졸업작품을 만들면서 사용하고 있는 mobilenet모델에 대해서 설명하겠다.
mobilenet의 특징
- 경량화 네트워크
스마트폰, 자율주행자동차 같이 제한된 하드웨어 환경에서 따로 경량화를 시키지 않아도 딥러닝 어플리케이션에다가 적용할 수 있다.
경량화를 시켜도 성능이 좋고 정확도, 낮은 복잡도, 작은모델크기라는 특징을 가지고 있다.
Mobilenet은 경량화모델 중 하나로 small deep neural network 기법을 쓰고있다.
-depthwise seperable convolution은 대표적인 mobilenet에서 사용하고 있는 연산 중 하나다.
-width multiplier와 resolution multiplier를 통해 scale를 줄여 더 작은 네트워크를 만든다.
standard convolution 수행과정
먼저 일반 cnn에서 사용하는 convolution 연산 과정과 연산량에 대해서 알아 보겠다.
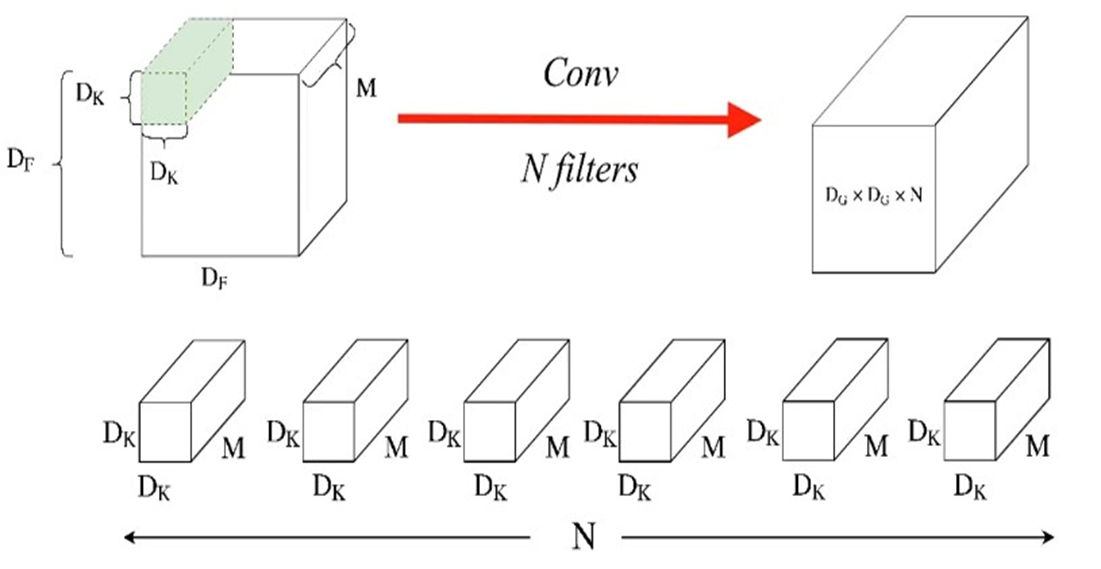 이 아키텍처는 필터의 수가 N개가 존재한다.
이 아키텍처는 필터의 수가 N개가 존재한다.
Input 크기 DfxDf 로 구성
채널의 수 M개로 구성
필터 크기 Dk x Dk
필터의 채널은 input 채널과 같고 따라서 M개이다.
Input이 필터와 convolution 연산을 하게 되면 채널이 1인 결과물이 나오게 되고 필터의 개수가 N이기 때문에 이를 쌓으면 아키텍처가 Dg x Dg x N인 출력층이 만들어진다.
standard convolution 연산량

mobilenet에서 이용하는 convolution 수행 과정
다음은 mobilenet에서 사용되는 convolution 연산 과정이다. 대표적으로 depthwise separable convolution이 수행되는데 두과정으로 세분화하여 depthwise convolution이 먼저 수행하고 그 다음 pointwise convolution이 수행된다.
