
Abstract
NLU는 tedtual entailment, QA, semantice similarity assessment, 문서 분류과 같은 다양한 task를 구성함.
large unlabeled text corpora🔺/ 특정 task를 학습하기 위한 labeled data 🔻
▶ discriminatively trained model이 적절하게 수행하는 것이 어려움
semi-supervised한 접근법을 소개
다양한 unlabeled text corpus에서 언어 모델의 generative pre-training과 각 task별 discriminative fine-tuning으로 큰 성과
▶unlabeled data로 general하게 모델을 학습한 후, laebeled data로 원하는 task에 specific하게 모델을 fine-tuning
Introduction
대부분의 딥러닝 방법들이 수동적으로 labeled data를 구해야하는 상황에서 unlabeled data의 언어 정보를 활용할 수 있는 annotation 작업의 대안으로 가치있음. (시간과 비용이 많이 드는 작업이기 때문)
비지도 방식으로 좋은 표현 학습 > 지도 방식
ex. pre-trained word embedding 사용 → NLP task의 성능 향상
unlabeled text에서 word-level 이상의 정보를 활용하는 것이 어려운 이유 → uncertainties (불확실성)
ⓛ transfer에 유용한 text를 표현을 학습하는 데 어떤 종류의 optimization objectives가 가장 효과적인지 명확하지 않음
② 학습된 표현을 target task로 transfer하는 가장 효과적인 방법이 정해져있지 않음
비지도(unsuperivsed) pre-training + 지도(supervised) fine-tuning → NLU에 대한 semi-supervised 방식 탐구
▶다양한 task에 사용하면서도 약간의 adaptation으로 transfer할 수 있는 universal representation 학습
두 단계의 훈련 절차
ⓛ unlabeled data에 대한 language modeling objective를 사용하여 신경망 모델의 초기 파라미터 학습
② 해당하는 supervised objective를 사용해 target task에 맞게 파라미터 수정
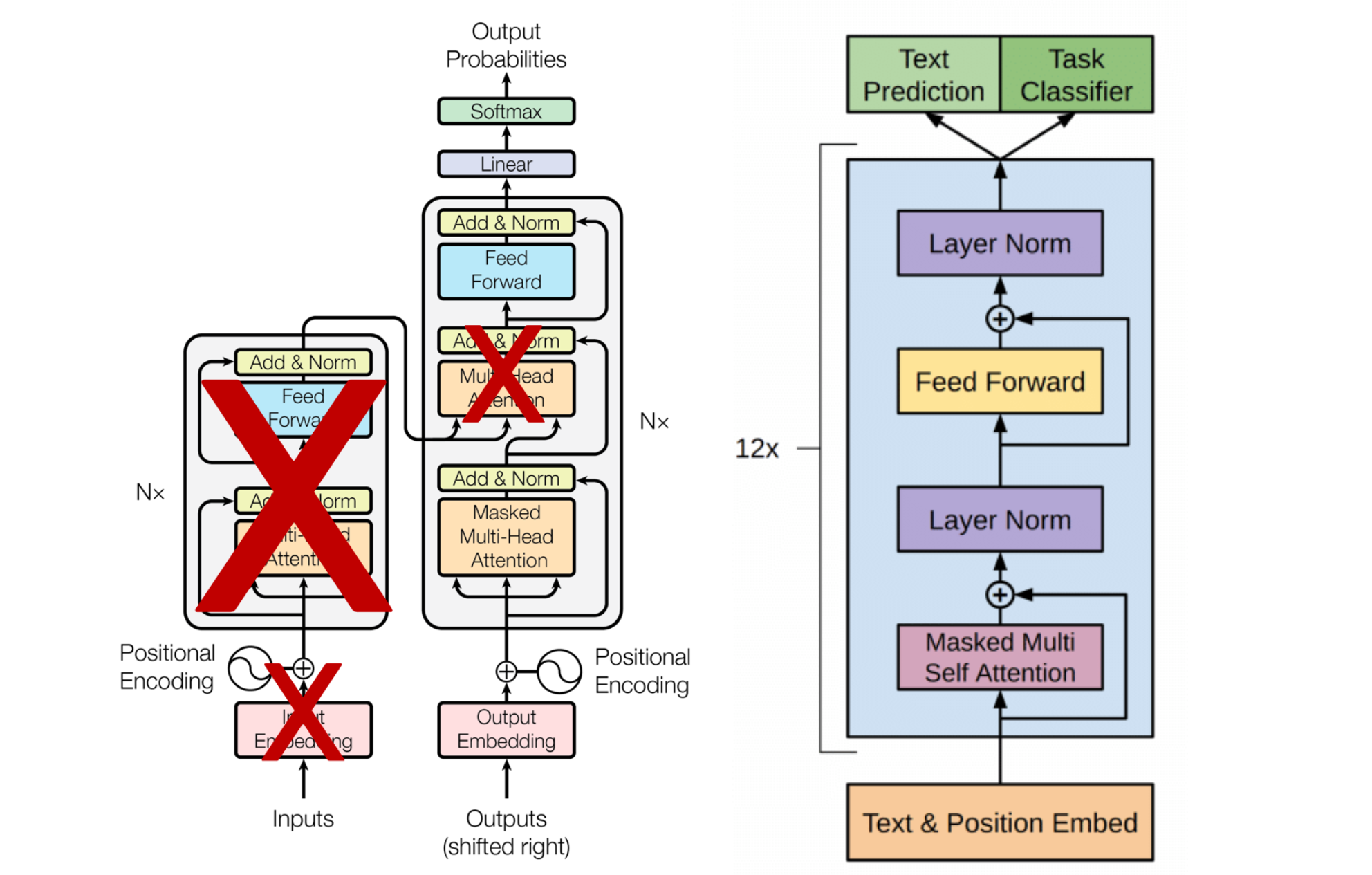
모델 구조 → Transformer 사용
▶ recurrent network와 같은 대안과 비교했을 때 텍스트의 장기 의존성을 다루기 위해 더 구조화된 메모리 제공
→ 다양한 task에 robust한 전이 성능을 얻음
transfer를 할 때는 traversal-style approachs에서 사용된 task-specific한 input adaptation 사용
→ 구조화된 text input을 single contiguous sequence of tokens로 처리함.
