BART: Denoising Sequence-to-Sequence Pre-training for NaturalLanguage Generation, Translation, and Comprehension
Paper Review - NLP

Abstract
BART는 seq2seq 모델을 사전 훈련시키기 위한 denoising autoencoder(DAE)
(1) noising funcion으로 corrupt시키고 (2) original text로 복원 하도록 학습되어짐.
standard Transformer를 기반으로 한 neural machine translation 구조를 사용하여 단순함 + BERT(bidirectional encoder), GPT(left-to-right decoder)와 최근의 다양한 사전 훈련 기법들을 일반화하는데 사용할 수 있음
많은 noising approach에 대해 평가하는데, 원래 문장의 순서를 섞고 text span을 단일 마스트 토큰으로 대체하는 in-filling 기법을 사용해서 최고의 성능을 찾음.
BART는 텍스트 생성을 위해 fine-tuning할 때 특히 효과적이며 comprehension task에서도 잘 작동함.
Introduction
Self-supervised(자기 지도) method는 많은 NLP task에서 성공적이었음.
가장 성공적인 접근 방식은 MLM(Masked Language Models)의 변형으로, 랜덤한 단어의 일부가 masking 처리된 text를 재구성하도록 훈련된 denoising autoencoder임.
최근 masking된 토큰의 분포, masking된 토큰의 순서 예측, masking된 토큰을 대체할 수 있는 context를 개선함으로써 발전함. 그러나, 이러한 방법들은 span prediction, generation와 같은 end task에만 집중해서 applicability을 제한함.
BART는 Bidirectional and Auto-Regressive Transformer를 결합한 모델을 사전 훈련함. seq2seq 모델로 구축된 denoising autoencoder로 다양한 end task에 적용할 수 있음.
(1) noising funcion으로 corrupt시키고 (2) original text로 복원의 두 단계로 사전 훈련됨. BART는 standard Transformer 기반의 neural machine translation 구조를 사용하는데 간단함에도 불구하고 BERT, GPT 및 다양한 사전 훈련 기법을 일반화하는 데 사용되어질 수 있음.
