semi- supervised learning이란?
전체 데이터 중 일부만 레이블 정보가 있는 상황에서 unlabeled 데이터를 함께 활용해서 학습하는 방법이다.
전체 데이터 N개중 일부 M개만 레이블 정보가 존재한다고 가정하고 레이블이 있는 데이터를 활용해서 각각 클래스를 분류하되 레이블이 없는 데이터도 학습과정에서 사용할 수 있도록 해서 결과적으로 성능을 향상시킨다.
레이블이 없는 데이터도 sementic한 특징을 가지고 있기 때문에 그러한 특징을 가지고 학습에 사용된다면 모델의 성능을 끌어올릴수 있을 것이다.
semi supervised learning 구조
레이블링 된 데이터와 레이블링 되지 않은 데이터를 같이 집어넣어서 학습하는 Consistent learning을 이용하며 학습과정에서 하나의 task를 활용하기 위해 unlabeled 데이터의 unsupervised loss와 labeled 데이터의 supervised loss를 더해서 학습한다.

저는 이번주에 TEMPORAL ENSEMBLING FOR SEMI - SUPERVISED LEARNING(ICLR 2017) 논문에서 Semi supervised learning을 이용한 두 가지의 모델 π-model과 temporal ensembling을 설명했는데 뭐가뭔지 간단히 읽어보았다.
π-model

xi에는 라벨링이 있는 데이터와 없는 데이터가 모두 섞여져 있으며 stochastic augmentation과정을 통해 원본 데이터를 가우시안 노이즈, 회전, 좌우반전, 확대 축소를 해서 적절히 변형시킨다. 그리고 모델의 과적합을 방지하기 위해 dropout과정을 거친다.
yi는 라벨링이며 xi에서 라벨링이 있는 데이터에 대해서만 cross entropy loss를 계산하고 전체 데이터에 대해서 squared difference loss를 계산한다.
두개의 augmentation을 수행한 데이터에 대한 정보는 인간은 알고 있지만 모델은 모르기 때문에 다른 결과를 내보낼 수 있는데 이때 squared difference는 두개의 결과를 서로 같아질 수 있게 업데이트 하는데 방향성을 잡아주고 레이블이 없는 이미지에서도 representation을 학습할 수 있도록한다. squared difference는 consistenting training 중 한 방법으로 라벨링 되어있지 않는 데이터를 모델 학습에 활용할 수 있도록 한다. 이때 데이터의 segmentic feature한 부분을 추출하여 입력이나 feature에 노이즈가 입력되어도 모델의 결과가 consistent하도록 만든다. 많은 양의 unlabeled data가 있을수록 더 강력한 효과를 누릴 수 있을것이다.
loss를 계산할때 cross entropy loss와 squared difference loss을 합해서 구하는데 이때 에포크에 따라 변화하는 가중치를 곱해서 계산한다. 초반에는 가중치 값이 0이며 labeled data를 중점적으로 학습한다. 아무리 좋게 설계된 semi- supervised 모델이라도 labeled data의 충분한 학습이 안되어 있으면 좋은 성능을 기대하기 힘들다. 따라서 가중치는 충분히 천천히 학습하도록 설정되었다.
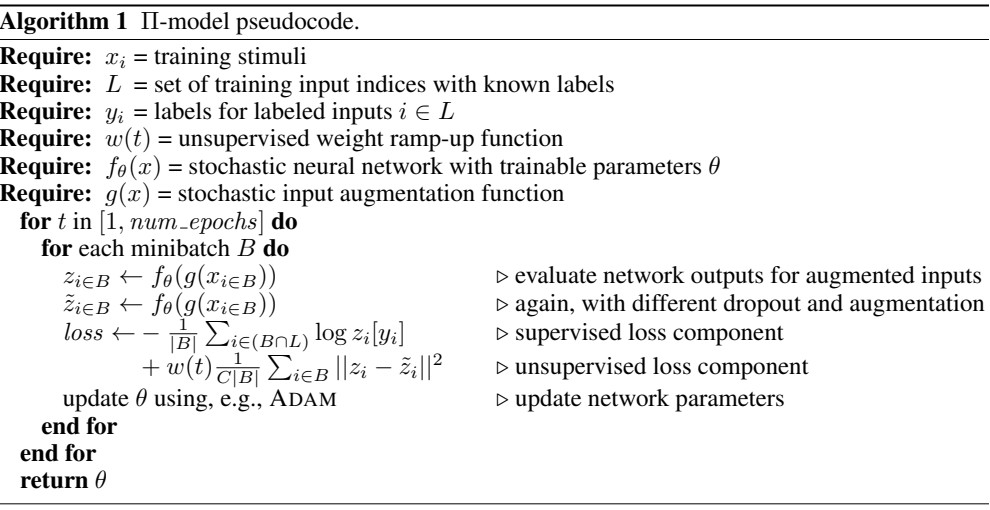
위에서 설명한 π-model 구조를 pseudocode를 통해 나타냈다.
Temporal ensembling
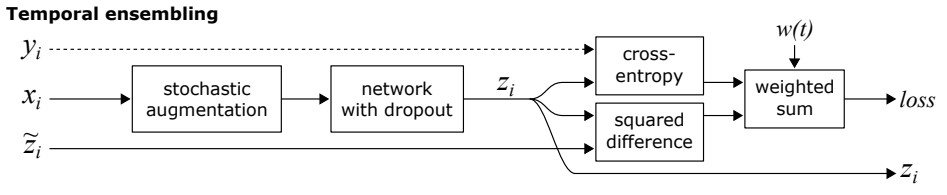
위에 π-model과 유사하지만 π-model같은 경우는 입력이미지에 augmentation을 수행한 Z햇 경우 dropout를 거치고 바로 single eval으로 계산되기 때문에 noisy하다는 단점을 가지고 있다.
temporal ensembling은 각각 이미지에 대해서 이전까지 prediction을 종합한 값인 Z햇이 사용된다. 따라서 π-model에서 사용한 z햇보다 훨씬 덜 noisy하다는 특징을 가지고 있다. 그리고 저장된 z햇을 사용하기 때문에 추가적인 augmentation과정과 dropout과정을 거치지 않아도 된다는 장점(속도 증가)을 가지고 있다. 하지만 이전까지 수행한 결과값을 저장해야 되서 별도의 저장 공간이 필요하다는 단점을 가지고 있다.
각 epoch마다 예측한 결과를 종합해서 사용하며 ensemble prediction을 한다. 이러한 ensemble효과 덕분에 뛰어난 성능을 보인다.