→ 모델의 구조를 최소한으로 변경하면서 효과적으로 fine tuning할 수 있음.
Related Work
Semi-supervised learning for NLP
sequence labeling, text classification에 적용되며 관심을 받았는데, 초기 연구에서는 unlabeled data를 사용해서 word-level이나 phrase-level의 통계량을 계산하고 이를 supervised model의 feature로 사용하였음.
최근 연구에서는 unlabeled data에서 word-level semantics 이상의 phrase-level이나 sentence-level embedding을 시도함.
Unsupervised pre-training
supervised learning objective 조절이 목표가 아닌 좋은 initialization point를 찾는 것이 목표 (semi-supervised learning의 special case)
이 논문과 비슷한 연구로 language modeling objective를 사용해서 사전 학습을 진행하고 target task에 fine-tuning하는 연구가 있었는데, 사전학습을 할 때 언어 정보를 얻기 위해 LSTM을 사용했고 이로인해 짧은 범위의 예측만 가능했음.
→ 본 논문에서는 transformer를 사용해 긴 범위의 데이터에서도 가능하도록 함.
Auxiliary training objectives
auxiliary unsupervised training objectives를 추가하는 것은 semi-supervised learinng의 다른 형태임.
본 논문에서도 auxiliary objective를 사용하지만, unsupervised pre-training은 이미 target task와 관련된 여러 언어적 측면을 학습함.
Framework
① large corpus of text에서 high-capacity 언어 모델을 학습
② fine-tuning → labeled data를 사용해서 모델을 discriminative task에 적용
Unsupervised pre-training
비지도 말뭉치 토큰 u={u_1, u_2, ... ,u_n}이 주어졌을 때, likelihood를 최대화하는 방향으로 stadard lanuage modeling objective 사용 :
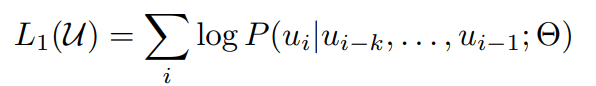
k : context window의 크기
조건부 확률 P : 파라미터 Θ를 가진 신경망을 사용하여 모델링
→ stchastic gradient descent(확률적 경사 하강법)를 사용하여 훈련
ex) I like you → I와 like가 주어졌을 때, you를 예측
i-k ~ i-1번째의 token들로 i번째 token을 예측할 likelihood를 최대화하도록 모델의 파라미터 업데이트
unlabeled data에서도 학습이 가능하기 때문에 Unsupervised learning에 해당함.
