트북을 선택할 수 있음.
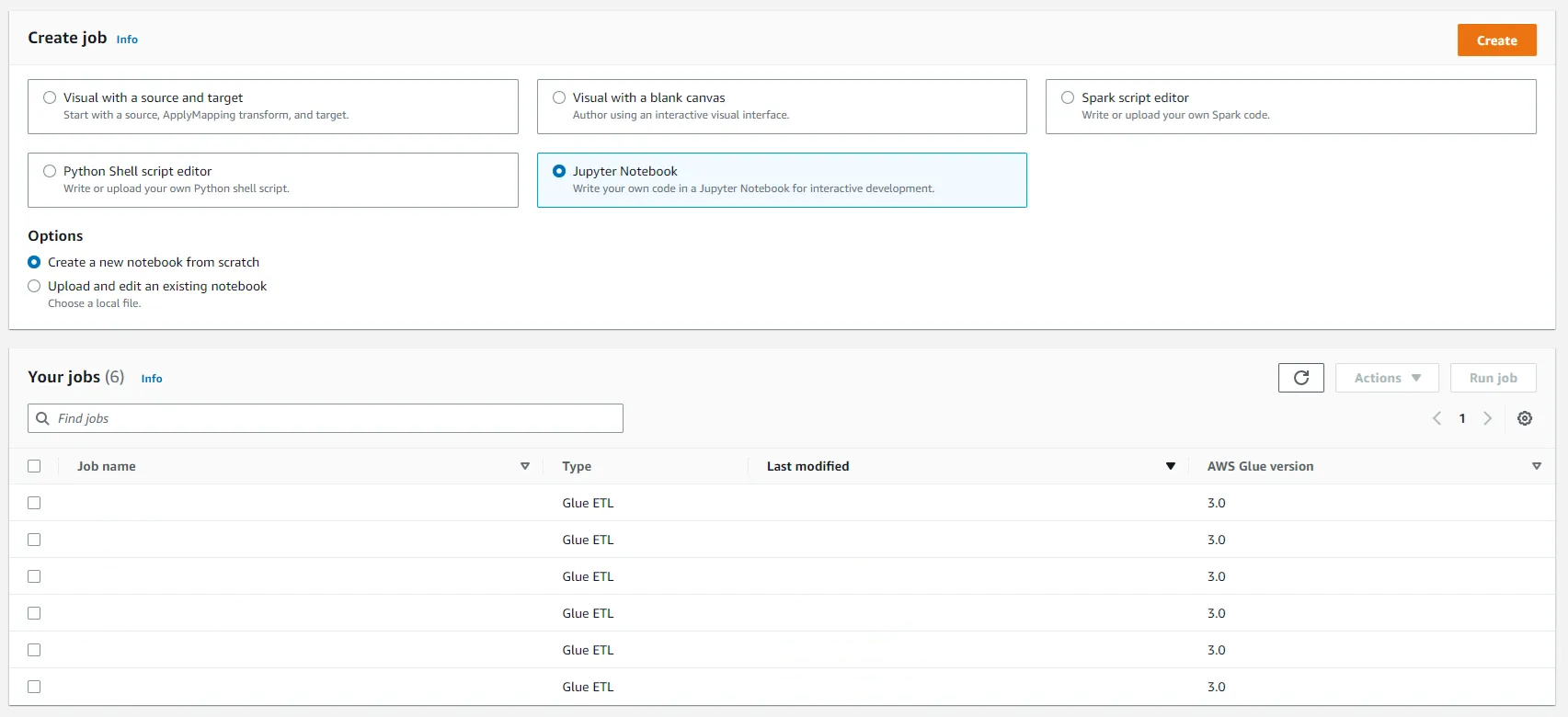
-
주피터 노트북을 선택한 경우 Job 이름과 IAM Role 설정 후 IAM Role 선택.