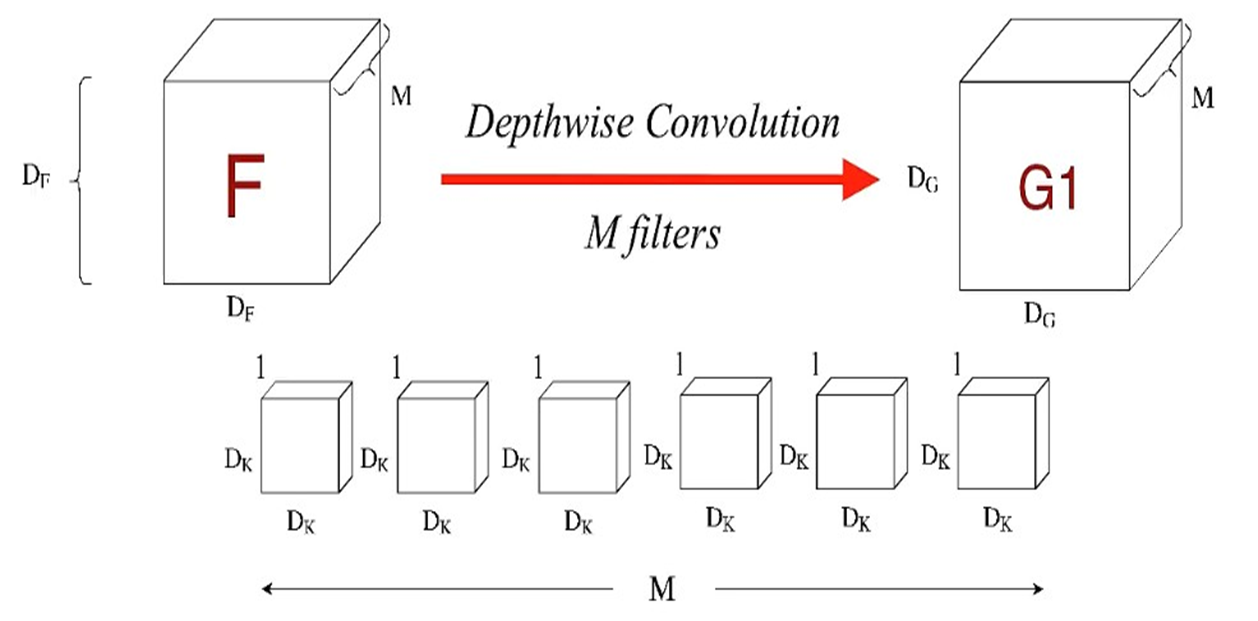
이그림은 depthwise convolution 수행 과정을 시각화한 것이다. 필터의 크기는 Dk x Dk이며 필터의 수는 M개 존재한다.
Input층 크기 Df x Df이고, 채널의 수는 M개로 구성되어있고 한 개의 필터가 input의 한 개의 채널에만 연산을 수행한다는점이 일반 convolution과 차이점이 있다. 따라서 Dk x Dk x 1의 필터가 M개 존재하고
연산을 수행하면 Dg x Dg x M 인 구조가 만들어진다.
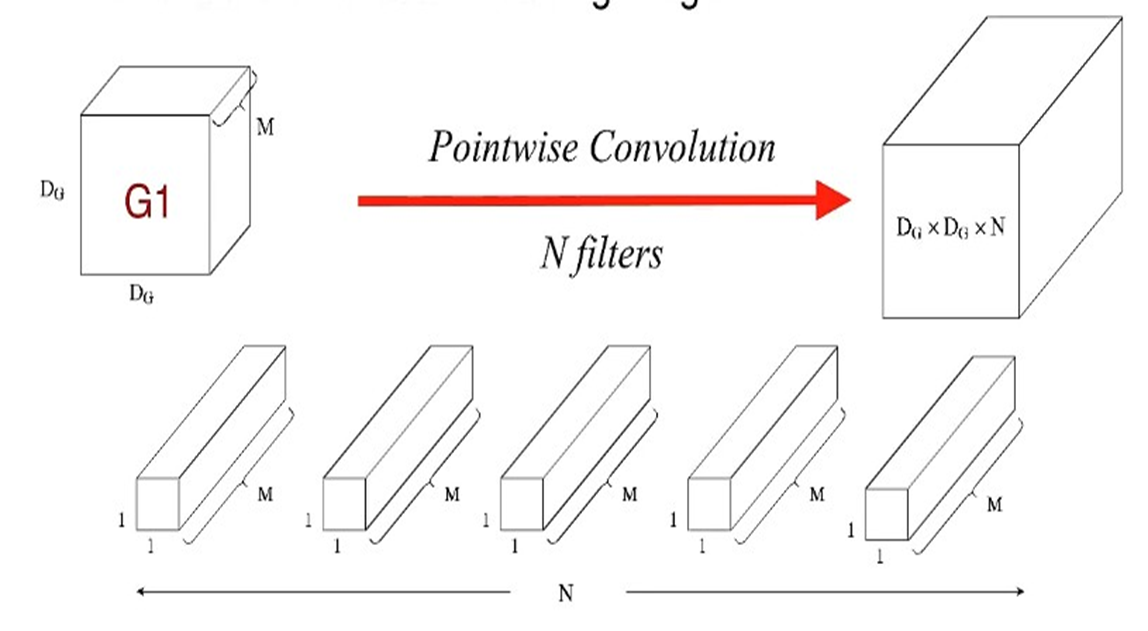
이 그림은 pointwise convolution 수행 과정을 시각화한 것이다. 이 과정에서 mobilenet의 identity가 뭍어나는데 크기가 1x1인 필터를 써서 출력된 결과를 쌓는다는 점이다. 다 쌓으면 standard convolution와 같은 출력층 Dg x Dg x N인 구조가 만들어진다.