알파는 이전까지의 결과를 얼마나 사용할지 결정하는 momentum parameter인데 0에 가까울수록 현재의 결과, 1에 가까울수록 이전까지 결과를 더 많이 활용한다.
결과분석
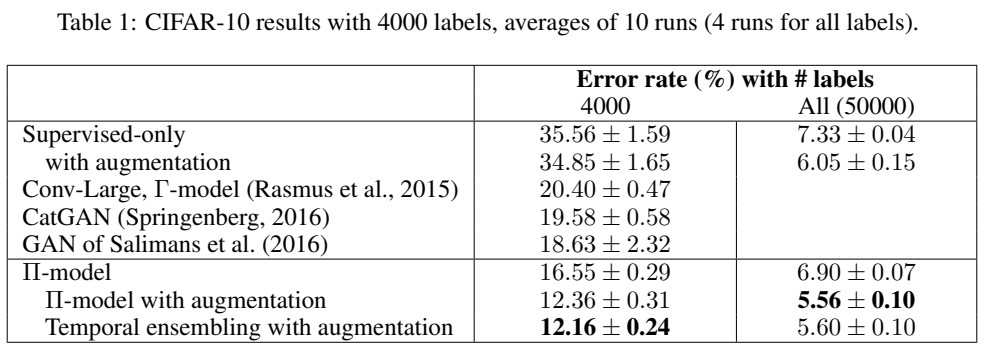
CIFAR-10데이터셋 중에서 라벨링이 있는 4000개, 그리고 전체 데이터 50000개를 학습했을때 error rate를 비교한 모습인데 semi supervised model이 성능이 높았음을 볼 수 있다.
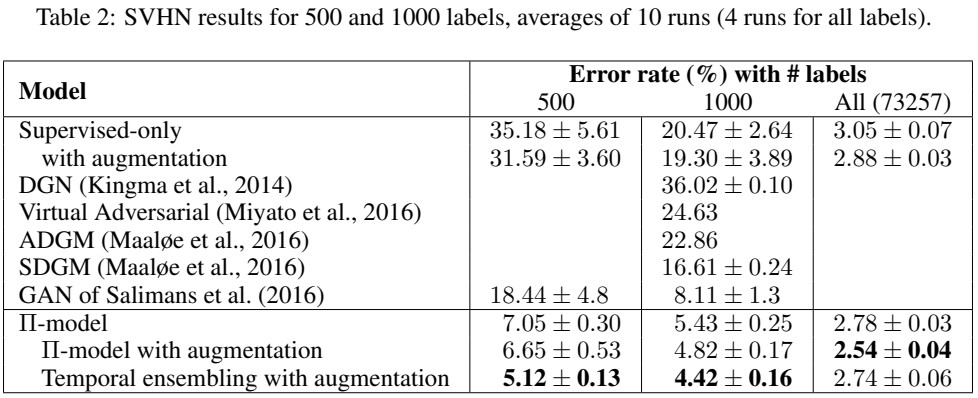
SVHN데이터셋에서 라벨링이 있는 데이터 500개 1000개 그리고 전체 데이터를 학습했을때 error rate를 비교했는데 semi supervised model 성능이 매우 우수했다.
