
ABSTRACT
더 정확하고, 다양하고 설명 가능한 추천을 위해서는 user-item interaction과 side information을 추가하는 것이 필요함.
FM(factorization machine)과 같은 Traditional method는 각 interaction을 independent instance로 가정해서 supervised learning 문제로 취급했는데 때문에 collborative signal을 추출하는 것이 부족함.
➡ knowledge graph(KG)와 user-item graph를 사용하는 hyhbride 구조를 제안!
- 각 노드의 임베딩을 개선하기 위해 해당 노드의 이웃들의 임베딩을 재귀적으로 전파
- 주변 neighbors의 중요성을 구별하기 위해 attention mechanism 사용
INTRODUCTION
CF(Collaborative Filtering) 방법
✔ side information (아이템 속성, 사용자 프로필 및 맥락 등)을 모델링할 수 없어 user와 item간의 상호 작용이 적은 상황에서 성능이 저하됨.
SL(Supervised Learning) 모델
user ID와 item ID를 함께 generic feature vector로 변환하여 score 예측
✔ 각 상호작용을 독립적인 data instance로 모델링하여 관계를 고려하지 않았음.
✔ Attribute-based Colloborative Signal이 잘 전달되지 않음.
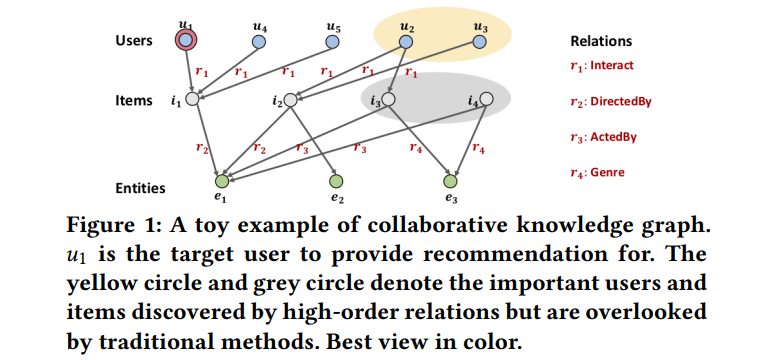
기존 CF 모델들은 user 이 선호하는 item 에 focus하여 user 에 관심이 있었고, SL 모델은 entity 을 통해 비슷한 item 에 관심이 있었음.
❗ 동일한 entity 에 관심을 갖는 user 과 entity 과 다른 relation을 갖는 item 을 고려하지 못함.
✔ high-order information을 활용하는 것에 어려움
1) target user와 high-order relation을 가진 노드들은 order size가 급격히 증가해서 계산량 복잡
2) high-order relation은 예측에 미치는 영향이 동일하지 않아서 가중치 고려 문제 존재
📍 기존 CKG (Collaborative Knowledge Graph)의 문제점
Path-based methods
high-order information에 대한 path를 추출하고 예측 모델에 입력
➡ path selection algorithm or meta-path pattern 사용
two-stage method (path select ➡ training)의 문제점
- path selection이 final performance에 많은 영향을 줌
- 효과적인 meta-path를 정의하기 위해 도메인에 대한 지식 요구
Regularization-based methods
추천 모델을 학습을 regularize하기 위해 KG structure의 loss를 추가적으로 구현
KTUP 및 CFKG는 KG에 포함된 entity 및 relation information을 shared item embedding으로 변환하여 추천과 KG completion 두 가지 task를 동시에 학습시킴.
➡ user와 item 간의 상호 작용뿐만 아니라 KG의 구조적 정보를 함께 고려하여 추천
❗high-order relation을 직접 plugging하는 대신, implicit한 방식으로만 인코딩함.
➡ long-range connectivity를 포착할 수 없고 high-order modeling의 해석도 어려움.
KGAT는 high-order rlation modeling에서 발생하는 문제들을 해결하기 위해 recursive embedding propagation과 attention-based aggregation을 활용함.