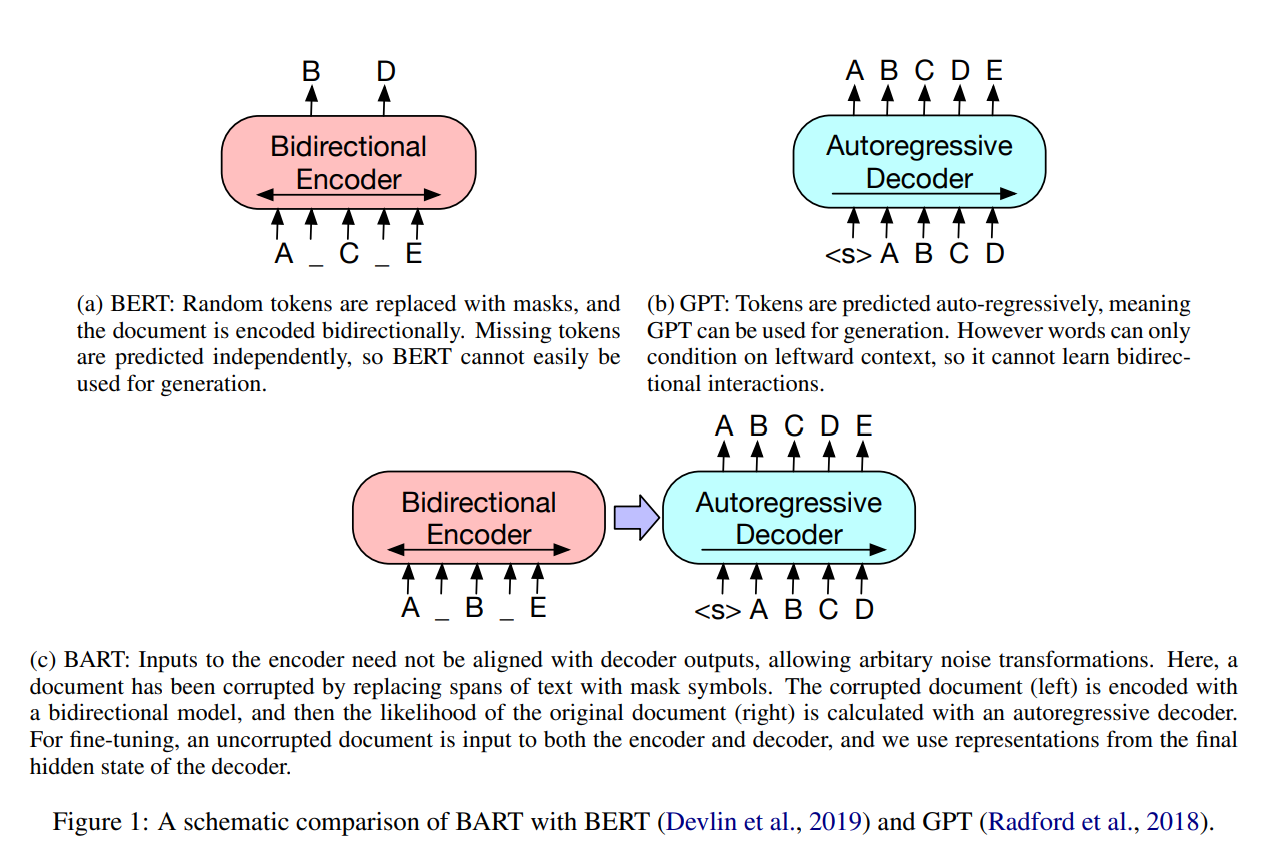
BART의 주요한 장점은 noising flexibility → 원래 text에 임의의 변형을 적용할 수 있고, 길이를 변화시킬 수도 있음.
다양한 noising approach를 평가하였고 원래 문장의 순서를 랜덤하게 섞고 새로운 in-filling기법(text span을 mask token으로 대체)을 사용하는 것이 가장 좋은 성능을 보였음. 이 접근 방식은 BERT의 original word masking과 next sentence prediction을 일반화시킴으로써 모델이 전체 길이의 문장을 추론하고 input에 더 긴 변형을 수행하도록 함.
Model
BART는 corrupted document를 원래의 상태로 매핑해주는 denoising autoencoder임.
seq2seq 모델로 구현되었는데, corrupted text에 대한 bidirectional encoder와 left-to-right autoregressive decoder로 되어있음. 사전 훈련을 위해서 original document의 negative log likelihood을 최적화함.
Architecture
BART는 standard seq2seq Transformer 구조를 사용함. decoder에서는 GPT에서 사용하는 ReLU가 아니라 GeLU를 사용하는 것으로 바꾸고 파라미터 초기화는 N(0, 0.02)로 함.
BART base에서는 encoder와 decoder 각각 6개의 layer 사용 / BART large에서는 encoder와 decoder 각각 12개의 layer 사용
구조는 BERT에서 사용한 것과 비슷하지만, 차이점이 2가지 있음.
(1) decoder의 각 layer가 encoder의 최종 hidden layer와 cross-attention수행 (Transformer와 동일)
(2) BERT는 word prediction 전에 FFN을 추가로 사용하지만, BART는 사용하지 않음.
→ BERT보다 파라미터를 약 10% 더 가지게 됨. (decoder에서 cross-attention을 수행하는 layer 추가)
Pre-training BART
BART는 document를 corrupt하고 decoder의 output과 original document와의 cross entropy인 reconstruction loss를 최적화하는 식으로 훈련되어짐.