Depthwise convolution 과정을 수행하면 구조가 Dg x Dg x M인 결과물이 만들어진다. 이후
Dg x DgxM 필터에 1x1xM 필터를 convolution을 하면 Dg x Dgx1인 결과가 만들어지고
위 모델은 N개의 1x1xM 필터가 있으므로 필터별로 convolution 수행 후 출력된 층을 쌓으면 Dg x DgxN인 구조가 만들어진다.
depthwise separable convolution 연산량
Depthwise convolution 연산량

Pointwise convolution 연산량
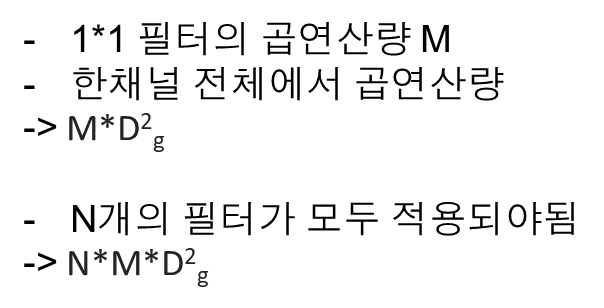
mobilenet의 내부구조
depthwise separable convolution의 이점
depthwise separable convolution과 standard convolution은 둘다 입력 레이어를 Df x Df x M 을 넣었을때 출력레이어의 크기는 Dg x Dg x N 가 된다는 공통점을 가지고 있다.
하지만 연산량을 비교해 보았을때 depthwise separable convolution가 비교적 작다는 특장을 가지고 있고 이로 인해 연산속도가 더욱더 빨라진다는 이점을 가지고 있다. 예를들어 depthwise separable convolution을 썼을 때 필터의 크기가 3, N은 1024 channel의 개수가 3개라면 1/9정도 연산량이 감소한다.
- standard convolution의 연산량
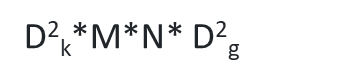
- depthwise separable convolution의 연산량
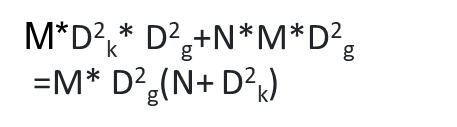
mobilenet의 아키텍처
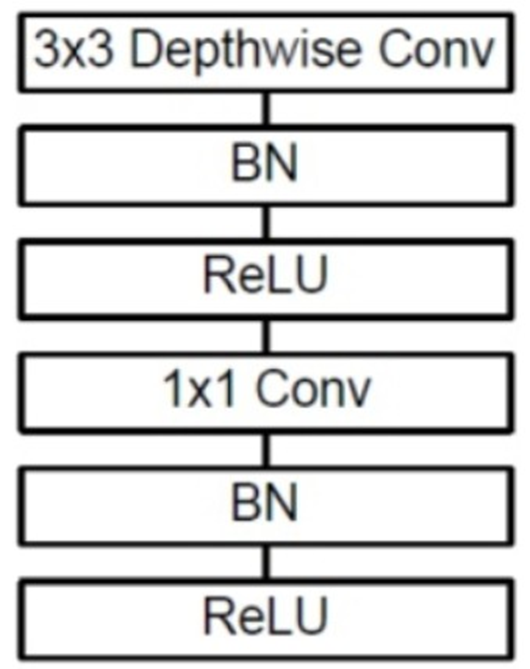
일반 cnn모델과 다르게 3 x 3 depthwise Conv(depthwise)와 1 x 1 Conv (pointwise) 연산이 순차적으로 실행이 되는 모습이다.
