09-2 순환 신경망으로 IMDB 리뷰 분류하기
키워드
-
말뭉치
: 자연어 처리에서 사용하는 텍스트 데이터의 모음, 훈련 데이터셋 -
토큰
: 텍스트에서 공백으로 구분되는 문자열, 종종 소문자로 변환하고 구둣점은 삭제함 -
원-핫 인코딩
: 어떤 클래스에 해당하는 원소만 1이고 나머지는 모두 0인 벡터, 정수로 변환된 토큰을 원-핫 인코딩으로 변환하려면 어휘 사전 크기의 벡터가 필요함 -
단어 임베딩
: 정수로 변환된 토큰을 비교적 작은 크기의 실수 밀집 벡터로 변환, 이 밀집 벡터는 단어 사이의 관계를 표현할 수 있기 때문에 자연어 처리에서 좋은 성능을 발휘
IMDB 리뷰 데이터셋
- 텍스트 자체를 신경망에 전달하는 것은 아님, 텍스트 데이터의 단어를 숫자 데이터로 바꾸는 일반적인 방법은 데이터에 나오는 단어마다 고유한 정수를 부여하는 것
ex) He -> 10 / follows -> 11 / the -> 12 ... He -> 10 / loves -> 13 ...
위 예시와 같이 단어들을 정수에 매핑하고 동일한 단어는 동일한 정수에 매핑함
일반적으로 영어 문장은 모두 소문자로 바꾸고 구둣점을 삭제한 다음 공백을 기준으로 분리함 -> 토큰(token), 하나의 샘플은 여러개의 토큰으로 이루어짐, 1개의 토큰이 하나의 타임스텝에 해당
# 실행마다 동일한 결과를 얻기 위해 케라스에 랜덤 시드를 사용하고 텐서플로 연산을 결정적으로 만듭니다.
import tensorflow as tf
tf.keras.utils.set_random_seed(42)
from tensorflow.keras.datasets import imdb
(train_input, train_target), (test_input, test_target) = imdb.load_data(
num_words=200)
print(train_input.shape, test_input.shape)
-> (25000,) (25000,)위 코드의 결과값을 보면 1차원 배열인 것을 알 수 있음, IMDB 리뷰 텍스트의 길이는 제각각이기 때문에 크기가 고정되어 있는 2차원 배열보다 이뷰마다 별도의 파이썬 리스트에 담아야 메모리를 효율적으로 사용가능함.

개별 리뷰를 담은 파이썬 리스트 객체로 이루어진 넘파이 배열임
print(len(train_input[0]))
->
218 # 218개 토큰
print(len(train_input[1]))
->
189 # 189개 토큰하나의 리뷰 == 하나의 샘플
[첫번째 리뷰에 담긴 내용]
- 앞서 num_words=500으로 지정 -> 어휘 사전에는 500개의 단어만 들어가 있음
- 어휘사전에 없는 단어는 모두 2로 표시됨
print(train_input[0])
->
[1, 14, 22, 16, 43, 2, 2, 2, 2, 65, 2, 2, 66, 2, 4, 173, 36, 2, 5,
25, 100, 43, 2, 112, 50, 2, 2, 9, 35, 2, 2, 5, 150, 4, 172, 112, 167,
2, 2, 2, 39, 4, 172, 2, 2, 17, 2, 38, 13, 2, 4, 192, 50, 16, 6, 147,
2, 19, 14, 22, 4, 2, 2, 2, 4, 22, 71, 87, 12, 16, 43, 2, 38, 76, 15,
13, 2, 4, 22, 17, 2, 17, 12, 16, 2, 18, 2, 5, 62, 2, 12, 8, 2, 8,
106, 5, 4, 2, 2, 16, 2, 66, 2, 33, 4, 130, 12, 16, 38, 2, 5, 25, 124,