기존의 특정 noising scheme에 맞춰진 denoising autoencoder와 다른 것은 BART는 어떤 document corruption이라도 적용할 수 있다는 점임. 극단적인 경우에 source에 대한 모든 정보가 없는 상태더라도 BART는 원래 언어 모델과 동일하게 동작할 수 있음.
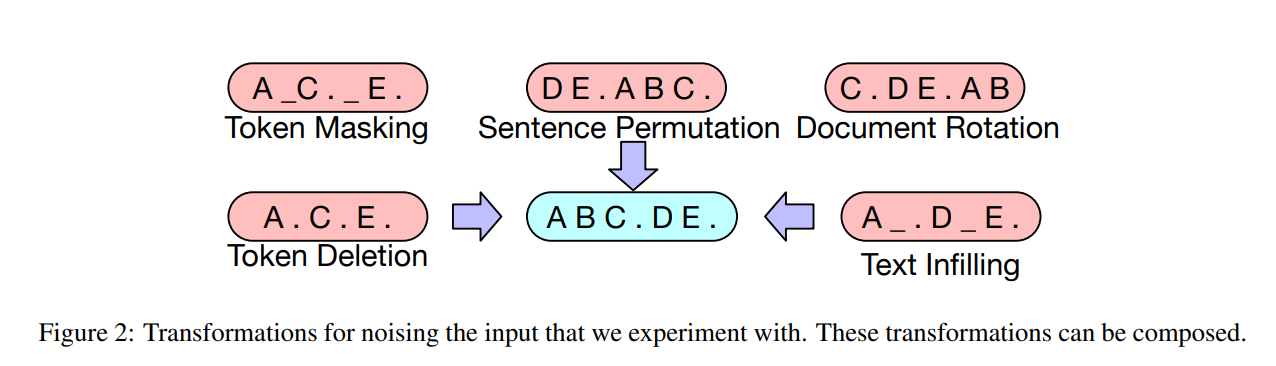
Token Masking
BERT와 마찬가지로 랜덤한 token들이 샘플링되어 [MASK]로 대체됨.
Token Deletion
랜덤한 token들이 input으로부터 제거됨. token masking과 다르게 모델이 missing input의 위치를 결정해야 함.
Text Infilling
여러 개의 text span이 샘플링되어 지고, span의 길이는 포아송 분포(λ = 3)를 따름. 각 span은 단일 [MASK] 토큰으로 대체됨. 0-length span도 [MASK] 토큰이 입력될 수 있음. Text Infilling은 SpanBERT에서 영향을 받았는데, SpanBERT는 서로 다른 분포에서 span length를 샘플링하고 각 span을 같은 길이의 [MASK] 토큰 시퀀스로 대체함. Text Infilling은 모델이 하나의 span에서 얼마나 많은 토큰이 없어졌는지 예측하는 방법을 학습시킴.
Sentence Permutation
document는 마침표를 기준으로 문장이 나눠지고 문장은 랜덤한 순서로 섞여짐.
Document Rotation
token이 랜덤하게 균일한 확률로 선택되고 document가 해당 토큰으로 시작되도록 회전되어짐. document의 시작 부분을 찾을 수 있게 훈련됨.