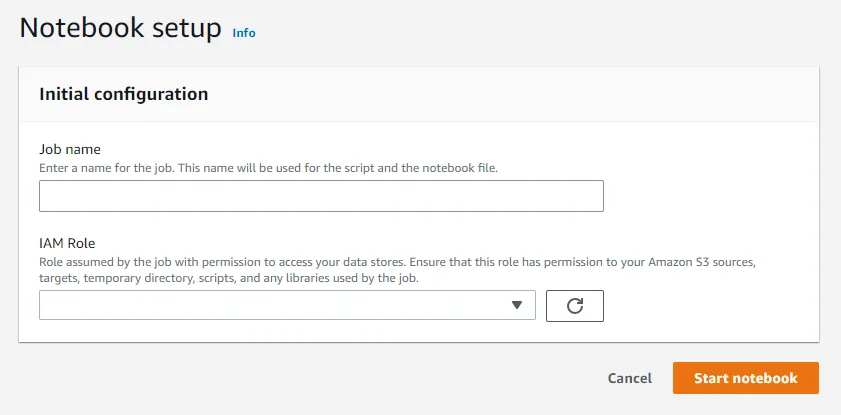
3-1. 화면에서 선택하는 방법
-
처리할 데이터를
Source에서, 데이터 Transform 방법을Action에서, 결과를 어떤 형태로 저장할지Target에서 선택.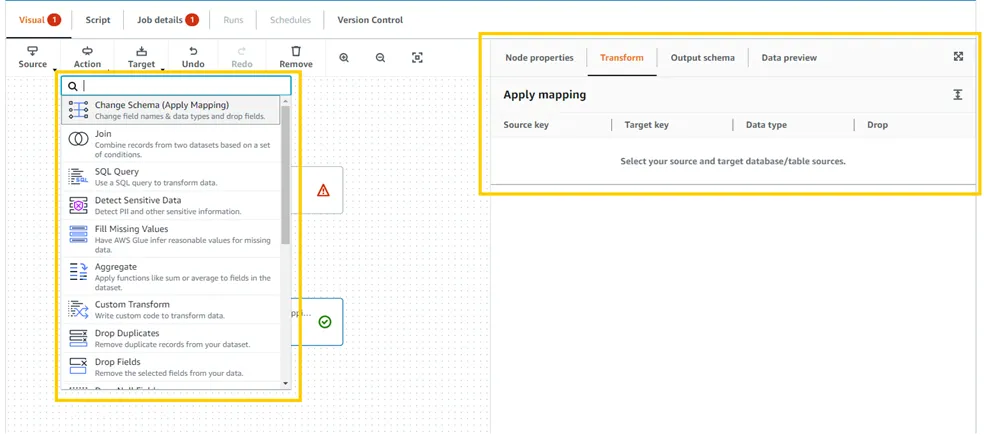
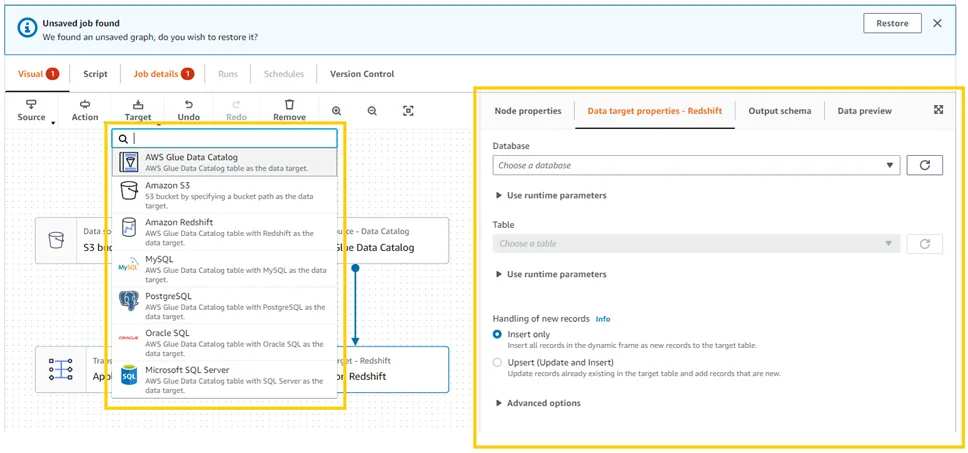
-
스크립트를 자동 생성. 수정이 가능하나 수정 후에는 다시 GUI로 돌아올 수 없음.
3-2. 코드로 작성하는 방법
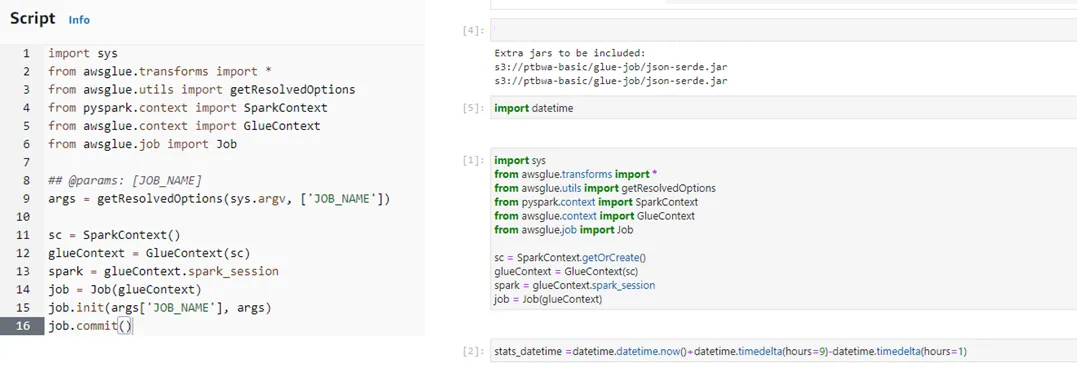
- 스크립트 코드 혹은 주피터 노트북으로 작성
- 주피터 노트북은
.show()혹은.display()로 데이터 카탈로그 확인 가능 - 북마크를 사용하려면 (이전 데이터는 여기까지 transform했다는 북마크)
- transform을 시작하기 전에
job.init(args['JOB_NAME'], args), transform 후에는job.commit()코드 추가 - spark.sql의 조건문을 사용한다면
job.init(args['JOB_NAME'], args)와job.commit()을 넣지 않는다.
- transform을 시작하기 전에

어쩌다보니 데이터쟁이