Introduction
너희 강아지가 세계 방방곡곡을 여행 할 수 있을까?
너가 최고로 아끼는 가방이 파리에 있는 최고급 showroom에 전시될 수 있을까?
너가 키우는 앵무새가 만화책의 주인공이 될 수 있을까?
최근 계속해서 발전하고 있는 large text to image model은 전례없이 높은 퀄리티의 사진과 text prompt에 따라서 다양한 사진을 생성한다.
t2I model은 학습된 image-caption pair에 따라 subject의 다양한 자세와 contexts를 취할 수 있다.
하지만 이렇게 뛰어난 이미지 생성모델도 학습된 context외의 다른 contexts에 대한 renditions이 떨어지고 주어진 reference set에 대한 subject의 표현 능력이 떨어진다는 단점이 있다. 주된 이유는 output domain의 표현력이 한정적이기 때문이다. 심지어 자세히 설명된 subject라도 전혀 다른 인스턴스를 생성할 수 있다.
이 dreambooth는 personalization에 대해 이전 논문과는 다른 새로운 접근법을 내세웠다. input 이미지를 넣으면 우리가 원하는 이미지로 generation 하거나 다른 포즈, 다른 배경에서도 이미지를 생성할 수 있다.

figure1을 보면 강아지를 아크로폴리스로 여행보낼수 있고 수영하거나 자는 모습을 generation 하는 등 원하는 동작으로 text prompt에 따라 바꿀 수 있다.
우리가 원하는 이미지로 바꾼다 해서 custom image라고 부를 수 있다.
Method
Text to Image Diffusions Models
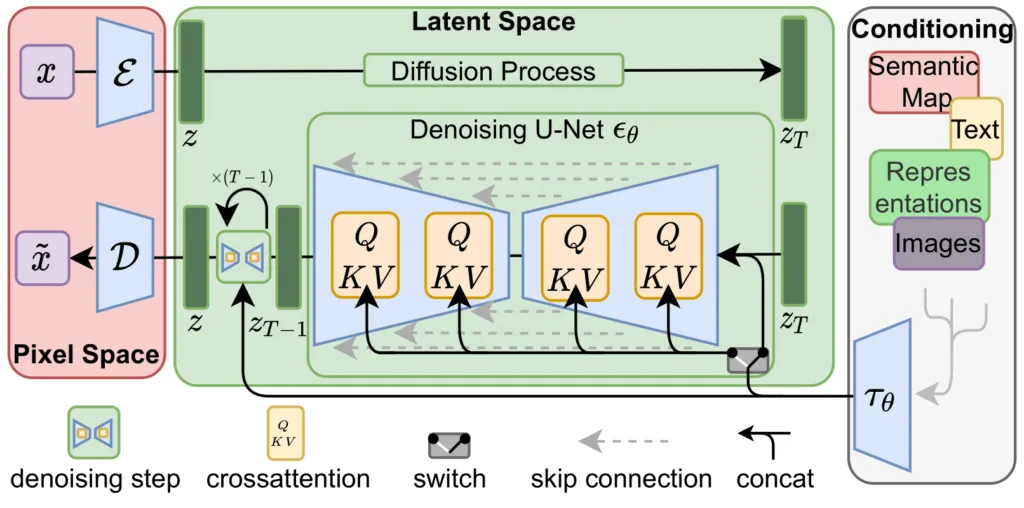
디퓨전모델은 가우시안 노이즈에서 점차 denoising 과정을 통해 data distribution을 학습하도록 trained된 probabilistic generation 모델이다.
loss function은 다음과 같다.
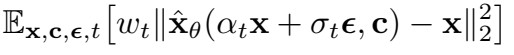
여기서는 text conditioning을 이용한다. loss식에서 c는 conditioning vector이며 이때 text encoder를 이용하여 text prompt를 인코딩한다.