Fine-tuning BART
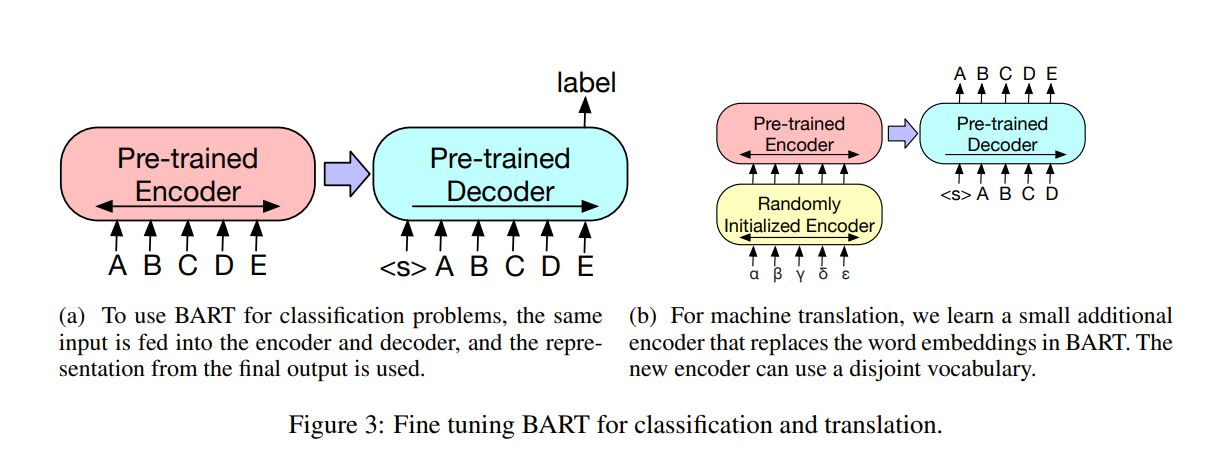
✅ Sequence Classification Tasks
sequence classification task를 위해 encoder와 decoder에 같은 input이 들어가고 마지막 decoder의 마지막 hidden state는 새로운 multi-class linear classifier에 들어감. 이 접근 방법은 BERT에 CLS token과 관련되어 있는데, 여기서는 마지막에 추가적인 토큰을 더하여 decoder에 해당 토큰(마지막에 추가한 토큰)의 representation이 전체 input으로부터 decoder state에 attention 할 수 있도록 함.
✅ Token Classification Tasks
token classification task를 위해 complete document를 encoder와 decoder에 입력으로 하고, 각 단어에 대한 representation으로 decoder의 가장 위의 hidden state를 사용함. 이 representation은 토큰을 분류하는데 사용됨.
✅ Sequence Generation Tasks
BART는 autoregressive docoder이기 때문에 abstractive QA와 summarization 같은 sequence geration task에 대해 직접적으로 fine-tuning할 수 있음. 이러한 task에서 정보는 input에서 복사되어지지만, 조작(manipulated)되는데 denoising pre-training objective와 관련되어있음. encoder input은 input sequence이고 decoder는 ouput을 autogressive하게 생성함.
✅ Machine Translation
BART를 사용하여 영어로 번역하는 machine translation decoer를 개선하는 것을 탐구함.
이전 연구에서는 pre-trained encoder를 통합해서 모델이 개선되었지만, decoder에 pre-trained language model을 사용하는데서는 제한된 효과만 얻음.
BART 전체 모델로 machine translation을 위한 single pretrained decoder로 사용할 수 있음을 보여주었고, bitext로 학습된 새로운 encoder parameter를 추가함.
BART의 encoder embedding layer를 새로 랜덤하게 초기화된 encoder로 변경함. 이 모델은 end-to-end로 학습되며 새로운 encoder를 학습시키는 것으로 외래어를 BART가 영어로 de-noise할 수 있는 input으로 매핑하도록 함. 새로운 encoder는 원래 BART 모델과 다른 별도의 vocabulary를 사용할 수 있음.
두 단계로 source encoder를 훈련하는데, 모두 BART 모델의 ouput으로부터 cross-entropy를 역전파함.
첫 번째 단계에서는 대부분의 BART parameter들을 고정하고 랜덤하게 초기화된 source encoder, BART positional embedding, BART encoder 첫 번째 layer의 self-attention input projection matrix만 업데이트함.
두 번째 단계에서는 모든 모델 parameter를 작은 수의 iteration으로 학습함.
Comparing Pre-training Objectives
BART는 이전 연구보다 pre-training 동안 더 넓은 범위의 noising 방식을 지원함.
Comparison Objectives
훈련 데이터, 훈련 자원, 모델 간의 구조적 차이, fine-tuning 절차의 차이로 인해 공정한 비교가 어려웠음.