Transformer의 변형인 multi-layer Transformer decoder를 언어 모델로 사용
✅ multi-headed self-attention을 input context token에 적용
✅ position-wise feedforward layer를 거쳐 target tokens에 대한 output distribution 생성
임베딩 후에 potision embedding matrix를 더하고, layer의 갯수만큼 decoder block을 통과한 후, position-wise layer를 거쳐 softmax로 확률값을 구함.
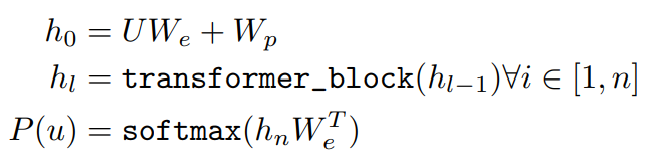
U = (u−k, . . . , u−1) : token context vetor
n : 레이어의 수
: token embedding matrix, : position embedding matrix
를 통해 token embedding하고, 그 결과값에 W_p을 통해 구한 position embedding 값을 더함
→ n개의 transformer의 decoder block에 통과
→ 최종 결과에 를 내적하고, softmax을 적용
Supervised fine-tuning
Unsupervised pre-training한 뒤에,사용된 파라미터들을 supervised target task에 맞게 fine-tuning
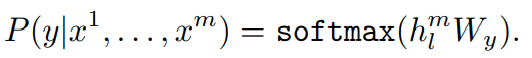