Personalization of Text to image models
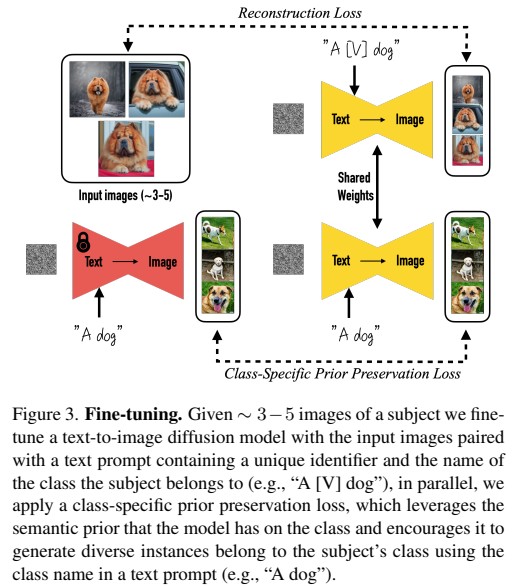
대략 3~5개정도 되는 input image에 fine tuning을 진행을 한다.
Designing Prompts for few shot personalization
우리가 원하는 dog을 생성하도록 a [identifier][class noun] 즉 "a [v] dog" 이렇게 라벨링을 한다. v자리에는 이미 prior된 단어가 들어간다면 이미지 생성이 망가질 수 있기 때문에 안쓰는 단어를 사용해야된다. 하지만 안쓰는 단어를 사용하더라도 한 단어가 아닌 여러 단어가 쪼개져서 tokenize될 수 있고 쪼개진 단어가 prior된 단어가 될 수 있기 때문에 상대적으로 길이가 1~3정도 되는 rare token을 생성한다. 예를 들어 'a sys dog' 이런식으로 말이다.
Class-specific Prior Preservation Loss
a sys dog을 넣고 파인튜닝을 했을때 dog는 잘 생성이 되지만 다른 subject를 generation할 때는 prior가 잘 보존되지 않는다는 문제가 생긴다. few shot을 사용 해서 fine tuning 했기때문에 오버피팅같은 문제점이 나타나는데 이때 어떻게 prior를 보존할 수 있을까?
prior에 관한 문제는 reduced output diversity, language drift가 있는데 language drift는 target subject와 같은 class를 생성할때 점차 지식을 잃어간다는 뜻이다. 따라서 reduced output diversity현상으로 오버피팅이 나타난다.
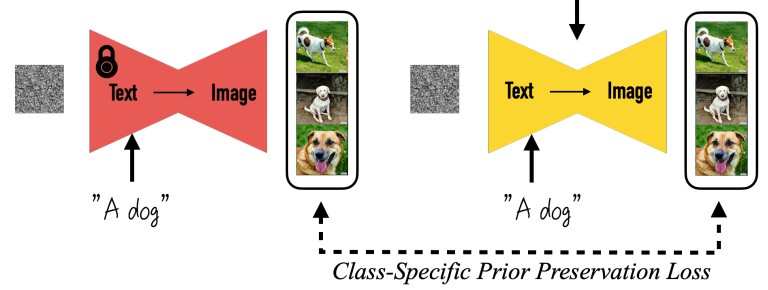
따라서 기존의 diffusion model에서 a dog라고 입력했을때 생성되는 이미지랑 fine tuning한 모델에서 a dog라고 입력했을때 생성되는 이미지의 Prior Preservation Loss를 비교해서 학습한다.
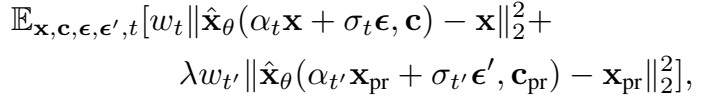
이 논문에서는 람다를 1로 두고 1000 iteration을 돌렸을때 최고의 성능이 나온다고 증명했다.
dreambooth같은 경우 fine tuning하다보니 굉장히 시간이 오래걸린다는 단점이 있다.