51, 36, 135, 48, 25, 2, 33, 6, 22, 12, 2, 28, 77, 52, 5, 14, 2, 16,
82, 2, 8, 4, 107, 117, 2, 15, 2, 4, 2, 7, 2, 5, 2, 36, 71, 43, 2, 2,
26, 2, 2, 46, 7, 4, 2, 2, 13, 104, 88, 4, 2, 15, 2, 98, 32, 2, 56,
26, 141, 6, 194, 2, 18, 4, 2, 22, 21, 134, 2, 26, 2, 5, 144, 30, 2,
18, 51, 36, 28, 2, 92, 25, 104, 4, 2, 65, 16, 38, 2, 88, 12, 16, 2,
5, 16, 2, 113, 103, 32, 15, 16, 2, 19, 178, 32][타깃 데이터 출력]
- 리뷰가 긍정(1)인지 부정(0)인지 나뉨
print(train_target[:20])
->
[1 0 0 1 0 0 1 0 1 0 1 0 0 0 0 0 1 1 0 1]from sklearn.model_selection import train_test_split
train_input, val_input, train_target, val_target = train_test_split(
train_input, train_target, test_size=0.2, random_state=42)
# 훈련세트 8: 검즘세트 2로 훈련세트 나눔- 리뷰 길이의 평균값과 중간값 구함
import numpy as np
lengths = np.array([len(x) for x in train_input])
print(np.mean(lengths), np.median(lengths))
->
239.00925 178.0- 데이터가 한쪽으로 치우쳐져 있는 것을 알 수 있음
- 평균이 중간값보다 높기 때문에 아주 큰 데이터가 존재한다는 것을 유추 가능
- 리뷰 길이를 맞추기 위해 패딩을 사용 -> 패딩을 나타내는 토큰으로 0 사용
- 수동으로 훈련세트에 있는 리뷰를 순회하면서 길이가 100이 되도록 잘라내거나 0으로 패딩할 수 있지만 불편함
import matplotlib.pyplot as plt
plt.hist(lengths)
plt.xlabel('length')
plt.ylabel('frequency')
plt.show()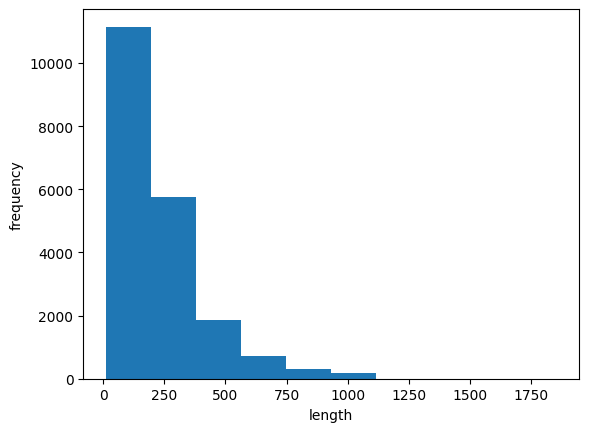
- 케라스는 시퀀스 데이터의 길이를 맞추는 pad_swquences()함수 제공
- train_input의 길이를 100으로 맞춤
- maxlen을 지정 -> 긴 경우는 잘라냄, 짧은 경우 0으로 패딩
from tensorflow.keras.preprocessing.sequence import pad_sequences
train_seq = pad_sequences(train_input, maxlen=100)
print(train_seq.shape)
->
(20000, 100)- 앞 부분에 0이 있음 즉, 이 샘플의 길이는 100이 안됨을 의미함
- 패딩 토큰은 뒷부분이 아니라 앞부분에 추가됨, 시퀀그의 마지막에 있는 단어가 셀의 은닉 상태레 가장 큰 영향을 미치게 되므로 마지막에 패딩을 추가하는 것을 일반적으로 선호하지 않음
- pad_sequences()함수의 padding 매개변수의 기본값을 'pre'에서 'post'로 바꾸면 뒷부분에 패딩 추가하는 것으로 변경 가능
print(train_seq[5])