TASK FORMULATION
User-Item Bipartite Graph
Knowledge Graph
Collaborative Knowledge Graph
High-Order Connectivity
METHODOLOGY
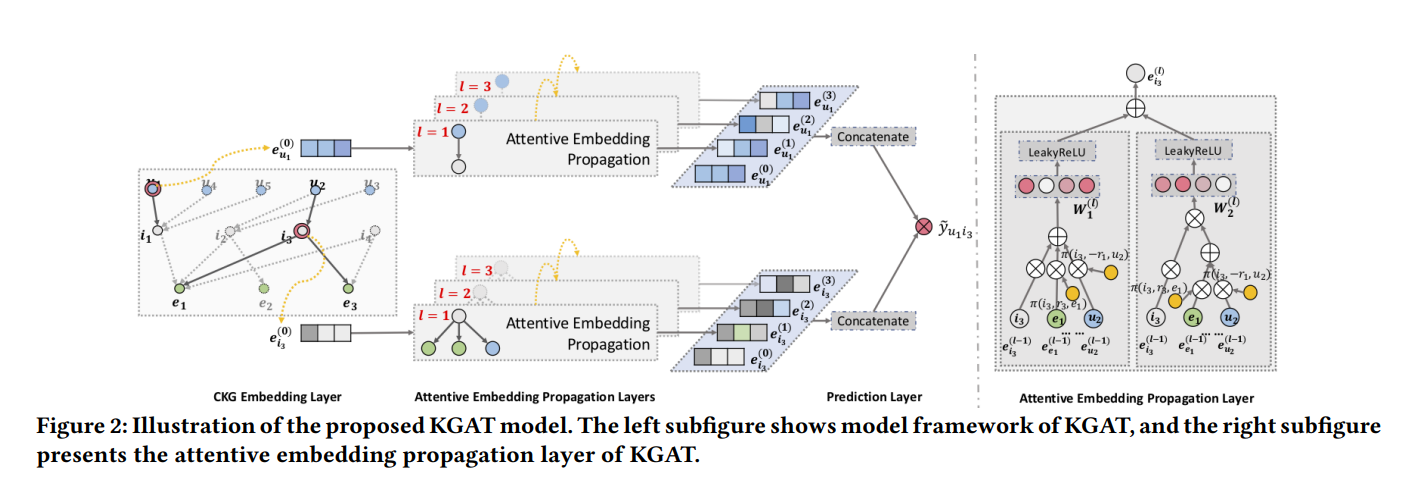
📍 Embedding Layer
KG의 노드를 공간 상의 벡터로 표현하여 각 노드의 특징을 임베딩
📍 Attentive Embedding
임베딩을 업데이트하는 데에 사용되며, attention mechanism을 통해 노드의 특징을 더욱 정교하게 모델링
📍 Prediction Layer
최종 예측 결과 생성
Embedding Layer
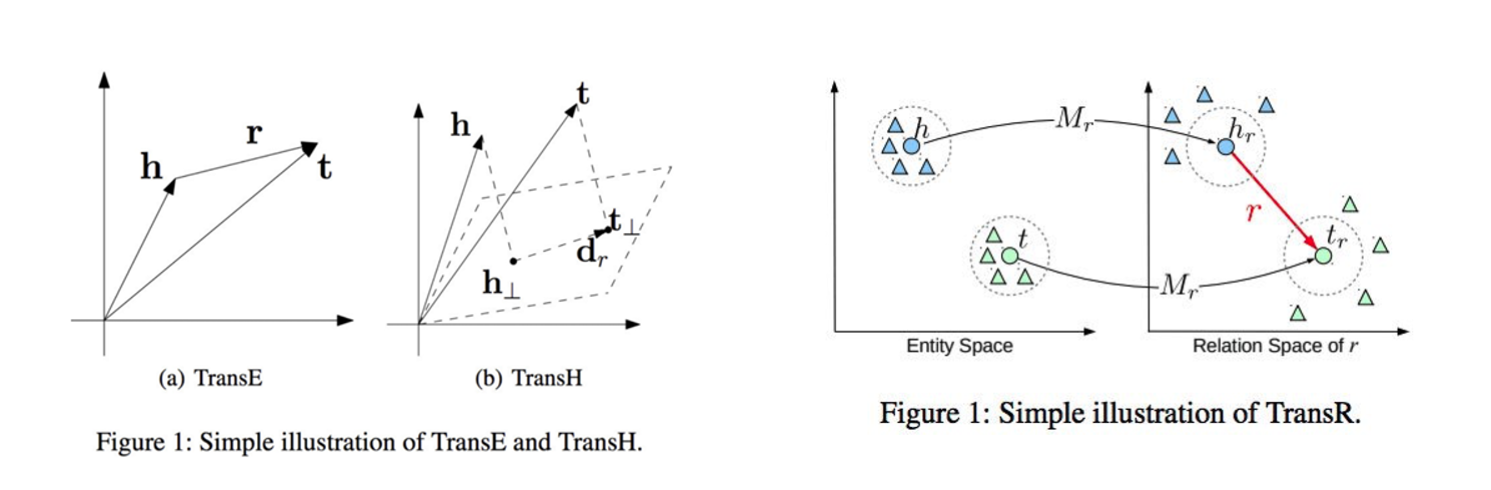
Knowledge Completion의 접근 방식인 Translation model에 대해 간단히 학습하고 논문을 읽는 것을 추천한다.
본 논문의 모델은 TransR(entity 와 relation을 다른 차원에 표현)을 이용해 KG를 임베딩함.
