내가 네부캠을 진행하면서 했던 최종 프로젝트의 이름은 Code Clash이다. db 조회 성능이 얼마나 나오는지 측정하는 데에 시간이 없어서 6주간 하지 못했는데, 네부캠 과정에 다 끝나고 나서 할게 없어서 한번 해보려고 한다.
우리는 자주 사용하는 api가 특정 문제에 대한 정답률을 가져오는 api인데, 그 api는 submission 테이블에 대해서 problem과 left join한 후, 특정 문제에 대해 필터링한 후 submission.status로 그룹화하여 그 갯수를 가져온다. 그리고, 그것을 클라이언트에게 응답해준다. 만약, submission이 엄청나게 쌓이면 여기서 병목이 일어날 것이리라 판단했고, problem에는 약 30만개의 row가,submission 테이블에 row가 100만개가 있다고 가정하고 테스트 및 조회 성능 개선을 해보려고 한다.
더미데이터 넣기
테스트를 하기 위해선 테이블에 더미데이터를 넣어야 한다. 넣는 방법은 검색하면 매우 쉽게 알아낼 수 있다.
우선 submission table에 더미 데이터를 넣어보겠다.
DELIMITER $$
DROP PROCEDURE IF EXISTS loopInsert$$
CREATE PROCEDURE loopInsert()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 1000000 DO
INSERT INTO submission(user_id, problem_id, status, language, code)
VALUES(1, 8, 'Wrong Answer', 'javascript', 'function solution() { now() }');
SET i = i + 1;
END WHILE;
END$$
CALL loopInsert$$
DELIMITER ;그리고 problem table에 더미 데이터를 넣어보자.
DELIMITER $$
DROP PROCEDURE IF EXISTS loopInsert$$
CREATE PROCEDURE loopInsert()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 300000 DO
INSERT INTO problem(title, time_limit, memory_limit, sample_code, description)
VALUES( concat('dummy', i), 1000, 256, 'function solution()', concat('dummy data', i));
SET i = i + 1;
END WHILE;
END$$
CALL loopInsert$$
DELIMITER ;이렇게 프로시져를 만들어서 그 프로시저를 실행하면, 더미데이터를 쉽게 생성할 수 있다. 이렇게 해서 더미데이터를 넣어보자.
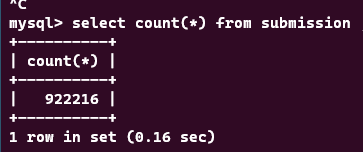
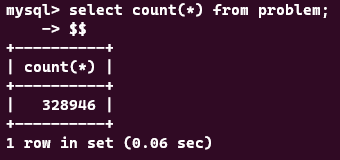
submission에는 대략 100만개의 데이터가, problem에는 30만개의 데이터가 들어간 모습이다.
성능 측정
select p.title, s.status, count(s.status) as 'count'
from submission as s
left join problem as p on s.problem_id = p.id
where p.id = 8
group by s.status위의 쿼리를 실행한 결과
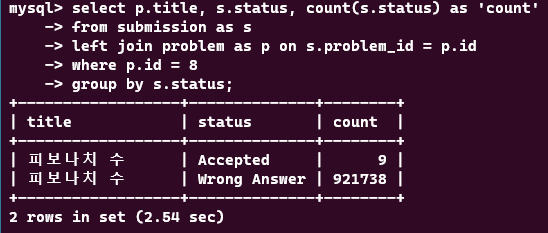
약 2500ms 응답 시간이 걸렸다. explain 구문으로 쿼리를 분석해보았다.

한 문제에 대해서 이름과 정답률을 가져오는 데에 너무 많은 시간이 소요된다고 생각하기 때문에 이 부분을 개선해야 한다.
개선
submission의 status 칼럼은 조회가 자주 일어나는 반면, 수정, 삭제는 거의 일어나지 않는다. 따라서 해당 칼럼(status)를 인덱싱하고 Join을 없애는 역정규화 기법을 통해 성능 개선을 시도해보았다.