->
[ 0 0 0 0 1 2 195 19 49 2 2 190 4 2 2 2 183 10
10 13 82 79 4 2 36 71 2 8 2 25 19 49 7 4 2 2
2 2 2 10 10 48 25 40 2 11 2 2 40 2 2 5 4 2
2 95 14 2 56 129 2 10 10 21 2 94 2 2 2 2 11 190
24 2 2 7 94 2 2 10 10 87 2 34 49 2 7 2 2 2
2 2 2 2 46 48 64 18 4 2]순환 신경망 만들기
- Dense나 Conv2D 클래스 대신 SimpleRNN 클래스 사용
- 정수값에 있는 크기 속성을 없애고 각 정수를 고유하게 표현하는 방법인 원-핫 인코딩으로 값을 바꾸면 정수값을 해당 정수 위치의 원소만1이고 나머지는 모두 0으로 변환함
- imdb.load_data() 함수에서 500개의 단어만 사용하도록 지정했기 때문에 고유한 단어는 모두 500개(0-499), 원-핫 인코딩으로 표현하려면 배열의 길이가 500
- 정수 하나마다 모두 500차원의 배열로 변경되었기 때문에 (20000, 100) 크기에서 (20000, 100, 500)으로 바뀜
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.SimpleRNN(8, input_shape=(100, 500)))
model.add(keras.layers.Dense(1, activation='sigmoid'))
# 원-핫 인코딩으로 변환
val_oh = keras.utils.to_categorical(val_seq)
train_oh = keras.utils.to_categorical(train_seq)
print(train_oh.shape)
->
(20000, 100, 500)모델 구조 출력
#책에서는 500으로 설정, 코랩 코드 내에서는 200으로 설정해서 책하고 param 값 다름
model.summary()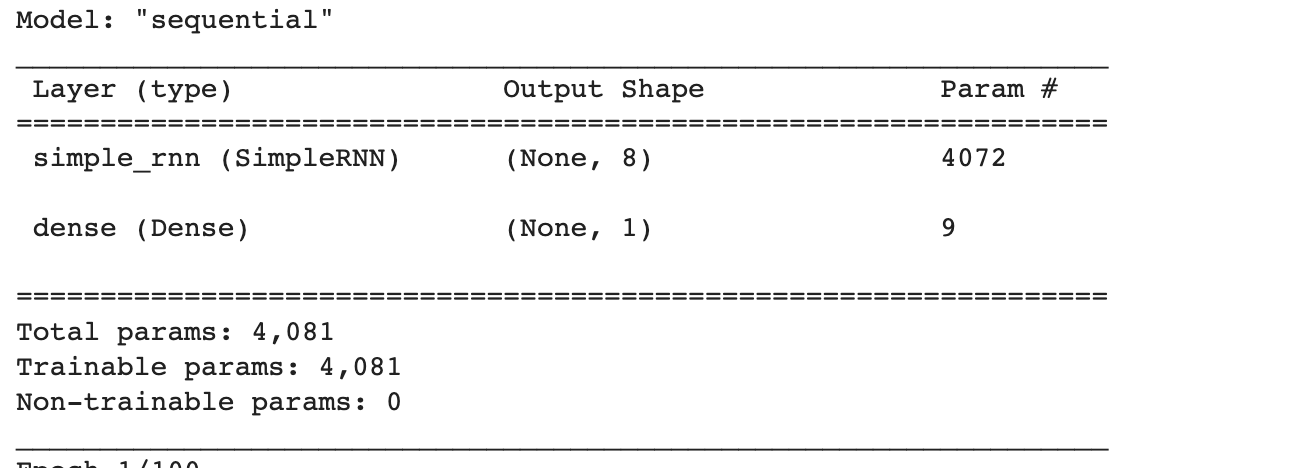
모델의 파라미터는 입력 토큰 500개 x 순환층 뉴런 8개 + 은닉상태 크기 8개 x 뉴런 8개 + 절편 8개 = 4072개
Dense층의 가중치 개수 9개까지 더해서 총 4081개가 됨
순환 신경망 훈련하기
RMSprop 가 default 이지만 학습률을 0.0001,
patience 는 3 으로 설정하였고 조기종료하여 최적 모델을 저장하도록 설정
epoch 횟수 100으로 늘리고 배치 크기는 64로 설정
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-simplernn-model.keras',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model.fit(train_oh, train_target, epochs=100, batch_size=64,
validation_data=(val_oh, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
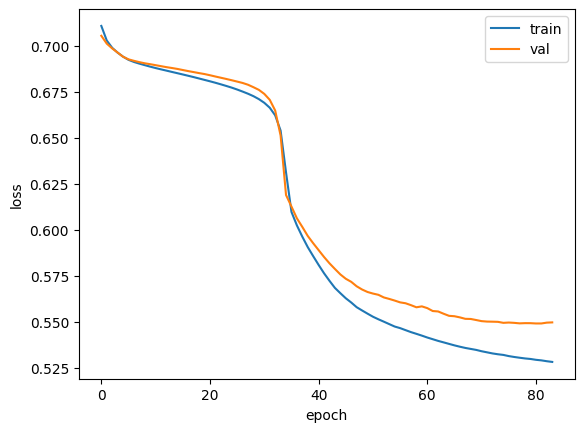
중간에 한번 튀는데 뭐지...
여튼 80번째쯤 가서 에포크 감소가 둔해지는 것으로 보아 에포크 훈련이 83번째에서 훈련을 멈췄다고 볼 수 있다.
keras.utils.to_categorical() 을 사용하여 원-핫 인코딩을 사용해 500개 중 하나만 1이고 나머지를 0으로 만들어서 크기 속성을 없애주었습니다.
