이번주에는 controlnet에 관련해서 논문을 읽고 리뷰해보았다.
controlnet의 특징
- 사전학습된 large text-to-image diffusion model 파라미터를 복사하고 encoding layer를 재사용하여 다양한 conditioning을 추가하기 위한 신경망 아키텍처이다.
- zero convolution layer를 사용하여 fine tuning을 하는데 harmful noise가 들어가는것을 막아준다.
- small(<50k) dataset, large(>1m) dataset에서도 robust하다는 특징이 있다.
- 기존의 image diffusion model에 덧붙여 다양한 분야에 적용될 수 있다.
- end to end 구조이다.
- personal device에 training 할 수 있다.
기존의 text to image diffusion 모델은 specific하고 고차원적인 상황을 해결하기 어려웠다. controlnet은 이에 맞써 diverse한 conditional control이 가능하도록 한다.
model 구조
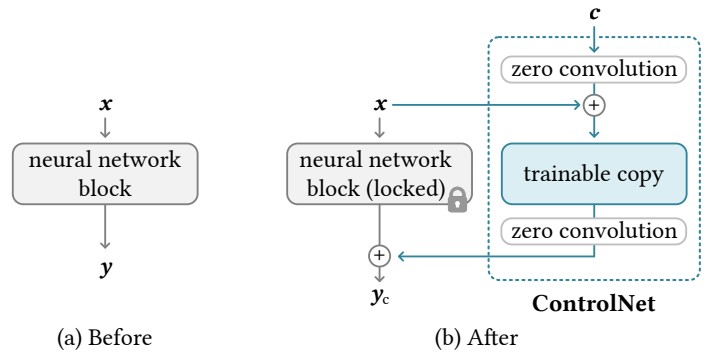
(a)는 stable diffusion model의 한 블록이고 (b)는 controlnet의 구조를 표현한 것이다. 기존 diffusion model의 파라미터는 변하지 않게 고정되어 있는 locked copy 이고 new parameters는 conditional control을 위해 여러 specific한 데이터셋에 학습시키기 위한 파라미터이고 trainable copy이다. 위의 c는 Canny edges, Hough lines, user scribbles, human key points,
segmentation maps, shape normals, depths 같은 conditional input이다.
copy를 만들어서 데이터셋의 오버피팅을 방지하고 production ready quality를 유지한다.
zero convolution
1x1 convolution layer가 2개 있는데 처음의 layer는 weight와 bias를 0으로 초기화한다. 결국은 초기엔 pre trained된 diffusion model의 입출력 관계와 controlnet에 의한 입출력 관계가 차이가 없어지게 된다.
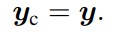
이에 따라 harmful noise에 영향을 받지 않게 되며 사전 학습된 모델의 기능을 그대로 유지하면서 동시에 추가적인 learning을 위한 강력한 backbone 역활을 하게 된다.
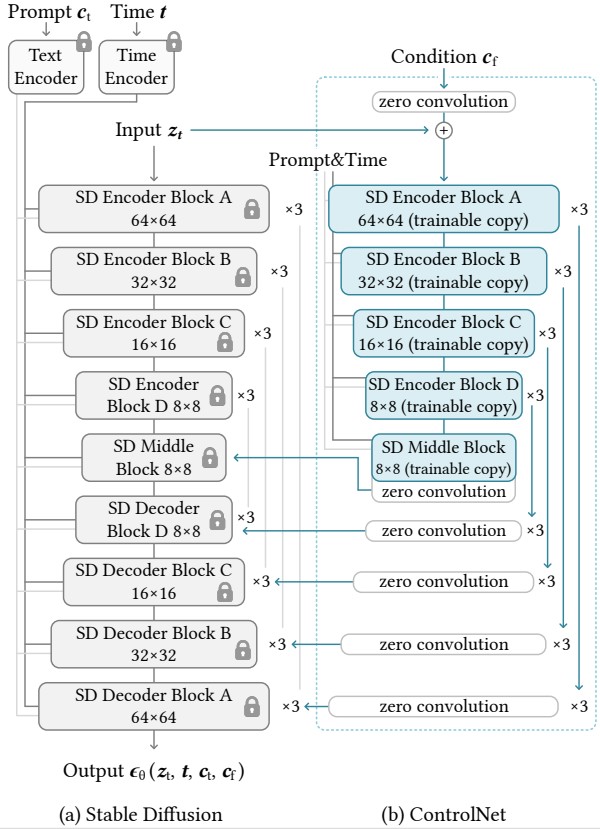
U-Net 구조에 각 단계마다 controlnet을 사용한 모습이다.
encoder block 12개, middle block 1개, decoder block 12개 총 25개의 블록이 있으며 8개의 블록에는 업샘플링이나 다운샘플링층이 있으며 17개 블록에는 4개의 resnet층과 2개의 vision transformer가 있다. 각각의 Vit에는 cross attention, self attention 매카니즘이 사용된다.
encoder는 resolution을 64x64 32x32 16x16 8x8로 줄어든다.
처음에 weight와 bias가 0이였던것이 점차 진행하면서 업데이트 되기 시작한다. text prompt는 CLIP text encoder을 사용했으며 diffusion time step은 positional encoding을 사용해서 인코딩되었다.
locked copy 파라미터로 인해 fine tuning하는데 no gradient computation해서 학습하는데 속도도 빠르고 계산이 굉장이 효율적이다는 장점이 있다. 기존 stable diffusion모다 23%의 GPU memory를 절약했다.
training
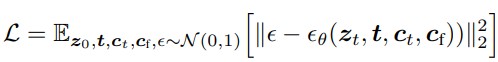
z0 :input image, zt : noisy image, ct : text prompts, cf :task specific conditions, t: timestep,ε: to predict the noise added to the noisy image
loss 함수는 기존 stable diffusion loss function에 task specific condition만 추가된 형태가 된다.