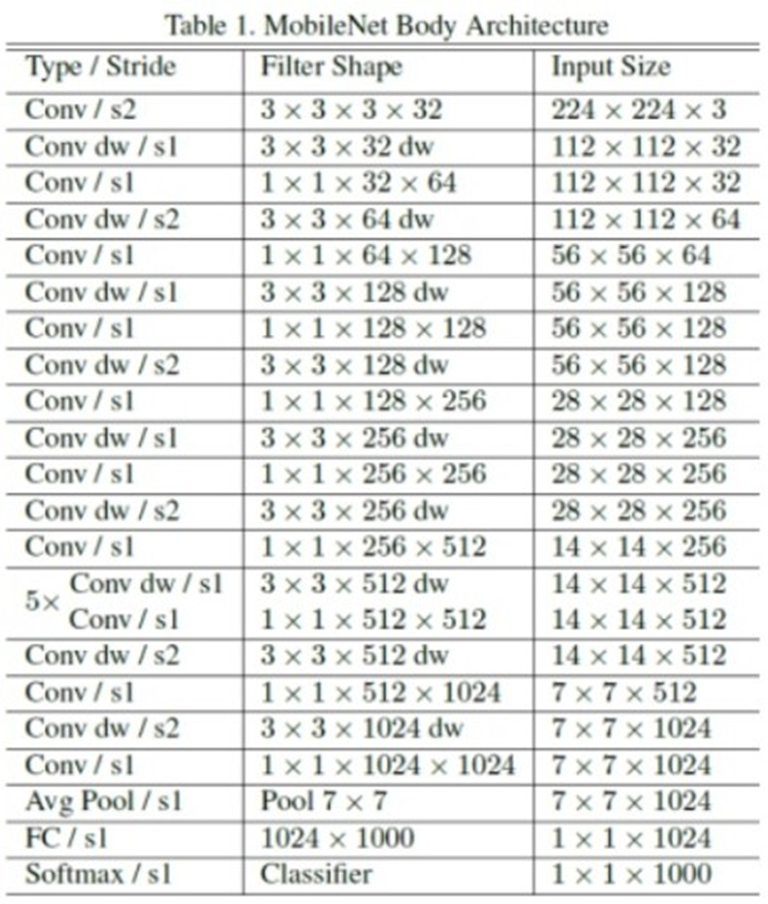
위 사진은 mobilenet의 전체 구조이다. cov dw는 depthwise convolution이고 1 x 1 conv필터는 pointwise convolution이다. s1/s2는 stride를 의미한다.
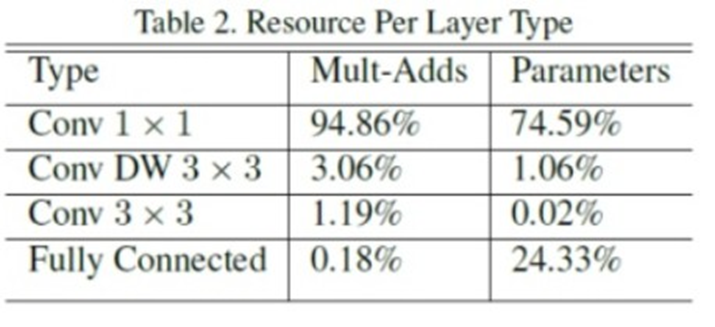
위 사진을 보았을때 일반적인 CNN모델에서는 fully connected layer의 파라미터가 많은 비중을 차지하지만 mobilenet에서는 1x1 pointwise convolution의 층과 파라미터 개수가 가장 많은 비중을 차지한다.
mobilenet에는 경량화 시키기 위해 width multiplier와 resolution multiplier를 사용해 scale을 줄이기도 한다.
- width multiplier
input과 output의 채널에 곱해지는 값으로 채널의 크기를 줄이기 위하여 사용되는 상수이다.
- resolution multiplier
input의 height와 width에 곱해지는 상수이다.
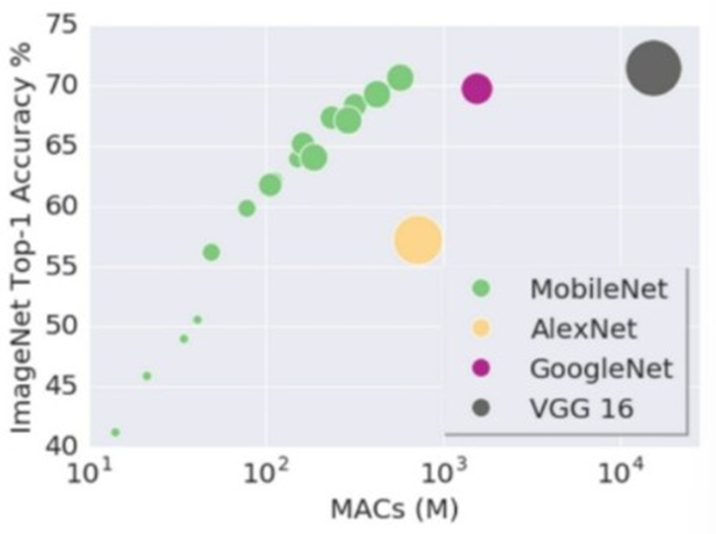
가로축은 연산량이고 세로축은 정확도이다. mobilenet의 정확도를 googlenet 수준으로 늘린다면 파라미터의 수가 늘어날 것이고 그로인해 연산량도 증가 할 것이다. 하지만 그래도 googlenet과 비슷한 정확도에 연산량이 작다는 장점이 있다.
경량화를 시켰기 때문에 성능과 연산량은 trade off관계가 발생되기는 한다.
하지만 다른 모델과 비교해보았을때(아래 표를 참조) 정확도가 크게 뒤쳐지지 않은 모습을 볼 수 있다.


즐겁게 읽었습니다. 유용한 정보 감사합니다.