하지만 토큰 1개를 500차원으로 늘렸기 때문에 데이터가 엄청 커짐
실제로 원-핫 인코딩 방식은 단어의 의미나 단어 사이의 관계를 전혀 고려하지 않고 만약 단어를 2000개로 늘리면 더욱 크기가 늘어나게 된다
단어 임베딩 사용하기
: 각 단어를 고정된 크기의 실수 벡터로 바꿔줌
단어를 고정된 크기의 실수 벡터로 바꾸어주는 방법인데 단어의 의미를 고려하여 벡터로 표현한 것이다. 예를 들어, [고양이, 강아지, 개구리] 가 있다면 각각을 벡터로 표현하지만 고양이와 강아지 사이의 거리가 개구리와의 거리보다 가깝습니다. 고양이와 강아지는 포유류이고 개구리는 양서류이기 때문이다
참고
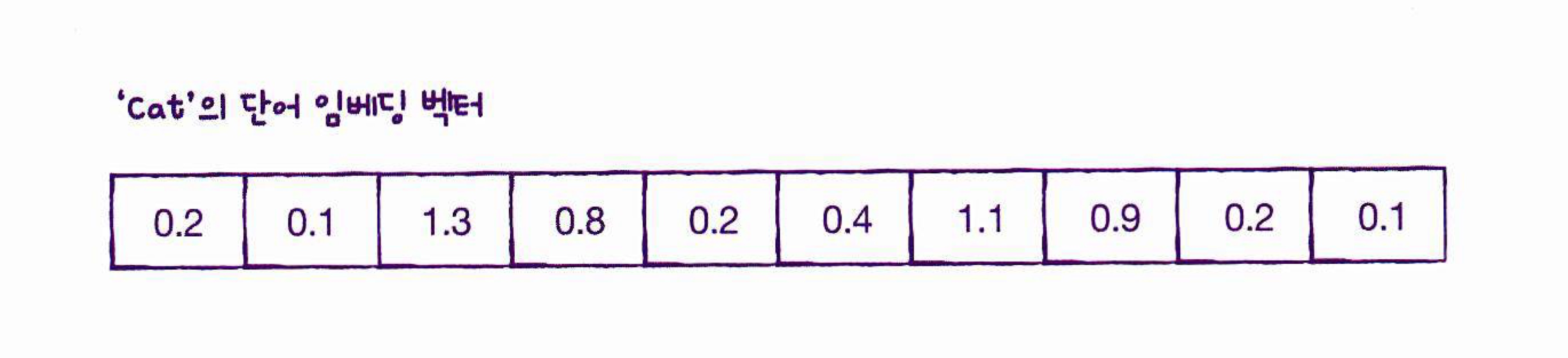
-
원-핫 인코딩된 벡터보다 의미 있는 값으로 채워져 있기 때문에 자연어 처리에서 더 좋은 성능을 내는 경우가 많음
-
단어 임베딩의 장점은 입력으로 정수 데이터를 받는 다는 것
즉, 원-핫 인코딩으로 변경된 train_oh가 아니라 train_seq를 사용할 수 있음 때문에 메모리를 효율적으로 사용가능 -
앞서 원-핫 인코딩은 샘플 하나를 500차원으로 늘렸기 때문에 (100, )크기의 샘플이 (100, 500)으로 커졌음.
-
이와 비슷하게 임베딩도 (100, )크기의 샘플을 (100, 20)과 같이 2차원 배열로 늘림, 원-핫 인코딩과 다르게 훨씬 작은 크기로도 단어를 표현할 수 있음
model2 = keras.Sequential()
# 500 => 어휘 사전 크기, 16 => 임베팅 벡터 크기
model2.add(keras.layers.Embedding(500, 16, input_shape=(100,)))
model2.add(keras.layers.SimpleRNN(8))
model2.add(keras.layers.Dense(1, activation='sigmoid'))
model2.summary()input_shape=(100,) 이 부분은 책에서 input_lenght=100으로 나오는데 실습 코드에서는 shape으로 사용한다. 이유는?
여튼 앞서 샘플 길이를 100으로 맞추었기 때문에 100으로 나타냄

500개 토큰을 크기 16 벡터로 변경하였기 때문에 500x16 크기의 모델 파라미터를 가진다. 뉴런이 8개 이기 때문에 16x8 개, 은닉상태의 가중치 8x8 + 8개 절편 -> 8200개 모델파라미터가 있고 Dense층 9개이므로 8209개

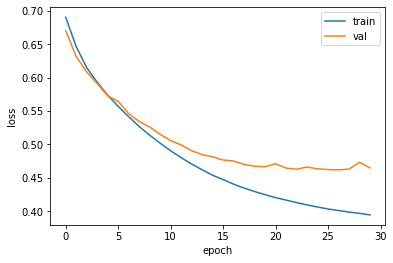
validation loss가 Epoch 27/100 에서 제일 낫기 때문에 조기종료
train loss 는 계속 줄어드는 것을 확인 가능