Join을 없애기 위해서 해당 문제의 이름을 가져오는 쿼리하고, 그 문제에 대해서 정답률을 가져오는 쿼리를 분리하였다.
문제의 이름 가져오기
select p.title
from problem as p
where p.id = 8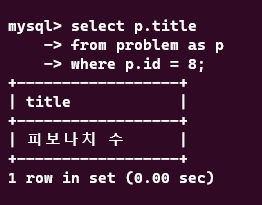
문제의 이름을 가져오는 데에 걸리는 시간을 측정해보았다. 문제의 title은 unique하기 때문에, 유니크 인덱싱이 되어있는 상황이고, index unique scan을 통해 엄청나게 빠르게 쿼리를 수행하는 것을 볼 수 있다.
문제의 정답률 가져오기
그리고, 해당 문제의 정답률을 가져와보자.
select count(s.status) as 'acceptedCount'
from submission as s
where s.problem_id = 8 and s.status = 'Accepted';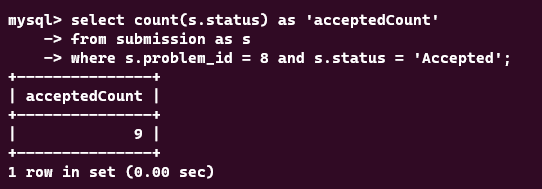
맞은 횟수를 가져오는 쿼리이다 status에 인덱싱을 걸고나서 얼마나 걸리나 테스트해보았다. status에 인덱싱이 되어있지 않았을 때는
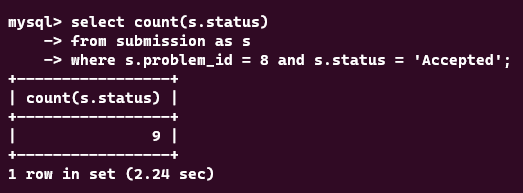
이정도의 시간이 소요되었는데, 아마 where 절에서 인덱싱이 되어있지 않은 칼럼을 넣으니, full scan이 되어 시간이 오래 걸린 것 같다. 인덱싱을 걸어서 Covering Index를 만드니, 엄청나게 시간이 감소된 것을 볼 수 있다.
이제 전체 제출 횟수를 구하는 쿼리를 작성해보자.
select count(*) as 'totalCount'
from submission as s
where s.problem_id = 8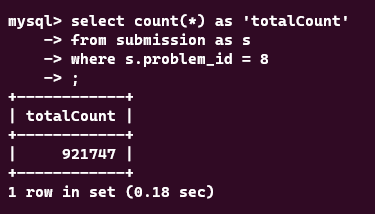
위의 쿼리의 소요시간이 이정도 나왔다. 이 쿼리는 매번 날릴 필요 없이, 인메모리에 캐싱해서 사용하면 훨씬 좋을 것 같다. 최초 1회시에만 쿼리 날리고, 그 다음부터는 어디 변수에 저장해서 사용하면 될 것 같다.
결론
처음에 submission.status 칼럼에 인덱싱을 걸지 않고, join하여 쿼리를 수행한 결과 2500ms의 시간이 걸린 반면, submission.status에 인덱싱을 걸고, 역정규화 기법을 통해 join을 다 풀어버린 다음 쿼리들을 날린 결과 총 대략 200ms의 시간이 걸렸다(만약 전체 제출 횟수 쿼리를 캐싱한다면, 대략 1ms). 엄청난 성능 향상을 볼 수 있다.
나도 이정도로 향상될 줄은 몰랏는데, 인덱싱과 역정규화가 이렇게 성능 향상에 도움이 되리라고는 상상도 하지 못했다 ㄷㄷ..
full scan과 index range scan의 엄청난 차이를 체감할 수 있는 계기가 된 것 같다. Covering Index를 만드는 것이 이렇게 중요하다니... 잘 짚고 넘어가도록 하자.