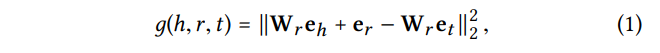
: head의 embedding, : relation의 embedding, : tail의 embedding, : relation r의 변환 행렬
TransR에서 의 translation principle을 따름
➡ 의 score가 낮을수록 triplet이 실제 있을 가능성🔺
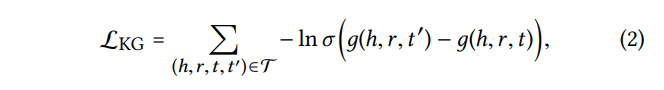
pairwise ranking loss를 통해 와 간의 상대적인 순서 고려
: 실제 그래프상에 존재하지 않는 triplet
: 실제 그래프상에 존재하는 triplet
Attentive Embedding Propagation Layers
🔍 Information Propagation
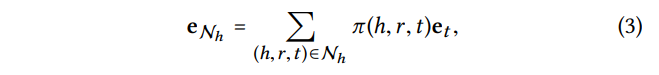
- 특정 entity h를 중심으로 h와 연결된 triplet들의 모음
- weight값이 (tail의 embedding)와 결합되어 propagate
Ego-network
: 특정 노드를 중심으로 주변에 직접적으로 연결된 모든 다른 노드의 집합
✔ 해당 entity가 관여한 관계들을 보다 자세히 이해하고 분석하는 데 사용
🔍 Knowledge-aware Attention
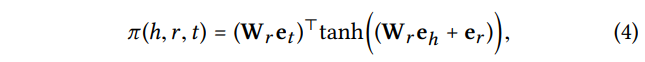
각 weight는 위의 식을 통해 학습함.
비선형 활성화 함수인 tanh를 사용함으로써 attention score가 relation r's space에 있는 와 사이의 거리를 고려할 수 있게 함.
entity들 사이의 거리가 가까울수록 attention score가 높아짐
➡ 해당 entity들 간의 관계가 더 중요하다고 판단
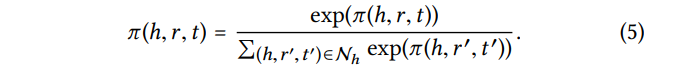
최종적으로 attention weight는 고정된 head 하나와 관련된 neighbor tail의 모든 weight를 softmax로 표현됨.
💡 final attention score는 collaborative signal을 포착하기 위해 어떤 이웃 노드에 더 많은 attention을 해야 하는지를 제안함.
🔍 Information Aggregation
entity h 와 ego-network 을 모아서 새로운 entity h 을 생성하는 과정
GCN Aggregator
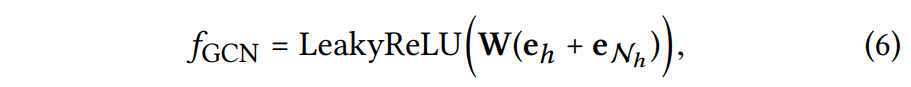
와 을 합치고 비선형 변환을 적용
GraphSage Aggregator
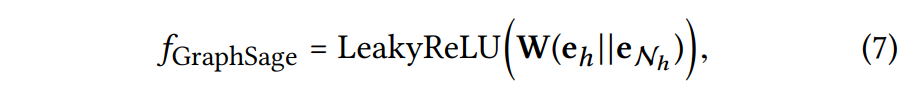
와 을 연결하고 비선형 변환을 적용
Bi-Interaction Aggregator
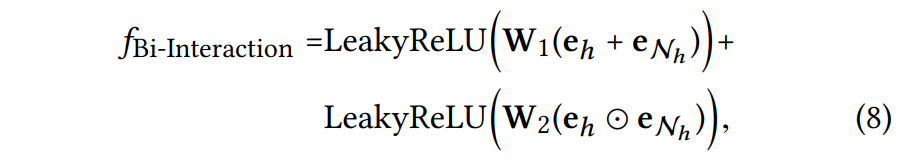
와 을 각각 합치고, element-wise product를 적용한 후 비선형 변환을 적용
➡ 와 간의 feature interaction을 추가로 인코딩하고 이를 통해 전파되는 정보가 와 간의 유사도에 민감하게 반응하도록 함.
💡 userm item, knowledge entity representation을 연관시키기 위해 embedding propagation layer를 통해 explicit하게 first-order connectivity information을 활용
Model Prediction
사용자 노드 에 대해 레이어를 수행하면 {}의 다층 표현을 얻을 수 있음. (item도 유사)
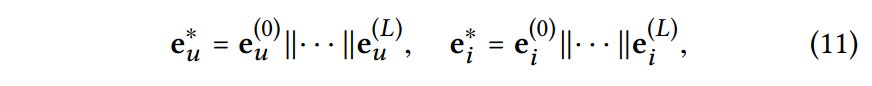
layer-aggregation mechanism을 적용해서 표현들을 연결하여 단일 벡터로 표현함.
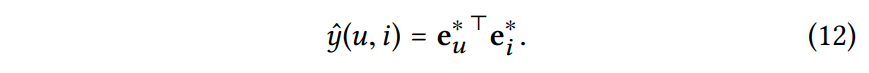
최종적으로 user와 item의 표현에 대해 내적을 수행하여 matching score 예측
EXPERIMENTS