y : label x : input token
pre-training된 transformer의 최종 출력물인 을 얻게 되고, label 를 예측하기 위해 와 곱해 softmax함수 적용
log likelihood를 최대화 하는 식 :
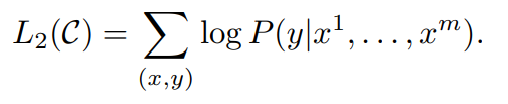
input token을 넣었을 때 label값을 반환할 likelihood를 의미하고 likelihood를 최대화하도록 를 업데이트함.
fine-tuning에 언어 모델링을 auxiliary objective로 포함
(a) supervised model의 일반화 성능 향상
(b) 수렴 가속화
→ 학습에 도움 + 성능 향상
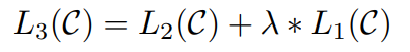
lambda : 가중치
L1은 pre-train에서의 식 즉, auxiliary objective
두 식을 함께 사용함으로써 모델의 generalization과 convergence에 도움이 됨.
Task-specific input transformatons
각 task에 적합하게 input data의 구조를 만들어주면 pre-train한 모델의 구조를 크게 바꾸지 않더라도 다양한 task에 fine-tuning 가능
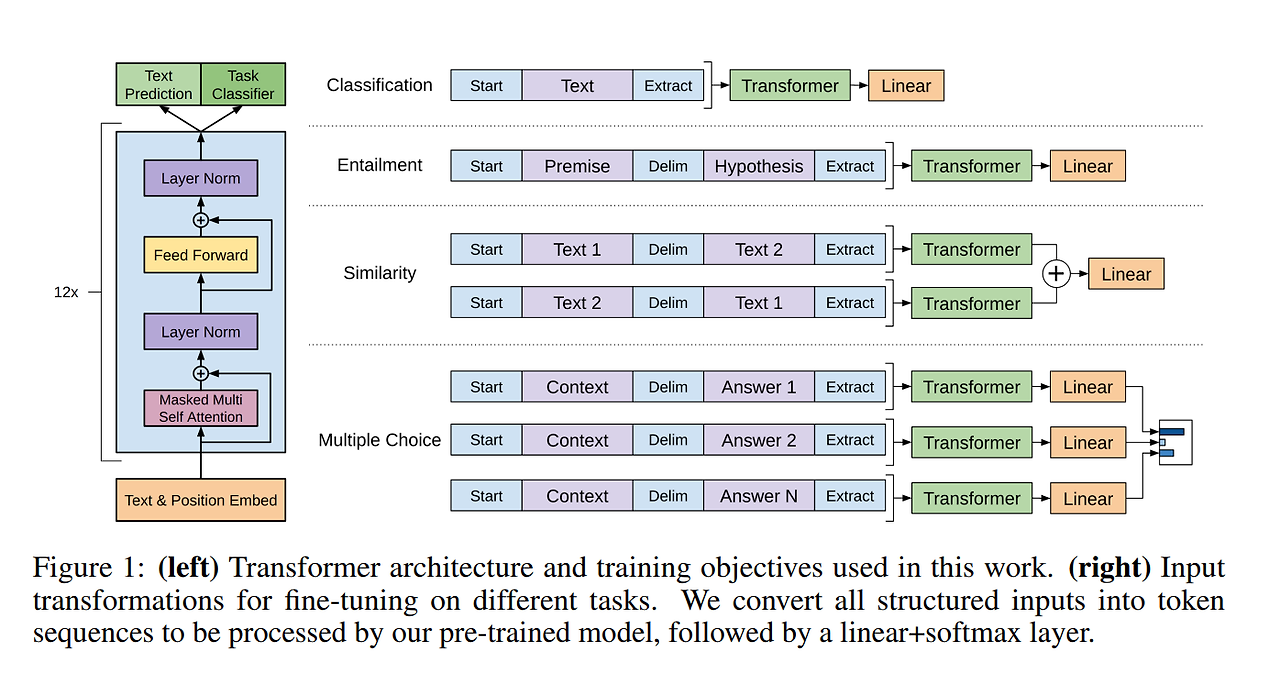
