
Abstract
새로운 type의 deep contextualized word representation을 소개
(1) 단어 사용의 복잡한 특성들 (e.g. syntax and semantics)을 모두 만족시키는 표현
(2) 언어적 맥락에서 어떻게 다양하게 사용되는지 (i.e. to model polysemy)
💭 ‘눈’이라는 다의어는 일부 문장에서는 snow❄로, 다른 문장에서는 eye👀로 다르게 해석됨.
논문에서 제시한 word vector는 large text corpus에서 사전 훈련된 deep bidirectional language model (biLM)의 내부 상태의 학습된 함수
▶ 기존 모델에 쉽게 추가
▶ QA, textual entailment, 감성 분석을 포함한 6개의 NLP 문제에서 SOTA 달성
ELMo(Embeddings from Language Model)는 2018년에 제안된 새로운 word embedding 방법론
- 더 좋은 단어 표현을 위해 만들어짐
- 사전 훈련된 언어 모델(Pre-trained language model) 사용
Introduction
사전 훈련된 word representations는 많은 NLU model에서 중요한 요소지만, high quality representations 학습은 어려움.
(1) 단어 사용의 복잡한 특성들 e.g. syntax and semantics
(2) 언어적 맥락에서 어떻게 다양하게 사용되는지 i.e. to model polysemy
에 대해 모델링해야 함. 문맥에 따라서 다르게 word embedding
→ new type of deep contextualized word representation
기존의 각 토큰별로 embedding하는 전통적인 word type embedding과 다름
▶ large text corpus에서 coupled language model (LM)로 훈련된 bidirectional LSTM에서 파생된 벡터 사용
▶ Embeddings from Language Models → ELMo
▶ LSTM의 마지막 레이어만 사용 X → LSTM의 모든 내부 레이어 사용 (각 입력 단어 위에 쌓인 벡터들의 선형 조합)
• higher-level LSTM : 문맥을 반영한 단어의 의미를 잘 표현
• lower-level LSTM : 단어의 문법적인 측면을 잘 표현
ELMo: Embeddings from Language Models
ELMo word representations
▶전체 입력 문장의 함수
▶ character convolutions을 사용한 two-layer biLMs 위에 계산됨
→ 대규모로 사전 학습된 biLM을 사용하여 semi-supervised learning 수행 + 기존의 neural NLP architecture에 쉽게 통합
Bidirectional language models
길이가 N인 token 이 있을 때,
forward language model은 가 주어졌을 때, token이 나올 확률 계산
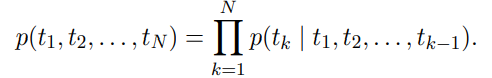
backward language model은 이 주어졌을 때 token 𝑡_𝑘가 나올 확률을 계산
→ 다음 context가 주어졌을 때, 이전 token 예측
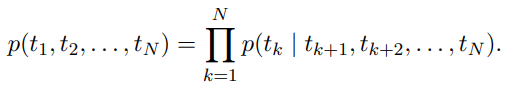
biLM = forward language model + backward language model
forward & backward directions의 log likelihood를 최대화
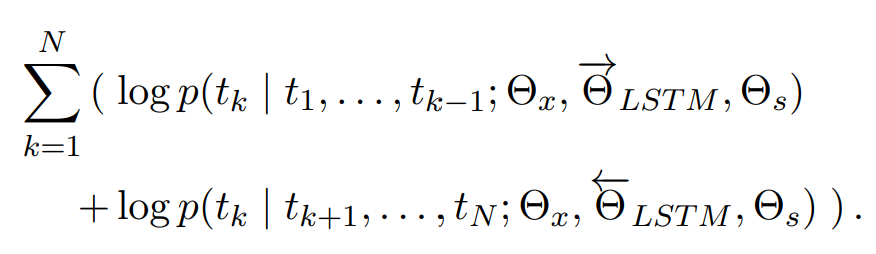
완전히 독립적인 parameter를 사용하는 대신 directions 간에 일부 weights 공유
ELMo
두 LSTM의 layer representations의 결합
biLM의 L개의 layer는 각 token 당 개의 representation 계산

모델을 downstream에 적용하기 전에 먼저 모든 layers를 하나의 vector로 압축시켜야 함.