최근 제안된 강력한 pre-training approach들을 discriminative와 generation task에 맞게 다시 구현함.
가능한 pre-training objective와 관계없는 차이들을 통제하고자 했지만, 성능 향상을 위해 학습률과 layer normalisation을 최소한으로 변경했음.
Language Model
GPT와 유사하게 left-to-right Transformer language model을 훈련함. 이 모델은 cross-attention을 수행하지 않은 BART decoder와 동일함.
Permuted Language Model
XLNet에 기반하여 1/6의 토큰을 샘플링하고 랜덤한 순서로 autoregressive하게 생성함. 다른 모델들과 동일하게 XLNet에서 수행한 relative positional embedding 또는 attention across segment를 구현하지 않았음.
Masked Language Model
BERT를 따라서 토큰의 15%를 [MASK] 처리하고 독립적으로 원래 토큰을 예측하도록 학습함.
Multitask Masked Language Model
UniLM에서와 같이 Masked Language 모델을 additional self-attention mask와 훈련함. Self-attentionmask는 1/6 left-to-right, 1/6 right-to-left, 1/3 unmasked, 1/3에서 처음 50% 토큰은 unmasked, 나머지는 left-to-right mask 중에 랜덤하게 선택
Masked Seq-to-Seq
MASS에서 영향 받아서 토큰의 50%을 포함한 span을 mask하고 masking된 토큰을 예측하기 위해 seq2seq 모델을 훈련함.