pre-trained model이 contiguous sequences of text에 대해 학습되었기 때문에 orderded sentence pairs, triplets of document, QA와 같은 task에 적용하기 위해서는 일부 수정이 필요함.
▶traversal-style approach를 사용해서 구조화된 입력을 pre-trained model이 사용할 수 있는 순서화된 시퀀스로 변환
Textual entailment
premise p와 hypothesis h 토큰 시퀀스를 결합함. 두 시퀀스 사이에 delimiter token ($)를 concat
Similarity
순서 X, 입력 시퀀스를 수정하여 가능한 두 문장 순서(delimiter 포함)를 모두 포함하여 독립적으로 처리, 두 시퀀스 표현 을 요소별로 더한 후에 linear ouput layer에 입력함.
Question Answering and Commonsense Reasoning
context documnet z, question q, possible answers 가 주어짐. delimiter token으로 [z; q; $; ak]를 더해줘서 document context와 question을 각각 가능한 answer와 concat함. 각 시퀀스들은 독립적으로 처리되고 softmax layer를 통해 정규화돼서 가능한 답변에 대한 분포를 생성함.
Experiments
setup
Model specifications
- masked self-attention heads를 가진 12개의 transformer decoder layer로 학습
- self-attention head (각 64개의 Q, K, V과 총 12개의 heads로 구성)
- position-wise feed-forward는 총 3072차원
- Adam optimizer 사용
- activation function : Gaussian Error Linear Unit (GELU)
Supervised fine-tuning
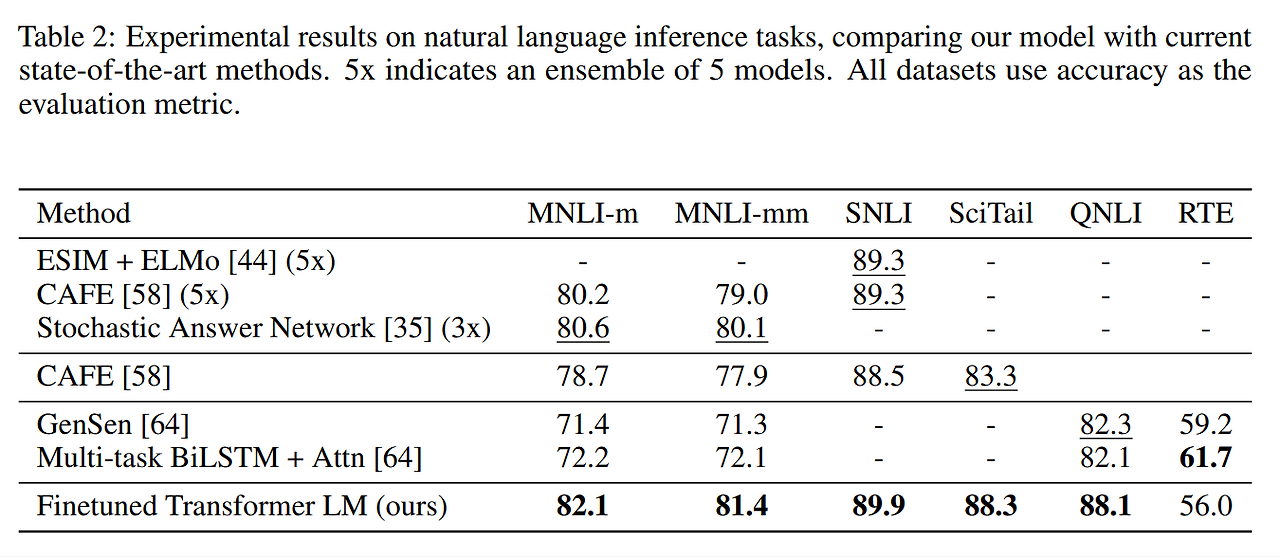
Natural Language inference
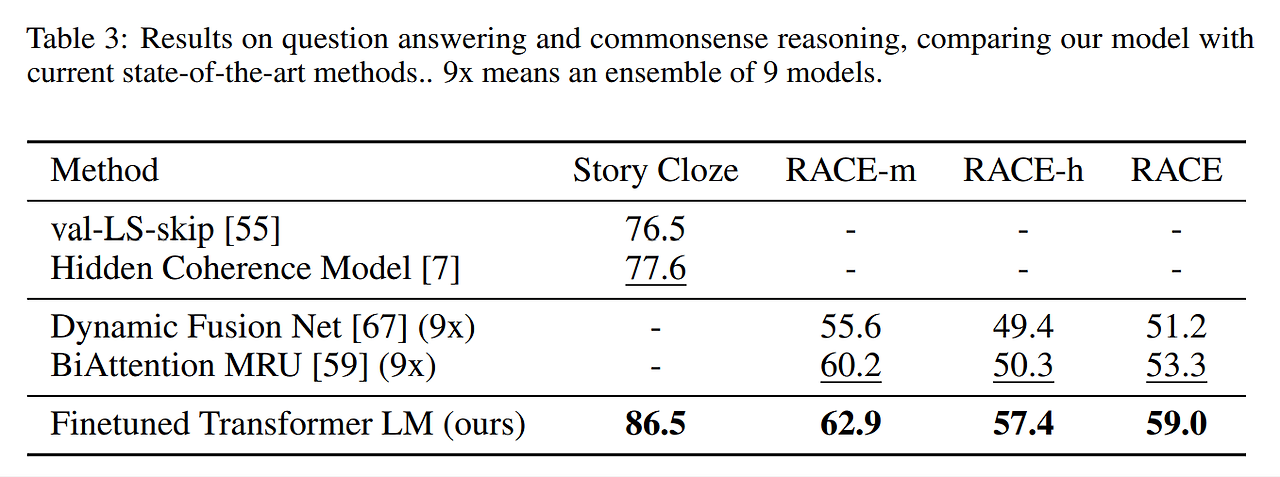
Question answering and commonsense reasoning
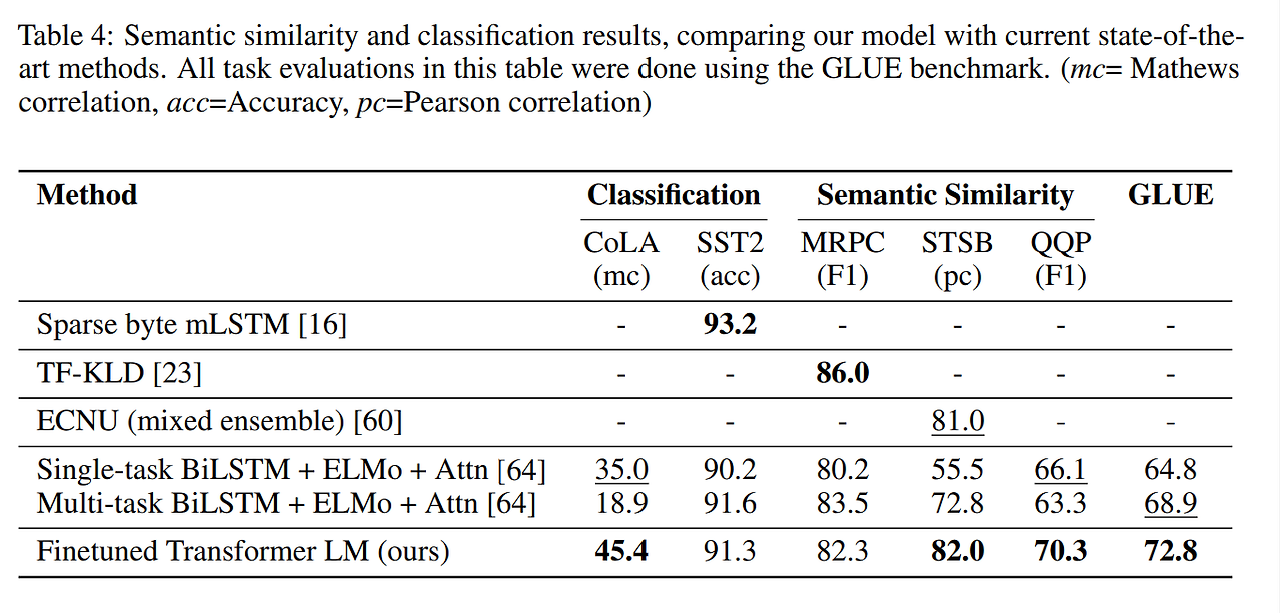
Semantic similarity and Classification
Analysis
Impact of number of layers transferred
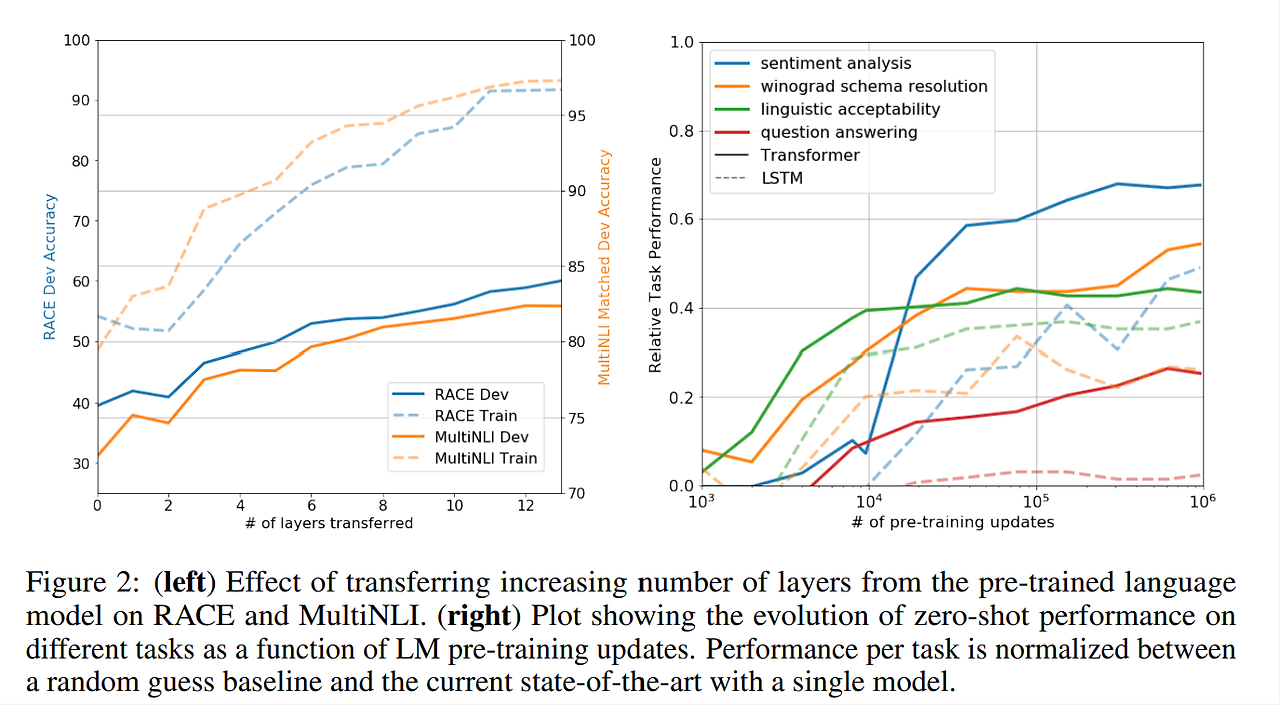
unsupervised pre-trainnig에서 supervised target task로 이동하는 layer의 수가 변할 때 영향
✅ transferring embedding들이 layer마다 최대 9%의 성능 향상 Figure2 : 왼쪽 그림
✅ pre-trained model의 각 layer가 유용한 기능을 포함한다는 것을 나타냄.