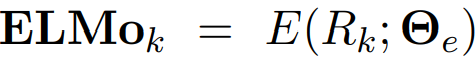
모든 biLM layers의 task specific weighting 계산
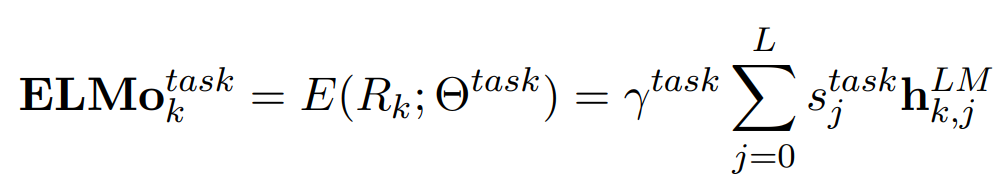
: softmax-normalized weights, scalar parameter
: 작업 모델이 전체 ELMo 벡터를 조절 scale
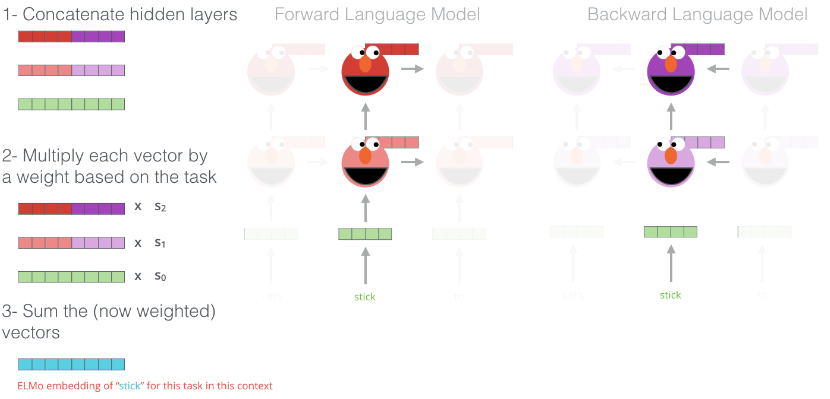
ELMo의 embedding 동작 방식
1. 단어마다 Forward LSTM의 hidden vector 및 token embedding vector와 Backward LSTM의 hidden vector 및 token embedding vector를 Concatenate
2. 이어 붙인 벡터에 각각 가중치 s0,s1,s2를 곱해줌.
3. 세 벡터를 더해준 벡터를 ELMo 임베딩 벡터로 사용함.
• s0,s1,s2는 학습을 통해 갱신되는 parameter로 task에 따라 달라짐.
• 단어의 문맥적인 의미가 중요한 태스크 - 상위 레이어에 곱해주는 s2 🔺
• 구조 관계가 중요한 태스크 - 하위 레이어에 곱해주는 s1 🔺
Using biLMs for supervised NLP tasks
supervised downstream task에 ELMo를 적용하는 구체적인 방법은 간단함.
1. biLM을 학습시켜 각 단어에 대한 layer representations를 저장
2. downstream이 pretrain된 모델의 선형결합 학습
biLM이 없는 supervised model의 가장 낮은 레이어 고려
▶ token sequence 가 주어지면, 사전 훈련된 word embedding과 선택적 character-based representations를 사용해 각 token position마다 context-independent token representation 를 만듦
▶ bidirectional RNNs, CNNs 또는 feed forward networks를 사용해 context-sensitive representation 생성
ELMo를 supervised model에 추가
▶ biLM의 가중치 고정
▶ ELMo vector ELMo_task_k를 xk에 연결
▶ [xk; ELMo_task_k]을 task RNN으로 전달
➕ moderate amount of dropout를 추가하는 것이 유용함
➕ ELMo 가중치를 정규화하기 위해 손실에 λ||w||2_2를 추가하는 것도 유용함
→ ELMo 가중치에 대한 inductive bias를 가해서 모든 biLM layers의 평균에 가깝게 유지 일반화 성능🔺
Pre-trained bidirectional language model architecture
L = 2 biLSTM을 사용, dimension = 512, LSTM 첫 번째와 두 번째 레이어 사이에 residual connection로 연결
(각 layer는 4096 units과 512 dimension projections)
embedding은 2048 character n-gram convolutional filters에 두 개의 highway layer 사용, 512차원으로 projection시켜줌.