Permuted LM, Masked LM, Multitask Masked LM을 위해 two-stream attention을 이용하여 효율적으로 sequence output에 대한 likelihood를 계산함. (left-to-right 단어 예측을 위해 diagonal self-attention mask를 출력에 사용)
(1) task를 standard seq2seq 문제로 취급, source input은 encoder에 target은 decoder ouput으로
(2) decoder에 source를 target에 prefix로 더하고, sequence의 target 부분에만 loss를 계산
로 실험했는데 전자(1)가 BART 모델에 더 잘 작동했음.
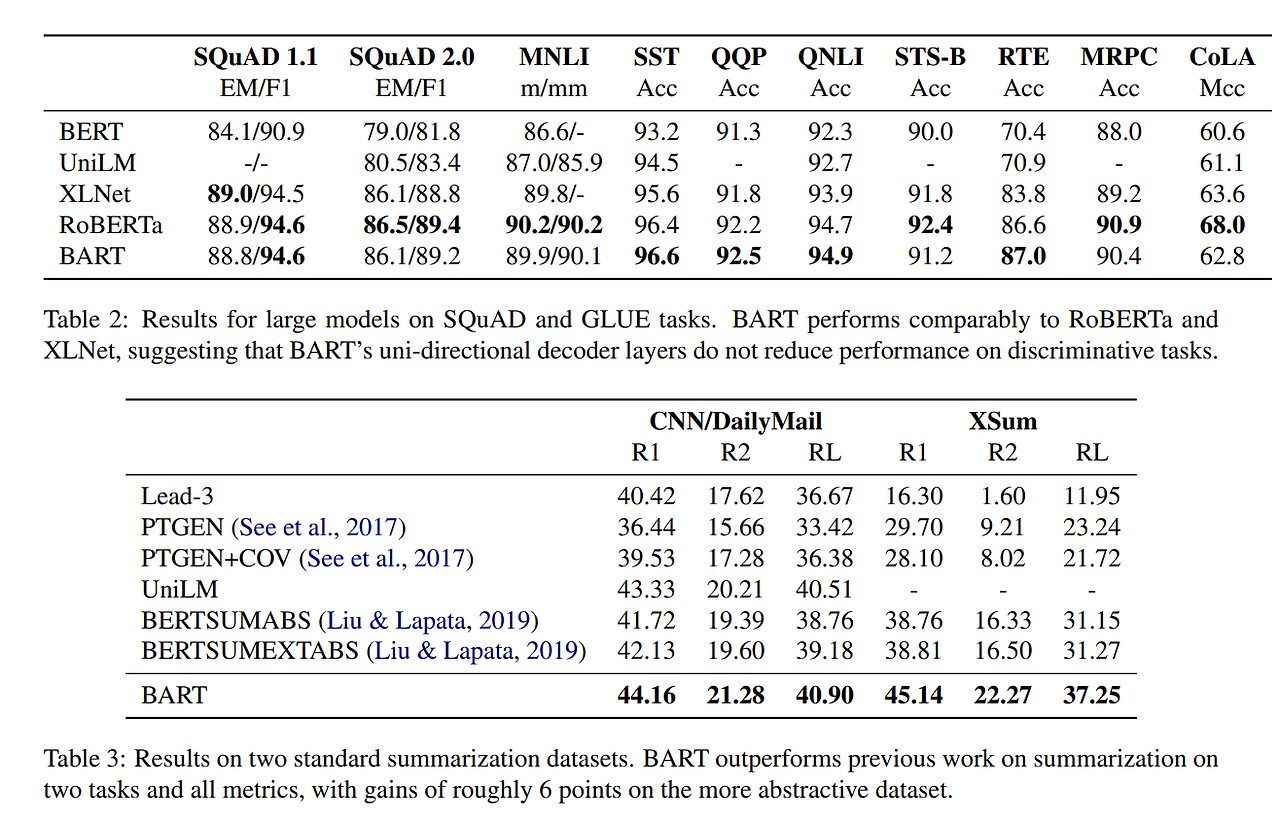
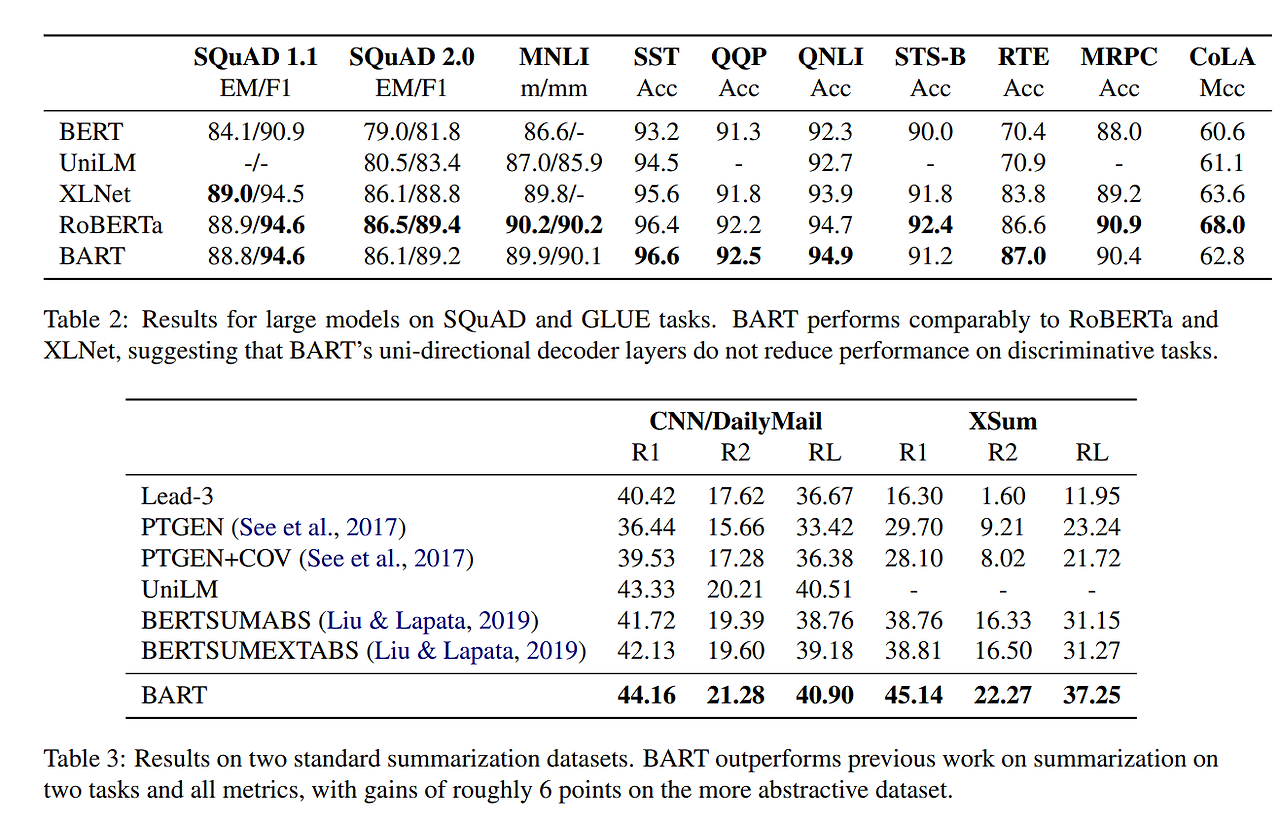
Results
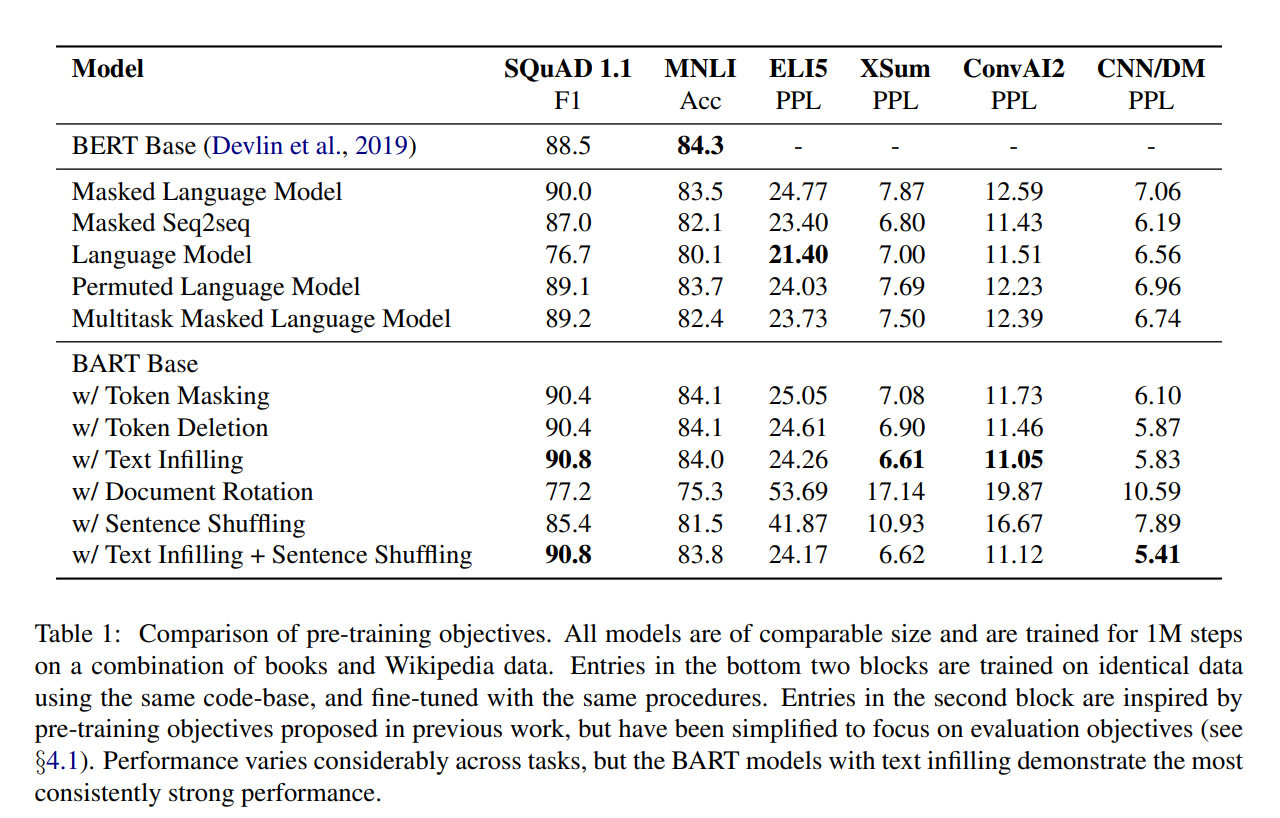
- pre-training method의 성능은 task마다 확연한 차이가 있음.