✅ Transfer하는 layer의 개수가 많을 수록 성능이 좋아짐.
Zero-shot Behaviors
transformer를 사용한 언어 모델 pre-training이 효과적인 이유
▶ generative model이 언어 모델링의 capability를 향상시키기 위해 많은 task를 배울 수 있고, LSTM과 비교해 transformer의 구조화된 attentional memory가 transfer에 도움이 됨.
▶ supervised fine tuning없이 generative model 사용
heuristic solution의 generative pre-training의 효과 시각화 Figure2 : 오른쪽 그림
: 학습 횟수에 따라 성능이 안정적으로 꾸준히 증가
→ generative pretraining이 다양한 task를 학습하는 것에 도움을 줌.
▶ pre-training을 더 많이 할수록 다양한 task에 성능 증가
LSTM은 zero-shot 성능에서 더 큰 분산을 보이는데, Transformer 아키텍쳐의 inductive bias(일반화가 잘 되었는지)가 transfer에 도움이 됨을 의미함.
Ablation studies
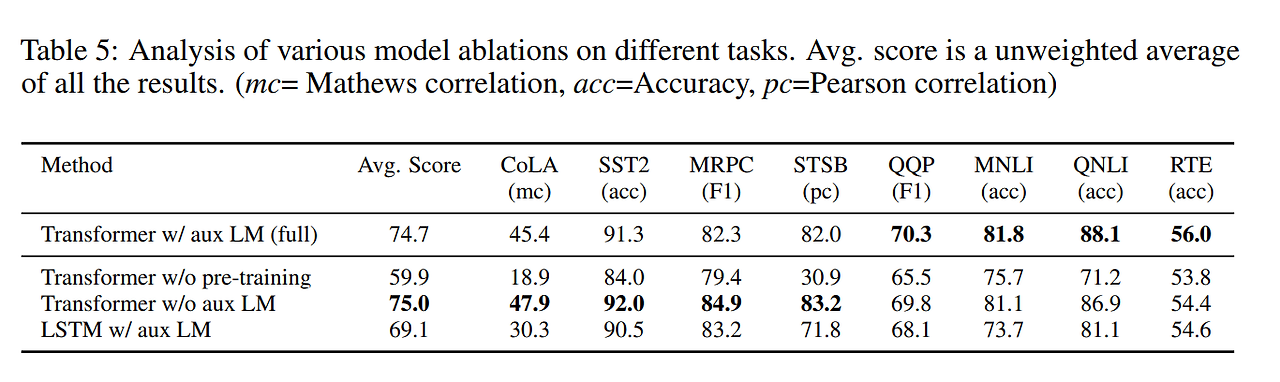
auxiliary objective의 효과
NLI와 QQP(Quora Question Pairs) 데이터셋에서 성능 향상에 도움을 줌 (크기가 작은 데이터셋에서는 X)
Transformer 대신에 LSTM 모델을 사용한 결과 - MRPC 데이터셋을 제외하고는 transformer가 더 좋은 성능을 보임
pre-training을 했을 때가 성능이 더 좋음
Conclusion
generative pre-training과 discriminative fine-tuning을 통해 여러 task에 강력한 NLU를 달성하는 framework를 소개함.
contiguous text의 long stretches로 다양한 corpus에서 pre-training함으로써 word knowledge와 long-range dependencies를 처리하는 능력을 얻어 QA, semantic similarity assessment, entailment determination, text classification과 같은 task에 맞게 성공적으로 전이되었고 12개의 데이터셋 중에서 9개에서 SOTA 달성함.