Evaluation
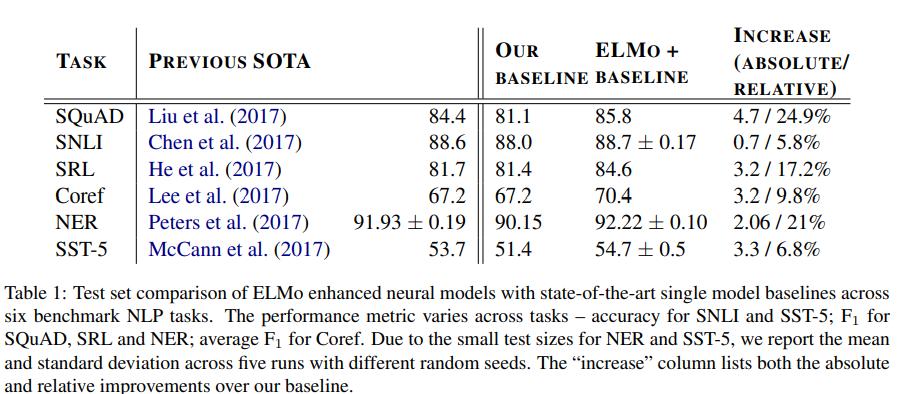
6개의 NLP task에 대해서 ELMo를 적용했을때 성능 향상이 있었고 일부 task에서는 SOTA성능을 얻음
Analysis
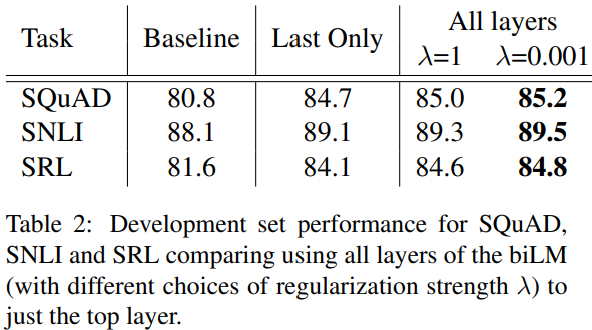
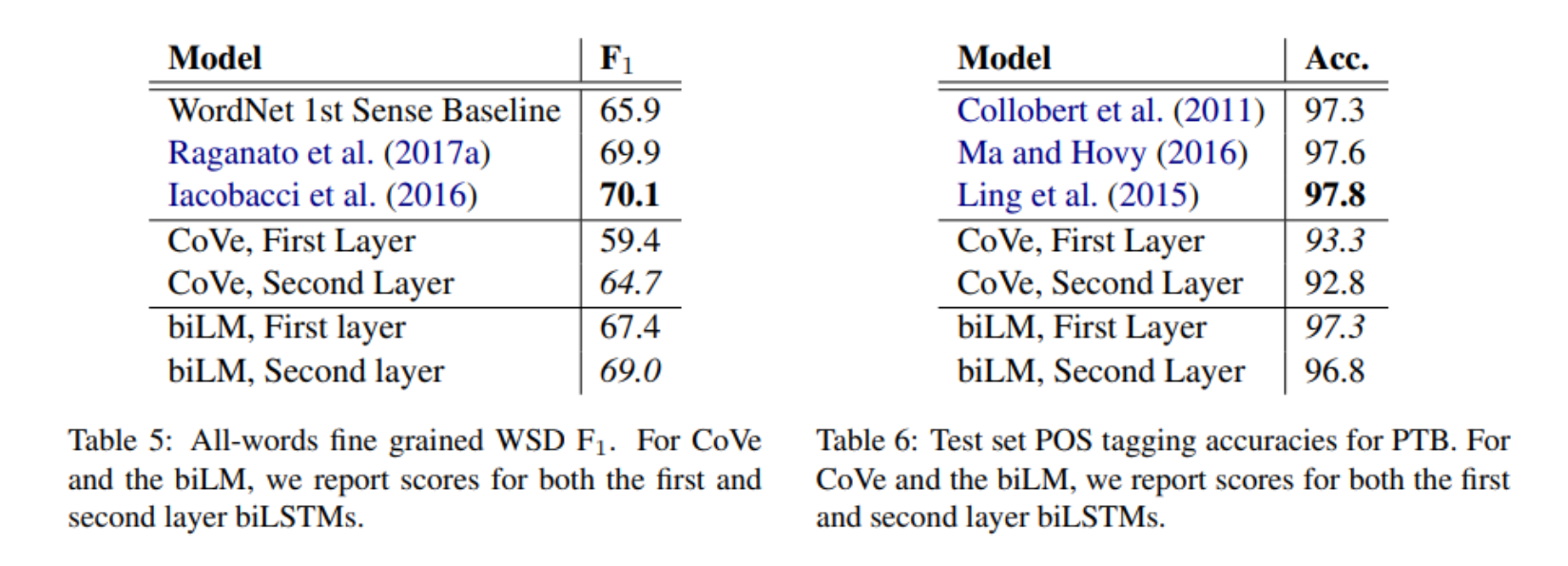
• 모두 다른 가중치를 적용했을때 가장 성능이 좋았음
• 선형 결합없이 최상단 은닉 벡터만 사용하는것이 임베딩 없이 사용할때보다 성능이 좋았음
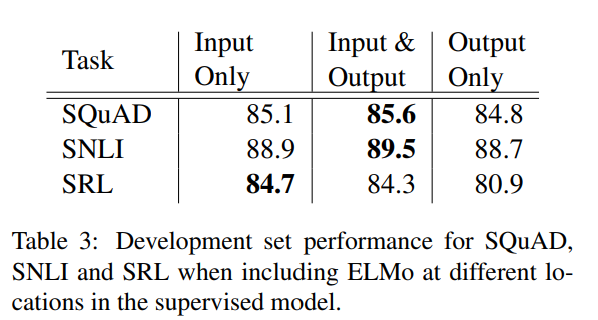
• 입출력 단계에 모두 ELMo 임베딩을 적용하는 것이 가장 좋음
• 입, 출력 벡터 중 하나에만 적용하는 경우는 모두 적용한 경우보다는 떨어지지만, 아무것도 사용하지 않은 모델보다는 좋은 성능을 보임