- Token masking은 중요함.
- Left-to-right pre-training은 generation 성능을 향상시킴.
- SQuAD에서 Bidirectional encoder는 중요함.
- pre-training objective 외에도 중요한 요소가 많음.
- Pure language model이 ELI5에서 최고 성능을 보임.
- BART는 꾸준히 좋은 성능을 달성함.
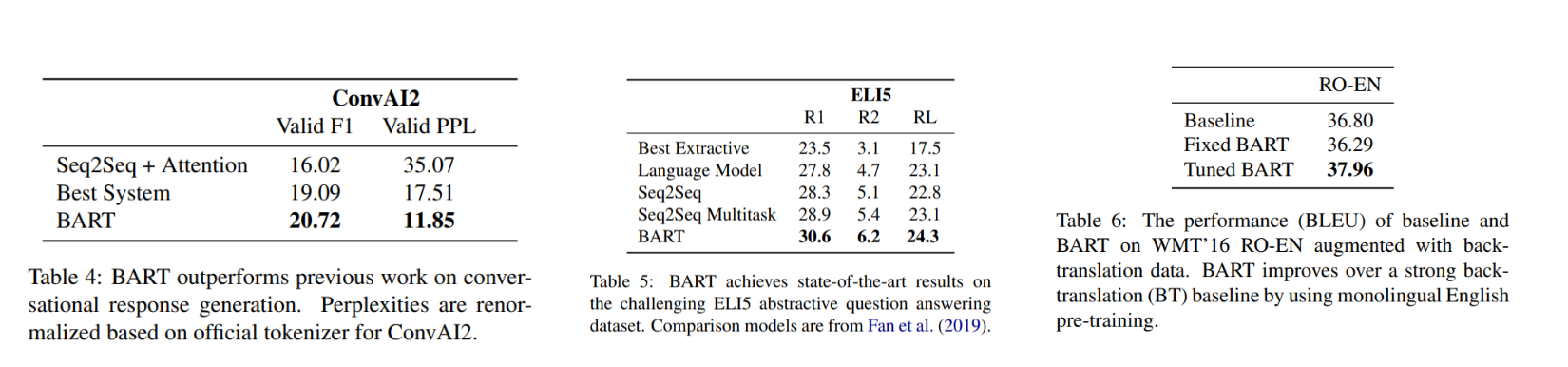
Large-scale Pre-training Experiments
최근 연구에서는 pre-training이 큰 배치 사이즈와 corpora로 스케일되어질 때, downstream 성능이 극적으로 개선된 것을 보여줌.
Conclusions
corrupted document를 원본으로 매핑하는 pre-training approach인 BERT를 소개함. BART는 discriminative task에서 RoBERTa와 비슷한 성능을 달성하면서 여러 텍스트 생성에서 SOTA를 달성함. 다음 연구에서는 pre-training을 위해 document를 corrupting하는 새로운 방식에 대해 탐구할 것이고 specific end task에 맞게 조정하는 것이 가능할 것임.