Glove에서는 “play”에 관련된 단어들로 스포츠와 관련된 단어 등장
biLM에서는 “play“와 유사한 의미로 사용되는 문장이 관련된 단어 등장
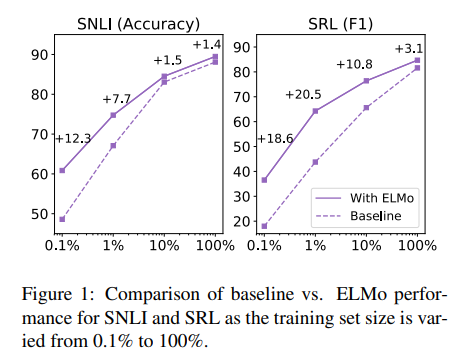
기존모델은 486 epochs에 최고 성능을 도달, ELMo를 적용한 모델은 10 epochs에 최고 성능을 도달
모델에 ELMo를 추가했을 때 학습속도가 빠름 + 더 작은 훈련 세트를 더 효율적으로 훈련함
Conclusion
ELMo를 시작으로 대량의 말뭉치로부터 생성된 품질 좋은 임베딩 벡터를 만드는 모델이 많이 사용됨. ELMo는 이후에 등장하는 트랜스포머 기반의 BERT나 GPT보다 많이 사용되지는 않지만 좋은 품질의 임베딩 벡터를 바탕으로 적절한 Fine-tuning후에 여러 태스크에 적용하는 전이 학습(Transfer learning)의 시초격인 모델로서의 의의가 있다고 할 수 있음.
